
网络编程2
五.socket套接字编程
如果我们需要编写基于网络进行数据交互的程序,意味着我们需要自己通过代码来控制我们之前所学习的OSI七层(很繁琐、很复杂,类似于我们自己编写操作系统)
什么是Socket呢?我们经常把Socket翻译为套接字,Socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。
socket抽象层类似于操作系统:封装了丑陋复杂的接口提供简单快捷的接口。以后直接通过Socket去跟下面的层打交道,Socket模块
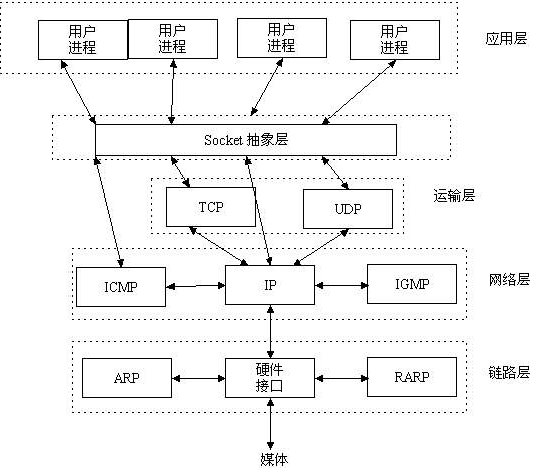
套接字家族
- 基于文件类型的套接字家族(单机、只能在同一台机子上使用)
AF_UNIX:用在局域网中 - 基于网络类型的套接字家族(联网)
AF_INET****:用在互联网
套接字工作流程
一个生活中的场景。你要打电话给一个朋友,先拨号,朋友听到电话铃声后提起电话,这时你和你的朋友就建立起了连接,就可以讲话了。等交流结束,挂断电话结束此次交谈。 生活中的场景就解释了这工作原理。
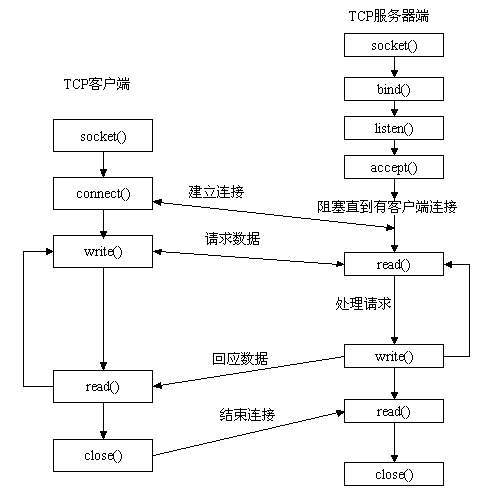
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
socket模块基本使用
socket.socket() 产生socket对象
bind() -------------- 绑定地址
listen() -------------- 半连接池
accept() -------------- 等待客户端链接
send() -------------- 发送消息
recv() -------------- 接收消息
connect() -------------- 链接服务端
基于TCP协议的套接字编程
案例:
服务端
"""
以后要养成查看源码编写代码的思路
"""
import socket # python提供的socket模块
# 1. 买手机
# SOCK_STREAM ====> 代表的是TCP协议
# socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # udp协议
# 参数:family=AF_INET, type=SOCK_STREAM, proto=0, fileno=None
# 默认是TCP协议
server = socket.socket() # socket模块.socket类,,类加括号产生一个对象,这个类可以不传参
# 2. 买手机卡
# '0.0.0.0' =====> 代表允许任何的ip链接,万能地址
# server.bind(('0.0.0.0', 8000)) # 服务端绑定一个地址
server.bind(('127.0.0.1', 8000)) # 服务端绑定一个地址(ip+port)
# 3. 开机
server.listen(5) # 监听,半连接池 # 表示同时监听的客户端的数量
print('123') # 用于检测代码停住位置
# 4. 等着接电话
# accept()有两个返回值:sock, addr
conn, client_addr = server.accept() # 接收, 程序启动之后,会在accept这里夯住,阻塞
print('456') # 用于检测代码停住位置
'''
conn:代表的是当次连接对象
client_addr:代表的是客户端的详细信息(ip:port)
'''
# 接收客户端发送过来的数据
# 隐藏了一个bug,粘包现象,有可能发送过来的数据是1025个字节,一次性接收不完
data = conn.recv(1024) # 括号里面写的是接收的字节数,最多接收1024个字节
print(data) # 还是bytes类型
# > 输出结果是:b'hello'
'''客户端给服务端发送了一个数据,服务端接收到了'''
# 2.
# 服务端开始给客户端也发送一个数据
conn.send(data.upper()) # 转成大写
conn.close() # 断开链接,客户端对象
server.close() # 关掉手机
客户端
import socket
'''客户端,不需要绑定地址监听,直接链接服务端'''
# 先有一个手机
client = socket.socket()
# 直接进行链接服务端
client.connect(('127.0.0.1', 8000)) # 链接服务端,传元组参数,服务端写的什么地址与端口,服务端就写什么地址与端口
# 向服务端主动发送数据
client.send('hello'.encode('utf-8')) # 发送的数据必须是二进制,bytes类型
'''通过网络传输的数据都是二进制'''
# 2.
# 接收服务端发送过来的数据
server_data = client.recv(1024) # 接收的最大字节数
print(server_data)
# > 输出结果是:b'HELLO'
client.close() # 程序结束,断开链接
代码优化:循环
-
聊天内容自定义
针对消息采用input获取 -
让聊天循环起来
将聊天的部分用循环包起来 -
用户输入的消息不能为空
客户端发了空消息,会走到下一步(client.reve(1024))
但是服务端没有收到任何消息,仍然还是(sock.recv(1024))
本质其实是两边不能都是recv或者send,一定是一方收一方发,是有先后顺序的。增加if判断空消息 -
服务端多次重启可能会报错
Address already in use 主要是mac电脑会报(苹果电脑)
方式1:改端口号,端口号被占用了
方式2:博客里面代码拷贝即可 -
当客户端异常断开的情况下,如何让服务端继续服务其他客人
windows服务端会直接报错()
mac服务端会有一段时间反复接收空消息延迟报错(BrokenPipeError)
异常处理、空消息判断 -
一个服务端一次性只能够服务一个客户端,只有这个客户端断开链接,服务端才会开始服务下一个客户端
服务端
```python
import socket # python提供的socket模块
# 1.产生一个socket对象(服务端对象)并指定采用的通信版本和协议(TCP)
server = socket.socket()
# 2.绑定一个固定的地址(服务端必备的条件)
server.bind(('127.0.0.1', 8000))
# 3.设立半连接池(暂且忽略),预防洪水攻击
server.listen(5) # 半连接池
print('服务端正在准备接收客户端消息:') # 提示语
# 一个服务端可以有多个客户端,服务端不能断线
while True: # 4.加上链接循环 # 可以接收多个客户端
# 5.等待客人连接
conn, client_addr = server.accept()
print(conn, client_addr) # 接收, 程序启动之后,会在accept这里夯住,阻塞
# conn:代表的是当次连接对象,client_addr:代表的是客户端的详细信息(ip:port)'''
# 与当前客户可以一直通信
while True: # 6.通讯循环
'''7.一个客户端出了问题会直接导致服务端发生错误,加异常处理'''
try:
# 8.服务客人,接收客人发过来的消息
data = conn.recv(1024)
# 9.用户输入信息为空,继续接收让客户下一次消息
if len(data) == 0:
continue
print(data.decode('utf-8'))
# 10.给客户端也发送一个数据
server_data = input('请输入往客户端发送的消息:>>>').strip()
conn.send(server_data.encode())
except Exception as e:
print(e)
break # 发生错误直接断开程序
# 11.关闭双向通道
conn.close() # 与当前客户端断开
# 12.关闭服务端
server.close()
'''一个服务端只能服务一个客户端,想要一个服务端服务多个客户端,要用多进程(高并发)'''
客户端
import socket
# 1.生成socket对象(客户端对象)指定类型和协议
client = socket.socket()
# 2.通过服务端的地址链接服务端
client.connect(('127.0.0.1', 8000)) # 链接服务端
# 客户端与服务端不间断的通信
while True: # 3.通信循环
# 4.让用户输入要发送的消息
input_data = input('请输入你要发送的数据:')
# 5.直接给服务端发送消息
client.send(input_data.encode('utf-8'))
# 6.接收服务端发送过来的消息
server_data = client.recv(1024) # 二进制格式
print(server_data.decode('utf-8')) # 解码
# 7.断开与服务端的链接
client.close()

基于UDP协议的套接字编程
- UDP服务端和客户端'各自玩各自的'
- UDP不会出现多个消息发送合并(粘包问题)
服务端
import socket
# 数据报协议---> UDP
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # SOCK_STREAM是TCP协议
server.bind(('127.0.0.1', 8080))
# 不需要建立半链接池
while True:
data, client_addr = server.recvfrom(1024) # accept()
# data接收回来的数据
# client_addr:客户端的信息
print('===>', data.decode('utf-8'), client_addr)
server.sendto(data.upper(), client_addr)
# server.sendto(data.upper(), ('127.0.0.1',8080))
server.close()
客户端
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 数据报协议->UDP
while True:
msg = input('>>: ').strip() # msg=''
# 不需要单独链接服务端,直接发送消息时第二个参数写上服务端地址,元组形式
client.sendto(msg.encode('utf-8'), ('127.0.0.1', 8080)) # send()
# 接收服务端的消息
data, server_addr = client.recvfrom(1024) # recv(1024)
print(data.decode('utff-8'))
client.close()
粘包现象
data = conn.recv(1024) # 1024代表的是一次性接收的最大字节数
# 粘包现象:如果客户端发送的数据超过了1024字节,那么,服务端一次性不能接收完整,导致客户端发送的数据丢失
同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种显现就是黏包。
粘包现象代码
服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
sock, addr = server.accept()
data1 = sock.recv(1024)
print(data1)
data2 = sock.recv(1024)
print(data2)
data3 = sock.recv(1024)
print(data3)
sock.close()
server.close()
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8081))
client.send(b'hello')
client.send(b'jason')
client.send(b'jerry')
# > 输出结果是:
b'hellojasonjerry'
b''
b''
黏包现象产生的原因
- 不知道每次的数据到底多大
- TCP也称为流式协议:数据像水流一样绵绵不绝没有间隔(TCP会针对数据量较小且发送间隔较短的多条数据一次性合并打包发送)
服务端接收数据的字节数参数改成5后就可以分开接收了
data1 = sock.recv(5)
print(data1)
data2 = sock.recv(5)
print(data2)
data3 = sock.recv(5)
print(data3)
# > 输出结果是:
b'hello'
b'jason'
b'jerry'
避免黏包现象的核心思路\关键点
- 如何明确即将接收的数据具体有多大
- 如何将长度变化的数据全部制作成固定长度的数据
解决思路
- 客户端知道自己发送数据有多大,但是服务端不知道,所以想要服务端知道客户端发送过来的数据是多少字节,然后分批次接收就可以了
- 如何让服务端知道发送过来的数据大小
客户端把数据通过pack()函数进行打包得到4个字节的数据,把4个字节的数据一起发送过去,并且放到发送数据的开头;服务端接收时,先切片,切出4个字节的数据,使用unpack()函数解包,得到的结果就是数据的具体大小,使用得到的结果去除以自己一次能够接收的数据大小,得到需要几次来接收(for i in range(次数))。
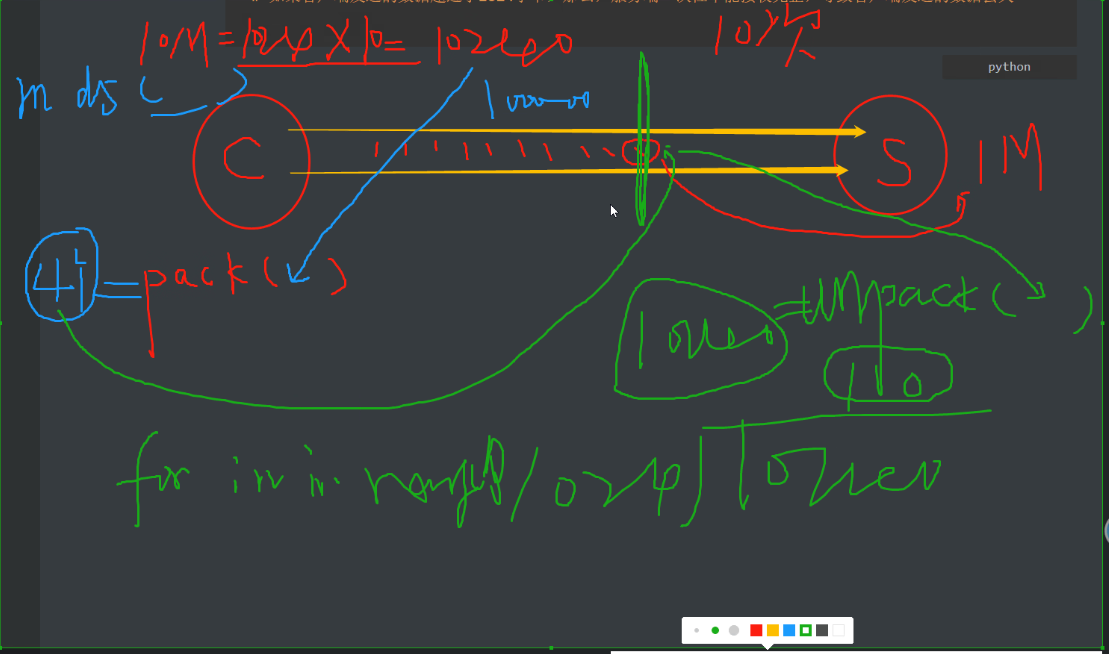
补充struct模块
解决黏包问题初次版本
import struct # 内置模块
# 该模块的作用是:把一些不是固定长度的数据变成固定长度
# 打包成固定长度
info = b'hello big baby'
print(len(info)) # 数据真实的长度(bytes) 14
res = struct.pack('i', len(info)) # 将数据打包成固定的长度 i是固定的打包模式,结果是字节类型
print(len(res)) # 打包之后长度为(bytes) 4 报头
# 解析成真实数据长度
real_len = struct.unpack('i', res)
print(real_len) # (14,) 根据固定长度的报头 解析出真实数据的长度
# 打包成固定长度
desc = b'hello my baby I will take you to play big ball'
print(len(desc)) # 数据真实的长度(bytes) 46
res1 = struct.pack('i', len(desc))
print(len(res1)) # 打包之后长度为(bytes) 4 报头
# 解析成真实数据长度
real_len1 = struct.unpack('i', res1)
print(real_len1) # (46,) 根据固定长度的报头 解析出真实数据的长度
但是也存在很多问题
'''问题1:struct模块无法打包数据量较大的数据,就算换更大的模式也不行'''
res = struct.pack('i', 12313213123)
print(res)
'''问题2:报头能否传递更多的信息,比如电影大小 电影名称 电影评价 电影简介'''
终极解决方案
字典作为报头打包 效果更好 数字更小
data_dict = {
'file_name': 'xxx老师教学.avi',
'file_size': 123132131232342342423423423423432423432,
'file_info': '内容很精彩 千万不要错过',
'file_desc': '一代神作 私人珍藏'
}
import json
data_json = json.dumps(data_dict) # 把字典转成bytes类型(序列化)
print(len(data_json.encode('utf8'))) # 真实字典的长度 252
res = struct.pack('i', len(data_json.encode('utf8')))
print(len(res)) # 4
解决黏包代码实战
思路:
客户端
1. 制作一个真实数据相关的字典
2. 将字典序列化并编码统计长度
3. 利用struct模块对上述长度做打包处理
4. 直接发送打包之后的数据
5. 再发送字典数据
6. 最后发送真实数据
服务端
1. 接收固定长度的报头
2. 利用struct模块反向解析出字典数据的长度
3. 接收字典数据并处理成字典
4. 根据字典中的信息接收真实数据
服务端
import socket
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
sock, addr = server.accept()
# 1.接收固定长度的字典报头
data_dict_head = sock.recv(4) # 先拿4个字节数。固定长度的
# 2.根据报头解析出字典数据的长度
data_dict_len = struct.unpack('i', data_dict_head)[0] # 元组取索引0,(46,)
# 3.接收字典数据
data_dict_bytes = sock.recv(data_dict_len) # 二进制
data_dict = json.loads(data_dict_bytes) # 自动解码再反序列化
# print(data_dict) # 字典报头数据
# 4.获取真实数据的各项信息----一次性全部接收
# total_size = data_dict.get('file_size')
# with open(data_dict.get('file_name'), 'wb') as f:
# f.write(sock.recv(total_size))
'''接收真实数据的时候,如果数据量非常大,recv括号内直接填写该数据量,不太合适,我们可以每次接收一点点,反正知道总长度'''
# 4.获取真实数据的各项信息-----每次接收一点点
total_size = data_dict.get('file_size')
recv_size = 0
with open(data_dict.get('file_name'), 'wb') as f:
while recv_size < total_size:
data = sock.recv(1024) # 一次性收1024字节的数据
f.write(data)
recv_size += len(data)
print(recv_size)
# 上面的判断条件也可以更改,改的更加细致一点,最后一次可能只剩下几个字节的数据,这样直接recv(几)就可以,不会接收到下个数据
# 或者收完一次数据后让程序睡几秒,与下一次的接收分隔开
客户端
import socket
import os
import struct
import json # 序列化
client = socket.socket()
client.connect(('127.0.0.1', 8081))
'''任何文件都是下列思路:图片、视频、文本 ...'''
# 1.获取真实数据大小
file_size = os.path.getsize(r'/Users/jiboyuan/PycharmProjects/day36/xx老师合集.txt') # 拷贝绝对路径 # os.path.getsize(path) 返回path的大小,字节数
# 2.制作真实数据的字典数据
data_dict = {
'file_name': '有你好看.txt',
'file_size': file_size,
'file_desc': '内容很长 准备好吃喝 我觉得营养快线挺好喝',
'file_info': '这是我的私人珍藏'
}
# 3.制作字典报头
data_dict_bytes = json.dumps(data_dict).encode('utf8') # 先序列化转成字符串,再转二进制
data_dict_len = struct.pack('i', len(data_dict_bytes)) # 打包成固定长度
# 4.发送字典报头
client.send(data_dict_len) # 报头数字本身也是bytes类型 我们在看的时候用len长度是4
# 5.先发送字典报头
client.send(data_dict_bytes)
# 6.最后发送真实数据
with open(r'/Users/jiboyuan/PycharmProjects/day36/xx老师合集.txt', 'rb') as f:
for line in f: # 一行行发送,和直接一起发效果一样 因为TCP流式协议的特性
client.send(line)
import time
time.sleep(10)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义