
继承与派生
继承
继承是一种创建新类的方式,在Python中,新建的类可以继承一个或多个父类,新建的类可称为子类或派生类,父类又可称为基类或超类
在编程世界中继承表示类与类之间资源的从属关系。子类可以继承父类的所有属性和方法。
class Parent1: # <==> Parent1(object)
pass
class Parent2:
pass
# 单继承:一个子类只能继承一个父类
class Sub1(Parent1):
pass
'''python中,支持多继承'''
class Sub2(Parent1, Parent2):
pass
通过类的内置属性__bases__可以查看类继承的所有父类
print(Sub1.__bases__) # (<class '__main__.Parent1'>,)
print(Sub2.__bases__) # (<class '__main__.Parent1'>, <class '__main__.Parent2'>)
print(Parent1.__bases__) # (<class 'object'>,)
在Python2中有经典类与新式类之分,没有显式地继承object类的类,以及该类的子类,都是经典类,显式地继承object的类,以及该类的子类,都是新式类。而在Python3中,即使没有显式地继承object,也会默认继承该类,如下
print(Parent1.__bases__)
# > (<class 'object'>,)
因而在Python3中统一都是新式类,关于经典类与新式类的区别,我们稍后讨论
提示:object类提供了一些常用内置方法的实现,如用来在打印对象时返回字符串的内置方法__str__
以后我们在定义类的时候 如果没有其他明确的父类 也可能习惯写object兼容(为了兼容python2)
class Student(object):
pass
继承与抽象
要找出类与类之间的继承关系,需要先抽象,再继承。抽象即总结相似之处,总结对象之间的相似之处得到类,总结类与类之间的相似之处就可以得到父类,如下图所示
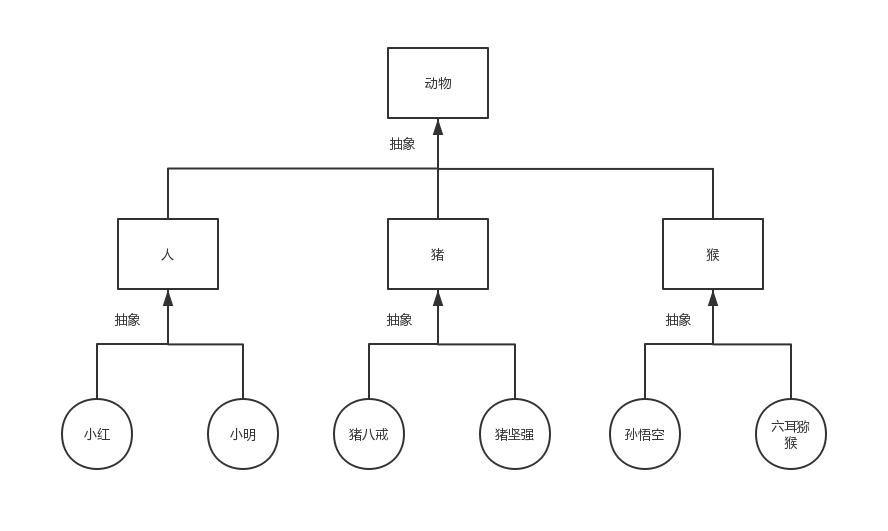
基于抽象的结果,我们就找到了继承关系

基于上图我们可以看出类与类之间的继承指的是什么‘是’什么的关系(比如人类,猪类,猴类都是动物类)。子类可以继承/遗传父类所有的属性,因而继承可以用来解决类与类之间的代码重用性问题。比如我们定义以下两个类:
class Student():
def __init__(self, name, age, gender, course=None):
if course is None:
course = []
self.name = name
self.age = age
self.gender = gender
self.courses = course
def choose_course(self):
pass
class Teacher():
def __init__(self, name, age, gender, level):
self.name = name
self.age = age
self.gender = gender
self.level = level
def score(self):
pass
类Teacher与Student之间存在重复的代码,老师与学生都是人类,所以我们可以得出如下继承关系,实现代码重用
class People():
school = 'SH'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def __init__(self, name, age, gender, course=None):
if course is None:
course = []
# 调用__init__方法即可
# 调用方法一:
# People(name, age, gender) # 类名(),实例化,即调用People中的__init__函数
# 调用方法二:
People.__init__(self, name, age, gender) # 类名.方法名(四个参数!)
'''类来调用绑定给对象的方法,网上找找'''
self.courses = course
def choose_course(self):
pass
class Teacher(People):
def __init__(self, name, age, gender, level):
People.__init__(self, name, age, gender)
self.level = level
def score(self):
pass
Teacher类内并没有定义__init__方法,但是会从父类中找到__init__,因而仍然可以正常实例化,如下
stu = Student('kevin', 20, 'male')
print(stu.name) # kevin
print(stu.age) # 20
print(stu.gender) # male
print(stu.school) # SH
tea = Teacher('ly', 18, 'male', 10)
print(tea.name) # ly
print(tea.age) # 18
print(tea.gender) # male
print(tea.level) # 10
print(tea.school) # SH
总结
继承本质应该分为两部分
- 抽象:将多个类相同的东西抽出去形成一个新的类
- 继承:将多个类继承刚刚抽取出来的新的类
"""
对象:数据与功能的结合体
类(子类):多个对象相同数据和功能的结合体
父类:多个类(子类)相同数据和功能结合体
ps:类与父类本质都是为了节省代码,都是给对象提供方便
"""
属性查找
有了继承关系,对象在查找属性时,先从对象自己的__dict__中找,如果没有则去子类中找,然后再去父类中找……
单继承下的属性查找
class Foo():
pass
class Bar(Foo):
pass
class Func(Bar):
pass
先从对象自己的名称空间中查找,找不到在从产生这个对象的类中查找,类中找不到在去继承的父类中查找,一直找到没有父类为止,在找不到就报错了
1.注意:一定要分清楚self是谁
class Foo():
def f1(self):
print('from Foo.f1')
def f2(self):
print('from Foo.f2')
self.f1()
class Bar(Foo):
def f1(self):
print('from Bar.f1')
obj = Bar()
obj.f2()
# > from Foo.f2
# > from Bar.f1
"""
强调:对象点名字 永远从对象自身开始一步步查找
以后在看到self.名字的时候 一定要搞清楚self指代的是哪个对象
"""
分析:Bar加括号表示实例化这个类得到一个对象,对象点方法名表示对象调方法,先去对象自己的名称空间查找,然后去产生这个对象的类(Bar)中查找,没有。去父类中查找,找见了。
self.f1(),此时的self是obj对象,此时self.f1()=>obj.f1(),又重新开始寻找,所以,又运行的是Bar类中的f1方法
2.隐藏属性
class Foo():
def __f1(self): # _Foo__f1()
print('from Foo.f1')
def f2(self):
print('from Foo.f2')
self.__f1() # self._Foo__f1()
class Bar(Foo):
def __f1(self): # _Bar__f1()
print('from Bar.f1')
obj = Bar()
obj.f2()
# > from Foo.f2
# > from Foo.f1
与上面不一样,隐藏属性在定义阶段就已经变形了,在哪个类中隐藏的就用的哪个的类名
这次是指名道姓的调用
这也体现了,隐藏对外不对内
多继承下的属性查找
多继承分为非菱形结构和菱形结构。菱形结构中经典类与新式类会有不同,分别对应属性的两种查找方式:深度优先和广度优先
非菱形查找
参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
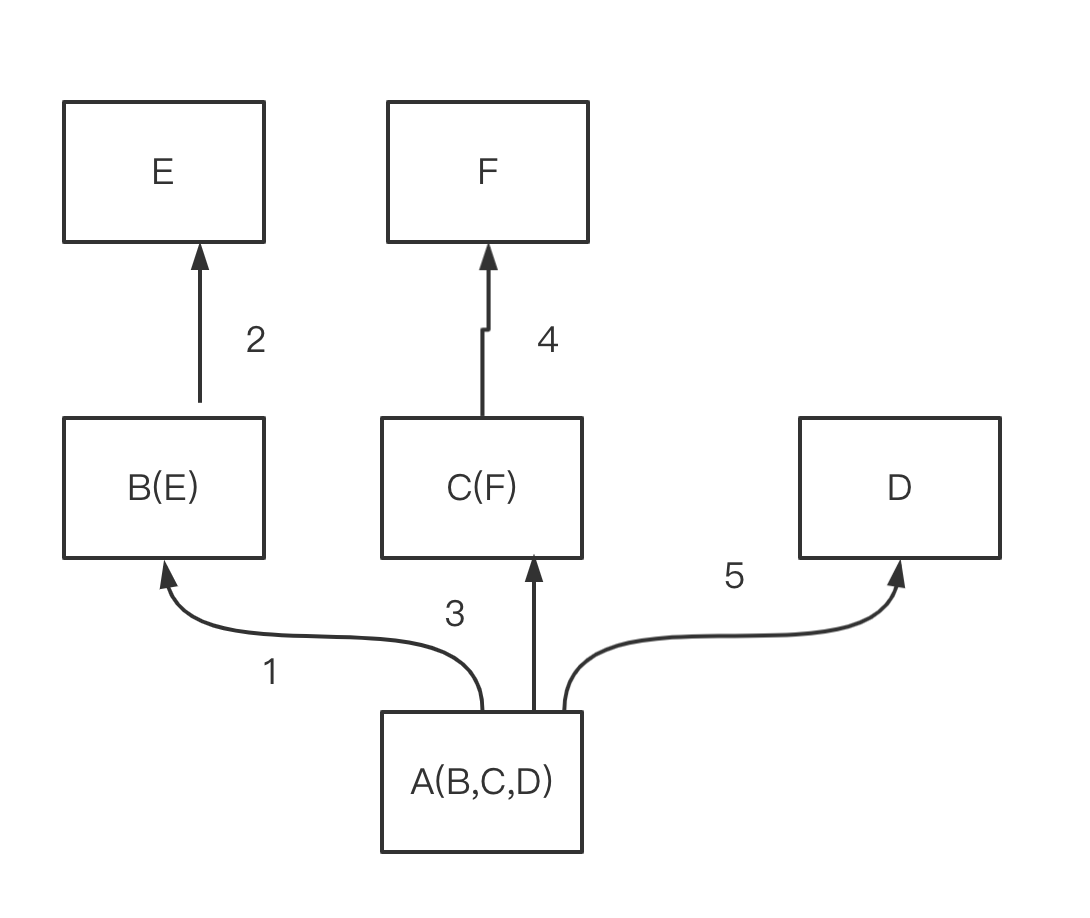
class E:
def test(self):
print('from E')
class F:
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D:
def test(self):
print('from D')
class A(B, C, D):
# def test(self):
# print('from A')
pass
print(A.mro())
'''
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
'''
obj = A()
obj.test() # 结果为:from B
# 可依次注释上述类中的方法test来进行验证
深度优先
当类是经典类时,多继承情况下,在要查找属性不存在时,会按照深度优先的方式查找下去(Python2中)
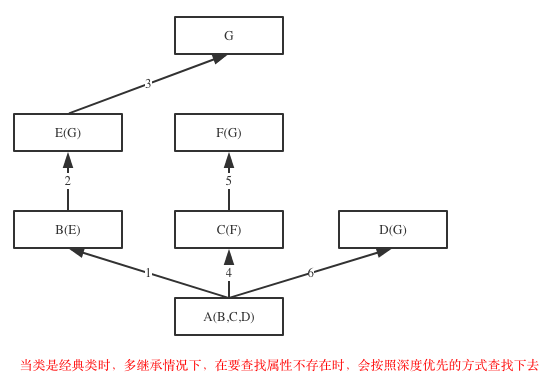
class G: # 在python2中,未继承object的类及其子类,都是经典类
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->G->C->F->D->object
# 可依次注释上述类中的方法test来进行验证,注意请在python2.x中进行测试
广度优先
当类是新式类时,多继承情况下,在要查找的属性不存在时,会按照广度优先的方式查找下去
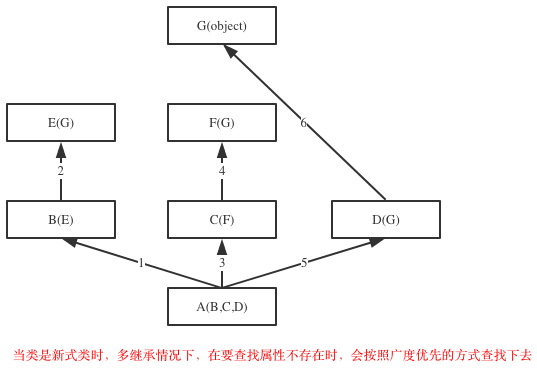
class G(object):
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->C->F->D->G->object
# 可依次注释上述类中的方法test来进行验证
super关键字与mro列表
派生方法
super关键字:子类调用父类的方法
- python2的写法:super(Student, self).init(name, age, gender)
- python3的写法:super().init(name, age, gender)
在以前学习中,使用类名点方法名,指名道姓的调用方法,有几个参数传几个参数。
使用这种方式,可以不继承父类
'''但是,Student实例化的对象想要调用school属性,必须依赖于继承'''
class People():
school = 'SH'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def __init__(self, name, age, gender, course=None):
if course is None:
course = []
# People(name, age, gender)
# 指名道姓的调用方法
People.__init__(self, name, age, gender) # 这样的调用方式,其实是不依赖于继承的
self.courses = course
def choose_course(self):
pass
stu = Student('kevin', 20, 'male')
print(stu.name)
print(stu.age)
print(stu.gender)
我们还可以直接使用super,拓展性更强
'''super(Student, self) 返回的是一个特殊对象(特殊之处后续讲解),它一定是个对象'''
class People():
school = 'SH'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Student(People):
def __init__(self, name, age, gender, course=None):
if course is None:
course = []
'''使用这种方式,比上面那种要强大'''
'''super(Student, self) 返回的是一个特殊对象,它一定是个对象'''
# 对象调方法,会把对象自己当成第一个参数传给self,所以只需要传3个参数
super(Student, self).__init__(name, age, gender) # 不能说继承的就是父类,不严谨
# 可以认为是People类里面刚好有
self.courses = course
def choose_course(self):
pass
stu = Student('kevin', 20, 'male')
print(stu.name) # kevin
print(stu.age) # 20
print(stu.gender) # male
多继承中如果存在super关键字,可以直接打印mro()列表来判断寻找顺序,要打印起始类的mro()列表
没有super,就按照多继承的顺序查找即可
# 打印mro()列表:
print(Student.mro())
# > [<class '__main__.Student'>, <class '__main__.People'>, <class 'object'>]
派生方法案例
案例1:
想要对一个方法有限制时。可以使用super(),先继承父类的方法,在子类中也定义这个方法,用super().方法名(父类方法参数),继承父类中的方法,然后在super()上面增加一些限制
class MyList(list):
def append(self, values):
if values == 'jason':
print('jason不能尾部追加')
return
super().append(values)
obj = MyList()
print(obj, type(obj))
obj.append(111)
obj.append(222)
obj.append(333)
obj.append('jason')
print(obj)
案例2:把以下字典序列化
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'jason'
}
import json
import datetime
d = {
't1': datetime.date.today(),
't2': datetime.datetime.today(),
't3': 'jason'
}
print(d)
# > {'t1': 2023-03-23, 't2':2023-03-23 14:29:15.803020, 't3': 'jason'}
# res = json.dumps(d)
# print(res) # 会报错
"""
序列化报错
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type date is not JSON serializable
"""
d不能被序列化的原因:外面是字典可以被序列化,但里面的t1,t2不能被序列化
import json
json.JSONEncoder
"""
能够被序列化的数据是有限的>>>:里里外外都必须是下列左边的类型
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
"""
想要能够被序列化:
1.转换方式1:手动转类型(简单粗暴)
d = {
't1': str(datetime.date.today()),
't2': str(datetime.datetime.today())
}
res = json.dumps(d)
print(res)
2.转换方式2:派生方法(儒雅高端)
可以使用面向对象
"""
查看dumps源码 注意cls=None参数 默认传JsonEncoder
查看该类的源码 发现default方法是报错的发起者
编写类继承JsonEncoder并重写default方法 之后调用dumps手动传cls=我们自己写的类
"""
class MyJsonEncoder(json.JSONEncoder):
def default(self, o):
"""
:param o: 接收无法被序列化的数据
:return: 返回可以被序列化的数据
"""
# 增加额外的功能
if isinstance(o, datetime.datetime): # 判断是否是datetime类型 如果是则处理成可以被序列化的类型
return o.strftime('%Y-%m-%d %X')
elif isinstance(o, datetime.date):
return o.strftime('%Y-%m-%d')
# 继承的原来的功能
return super().default(o) # 最后还是调用原来的方法 防止有一些额外操作没有做
res = json.dumps(d, cls=MyJsonEncoder)
print(res)
mro列表
python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下
print(Student.mro())
# > [<class '__main__.Student'>, <class '__main__.People'>, <class 'object'>]
python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
所以对象名.属性名的查找顺序是,先从对象本身的属性里,没有找到,则参照属性查找的发起者(即对象)所处类的MRO列表来依次检索。
1.由对象发起的属性查找,会从对象自身的属性里检索,没有则会按照对象的类.mro()规定的顺序依次找下去,
2.由类发起的属性查找,会按照当前类.mro()规定的顺序依次找下去
案例:
class A:
def test(self):
super().test()
class B:
def test(self):
print('from B')
class C(A, B):
pass
c = C()
c.test()
# > from B
'''查看一个类的mro列表, 要从起始类开始看.是从哪个类开始的'''
print(C.mro()) # 要查看C类的mro列表 # 类名.mro()
# > [<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
如果类A与类B换了位置
class C(B, A):
pass
c = C()
c.test()
print(C.mro()) # 先从C里面找,没有,去B找,找见了,就直接返回,碰不到super()关键字
# > [<class '__main__.C'>, <class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
c = A()
print(A.mro())
# > <class '__main__.A'>, <class 'object'>]
c.test() # 会报错
# > 'super' object has no attribute 'test'
组合
在一个类中以另外一个类的对象作为数据属性,称为类的组合。组合与继承都是用来解决代码的重用性问题。不同的是:继承是一种“是”的关系,比如老师是人、学生是人,当类之间有很多相同的之处,应该使用继承;而组合则是一种“有”的关系,比如老师有生日,老师有多门课程,当类之间有显著不同,并且较小的类是较大的类所需要的组件时,应该使用组合,如下示例
class Foo():
def __init__(self, m):
self.m = m
class Bar():
def __init__(self, n):
self.n = n
obj = Foo(10)
obj1 = Bar(20)
'''这就是组合,此时的obj对象已经变成了超级对象,可以通过一个对象得到另外一个对象的值'''
obj.x = obj1 # 对象增加一个属性:对象名.属性名 (赋值)= 另一个对象名
# 想要输出n值
# print(obj1.n) # 方法一,如果不使用这种方法呢
# 方法二:
# obj.x是obj1,obj1.n就是求对象的属性
print(obj.x.n) # 20
案例
# 继承是满足什么是什么的关系才用
# 组合是满足什么有什么的关系才用
class People(): # 父类
school = 'SH'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 加一门课程
class Course():
def __init__(self, name, period, price):
self.name = name
self.period = period
self.price = price
python=Course('python', '6mon', 30000) # 产生一个课程对象
linux=Course('linux', '5mon', 20000)
# 求对象的任意属性
# print(python.name)
# print(python.price)
# print(python.period)
# print(linux.name)
# print(linux.price)
'''以上是产生了一门课程,怎么让学生拥有一门课程呢?'''
# 管理员
class Admin(People): # 继承People类
pass # 继承是满足什么是什么的关系才用
class Student(People):
def __init__(self, name, age, gender, course=None):
if course is None:
course = []
# python2中的写法
# super(Student, self).__init__(name, age, gender)
# python3中的写法
super().__init__(name, age, gender)
self.courses = course
def choose_course(self):
pass
stu = Student('kevin',20, 'female')
'''一门课程'''
stu.course = python # 组合
'''多门课程,可以用列表'''
stu.courses.append(python.name) # 组合
stu.courses.append(linux.name)
print(stu.courses) # [python对象,linux对象]
# > [<__main__.Course object at 0x00000215378C9B00>, <__main__.Course object at 0x00000215378C9BA8>]
for course in stu.courses: # 查看对象
print(course)
stu.courses.append(python.name) # 也可以直接将课程对象的名字存入列表中
stu.courses.append(linux.name)
print(stu.courses)
# > ['python', 'linux']
# for course_obj in stu.courses: # 使用循环
# print(course_obj.name) # 查看对象名字
class Teacher(People):
def __init__(self, name, age, gender, level):
super().__init__(name, age, gender)
self.level = level
def score(self):
pass
tea = Teacher('ly', 10, 'male',10)
tea.course = python # 拥有一门课程
print(tea.course.name)
print(tea.course.period)
print(tea.course.price)

