面向对象编程
python中的两大编程思想
面向过程
面向过程的核心是:过程二字。过程是先干什么,再干什么,最后干什么的流程,也就是机械化的思维方式,面向过程就是按照固定的流程解决问题。
面向过程是提出问题,然后制定出问题的解决方案。就是需要列举出每一步的流程,并且会随着步骤的深入,问题的解决越来越简单。
列举一个生活中的例子:把大象放进冰箱需要分几步? 1.打开冰箱门, 2.把大象放进冰箱, 3.关上冰箱门
优点:把复杂的问题简单化,进而流程化
缺点:扩展性差
使用场景:对扩展性要求不高的地方
'''
之前学习截止ATM为止,使用的几乎都是面向过程编程
eg:注册功能、登录功能、转账功能
'''
# 注册功能分布封装成函数
# 1. 接收用户输入的用户名和密码
def get_info():
username = input('username:')
password = input('password')
email = input('email:')
return {
'username': username,
'password': password,
'email':email
}
# 2. 验证参数
def check_info(userinfo):
# userinfo = {
# 'username': username,
# 'password': password
# }
flag = False
if len(userinfo['username']) == 0:
print('username不能为空')
flag = True
if len(userinfo['password']) == 0:
print('password不能为空')
flag = True
if len(userinfo['email']) == 0:
print('email不能为空')
flag = True
return {
'flag':flag,
'userinfo':userinfo
}
# 3. 写入文件
def save_info(param):
if not param['flag']:
'''写文件'''
with open('a.txt', 'w', encoding='utf-8') as f:
import json
json.dump(param['userinfo'], f)
def main():
userinfo = get_info()
param = check_info(userinfo)
save_info(param)
if __name__ == '__main__':
main()
面向对象
“面向对象”的核心是“对象”二字,而对象的精髓在于“整合“,什么意思?
所有的程序都是由”数据”与“功能“组成,因而编写程序的本质就是定义出一系列的数据,然后定义出一系列的功能来对数据进行操作。在学习”对象“之前,程序中的数据与功能是分离开的,如下
# 数据:name、age、sex
name='lili'
age=18
sex='female'
# 功能:tell_info
def tell_info(name,age,sex):
print('<%s:%s:%s>' %(name,age,sex))
# 此时若想执行查看个人信息的功能,需要同时拿来两样东西,一类是功能tell_info,另外一类则是多个数据name、age、sex,然后才能执行,非常麻烦
tell_info(name,age,sex)
在学习了“对象”之后,我们就有了一个容器,该容器可以盛放数据与功能,所以我们可以说:对象是把数据与功能整合到一起的产物,或者说”对象“就是一个盛放数据与功能的容器/箱子/盒子。
在了解了对象的基本概念之后,理解面向对象的编程方式就相对简单很多了,面向对象编程就是要造出一个个的对象,把原本分散开的相关数据与功能整合到一个个的对象里,这么做既方便使用,也可以提高程序的解耦合程度,进而提升了程序的可扩展性(需要强调的是,软件质量属性包含很多方面,面向对象解决的仅仅只是扩展性问题)
两种编程思想的分析
上述两种编程思想没有优劣之分,需要结合实际需求而定:
- 如果需求是注册、登录、人脸识别肯定面向过程更合适
- 如果需求是游戏人物肯定是面向对象更合适
实际编程两种思想是彼此交融的,只不过占比不同
面向对象的推导
面向对象对于初学者而言是一个非常抽象的东西,直接讲解晦涩难懂,浅尝辄止!
python中一切皆对象>>>:都是数据和功能的整合
我们先编写一个学生选课系统
步骤1:定义学生和选课功能
代码定义出学生信息和选课,直接使用变量和函数
stu_name = 'kevin'
stu_age = 20
stu_gender = 'male'
stu_courses = []
stu1_name = 'tony'
stu1_age = 21
stu1_gender = 'female'
stu1_courses = []
# 选课的功能:谁,选择的课程(可一可多,以列表储存),课程
def choose_course(stu_name, stu_courses, course):
stu_courses.append(course)
print('%s选课成功%s' % (stu_name, stu_courses))
choose_course(stu_name, stu_courses, 'python')
# > kevin选课成功['python']
choose_course(stu1_name, stu1_courses, 'linux')
# > tony选课成功['linux']
'''上述的学生信息还比较少,如果学生人数变多了,有几百个,或者不同学生的信息都混合在一起时,想要找出一个学生的信息就变得难上加难'''
步骤2:信息字典
将学生的信息放到一个字典中,选课功能函数的参数随之变化
stu1 = {
'name': 'kevin',
'age': 20,
'gender': 'male',
'courses': [],
}
stu2 = {
'name': 'tony',
'age': 21,
'gender': 'female',
'courses': []
}
def choose_course(stu_dict, course):
stu_dict['courses'].append(course)
print('%s选课成功%s' % (stu_dict['name'], stu_dict['courses']))
choose_course(stu1, 'python')
choose_course(stu2, 'linux')
# > kevin选课成功['python']
# > tony选课成功['linux']
'''面向对象中的对象是特征和技能的结合体,上述定义的学生,只有特征,没有技能,所以要将选课功能也加入进去,才能够组成一个对象'''
步骤3:数据与功能的绑定
将选课的功能跟学生的信息绑定,>>>:数据与功能的绑定
def choose_course(stu_dict, course):
stu_dict['courses'].append(course)
print('%s选课成功%s' % (stu_dict['name'], stu_dict['courses']))
stu1 = {
'name': 'kevin',
'age': 20,
'gender': 'male',
'courses': [],
'choose_courses': choose_course
}
stu2 = {
'name': 'tony',
'age': 21,
'gender': 'female',
'courses': [],
'choose_courses': choose_course
}
stu1['choose_courses'](stu1, 'python')
stu2['choose_courses'](stu2, 'linux')
# > kevin选课成功['python']
# > tony选课成功['linux']
'''调用方式改变了,谁来调用这个方法,会将自己当成参数传进去'''
类与对象
类即类别/种类,是面向对象分析和设计的基石,如果多个对象有相似的数据与功能,那么该多个对象就属于同一种类。有了类的好处是:我们可以把同一类对象相同的数据与功能存放到类里,而无需每个对象都重复存一份,这样每个对象里只需存自己独有的数据即可,极大地节省了空间。所以,如果说对象是用来存放数据与功能的容器,那么类则是用来存放多个对象相同的数据与功能的容器。
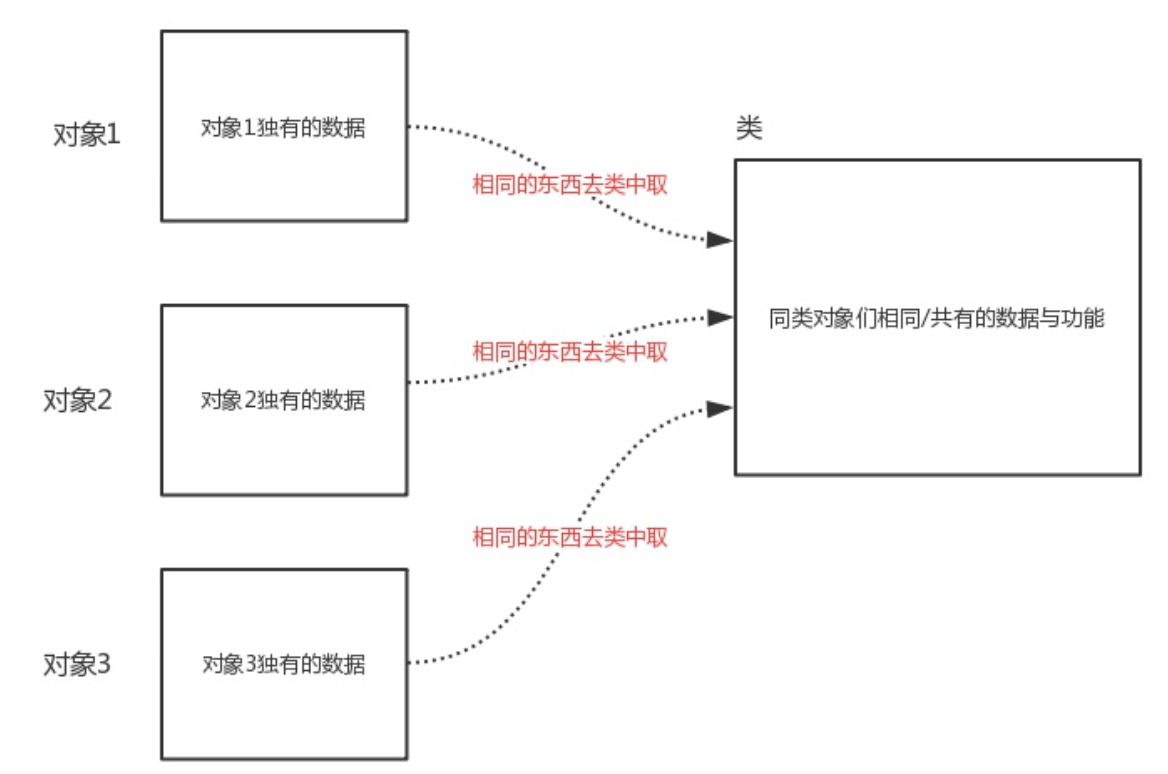
综上所述,虽然我们是先介绍对象后介绍类,但是需要强调的是:在程序中,必须要事先定义类,然后再调用类产生对象(调用类拿到的返回值就是对象)。产生对象的类与对象之间存在关联,这种关联指的是:对象可以访问到类中共有的数据与功能,所以类中的内容仍然是属于对象的,类只不过是一种节省空间、减少代码冗余的机制,面向对象编程最终的核心仍然是去使用对象。
对象:'特征'与'技能'的结合体
类:一系列相似特征与相似技能的结合体
面向对象编程
类的语法结构
"""
专业语法来定义类
语法格式:
def index():
pass
class 类名():
pass
"""
- 类名的命名遵循变量的命名规范
- 类名的首字母一般大写
- 如果类名存在多个单词,一般是大驼峰格式
我们还可以定义一个空类
class Student():
pass
定义类发生的几件事情?
- 定义类,会立马执行类体代码
- 产生类的名称空间,并且把类中的属性和方法名字丢在类的名称空间中,其实就是丢在大字典里
- 把类的名称空间绑定给__dict__,类名.dict
类的定义与实例化
简单介绍基于面向对象的思想如何编写程序
# 类名后可以不加括号(后续学习),但是推荐加上括号
class Student():
# 定义一个特征---->变量
school = 'SH' # 属性:变量名与数据值的绑定
country = 'China' # 变量在类里面叫属性
# 定义功能---->函数
# 函数写到类里面叫方法
def choose_course(stu_dict, course):
stu_dict['courses'].append(course)
print('%s选课成功%s' % (stu_dict['name'], stu_dict['courses']))
类体最常见的是变量的定义和函数的定义,但其实类体可以包含任意Python代码,类体的代码在类定义阶段就会执行,因而会产生新的名称空间用来存放类中定义的名字,可以打印Student.__dict__来查看类这个容器内盛放的东西
print(Student.__dict__)
# > 输出结果是:
# {'__module__': '__main__',
# 'school': 'SH', # 属性:值
# 'country': 'China', # 属性:值
# 'choose_course': <function Student.choose_course at 0x000001C49957FD08>, # 方法:内存地址
# '__dict__': <attribute '__dict__' of 'Student' objects>,
# '__weakref__': <attribute '__weakref__' of 'Student' objects>,
# '__doc__': None}
先定义类,调用类产生对象。调用类的过程称为将类实例化,拿到的返回值就是程序中的对象,或称为一个实例
'''类名加括号就会产生对象 并且每执行一次都会产生一个全新的对象'''
# 变量名stu1接收类名加括号之后的返回值(结果)
stu1 = Student() # 类名() 对象1
stu2 = Student() # 类名() 对象2
打印对象, 得到一个地址, 是Student类产生的对象
print(stu1) # > <__main__.Student object at 0x000001CB32F3D470>
print(stu2) # > <__main__.Student object at 0x000001E756659B00>
对象也有自己的名称空间
print(stu1.__dict__) # {}
print(stu2.__dict__) # {}
'''调用类产生对象,得到的对象就是一个空对象,空字典'''
定制对象自己独有的属性
对象属性的推导流程
推导流程1:每个对象手动添加独有的数据, 想要往对象名称空间中加变量,就是直接往字典里面加值
# 添加第一个对象的属性
stu1.__dict__['name'] = 'kevin' # 新增键值对
stu1.__dict__['age'] = 20
stu1.__dict__['gender'] = 'male'
stu1.__dict__['courses'] = []
print(stu1.__dict__)
# > {'name': 'kevin', 'age': 20, 'gender': 'male', 'courses': []}
# 添加第二个对象的属性
stu2.__dict__['name'] = 'tom'
stu2.__dict__['age'] = 28
stu2.__dict__['gender'] = 'fmale'
stu2.__dict__['courses'] = []
print(obj2.__dict__)
在面向对象中,类和对象访问数据或者功能,可以统一采用句点符。以上可以直接写成
stu = Student()
stu.name = 'kevin' # stu.__dict__['name'] = 'kevin'
stu.age = 20 # stu.__dict__['age'] = 20
stu.gender = 'male' # stu.__dict__['gender'] = 'male'
stu.courses = [] # stu.__dict__['courses'] = []
print(stu.__dict__)
# > {'name': 'kevin', 'age': 20, 'gender': 'male', 'courses': []}
# 建其他对象
stu1 = Student()
stu1.name = 'jack'
stu1.age = 21
stu1.gender = 'male'
stu1.courses = []
print(stu1.__dict__)
# > {'name': 'jack', 'age': 21, 'gender': 'male', 'courses': []}
stu2 = Student()
stu2.name = 'tom'
stu2.age = 22
stu2.gender = 'male'
stu2.courses = []
print(stu2.__dict__)
# > {'name': 'tom', 'age': 22, 'gender': 'male', 'courses': []}
'''代码冗余,可以封装成函数'''
推导流程2:封装成函数版本,将内部的值,直接当成参数传输进来,并且,对象名可以当成参数传输进来
stu = Student()
stu1 = Student()
stu2 = Student()
def init(stu_dict, name, age, gender, course=[]):
stu_dict.name = name
stu_dict.age = age
stu_dict.gender = gender
stu_dict.courses = course
init(stu, 'kevin', 20, 'male')
init(stu1, 'kevin1', 21, 'male')
init(stu2, 'kevin2', 22, 'male')
print(stu.__dict__)
print(stu1.__dict__)
print(stu2.__dict__)
# > {'name': 'kevin', 'age': 20, 'gender': 'male', 'courses': []}
# > {'name': 'kevin1', 'age': 21, 'gender': 'male', 'courses': []}
# > {'name': 'kevin2', 'age': 22, 'gender': 'male', 'courses': []}
'''每一次调用对象都要使用init函数,不想使用这种方法,怎么优化?'''
推导流程3:给学生对象添加独有数据的函数只有学生对象有资格调用
class Student():
# 定义一个特征
school = 'SH' # 属性
country = 'China'
# 初始化方法,当类被加括号调用的时候,会自动触发这个函数的执行
'''即是:类被调用的时候,__init__函数把对象自己当成第一个参数传给了第一个位置形参'''
def __init__(self, name, age, gender, course=[]):
# self => stu
# self => stu1
self.name = name
self.age = age
self.gender = gender
self.courses = course
# 函数写到类里面叫方法
def choose_course(stu_dict, course):
stu_dict['courses'].append(course)
print('%s选课成功%s' % (stu_dict['name'], stu_dict['courses']))
'''类被调用的时候,类里面传的第一个参数是这个类产生的对象'''
stu = Student('kevin', 20, 'male') # stu = Student(stu, 'kevin', 20, 'male')
print(stu.__dict__)
# > {'name': 'kevin', 'age': 20, 'gender': 'male', 'courses': []}
stu1 = Student('kevin1', 21, 'male') # stu = Student(stu, 'kevin', 20, 'male')
print(stu1.__dict__)
# > {'name': 'kevin1', 'age': 21, 'gender': 'male', 'courses': []}
__init__函数在类里面可有可无,但是想要传参数,就一定要有。谁来调用,就会先把自己当成第一个参数传进去
属性的查找顺序
类属性的查找
查找: 类名.属性名
print(Student.school)
print(Student.country)
print(Student.country1) # 不存在会报错
增加:增加就是赋值
Student.aaa = 'xxx' # 类中不存在的属性
print(Student.__dict__)
修改
Student.school = 'beijing' # 类种存在的属性
print(Student.__dict__)
删除
del Student.school
print(Student.__dict__)
对象属性的查找
先产生一个对象
stu = Student('kevin', 20, 'male') # 产生一个对象
print(stu.__dict__) # 对象的名称空间
查看
print(stu.__dict__['name'])
print(stu.name)
print(stu.age) # 查看对象自己的属性
print(stu.gender)
print(stu.school)
print(stu.__dict__['school']) # 先从对象自己的属性里面去查找,没有去类中查找,再没有则直接报错
# stu.school = 'aaaaa' # 这个属于对象属性的增加,增加的school是在对象名称空间中
'''对象的属性查找,先从自己对象属性里面去找,如果找到了,直接返回,如果找不到,在去产生这个对象的类中取查找,如果也没有,则报错'''
增加
stu.aaa = 'xxx'
print(stu.__dict__)
修改
stu.name = 'xxxx'
print(stu.__dict__)
删除
del stu.name
print(stu.__dict__)
练习
定义一个计数器,记录一共产生了多少个对象?
class Student():
school = 'SH'
count = 0
def __init__(self, name, age):
self.name = name
self.age = age
# self.count += 1
Student.count+=1
stu = Student('kevin', 20)
stu1 = Student('kevin1', 21)
stu2 = Student('kevin2', 22)
stu3 = Student('kevin3', 23)
'''类属性一改,对象在调用的时候全改'''
print(Student.count)
print(stu.count)
print(stu.__dict__)
print(stu1.__dict__)
print(stu2.__dict__)
print(stu3.__dict__)
小结
在上述介绍类与对象的使用过程中,我们更多的是站在底层原理的角度去介绍类与对象之间的关联关系,如果只是站在使用的角度,我们无需考虑语法“对象.属性"中”属性“到底源自于哪里,只需要知道是通过对象获取到的就可以了,所以说,对象是一个高度整合的产物,有了对象,我们只需要使用”对象.xxx“的语法就可以得到跟这个对象相关的所有数据与功能,十分方便且解耦合程度极高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号