

drf-序列化组件
目录
作业讲解
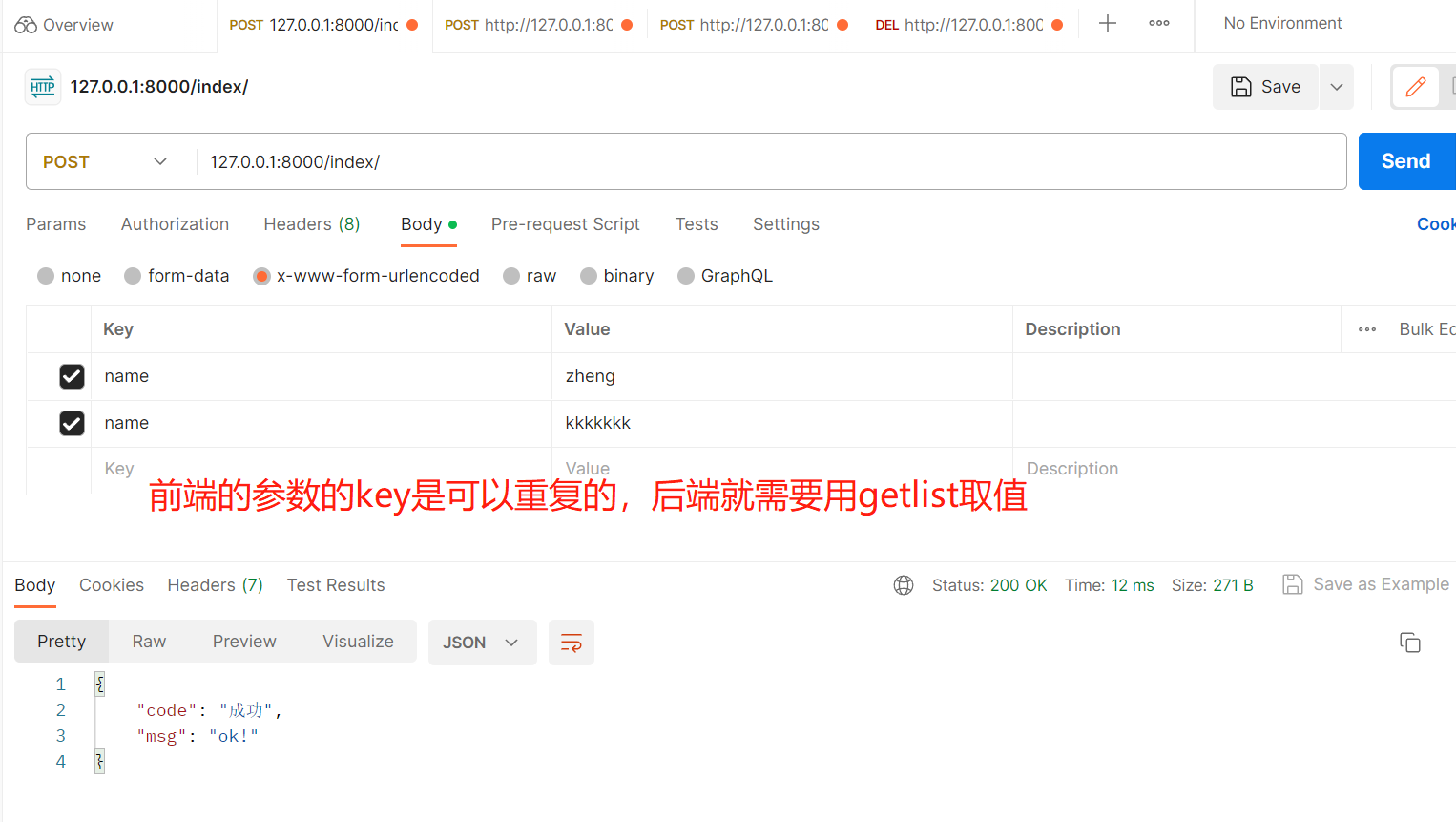
# 装饰器---> 装饰视图函数(fbv)---> 无论是哪种编码格式,在body中的数据,都从request.data中取出来
为什么要写这个?是因为后面,继承APIView后,body中提交的数据,都会从request.data中取出。先自己写一下看怎么实现这种情况,再了解源码中是怎么实现的。
from django.http import JsonResponse
import json
def auth(func):
def inner(request, *args, **kwargs):
# 无论那种方式都定义一个data字典
try:
# 如果是json格式,就成功;如果是其他格式,直接就报错了
request.data = json.loads(request.body)
except Exception as f:
# 报错就说明是urlencoded,或form-data格式
request.data = request.POST
# 此时的request是个新的request了,里面包含了request.data,data是个字典形式
res = func(request, *args, **kwargs)
return res
return inner
@auth # index = auth(index)
def index(request):
# post提交数据,urlencoded,form-data,json
print(request.data)
print(request.FILES) # 文件数据永远都在.FILES中取出
return JsonResponse({'code': '成功', 'msg': 'ok!'})
# 补充:
1. 文件是文件,数据是数据,要区分开
2.取出数据的不同方式:
get():取出最后一条记录
getlist():取所有,列表形式,为什么会有getlist形式来取出数据,是因为前端的数据是可以重名的。urlencode和form-data是可以重复的,jaon格式不可以
# 高级:装饰在视图类上的装饰器,自己想一下怎么写
1 Request类源码分析
1.1 总结的知识点
1 新的request有个data方法,包装成了数据属性,以后只要是在请求body体中的数据,无论什么编码格式,无论什么请求方式。
2 取文件还是从:request.FILES
3 取其他属性,跟之前完全一样 request.method ....
-原理是:新的Request重写了__getattr__,通过反射获取老的request中的属性
4 request.GET 现在可以使用 request.query_params。两者是一摸一样的。(问号的参数:写在地址问号后的都当作是搜索条件)
# get请求能不能在body体中带数据
-能,可以打印出request.POST
1.2 源码分析
Request类的源码
1.第一点:
从from rest_framework.request import Request中进入,找init初始化方法
class Request:
def __init__(self, request): # request是老的request
self._request = request
2.第二点:
取数据应该使用request._request.POST来取值,现在可以使用request.POST来取值,底层发生了什么事情?
我去拿request.method没有,就直接触发魔法方法__getattr__,去执行类中__getattr__方法,拿到返回的字符串。
class Request:
def __getattr__(self, attr): # attr就是对象点的东西的字符串
try:
# 去老的request里面反射出attr字符串对应的方法内存地址或者属性
# getattr字符串对应属性存在时,会执行self._request.attr
return getattr(self._request, attr)
except AttributeError:
return self.__getattribute__(attr)
总结:
-老的request在新的request._request
-照常理来讲,如果取method,应该request._request.method,但是我现在可以request.method。原因是:新的Request重写了__getattr__,通过反射获取老的request中的属性的值。
# 复习:
1.魔法方法之 __getattr__, 点拦截,对象.属性 当属性不存在时,会触发 类中 __getattr__的执行,__getattr__返回什么,就拿到什么
request方法获取数据的不同源码分析
query_params的源码分析:
@property # 把方法包装成了数据属性
def query_params(self):
return self._request.GET
FILES的源码分析:
@property # 把方法包装成了数据属性
def FILES(self):
if not _hasattr(self, '_files'):
self._load_data_and_files()
return self._files
data的源码分析: 根据不同的编码方式,把数据放到data中了
@propertyv # 把方法包装成了数据属性
def data(self):
if not _hasattr(self, '_full_data'):
self._load_data_and_files()
return self._full_data
魔法方法之 __getattr__的应用:
# 魔法方法之 __getattr__, 点拦截,对象.属性 当属性不存在时,会触发 类中 __getattr__的执行,__getattr__返回什么,就拿到什么
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p = Person('lqz', 19)
print(p.name)
# print(p.hobby) # 一个不存在的属性,拿到就会报错
# AttributeError: 'Person' object has no attribute 'hobby'
class Charden():
def __init__(self, name, age):
self.name = name
self.age = age
def __getattr__(self, item):
print('-----', item) # item就是对象点的参数
print(type(item)) # <class 'str'>
return 'sb'
c = Charden('kevin', 20)
print(c.name)
print(c.hobby)
print(c.xxx)
"""
结果是:
kevin
----- hobby
sb
----- xxx
sb
"""
1.2 APIView+Response写个接口
class BookView(APIView):
def get(self, request):
print(request.POST) # <QueryDict: {'name': ['三国演义'], 'price': ['999']}>
print(request.data)
# GET请求的数据,两种打印方式
print(request.GET) # <QueryDict: {'yyy': ['111']}>
print(request.query_params)
# 老的request
# 是面向对象的封装,新的request把老的request封装起来了
print(request._request) # <WSGIRequest: GET '/books/?yyy=111'>
print(type(request._request)) # <class 'django.core.handlers.wsgi.WSGIRequest'>
# 取值可以使用老的request点来取
print(request._request.POST)
return Response('get, ok啦') # 必须要返回数据,新手四件套或者Response
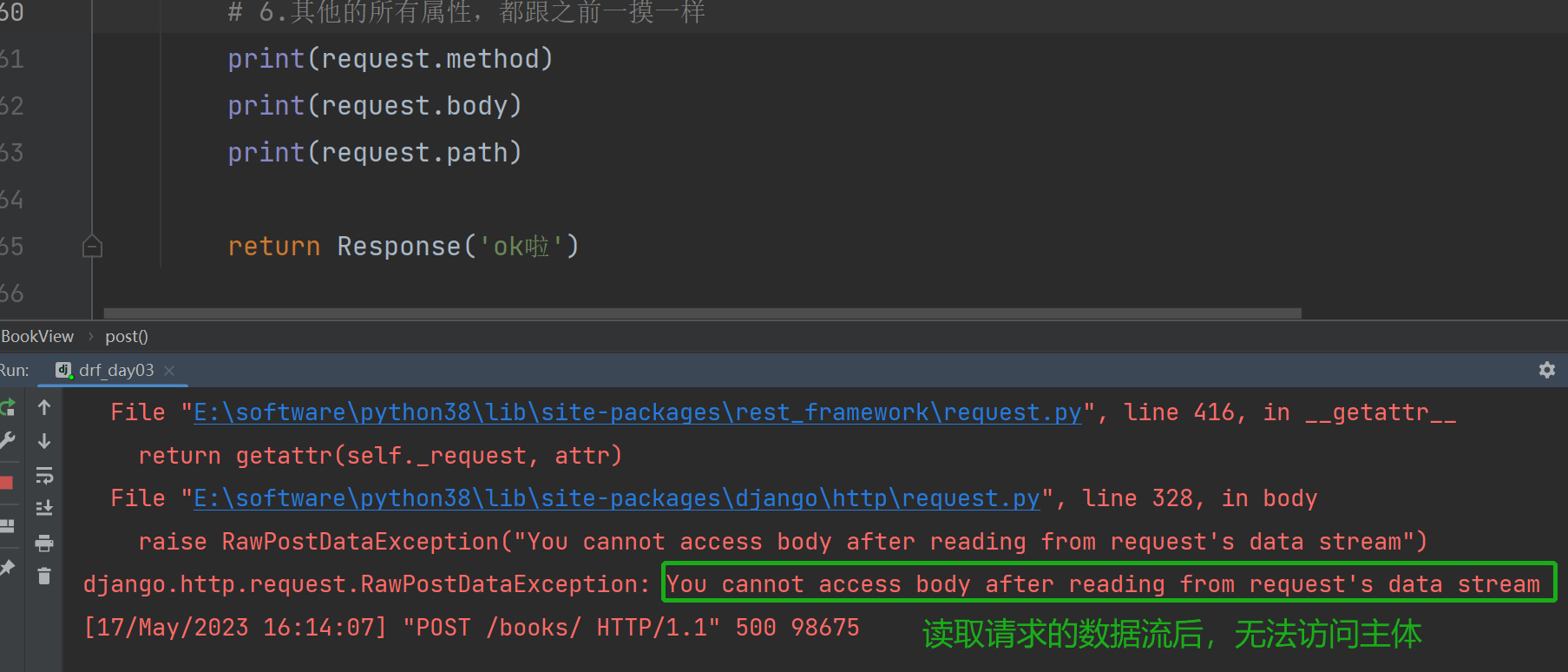
def post(self, request):
print(request.body) # 数据流需要放到最上面读取
# 3.这个request是新的request了
# print(request) # <rest_framework.request.Request: POST '/books/'>
# print(type(request)) # <class 'rest_framework.request.Request'>
print(request.data) # 原来的的request没有data属性,新的有了
# 4.原来的request.POST中还有数据
print(request.POST)
# 5. 提交文件form-data格式,还在request.FILES中
print(request.FILES)
# 6.其他的所有属性,都跟之前一摸一样
print(request.method)
print(request.path) # 路由 # /books/
return Response('ok啦')
"""
扩展:
1.Response跟JsonResponse很想,但是比后者更加强大。
JsonResponse只能直接返回字典格式,想返回列表,需要加个safe=True。并且不允许传字符串,想要传字符串需要使用HttpResponse
Response可以传字符串,列表,字典都可以,就是不能传对象
2.post请求不同编码格式的结果是:
urlencoded: <QueryDict: {'name': ['三国演义'], 'price': ['999']}>
form_data: <QueryDict: {'charset': ['form_data'], 'name': ['kevin']}>
json: {'char': 'json', 'xxx': 'kkkk', 'age': 19}
总结:urlencoded和form-data返回一个QueryDict,QueryDict继承字典。json格式返回的就是字典。他们三者都可以根据字典的key取值。
3. 新的request的类型是:
<class 'rest_framework.request.Request'>
4. 原来的request.POST中还有数据。
5. 文件数据request.data中也有,但取文件仍然还是使用request.FILES
6. 其他属性的查找跟之前一样:
request.body:请求数据流,需要放到最上面读取
request.method:请求方式
request.path:请求路径
"""
2 序列化组件介绍
1. 序列化,序列化器会把模型对象(queryset,单个对象)转换成字典,经过response以后变成json字符串,给前端。
2. 反序列化,把客户端发送过来的数据,经过request.data后变成字典,序列化器可以把字典转成模型(表模型:单个对象)。
3. 反序列化,完成数据校验功能。(把数据保存到数据库之前)
3 序列化类的基本使用
# 1 创建book表模型,数据迁移
# 2 写查询所有图书的接口:APIVie+序列化类+Response
"""面试题"""
BigIntegerField跟IntegerField有什么区别?
IntegerField: -2^32 ~ 2^31-1 十亿级别
BigIntegerField: -2^63 ~ 2^63-1
models.py
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.BigIntegerField()
3.1 查询所有和查询单条
views.py
from .models import Book
from .serializer import BookSerializer
class BookView(APIView):
def get(self, request):
"""查询所有"""
book_list = Book.objects.all()
# 使用序列化类,完成序列化 两个很重要参数: instance实例,对象 data:数据
# instance=None, data=empty,
# 如果是多条many=True 如果是queryset对象,就要写
# 如果是单个对象 many=False,默认是False
serializer = BookSerializer(instance=book_list, many=True) # 实例化一个对象
# serializer.data # 把qs对象,转成列表套字典 ReturnList格式
print(serializer.data)
# [OrderedDict([('id', 1), ('name', '西游记'), ('price', 100)]), OrderedDict([('id', 2), ('name', '红楼梦'), ('price', 200)])]
# 上面是列表套字典的形式,只是表现的不一样
print(type(serializer.data))
# <class 'rest_framework.utils.serializer_helpers.ReturnList'>
return Response({'code': 100, 'msg': '查询所有成功', 'data': serializer.data})
class BookDetailView(APIView):
def get(self, request, pk):
"""查询单条"""
book = Book.objects.all().get(pk=pk) # 这样写如果数据不存在会报错
serializer = BookSerializer(instance=book)
return Response({'code': 100, 'msg': '查询一条成功', 'data': serializer.data})
urls.py
urlpatterns = [
path('books/', views.BookView.as_view()),
path('books/<int:pk>/', views.BookDetailView.as_view()),
]
序列化类
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 要序列化的字段
id = serializers.IntegerField()
name = serializers.CharField()
price = serializers.IntegerField()
总结
# 序列化类的使用
1 写一个类,继承serializers.Serializer
2 在类中写字段,要序列化的字段
3 在视图类中使用:(多条,单条)
serializer = BookSerializer(instance=book_list, many=True) # 多条
serializer = BookSerializer(instance=book) # 单条
其中有两个重要的参数:instance=None, data=empty,
1. instance实例,对象
2. data:数据
3. many
多条数据,many=True,(是queryset对象,就要写)
单条数据,many=False,默认是False,可以省略。(是单个对象)
4 常用字段类和参数(了解)
4.1 常用字段类
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol=’both’, unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
# IntegerField CharField DateTimeField DecimalField
# ListField和DictField---> 比较重要,但是后面以案例形式讲
4.2 字段参数(校验数据来用的)
选项参数:(CharField,IntegerField)
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
通用参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
# read_only write_only 很重要,后面以案例讲
5 反序列化之校验
# 反序列化,有三层校验
-1 字段自己的(写的字段参数:required max_length 。。。)
-2 局部钩子:写在序列化类中的方法,方法名必须是 validate_字段名
def validate_name(self, name):
if 'sb' in name:
# 不合法,抛异常
raise ValidationError('书名中不能包含sb')
else:
return name
-3 全局钩子:写在序列化类中的方法 方法名必须是 validate
def validate(self, attrs):
price = attrs.get('price')
name = attrs.get('name')
if name == price:
raise ValidationError('价格不能等于书名')
else:
return attrs
# 只有三层都通过,在视图类中:
ser.is_valid(): 才是True,才能保存
6 反序列化之保存
# 新增接口:
-序列化类的对象,实例化的时候:ser = BookSerializer(data=request.data)
-数据校验过后----> 调用 序列化类.save()---> 但是要在序列化类中重写 create方法
def create(self, validated_data):
book=Book.objects.create(**validated_data)
return book
# 修改接口
-序列化类的对象,实例化的时候:ser = BookSerializer(instance=book,data=request.data)
-数据校验过后----> 调用 序列化类.save()--->但是要在序列化类中重写 update方法
def update(self, book, validated_data):
for item in validated_data: # {"name":"jinping","price":55}
setattr(book, item, validated_data[item])
book.save()
return book
# 研究了一个问题
在视图类中,无论是保存还是修改,都是调用序列化类.save(),底层实现是根据instance做一个判断
# 研究源码
直接写序列化类.save()会报错。没有实现create()方法。
Serializer类的父类BaseSerializer中有个create()方法
class BaseSerializer(Field):
def update(self, instance, validated_data):
raise NotImplementedError('`update()` must be implemented.') # 直接抛异常
def create(self, validated_data):
raise NotImplementedError('`create()` must be implemented.')
def save(self, **kwargs):
if self.instance is not None:
# self.instance不是None,调update
self.instance = self.update(self.instance, validated_data)
else:
# self.instance是None,调create
self.instance = self.create(validated_data)
return self.instance
需要在自己的类中写create()、update()方法
为什么要重新写create()、update()方法?

7 5个接口代码
路由
urlpatterns = [
path('books/', views.BookView.as_view()),
path('books/<int:pk>/', views.BookDetailView.as_view()),
]
视图
from .models import Book
from .serializer import BookSerializer
class BookView(APIView):
def get(self, request):
"""查询所有"""
book_list = Book.objects.all()
# 使用序列化类,完成序列化 两个很重要参数: instance实例,对象 data:数据
# 如果是多条many=True 如果是queryset对象,就要写
# 如果是单个对象 many=False,默认是False
serializer = BookSerializer(instance=book_list, many=True)
# serializer.data # 把qs对象,转成列表套字典 ReturnList
# print(serializer.data)
# print(type(serializer.data))
# return Response(serializer.data)
return Response({'code': 100, 'msg': '成功', 'data': serializer.data})
# 新增
def post(self, request):
"""新增数据"""
# 前端会传入数据,request.data--->把这个数据保存到数据库中
# 借助于序列化类,完成 校验和反序列化
# data 前端传入的数据 {"name":"三国演义","price":88}
ser = BookSerializer(data=request.data)
# 校验数据
if ser.is_valid(): # 三层:字段自己的校验,局部钩子校验,全局钩子校验
# ser.is_valid()是True说明,校验通过,保存数据
print(ser.validated_data) # 字典 # validated_data:校验过后的数据
# 如果没有save,如何保存,自己做
# Book.objects.create(**ser.validated_data)
ser.save() # 会保存,但是会报错,因为它不知道你要保存到那个表中
return Response({'code': 100, 'msg': '新增成功'})
else:
print(ser.errors) # 校验失败的错误
return Response({'code': 101, 'msg': '新增失败', 'errors': ser.errors})
class BookDetailView(APIView):
def get(self, request, pk):
"""查询单条数据"""
book = Book.objects.all().get(pk=pk)
serializer = BookSerializer(instance=book)
return Response({'code': 100, 'msg': '成功', 'data': serializer.data})
def put(self, request, pk):
"""修改数据"""
book = Book.objects.get(pk=pk)
# instance:实例化的对象 data:前端传来的数据
ser = BookSerializer(instance=book, data=request.data)
# 数据校验
if ser.is_valid():
ser.save() # 也会报错,重写update
return Response({'code': 100, 'msg': '修改成功'})
else:
return Response({'code': 101, 'msg': '修改失败', 'errors': ser.errors})
序列化类
# from rest_framework.serializers import Serializer
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
from .models import Book
class BookSerializer(serializers.Serializer):
# 要序列化的字段
id = serializers.IntegerField(required=False) # 前端传入数据,可以不填这个字段
name = serializers.CharField(allow_blank=True, required=False, max_length=8,
min_length=3, error_messages={'max_length': '太长了'}) # allow_blank: 这个字段传了,value值可以为空
price = serializers.IntegerField(max_value=100, min_value=10, error_messages={'max_value': '必须小于100'})
# price = serializers.CharField()
# 局部钩子:给某个字段做个校验
# 书名中不能包含sb
# validate_字段名
def validate_name(self, name):
if 'sb' in name:
# 不合法,抛异常
raise ValidationError('书名中不能包含sb')
else:
return name
def validate_price(self, item):
if item == 88:
raise ValidationError('价格不能等于88')
else:
return item
# 全局钩子
# 价格和书名不能一样 validate
def validate(self, attrs):
price = attrs.get('price')
name = attrs.get('name')
if name == price:
raise ValidationError('价格不能等于书名')
else:
return attrs
def create(self, validated_data): # 固定写法
# validated_data校验过后的数据,字典
book = Book.objects.create(**validated_data)
return book
# def update(self, book, validated_data):
# # instance 要修改的对象
# # validated_data:前端传入,并且校验过后的数据
# book.name = validated_data.get('name')
# book.price = validated_data.get('price')
# # 一定不要忘了
# book.save() # 数据库的保存 # 模型类对象的save方法
# return book
# 优化修改功能(高级写法)
def update(self, book, validated_data):
for item in validated_data: # {"name":"jinping","price":55}
setattr(book, item, validated_data[item])
# 等同于下面
# setattr(book,'name','jinping')
# setattr(book,'price',55)
# 等同于
# book.name = validated_data.get('name')
# book.price = validated_data.get('price')
book.save() # 模型类对象的save方法,跟视图中的序列化对象点save()要区分开
return book
解耦:
好处:是后期拓展好
解耦:
在Django中使用解耦的主要原因有以下几点:
提高代码的可维护性:将不同的功能和逻辑分解成不同的模块和函数,可以使得代码更加清晰易懂,便于维护和修改。
提高代码的可扩展性:模块和函数的独立性可以使得代码更容易进行扩展和修改,从而满足业务需求的变化。
提高代码的灵活性:通过使用装饰器和观察者模式等技术,可以将代码的控制权交还给应用程序的用户,从而使得代码更加灵活。
提高代码的性能:将不同的功能和逻辑分解成不同的模块和函数可以减少代码的重复和耦合,从而提高代码的性能和效率。
表模型
from django.db import models
# Create your models here.
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.BigIntegerField()
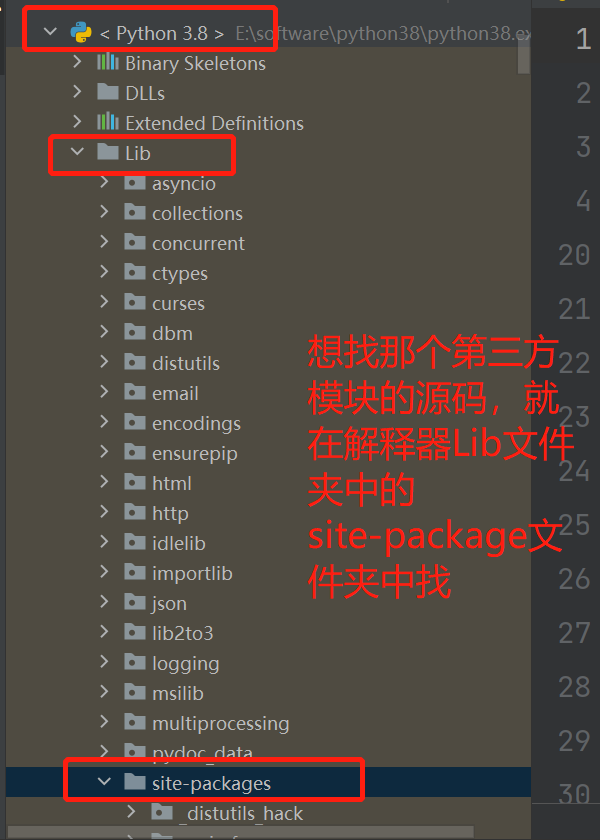
补充:查看源码的位置


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具