
进程
理论知识
什么是进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
进程与程序中的区别
程序:就是一堆代码,没有生命周期(还没有被运行起来)
进程:是动态,有生命周期。正在运行的程序(被运行起来了),
发明进程的目的:就是为了表达一些特定的状态
进程和线程
进程:做事的过程就是进程
线程:是实际做事的人
协程:单线程下的并发,比线程还要小,如果开协程,那么,消耗的资源更小。协程是由程序员调度的
1.进程与线程的关系:先开进程,在进程里面开线程
2.一个进程中可以有多个线程,一个进程中至少要有一个线程
3.进程和线程全部都是由操作系统来调度的
4.如果一个进程中只有一个线程,这个线程就叫主线程,子线程
进程的调度算法
要想多个进程交替运行,操作系统必须对这些进程进行调度,这个调度也不是随即进行的,而是需要遵循一定的法则,由此就有了进程的调度算法。
- 先来先服务调度算法
先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。FCFS算法比较有利于长作业(进程),而不利于短作业(进程)。 - 短作业优先调度算法
短作业(进程)优先调度算法(SJ/PF)是指对短作业或短进程优先调度的算法,该算法既可用于作业调度,也可用于进程调度。但其对长作业不利;不能保证紧迫性作业(进程)被及时处理;作业的长短只是被估算出来的。 - 时间片轮转法
时间片轮转(Round Robin,RR)法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。
将时间均分,然后根据进程时间长短再分多个等级。
4. 多级反馈队列
多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。
等级越靠下表示耗时越长,每次分到的时间越多,但是优先级越低
进程的并行与并发
并行:并行是指两者同时执行,比如赛跑,两个人都在不停的往前跑。是在同一时刻,执行多个任务。必须要有多个CPU参与,单个CPU无法实现并行。
并发:并发是指资源有限的情况下,两者交替轮流使用资源。是在一段时间内,执行多个任务。单个CPU可以实现 多个CPU肯定也可以。
同步异步阻塞非阻塞
状态介绍
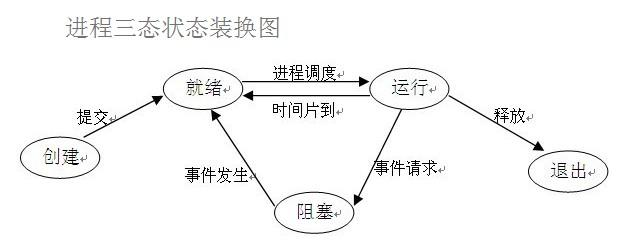
在了解其他概念之前,我们首先要了解进程的几个状态。在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。
(1)就绪(Ready)状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。

同步和异步
用来表达任务的提交方式
同步:提交完任务之后原地等待任务的返回结果 期间不做任何事#之前学习的都是同步
异步:提交完任务之后不愿地等待任务的返回结果,直接去做其他事,有结果自动通知
举个通俗的例子:
你打电话问书店老板有没有《分布式系统》这本书,
如果是同步通信机制,书店老板会说,你稍等,“我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
阻塞与非阻塞
用来表达任务的执行状态
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞:非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子:
你打电话问书店老板有没有《分布式系统》这本书,
你如果是阻塞式调用,你会一直把'自己'“挂起”,直到得到这本书有没有的结果,
如果是非阻塞式调用,你不管老板有没有告诉你,你'自己'先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
结合
- 同步阻塞 ---------------> 效率最低
- 同步非阻塞
- 异步阻塞
- 异步非阻塞----------------> 效率最高,使用率高
在python程序中的进程操作
multiprocess.process模块
process模块介绍
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
# 实例化对象的参数
def __init__(self, group=None, target=None, name=None, args=(), kwargs={},
*, daemon=None)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'jason',)
4 kwargs表示调用对象的字典,kwargs={'name':'jason','age':18}
5 name为子进程的名称
方法介绍:
1 p.start():启动进程,并调用该子进程中的p.run()
2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
3 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
4 p.is_alive():如果p仍然运行,返回True
5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
属性介绍
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
2 p.name:进程的名称
3 p.pid:进程的pid
4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
创建进程
创建进程的第一种方式
'''使用进程的场景:你想让某个函数反复执行(在同一个时间中执行多次)时'''
from multiprocessing import Process
import time
def task(name):
print('task is running')
time.sleep(3)
print('task is over',name)
"""
在不同的操作系统中创建进程底层原理不一样
windows
以导入模块的形式创建进程
避免代码反复执行,所以要使用__main__判断
linux/mac
以拷贝代码的形式创建进程
"""
# 在Windows系统中,开启进程必须写在__main__判断里面
if __name__ == '__main__':
# p1 = Process(target=task) # 实例化得出一个对象,并不会执行函数 # target=task不能加括号,加上括号把相当于函数的返回值当成参数了,None
p1 = Process(target=task, args=('jason',)) # 位置参数
# 调用一个方法来真正的开一个进程
p1.start() # 异步,告诉操作系统创建一个新的进程 并在该进程中执行task函数
# 执行了该步骤后,代码不等待结果,直接运行下面的代码
print('主')
# 输出结果是:
主
task is running
task is over
解析:
执行了py文件后,在内存中产生了一个内存地址,从上到下执行py文件中的代码,执行到p1.start()后,操作系统就会从上往下再次执行代码,并开辟一个新的内存空间,把刚刚导入模块形式的代码放进去,然后是让子进程调用了task()函数。而主进程是异步操作,会立刻执行下面的代码。子进程创建内存空间,拷贝代码需要时间,所以打印'主'一定会在子进程函数之前。
其中,主进程打印了'主',子进程调用了task()函数
创建进程的第二种方式
from multiprocessing import Process
import time
class MyProcess(Process): # 继承Process类,自己创建类
def __init__(self, name, age): # 传参数需要用__init__方法
super().__init__() # 一点要放在前面
self.name = name
self.age = age
def run(self): # 必须写run()方法
print('run is running')
time.sleep(3)
print('run is over', self.name, self.age)
if __name__ == '__main__':
obj = MyProcess('jason', 123) # 调用自己创建的类建立对象
obj.start()
print('主')
# > 输出结果是:
主
task is running
task is over jason 123
查看进程号pid
os模块 --- os是跟操作系统打交道的
p.pid --> 查看进程对象的子进程的进程号
os.getpid() --> 查看当前进程的进程号
os.getppid() --> 查看当前进程的父进程的进程号
from multiprocessing import Process
import os
def write_file(a):
print('a:', a)
# 在这里查看进程号,
print('(里面)子进程的进程号:', os.getpid()) # os.getpid() ----> 写在哪个进程中,就获取的是这个进程的pid
print('(里面)父进程的进程号:', os.getppid()) # parent
import time
time.sleep(20)
if __name__ == '__main__':
p = Process(target=write_file, name='ly', args=(1,)) # 实例化得出一个对象
p.start()
print('子进程的进程号:', p.pid)
print('主进程的进程号:', os.getpid())
# > 输出结果是:
子进程的进程号: 10032
主进程的进程号: 23364
a: 1
(里面)子进程的进程号: 10032
(里面)父进程的进程号: 23364
创建多进程
from multiprocessing import Process
def write_file():
print('start....')
if __name__ == '__main__':
for i in range(10): # 循环开启多进程
'''通知开进程,但是不一定能立马开起来,开进程肯定会消耗资源的'''
p = Process(target=write_file, name='ly', ) # 实例化得出一个对象
p.start()
print('end.......')
'''
此时,会先执行主进程中的代码,再执行子进程中的代码。
原因:通知开进程,但是不一定能立马开起来
'''
进程的join方法
def write_file():
print('start....')
import time
time.sleep(1)
import time
if __name__ == '__main__':
ctime = time.time()
for i in range(10):
'''通知开进程,但是不一定能立马开起来,开进程肯定会消耗资源的'''
p = Process(target=write_file, name='ly', ) # 实例化得出一个对象
p.start() # 异步
'''主进程代码等待子进程代码运行结束再执行'''
p.join() # 此时的程序变成了串行执行
# 需求:我就想让所有的子进程先执行完,最后在执行主进程代码,怎么做?
print('end.......')
print('一共用的时间:', time.time() - ctime) # 一共用的时间: 12.150434494018555
解析:
我们开多进程的目的是让多个进程可以同时进行,省时间,上述开了10个进程应该执行1秒多的时间
p.join()加上后程序变成了串行执行,第一个子程序执行结束之后才会开始执行第二个子程序
多个进程同时运行,再谈join方法
# 进程并发,但是先运行子进程
from multiprocessing import Process
def write_file():
print('start....')
import time
time.sleep(1)
import time
if __name__ == '__main__':
ctime = time.time()
ll = []
for i in range(10):
'''通知开进程,但是不一定能立马开起来,开进程肯定会消耗资源的'''
p = Process(target=write_file, name='ly', )
p.start()
ll.append(p) # 开完进程后将每一个程序放入列表中,此时的每个进程的运行不需要等待
'''先执行子进程,并且子进程并发运行'''
for j in ll:
j.join() # 让列表中的所有子程序都先执行完毕,主进程在执行
# 需求:我就想让所有的子进程先执行完,最后在执行主进程代码,怎么做?
print(ll)
print('end.......')
print('一共用的时间:', time.time() - ctime) # 一共用的时间: 1.7971177101135254
守护进程
守护进程会随着守护的进程结束而立刻结束
使用场景:一键关闭所有的进程,把子进程都设置成守护进程
from multiprocessing import Process
def write_file(a):
import time
time.sleep(1)
print('a:', a)
if __name__ == '__main__':
p = Process(target=write_file, name='ly', args=(1,)) # 实例化得出一个对象
'''守护进程的意思是:主进程代码执行完毕,子进程立马结束!!!'''
# 注意:p.daemon=True这一行代码必须要写在start()前面
p.daemon = True # 把p进程设置为守护进程
p.start()
print('end')
print('end')
# > 输出结果是:
end
end
僵尸进程与孤儿进程
僵尸进程
1.进程执行完毕后并不会立刻销毁所有的数据 会有一些信息短暂保留下来,时间很短(2~3秒)
2.比如进程号、进程执行时间、进程消耗功率等,给父进程查看
ps:所有的进程都会变成僵尸进程(一结束就会变成僵尸进程)
孤儿进程
1.子进程正常运行,父进程意外死亡。操作系统针对孤儿进程会派遣一个机制来管理(福利院管理)
基于TCP的高并发程序
想要一个服务端同时可以接收多个客户端,使用并发编程。但是方式不推荐工作中使用,每次运行一个客户端,就会同时开启一个服务端来服务这个客户端。会开启很多个服务端,会浪费很多资源。开多进程的目的就是提升效率。
服务端
import socket # python提供的socket模块
'''把接收客户端信息和发送信息的过程组织成一个任务'''
def task(conn):
while True:
try:
data = conn.recv(1024) # 括号里面写的是接收的字节数,最多接收1024个字节
if len(data) == 0:
continue
print(data) # 还是bytes类型
# 服务端开始给客户端也发送一个数据
conn.send(data.upper())
except Exception as e:
print(e)
break
conn.close()
from multiprocessing import Process
'''开启多个进程,每次都执行任务。本质上是来了一个客户就执行了一遍task()函数内部'''
if __name__ == '__main__':
# 1. 买手机
server = socket.socket() # 默认是TCP协议
# 2. 买手机卡
server.bind(('127.0.0.1', 8001)) # 服务端绑定一个地址
# 3. 开机
server.listen(1) # 监听,半连接池
print('服务端正在准备接收客户端消息:')
while True: # 使用循环开启多进程
'''要注意,while循环中如果只有建立循环对象和start()方法这两行代码,会成为一个死循环,一直在开启进程,会浪费大量资源,也会引起内存爆满!!!!!'''
conn, client_addr = server.accept() # 必须加上这行数据, # 接收, 程序启动之后,会在accept这里夯住,阻塞,就不会一直开进程了
p = Process(target=task, args=(conn,))
p.start()
客户端
'''客户端没有任何变化'''
import socket
# 先有一个手机
client = socket.socket()
# 直接进行链接服务端
client.connect(('127.0.0.1', 8001)) # 链接服务端
while True:
# 让用户输入要发送的数据
input_data = input('请输入你要发送的数据:')
# 向服务端主动发送数据
client.send(input_data.encode('utf-8')) # 发送的数据必须是二进制,bytes类型
# 接收服务端发送过来的数据
server_data = client.recv(1024) # 接收的最大字节数
print(server_data)
client.close()
锁:让进程同步
通过刚刚的学习,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO资源,但是也给我们带来了新的问题。
当多个进程使用同一份数据资源的时候,就会引发数据安全或顺序混乱问题。
进程锁
进程锁是我们目前学习的第一把锁,锁在IT界非常重要,用的也非常多,MySQL中用锁的地方很多。比如:行锁,表锁,乐观锁,悲观锁...
锁的目的:所有的锁都是为了安全!!!
执行步骤1:一次性开启多个进程的时候,这些进程谁先开起来,是不确定的,是有操作系统决定的
from multiprocessing import Process
def task(i):
print('第%s个进程进来了' % i)
print('第%s个进程走了' % i)
if __name__ == '__main__':
for i in range(4):
# 通知去开进程,但是谁先开起来,并不确定,对于操作系统来说,中间的间隔时间极短,能够确定的是,每个进程的进出一定是一对的
p = Process(target=task, args=(i,))
p.start()
# > 输出结果是:
第1个进程进来了
第1个进程走了
第2个进程进来了
第2个进程走了
第0个进程进来了
第0个进程走了
第3个进程进来了
第3个进程走了
执行步骤2:任务中间有阻塞的时候,CPU就会切换。类似于百米赛跑,开枪后不确定谁先跑出去
from multiprocessing import Process
import time
def task(i):
print('第%s个进程进来了' % i)
time.sleep(1)
print('第%s个进程走了' % i)
if __name__ == '__main__':
for i in range(4):
p = Process(target=task, args=(i,))
p.start()
# > 输出结果是:
第0个进程进来了
第1个进程进来了
第2个进程进来了
第3个进程进来了
第1个进程走了
第2个进程走了
第0个进程走了
第3个进程走了
推导步骤3:使用进程锁。无论开始先执行哪个任务,想要保证任务中的代码是打包在一起的,只有这个任务执行金结束之后才会执行下一个任务
# 进程锁
from multiprocessing import Process, Lock # 导入锁类
import time
def task(i, lock): # 保证了一个任务中的数据安全,不会串
# 进程锁
# 先上锁
lock.acquire()
print('第%s个进程进来了' % i)
time.sleep(1)
print('第%s个进程走了' % i)
# 释放锁,不释放锁,后面的程序就进不来
lock.release()
'''牺牲时间换空间,时间复杂度'''
if __name__ == '__main__':
lock = Lock() # 此时就拿到了一把锁
for i in range(5):
# 不需要每开一个进程就拿一把锁,所以把锁放在外面即可,不同的进程都可以使用这把锁
p = Process(target=task, args=(i, lock)) # 把锁传入任务中
p.start()
# > 输出结果是:
第1个进程进来了
第1个进程走了
第0个进程进来了
第0个进程走了
第3个进程进来了
第3个进程走了
第2个进程进来了
第2个进程走了
第4个进程进来了
第4个进程走了
实例:模拟抢票
我们以模拟抢票为例,来看看数据安全的重要性。
多进程数据错乱问题
data.json文件中数据:{'ticket_num': 1}票数只有一张。
from multiprocessing import Process
import time
import json
import random
# 查票
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s在查票 当前余票为:%s' % (name, data.get('ticket_num')))
# 买票
def buy(name):
# 再次确认票
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 判断是否有票 有就买
if data.get('ticket_num') > 0:
data['ticket_num'] -= 1
with open(r'data.json', 'w', encoding='utf8') as f:
json.dump(data, f)
print('%s买票成功' % name)
else:
print('%s很倒霉 没有抢到票' % name)
def run(name):
search(name)
buy(name)
if __name__ == '__main__':
for i in range(10):
p = Process(target=run, args=('用户%s'%i, ))
p.start()
"""
多进程操作数据很可能会造成数据错乱>>>:进程锁
进程锁
将并发变成串行 牺牲了效率但是保障了数据的安全
"""
加进程锁
建议只加载操作数据的部分 否则整个程序的效率会极低
data.json文件中数据:
{'ticket_num': 1}
票数只有一张。
from multiprocessing import Process, Lock
import time
import json
import random
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s查看票 目前剩余:%s' % (name, data.get('ticket_num')))
def buy(name):
# 先查询票数
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 买票
if data.get('ticket_num') > 0:
with open(r'data.json', 'w', encoding='utf8') as f:
data['ticket_num'] -= 1
json.dump(data, f)
print('%s 买票成功' % name)
else:
print('%s 买票失败 非常可怜 没车回去了!!!' % name)
def run(name, mutex):
search(name) # 可以一起看,只要买的时候加个锁就行
mutex.acquire() # 抢锁
buy(name)
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock() # 产生一把锁
for i in range(10):
p = Process(target=run, args=('用户%s号' % i, mutex))
p.start()
进程间通信
IPC(Inter-Process Communication)
进程之间数据隔离问题
'''进程之间的数据是相互隔离的,不能互相使用'''
n = 100
def task():
global n
n = 200
print('子进程的task函数查看n', n)
from multiprocessing import Process
if __name__ == '__main__':
p = Process(target=task)
p.start() # 创建子进程
p.join()
print('主进程中得n:', n) # 主进程代码打印n
# > 输出结果是:
子进程的task函数查看n 200
主进程中得n: 100
上述是有两个进程,子进程中的任务是想要更改主进程中的n的值,但是并没有更改成功。说明了进程之间的数据是相互隔离的
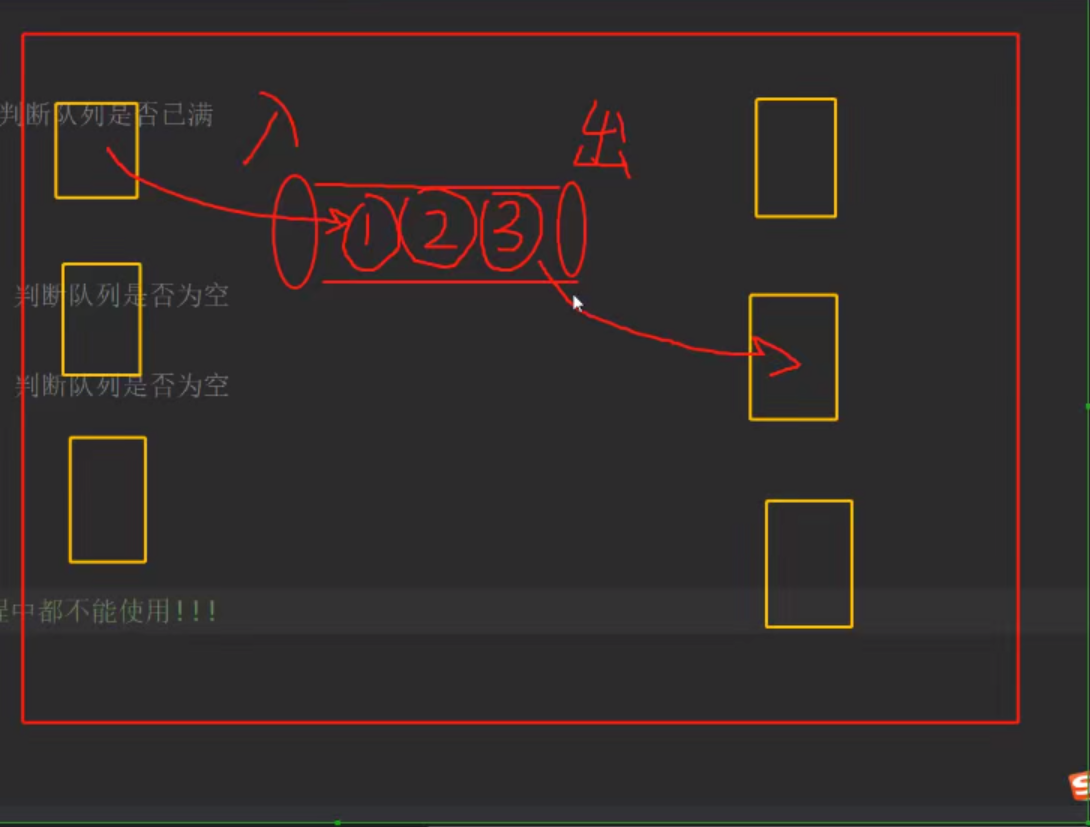
队列
数据结构是存储数据的形式
数据结构有:队列,链表,单链表,双链表,循环链表,栈,树:二叉树,平衡树,红黑树,b树,b+树,b-树,图
创建队列:1. 先创建队列,2. 入队,3. 出队
from multiprocessing import Queue
if __name__ == '__main__':
# 1. 创建队列,大小为3的队列
# 参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。
q = Queue(3) # 括号里面的数字代表的是队列的大小
# 2. 入队
q.put('helloworld1')
q.put('helloworld2')
q.put('helloworld3')
# 3. 出队
res = q.get() # helloworld, get一次得到一个结果
res1 = q.get()
res2 = q.get()
print(res, res1, res2) # helloworld1 helloworld2 helloworld3
队列大小为3,如果队列已满,此方法将阻塞至有空间可用为止。下面的代码就不会运行
put方法的参数: put(self, obj, block=True, timeout=None)
1.block=True
if __name__ == '__main__':
q = Queue(3) # 括号里面的数字代表的是队列的大小
# 2. 入队
q.put('helloworld1')
q.put('helloworld2')
q.put('helloworld3')
# block:当队列满的时候,
# block=False,如果有数据在继续入队,就会直接报错
# block=True(默认),会一直等待
q.put('helloworld4', block=False) # 直接报错 # queue.Full
2.timeout=None
if __name__ == '__main__':
q = Queue(3) # 括号里面的数字代表的是队列的大小
# 2. 入队
q.put('helloworld1')
q.put('helloworld2')
q.put('helloworld3')
# timeout:超时,超过给定的时间,如果再放不进去,就直接报错
# 不能和block一起使用
q.put('helloworld4', timeout=3) # 等待3秒后报错 # queue.Full
3.q.put_nowait()方法
有位置则将字符加入队列,队列满了后再加直接报错。
if __name__ == '__main__':
q = Queue(3) # 括号里面的数字代表的是队列的大小
# 2. 入队
q.put('helloworld1')
q.put('helloworld2')
q.put('helloworld3')
q.put_nowait('helloworld4') # 相当于block参数
4.出队时也是一样的
q.get(block=False),已经全部取出完,再取会立刻报错
q.get(timeout=3),已经全部取出完,再取等待3秒后报错
5.q.qsize():返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发
6.q.full():如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的
7.q.empty(): 判断队列是否为空,队列空返回True.由于线程的存在,结果也可能是不可靠的
进程之间的数据共享
进程间通信(IPC:Inter-Process Communication)
所以两个进程之间想要通信,就可以在一个进程中把数据写入队列中,然后在另一个进程中使用队列读取这个数据,就可以通信了。两个进程之间通过中间管道:队列,来通信。
消息队列:存储数据的地方,所有人都可以存,也都可以取,相当于公共的仓库
此时, Queue队列中得数据是在内存中存着的
在实际工作中,队列我们会使用专业的消息队列:RabbitMq,Kafka,Rocket Mq...(这些有自己的存储机制,会把数据单独存起来,比如数据库)
Redis数据库(用在缓存)------>作为队列使用
队列(单台计算机上的消息队列)
from multiprocessing import Process,Queue
def task(q):
# 在子进程中往队列里面写入数据
q.put('hello')
if __name__ == '__main__':
# 1. 创建队列
q = Queue(10)
p = Process(target=task, args=(q, )) # 往子进程中传入队列对象
p.start()
'''在子进程中写入数据,去主进程中读取子进程中写的数据,如果能读到,说明通信了,如果读不到就不能通信'''
# 主进程中从队列中读取数据
print('主进程中读数据:', q.get()) # 主进程中读数据: hello # 可以读取信息
使用1:主进程和子进程交流
from multiprocessing import Process, Queue
def consumer(q):
print('子进程获取队列中的数据', q.get())
if __name__ == '__main__':
q = Queue()
# 主进程往队列中添加数据
q.put('我是主进程添加的数据')
p1 = Process(target=consumer, args=(q,))
p1.start()
p1.join()
print('主')
# > 输出结果是:
子进程获取队列中的数据 我是主进程添加的数据
主
使用2:两个子进程之间交流
from multiprocessing import Process, Queue
def product(q):
q.put('p2子进程添加的数据')
def consumer(q):
print('子进程p1获取队列中的数据', q.get())
if __name__ == '__main__':
q = Queue()
# p2子进程放,p1子进程获取
p1 = Process(target=consumer, args=(q,))
p2 = Process(target=product, args=(q,))
p1.start()
p2.start()
print('主')
# > 输出结果是:
主
子进程p1获取队列中的数据 p2子进程添加的数据
分析:
主进程开启了内存空间,p1.start()开启了p1子进程的内存空间,p2.start()开启了p2子进程的内存空间,操作系统运行这两个子进程的时候,没有前后顺序,
如果先运行了p1子进程,执行consumer函数,获取队列中的数据,此时队列中没有数据,就会阻塞,CPU就去执行其他程序。运行p2子进程,执行product函数,往队列中放数据,进程执行完毕。CPU切换,又去执行p1子进程上一次保存的情况,此时队列中有了数据,取出数据。输出结果。
如果先运行了p2子进程,就是正常执行了。
生产者消费者模型
- 生产者:负责产生数据的'人'。eg:主要用在爬虫红牛数据,requist.get()这句话就是生产者
- 消费者:负责处理数据的'人'。eg:正则
生产者和消费者模式解决大多数的并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。该容器可以使用队列或者消息队列(消息队列:只要是能够提供数据保存服务和提取服务的理论上都可以,eg:文件、数据库(下周学习))
基于队列实现生产者消费者模型
# 1. 生产者
def producer(q):
# 生产10个包子
for i in range(10):
q.put('生产的第%s个包子' % i) # 放入队列中
# print('第%s个包子' % i)
# 2. 消费者
def consumer(q):
while True:
print('取出了%s' %q.get())
from multiprocessing import Process, Queue
if __name__ == '__main__':
q = Queue(20)
p = Process(target=producer, args=(q,)) # 生产者进程
p.start()
p1 = Process(target=consumer, args=(q,)) # 消费者进程
p1.start()
'''
执行进程有先后是因为:如果先执行了消费者进程,就会产生阻塞,CPU就切换了,执行其他进程,执行了生产者进程,去生产包子
打印出来的有顺序是因为:队列的顺序,队列是先进先出的
最后程序没有结束的原因是:把队列中的数据取完后,程序一直等待,阻塞在这里,怎么解决呢?
'''
# > 输出结果是:
取出了生产的第0个包子
取出了生产的第1个包子
取出了生产的第2个包子
取出了生产的第3个包子
取出了生产的第4个包子
取出了生产的第5个包子
取出了生产的第6个包子
取出了生产的第7个包子
取出了生产的第8个包子
取出了生产的第9个包子
解决方法一:队列末尾添加一个标志位
把队列中的数据取完之后,程序可以结束,在队列末尾添加一个标志位,只要取到了这个标志位,就结束程序
# 1. 生产者
def producer(q):
# 生产10个包子
for i in range(10):
q.put('生产的第%s个包子' % i) # 放入队列中
# 添加一个标志位,放在最后面
q.put(None) # 内部什么元素都可以
# 2. 消费者
def consumer(q):
while True:
res = q.get()
print('取出了%s' % res)
# 只要取到了None,就表示取到队列最后了,没有其他数据了,直接退出
if res is None:
break
from multiprocessing import Process, Queue
if __name__ == '__main__':
q = Queue(20)
p = Process(target=producer, args=(q,))
p.start()
p1 = Process(target=consumer, args=(q,))
p1.start()
# > 输出结果是:
取出了生产的第0个包子
取出了生产的第1个包子
取出了生产的第2个包子
取出了生产的第3个包子
取出了生产的第4个包子
取出了生产的第5个包子
取出了生产的第6个包子
取出了生产的第7个包子
取出了生产的第8个包子
取出了生产的第9个包子
取出了None
解决方法二:把标志位放入主进程中
把标志位放入主进程中,这样就必须先把子进程结束,才能执行主进程
# 1. 生产者
def producer(q):
# 生产10个包子
for i in range(10):
q.put('生产的第%s个包子' % i) # 放入队列中
# 2. 消费者
def consumer(q):
while True:
res = q.get()
print('取出了%s' % res)
if res is None:
break
from multiprocessing import Process, Queue
if __name__ == '__main__':
q = Queue(20)
p = Process(target=producer, args=(q,))
p.start()
p1 = Process(target=consumer, args=(q,))
p1.start()
p.join() # 先进行子进程p(先把生产的都放入队列中),就可以执行主进程了,最后再执行子进程p1(这个不需要代码操控)
q.put(None) # 其实就是个标志位
# > 输出结果是:
取出了生产的第0个包子
取出了生产的第1个包子
取出了生产的第2个包子
取出了生产的第3个包子
取出了生产的第4个包子
取出了生产的第5个包子
取出了生产的第6个包子
取出了生产的第7个包子
取出了生产的第8个包子
取出了生产的第9个包子
取出了None
多生产者,少消费者
# 1. 生产者
def producer(q, food, name):
# 生产10个包子
for i in range(5):
q.put('%s生产了第%s个%s' % (name, i, food)) # 放入队列中
# 2. 消费者
def consumer(q, name):
while True:
res = q.get()
print('%s取出了%s' % (name, res))
if res is None:
break
from multiprocessing import Process, Queue
if __name__ == '__main__':
q = Queue(100)
p1 = Process(target=producer, args=(q, '馒头', 'ly')) # 4个生产者
p2 = Process(target=producer, args=(q, '咖啡', 'kevin'))
p3 = Process(target=producer, args=(q, '烧麦', 'tony'))
p4 = Process(target=producer, args=(q, '奶茶', 'tank'))
p1.start()
p2.start()
p3.start()
p4.start()
pp1 = Process(target=consumer, args=(q, '消费者1')) # 2个消费者
pp2 = Process(target=consumer, args=(q, '消费者2'))
pp1.start()
pp2.start()
p1.join() # 先执行生产者进程
p2.join()
p3.join()
p4.join()
q.put(None) # 其实就是个标志位
q.put(None) # 几个消费者就使用几个标志位,也可以超过消费者个数
# > 输出结果是:
消费者2取出了kevin生产了第0个咖啡
消费者2取出了kevin生产了第1个咖啡
消费者2取出了kevin生产了第2个咖啡
消费者2取出了kevin生产了第3个咖啡
消费者2取出了kevin生产了第4个咖啡
消费者2取出了tony生产了第0个烧麦
消费者2取出了ly生产了第0个馒头
消费者2取出了ly生产了第1个馒头
消费者2取出了tony生产了第1个烧麦
消费者2取出了tony生产了第2个烧麦
消费者2取出了tony生产了第3个烧麦
消费者2取出了tony生产了第4个烧麦
消费者2取出了ly生产了第2个馒头
消费者2取出了ly生产了第3个馒头
消费者2取出了ly生产了第4个馒头
消费者2取出了tank生产了第0个奶茶
消费者1取出了tank生产了第1个奶茶
消费者2取出了tank生产了第2个奶茶
消费者1取出了tank生产了第3个奶茶
消费者2取出了tank生产了第4个奶茶
消费者1取出了None
消费者2取出了None
多生产者,少消费者
# 1. 生产者
def producer(q, food, name):
# 生产10个包子
for i in range(10):
q.put('%s生产了第%s个%s' % (name, i, food)) # 放入队列中
# 2. 消费者
def consumer(q, name):
while True:
res = q.get()
print('%s取出了%s' % (name, res))
if res is None:
break
from multiprocessing import Process, Queue
if __name__ == '__main__':
q = Queue(100)
p1 = Process(target=producer, args=(q, '馒头', 'ly')) # 2个生产者
p2 = Process(target=producer, args=(q, '咖啡', 'kevin'))
p1.start()
p2.start()
pp1 = Process(target=consumer, args=(q, '消费者1')) # 5个消费者
pp2 = Process(target=consumer, args=(q, '消费者2'))
pp3 = Process(target=consumer, args=(q, '消费者3'))
pp4 = Process(target=consumer, args=(q, '消费者4'))
pp5 = Process(target=consumer, args=(q, '消费者5'))
pp1.start()
pp2.start()
pp3.start()
pp4.start()
pp5.start()
p1.join() # 先执行生产者进程
p2.join()
q.put(None) # 其实就是个标志位
q.put(None) # 几个消费者就使用几个标志位,也可以超过消费者个数
q.put(None)
q.put(None)
q.put(None)
# > 输出结果是:
消费者2取出了ly生产了第0个馒头
消费者5取出了ly生产了第1个馒头
消费者1取出了ly生产了第2个馒头
消费者4取出了ly生产了第3个馒头
消费者2取出了ly生产了第4个馒头
消费者5取出了ly生产了第5个馒头
消费者1取出了ly生产了第6个馒头
消费者4取出了ly生产了第7个馒头
消费者2取出了ly生产了第8个馒头
消费者5取出了ly生产了第9个馒头
消费者1取出了kevin生产了第0个咖啡
消费者4取出了kevin生产了第1个咖啡
消费者2取出了kevin生产了第2个咖啡
消费者5取出了kevin生产了第3个咖啡
消费者1取出了kevin生产了第4个咖啡
消费者4取出了kevin生产了第5个咖啡
消费者2取出了kevin生产了第6个咖啡
消费者1取出了kevin生产了第8个咖啡
消费者4取出了kevin生产了第9个咖啡
消费者5取出了kevin生产了第7个咖啡
消费者2取出了None
消费者1取出了None
消费者4取出了None
消费者5取出了None
消费者3取出了None
