

Django基础之模型层 -- ORM
Django模型层(models层)之ORM介绍
我们在使用Django框架开发web应用的过程中,不可避免地会涉及到数据的管理操作(增、删、改、查),而一旦谈到数据的管理操作,就需要用到数据库管理软件,例如mysql、oracle、Microsoft SQL Server等。
ORM全称Object Relational Mapping,即对象关系映射,是在pymysq之上又进行了一层封装,对于数据的操作,我们无需再去编写原生sql,取代代之的是基于面向对象的思想去编写类、对象、调用相应的方法等,ORM会将其转换/映射成原生SQL然后交给pymysql执行。
sqlite3数据库
pycharm查看sqlite3文件
直接双击db.sqlite3文件
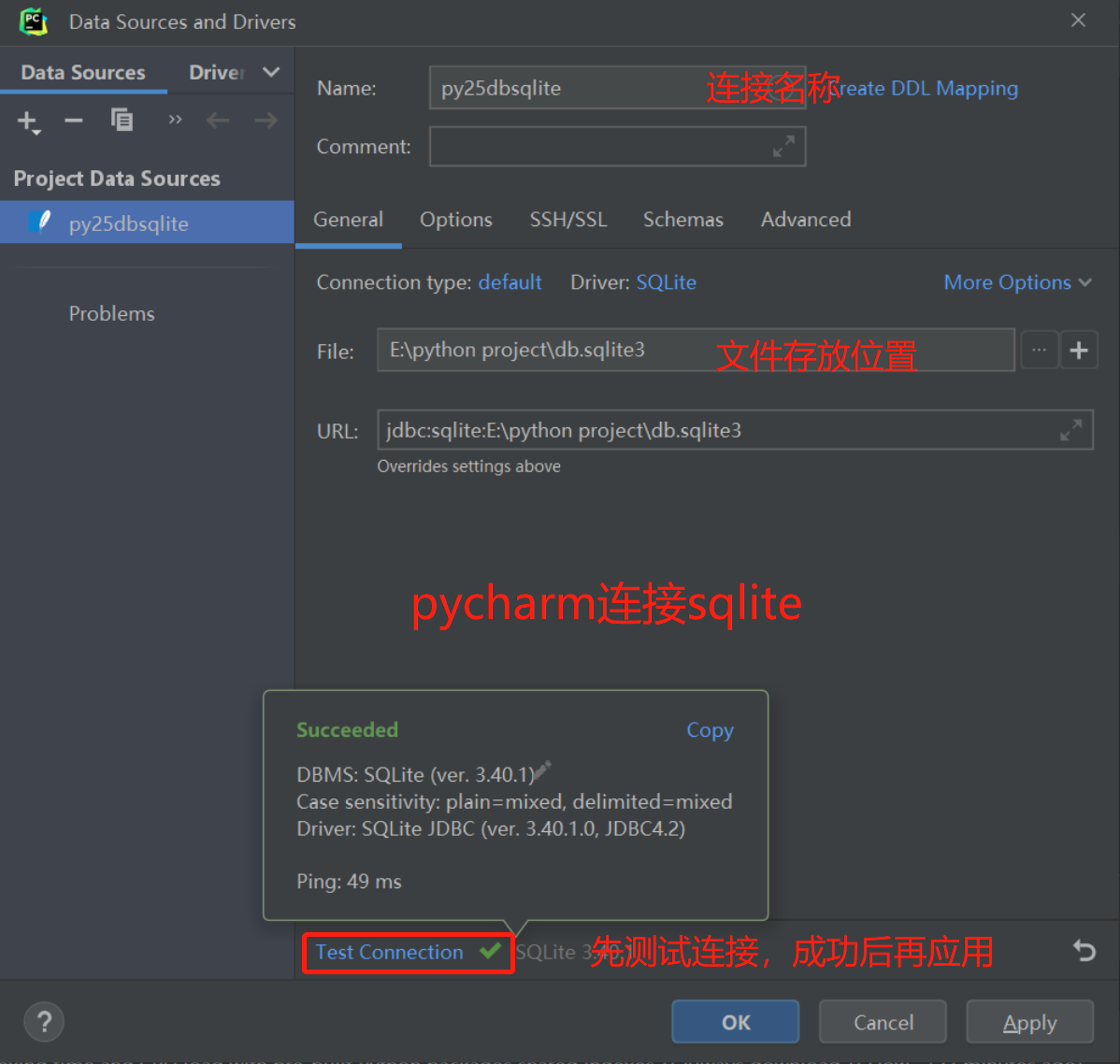
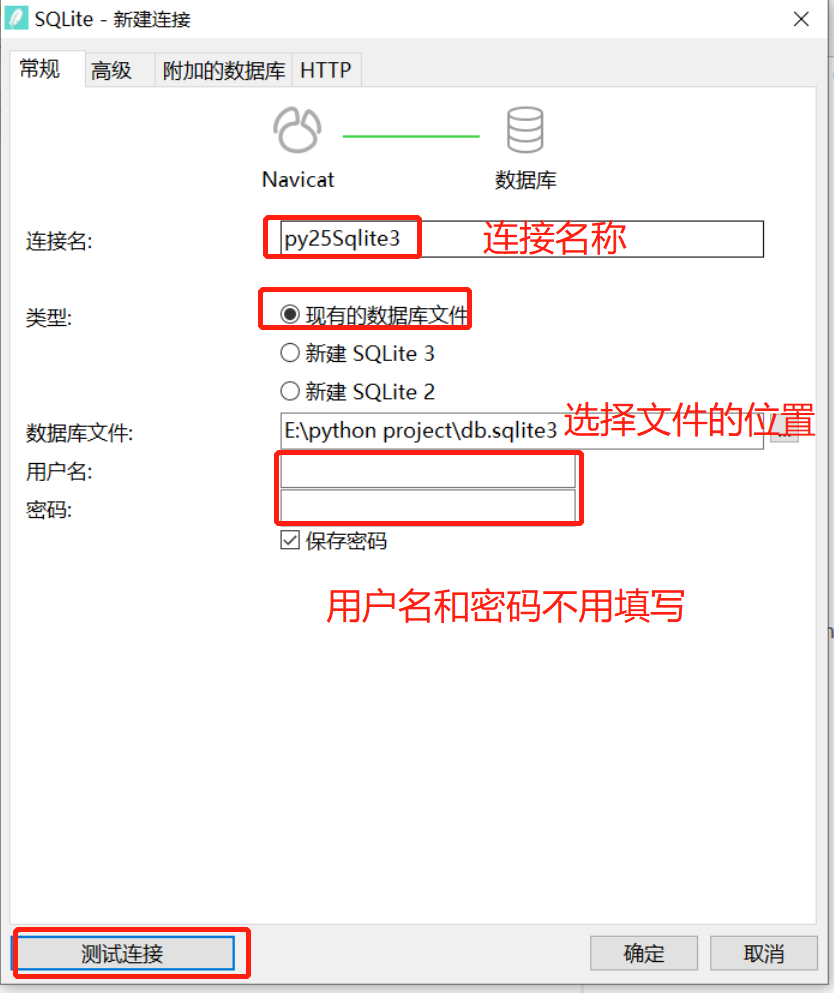
Navicate连接sqlite3
进入Navicate软件,点击左上角连接 --> SQLite
测试环境的搭建
在开发django项目时,如果我们想跳过django的启动与操作流程,只测试某一部分的代码的功能,需要首先引入django的配置环境才可以。
在test.py文件创建django环境,代码如下
# 创建Django环境
# 在单个文件中启动Django就可以使用这几行代码
if __name__ == '__main__':
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "项目名.settings")
import django
django.setup() # 启动Django
# 编写测试代码,直接运行该文本文件即可
单表操作
单表的增删改查
在test.py文件,配置好django环境。
from django.test import TestCase
# Create your tests here.
if __name__ == '__main__':
import os
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day54D.settings")
import django
django.setup()
1.增加
# 在这里面导入models文件
# 以后再写ORM相关的操作的时候,就写在这个下面
from app01 import models
# 增加
# 第一种方式
models.User.objects.create(username='kevin', password='123', age=20)
# 第二种方式
# cls = models.User # <class 'app01.models.User'>
res = models.User(username='tank', password='123', age=23) # <class 'app01.models.User'>
res.save()
2.修改
# 第一种方式
models.User.objects.filter(pk=1).update(username='jerry', password='123')
# 第二种方式
user_obj = models.User.objects.filter(pk=3).first()
user_obj.username = 'tom'
user_obj.password = '888'
user_obj.age = 16
user_obj.save()
3.删除
# 第一种方式
models.User.objects.filter(pk=2).delete()
# 第二种方式
user_obj = models.User.objects.filter(pk=1).first()
user_obj.delete()
4.查询
# QuerySet对象,类似与列表套对象的形式,[obj1,obj2]
res = models.User.objects.filter(pk=3) # <QuerySet [<User: User object>]>
print(res) # QuerySet对象,
print(res[0]) # 具体的对象 # User object
print(res[0].username) # 对象具体的属性 # tom
print(res[0].password)
print(res[0].age)
print(models.User.objects.filter(age=16)) # <QuerySet [<User: User object>, <User: User object>]>
# User object,用户对象,就是这个用户的一条记录信息
res1 = models.User.objects.filter(pk=3).first() # User object
print(res1)
print(res1.username)
print(models.User.objects.filter(username='kevin', password='666').first()) # User object
print(models.User.objects.filter(username='kevin').filter(password='666').first()) # 与上面是等价的
# 查询所有
res2 = models.User.objects.all()
print(res2) # <QuerySet [<User: User object>, <User: User object>, <User: User object>, <User: User object>]>
for obj in res2:
print(obj.username)
# 查询一条记录的两种方法
one1 = models.User.objects.filter(pk=10).first() # 当查询记录不存在的时候返回None
print(one1) # User object # None
one2 = models.User.objects.get(pk=10) # 查询记录不存在的时候,报错
print(one2) # User object # 报错
try:
one2 = models.User.objects.get(pk=3)
except Exception:
print('数据查询不存在')
常见的十几种查询方法
models.py文件:
def __str__(self): # str魔法,打印时直接运行该方法
return self.username
1.all() 查询所有数据
2.filter() 带有过滤条件的查询
3.get() 直接拿数据对象 但是条件不存在直接报错
4.first() 拿queryset里面第一个元素
5.last() 拿queryset里面最后一个元素
res = models.User.objects.all().first()
print(res)
res = models.User.objects.all().last()
print(res)
6.values value_list
# values:指定查询的字段,返回的是列表套字典
# value_list:指定查询的字段,返回的是列表套元组
# select username, password from user
res = models.User.objects.values('username', 'password') # 指定查询的字段,返回的是列表套字典
# <QuerySet [{'username': 'tom', 'password': '888'}, {'username': 'tank', 'password': '123'}]>
print(res)
res = models.User.objects.values_list('username', 'password', 'age') # 指定查询的字段,返回的是列表套元组
# <QuerySet [('tom', '888', 16), ('tank', '123', 23)]>
print(res)
7.distinct()
# 去重, 每一条数据都要完全一样,如果说带主键,一定不会重复
res = models.User.objects.all().values('password', 'age').distinct()
print(res)
8.排序order_by()
# order by age asc/desc
res = models.User.objects.all().order_by('age') # 默认是升序排列
res = models.User.objects.all().order_by('-age') # 降序排列
res = models.User.objects.all().order_by('age', 'id')
res = models.User.objects.all().order_by('age', '-id')
print(res)
9.反转reverse()
# 反转,先排序,数据要先有序才能翻转
res = models.User.objects.all().order_by('-age').reverse() # 与order_by('age')一致
print(res)
10.计数count()
# 对表中的数据计数
# select count(*) from user
res = models.User.objects.count()
print(res)
11.排除exclude()
# 排除用户名等于kevin1,输出剩下的用户对象
res = models.User.objects.exclude(username='kevin1')
print(res)
12.存在exists()
# 返回布尔值,存在该对象返回True,不存在返回False。
# res = models.User.objects.filter(pk=3).exists()
print(res)
查看原生SQL语句
query属性
注意:返回的结果只有是QuerySet对象的时候,才有query属性,才能看sql语句。
res = models.User.objects.values_list('username', 'password', 'age')
print(res.query)
# SELECT "app01_user"."username", "app01_user"."password", "app01_user"."age" FROM "app01_user"
# res = models.User.objects.create(username='kevin', password='123', age=20) # 插入成功的这条记录对象
# print(res.query) # 会报错
在settings中配置LOGGING日志
# 查看原生SQL语句的配置日志
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level': 'DEBUG',
},
}
}
实际应用:
创建表、QuerySet对象、记录对象 ... 都会输出原生的SQL语句。
res = models.User.objects.values_list('username', 'password', 'age')
print(res)
# (0.000) SELECT "app01_user"."username", "app01_user"."password", "app01_user"."age" FROM "app01_user" LIMIT 21; args=()
res = models.User.objects.create(username='kevin', password='123', age=20) # 插入成功的这条记录对象
# (0.008) INSERT INTO "app01_user" ("username", "password", "age") VALUES ('kevin', '123', 20); args=['kevin', '123', 20]
基于双下划线查询
属性__gt=值:大于值
属性__lt=值:大于值
属性__gte=值:大于等于值
属性__lte=值:大于等于值
属性__in=[值1,值2,值3]:值在列表中
属性__range=[11,40]:值位于区间[11,40]之间
属性__contains='s':模糊查找,属性值中有s
属性__startswith='s':模糊查找,属性值以s开头
属性__endswith='s':模糊查找,属性值中有s结尾
# 针对时间有:
属性__year='2023':年
属性__month='5' :月
属性__day='28' :日
属性__week_day='5' :星期
实际应用:
# 1.年龄大于19岁的数据
# select * from user where age > 10
res = models.User.objects.filter(age__gt=19).all()
print(res)
# 2.年龄小于19岁的数据
res = models.User.objects.filter(age__lt=19).all()
print(res)
# 年龄大于等于20岁的数据 e---------->equal
res = models.User.objects.filter(age__gte=20).all()
# 小于等于20岁
res = models.User.objects.filter(age__lte=20).all()
# 年龄是 16 或者 20 或者 23
# select * from user where age in (11, 20, 23)
res = models.User.objects.filter(age__in=[11,20,23]).all()
print(res)
# 年龄在18到40岁之间的,首尾都要
# select * from user where age between 18 and 40
res = models.User.objects.filter(age__range=[11,40])
print(res)
# 查询出名字里面含有s的数据,模糊查询
# select * from user where username like '%s%'
res = models.User.objects.filter(username__contains='s').all()
print(res)
# 用户名以s开头的
# select *from user where username like 's%'
res = models.User.objects.filter(username__startswith='s').all()
# 以s结尾
res = models.User.objects.filter(username__endswith='s').all()
print(res)
models.py
User表中新增一个注册时间字段
reg_time = models.DateField(default='2023-5-1')
# 数据类型
models.DateField(auto_now=True, auto_now_add=True) # 年月日
models.DateTimeField() # 年月日 时分秒
""""
auto_now=False,:当你往表里面更新一条记录的时候,这个字段的值会自动把当前时间每次都更新,你不用自己写了
auto_now_add=False: 当你往表里面新插入一条记录的时候,这个字段的值会自动把当前时间写进入,你不用自己写了
"""
# 查询出注册时间是 2023 5月
# select date_format(reg_time, '%Y-%m') from user where date_format(reg_time, '%Y-%m') = '2023-05'
res = models.User.objects.filter(reg_time__month='5') # 查5月的
res = models.User.objects.filter(reg_time__month='5', reg_time__year='2023') # 查2023年5月的
print(res)
多表查询之表关系操作
前期表准备
# 用图书表,出版社表,作者表,作者详情表
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 一对多
publish = models.ForeignKey(to='Publish')
# 多对多
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 一对一
author_detail = models.OneToOneField(to='AuthorDetail')
class AuthorDetail(models.Model):
phone = models.BigIntegerField() # 电话号码用BigIntegerField或者直接用CharField
addr = models.CharField(max_length=64)
一对多的外键增删改查数据
一定要先填写没有外键的表。
1.增加
# 如何增加一本书?
# 第一种方式:直接指定外键字段的id值
models.Book.objects.create(title='洋哥自传', price=99999, publish_id=1) # 日期是自增的
# 第二种方式:先查出对应出版社的记录对象,book表中添加对象
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.create(title='洋哥自传1', price=99, publish=publish_obj)
2.修改
# 第一种方式
models.Book.objects.filter(pk=5).update(title='哈哈哈', publish_id=2)
# 第二种方式
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj)
多对多外键增删改查
多对多本质上就是在操作第三张表。
# 增加
对象.外键字段.add()
# 删除
对象.外键字段.remove()
# 修改
对象.外键字段.set([ ])
# 查询
对象.外键字段.all()[0]
1.增加
# 给书籍主键为2的图书添加一个作者
book_obj = models.Book.objects.filter(pk=3).first()
print(book_obj.authors) # app01.Author.None------------>就相当于已经到了第三张表
book_obj.authors.add(3) # 增加了pk=3的作者
# 图书和作者是不是多对多,一本书可以有多个作者
book_obj.authors.add(2, 1)
2.删除
book_obj.authors.remove(1)
book_obj.authors.remove(2, 3)
3.修改
# book_obj.authors.set(1, 3) # 这样写是有问题的
# TypeError: set() takes 2 positional arguments but 3 were given
book_obj.authors.set([1, 3])
book_obj.authors.set([2]) # 单个序号也要放到列表中
4.查询
# 查询图书主键为1的所有作者
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all())
# <QuerySet [<Author: Author object>, <Author: Author object>, <Author: Author object>]>
# QuerySet列表中对象的顺序是从表中从上到下取到赋值的
author_obj = book_obj.authors.all()[0]
print(author_obj.name) # tank
多表查询
多表查询的方式有两种:子查询和连表查询。
正反向的概念
-
正向:外键在我手上,我查你,就是正向查询
-
反向:外键在我手上,你查我,就是反向查询
eg:
book----------外键字段在book表中------------>publish-------------->正向查询
publish-------外键字段在book表中------------->book----------------->反向查询
'''
判断出来正反向之后,如何查询
正向查询按字段(外键字段)
反向查询按表名小写或者表名小写_set
'''
子查询
# 1.查询书籍主键为1的出版社 --- 一对多
# 先查询书籍,赋值给一个对象
book_obj = models.Book.objects.filter(pk=1).first()
# book --> publish 是正向查询 ----> 正向查询使用外键字段
# book对象点外键字段(publish) ---> 就相当于是出版社对象了
print(book_obj.publish)
publish_obj = book_obj.publish # Publish object
# 输出出版社的信息
print(publish_obj.name) # 人民出版社
print(publish_obj.addr) # 上海
# 2.查询书籍主键为2的作者 --- 多对多
# book --> author 是正向查询 ----> 正向查询使用外键字段
book_obj = models.Book.objects.filter(pk=2).first()
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all()) # <QuerySet [<Author: Author object>, <Author: Author object>]>
# 3.查询作者jerry的电话号码 --- 一对一
# author --> authordetail 是正向查询 ----> 正向查询使用外键字段
author_obj = models.Author.objects.filter(name='jerry').first()
print(author_obj) # Author object
author_detail_obj = author_obj.author_detail
print(author_detail_obj) # AuthorDetail object
print(author_detail_obj.phone) # 120
# 4.查询出版社是北京出版社出版的书 --- 一对多
# 先查出出版社的对象
publish_obj = models.Publish.objects.filter(name='北京出版社').first()
# publish --> book 是反向查询 ----> 反向查询按表名小写或者_set
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all()) # <QuerySet [<Book: Book object>, <Book: Book object>]>
book_obj = publish_obj.book_set.all()
print(book_obj[0].title) # 笑傲
print(book_obj[1].title) # 洋哥自传
# 5.查询作者是jerry写过的书 --- 多对多
author_obj = models.Author.objects.filter(name='jerry').first()
# author --> book 是反向查询 ----> 反向查询按表名小写或者_set
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all()) # <QuerySet [<Book: Book object>, <Book: Book object>]>
book_obj = author_obj.book_set.all()
print(book_obj[0].title) # 红楼梦
print(book_obj[1].title) # 余华
# 6.查询手机号是110的作者姓名 --- 一对一
# authordetail表
author_detail_obj = models.AuthorDetail.objects.filter(phone='110').first()
# authordetail --> author 是反向查询 ----> 反向查询按表名小写或者_set
print(author_detail_obj.author) # Author object
print(author_detail_obj.author.name) # kevin
连表查询(基于双下划线)
基于双下划线的查询的关键是:
可以使用双下滑线语法来指定多个表之间的关系。
- 正向,按照外键字段名__字段。
- 反向,是表名小写__字段。
可以在查询中使用多双下划线构成一个嵌套属性路径,以便从一个表到达另一个表的字段。
# 1.查询jerry的手机号和作者姓名
# author --> author_detail 是正向查询 ---> 外键字段
author_obj = models.Author.objects.filter(name='jerry').values('name', 'author_detail__phone') # 外键字段__字段名
print(author_obj) # QuerySet对象
# <QuerySet [{'name': 'jerry', 'author_detail__phone': 120}]>
# author_detail --> author 是反向查询 ---> 表名小写
author_detail_obj = models.AuthorDetail.objects.filter(author__name='jerry').values('author__name', 'phone')
print(author_detail_obj)
# <QuerySet [{'author__name': 'jerry', 'phone': 120}]>
# 2.查询书籍主键为1的出版社名称和书的名称
# book --> publish 是正向查询 ---> 外键字段
book_obj = models.Book.objects.filter(pk=1).values('title', 'publish__name')
print(book_obj)
# <QuerySet [{'title': '红楼梦', 'publish__name': '人民出版社'}]>
# publish --> book 是反向查询 ---> 表名小写
publish_obj = models.Publish.objects.filter(book__pk=1).values('book__title', 'name')
print(publish_obj)
# <QuerySet [{'book__title': '红楼梦', 'name': '人民出版社'}]>
# 3.查询书籍主键为1的作者姓名
# book --> author 是正向查询 ---> 外键字段
models.Book.objects.filter(pk=1).values('authors__name')
print(book_obj)
# <QuerySet [{'authors__name': 'jerry'}, {'authors__name': 'kevin'}, {'authors__name': 'tank'}]>
# publish --> book 是反向查询 ---> 表名小写
author_obj = models.Author.objects.filter(book__pk=1).values('name')
print(author_obj)
# <QuerySet [{'authors__name': 'jerry'}, {'authors__name': 'kevin'}, {'authors__name': 'tank'}]>
# 4.查询书籍主键是1的作者的手机号
# book ---> author ---> author_detail 正向查询 ---> 外键字段
author_detail_obj = models.Book.objects.filter(pk=1).values('authors__author_detail__phone')
print(author_detail_obj)
# <QuerySet [{'authors__author_detail__phone': 120}, {'authors__author_detail__phone': 110}, {'authors__author_detail__phone': 130}]>
# 反向查询 ---> 表名小写
book_obj = models.AuthorDetail.objects.filter(author__book__pk=1).values('phone')
print(book_obj)
# <QuerySet [{'phone': 120}, {'phone': 110}, {'phone': 130}]>
'''当表特别多的时候,ORM语句其实并不好写,如果你真遇到这种不好写的语句的时候,就是要原生sql语句'''
聚合查询和分组查询
聚合查询(aggregate)
就是指聚合函数:sum min max avg count
| 名字 | 函数 |
|---|---|
| max | 最大值 |
| min | 最小值 |
| sum | 合计 |
| avg | 平均值 |
| count | 计数 |
# 在orm中如何使用聚合函数
1.关键字:aggregate
2.需要在django.db.models中导入
3.结果是个字典形式
实际应用:
# 求书籍表中得书的平均价格
from django.db.models import Max, Min, Avg, Sum, Count
# 单个使用
res = models.Book.objects.aggregate(Avg('price')) # {'price__avg': 380.0}
res = models.Book.objects.aggregate(Max('price')) # {'price__max': Decimal('658.00')}
res = models.Book.objects.aggregate(Min('price')) # {'price__min': Decimal('99.00')}
res = models.Book.objects.aggregate(Sum('price')) # {'price__sum': Decimal('1900.00')}
res = models.Book.objects.aggregate(Count('price')) # {'price__count': 5}
# 也可以一起使用
res = models.Book.objects.aggregate(Max('price'),Min('price'),Sum('price'),Avg('price'),Count('price'))
# {'price__max': Decimal('658.00'), 'price__min': Decimal('99.00'), 'price__sum': Decimal('1900.00'), 'price__avg': 380.0, 'price__count': 5}
print(res) # {'price__avg': 20248.2}
分组查询(annotate)
MySQL:
# group by分组
select * from book group by id
# 分组之后只能取得分组的依据,其他的字段不能拿到
# 需要设置一个严格模式:sql_mode='only...'
Django:
# 1.关键字:annotate
# 2.annotate就是对models后面的表进行分组
models.Book.objects.annotate() # 就是按照书来分组的
models.Book.objects.values('字段').annotate() # 按照Book表中的具体字段分组的
分组查询
from django.db.models import Count, Sum, Max, Min, Avg
1.统计每一本书的作者个数
# 书---->作者----->正向----->外键字段
# 聚合函数一般都是配合分组使用的
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title', 'author_num')
print(res)
2.统计每个出版社卖的最便宜的书的价格
# 1. 按照出版社分组
# 2. 聚合查询书的价格
# 3. 出版社查书 ------> 反向查询 -----> 表名小写
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res)
3.统计不止一个作者的图书
# 1. 统计每一本的作者个数
# 2. 在过滤出作者个数大于1的就可以了
# 书 ------> 作者 ------> 正向 ------> 外键字段
# models.Book.objects.annotate(Count('authors')) # 计数的参数是主键,可以不写__pk,但是建议写上
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('title', 'author_num')
# res只要返回的结果是queryset,就可以一直往下点 queryset提供的方法
print(res)
4.查询每个作者出的书的总价格
# 1. 按照作者分组
# 2. 作者查书
# 总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name', 'sum_price')
print(res)
F与Q查询
F查询
F查询够帮你直接获取到表中的某个字段对应的值,具体应用如下
from django.db.models import F
# 1.查询卖出数大于库存数的书籍
# select * from book where sale_num > kucun;
res = models.Book.objects.filter(sale_num__gt=F('kucun'))
print(res)
# 2.将所有书籍的价格提升500块
# update app01_book set price = price+500;
res = models.Book.objects.update(price=F('price')+500)
# 3.将所有书的名称后面加上爆款两个字
# update app01_book set title = title + 'haha' ;
# models.Book.objects.update(title=F('title')+'haha') # 不能这样写
# 1.先导入两个模块
# 2.原有字段包裹在F中
# 3.新的字符包裹在Value中
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'), Value('haha')))
Q查询
对于filter()方法内逗号分隔开的多个条件,都是and关系,如果想用or或者not关系,则需要使用Q
# 1.查询卖出数大于100或者价格小于600的书籍
# select * from book where sale_num > 100 or price < 600;
res = models.Book.objects.filter(sale_num__gt=100, price__lt=600) # and关系
res = models.Book.objects.filter(sale_num__gt=100).filter(price__lt=600) # and关系
# 导入Q
from django.db.models import Q
res = models.Book.objects.filter(Q(sale_num__gt=100), Q(price__lt=600)) # , 是and关系
res = models.Book.objects.filter(Q(sale_num__gt=100)|Q(price__lt=600)) # | 是or关系
res = models.Book.objects.filter(~Q(sale_num__gt=100)|Q(price__lt=600)) # ~ 是非的关系
print(res)
Q查询的高阶用法:能够以字符串作为查询字段
res = models.Book.objects.filter(Q(sale_num__gt=100) | Q(price__lt=600))
# 前端传给后端额的是字符串'price'
requests.GET.get('sort') # price
# res = models.Book.objects.filter(price__gt=100)
# res = models.Book.objects.filter('price'+'__gt'=100) 出错
q = Q()
q.connector = 'or' # 把多个查询条件改为OR关系了
q.children.append(('maichu__gt', 100))
q.children.append(('sale_num__lt',100))
# 不同条件之间使用,隔开 --- and关系
res = models.Book.objects.filter(q)
print(res)
想学习Q的更高级用法,自行百度
django开启事务
mysql中的事务,ACID特性。开启事务的步骤:
复习知识:事务
1、 开启事务
start transaction;
2、提交事务
commit;
3、回滚事务
rollback;
django中如何开启事务
from django.db import transaction
try:
with transaction.atomic():
# with内部写入SQL语句
# sql1
models.Book.objects.create()
# sql2
models.Publish.objects.update()
...
except Exception as e:
print(e) # 当sql语句出现异常的时候,可以在这里打印错误信息
transaction.rollback() # 回滚事务


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)