


数据类型----字符串内置方法
一、定义
# 定义:在单引号\双引号\三引号内包含一串字符
name1 = 'jason' # 本质:name = str('任意形式内容')
name2 = "lili" # 本质:name = str("任意形式内容")
name3 = '''ricky''' # 本质:name = str('''任意形式内容''')
name4 = """ricky""" # 本质:name = str("""任意形式内容""")
二、类型转换
# 数据类型转换:str()可以将任意数据类型转换成字符串类型,例如
print(str(19))
print(str(19.1))
print(str([1, 2, 3, 4]))
print(str({'username': 'kevin', 'age': 18}))
print(str((1, 2, 3, 4)))
print(str(True))
print(str({11, 22, 33}))

三、使用
3.1 优先掌握的操作
3.1.1 按索引取值
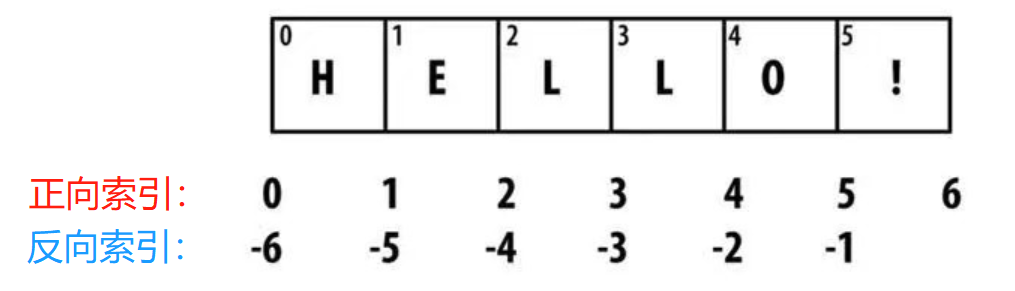
str1 = 'hello python!'
# 1.按索引取值(正向取,反向取)
# 1.1 正向取(从左往右)
'''空格也是一个字符串,索引从0开始'''
print(str1[0]) # h
print(str1[6]) # p
# 1.2 反向取(负号表示从右往左)
print(str1[-1]) # !
# 1.3 对于str来说,只能按照索引取值,不能改
# print(str1[0]='H') # SyntaxError: keyword can't be an expression
'''字符串不支持修改,字符串为不可变类型'''
3.1.2 []切片
str1 = 'hello python!'
# 2.切片(顾头不顾尾,步长)
# 2.1顾头不顾尾:取出索引为0到8的所有字符
print(str1[0:9]) # hello pyt
print(str1[-4:-1]) # hon
'''实际工作中,尽量不要用负数切片'''
'''第一位参数要小于第二位参数数,不然数据是空'''
print(str1[4:1])
print(str[-1:-4])
#TypeError: 'type' object is not subscriptable(类型错误:类型对象是不可下标的)
# 2.2 步长:0:9:2,第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2、4、6、8的字符
print(str1[0:9:2]) # hlopt
# 2.3 反向切片:-1表示从右往左依次取值,实现的功能就是字符串翻转 (记忆)
print(str1[::-1]) # !nohtyp olleh
print(str1[0:14:-1])
#这种取法不可以,输出的是None
3.1.3 长度len => length
# 3.长度len:获取字符串的长度,即字符的个数,但凡存在于引号内的都算作字符)
'''空格也是字符串'''
print(len(str1)) # 13
3.1.4 成员运算 in 和 not in
# 4.1 int:判断hello 是否在 str1里面
print('lo' in str1) # True
# 4.2 not in:判断tony 是否不在 str1里面
print('tony' not in str1) # True
3.1.5 strip移除 lstrip rstrip
# 5.strip移除移除字符串**首尾**指定的字符(默认移除空格),不能去除中间的
# 5.1 括号内不指定字符,默认移除首尾空白字符(空格、\n、\t)
str1 = ' life is short! '
print(str1.strip()) # life is short!
# 5.1.1strip去除的是左右两边的空格,lstrip去除的是左边的空格,rstrip去除的是右边的空格
str2 = ' hello '
print(str2) # hello
print(str2.strip()) # hello
print(str2.lstrip()) # hello
print(str2.rstrip()) # hello
# 5.1.2应用:输入用户名和密码时要去除空格
username = input('username:>>>').strip()
password = input('password:>>>').strip()
if username == 'kevin' and password == '123':
print('登录成功')
else:
print('登录失败')
# 5.2 括号内特殊字符串,移除首尾指定的字符
str3 = '**tony**'
print(str3.strip('*')) # tony
str4 = '@@kevin@##'
print(str4.strip('@')) # kevin@##
print(str4.strip('#')) # @@kevin@
3.1.6 split切分
# 6.切分split
# 6.1 括号内不指定字符,默认以空格作为切分符号
'''注意:split切割得到的结果是列表数据类型'''
str5 = 'hello world'
print(str5.split()) # ['hello', 'world']
# 6.2 括号内指定分隔字符,则按照括号内指定的字符切割字符串
str6 = '127.0.0.1'
print(str6.split('.')) # ['127', '0', '0', '1']
# 6.3 split会按照从左到右的顺序对字符串进行切分,可以指定切割次数
str7 = 'C:/a/b/c/d.txt'
print(str7.split('/')) # ['C:', 'a', 'b', 'c', 'd.txt']
# 切割1次
print(str7.split('/', 1)) # ['C:', 'a/b/c/d.txt']
# 6.4 rsplit刚好与split相反,从右往左切割,可以指定切割次数
str8 = 'a|b|c'
print(str8.rsplit('|', 1)) # ['a|b', 'c']
print(str8.rsplit('|', 2)) # ['a', 'b', 'c']
3.1.7 循环
# 7.循环
str9 = '今天你好吗?'
for line in str9: # 依次取出字符串中每一个字符
print(line)

3.2 需要掌握的操作
3.2.1 lower upper
res = 'keViN123 oldBoY!'
# 1.改写
# 将英文字符串全部变小写
print(res.lower()) # kevin123 oldboy!
# 将英文字符串全部变大写
print(res.upper()) # KEVIN123 OLDBOY!
# 2.判断该变量是否全是大写或者小写
print(res.islower()) # False
print(res.isupper()) # False
a ='hello'
print(a.islower()) # True
# 3.应用
"""
图片验证码不区分大小写
思路:把用户输入的验证码全部转为大写或者小写,
跟原来的验证码都转为大写或者小写进行比较
"""
old_code = 'oldBoY'
print('返回给你的验证码是:%s' % old_code)
# 用户输入的验证码
real_code = input('请输入验证码:')
# if old_code.lower() == real_code.lower():
if old_code.upper() == real_code.upper():
print('验证码输入正确')
else:
print('验证码错误')
3.2.2 startswith, endswith
res = 'Kevin123 OldGirl'
# 1.startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False,是区分大小写的
print(res.startswith('K')) # True
print(res.startswith('Kev')) # True
print(res.startswith('kev')) # False
print(res.startswith('Keva')) # False
# 2.endswith()判断字符串是否以括号内指定的字符结尾
print(res.endswith('Girl')) # True
print(res.endswith('Rl')) # False
3.2.3 格式化输出之format
之前我们使用%s来做字符串的格式化输出操作,在传值时,必须严格按照位置与%s一一对应,而字符串的内置方法format则提供了一种不依赖位置的传值方式
# 3.格式化输出之forma
# 3.1第一种用法
# 格式化输出:%s %d
ss = 'my name is %s, my age is %s' % ('kevin', 18)
print(ss) # my name is kevin, my age is 18
# 类似与%s的方法,但format是用{}来占位,占位与变量要一一对应,个数不一致会报错
s1 = 'my name is {}, my age is {}'
print(s1.format('kevin', 20)) # my name is kevin, my age is 20
s2 = 'my name is {}, my age is {},{}{}{}'
print(s2.format('kevin', 20, 'a', 'b', 'c')) # my name is kevin, my age is 20,abc
# 3.2第二种用法
# 把format传入的多个值当作一个列表,然后用{索引}取值,就不需要个数一致了
s3 = '{1}my name is {0}, my age is {1}{0}{0}, {2}'
print(s3.format('tony', 22, 'helloworld')) # 22my name is tony, my age is 22tonytony, helloworld
# 3.3第三种用法
# format括号内在传参数时完全可以打乱顺序,但仍然能指名道姓地为指定的参数传值,name=‘kevin’就是传给{name}
s4 = 'my name is {name}, my age is {age}'
print(s4.format(name='kevin', age=20)) # my name is kevin, my age is 20
s4 = '{age}my name is {name}, my age is {age}{name}{name}'
print(s4.format(name='kevin', age=20)) # 20my name is kevin, my age is 20kevinkevin
3.2.4 join拼接
# join拼接是从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接,拼接的结果为字符串
# join的内部就是简单的for循环
l = ['tony', 'kevin', 'jack', 'tom']
# 麻烦的方法:可以用列表索引取值,字符串相加 '+'
print(l[0] + '|' + l[1] + '|' + l[2] + '|' + l[3]) # tony|kevin|jack|tom
# 简单方法:直接用join,指定的分隔符.join()
print('|'.join(l)) # tony|kevin|jack|tom
print('%@'.join('hello')) # h%@e%@l%@l%@o
3.2.5 replace替换字符串
# 1.用新的字符替换字符串中旧的字符
s = 'my name is kevin kevin kevin kevin'
print(s.replace('kevin', 'jack')) # my name is jack jack jack jack
# 2.可以指定替换的个数,是将2个'kevin'替换成 'jack'
print(s.replace('kevin', 'jack', 2)) # my name is jack jack kevin kevin
3.2.6 isdigit
# 判断字符串是否是纯数字组成,返回结果为True或False
s = 'kevin123'
print(s.isdigit()) # False
s = '123'
print(s.isdigit()) # True
s = '123.4'
print(s.isdigit()) # False
# 应用:猜年龄
guess_age = input('请输入你的年龄:')
if guess_age.isdigit(): # 不加这一步,输入str类型就会出现bug
if int(guess_age) == 18:
print('猜对了')
else:
print('猜错了!')
else:
print('你输入的年龄不合法')

3.3 只需要了解的操作
3.3.1 find,index,count
# 1.find,index,count
# 1.1 find:从指定范围内查找子字符串的起始索引,找得到则返回第一个子字符串字母的索引
msg = 'tony say hello hello hello'
print(msg.find('s')) # 5
print(msg.find('hello')) # 9
# 找不到则返回-1
print(msg.find('helloa')) # -1
# 在索引为1和2(顾头不顾尾)的字符中查找字符o的索引
print(msg.find('o', 1, 3)) # 1
'''
与in作用相似
find:是用来判断一个子字符串是否在另外一个字符串中,只要不返回-1,就代表在
'''
# 1.2 index:同find,但在找不到时会报错
print(msg.index('s')) # 5
print(msg.index('hello')) # 9
print(msg.index('helloa')) # 如果查不到字符串直接报错
print(msg.index('s', 2, 6)) # 5
# 1.3 count:统计字符串在大字符串中出现的次数
# 统计字符串e出现的次数
print(msg.count('e')) # 3
# 没有就输出0
print(msg.count('helloa')) # 0
# # 字符串e在索引1~11范围内出现的次数
print(msg.count('e', 1, 11)) # 1
3.3.2 center,ljust,rjust,zfill
# 2.center,ljust,rjust,zfill
res = 'kevin'
# 2.1 center总宽度是16,字符串居中展示,不够默认用空格填充
print(res.center(16))
# 可以用特殊字符填充 # kevin
print(res.center(16, '@')) # @@@@@kevin@@@@@@
# 2.2 ljust总宽度是16,字符串向左对齐,不够用'*'填充
print(res.ljust(16, '*')) # kevin***********
# 2.3 rjust总宽度是16,字符串向右对齐,不够用'-'填充
print(res.rjust(16, '-')) # -----------kevin
# 2.4 zfill只有一个参数,总宽度是16,字符串右对齐显示,不够用0填充
print(res.zfill(16)) # 00000000000kevin
3.3.3 captalize,swapcase,title
# 3.captalize,swapcase,title
res = 'my name is keVIn'
# 3.1 title:每个单词的首字母大写
print(res.title()) # My Name Is Kevin
# 3.2 captalize:第一个单词的首字母大写
print(res.capitalize()) # My name is kevin
# 3.3swapcase:大小写翻转
print(res.swapcase()) # MY NAME IS KEviN
3.3.4 expandtabs
# 4.expandtabs
name = 'tony\thello' # \t表示制表符(tab键)
print(name) # tony hello
# 修改\t制表符代表的空格数
print(name.expandtabs(1)) #tony hello
3.3.5 is其他
# 5.is其他
name = 'tony123'
# alnum:字母数字字符,字符串中既可以包含数字也可以包含字母
print(name.isalnum()) # True
# alpha:字符串中只包含字母
print(name.isalpha()) # False
# identifier:标识符,是否含有标识符
# 标识符(identifier)主要用来表示常量、变量、函数和类 型等程序要素的名字,是只起标识作用的一类符号
print(name.isidentifier()) # True
# 字符串是否是纯小写
print(name.islower()) # True
# 字符串是否是纯大写
print(name.isupper()) # False
# 字符串是否全是空格
print(name.isspace()) # False
# 字符串中的单词首字母是否都是大写
print(name.istitle()) # False
3.3.6 is数字系列
# 6.is数字系列
# 在python3中
num1 = b'4' # bytes
num2 = u'4' # unicode:一种不用字节的形式来表示文本,python3中无需加u就是unicode
num3 = '四' # 中文数字
num4 = 'Ⅳ' # 罗马数字
# 6.1 isdigit():检测字符串是否只由数字组成,只对 0 和 正数有效
# isdigit能判断bytes,unicode,最常用的
print(num1.isdigit()) # True
print(num2.isdigit()) # True
print(num3.isdigit()) # False
print(num4.isdigit()) # False
# 6.2 isdecimal:检查字符串是否只包含十进制字符
# isdecimal能判断unicode
# bytes类型无isdecimal方法,会报错
print(num2.isdecimal()) # True
print(num3.isdecimal()) # False
print(num4.isdecimal()) # False
# 6.3 isnumberic:(bytes类型无isnumberic方法)
# isnumberic能判断unicode,汉字,罗马
print(num2.isnumeric()) # True
print(num3.isnumeric()) # True
print(num4.isnumeric()) # True
# 6.4 三者不能判断浮点数
num5 = '4.3'
print(num5.isdigit()) # False
print(num5.isdecimal()) # False
print(num5.isnumeric()) # False
'''
总结:
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumeric。
'''


