2023数据采集与融合技术实践作业1
2023数据采集与融合技术实践作业1
作业1
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
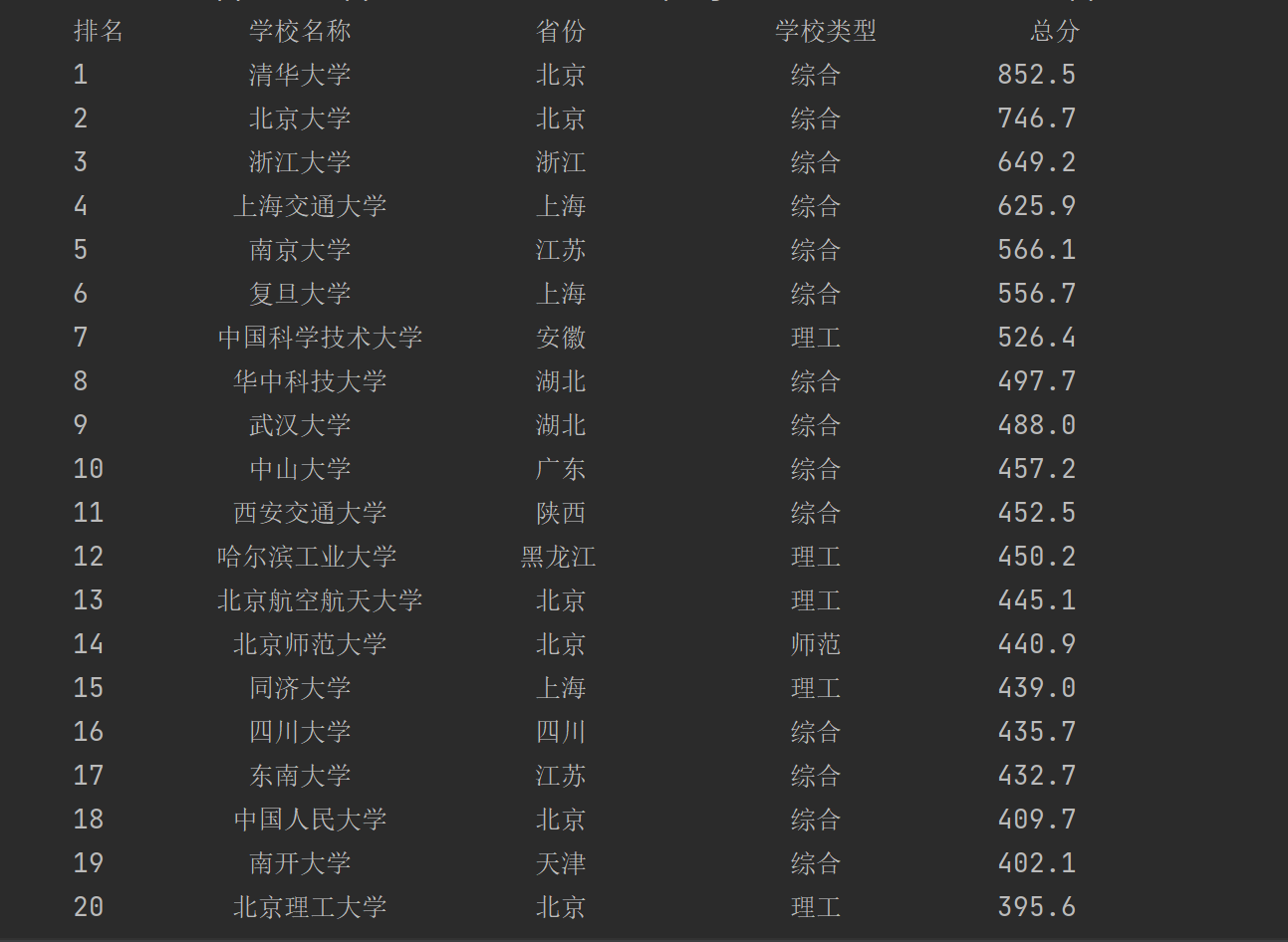
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | ... | ... | ... | ... |
思路:
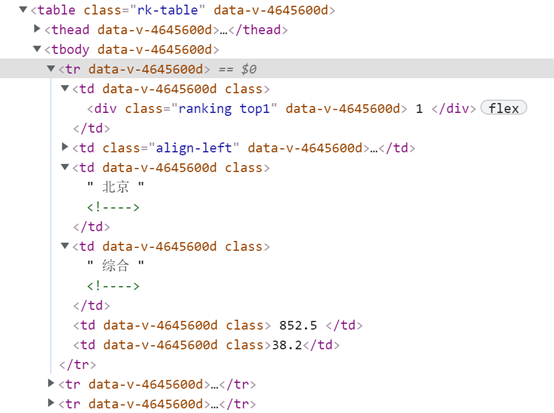
观察网页源代码,我们可以看到,所有大学信息都封装在一个表格(标签tbody)中,单个学校信息在tr标签中,详细信息在td标签中,大学的名字被包在a标签中。
所以我们首先遍历tbody标签,获得所有大学信息,然后在tbody标签中找到tr标签,获得每个大学信息,最后在tr标签里找到td标签,把我们需要的相关数据写在我们的ulist列表中。
(1)实验代码
import urllib.request
from bs4 import BeautifulSoup
import bs4
# 从网络上获取大学排名网页内容。
def getHTMLText(url):
try:
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/11"}
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req).read().decode()
return data
except Exception as err:
print(err)
# 将html页面放到ulist列表中
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
#所用数据都封装在一个表格(标签tbody)中,单个学校信息在tr标签中,详细信息在td标签中
# 学校名称在a标签中,定义一个列表单独存放a标签内容
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
a = tr('a') # 把所用的a标签存为一个列表类型
tds = tr('td') # 将所有的td标签存为一个列表类型
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
# 打印出ulist列表的信息,num表示希望将列表中的多少个元素打印出来
def printUnivList(ulist1, num):
# 格式化输出
lt= "{0:^10}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^10}"
print(lt.format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(num):
u = ulist1[i]
print(lt.format(u[0], u[1], u[2], u[3], u[4]))
def main():
uinfo = [] # 将大学信息放到列表中
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 30) # 一个界面的数据
if __name__ == '__main__':
main()
运行结果:
(2)心得体会
1、一开始运行出现下面报错:TypeError: object of type 'NoneType' has no len(),后来发现是服务器拒绝了我的访问,爬取不到内容所以为None,于是增加headers则可访问
2、查看网页源码时,需定位到所需信息所对应的源码并分析它们的特点,不然会爬到一堆不需要的信息,解析网页时找到最合适的BeautifulSoup中的方法,这样能够缩减代码量。
作业2
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | ... | ... |
思路:

查看源码信息,发现书包都在ul中,每个书包的信息在li中,商品名称在a标签的title中,而价格在p标签中,于是按照上述思路编写代码。
(1)实验代码
import requests
from bs4 import BeautifulSoup
def crawl_dangdang(keyword):
url = f'http://search.dangdang.com/?key={keyword}&act=input'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
response = requests.get(url, headers=headers)
content = response.text
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(content, 'html.parser')
# 定位商品列表
item_list = soup.find('ul', class_='bigimg cloth_shoplist').find_all('li')
i=0
# 提取商品名称和价格
print(f'序号\t价格\t\t商品名称')
for item in item_list:
name = item.find('a', class_='pic').get('title')
price = item.find('span', class_='price_n').text
i=i+1
print(f'{i}\t{price}\t{name}')
# 测试爬虫
crawl_dangdang('书包')
运行结果:

(2)心得体会
1、一开始使用淘宝爬了半天都爬不出来,后来发现淘宝的反爬机制做的太好,于是放弃转战当当
2、发现正则表达式运用不熟练,有好几次没匹配到信息还有匹配到不要的信息,于是又去看了一遍上课ppt,然后对比了一下BeautifulSoup,发现还是BeautifulSoup更易上手
作业3
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
思路:
利用BeautifulSoup解析网页信息,使用find_all方法查找标签并根据src中的信息获取图片的下载地址,最后下载图片到本地。
(1)实验代码
import requests
import os
from urllib.parse import urljoin, urlparse
from bs4 import BeautifulSoup
# 下载并保存JPEG文件
def save_jpeg_from_url(url, save_folder):
# 发送HTTP请求并下载图片
response = requests.get(url)
content_type = response.headers["Content-Type"]
if not content_type.startswith("image/jpeg"):
return None
# 提取JPEG文件名
filename = os.path.basename(urlparse(url).path)
# 去掉文件名中的问号
filename = filename.split("?")[0]
# 拼接保存路径
save_path = os.path.join(save_folder, filename)
# 保存图片
with open(save_path, "wb") as f:
f.write(response.content)
print(f"已保存图片:{save_path}")
# 定义要爬取的网页URL
url = "https://xcb.fzu.edu.cn/info/1071/4481.htm"
# 创建保存JPEG文件的文件夹
save_folder = "D:\\files\\project\\files\\爬虫实践\\images"
os.makedirs(save_folder, exist_ok=True)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/11"
}
# 发送HTTP请求并获取网页内容
response = requests.get(url,headers=headers)
html = response.text
# 解析网页内容,提取图片链接
soup = BeautifulSoup(html, "html.parser")
img_tags = soup.find_all("img")
# 遍历图片链接,下载并保存图片
for img_tag in img_tags:
# 获取图片链接
src = img_tag.get("src")
# 构造绝对路径
img_url = urljoin(url, src)
save_jpeg_from_url(img_url, save_folder)
运行结果:

(2)心得体会
1、查看图片所对应的源码时,发现图片有以.jpg和.jpeg结尾,但是图片链接都是在img下的src中,于是直接使用BeautifulSoup中的方法
2、本来想以图片的地址作为下载图片的名字,但出现文件命名出错:文件名字中不能出现'?'号,于是删除问号后再命名


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)