

正则表达式
什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本, 它可以用来从文本中找出满足你想要的格式的句子.
一个正则表达式是在一个主体字符串中从左到右匹配字符串时的一种样式. "Regular expression"这个词比较拗口, 我们常使用缩写的术语"regex"或"regexp". 正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串、验证表单、提取字符串等等.
想象你正在写一个应用, 然后你想设定一个用户命名的规则, 让用户名包含字符,数字,下划线和连字符,以及限制字符的个数,好让名字看起来没那么丑. 我们使用以下正则表达式来验证一个用户名:

以上的正则表达式可以接受 john_doe, jo-hn_doe, john12_as. 但不匹配Jo, 因为它包含了大写的字母而且太短了.
目录
1. 基本匹配
正则表达式其实就是在执行搜索时的格式, 它由一些字母和数字组合而成. 例如: 一个正则表达式 the, 它表示一个规则: 由字母t开始,接着是h,再接着是e.
"the" => The fat cat sat on the mat.
正则表达式123匹配字符串123. 它逐个字符的与输入的正则表达式做比较.
正则表达式是大小写敏感的, 所以The不会匹配the.
"The" => The fat cat sat on the mat.
2. 元字符
正则表达式主要依赖于元字符. 元字符不代表他们本身的字面意思, 他们都有特殊的含义. 一些元字符写在方括号中的时候有一些特殊的意思. 以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符. |
| [ ] | 字符种类. 匹配方括号内的任意字符. |
| [^ ] | 否定的字符种类. 匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符. |
| + | 匹配>=1个重复的+号前的字符. |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符 (n <= num <= m). |
| (xyz) | 字符集, 匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
2.1 点运算符 .
.是元字符中最简单的例子. .匹配任意单个字符, 但不匹配换行符. 例如, 表达式.ar匹配一个任意字符后面跟着是a和r的字符串.
".ar" => The car parked in the garage.
2.2 字符集
字符集也叫做字符类. 方括号用来指定一个字符集. 在方括号中使用连字符来指定字符集的范围. 在方括号中的字符集不关心顺序. 例如, 表达式[Tt]he 匹配 the 和 The.
"[Tt]he" => The car parked in the garage.
方括号的句号就表示句号. 表达式 ar[.] 匹配 ar.字符串
"ar[.]" => A garage is a good place to park a car.
2.2.1 否定字符集
一般来说 ^ 表示一个字符串的开头, 但它用在一个方括号的开头的时候, 它表示这个字符集是否定的. 例如, 表达式[^c]ar匹配一个后面跟着ar的除了c的任意字符.
"[^c]ar" => The car parked in the garage.
2.3 重复次数
后面跟着元字符 +, * or ? 的, 用来指定匹配子模式的次数. 这些元字符在不同的情况下有着不同的意思.
2.3.1 * 号
*号匹配 在*之前的字符出现大于等于0次. 例如, 表达式 a* 匹配以0或更多个a开头的字符, 因为有0个这个条件, 其实也就匹配了所有的字符. 表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串.
"[a-z]*" => The car parked in the garage #21.
*字符和.字符搭配可以匹配所有的字符.*. *和表示匹配空格的符号\s连起来用, 如表达式\s*cat\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串.
"\s*cat\s*" => The fat cat sat on the concatenation.
2.3.2 + 号
+号匹配+号之前的字符出现 >=1 次. 例如表达式c.+t 匹配以首字母c开头以t结尾,中间跟着任意个字符的字符串.
"c.+t" => The fat cat sat on the mat.
2.3.3 ? 号
在正则表达式中元字符 ? 标记在符号前面的字符为可选, 即出现 0 或 1 次. 例如, 表达式 [T]?he 匹配字符串 he 和 The.
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
2.4 {} 号
在正则表达式中 {} 是一个量词, 常用来一个或一组字符可以重复出现的次数. 例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的数字.
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
我们可以省略第二个参数. 例如, [0-9]{2,} 匹配至少两位 0~9 的数字.
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
如果逗号也省略掉则表示重复固定的次数. 例如, [0-9]{3} 匹配3位数字
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
2.5 (...) 特征标群
特征标群是一组写在 (...) 中的子模式. 例如之前说的 {} 是用来表示前面一个字符出现指定次数. 但如果在 {} 前加入特征标群则表示整个标群内的字符重复 N 次. 例如, 表达式 (ab)* 匹配连续出现 0 或更多个 ab.
我们还可以在 () 中用或字符 | 表示或. 例如, (c|g|p)ar 匹配 car 或 gar 或 par.
"(c|g|p)ar" => The car is parked in the garage.
2.6 | 或运算符
或运算符就表示或, 用作判断条件.
例如 (T|t)he|car 匹配 (T|t)he 或 car.
"(T|t)he|car" => The car is parked in the garage.
2.7 转码特殊字符
反斜线 \ 在表达式中用于转码紧跟其后的字符. 用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符. 如果想要匹配这些特殊字符则要在其前面加上反斜线 \.
例如 . 是用来匹配除换行符外的所有字符的. 如果想要匹配句子中的 . 则要写成 \. 以下这个例子 \.?是选择性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat.
2.8 锚点
在正则表达式中, 想要匹配指定开头或结尾的字符串就要使用到锚点. ^ 指定开头, $ 指定结尾.
2.8.1 ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头.
例如, 在 abc 中使用表达式 ^a 会得到结果 a. 但如果使用 ^b 将匹配不到任何结果. 因为在字符串 abc 中并不是以 b开头.
例如, ^(T|t)he 匹配以 The 或 the 开头的字符串.
"(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
2.8.2 $ 号
同理于 ^ 号, $ 号用来匹配字符是否是最后一个.
例如, (at\.)$ 匹配以 at. 结尾的字符串.
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
3. 简写字符集
正则表达式提供一些常用的字符集简写. 如下:
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字, 等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字, 即符号, 等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符, 等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF (等同于 \r\n),用来匹配 DOS 行终止符 |
4. 零宽度断言(前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 ,也不针对组合计进行计数). 先行断言用于判断所匹配的格式是否在另一个确定的格式之前, 匹配结果不包含该确定格式(仅作为约束).
例如, 我们想要获得所有跟在 $ 符号后的数字, 我们可以使用正后发断言 (?<=\$)[0-9\.]*. 这个表达式匹配 $ 开头, 之后跟着 0,1,2,3,4,5,6,7,8,9,. 这些字符可以出现大于等于 0 次.
零宽度断言如下:
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 |
| ?! | 负先行断言-排除 |
| ?<= | 正后发断言-存在 |
| ?<! | 负后发断言-排除 |
4.1 ?=... 正先行断言
?=... 正先行断言, 表示第一部分表达式之后必须跟着 ?=...定义的表达式.
返回结果只包含满足匹配条件的第一部分表达式. 定义一个正先行断言要使用 (). 在括号内部使用一个问号和等号: (?=...).
正先行断言的内容写在括号中的等号后面. 例如, 表达式 (T|t)he(?=\sfat) 匹配 The 和 the, 在括号中我们又定义了正先行断言 (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat.
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
4.2 ?!... 负先行断言
负先行断言 ?! 用于筛选所有匹配结果, 筛选条件为 其后不跟随着断言中定义的格式. 正先行断言 定义和 负先行断言 一样, 区别就是 = 替换成 ! 也就是 (?!...).
表达式 (T|t)he(?!\sfat) 匹配 The 和 the, 且其后不跟着 (空格)fat.
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
4.3 ?<= ... 正后发断言
正后发断言 记作(?<=...) 用于筛选所有匹配结果, 筛选条件为 其前跟随着断言中定义的格式. 例如, 表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat, 且其前跟着 The 或 the.
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
4.4 ?<!... 负后发断言
负后发断言 记作 (?<!...) 用于筛选所有匹配结果, 筛选条件为 其前不跟随着断言中定义的格式. 例如, 表达式 (?<!(T|t)he\s)(cat) 匹配 cat, 且其前不跟着 The 或 the.
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
5. 标志
标志也叫模式修正符, 因为它可以用来修改表达式的搜索结果. 这些标志可以任意的组合使用, 它也是整个正则表达式的一部分.
| 标志 | 描述 |
|---|---|
| i | 忽略大小写. |
| g | 全局搜索. |
| m | 多行的: 锚点元字符 ^ $ 工作范围在每行的起始. |
5.1 忽略大小写 (Case Insensitive)
修饰语 i 用于忽略大小写. 例如, 表达式 /The/gi 表示在全局搜索 The, 在后面的 i 将其条件修改为忽略大小写, 则变成搜索 the 和 The, g 表示全局搜索.
"The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
5.2 全局搜索 (Global search)
修饰符 g 常用于执行一个全局搜索匹配, 即(不仅仅返回第一个匹配的, 而是返回全部). 例如, 表达式 /.(at)/g 表示搜索 任意字符(除了换行) + at, 并返回全部结果.
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
5.3 多行修饰符 (Multiline)
多行修饰符 m 常用于执行一个多行匹配.
像之前介绍的 (^,$) 用于检查格式是否是在待检测字符串的开头或结尾. 但我们如果想要它在每行的开头和结尾生效, 我们需要用到多行修饰符 m.
例如, 表达式 /at(.)?$/gm 表示小写字符 a 后跟小写字符 t , 末尾可选除换行符外任意字符. 根据 m 修饰符, 现在表达式匹配每行的结尾.
"/.at(.)?$/" => The fat
cat sat
on the mat.
"/.at(.)?$/gm" => The fat cat sat on the mat.
6. 贪婪匹配与惰性匹配 (Greedy vs lazy matching)
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式。
"/(.*at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.
常用正则表达式
一、校验数字的表达式
1 数字:^[0-9]*$
2 n位的数字:^\d{n}$
3 至少n位的数字:^\d{n,}$
4 m-n位的数字:^\d{m,n}$
5 零和非零开头的数字:^(0|[1-9][0-9]*)$
6 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13 非负整数:^\d+$ 或 ^[1-9]\d*|0$
14 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
二、校验字符的表达式
1 汉字:^[\u4e00-\u9fa5]{0,}$
2 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3 长度为3-20的所有字符:^.{3,20}$
4 由26个英文字母组成的字符串:^[A-Za-z]+$
5 由26个大写英文字母组成的字符串:^[A-Z]+$
6 由26个小写英文字母组成的字符串:^[a-z]+$
7 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
12 禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4 手机号码:^(13[0-9]|14[0-9]|15[0-9]|16[0-9]|17[0-9]|18[0-9]|19[0-9])\d{8}$ (由于工信部放号段不定时,所以建议使用泛解析 ^([1][3,4,5,6,7,8,9])\d{9}$)
5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 18位身份证号码(数字、字母x结尾):^((\d{18})|([0-9x]{18})|([0-9X]{18}))$
8 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
9 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
10 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
11 日期格式:^\d{4}-\d{1,2}-\d{1,2}
12 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
13 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
14 钱的输入格式:
15 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
16 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
17 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
18 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
19 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
20 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
21 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
22 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
23 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
24 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
25 中文字符的正则表达式:[\u4e00-\u9fa5]
26 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
27 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
28 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
29 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
30 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
31 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
32 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
33 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)) (由@飞龙三少 提供,感谢共享)
把一串数字表示成千位分隔形式——JS正则表达式的应用
一个案例
如何把一串整数转换成千位分隔形式,例如10000000000,转换成10,000,000,000。
在了解正则表达式之前,想要实现这个功能,无论代码量还是烧脑程度,都很令人抓狂,但若是运用正则表达式来解决的话,两三行代码即可搞定!匹配、替换那些符合某种规则的字符串,恰恰是正则表达式的强项。
正则表达式
#####概念 正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。它不仅仅是Javascript独有的东西,绝大多数主流操作系统、主流开发语言、无数的应用软件中,都可以看到正则表达式的优美舞姿。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。 #####特点
- 灵活性、逻辑性、功能性非常强
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 对于刚接触的人来说,比较晦涩难懂。
本文只是通过解决上述案例进而讨论Javascript所支持的正则表达式的部分常用且重要的方法,想查询Javascript中正则表达式的全部强大功能,请点击此处JavaScript RegExp 对象,查看W3school官方文档。
梳理思路
要先明白的是,我们将要转换成的数字格式是这样:从个位往左数起,每三位前插入一个千位分隔符,,即可以想象成我们要把每三位数字前面的那个空""匹配出来,并替换成千位分隔符,。每个千位分隔符后面的数字个数是3个或3的倍数个。
代码书写
创建一个正则表达式字面量,并加上全局匹配修饰符g。var reg = //g; W3C对全局匹配的解释是:查找所有匹配而非在找到第一个匹配后停止。
因为需要从右往左匹配,所以表示结尾的$是必须要有的。三位数字用\d{3}来表示,由于我们不知道究竟有多少组这样的三位数字,所以需要在\d{3}后面加上+,来表示匹配任何包含至少一组三位数字的字符串。至目前,/(\d{3})+$/g表示作为结尾的3个或3的倍数个数字。
由于要替换的是每三位数(从末尾起)紧前面的那个"",所以需要用到正向预查,即?=n(匹配任何其后紧接指定字符串 n 的字符串)。正向预查咋用呢?这里先举个例子:有一个字符串var str = "abaaaaa";,我们想把后面跟着字符b的字符a表示出来,于是正则表达式写法:var reg = /a(?=b)/g;,匹配的是后面紧跟着字符b的字符a,字符串str中只有一个符合条件的a,最后查看匹配结果为["a"]。这个例子的代码如下:
var str = "abaaaaa",
reg = /a(?=b)/g;
console.log(str.match(reg));
复制代码粗略了解正向预查之后,回到原来的案例,我们可以写成/(?=(\d{3})+$)/g;,为什么(?=...)前面什么也不写呀?因为我们要找的是那些后面紧跟着三位数字的""呀,空当然什么都不用写了。 我们来检验一下,是不是匹配出来三个""?
var str = "10000000000",
reg = /(?=(\d{3})+$)/g;
console.log(str.match(reg));
复制代码结果如下,果然是三个""。
var str = "10000000000",
reg = /(?=(\d{3})+$)/g;
console.log(str.replace(reg, ","));
复制代码结果如下,转换成功。
但是,还没完…… 现在是十一位数字,如果再加一个0,凑够十二位数呢,它可是3的倍数,我们试验一下:
var str = "100000000000",
reg = /(?=(\d{3})+$)/g;
console.log(str.replace(reg, ","));
复制代码结果变成了这样:
, 。这个原因就不解释了,你们应该明白为什么。那么怎么解决呢?我们对代码进行一下完善,在\d前面加一个非单词边界\B,用来表示所匹配的这个空后面不能是一个单词边界,这样就可以把最前面的这个,去掉了。 最终的代码如下
var str = "100000000000",
reg = /(?=(\B\d{3})+$)/g;
console.log(str.replace(reg, ","));
复制代码
总结
综上,”把一串整数转换成千位分隔形式“这个案例就说完了。我再把这个案例用到的一些知识点梳理一下。
g是表示全局匹配的修饰符,全局匹配指查找所有匹配而非在找到第一个匹配后停止。$是表示结尾的量词,如n$,匹配的是任何以n为结尾的字符串。\d是查找数字的元字符。n{X}是匹配包含 X 个 n 的序列的字符串的量词。n+是匹配任何包含至少一个 n 的字符串的量词。?=n正向预查,用于匹配任何其后紧接指定字符串 n 的字符串。match()String对象的方法,作用是找到一个或多个正则表达式的匹配。replace()String对象的方法,作用是替换与正则表达式匹配的子串。\B是表示匹配非单词边界的元字符,与其互为补集的元字符是\b,表示匹配单词边界。
本文无法做到十分细致,如果看完还是一头雾水的话,需要先从头学一下正则表达式。 欢迎提出意见或建议,感谢你的阅读!
RegExp 对象
test()方法
test() 方法用于检测一个字符串是否匹配某个模式,如果字符串中含有匹配的文本,则返回 true,否则返回 false。
var patt = /are/;
var res=patt.test("The best things in life are free!");
console.log(res) //true
相当于
var res=/e/.test("The best things in life are free!")
console.log(res)
exec()方法
exec() 方法用于检索字符串中的正则表达式的匹配。
该函数返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。
var patt=/are/
var res=patt.exec("The best things in life are free!")
console.log(res)
// ["are", index: 24, input: "The best things in life are free!", groups: undefined]
// 0: "are"
// groups: undefined
// index: 24
// input: "The best things in life are free!"
// length: 1
// __proto__: Array(0)
结果放在数组索引0位置,index为匹配项在字符串中的位置,input为应用正则表达式的字符串
注意:对于exec()方法而言,即使 在模式中设置全局标志(g),他每次也只会返回一个匹配项。
在不设置全局标志,在用一个字符串多次调用exec()将始终返回第一个匹配项
在设置全局标志,每次调用exec()都会在字符串中继续查找新匹配项
使用字符串方法
search(正则) 返回匹配项在字符串中的位置
var str="this is an antzone good";
var patt=/an/;
var res=str.search(patt)
console.log(res)
repalce(正则,替换后的字符串)
var str="this is an antzone good";
var patt=/an/;
var res=str.replace(patt,'123')
console.log(res) //this is 123 antzone good
正则修饰符
| i | 执行对大小写不敏感的匹配。 |
| g | 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。 |
| m | 执行多行匹配。 |
正则匹配 方括号查找范围内字符串
| [abc] | 查找方括号之间的任何字符。 |
| [0-9] | 查找任何从 0 至 9 的数字。 |
| (x|y) | 查找任何以 | 分隔的选项。 |
元字符是拥有特殊含义的字符
| \d | 查找数字。 |
| \s | 查找空白字符。 |
| \b | 匹配单词边界。 |
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字 等价于 '[^A-Za-z0-9_]'。
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
量词
| n+ | 匹配任何包含至少一个 n 的字符串。 1-n |
| n* | 匹配任何包含零个或多个 n 的字符串。 0-n |
| n? | 匹配任何包含零个或一个 n 的字符串。 0-1 |
注意转义,模式中使用的所有元字符都必须要转义
元字符 ( [ { \ ^ $ | ) ? * + . ] }
例如
// 例如匹配第一个 "[bc]at",不区分大小写
// 匹配元字符需要转义
var pat=/\[bc\]at/i
var str="sadfas[bc]atsdfasdf"
var res=pat.exec(str)
console.log(res) //["[bc]at", index: 6, input: "sadfas[bc]atsdfasdf", groups: undefined]
var index=str.search(pat)
console.log(index) //6
正则模式
1.使用字面量形式定义正则表达式
var pat=/[bc]at/i
2.使用构造函数创建正则表达式
注意:由于RegExp构造函数的模式参数是字符串,在某些情况下需要对字符串进行进行双重转义,所有元字符都必须双重转义,那些已经转义过的字符也同样。
二者完全等价
过目不忘JS正则表达式
正则表达式,有木有人像我一样,学了好几遍却还是很懵圈,学的时候老明白了,学完了忘光了。好吧,其实还是练的不够,所谓温故而知新,可以为师矣,今天就随我来复习一下这傲娇的正则表达式吧。
为啥要有正则表达式呢?其实就是因为计算机笨(这话不是我说的),比如123456@qq.com,我们一看就是邮箱,可是计算机不认识啊,所以我们就要用一些计算机认识的语言,来制定好规则,告诉它符合这个规则的就是个邮箱,这样计算机就能帮我们找到对应的东西了。所以正则就是用来设置规则,来完成我们需求的一些操作的,比如登录验证啦,搜索指定的东西啦等等,说太多都是多余,直接看正题吧。
定义正则:
1 var re = new RegExp(“a”); //RegExp对象。参数就是我们想要制定的规则。有一种情况必须用这种方式,下面会提到。 2 var re = /a/; // 简写方法 推荐使用 性能更好 不能为空 不然以为是注释 ,
正则的常用方法
1 test() :在字符串中查找符合正则的内容,若查找到返回true,反之返回false.
用法:正则.test(字符串)
例子:判断是否是数字

var str = '374829348791';
var re = /\D/; // \D代表非数字
if( re.test(str) ){ // 返回true,代表在字符串中找到了非数字。
alert('不全是数字');
}else{
alert('全是数字');
}
正则表达式中有很多符号,代表着不同的意思,用来让我们去定义不同的规则,比如上面\D,还有下面的这些:
\s : 空格
\S : 非空格
\d : 数字
\D : 非数字
\w : 字符 ( 字母 ,数字,下划线_ )
\W : 非字符例子:是否有不是数字的字符
(下面会根据例子,依次讲一些常用的字符,最后再作总结。)
2 search() :在字符串搜索符合正则的内容,搜索到就返回出现的位置(从0开始,如果匹配的不只是一个字母,那只会返回第一个字母的位置), 如果搜索失败就返回 -1
用法:字符串.search(正则)
在字符串中查找复合正则的内容。忽略大小写:i——ignore(正则中默认是区分大小写的 如果不区分大小写的话,在正则的最后加标识 i )
例子:在字符串中找字母b,且不区分大小写
var str = 'abcdef';
var re = /B/i;
//var re = new RegExp('B','i'); 也可以这样写
alert( str.search(re) ); // 1
3 match() 在字符串中搜索复合规则的内容,搜索成功就返回内容,格式为数组,失败就返回null。
用法: 字符串.match(正则)
量词:+ 至少出现一次 匹配不确定的次数(匹配就是搜索查找的意思)
全局匹配:g——global(正则中默认,只要搜索到复合规则的内容就会结束搜索 )
例子:找出指定格式的所有数字,如下找到 123,54,33,879
var str = 'haj123sdk54hask33dkhalsd879'; var re = /\d+/g; // 每次匹配至少一个数字 且全局匹配 如果不是全局匹配,当找到数字123,它就会停止了。就只会弹出123.加上全局匹配,就会从开始到结束一直去搜索符合规则的。如果没有加号,匹配的结果就是1,2,3,5,4,3,3,8,7,9并不是我们想要的,有了加号,每次匹配的数字就是至少一个了。 alert( str.match(re) ); // [123,54,33,879]
4 replace() :查找符合正则的字符串,就替换成对应的字符串。返回替换后的内容。
用法: 字符串.replace(正则,新的字符串/回调函数)(在回调函数中,第一个参数指的是每次匹配成功的字符)
| : 或的意思 。
例子:敏感词过滤,比如 我爱北京天安门,天安门上太阳升。------我爱*****,****上太阳升。即北京和天安门变成*号,
一开始我们可能会想到这样的方法:
var str = "我爱北京天安门,天安门上太阳升。"; var re = /北京|天安门/g; // 找到北京 或者天安门 全局匹配 var str2 = str.replace(re,'*'); alert(str2) //我爱**,*上太阳升 //这种只是把找到的变成了一个*,并不能几个字就对应几个*。
要想实现几个字对应几个*,我们可以用回调函数实现:
var str = "我爱北京天安门,天安门上太阳升。";
var re = /北京|天安门/g; // 找到北京 或者天安门 全局匹配
var str2 = str.replace(re,function(str){
alert(str); //用来测试:函数的第一个参数代表每次搜索到的符合正则的字符,所以第一次str指的是北京 第二次str是天安门 第三次str是天安门
var result = '';
for(var i=0;i<str.length;i++){
result += '*';
}
return result; //所以搜索到了几个字就返回几个*
});
alert(str2) //我爱*****,***上太阳升
//整个过程就是,找到北京,替换成了两个*,找到天安门替换成了3个*,找到天安门替换成3个*。
replace是一个很有用的方法,经常会用到。
正则中的字符
():,小括号,叫做分组符。就相当于数学里面的括号。如下:
var str = '2013-6-7'; var re1 = /\d-+/g; // 全局匹配数字,横杠,横杠数量至少为1,匹配结果为: 3- 6- var re1 = /(\d-)+/g; // 全局匹配数字,横杠,数字和横杠整体数量至少为1 3-6- var re2 = /(\d+)(-)/g; // 全局匹配至少一个数字,匹配一个横杠 匹配结果:2013- 6-
同时,正则中的每一个带小括号的项,都叫做这个正则的子项。子项在某些时候非常的有用,比如我们来看一个栗子。
例子:让2013-6-7 变成 2013.6.7
var str = '2013-6-7';
var re = /(\d+)(-)/g;
str = str.replace(re,function($0,$1,$2){
//replace()中如果有子项,
//第一个参数:$0(匹配成功后的整体结果 2013- 6-),
// 第二个参数 : $1(匹配成功的第一个分组,这里指的是\d 2013, 6)
//第三个参数 : $1(匹配成功的第二个分组,这里指的是- - - )
return $1 + '.'; //分别返回2013. 6.
});
alert( str ); //2013.6.7
//整个过程就是利用子项把2013- 6- 分别替换成了2013. 6. 最终弹出2013.6.7
match方法也会返回自己的子项,如下:
var str = 'abc'; var re = /(a)(b)(c)/; alert( str.match(re) ); //[abc,a,b,c]( 返回的是匹配结果 以及每个子项 当match不加g的时候才可以获取到子项的集合)
补充:exec()方法:和match方法一样,搜索符合规则的内容,并返回内容,格式为数组。
用法:正则.exec(字符串);
属性:input(代表要匹配的字符串)
栗子:不是全局匹配的情况:
var testStr = "now test001 test002"; var re = /test(\d+)/; //只匹配一次 var r = ""; var r = re.exec(testStr) alert(r);// test001 001 返回匹配结果,以及子项 alert(r.length); //2 返回内容的长度 alert(r.input); //now test001 test002 代表每次匹配成功的字符串 alert(r[0]); //test001 alert(r[1]); //001 代表每次匹配成功字符串中的第一个子项 (\d+) alert(r.index ); // 4 每次匹配成功的字符串中的第一个字符的位置
全局匹配:如果是全局匹配,可以通过while循环 找到每次匹配到的字符串,以及子项。每次匹配都接着上次的位置开始匹配
var testStr = "now test001 test002";
var re = /test(\d+)/g;
var r = "";
//匹配两次 每次匹配都接着上一次的位置开始匹配,一直匹配到最后r就为false,就停止匹配了 匹配到test001 test002
while(r = re.exec(testStr)){
alert(r);//返回每次匹配成功的字符串,以及子项,分别弹出 :test001 001,test002 002
alert(r.input); //分别弹出: now test001 test002 now test001 test002
alert(r[0]); //代表每次匹配成功的字符串 分别弹出: test001 test002
alert(r[1]); //代表每次匹配成功字符串中的第一个子项 (\d+) 分别弹出:001 002
alert(r.index ); // 每次匹配成功的字符串中的第一个字符的位置,分别弹出:4 12
alert(r.length); //分别弹出:2 2
}
[] : 表示某个集合中的任意一个,比如 [abc] 整体代表一个字符 匹配 a b c 中的任意一个,也可以是范围,[0-9] 范围必须从小到大 。
[^a] 整体代表一个字符 :^写在[]里面的话,就代表排除的意思
例子:匹配HTML标签 比如<div class="b">hahahah </div> 找出标签<div class="b"></div>
var re = /<[^>]+>/g; //匹配左括号 中间至少一个非右括号的内容(因为标签里面还有属性等一些东西),然后匹配右括号 var re = /<[\w\W]+>/g; //匹配左括号 中间至少一个字符或者非字符的内容,然后匹配右括号
// 其实就是找到左括号,然后中间可以有至少一个内容,一直到找到右括号就代表是一个标签。
转义字符
\s : 空格
\S : 非空格
\d : 数字
\D : 非数字
\w : 字符 ( 字母 ,数字,下划线_ )
\W : 非字符
.(点)——任意字符
\. : 真正的点
\b : 独立的部分 ( 起始,结束,空格 )
\B : 非独立的部分
关于最后两个来看个栗子:
var str = 'onetwo'; var str2 ="one two"; var re = /one\b/; // e后面必须是独立的 可以是起始,空格,或结束 alert( re.test(str) ); //false alert( re.test(str2) );//true
例子:写一个用class名获取节点的函数:
我们之前可能见过这样的函数:
function getByClass(parent,classname){
if(parent.getElementsByClassName){
return parent.getElementsByClassName(classname);
}
else{
var results = new Array();//用来存储所有取到的class为box的元素
var elems = parent.getElementsByTagName("*");
for(var i =0;i<elems.length;i++){
if(elems[i].className==classname){
results.push(elems[i]);
}
}
return results;
}
}
其实这是存在问题的,比如它如果一个标签里面有两个class,或者存在相同名字的class,比如<div class="box1 box1">,<div class="box1 box2>它就没办法获取到了,我们可以用正则来解决这个问题。
function getByClass(parent,classname){
if(parent.getElementsByClassName){
return parent.getElementsByClassName(classname);
}else{
var arr = [];
var aEle = parent.getElementsByTagName('*');
//var re = /\bclassname\b/; //不能这样写,当正则需要用到参数时候,一定要用全称的写法,简写方式会把classname当做一个字符串去匹配。
var re = new RegExp('\\b'+classname+'\\b'); // 匹配的时候,classname前面必须是起始或者空格,后面也是。 默认匹配成功就停止,所以就算有重复的也不会再匹配进去了。
//需要注意的是,全称的方式声明正则的时候,参数是字符串类型的,所以我们用的时候,需要保证这些特殊的字符在字符串内也能输出才行。\b本身是特殊字符,在字符串中无法输出,所以要加反斜杠转义才行。
for(var i=0;i<aEle.length;i++){
if( re.test(aEle[i].className) ){
arr.push( aEle[i] );
}
}
return arr;
}
}
\a 表示重复的某个子项 比如:
\1 重复的第一个子项
\2 重复的第二个子项
/ (a) (b) (c) \1/-----匹配 abca / (a) (b) (c) \2/------匹配 abcb
例子(面试题中经常问到):找重复项最多的字符个数
split():字符串中的方法,把字符串转成数组。
sort():数组中的排序方法,按照ACALL码进行排序。
join():数组中的方法,把数组转换为字符串
var str = 'assssjdssskssalsssdkjsssdss';
var arr = str.split(''); //把字符串转换为数组
str = arr.sort().join(''); //首先进行排序,这样结果会把相同的字符放在一起,然后再转换为字符串
//alert(str); // aaddjjkklsssssssssssssssss
var value = '';
var index = 0;
var re = /(\w)\1+/g; //匹配字符,且重复这个字符,重复次数至少一次。
str.replace(re,function($0,$1){
//alert($0); 代表每次匹配成功的结果 : aa dd jj kk l sssssssssssssssss
//alert($1); 代表每次匹配成功的第一个子项,也就是\w: a d j k l S
if(index<$0.length){ //如果index保存的值小于$0的长度就进行下面的操作
index = $0.length; // 这样index一直保存的就在最大的长度
value = $1; //value保存的是出现最多的这个字符
}
});
alert('最多的字符:'+value+',重复的次数:'+index); // s 17
量词:代表出现的次数
{n,m}:至少出现n次,最多m次
{n,} :至少n次
* :任意次 相当于{0,}
? :零次或一次 相当于{0,1}
+ :一次或任意次相当于 {1,}
{n}: 正好n次
例子:判断是不是QQ号
//^ : 放在正则的最开始位置,就代表起始的意思,注意 /[^a] / 和 /^[a]/是不一样的,前者是排除的意思,后者是代表首位。
//$ : 正则的最后位置 , 就代表结束的意思
//首先想QQ号的规则
1 首位不能是0
2 必须是 5-12位的数字
var aInput = document.getElementsByTagName('input');
var re = /^[1-9]\d{4,11}$/;
//123456abc为了防止出现这样的情况,所以必须限制最后
//首位是0-9,接着是4-11位的数字类型。
aInput[1].onclick = function(){
if( re.test(aInput[0].value) ){
alert('是QQ号');
}else{
alert('不是QQ号');
}
};
例子:去掉前后空格(面试题经常出现)
var str = ' hello ';
alert( '('+trim(str)+')' );//为了看出区别所以加的括号。 (hello)
function trim(str){
var re = /^\s+|\s+$/g; // |代表或者 \s代表空格 +至少一个 前面有至少一个空格 或者后面有至少一个空格 且全局匹配
return str.replace(re,''); //把空格替换成空
}
常用的一些表单校验
匹配中文:[\u4e00-\u9fa5] //中文ACALL码的范围
行首行尾空格:^\s*|\s*$ //首行出现任意个空格或者尾行出现任意个空格(任意表示也可以没有空格)
Email:^\w+@[a-z0-9]+(\.[a-z]+){1,3}$
//起始至少为一个字符(\w字母,数字或者下划线),然后匹配@,接着为任意个字母或者数字,\.代表真正的点,.后面为至少一个的字符(a-z),同时这个(比如.com)整体为一个子项作为结束,可以出现1-3次。因为有的邮箱是这样的.cn.net。(xxxx.@qq.com xxxx.@163.com xxxx.@16.cn.net )
网址:[a-zA-z]+://[^\s]* http://......
//匹配不分大小写的任意字母,接着是//,后面是非空格的任意字符
邮政编码:[1-9]\d{5} //起始数字不能为0,然后是5个数字
身份证:[1-9]\d{14}|[1-9]\d{17}|[1-9]\d{16}x
为了方便且不冲突,我们可以用json的格式 建立自己的空间,如下:
/*
var re = {
email : /^\w+@[a-z0-9]+(\.[a-z]+){1,3}$/,
number : /\d+/
};
re.email
*/
正则表达式
正则——规则、模式
一. 复习字符串操作:
字符串的位置也包括0。
- search——查找
var str='abcdef'
alert(str.search('bc'));弹出结果为1,表示字符串b出现的位置。如果查找一个不存在的字符,返回的值为-1。
- substring——获取子字符串
var str='abcdef'
alert(str.substring(1,4));得到的字符串值为bcd。注意从起始位置开始,不包括结束位置,但如果你不定义结束位置,则取值从开始到字符串结束。
- charAt——获取某个字符串
var str='abcdef'
alert(str.charAt(0));弹出结果为:a
- split——分割字符串,获得数组
var str='abc-12-u-uw'
alert(str.split('-'));得到abc,12,u,uw四个元素的数组。
以上四个方法数用的最多的操作。
二. 关于正则
你可以不用正则做任何事情,但是——
【例1】有一个字符串var str='12,87 76 -ddf ddf 89',要求把所有数字挑出来。
不用正则的情况下:
var str='12,87 76 -ddf ddf 89'
var tmp='';
var arr=[];
var i=0;
for(i=0;i<str.length;i++){
if(str.charAt(i)>='0'&&str.charAt(i)<='9'){
tmp+=str.charAt(i);
}else{
if(tmp){
arr.push(tmp);
tmp='';
}
}
}
if(tmp){
arr.push(tmp);
tmp='';
}//最后一个数加进去
alert(arr);整个过程相当麻烦。
如果用正则——
var str='12,87 76 -ddf ddf 89';
var re=/\d+/g;
alert(str.match(re));结果是一样的。
这——就是为什么用正则——大大简化了代码。
到底什么叫正则表达式
台译法为“规则表达式”。常见的各种字符串都有邮箱,网址,手机号,身份证号,qq号等。像邮箱——一串字母数字下划线@英文(数字),一串英文,.号,又一串英文。
强大的字符串匹配工具。
正则能做什么
只能操作字符串。——正常人难以读懂。
【例2】
var str='abcdef';
var re=new RegExp('a');//检测字符串是否有a——定义规则。
alert(re.test(str));//检测字符串是否符合规则,返回true正则表达式是大小写敏感的。如果要忽略大小写,应该在规则写上:var re=new RegExp('a','i');也就是用i来忽略大小写——属于javascript风格。
同理,上面的正则的简写为
var re=/a/i;一般都是采用下面的写法——Perl风格。所谓perl程序是正则的最早提出者。
现在关注一下,字符串和正则是如何配合的。
var str='abcdef';
alert(str.search(/b/));和str.search('a')的过程是完全一样的。
【例2.1】再看一个例子:
var str='asdf3 4323 fas23';
var re=/\d/;//杠d表示就是数字
alert(str.search(re));//查找首个数字出现的位置返回结果为4所谓\d表示数字。(digtal)
【例3】检测浏览器版本
检测浏览器常用userAgent方法——
alert(window.navigator.userAgent);弹出的是当前使用浏览器的类型和版本。通常是一大串字符串,比如: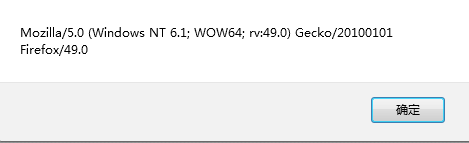
现在可以通过正则来把关键字符取出来——然后判断。
if(window.navigator.userAgent.search(/firefox/i)!=-1){
alert('这是火狐');
}else if(window.navigator.userAgent.search(/chrome/i)!=-1){
alert('这是chrome');
}else if(window.navigator.userAgent.search(/msie 9/i)!=-1){
alert('这是IE9');
}并且,你可以封装为一个函数到处去用。
三. march方法——匹配
【例4】匹配符合正则的东西,返回一个数组。
在例2.1的例子中,稍作修改
var str='asdf3 4323 fas23';
var re=/\d/g;//杠d表示就是数字
alert(str.match(re));输出结果为: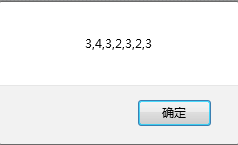
如果不加g(global)返回一个3
如果我需要一个两个连着的字符串——var re=/\d\d/g;就返回的是彼此连着的字符串组。但是,不连着的就被过滤掉了。
+号表示量词——衡量东西的数量,“许多”的意思。var re=/\d+/g;表示多个数字
修改之后: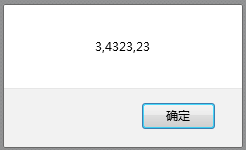
所有的数字都出来了。
四. replace——用来替换
【例5】
replace本身是一个字符串的操作:
var str='abcdef';
alert(str.replace('a','A'));在上面的demo中str内的第一个小写a被替换为大写的'A'.正是因为第一个,成为了此方法的最大缺陷。
这个问题很好解决,结合正则应用就可以了:
var str='abacAdef';
alert(str.replace(/a/g,'T'));输出TbTcAdef。还是不完善——如果想把A也改为T——只需要把正则写成:alert(str.replace(/a/gi,'T'));,就完美解决了问题。
【例5.1】应用——敏感词过滤
<textarea id="txt1" row="10" cols="40"></textarea><br>
<input id="btn1" type="button" value="过滤"><br>
<textarea id="txt2" row="10" cols="40"></textarea>现在要求在txt1上输入,点击过滤之后,输入文本的三国杀敏感词变为**。
window.onload=function(){
var oTxt1=document.getElementById('txt1');
var oTxt2=document.getElementById('txt2');
var oBtn=document.getElementById('btn1');
oBtn.onclick=function(){
var re=/忠臣|反贼|内奸/g;
oTxt2.value=oTxt1.value.replace(re,'**');
}
}
竖线|的作用:就是或者的意思。
五. 字符类
【例6】
字符类就是方括号
var re=/1[abc]2/;表示出现在1,2之间出现的任何a,b,c。等效于/1a2|1b2|1c2/
例5.1中,如果把正则写为:var re=/f[uc]k/g;在文本框输入测试文字fuck,效果为:***k
结论——但凡出现在方括号内的都表示或者。
另外一个用法
[0-9]表示所有数字
[a-z]表示所有小写字母
[0-9a-z]表示数字+小写字母
[^a]表示取反,除了a以外什么都可以。只要不是a
结合应用
[^0-9a-z]就表示特殊字符
【例6.1】偷小说——应用
采集器的原理:采集过来的实际上是一堆html代码。代码不能直接塞到网站中。因此需要过滤里面的标签。
比如“霸道总裁”系列:
<h1 >霸道总裁爱上我</h1>
<a href="[javascript:;](javascript:;)" class="edit-lemma cmn-btn-hover-blue cmn-btn-28 j-edit-link"><em class="cmn-icon wiki-lemma-icons wiki-lemma-icons_edit-lemma"></em>编辑</a>
<a class="lock-lemma" target="_blank" href="[/view/10812319.htm](http://baike.baidu.com/view/10812319.htm)" title="锁定"><em class="cmn-icon wiki-lemma-icons wiki-lemma-icons_lock-lemma"></em>锁定</a>
</dd>
</dl><div class="promotion-declaration">
</div><div class="lemma-summary" label-module="lemmaSummary">
<div class="para" label-module="para">几年前,他无助时,她救了他,他那时候觉得她只是对她有一点好感,却不知道,自己已经已经陷入爱情的深渊,他爱上了她,几年后,她在闺蜜榕衫介绍的工作下,无意中当上了他的女仆,他发现了,她就是几年前的她…… (本故事及人物纯属虚构,如有雷同,纯属巧合,切勿模仿。)</div>需要把html标签过滤掉。
转换器设置和例5.1的html一样,写入如下代码
window.onload=function(){
var oTxt1=document.getElementById('txt1');
var oTxt2=document.getElementById('txt2');
var oBtn=document.getElementById('btn1');
oBtn.onclick=function(){
var re=/<.+>/g;
oTxt2.value=oTxt1.value.replace(re,'');
}
}var re=/<.+>/g;中,.表示匹配尖括号内所有的内容。按理来说所有的都应该被匹配了。然而——转换结果一片空白。
正则的特点在于——贪婪。在解析过程中只认尽可能长的代码段,因此把中间的尖括号全部都算入替代中了。必须重新考虑规则。
实际上在html标签内唯独不可能出现左右尖括号本身。一次正则改为:var re=/<[^<>]+>/g,就没问题了。
\w——word包括数字英文字母和下划线\s——space包括空格。
比如:去除所有字符内的空格:
var str='das aasvg dvf d d2 2';
alert(str.replace(/\s+/g,''));大写字母:——也是是取反,不过是比较高级的取反。
\D代表[^0-9]\W代表[^a-z0-9]\S代表除了空格字符以外的所有东西
六. 量词
什么是量词:一个东西出现的次数。现在进一步深入了解下。
基本用法:{n,m}——至少出现n次,最多m次。
常用量词
{n,}至少n次,最多不限制。{,m}做多m次,最少不限{n}恰好n次。
【例6.2】案例:查找QQ号。
qq号的位数——5-11,第一位不能是0.
var str='我的qq号是:123456789;你的是:123456;他的是1234567吗?';
var re=/[1-9]\d{4,10}/g;
//表示:必须1-9开头,后面为数字且最少出现4次,最多出现10次
alert(str.match(re));输出的是三个qq号的数组。
*任意次数{0,}——可以出现也可以不出现,不建议使用,用+号就好。?0次或1次{0,1}——可以出现也可以不出现。出现的话只能出现1次。+1次或任意次——实际意思是只要出现就被全部逮着。
七. 实例分析:常用正则表达式的应用
【例7】邮箱校验
邮箱规则是:
第一部分用户名(字母,数字,下划线)——\w+
第二部分为@
第三部分是既能是域名可以是英文数字——但不能是下划线——[a-z,0-9]+
第四部分是.,但.本身是有特殊含义的,表示任意字符。所以必须转义——用\.来替代。
第四部分为一串英文,长度-4位
按部就班来写:
var str='asads@asda.xxx';
var re=/\w+@[a-z0-9]+\.[a-z]{2,4}/g;
alert(re.test(str));如果返回的结果为false,表示str不符合email的正则表达式。但是这样写有两个问题:
(1)当用户名有中文时,校验居然可以通过
(2)当域名多于4位时,校验还是能够通过。
首先,正则含义表示当前字符串部分符合,验证就被通过了。
因此,需要引入行首和行尾的概念。
之前说过,方括号内的^表示取反,但是在方括号之外,就是行首的意思。另一方面$表示行尾。因此把正则写成:
var re=/^\w+@[a-z0-9]+\.[a-z]{2,4}$/就算完成了。
校验必须加行首行尾。
【例7.1】去除首尾空格
用户在输入字符串时总是不小心输入到前面有空格。可以通过首尾来验证这段错误的字符串。
var str=' sssd asd ds ';
var re=/^\s+/;//把左边的空格(任意个)选中了。
alert('('+str.replace(re,'')+')');如果我想行首行尾一块用呢?
注意$的写法——写在右边,:
var re=/^\s+|\s$/g;两边的空格被去掉了。中段的空格被保留。
【例8】中文校验——[\u4e00-\u9fa5]
在婚恋类网站中,经常要求用户名必须是中文。
怎么理解[\u4e00-\u9fa5]:网页都是UTF-8编码的。\u代表汉字。这里是一个范围,表示从utf-8编码的第一个汉字到最后一个utf-8编码的汉字。可以在在线utf-8编码转换器上测试,\u加上转出来的最后四位就是这个汉字的正则表达式。
var str='sad葡萄asd';
var re=/[\u4e00-\u9fa5]/;
alert(re.test(str));返回为true。
【例9】原生javascript的class选择器——getByClass
原版的getByClass思想是:传入一个父级的参数,然后遍历所有父级内的元素,当className值为目标的class名时,push到数组中。
function getByClass(oParent,sClass){
var aEle=oParent.getElementsByTagName('*');//选择父元素的所有标签
var aResult=[];
var i=0;
for(i=0;i<aEle.length;i++){
if(aEle[i].className==sClass){
aResult.push(aEle[i]);
}
}
return aResult;
}有什么局限性呢?有时候布局时,存在两个class同时存在于一个标签时,这个class就不能被被选中。必须使用字符串方法,判断这个标签的className包不包含class。
思路
(1)一个不靠谱的办法是用search方法:
function getByClass(oParent,sClass){
var aEle=oParent.getElementsByTagName('*');//选择父元素的所有标签
var aResult=[];
var i=0;
for(i=0;i<aEle.length;i++){
if(aEle[i].className.search(sClass)!=-1){
aResult.push(aEle[i]);
}
}
return aResult;
}(2)另一个不靠谱的办法如下
然而,只是看到了包含的一面,却没有考虑诸如从<a class="btn default">搜寻.btn这样的情形。严格的方法需要用到单词边界(\b)来实现。
什么是单词边界呢?单词之间是由空格,标点等区分开的。这个元素称为单词边界。
var re=new RegExp('\\b'+sClass+'\\b');表示sClass是一个单独的单词。为什么是'\\b'呢,因为还有一个是转义的\。
所以完美版的class选择器是:
function getByClass(oParent,sClass){
var aEle=oParent.getElementsByTagName('*');//选择父元素的所有标签
var aResult=[];
var re=new RegExp('\\b'+sClass+'\\b','i');
var i=0;
for(i=0;i<aEle.length;i++){
if(re.test(aEle[i].className)){
aResult.push(aEle[i]);
}
}
return aResult;
}结果还是有问题:先在获取到的className值两边加上空格,这样就保证了className里的每个值两边都会有空格,然后再用正则去匹配。
function getByClass(oParent, sClass){
if(oParent.getElementsByClassName){
return oParent.getElementsByClassName(sClass);
}else{
var res=[];
var re=new RegExp(' '+sClass+' ','i')
var aEle=oParent.getElementsByTagName('*');
for(var i=0; i<aEle.length; i++){
if(re.test(' '+aEle[i].className+' ')){
res.push(aEle[i]);
}
}
return res;
}
}总结:
- 字符串的基本操作:重点的4个——search(查找首个字符串出现的位置),substring(获取子字符串),charAt(定位获取字符串的一部分),split(按照一定的规则切割字符串)
- 正则表达式是把字符串规则告诉计算机的表达形式。创建正则对象有两种方法:javascript风格和perl风格。
正则的选项:一个是i——忽略大小写,g——是搜索全部 - search依旧是查找,match是挑选匹配,replace是替换符合规则的字符串
- 字符类:[abc]——任意字符;范围[a-z],[0-9];在方括号内有
^表示取反排除。 - 转义字符——
.代表所有的字符,\d表示左右数字,\s表示空格。当使用大写的时候,表示取反。 - 量词——出现的次数,最普通是
{n,m}最少n最多m次。 - 正则的例子——邮箱中文,qq号等。
常用rules校验规则
1、是否合法IP地址
export function validateIP(rule, value,callback) {
if(value==''||value==undefined||value==null){
callback();
}else {
const reg = /^(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\
.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])\.(\d{1,2}|1\d\d|2[0-4]\d|25[0-5])$/;
if ((!reg.test(value)) && value != '') {
callback(new Error('请输入正确的IP地址'));
} else {
callback();
}
}
}
复制代码2、是否手机号码或者固话
export function validatePhoneTwo(rule, value, callback) {
const reg = /^((0\d{2,3}-\d{7,8})|(1[34578]\d{9}))$/;;
if (value == '' || value == undefined || value == null) {
callback();
} else {
if ((!reg.test(value)) && value != '') {
callback(new Error('请输入正确的电话号码或者固话号码'));
} else {
callback();
}
}
}
复制代码3、是否固话
export function validateTelphone(rule, value,callback) {
const reg =/0\d{2,3}-\d{7,8}/;
if(value==''||value==undefined||value==null){
callback();
}else {
if ((!reg.test(value)) && value != '') {
callback(new Error('请输入正确的固定电话)'));
} else {
callback();
}
}
}
复制代码4、是否手机号码
export function validatePhone(rule, value,callback) {
const reg =/^[1][3-9][0-9]{9}$/;
if(value==''||value==undefined||value==null){
callback();
}else {
if ((!reg.test(value)) && value != '') {
callback(new Error('请输入正确的电话号码'));
} else {
callback();
}
}
}
复制代码5、是否身份证号码
export function validateIdNo(rule, value,callback) {
const reg = /(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)/;
if(value==''||value==undefined||value==null){
callback();
}else {
if ((!reg.test(value)) && value != '') {
callback(new Error('请输入正确的身份证号码'));
} else {
callback();
}
}
}
复制代码6、是否邮箱
export function validateEMail(rule, value,callback) {
const reg =/^([a-zA-Z0-9]+[-_\.]?)+@[a-zA-Z0-9]+\.[a-z]+$/;
if(value==''||value==undefined||value==null){
callback();
}else{
if (!reg.test(value)){
callback(new Error('请输入正确的邮箱'));
} else {
callback();
}
}
}
复制代码7、合法url
export function validateURL(url) {
const urlregex = /^(https?|ftp):\/\/([a-zA-Z0-9.-]+(:[a-zA-Z0-9.&%$-]+)*@)*((25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9][0-9]?)(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3}|([a-zA-Z0-9-]+\.)*[a-zA-Z0-9-]+\.(com|edu|gov|int|mil|net|org|biz|arpa|info|name|pro|aero|coop|museum|[a-zA-Z]{2}))(:[0-9]+)*(\/($|[a-zA-Z0-9.,?'\\+&%$#=~_-]+))*$/;
return urlregex.test(url);
}
复制代码8、验证内容是否包含英文数字以及下划线
export function isPassword(rule, value, callback) {
const reg =/^[_a-zA-Z0-9]+$/;
if(value==''||value==undefined||value==null){
callback();
} else {
if (!reg.test(value)){
callback(new Error('仅由英文字母,数字以及下划线组成'));
} else {
callback();
}
}
}
复制代码9、自动检验数值的范围
export function checkMax20000(rule, value, callback) {
if (value == '' || value == undefined || value == null) {
callback();
} else if (!Number(value)) {
callback(new Error('请输入[1,20000]之间的数字'));
} else if (value < 1 || value > 20000) {
callback(new Error('请输入[1,20000]之间的数字'));
} else {
callback();
}
}
复制代码10、验证数字输入框最大数值
export function checkMaxVal(rule, value,callback) {
if (value < 0 || value > 最大值) {
callback(new Error('请输入[0,最大值]之间的数字'));
} else {
callback();
}
}
复制代码11、验证是否1-99之间
export function isOneToNinetyNine(rule, value, callback) {
if (!value) {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入正整数'));
} else {
const re = /^[1-9][0-9]{0,1}$/;
const rsCheck = re.test(value);
if (!rsCheck) {
callback(new Error('请输入正整数,值为【1,99】'));
} else {
callback();
}
}
}, 0);
}
复制代码12、验证是否整数
export function isInteger(rule, value, callback) {
if (!value) {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入正整数'));
} else {
const re = /^[0-9]*[1-9][0-9]*$/;
const rsCheck = re.test(value);
if (!rsCheck) {
callback(new Error('请输入正整数'));
} else {
callback();
}
}
}, 0);
}
复制代码13、验证是否整数,非必填
export function isIntegerNotMust(rule, value, callback) {
if (!value) {
callback();
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入正整数'));
} else {
const re = /^[0-9]*[1-9][0-9]*$/;
const rsCheck = re.test(value);
if (!rsCheck) {
callback(new Error('请输入正整数'));
} else {
callback();
}
}
}, 1000);
}
复制代码14、 验证是否是[0-1]的小数
export function isDecimal(rule, value, callback) {
if (!value) {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入[0,1]之间的数字'));
} else {
if (value < 0 || value > 1) {
callback(new Error('请输入[0,1]之间的数字'));
} else {
callback();
}
}
}, 100);
}
复制代码15、 验证是否是[1-10]的小数,即不可以等于0
export function isBtnOneToTen(rule, value, callback) {
if (typeof value == 'undefined') {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入正整数,值为[1,10]'));
} else {
if (!(value == '1' || value == '2' || value == '3' || value == '4' || value == '5' || value == '6' || value == '7' || value == '8' || value == '9' || value == '10')) {
callback(new Error('请输入正整数,值为[1,10]'));
} else {
callback();
}
}
}, 100);
}
复制代码16、验证是否是[1-100]的小数,即不可以等于0
export function isBtnOneToHundred(rule, value, callback) {
if (!value) {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入整数,值为[1,100]'));
} else {
if (value < 1 || value > 100) {
callback(new Error('请输入整数,值为[1,100]'));
} else {
callback();
}
}
}, 100);
}
复制代码17、验证是否是[0-100]的小数
export function isBtnZeroToHundred(rule, value, callback) {
if (!value) {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (!Number(value)) {
callback(new Error('请输入[1,100]之间的数字'));
} else {
if (value < 0 || value > 100) {
callback(new Error('请输入[1,100]之间的数字'));
} else {
callback();
}
}
}, 100);
}
复制代码18、验证端口是否在[0,65535]之间
export function isPort(rule, value, callback) {
if (!value) {
return callback(new Error('输入不可以为空'));
}
setTimeout(() => {
if (value == '' || typeof(value) == undefined) {
callback(new Error('请输入端口值'));
} else {
const re = /^([0-9]|[1-9]\d|[1-9]\d{2}|[1-9]\d{3}|[1-5]\d{4}|6[0-4]\d{3}|65[0-4]\d{2}|655[0-2]\d|6553[0-5])$/;
const rsCheck = re.test(value);
if (!rsCheck) {
callback(new Error('请输入在[0-65535]之间的端口值'));
} else {
callback();
}
}
}, 100);
}
复制代码19、验证端口是否在[0,65535]之间,非必填,isMust表示是否必填
export function isCheckPort(rule, value, callback) {
if (!value) {
callback();
}
setTimeout(() => {
if (value == '' || typeof(value) == undefined) {
//callback(new Error('请输入端口值'));
} else {
const re = /^([0-9]|[1-9]\d|[1-9]\d{2}|[1-9]\d{3}|[1-5]\d{4}|6[0-4]\d{3}|65[0-4]\d{2}|655[0-2]\d|6553[0-5])$/;
const rsCheck = re.test(value);
if (!rsCheck) {
callback(new Error('请输入在[0-65535]之间的端口值'));
} else {
callback();
}
}
}, 100);
}
复制代码20、小写字母
export function validateLowerCase(val) {
const reg = /^[a-z]+$/;
return reg.test(val);
}
复制代码22、两位小数验证
const validateValidity = (rule, value, callback) => {
if (!/(^[1-9]([0-9]+)?(\.[0-9]{1,2})?$)|(^(0){1}$)|(^[0-9]\.[0-9]([0-9])?$)/.test(value)) {
callback(new Error('最多两位小数!!!'));
} else {
callback();
}
};
复制代码23、是否大写字母
export function validateUpperCase(val) {
const reg = /^[A-Z]+$/;
return reg.test(val);
}
复制代码24、是否大小写字母
export function validatAlphabets(val) {
const reg = /^[A-Za-z]+$/;
return reg.test(val);
}
复制代码25、密码校验
export const validatePsdReg = (rule, value, callback) => {
if (!value) {
return callback(new Error('请输入密码'))
}
if (!/^(?![\d]+$)(?![a-zA-Z]+$)(?![^\da-zA-Z]+$)([^\u4e00-\u9fa5\s]){6,20}$/.test(value)) {
callback(new Error('请输入6-20位英文字母、数字或者符号(除空格),且字母、数字和标点符号至少包含两种'))
} else {
callback()
}
}
复制代码26、中文校验
export const validateContacts = (rule, value, callback) => {
if (!value) {
return callback(new Error('请输入中文'))
}
if (!/^[\u0391-\uFFE5A-Za-z]+$/.test(value)) {
callback(new Error('不可输入特殊字符'))
} else {
callback()
}
}
复制代码27、 账号校验
export const validateCode = (rule, value, callback) => {
if (!value) {
return callback(new Error('请输入账号'))
}
if (!/^(?![0-9]*$)(?![a-zA-Z]*$)[a-zA-Z0-9]{6,20}$/.test(value)) {
callback(new Error('账号必须为6-20位字母和数字组合'))
} else {
callback()
}
}
复制代码28 、纯数字校验
export const validateNumber = (rule, value, callback) => {
let numberReg = /^\d+$|^\d+[.]?\d+$/
if (value !== '') {
if (!numberReg.test(value)) {
callback(new Error('请输入数字'))
} else {
callback()
}
} else {
callback(new Error('请输入值'))
}
}
复制代码29、最多一位小数
const onePoint = (rule, value, callback) => {
if (!/^[0-9]+([.]{1}[0-9]{1})?$/.test(value)) {
callback(new Error('最多一位小数!!!'));
} else {
callback();
}
};
复制代码使用方法:
在使用地方直接 import 引入,然后在 rules 校验中加入即可。
