
函数递归与数据类型生成式
一、函数递归调用介绍
函数不仅可以嵌套定义,还可以嵌套调用,即在调用一个函数的过程中,函数内部又调用另一个函数,而函数的递归调用指的是在调用一个函数的过程中又直接或间接地调用该函数本身
例如
直接调用:
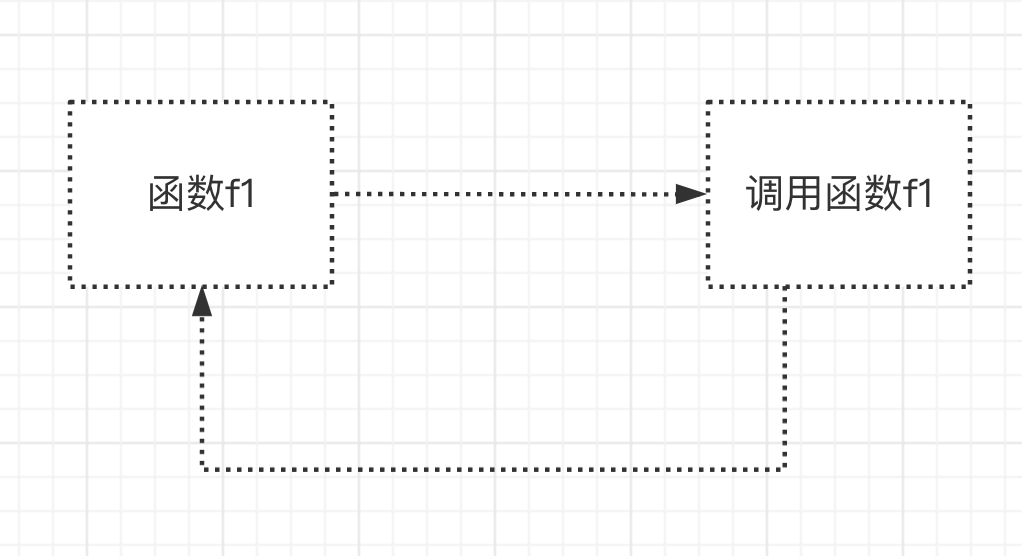
在调用index的过程中,又调用index,这就是直接调用函数index本身
def index():
print('from index')
index()
index()
间接调用:
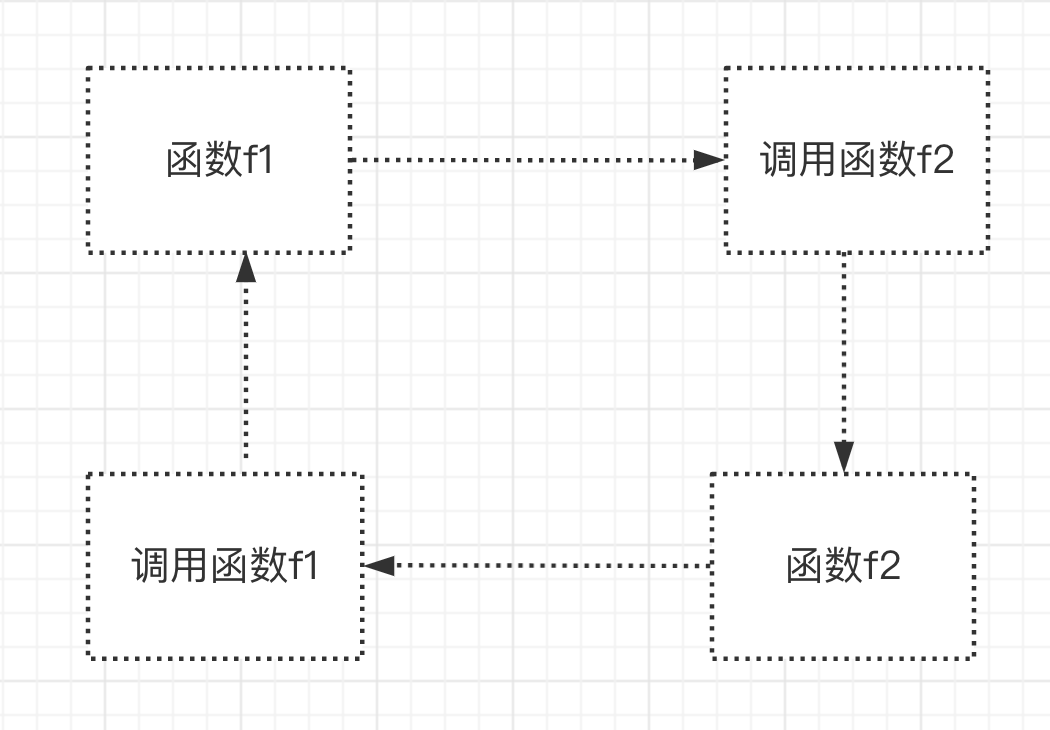
在调用func的过程中,又调用index,而在调用index的过程中又调用func,这就是间接调用函数func本身
def index():
print('from index')
func()
def func():
print('from func')
index()
func()
从上图可以看出,两种情况下的递归调用都是一个无限循环的过程,但在python对函数的递归调用的深度做了限制(最大递归深度),因而并不会像大家所想的那样进入无限循环,会抛出异常。要避免出现这种情况,就必须让递归调用在满足某个特定条件下终止。
# python官网介绍:默认的递归深度是1000
import sys
# 查看递归深度,默认值为1000
print(sys.getrecursionlimit()) # 1000
'''官网提供的最大递归深度为1000 我们在测试的时候可能会出现996 997 998'''
# 可以设置递归深度
sys.setrecursionlimit(20)
print(sys.getrecursionlimit()) # 20
二、回溯与递推
下面直接用一个例子,阐述递归的原理和使用:
2.1 例子
某一排有五个学生,问第五个学生的年龄是多少,他说比第四个大2岁,问第四个学生年龄,他说比第三个学生大2岁,问第二个学生的年龄,他说比第一个大2岁,最后第一个人说自己是18岁,请问第五个人是多少岁?
思路解析:
想要知道第五个人的年龄,就必须知道第四个人的,第四个人的年龄又取决于第三个人的,第三个人的又取决于第二个人的,第二个人的又取决于第一个人的,而且每个人都比前一个大2岁,数学表达式为:
# 伪代码:
age(5) = age(4) + 2
age(4) = age(3) + 2
age(3) = age(2) + 2
age(2) = age(1) + 2
age(1) = 18
age(n) = age(n-1)+2
age(1) = 18
需要注意的一点是,递归一定要有一个结束条件,这里n=1就是结束条件。
真实代码:
def age(n):
if n == 1:
return 18
res = age(n-1)+2 # age(4)+2
return res
print(age(5))
执行结果:
26
程序分析:
在未满足n1的条件时,一直进行递归调用,即一直回溯。而在满足n1的条件时,终止递归调用,即结束回溯,从而进入递推阶段,依次推导直到得到最终的结果。
2.2 嵌套多层列表
递归本质就是在做重复的事情,所以理论上递归可以解决的问题循环也都可以解决,只不过在某些情况下,使用递归会更容易实现,比如有一个嵌套多层的列表,要求打印出所有的元素 lst = [1, [2, [3, [4, [5, [6, [7, ]]]]]]]
伪代码
for i in lst:
# 判断此时的i值是整数还是列表,如果是整数直接打印,如果是列表,直接for循环
if type(i) is int:
print(i)
else:
# 如果是列表,直接for循环
for j in i:
if type(j) is int:
print(j)
else:
# 如果是列表,直接for循环
for m in j:
if type(m) is int:
print(m)
真实代码:
lst = [1, [2, [3, [4, [5, [6, [7, ]]]]]]]
def get_lst(lst):
for i in lst: # for循环,如果内部没有元素,自动结束,不需要再设置结束条件了
if type(i) is int:
print(i)
else:
get_lst(i)
get_lst(lst)
三、算法中的二分法
3.1 算法
算法:是解决问题的方法, 为了提高效率而产生的。并没有能够解决任何问题的一种算法,一种算法只能解决一类特定问题。
常见的算法有:二分法、冒泡排序、选择排序、快拍、插入、堆排、桶排、数据结构(链表约瑟夫问题,如何链表是否成环)
3.2 二分法
一分为二
二分法的原则:1、 列表中得数字必须要有序,不管是升序还是降序都可以,如果没有顺序就不能使用二分法
二分法的使用:
例子:在列表中找出某个数字
列表:l = [1, 22, 44 ,10, 3, 45, 66, 88,101, 20, 30 ,40],在列表中找出20这个数字
l = [1, 22, 44, 10, 3, 45, 66, 88, 101, 20, 30, 40, 12]
l.sort()
print(l) # [1, 3, 10, 12, 20, 22, 30, 40, 44, 45, 66, 88, 101]
# 1.定义我们要找的数值
# targrt_num = 44
# 1.函数的形参两个是目标值,列表,这样可以找其他列表,其他目标值
def my_half(target_num, l):
# 6.添加一个结束条件
if len(l) == 0:
print('不好意思,没找到')
return
# 2.获取列表中间索引值
middle_index = len(l) // 2 # 6
# 3.比较目标数据值与中间索引值的大小
if target_num > l[middle_index]:
# 4.切片保留列表右边一半
l_right = l[middle_index+1:] # l[7:]
print(l_right)
# 5.针对右边一半的列表继续二分并判断 >>>: 用递归函数
my_half(target_num, l_right)
elif target_num < l[middle_index]:
# 切片保留列表左边一般
l_left = l[:middle_index] # l[:6]
print(l_left)
my_half(target_num, l_left)
else:
print('找到了')
# my_half(44, l)
# my_half(100, l)
# my_half(12, l)
四、三元表达式
4.1 语法结构:
"""
语法结构:
条件成立之后的结果 if 条件 else 条件不成功之后的结果
使用场景:结果二选一的情况
"""
4.2 使用
def my_max(a, b):
if a > b:
return a
else:
return b
用三元表达式实现上述功能
def my_max(a, b):
return a if a > b else b
# print(my_max(1, 10))
print(my_max(60, 6))
4.3 嵌套使用
a = 1
b = 10
c = 10
d = 20
# 1.单层嵌套
res = a if a > b else (c if c > d else d)
print(res) # 20
# 2.嵌套多层
res1 = a if a > b else (c if c > d else ('bbb' if d > c else 'aaa'))
print(res1) # bbb
'''不推荐使用三元表达式嵌套使用,嵌套的使用出现最多的场景就是:面试题'''
# 练习
# is_beautiful=True
# res = '漂亮' if is_beautiful else '不漂亮'
# print(res)
cmd = input('请选择是否输入:(y/n)')
res='继续' if cmd == 'y' else '不继续'
print(res)
五、列表生成式(掌握)
语法格式:
"""
语法格式:
res=[变量 for 变量 in 可迭代对象]
res=[变量 for 变量 in 可迭代对象 if 条件]
res=[变量 if 条件 else 666 for 变量 in 可迭代对象 ]
"""
使用1:
name_list = ['kevin', 'jack', 'ly', 'tony']
# 需求是:把列表中得名字都添加一个后缀:_NB
1. 传统做法:
new_list = []
for name in name_list:
res='%s_NB' % name # 字符串拼接
new_list.append(res) # 加入到列表中
print(new_list)
2.使用列表生成式
# 2. 使用列表生成式
# 先for循环,之后再看for关键字前面的操作
res = ['%s_NB' % name for name in name_list]
print(res)
使用2:
# 需求:除了jack不加,其他都加,如果是jack直接去掉
name_list = ['kevin', 'jack', 'ly', 'tony']
# 传统做法
new_list = []
for name in name_list:
if name == 'jack':
continue
else:
res = '%s_NB' % name
new_list.append(res)
print(new_list) # ['kevin_NB', 'ly_NB', 'tony_NB']
# 列表生成式的使用
res = ['%s_NB' % name for name in name_list if name != 'jack']
print(res) # ['kevin_NB', 'ly_NB', 'tony_NB']
new_list = ['%s_NB' % name for name in name_list if name == 'jack']
print(new_list) # ['jack_NB']
# 不可以在if后面加else,因为计算机不能识别else是跟着if还是跟着for,
使用3:
'''特殊用法'''
# 但if...else...放在for前面可以使用,如下
res = ['%s_NB' % name if name != 'jack' else '666' for name in name_list ]
print(res) # ['kevin_NB', '666', 'ly_NB', 'tony_NB']
六、字典生成式,集合生成式(了解)
6.1 enumerate
l1 = ['name', 'age', 'salary']
l2 = ['kevin', 18, 3000]
#
count = 0
for i in l1:
print(count, i)
count += 1
# 记忆
"""
enumerate:使用for循环的时候,可以解压赋值出来两个值,一个是索引,一个是元素
start:控制的是起始位置,默认是从0开始
"""
for i, j in enumerate(l1):
print(i, j)
for i, j in enumerate(l1, start=2):
print(i, j)
6.2 字典生成式
'''将列表l1,l2写成了, l1:l2一对一形式写入字典中'''
# 1.传统写法
new_dict = {}
for i in range(len(l1)):
new_dict[l1[i]] = l2[i]
print(new_dict) # {'name': 'kevin', 'age': 18, 'salary': 3000}
# 2. 字典生成式
res = {i: j for i, j in enumerate(l1)}
print(res)
# 输出结果是:{0: 'name', 1: 'age', 2: 'salary'}
6.3 集合生成式
l1 = ['name', 'age', 'salary']
# 集合
res = {i for i in l1}
print(res) # {'age', 'name', 'salary'}
元组>>>:没有元组生成式 下列的结果是生成器(后面讲)
# 迭代器
res = (i for i in l1)
print(res) # generator
七、匿名函数
指没有名字的函数
7.1 语法格式
"""
语法格式:
lambda 形参:返回值
lambda x:x**2
匿名函数一般不单独使用,会配合其他函数使用
map()
"""
7.2 使用:
# 直接用函数
def index(x):
return x ** 2
print(index(3)) # 9
# 匿名函数
res = lambda x: x ** 2
print(res(2)) # 4
# 函数地址输出index函数名
print(index) # <function index at 0x000001923C022F28>
# 函数地址输出后没有函数名
print(res) # <function <lambda> at 0x000001923C1FED08>
7.3 配合其他函数使用
映射:map()
map(函数,可迭代对象)
函数接收两个参数,一个是函数,一个是iterable(可迭代的),
map将传入的函数依次作用到序列的每一个元素,并把结果作为新的iterable返回
使用1:
# 配合map()函数使用
l1 = [1, 2, 4, 6, 7]
# def func(a):
# return a + 1
res = map(lambda x:x+1, l1)
print(list(res))
# 输出结果是:[2, 3, 5, 7, 8]
使用2:
l = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 函数
def index(x):
return x**2
res = list(map(index, l))
print(map(index, l)) # <map object at 0x000001AE4E6FF240>
print(res) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
# 匿名函数
res = list(map(lambda x: x**2, l))
print(map(lambda x: x**2, l)) # <map object at 0x0000025552D7F198>
print(res) # [1, 4, 9, 16, 25, 36, 49, 64, 81]

