

转载:JavaScript线程机制与事件机制
引子
本文介绍JavaScript运行机制,这一部分比较抽象,我们先从一道面试题入手:
console.log(1); setTimeout(function(){ console.log(3); },0); console.log(2);
请问数字打印顺序是什么?题目的答案是依次输出1 2 3
再看一道题
<div class="test">测试内容</div>
<script>
$('.test').text('内容改变')
alert($('.test').text())
// 页面加载后首先时alert弹出,alert的内容为 ‘内容改变’,而dom此时还未发生变化,dom的内容是‘测试内容’
// 然后会一直堵塞,直到我们点击确认,alert消失时,页面内容才会变成‘内容改变’
// 所以alert prompt confirm等提示框都会跳过页面渲染先执行
</script>
解决这个问题之前先了解一下它是怎么导致的,而要了解它需要从 JavaScript 的线程模型说起。
JavaScript 引擎是单线程运行的,浏览器无论在什么时候都只且只有一个线程在运行 JavaScript 程序,初衷是为了减少 DOM 等共享资源的冲突。可是单线程永远会面临着一个问题,那就是某一段代码阻塞会导致后续所有的任务都延迟。又由于 JavaScript 经常需要操作页面 DOM 和发送 HTTP 请求,这些 I/O 操作耗时一般都比较长,一旦阻塞,就会给用户非常差的使用体验。
于是便有了事件循环(event loop)的产生,JavaScript 将一些异步操作或 有I/O 阻塞的操作全都放到一个事件队列,先顺序执行同步 CPU代码,等到 JavaScript 引擎没有同步代码,CPU 空闲下来再读取事件队列的异步事件来依次执行。
这些事件包括:
setTimeout()设置的异步延迟事件;- DOM 操作相关如布局和绘制事件;
- 网络 I/O 如 AJAX 请求事件;
- 用户操作事件,如鼠标点击、键盘敲击。
明白了原理, 再解决这个问题就有了方向,我们来分析这个问题:
- 由于页面渲染是 DOM 操作,会被 JavaScript 引擎放入事件队列;
alert()是 window 的内置函数,被认为是同步 CPU代码;- JavaScript 引擎会优先执行同步代码,alert 弹窗先出现;
- alert 有特殊的阻塞性质,JavaScript 引擎的执行被阻塞住;
- 点击 alert 的“确定”,JavaScript 没有了阻塞,执行完同步代码后,又读取事件队列里的 DOM 操作,页面渲染完成。
由上述原因,导致了诡异的 “Alert执行顺序问题”。 我们无法将页面渲染变成同步操作,那么只好把 alert() 变为异步代码,从而才能在页面渲染之后执行。
解决方法:
setTimeout() 使用它,可以延迟执行某些代码。而对于延迟执行的代码,JavaScript 引擎总是把这些代码放到事件队列里去,再去检查是否已经到了执行时间,再适时执行。代码进入事件队列,就意味着代码变成和页面渲染事件一样异步了。由于事件队列是有序的,我们如果用 setTimeout 延时执行,就可以实现在页面渲染之后执行 alert 的功能了。
setTimeout 的函数原型为 setTimeout(code, msec),code 是要变为异步的代码或函数,msec 是要延时的时间,单位为毫秒。这里我们不需要它延时,只需要它变为异步就行了,所以可以将 msec 设置为 0;
<div class="test">测试内容</div>
<script>
$('.test').text('内容改变')
setTimeout(function(){
alert($('.test').text())
},0)
// 由于使用setTimeout操作,使alert被放入到事件队列 ,
// 同时 $('.test').text('内容改变')也是在事件队列
// 所以 dom和alert的内容都是 ‘内容改变’
下面重点介绍下JavaScript线程机制与事件机制

一、进程与线程
1.进程
进程是指程序的一次执行,它占有一片独有的内存空间,可以通过windows任务管理器查看进程(如下图)。同一个时间里,同一个计算机系统中允许两个或两个以上的进程处于并行状态,这是多进程。比如电脑同时运行微信,QQ,以及各种浏览器等。浏览器运行是有些是单进程,如firefox和老版IE,有些是多进程,如chrome和新版IE。
2.线程
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
线程是指CPU的基本调度单位,是程序执行的一个完整流程,是进程内的一个独立执行单元。多线程是指在一个进程内, 同时有多个线程运行。浏览器运行是多线程。比如用浏览器一边下载,一边听歌,一边看视频。另外我们需要知道JavaScript语言的一大特点就是单线程,为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
由于每个进程至少要干一件事,所以,一个进程至少有一个线程。当然,像Word这种复杂的进程可以有多个线程,多个线程可以同时执行,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。当然,真正地同时执行多线程需要多核CPU才可能实现。
3.进程与线程
-
应用程序必须运行在某个进程的某个线程上
-
一个进程中至少有一个运行的线程: 主线程, 进程启动后自动创建
-
一个进程中如果同时运行多个线程, 那这个程序是多线程运行的
-
一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
-
多个进程之间的数据是不能直接共享的
用官方术语描述:
进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)
线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
进程和线程可以形象比喻为:
进程是一个工厂,工厂有它的独立资源-工厂之间相互独立-线程是工厂中的工人,多个工人协作完成任务-工厂内有一个或多个工人-工人之间共享空间
线程和进程区分不清,是很多新手都会犯的错误,没有关系。这很正常。先看看下面这个形象的比喻:
- 进程是一个工厂,工厂有它的独立资源
- 工厂之间相互独立
- 线程是工厂中的工人,多个工人协作完成任务
- 工厂内有一个或多个工人
- 工人之间共享空间再完善完善概念:
- 工厂的资源 -> 系统分配的内存(独立的一块内存)
- 工厂之间的相互独立 -> 进程之间相互独立
- 多个工人协作完成任务 -> 多个线程在进程中协作完成任务
- 工厂内有一个或多个工人 -> 一个进程由一个或多个线程组成
- 工人之间共享空间 -> 同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)然后再巩固下:
如果是windows电脑中,可以打开任务管理器,可以看到有一个后台进程列表。对,那里就是查看进程的地方,而且可以看到每个进程的内存资源信息以及cpu占有率。

所以,应该更容易理解了:进程是cpu资源分配的最小单位(系统会给它分配内存)
最后,再用较为官方的术语描述一遍:
- 进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)
- 线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
tips
- 不同进程之间也可以通信,不过代价较大
- 现在,一般通用的叫法:单线程与多线程,都是指在一个进程内的单和多。(所以核心还是得属于一个进程才行)
4.单线程与多线程的优缺点?
单线程的优点:顺序编程简单易懂
单线程的缺点:效率低
多线程的优点:能有效提升CPU的利用率
多线程的缺点:
- 创建多线程开销
- 线程间切换开销
- 死锁与状态同步问题
二、浏览器内核
浏览器的内核是指支持浏览器运行的最核心的程序,分为两个部分的,一是渲染引擎,另一个是JS引擎。现在JS引擎比较独立,内核更加倾向于说渲染引擎。
1.不同的浏览器可能不太一样
- Chrome, Safari: webkit
- firefox: Gecko
- IE: Trident
- 360,搜狗等国内浏览器: Trident + webkit
2.内核由很多模块组成
- html,css文档解析模块 : 负责页面文本的解析
- dom/css模块 : 负责dom/css在内存中的相关处理
- 布局和渲染模块 : 负责页面的布局和效果的绘制
- 定时器模块 : 负责定时器的管理
- 网络请求模块 : 负责服务器请求(常规/Ajax)
- 事件响应模块 : 负责事件的管理
3.浏览器是多线程
虽然JS运行在浏览器中,是单线程的,每个window一个JS线程,但浏览器不是单线程的,例如Webkit或是Gecko引擎,都可能有如下线程:
- javascript引擎线程
- 界面渲染线程
- 浏览器事件触发线程
- Http请求线程
很多童鞋搞不清,如果js是单线程的,那么谁去轮询大的Event loop事件队列?答案是浏览器会有单独的线程去处理这个队列。
重点是浏览器内核(渲染进程)
重点来了,我们可以看到,上面提到了这么多的进程,那么,对于普通的前端操作来说,最终要的是什么呢?答案是渲染进程
可以这样理解,页面的渲染,JS的执行,事件的循环,都在这个进程内进行。接下来重点分析这个进程
请牢记,浏览器的渲染进程是多线程的(这点如果不理解,请回头看进程和线程的区分)
终于到了线程这个概念了?,好亲切。那么接下来看看它都包含了哪些线程(列举一些主要常驻线程):
-
GUI渲染线程
- 负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
- 注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
-
JS引擎线程
- 也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎)
- JS引擎线程负责解析Javascript脚本,运行代码。
- JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
- 同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
-
事件触发线程
- 归属于浏览器而不是JS引擎,用来控制事件循环(可以理解,JS引擎自己都忙不过来,需要浏览器另开线程协助)
- 当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
-
注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
-
定时触发器线程
- 传说中的
setInterval与setTimeout所在线程 - 浏览器定时计数器并不是由JavaScript引擎计数的,(因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
- 注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
- 传说中的
-
异步http请求线程
- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。
三、定时器引发的思考
1. 定时器真是定时执行的吗?
我们先来看个例子,试问定时器会保证200ms后执行吗?
document.getElementById('btn').onclick = function () {
var start = Date.now()
console.log('启动定时器前...')
setTimeout(function () {
console.log('定时器执行了', Date.now() - start)
}, 200)
console.log('启动定时器后...')
// 做一个长时间的工作
for (var i = 0; i < 1000000000; i++) {
}
}
事实上,经过了625ms后定时器才执行。定时器并不能保证真正定时执行,一般会延迟一丁点,也有可能延迟很长时间(比如上面的例子)
2.定时器回调函数是在分线程执行的吗?
定时器回调函数在主线程执行的, 具体实现方式下文会介绍。
四、浏览器的事件循环(轮询)模型
1. 为什么JavaScript是单线程
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。即单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
2.Event Loop
JavaScript语言的设计者意识到单线程意味着排队,同一时间只能做一件事,所以将所有任务分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)如各种浏览器事件、定时器和Ajax等。
同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;
例如:
console.log("A"); while(true){ } console.log("B"); 请问最后的输出结果是什么?如果你的回答是A,恭喜你答对了,因为这是同步任务,程序由上到下执行,遇到while()死循环,下面语句就没办法执行。
异步任务指的是,不进入主线程、而进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
例如:
console.log("A"); setTimeout(function(){ console.log("B"); },0); while(true){} 请问最后的输出结果是什么?如果你的答案是A,恭喜你现在对js运行机制已经有个粗浅的认识了!题目中的setTimeout()就是个异步任务。在所有同步任务执行完之前,任何的异步任务是不会执行的
具体来说,异步执行的运行机制如下。(同步执行也是如此,因为它可以被视为没有异步任务的异步执行。)
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步
ps:
js执行栈又可称事件循环:(事件循环是指主线程重复从消息队列中取消息、执行的过程)
js任务队列又可称消息队列(消息队列是一个先进先出的队列,它里面存放着各种消息,消息可简单理解为回调函数)
主线程从"任务队列"中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)
一般来说,有以下四种会放入异步任务队列:
1.setTimeout()设置的异步延迟事件;2.DOM 操作相关如布局和绘制事件;
3.网络 I/O 如 AJAX 请求事件;
4.用户操作事件,如鼠标点击、键盘敲击。
上图Event Loop大致描述就是:
- 主线程运行时会产生执行栈,栈中的代码调用某些api时,它们会在事件队列中添加各种事件(当满足触发条件后,如ajax请求完毕)
- 而栈中的代码执行完毕,就会读取事件队列中的事件,去执行那些回调
- 如此循环
- 注意,总是要等待栈中的代码执行完毕后才会去读取事件队列中的事件
下面这个例子很好阐释事件循环:
setTimeout(function () {
console.log('timeout 2222')
alert('22222222')
}, 2000)
setTimeout(function () {
console.log('timeout 1111')
alert('1111111')
}, 1000)
setTimeout(function () {
console.log('timeout() 00000')
}, 0)//当指定的值小于 4 毫秒,则增加到 4ms(4ms 是 HTML5 标准指定的,对于 2010 年及之前的浏览器则是 10ms)
function fn() {
console.log('fn()')
}
fn()
console.log('alert()之前')
alert('------') //暂停当前主线程的执行, 同时暂停计时, 点击确定后, 恢复程序执行和计时
console.log('alert()之后')
有两点我们需要注意下:
- 定时器零延迟(setTimeout(func, 0))并不是意味着回调函数立刻执行。至少4ms,才会执行回调函数。它取决于主线程当前是否空闲与“任务队列”里其前面正在等待的任务。
- 只有在到达指定时间时,定时器就会将相应回调函数插入“任务队列”尾部
总结:异步任务(各种浏览器事件、定时器和Ajax等)都是先添加到“任务队列”(定时器则到达其指定参数时)。当 Stack 栈(JavaScript 主线程)为空时,就会读取 Queue 队列(任务队列)的第一个任务(队首),最后执行。
补充1:
放入异步任务队列的时机,我们通过 setTimeout的例子来详细说明:
<script>
for(var i=0;i<5;i++){
setTimeout(function(){
console.log(i)
},1000)
} //结果输出5个5
</script>
for循环一次碰到一个 setTimeout(),并不是马上把setTimeout()拿到异步队列中,而要等到一秒后,才将其放到任务队列里面,一旦"执行栈"中的所有同步任务执行完毕(即for循环结束,此时i已经为5),系统就会读取已经存放"任务队列"的setTimeout()(有五个),于是答案是输出5个5。
因为 for 循环会先执行完(同步优先于异步优先于回调),这时五个 setTimeout 的回调全部塞入了事件队列中,然后 1 秒后一起执行了。
因为 setTimeout 的 console.log(i); 的i是 var 定义的,所以是函数级的作用域,不属于 for 循环体,属于 global。等到 for 循环结束,i 已经等于 5 了,这个时候再执行 setTimeout 的五个回调函数(参考上面对事件机制的阐述),里面的 console.log(i); 的 i 去向上找作用域,只能找到 global下 的 i,即 5。所以输出都是 5。
解决办法:人为给 console.log(i); 创造作用域,保存i的值。
解决方法1:使用let
<script>
for(let i=0;i<5;i++){
setTimeout(function(){
console.log(i)
},1000)
}
</script>
let 为代码块的作用域,所以每一次 for 循环,console.log(i); 都引用到 for 代码块作用域下的i,因为这样被引用,所以 for 循环结束后,这些作用域在 setTimeout 未执行前都不会被释放。
解决方法2:使用立即执行函数
<script>
for(var i=0;i<5;i++){
(function(i){
setTimeout(function(){
console.log(i)
},1000)
})(i)
}
</script>
里用到立刻执行函数。这样 console.log(i); 中的i就保存在每一次循环生成的立刻执行函数中的作用域里了。
解决方法3:闭包
for(var i = 1;i < 5;i++){
var a = function(){
var j = i;
setTimeout(function(){
console.log(j);
},1000)
}
a();
}
补充2:
以异步AJAX为例,说明Event loop执行机制
假设存在如下的代码
$.ajax('http://segmentfault.com', function(resp) {
console.log('我是响应:', resp);
});
// 其他代码
...
...
...
那么,
再次:
主线程在发起AJAX请求后,会继续执行其他代码。AJAX线程负责请求segmentfault.com,拿到响应后,它会把响应封装成一个JavaScript对象,往任务队列里添加一个事件:
// 任务队列中的事件可想象成函数
var message = function () {
callbackFn(response);
}其中的callbackFn就是前面代码中得到成功响应时的回调函数。主线程在执行完当前循环中的所有代码后,就会到任务队列取出这个事件(也就是message函数),并执行它。到此为止,就完成了工作线程对主线程的通知,回调函数也就得到了执行。
用图表示这个过程就是:

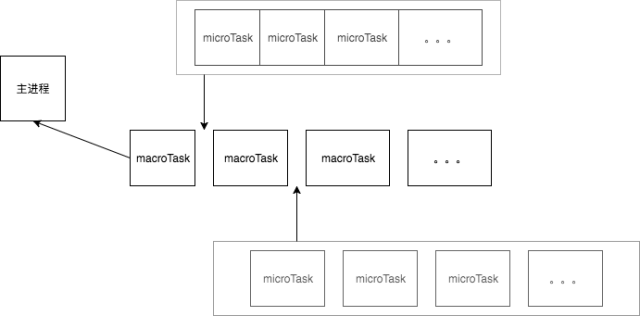
五、微任务(Microtask)与宏任务(Macrotask)
我们上面提到异步任务分为宏任务和微任务,宏任务队列可以有多个,微任务队列只有一个。
- 宏任务包括:script(全局任务), setTimeout, setInterval, setImmediate, I/O, UI rendering。
- 微任务包括: new Promise().then(回调), process.nextTick, Object.observe(已废弃), MutationObserver(html5新特性)
当执行栈中的所有同步任务执行完毕时,是先执行宏任务还是微任务呢?
- 由于执行代码入口都是全局任务 script,而全局任务属于宏任务,所以当栈为空,同步任务任务执行完毕时,会先执行微任务队列里的任务。
- 微任务队列里的任务全部执行完毕后,会读取宏任务队列中拍最前的任务。
- 执行宏任务的过程中,遇到微任务,依次加入微任务队列。
- 栈空后,再次读取微任务队列里的任务,依次类推。

一句话概括上面的流程图:当某个宏任务队列的中的任务全部执行完以后,会查看是否有微任务队列。如果有,先执行微任务队列中的所有任务,如果没有,就查看是否有其他宏任务队列。
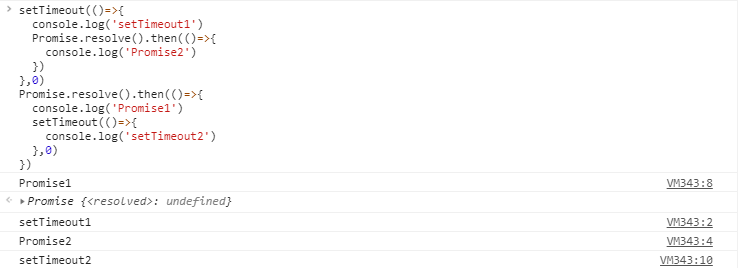
接下来我们看两道例子来介绍上面流程:
Promise.resolve().then(()=>{
console.log('Promise1')
setTimeout(()=>{
console.log('setTimeout2')
},0)
})
setTimeout(()=>{
console.log('setTimeout1')
Promise.resolve().then(()=>{
console.log('Promise2')
})
},0)最后输出结果是Promise1,setTimeout1,Promise2,setTimeout2
- 一开始执行栈的同步任务执行完毕,会去查看是否有微任务队列,上题中存在(有且只有一个),然后执行微任务队列中的所有任务输出Promise1,同时会生成一个宏任务 setTimeout2
- 然后去查看宏任务队列,宏任务 setTimeout1 在 setTimeout2 之前,先执行宏任务 setTimeout1,输出 setTimeout1
- 在执行宏任务setTimeout1时会生成微任务Promise2 ,放入微任务队列中,接着先去清空微任务队列中的所有任务,输出 Promise2
- 清空完微任务队列中的所有任务后,就又会去宏任务队列取一个,这回执行的是 setTimeout2
console.log('----------------- start -----------------');
setTimeout(() => {
console.log('setTimeout');
}, 0)
new Promise((resolve, reject) =>{
for (var i = 0; i < 5; i++) {
console.log(i);
}
resolve(); // 修改promise实例对象的状态为成功的状态
}).then(() => {
console.log('promise实例成功回调执行');
})
console.log('----------------- end -----------------');将上题调换顺序
六、H5 Web Workers(多线程)
1. Web Workers的作用
正如上面所提到,JavaScript是单线程。当一个页面加载一个复杂运算的 js 文件时,用户界面可能会短暂地“冻结”,不能再做其他操作。比如下面这个例子:
<input type="text" placeholder="数值" id="number">
<button id="btn">计算</button>
<script type="text/javascript">
// 1 1 2 3 5 8 f(n) = f(n-1) + f(n-2)
function fibonacci(n) {
return n<=2 ? 1 : fibonacci(n-1) + fibonacci(n-2) //递归调用
}
var input = document.getElementById('number')
document.getElementById('btn').onclick = function () {
var number = input.value
var result = fibonacci(number)
alert(result)
}
</script>
很显然遇到这种页面堵塞情况,很影响用户体验的,有没有啥办法可以改进这种情形?----Web Worker就应运而生了!
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。其原理图如下:
2. Web Workers的基本使用
主线程
- 首先主线程采用new命令,调用Worker()构造函数,新建一个 Worker 线程
var worker = new Worker('work.js');
- 然后主线程调用worker.postMessage()方法,向 Worker 发消息。
- 接着,主线程通过worker.onmessage指定监听函数,接收子线程发回来的消息。
var input = document.getElementById('number')
document.getElementById('btn').onclick = function () {
var number = input.value
//创建一个Worker对象
var worker = new Worker('worker.js')
// 绑定接收消息的监听
worker.onmessage = function (event) {
console.log('主线程接收分线程返回的数据: '+event.data)
alert(event.data)
}
// 向分线程发送消息
worker.postMessage(number)
console.log('主线程向分线程发送数据: '+number)
}
console.log(this) // window
Worker 线程
- Worker 线程内部需要有一个监听函数,监听message事件。
- 通过 postMessage(data) 方法来向主线程发送数据。
//worker.js文件
function fibonacci(n) {
return n<=2 ? 1 : fibonacci(n-1) + fibonacci(n-2) //递归调用
}
console.log(this)//[object DedicatedWorkerGlobalScope]
this.onmessage = function (event) {
var number = event.data
console.log('分线程接收到主线程发送的数据: '+number)
//计算
var result = fibonacci(number)
postMessage(result)
console.log('分线程向主线程返回数据: '+result)
// alert(result) alert是window的方法, 在分线程不能调用
// 分线程中的全局对象不再是window, 所以在分线程中不可能更新界面
}
这样当分线程在计算时,用户界面还可以操作,而且更早拿到计算后数据,响应速度更快了。
3. Web Workers的缺点
- 不能跨域加载JS
- worker内代码不能访问DOM(更新UI)
- 不是每个浏览器都支持这个新特性(本文例子只能在Firefox浏览器上运行,chrome不支持)
如果需要源代码,请猛戳Web Workers
如果觉得文章对你有些许帮助,欢迎在我的GitHub博客点赞和关注,感激不尽!
七、Node 中的 Event Loop
1.Node简介
Node 中的 Event Loop 和浏览器中Event Loop的是完全不相同的东西。Node.js采用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现(下文会详细介绍)。
- V8引擎解析JavaScript脚本。
- 解析后的代码,调用Node API。
- libuv库负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
- V8引擎再将结果返回给用户。
2.六个阶段
其中libuv引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
从上图中,大致看出node中的事件循环的顺序:
外部输入数据-->轮询阶段(poll)-->检查阶段(check)-->关闭事件回调阶段(close callback)-->定时器检测阶段(timer)-->I/O事件回调阶段(I/O callbacks)-->闲置阶段(idle, prepare)-->轮询阶段(按照该顺序反复运行)...
- timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调
- idle, prepare 阶段:仅node内部使用
- poll 阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里
- check 阶段:执行 setImmediate() 的回调
- close callbacks 阶段:执行 socket 的 close 事件回调
注意:上面六个阶段都不包括 process.nextTick()(下文会介绍)
接下去我们详细介绍timers、poll、check这3个阶段,因为日常开发中的绝大部分异步任务都是在这3个阶段处理的。
(1) timer
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。 同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。
(2) poll
poll 是一个至关重要的阶段,这一阶段中,系统会做两件事情
1.回到 timer 阶段执行回调
2.执行 I/O 回调
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
- 如果 poll 队列为空时,会有两件事发生
- 如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
- 如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
(3) check阶段
setImmediate()的回调会被加入check队列中,从event loop的阶段图可以知道,check阶段的执行顺序在poll阶段之后。 我们先来看个例子:
console.log('start')
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(() => {
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
Promise.resolve().then(function() {
console.log('promise3')
})
console.log('end')
//start=>end=>promise3=>timer1=>timer2=>promise1=>promise2
复制代码- 一开始执行栈的同步任务(这属于宏任务)执行完毕后(依次打印出start end,并将2个timer依次放入timer队列),会先去执行微任务(这点跟浏览器端的一样),所以打印出promise3
- 然后进入timers阶段,执行timer1的回调函数,打印timer1,并将promise.then回调放入microtask队列,同样的步骤执行timer2,打印timer2;这点跟浏览器端相差比较大,timers阶段有几个setTimeout/setInterval都会依次执行,并不像浏览器端,每执行一个宏任务后就去执行一个微任务(关于Node与浏览器的 Event Loop 差异,下文还会详细介绍)。
3.Micro-Task 与 Macro-Task
Node端事件循环中的异步队列也是这两种:macro(宏任务)队列和 micro(微任务)队列。
- 常见的 macro-task 比如:setTimeout、setInterval、 setImmediate、script(整体代码)、 I/O 操作等。
- 常见的 micro-task 比如: process.nextTick、new Promise().then(回调)等。
4.注意点
(1) setTimeout 和 setImmediate
二者非常相似,区别主要在于调用时机不同。
- setImmediate 设计在poll阶段完成时执行,即check阶段;
- setTimeout 设计在poll阶段为空闲时,且设定时间到达后执行,但它在timer阶段执行
setTimeout(function timeout () {
console.log('timeout');
},0);
setImmediate(function immediate () {
console.log('immediate');
});
复制代码- 对于以上代码来说,setTimeout 可能执行在前,也可能执行在后。
- 首先 setTimeout(fn, 0) === setTimeout(fn, 1),这是由源码决定的 进入事件循环也是需要成本的,如果在准备时候花费了大于 1ms 的时间,那么在 timer 阶段就会直接执行 setTimeout 回调
- 如果准备时间花费小于 1ms,那么就是 setImmediate 回调先执行了
但当二者在异步i/o callback内部调用时,总是先执行setImmediate,再执行setTimeout
const fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0)
setImmediate(() => {
console.log('immediate')
})
})
// immediate
// timeout
复制代码在上述代码中,setImmediate 永远先执行。因为两个代码写在 IO 回调中,IO 回调是在 poll 阶段执行,当回调执行完毕后队列为空,发现存在 setImmediate 回调,所以就直接跳转到 check 阶段去执行回调了。
(2) process.nextTick
这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
})
})
})
})
// nextTick=>nextTick=>nextTick=>nextTick=>timer1=>promise1
复制代码五、Node与浏览器的 Event Loop 差异
浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。而在Node.js中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务。
接下我们通过一个例子来说明两者区别:
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
复制代码浏览器端运行结果:timer1=>promise1=>timer2=>promise2
浏览器端的处理过程如下:
Node端运行结果分两种情况:
- 如果是node11版本一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这就跟浏览器端运行一致,最后的结果为
timer1=>promise1=>timer2=>promise2 - 如果是node10及其之前版本:要看第一个定时器执行完,第二个定时器是否在完成队列中。
- 如果是第二个定时器还未在完成队列中,最后的结果为
timer1=>promise1=>timer2=>promise2 - 如果是第二个定时器已经在完成队列中,则最后的结果为
timer1=>timer2=>promise1=>promise2(下文过程解释基于这种情况下)
- 如果是第二个定时器还未在完成队列中,最后的结果为
1.全局脚本(main())执行,将2个timer依次放入timer队列,main()执行完毕,调用栈空闲,任务队列开始执行;
2.首先进入timers阶段,执行timer1的回调函数,打印timer1,并将promise1.then回调放入microtask队列,同样的步骤执行timer2,打印timer2;
3.至此,timer阶段执行结束,event loop进入下一个阶段之前,执行microtask队列的所有任务,依次打印promise1、promise2
Node端的处理过程如下:
六、总结
浏览器和Node 环境下,microtask 任务队列的执行时机不同
- Node端,microtask 在事件循环的各个阶段之间执行
- 浏览器端,microtask 在事件循环的 macrotask 执行完之后执行
后记
文章于2019.1.16晚,对最后一个例子在node运行结果,重新修改!再次特别感谢zy445566的精彩点评,由于node版本更新到11,Event Loop运行原理发生了变化,一旦执行一个阶段里的一个宏任务(setTimeout,setInterval和setImmediate)就立刻执行微任务队列,这点就跟浏览器端一致。
参考文章
参考文章
进程和线程
进程与线程的一个简单解释
关于JavaScript单线程的一些事
JavaScript 运行机制详解:再谈Event Loop
Web Worker 是什么鬼?
Web Worker 使用教程
前言
见解有限,如有描述不当之处,请帮忙及时指出,如有错误,会及时修正。
----------超长文+多图预警,需要花费不少时间。----------
如果看完本文后,还对进程线程傻傻分不清,不清楚浏览器多进程、浏览器内核多线程、JS单线程、JS运行机制的区别。那么请回复我,一定是我写的还不够清晰,我来改。。。
----------正文开始----------
最近发现有不少介绍JS单线程运行机制的文章,但是发现很多都仅仅是介绍某一部分的知识,而且各个地方的说法还不统一,容易造成困惑。
因此准备梳理这块知识点,结合已有的认知,基于网上的大量参考资料,
从浏览器多进程到JS单线程,将JS引擎的运行机制系统的梳理一遍。
展现形式:由于是属于系统梳理型,就没有由浅入深了,而是从头到尾的梳理知识体系,
重点是将关键节点的知识点串联起来,而不是仅仅剖析某一部分知识。
内容是:从浏览器进程,再到浏览器内核运行,再到JS引擎单线程,再到JS事件循环机制,从头到尾系统的梳理一遍,摆脱碎片化,形成一个知识体系
目标是:看完这篇文章后,对浏览器多进程,JS单线程,JS事件循环机制这些都能有一定理解,
有一个知识体系骨架,而不是似懂非懂的感觉。
另外,本文适合有一定经验的前端人员,新手请规避,避免受到过多的概念冲击。可以先存起来,有了一定理解后再看,也可以分成多批次观看,避免过度疲劳。
大纲
- 区分进程和线程
-
浏览器是多进程的
- 浏览器都包含哪些进程?
- 浏览器多进程的优势
- 重点是浏览器内核(渲染进程)
- Browser进程和浏览器内核(Renderer进程)的通信过程
-
梳理浏览器内核中线程之间的关系
- GUI渲染线程与JS引擎线程互斥
- JS阻塞页面加载
- WebWorker,JS的多线程?
- WebWorker与SharedWorker
-
简单梳理下浏览器渲染流程
- load事件与DOMContentLoaded事件的先后
- css加载是否会阻塞dom树渲染?
- 普通图层和复合图层
-
从Event Loop谈JS的运行机制
- 事件循环机制进一步补充
- 单独说说定时器
- setTimeout而不是setInterval
- 事件循环进阶:macrotask与microtask
- 写在最后的话
区分进程和线程
线程和进程区分不清,是很多新手都会犯的错误,没有关系。这很正常。先看看下面这个形象的比喻:
- 进程是一个工厂,工厂有它的独立资源
- 工厂之间相互独立
- 线程是工厂中的工人,多个工人协作完成任务
- 工厂内有一个或多个工人
- 工人之间共享空间再完善完善概念:
- 工厂的资源 -> 系统分配的内存(独立的一块内存)
- 工厂之间的相互独立 -> 进程之间相互独立
- 多个工人协作完成任务 -> 多个线程在进程中协作完成任务
- 工厂内有一个或多个工人 -> 一个进程由一个或多个线程组成
- 工人之间共享空间 -> 同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)然后再巩固下:
如果是windows电脑中,可以打开任务管理器,可以看到有一个后台进程列表。对,那里就是查看进程的地方,而且可以看到每个进程的内存资源信息以及cpu占有率。
所以,应该更容易理解了:进程是cpu资源分配的最小单位(系统会给它分配内存)
最后,再用较为官方的术语描述一遍:
- 进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)
- 线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
tips
- 不同进程之间也可以通信,不过代价较大
- 现在,一般通用的叫法:单线程与多线程,都是指在一个进程内的单和多。(所以核心还是得属于一个进程才行)
浏览器是多进程的
理解了进程与线程了区别后,接下来对浏览器进行一定程度上的认识:(先看下简化理解)
- 浏览器是多进程的
- 浏览器之所以能够运行,是因为系统给它的进程分配了资源(cpu、内存)
- 简单点理解,每打开一个Tab页,就相当于创建了一个独立的浏览器进程。
关于以上几点的验证,请再第一张图:

图中打开了Chrome浏览器的多个标签页,然后可以在Chrome的任务管理器中看到有多个进程(分别是每一个Tab页面有一个独立的进程,以及一个主进程)。
感兴趣的可以自行尝试下,如果再多打开一个Tab页,进程正常会+1以上
注意:在这里浏览器应该也有自己的优化机制,有时候打开多个tab页后,可以在Chrome任务管理器中看到,有些进程被合并了
(所以每一个Tab标签对应一个进程并不一定是绝对的)
浏览器都包含哪些进程?
知道了浏览器是多进程后,再来看看它到底包含哪些进程:(为了简化理解,仅列举主要进程)
-
Browser进程:浏览器的主进程(负责协调、主控),只有一个。作用有
- 负责浏览器界面显示,与用户交互。如前进,后退等
- 负责各个页面的管理,创建和销毁其他进程
- 将Renderer进程得到的内存中的Bitmap,绘制到用户界面上
- 网络资源的管理,下载等
- 第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
- GPU进程:最多一个,用于3D绘制等
-
浏览器渲染进程(浏览器内核)(Renderer进程,内部是多线程的):默认每个Tab页面一个进程,互不影响。主要作用为
- 页面渲染,脚本执行,事件处理等
强化记忆:在浏览器中打开一个网页相当于新起了一个进程(进程内有自己的多线程)
当然,浏览器有时会将多个进程合并(譬如打开多个空白标签页后,会发现多个空白标签页被合并成了一个进程),如图

另外,可以通过Chrome的更多工具 -> 任务管理器自行验证
浏览器多进程的优势
相比于单进程浏览器,多进程有如下优点:
- 避免单个page crash影响整个浏览器
- 避免第三方插件crash影响整个浏览器
- 多进程充分利用多核优势
- 方便使用沙盒模型隔离插件等进程,提高浏览器稳定性
简单点理解:如果浏览器是单进程,那么某个Tab页崩溃了,就影响了整个浏览器,体验有多差;同理如果是单进程,插件崩溃了也会影响整个浏览器;而且多进程还有其它的诸多优势。。。
当然,内存等资源消耗也会更大,有点空间换时间的意思。
重点是浏览器内核(渲染进程)
重点来了,我们可以看到,上面提到了这么多的进程,那么,对于普通的前端操作来说,最终要的是什么呢?答案是渲染进程
可以这样理解,页面的渲染,JS的执行,事件的循环,都在这个进程内进行。接下来重点分析这个进程
请牢记,浏览器的渲染进程是多线程的(这点如果不理解,请回头看进程和线程的区分)
终于到了线程这个概念了?,好亲切。那么接下来看看它都包含了哪些线程(列举一些主要常驻线程):
-
GUI渲染线程
- 负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
- 注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
-
JS引擎线程
- 也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎)
- JS引擎线程负责解析Javascript脚本,运行代码。
- JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
- 同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
-
事件触发线程
- 归属于浏览器而不是JS引擎,用来控制事件循环(可以理解,JS引擎自己都忙不过来,需要浏览器另开线程协助)
- 当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
-
注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
-
定时触发器线程
- 传说中的
setInterval与setTimeout所在线程 - 浏览器定时计数器并不是由JavaScript引擎计数的,(因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
- 注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
- 传说中的
-
异步http请求线程
- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。
看到这里,如果觉得累了,可以先休息下,这些概念需要被消化,毕竟后续将提到的事件循环机制就是基于事件触发线程的,所以如果仅仅是看某个碎片化知识,
可能会有一种似懂非懂的感觉。要完成的梳理一遍才能快速沉淀,不易遗忘。放张图巩固下吧:

再说一点,为什么JS引擎是单线程的?额,这个问题其实应该没有标准答案,譬如,可能仅仅是因为由于多线程的复杂性,譬如多线程操作一般要加锁,因此最初设计时选择了单线程。。。
Browser进程和浏览器内核(Renderer进程)的通信过程
看到这里,首先,应该对浏览器内的进程和线程都有一定理解了,那么接下来,再谈谈浏览器的Browser进程(控制进程)是如何和内核通信的,
这点也理解后,就可以将这部分的知识串联起来,从头到尾有一个完整的概念。
如果自己打开任务管理器,然后打开一个浏览器,就可以看到:任务管理器中出现了两个进程(一个是主控进程,一个则是打开Tab页的渲染进程),
然后在这前提下,看下整个的过程:(简化了很多)
- Browser进程收到用户请求,首先需要获取页面内容(譬如通过网络下载资源),随后将该任务通过RendererHost接口传递给Render进程
-
Renderer进程的Renderer接口收到消息,简单解释后,交给渲染线程,然后开始渲染
- 渲染线程接收请求,加载网页并渲染网页,这其中可能需要Browser进程获取资源和需要GPU进程来帮助渲染
- 当然可能会有JS线程操作DOM(这样可能会造成回流并重绘)
- 最后Render进程将结果传递给Browser进程
- Browser进程接收到结果并将结果绘制出来
这里绘一张简单的图:(很简化)

看完这一整套流程,应该对浏览器的运作有了一定理解了,这样有了知识架构的基础后,后续就方便往上填充内容。
这块再往深处讲的话就涉及到浏览器内核源码解析了,不属于本文范围。
如果这一块要深挖,建议去读一些浏览器内核源码解析文章,或者可以先看看参考下来源中的第一篇文章,写的不错
梳理浏览器内核中线程之间的关系
到了这里,已经对浏览器的运行有了一个整体的概念,接下来,先简单梳理一些概念
GUI渲染线程与JS引擎线程互斥
由于JavaScript是可操纵DOM的,如果在修改这些元素属性同时渲染界面(即JS线程和UI线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置GUI渲染线程与JS引擎为互斥的关系,当JS引擎执行时GUI线程会被挂起,
GUI更新则会被保存在一个队列中等到JS引擎线程空闲时立即被执行。
JS阻塞页面加载
从上述的互斥关系,可以推导出,JS如果执行时间过长就会阻塞页面。
譬如,假设JS引擎正在进行巨量的计算,此时就算GUI有更新,也会被保存到队列中,等待JS引擎空闲后执行。
然后,由于巨量计算,所以JS引擎很可能很久很久后才能空闲,自然会感觉到巨卡无比。
所以,要尽量避免JS执行时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
WebWorker,JS的多线程?
前文中有提到JS引擎是单线程的,而且JS执行时间过长会阻塞页面,那么JS就真的对cpu密集型计算无能为力么?
所以,后来HTML5中支持了Web Worker。
MDN的官方解释是:
Web Worker为Web内容在后台线程中运行脚本提供了一种简单的方法。线程可以执行任务而不干扰用户界面
一个worker是使用一个构造函数创建的一个对象(e.g. Worker()) 运行一个命名的JavaScript文件
这个文件包含将在工作线程中运行的代码; workers 运行在另一个全局上下文中,不同于当前的window
因此,使用 window快捷方式获取当前全局的范围 (而不是self) 在一个 Worker 内将返回错误这样理解下:
- 创建Worker时,JS引擎向浏览器申请开一个子线程(子线程是浏览器开的,完全受主线程控制,而且不能操作DOM)
- JS引擎线程与worker线程间通过特定的方式通信(postMessage API,需要通过序列化对象来与线程交互特定的数据)
所以,如果有非常耗时的工作,请单独开一个Worker线程,这样里面不管如何翻天覆地都不会影响JS引擎主线程,
只待计算出结果后,将结果通信给主线程即可,perfect!
而且注意下,JS引擎是单线程的,这一点的本质仍然未改变,Worker可以理解是浏览器给JS引擎开的外挂,专门用来解决那些大量计算问题。
其它,关于Worker的详解就不是本文的范畴了,因此不再赘述。
WebWorker与SharedWorker
既然都到了这里,就再提一下SharedWorker(避免后续将这两个概念搞混)
-
WebWorker只属于某个页面,不会和其他页面的Render进程(浏览器内核进程)共享
- 所以Chrome在Render进程中(每一个Tab页就是一个render进程)创建一个新的线程来运行Worker中的JavaScript程序。
-
SharedWorker是浏览器所有页面共享的,不能采用与Worker同样的方式实现,因为它不隶属于某个Render进程,可以为多个Render进程共享使用
- 所以Chrome浏览器为SharedWorker单独创建一个进程来运行JavaScript程序,在浏览器中每个相同的JavaScript只存在一个SharedWorker进程,不管它被创建多少次。
看到这里,应该就很容易明白了,本质上就是进程和线程的区别。SharedWorker由独立的进程管理,WebWorker只是属于render进程下的一个线程
简单梳理下浏览器渲染流程
本来是直接计划开始谈JS运行机制的,但想了想,既然上述都一直在谈浏览器,直接跳到JS可能再突兀,因此,中间再补充下浏览器的渲染流程(简单版本)
为了简化理解,前期工作直接省略成:(要展开的或完全可以写另一篇超长文)
- 浏览器输入url,浏览器主进程接管,开一个下载线程,
然后进行 http请求(略去DNS查询,IP寻址等等操作),然后等待响应,获取内容,
随后将内容通过RendererHost接口转交给Renderer进程
- 浏览器渲染流程开始浏览器器内核拿到内容后,渲染大概可以划分成以下几个步骤:
- 解析html建立dom树
- 解析css构建render树(将CSS代码解析成树形的数据结构,然后结合DOM合并成render树)
- 布局render树(Layout/reflow),负责各元素尺寸、位置的计算
- 绘制render树(paint),绘制页面像素信息
- 浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上。
所有详细步骤都已经略去,渲染完毕后就是load事件了,之后就是自己的JS逻辑处理了
既然略去了一些详细的步骤,那么就提一些可能需要注意的细节把。
这里重绘参考来源中的一张图:(参考来源第一篇)

load事件与DOMContentLoaded事件的先后
上面提到,渲染完毕后会触发load事件,那么你能分清楚load事件与DOMContentLoaded事件的先后么?
很简单,知道它们的定义就可以了:
- 当 DOMContentLoaded 事件触发时,仅当DOM加载完成,不包括样式表,图片。
(譬如如果有async加载的脚本就不一定完成)
- 当 onload 事件触发时,页面上所有的DOM,样式表,脚本,图片都已经加载完成了。
(渲染完毕了)
所以,顺序是:DOMContentLoaded -> load
css加载是否会阻塞dom树渲染?
这里说的是头部引入css的情况
首先,我们都知道:css是由单独的下载线程异步下载的。
然后再说下几个现象:
- css加载不会阻塞DOM树解析(异步加载时DOM照常构建)
- 但会阻塞render树渲染(渲染时需等css加载完毕,因为render树需要css信息)
这可能也是浏览器的一种优化机制。
因为你加载css的时候,可能会修改下面DOM节点的样式,
如果css加载不阻塞render树渲染的话,那么当css加载完之后,
render树可能又得重新重绘或者回流了,这就造成了一些没有必要的损耗。
所以干脆就先把DOM树的结构先解析完,把可以做的工作做完,然后等你css加载完之后,
在根据最终的样式来渲染render树,这种做法性能方面确实会比较好一点。
普通图层和复合图层
渲染步骤中就提到了composite概念。
可以简单的这样理解,浏览器渲染的图层一般包含两大类:普通图层以及复合图层
首先,普通文档流内可以理解为一个复合图层(这里称为默认复合层,里面不管添加多少元素,其实都是在同一个复合图层中)
其次,absolute布局(fixed也一样),虽然可以脱离普通文档流,但它仍然属于默认复合层。
然后,可以通过硬件加速的方式,声明一个新的复合图层,它会单独分配资源
(当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响默认复合层里的回流重绘)
可以简单理解下:GPU中,各个复合图层是单独绘制的,所以互不影响,这也是为什么某些场景硬件加速效果一级棒
可以Chrome源码调试 -> More Tools -> Rendering -> Layer borders中看到,黄色的就是复合图层信息
如下图。可以验证上述的说法

如何变成复合图层(硬件加速)
将该元素变成一个复合图层,就是传说中的硬件加速技术
- 最常用的方式:
translate3d、translateZ opacity属性/过渡动画(需要动画执行的过程中才会创建合成层,动画没有开始或结束后元素还会回到之前的状态)will-chang属性(这个比较偏僻),一般配合opacity与translate使用(而且经测试,除了上述可以引发硬件加速的属性外,其它属性并不会变成复合层),
作用是提前告诉浏览器要变化,这样浏览器会开始做一些优化工作(这个最好用完后就释放)
<video><iframe><canvas><webgl>等元素- 其它,譬如以前的flash插件
absolute和硬件加速的区别
可以看到,absolute虽然可以脱离普通文档流,但是无法脱离默认复合层。
所以,就算absolute中信息改变时不会改变普通文档流中render树,
但是,浏览器最终绘制时,是整个复合层绘制的,所以absolute中信息的改变,仍然会影响整个复合层的绘制。
(浏览器会重绘它,如果复合层中内容多,absolute带来的绘制信息变化过大,资源消耗是非常严重的)
而硬件加速直接就是在另一个复合层了(另起炉灶),所以它的信息改变不会影响默认复合层
(当然了,内部肯定会影响属于自己的复合层),仅仅是引发最后的合成(输出视图)
复合图层的作用?
一般一个元素开启硬件加速后会变成复合图层,可以独立于普通文档流中,改动后可以避免整个页面重绘,提升性能
但是尽量不要大量使用复合图层,否则由于资源消耗过度,页面反而会变的更卡
硬件加速时请使用index
使用硬件加速时,尽可能的使用index,防止浏览器默认给后续的元素创建复合层渲染
具体的原理时这样的:
**webkit CSS3中,如果这个元素添加了硬件加速,并且index层级比较低,
那么在这个元素的后面其它元素(层级比这个元素高的,或者相同的,并且releative或absolute属性相同的),
会默认变为复合层渲染,如果处理不当会极大的影响性能**
简单点理解,其实可以认为是一个隐式合成的概念:如果a是一个复合图层,而且b在a上面,那么b也会被隐式转为一个复合图层,这点需要特别注意
另外,这个问题可以在这个地址看到重现(原作者分析的挺到位的,直接上链接):
从Event Loop谈JS的运行机制
到此时,已经是属于浏览器页面初次渲染完毕后的事情,JS引擎的一些运行机制分析。
注意,这里不谈可执行上下文,VO,scop chain等概念(这些完全可以整理成另一篇文章了),这里主要是结合Event Loop来谈JS代码是如何执行的。
读这部分的前提是已经知道了JS引擎是单线程,而且这里会用到上文中的几个概念:(如果不是很理解,可以回头温习)
- JS引擎线程
- 事件触发线程
- 定时触发器线程
然后再理解一个概念:
- JS分为同步任务和异步任务
- 同步任务都在主线程上执行,形成一个
执行栈 - 主线程之外,事件触发线程管理着一个
任务队列,只要异步任务有了运行结果,就在任务队列之中放置一个事件。 - 一旦
执行栈中的所有同步任务执行完毕(此时JS引擎空闲),系统就会读取任务队列,将可运行的异步任务添加到可执行栈中,开始执行。
看图:

看到这里,应该就可以理解了:为什么有时候setTimeout推入的事件不能准时执行?因为可能在它推入到事件列表时,主线程还不空闲,正在执行其它代码,
所以自然有误差。
事件循环机制进一步补充
这里就直接引用一张图片来协助理解:(参考自Philip Roberts的演讲《Help, I'm stuck in an event-loop》)

上图大致描述就是:
- 主线程运行时会产生执行栈,
栈中的代码调用某些api时,它们会在事件队列中添加各种事件(当满足触发条件后,如ajax请求完毕)
- 而栈中的代码执行完毕,就会读取事件队列中的事件,去执行那些回调
- 如此循环
- 注意,总是要等待栈中的代码执行完毕后才会去读取事件队列中的事件
单独说说定时器
上述事件循环机制的核心是:JS引擎线程和事件触发线程
但事件上,里面还有一些隐藏细节,譬如调用setTimeout后,是如何等待特定时间后才添加到事件队列中的?
是JS引擎检测的么?当然不是了。它是由定时器线程控制(因为JS引擎自己都忙不过来,根本无暇分身)
为什么要单独的定时器线程?因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确,因此很有必要单独开一个线程用来计时。
什么时候会用到定时器线程?当使用setTimeout或setInterval时,它需要定时器线程计时,计时完成后就会将特定的事件推入事件队列中。
譬如:
setTimeout(function(){
console.log('hello!');
}, 1000);这段代码的作用是当1000毫秒计时完毕后(由定时器线程计时),将回调函数推入事件队列中,等待主线程执行
setTimeout(function(){
console.log('hello!');
}, 0);
console.log('begin');这段代码的效果是最快的时间内将回调函数推入事件队列中,等待主线程执行
注意:
- 执行结果是:先
begin后hello! - 虽然代码的本意是0毫秒后就推入事件队列,但是W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
(不过也有一说是不同浏览器有不同的最小时间设定)
- 就算不等待4ms,就算假设0毫秒就推入事件队列,也会先执行
begin(因为只有可执行栈内空了后才会主动读取事件队列)
setTimeout而不是setInterval
用setTimeout模拟定期计时和直接用setInterval是有区别的。
因为每次setTimeout计时到后就会去执行,然后执行一段时间后才会继续setTimeout,中间就多了误差
(误差多少与代码执行时间有关)
而setInterval则是每次都精确的隔一段时间推入一个事件
(但是,事件的实际执行时间不一定就准确,还有可能是这个事件还没执行完毕,下一个事件就来了)
而且setInterval有一些比较致命的问题就是:
- 累计效应(上面提到的),如果setInterval代码在(setInterval)再次添加到队列之前还没有完成执行,
就会导致定时器代码连续运行好几次,而之间没有间隔。
就算正常间隔执行,多个setInterval的代码执行时间可能会比预期小(因为代码执行需要一定时间)
譬如像iOS的webview,或者Safari等浏览器中都有一个特点,在滚动的时候是不执行JS的,如果使用了setInterval,会发现在滚动结束后会执行多次由于滚动不执行JS积攒回调,如果回调执行时间过长,就会非常容器造成卡顿问题和一些不可知的错误(这一块后续有补充,setInterval自带的优化,不会重复添加回调)- 而且把浏览器最小化显示等操作时,setInterval并不是不执行程序,
它会把setInterval的回调函数放在队列中,等浏览器窗口再次打开时,一瞬间全部执行时
所以,鉴于这么多但问题,目前一般认为的最佳方案是:用setTimeout模拟setInterval,或者特殊场合直接用requestAnimationFrame
补充:JS高程中有提到,JS引擎会对setInterval进行优化,如果当前事件队列中有setInterval的回调,不会重复添加。不过,仍然是有很多问题。。。
事件循环进阶:macrotask与microtask
这段参考了参考来源中的第2篇文章(英文版的),(加了下自己的理解重新描述了下),
强烈推荐有英文基础的同学直接观看原文,作者描述的很清晰,示例也很不错,如下:
https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/
上文中将JS事件循环机制梳理了一遍,在ES5的情况是够用了,但是在ES6盛行的现在,仍然会遇到一些问题,譬如下面这题:
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');嗯哼,它的正确执行顺序是这样子的:
script start
script end
promise1
promise2
setTimeout为什么呢?因为Promise里有了一个一个新的概念:microtask
或者,进一步,JS中分为两种任务类型:macrotask和microtask,在ECMAScript中,microtask称为jobs,macrotask可称为task
它们的定义?区别?简单点可以按如下理解:
-
macrotask(又称之为宏任务),可以理解是每次执行栈执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行)
- 每一个task会从头到尾将这个任务执行完毕,不会执行其它
- 浏览器为了能够使得JS内部task与DOM任务能够有序的执行,会在一个task执行结束后,在下一个 task 执行开始前,对页面进行重新渲染
(`task->渲染->task->...`)
-
microtask(又称为微任务),可以理解是在当前 task 执行结束后立即执行的任务
- 也就是说,在当前task任务后,下一个task之前,在渲染之前
- 所以它的响应速度相比setTimeout(setTimeout是task)会更快,因为无需等渲染
- 也就是说,在某一个macrotask执行完后,就会将在它执行期间产生的所有microtask都执行完毕(在渲染前)
分别很么样的场景会形成macrotask和microtask呢?
- macrotask:主代码块,setTimeout,setInterval等(可以看到,事件队列中的每一个事件都是一个macrotask)
- microtask:Promise,process.nextTick等
__补充:在node环境下,process.nextTick的优先级高于Promise__,也就是可以简单理解为:在宏任务结束后会先执行微任务队列中的nextTickQueue部分,然后才会执行微任务中的Promise部分。
参考:https://segmentfault.com/q/1010000011914016
再根据线程来理解下:
- macrotask中的事件都是放在一个事件队列中的,而这个队列由事件触发线程维护
- microtask中的所有微任务都是添加到微任务队列(Job Queues)中,等待当前macrotask执行完毕后执行,而这个队列由JS引擎线程维护
(这点由自己理解+推测得出,因为它是在主线程下无缝执行的)
所以,总结下运行机制:
- 执行一个宏任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)
如图:

另外,请注意下Promise的polyfill与官方版本的区别:
- 官方版本中,是标准的microtask形式
- polyfill,一般都是通过setTimeout模拟的,所以是macrotask形式
- 请特别注意这两点区别
注意,有一些浏览器执行结果不一样(因为它们可能把microtask当成macrotask来执行了),
但是为了简单,这里不描述一些不标准的浏览器下的场景(但记住,有些浏览器可能并不标准)
20180126补充:使用MutationObserver实现microtask
MutationObserver可以用来实现microtask
(它属于microtask,优先级小于Promise,
一般是Promise不支持时才会这样做)
它是HTML5中的新特性,作用是:监听一个DOM变动,
当DOM对象树发生任何变动时,Mutation Observer会得到通知
像以前的Vue源码中就是利用它来模拟nextTick的,
具体原理是,创建一个TextNode并监听内容变化,
然后要nextTick的时候去改一下这个节点的文本内容,
如下:(Vue的源码,未修改)
var counter = 1
var observer = new MutationObserver(nextTickHandler)
var textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2
textNode.data = String(counter)
}不过,现在的Vue(2.5+)的nextTick实现移除了MutationObserver的方式(据说是兼容性原因),
取而代之的是使用MessageChannel
(当然,默认情况仍然是Promise,不支持才兼容的)。
MessageChannel属于宏任务,优先级是:MessageChannel->setTimeout,
所以Vue(2.5+)内部的nextTick与2.4及之前的实现是不一样的,需要注意下。
这里不展开,可以看下https://juejin.im/post/5a1af88f5188254a701ec230
写在最后的话
看到这里,不知道对JS的运行机制是不是更加理解了,从头到尾梳理,而不是就某一个碎片化知识应该是会更清晰的吧?
同时,也应该注意到了JS根本就没有想象的那么简单,前端的知识也是无穷无尽,层出不穷的概念、N多易忘的知识点、各式各样的框架、
底层原理方面也是可以无限的往下深挖,然后你就会发现,你知道的太少了。。。
另外,本文也打算先告一段落,其它的,如JS词法解析,可执行上下文以及VO等概念就不继续在本文中写了,后续可以考虑另开新的文章。
最后,喜欢的话,就请给个赞吧!
附录
博客
初次发布2018.01.21于我个人博客上面
http://www.dailichun.com/2018/01/21/js_singlethread_eventloop.html
参考资料
- https://www.cnblogs.com/lhb25/p/how-browsers-work.html
- https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/
- https://segmentfault.com/p/1210000012780980
- http://blog.csdn.net/u013510838/article/details/55211033
- http://blog.csdn.net/Steward2011/article/details/51319298
- http://www.imweb.io/topic/58e3bfa845e5c13468f567d5
- https://segmentfault.com/a/1190000008015671
- https://juejin.im/post/5a4ed917f265da3e317df515
- http://www.cnblogs.com/iovec/p/7904416.html
- https://www.cnblogs.com/wyaocn/p/5761163.html
- http://www.ruanyifeng.com/blog/2014/10/event-loop.html#comment-text
一次弄懂Event Loop(彻底解决此类面试问题)
前言
Event Loop即事件循环,是指浏览器或Node的一种解决javaScript单线程运行时不会阻塞的一种机制,也就是我们经常使用异步的原理。
为啥要弄懂Event Loop
-
是要增加自己技术的深度,也就是懂得
JavaScript的运行机制。 -
现在在前端领域各种技术层出不穷,掌握底层原理,可以让自己以不变,应万变。
-
应对各大互联网公司的面试,懂其原理,题目任其发挥。
堆,栈、队列
堆(Heap)
堆是一种数据结构,是利用完全二叉树维护的一组数据,堆分为两种,一种为最大堆,一种为最小堆,将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆是线性数据结构,相当于一维数组,有唯一后继。
如最大堆
栈(Stack)
栈在计算机科学中是限定仅在表尾进行插入或删除操作的线性表。 栈是一种数据结构,它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据。
栈是只能在某一端插入和删除的特殊线性表。
队列(Queue)
特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。
进行插入操作的端称为队尾,进行删除操作的端称为队头。 队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)
Event Loop
在JavaScript中,任务被分为两种,一种宏任务(MacroTask)也叫Task,一种叫微任务(MicroTask)。
MacroTask(宏任务)
script全部代码、setTimeout、setInterval、setImmediate(浏览器暂时不支持,只有IE10支持,具体可见MDN)、I/O、UI Rendering。
MicroTask(微任务)
Process.nextTick(Node独有)、Promise、Object.observe(废弃)、MutationObserver(具体使用方式查看这里)
浏览器中的Event Loop
Javascript 有一个 main thread 主线程和 call-stack 调用栈(执行栈),所有的任务都会被放到调用栈等待主线程执行。
JS调用栈
JS调用栈采用的是后进先出的规则,当函数执行的时候,会被添加到栈的顶部,当执行栈执行完成后,就会从栈顶移出,直到栈内被清空。
同步任务和异步任务
Javascript单线程任务被分为同步任务和异步任务,同步任务会在调用栈中按照顺序等待主线程依次执行,异步任务会在异步任务有了结果后,将注册的回调函数放入任务队列中等待主线程空闲的时候(调用栈被清空),被读取到栈内等待主线程的执行。
Task Queue,即队列,是一种先进先出的一种数据结构。
事件循环的进程模型
- 选择当前要执行的任务队列,选择任务队列中最先进入的任务,如果任务队列为空即
null,则执行跳转到微任务(MicroTask)的执行步骤。 - 将事件循环中的任务设置为已选择任务。
- 执行任务。
- 将事件循环中当前运行任务设置为null。
- 将已经运行完成的任务从任务队列中删除。
- microtasks步骤:进入microtask检查点。
- 更新界面渲染。
- 返回第一步。
执行进入microtask检查点时,用户代理会执行以下步骤:
- 设置microtask检查点标志为true。
- 当事件循环
microtask执行不为空时:选择一个最先进入的microtask队列的microtask,将事件循环的microtask设置为已选择的microtask,运行microtask,将已经执行完成的microtask为null,移出microtask中的microtask。 - 清理IndexDB事务
- 设置进入microtask检查点的标志为false。
上述可能不太好理解,下图是我做的一张图片。
执行栈在执行完同步任务后,查看执行栈是否为空,如果执行栈为空,就会去检查微任务(microTask)队列是否为空,如果为空的话,就执行Task(宏任务),否则就一次性执行完所有微任务。
每次单个宏任务执行完毕后,检查微任务(microTask)队列是否为空,如果不为空的话,会按照先入先出的规则全部执行完微任务(microTask)后,设置微任务(microTask)队列为null,然后再执行宏任务,如此循环。
举个例子
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
复制代码首先我们划分几个分类:
第一次执行:
Tasks:run script、 setTimeout callback
Microtasks:Promise then
JS stack: script
Log: script start、script end。
复制代码执行同步代码,将宏任务(Tasks)和微任务(Microtasks)划分到各自队列中。
第二次执行:
Tasks:run script、 setTimeout callback
Microtasks:Promise2 then
JS stack: Promise2 callback
Log: script start、script end、promise1、promise2
复制代码执行宏任务后,检测到微任务(Microtasks)队列中不为空,执行Promise1,执行完成Promise1后,调用Promise2.then,放入微任务(Microtasks)队列中,再执行Promise2.then。
第三次执行:
Tasks:setTimeout callback
Microtasks:
JS stack: setTimeout callback
Log: script start、script end、promise1、promise2、setTimeout
复制代码当微任务(Microtasks)队列中为空时,执行宏任务(Tasks),执行setTimeout callback,打印日志。
第四次执行:
Tasks:setTimeout callback
Microtasks:
JS stack:
Log: script start、script end、promise1、promise2、setTimeout
复制代码清空Tasks队列和JS stack。
以上执行帧动画可以查看Tasks, microtasks, queues and schedules
或许这张图也更好理解些。
再举个例子
console.log('script start')
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
async1()
setTimeout(function() {
console.log('setTimeout')
}, 0)
new Promise(resolve => {
console.log('Promise')
resolve()
})
.then(function() {
console.log('promise1')
})
.then(function() {
console.log('promise2')
})
console.log('script end')
复制代码这里需要先理解async/await。
async/await 在底层转换成了 promise 和 then 回调函数。
也就是说,这是 promise 的语法糖。
每次我们使用 await, 解释器都创建一个 promise 对象,然后把剩下的 async 函数中的操作放到 then 回调函数中。async/await 的实现,离不开 Promise。从字面意思来理解,async 是“异步”的简写,而 await 是 async wait 的简写可以认为是等待异步方法执行完成。
关于73以下版本和73版本的区别
- 在老版本版本以下,先执行
promise1和promise2,再执行async1。 - 在73版本,先执行
async1再执行promise1和promise2。
主要原因是因为在谷歌(金丝雀)73版本中更改了规范,如下图所示:
- 区别在于
RESOLVE(thenable)和之间的区别Promise.resolve(thenable)。
在老版本中
- 首先,传递给
await的值被包裹在一个Promise中。然后,处理程序附加到这个包装的Promise,以便在Promise变为fulfilled后恢复该函数,并且暂停执行异步函数,一旦promise变为fulfilled,恢复异步函数的执行。 - 每个
await引擎必须创建两个额外的 Promise(即使右侧已经是一个Promise)并且它需要至少三个microtask队列ticks(tick为系统的相对时间单位,也被称为系统的时基,来源于定时器的周期性中断(输出脉冲),一次中断表示一个tick,也被称做一个“时钟滴答”、时标。)。
引用贺老师知乎上的一个例子
async function f() {
await p
console.log('ok')
}
复制代码简化理解为:
function f() {
return RESOLVE(p).then(() => {
console.log('ok')
})
}
复制代码- 如果
RESOLVE(p)对于p为promise直接返回p的话,那么p的then方法就会被马上调用,其回调就立即进入job队列。 - 而如果
RESOLVE(p)严格按照标准,应该是产生一个新的promise,尽管该promise确定会resolve为p,但这个过程本身是异步的,也就是现在进入job队列的是新promise的resolve过程,所以该promise的then不会被立即调用,而要等到当前job队列执行到前述resolve过程才会被调用,然后其回调(也就是继续await之后的语句)才加入job队列,所以时序上就晚了。
谷歌(金丝雀)73版本中
- 使用对
PromiseResolve的调用来更改await的语义,以减少在公共awaitPromise情况下的转换次数。 - 如果传递给
await的值已经是一个Promise,那么这种优化避免了再次创建Promise包装器,在这种情况下,我们从最少三个microtick到只有一个microtick。
详细过程:
73以下版本
- 首先,打印
script start,调用async1()时,返回一个Promise,所以打印出来async2 end。 - 每个
await,会新产生一个promise,但这个过程本身是异步的,所以该await后面不会立即调用。 - 继续执行同步代码,打印
Promise和script end,将then函数放入微任务队列中等待执行。 - 同步执行完成之后,检查微任务队列是否为
null,然后按照先入先出规则,依次执行。 - 然后先执行打印
promise1,此时then的回调函数返回undefinde,此时又有then的链式调用,又放入微任务队列中,再次打印promise2。 - 再回到
await的位置执行返回的Promise的resolve函数,这又会把resolve丢到微任务队列中,打印async1 end。 - 当微任务队列为空时,执行宏任务,打印
setTimeout。
谷歌(金丝雀73版本)
- 如果传递给
await的值已经是一个Promise,那么这种优化避免了再次创建Promise包装器,在这种情况下,我们从最少三个microtick到只有一个microtick。 - 引擎不再需要为
await创造throwaway Promise- 在绝大部分时间。 - 现在
promise指向了同一个Promise,所以这个步骤什么也不需要做。然后引擎继续像以前一样,创建throwaway Promise,安排PromiseReactionJob在microtask队列的下一个tick上恢复异步函数,暂停执行该函数,然后返回给调用者。
具体详情查看(这里)。
NodeJS的Event Loop
Node中的Event Loop是基于libuv实现的,而libuv是 Node 的新跨平台抽象层,libuv使用异步,事件驱动的编程方式,核心是提供i/o的事件循环和异步回调。libuv的API包含有时间,非阻塞的网络,异步文件操作,子进程等等。 Event Loop就是在libuv中实现的。
Node的Event loop一共分为6个阶段,每个细节具体如下:
timers: 执行setTimeout和setInterval中到期的callback。pending callback: 上一轮循环中少数的callback会放在这一阶段执行。idle, prepare: 仅在内部使用。poll: 最重要的阶段,执行pending callback,在适当的情况下回阻塞在这个阶段。check: 执行setImmediate(setImmediate()是将事件插入到事件队列尾部,主线程和事件队列的函数执行完成之后立即执行setImmediate指定的回调函数)的callback。close callbacks: 执行close事件的callback,例如socket.on('close'[,fn])或者http.server.on('close, fn)。
具体细节如下:
timers
执行setTimeout和setInterval中到期的callback,执行这两者回调需要设置一个毫秒数,理论上来说,应该是时间一到就立即执行callback回调,但是由于system的调度可能会延时,达不到预期时间。
以下是官网文档解释的例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
复制代码当进入事件循环时,它有一个空队列(fs.readFile()尚未完成),因此定时器将等待剩余毫秒数,当到达95ms时,fs.readFile()完成读取文件并且其完成需要10毫秒的回调被添加到轮询队列并执行。
当回调结束时,队列中不再有回调,因此事件循环将看到已达到最快定时器的阈值,然后回到timers阶段以执行定时器的回调。
在此示例中,您将看到正在调度的计时器与正在执行的回调之间的总延迟将为105毫秒。
以下是我测试时间:
pending callbacks
此阶段执行某些系统操作(例如TCP错误类型)的回调。 例如,如果TCP socket ECONNREFUSED在尝试connect时receives,则某些* nix系统希望等待报告错误。 这将在pending callbacks阶段执行。
poll
该poll阶段有两个主要功能:
- 执行
I/O回调。 - 处理轮询队列中的事件。
当事件循环进入poll阶段并且在timers中没有可以执行定时器时,将发生以下两种情况之一
- 如果
poll队列不为空,则事件循环将遍历其同步执行它们的callback队列,直到队列为空,或者达到system-dependent(系统相关限制)。
如果poll队列为空,则会发生以下两种情况之一
-
如果有
setImmediate()回调需要执行,则会立即停止执行poll阶段并进入执行check阶段以执行回调。 -
如果没有
setImmediate()回到需要执行,poll阶段将等待callback被添加到队列中,然后立即执行。
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
check
此阶段允许人员在poll阶段完成后立即执行回调。
如果poll阶段闲置并且script已排队setImmediate(),则事件循环到达check阶段执行而不是继续等待。
setImmediate()实际上是一个特殊的计时器,它在事件循环的一个单独阶段运行。它使用libuv API来调度在poll阶段完成后执行的回调。
通常,当代码被执行时,事件循环最终将达到poll阶段,它将等待传入连接,请求等。
但是,如果已经调度了回调setImmediate(),并且轮询阶段变为空闲,则它将结束并且到达check阶段,而不是等待poll事件。
console.log('start')
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(() => {
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
Promise.resolve().then(function() {
console.log('promise3')
})
console.log('end')
复制代码如果node版本为v11.x, 其结果与浏览器一致。
start
end
promise3
timer1
promise1
timer2
promise2
复制代码具体详情可以查看《又被node的eventloop坑了,这次是node的锅》。
如果v10版本上述结果存在两种情况:
- 如果time2定时器已经在执行队列中了
start
end
promise3
timer1
timer2
promise1
promise2
复制代码- 如果time2定时器没有在执行对列中,执行结果为
start
end
promise3
timer1
promise1
timer2
promise2
复制代码具体情况可以参考poll阶段的两种情况。
从下图可能更好理解:
setImmediate() 的setTimeout()的区别
setImmediate和setTimeout()是相似的,但根据它们被调用的时间以不同的方式表现。
setImmediate()设计用于在当前poll阶段完成后check阶段执行脚本 。setTimeout()安排在经过最小(ms)后运行的脚本,在timers阶段执行。
举个例子
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
复制代码执行定时器的顺序将根据调用它们的上下文而有所不同。 如果从主模块中调用两者,那么时间将受到进程性能的限制。
其结果也不一致
如果在I / O周期内移动两个调用,则始终首先执行立即回调:
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
复制代码其结果可以确定一定是immediate => timeout。
主要原因是在I/O阶段读取文件后,事件循环会先进入poll阶段,发现有setImmediate需要执行,会立即进入check阶段执行setImmediate的回调。
然后再进入timers阶段,执行setTimeout,打印timeout。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
复制代码Process.nextTick()
process.nextTick()虽然它是异步API的一部分,但未在图中显示。这是因为process.nextTick()从技术上讲,它不是事件循环的一部分。
process.nextTick()方法将callback添加到next tick队列。 一旦当前事件轮询队列的任务全部完成,在next tick队列中的所有callbacks会被依次调用。
换种理解方式:
- 当每个阶段完成后,如果存在
nextTick队列,就会清空队列中的所有回调函数,并且优先于其他microtask执行。
例子
let bar;
setTimeout(() => {
console.log('setTimeout');
}, 0)
setImmediate(() => {
console.log('setImmediate');
})
function someAsyncApiCall(callback) {
process.nextTick(callback);
}
someAsyncApiCall(() => {
console.log('bar', bar); // 1
});
bar = 1;
复制代码在NodeV10中上述代码执行可能有两种答案,一种为:
bar 1
setTimeout
setImmediate
复制代码另一种为:
bar 1
setImmediate
setTimeout
复制代码无论哪种,始终都是先执行process.nextTick(callback),打印bar 1。
最后
感谢@Dante_Hu提出这个问题await的问题,文章已经修正。 修改了node端执行结果。V10和V11的区别。
关于await问题参考了以下文章:.
《promise, async, await, execution order》
《Normative: Reduce the number of ticks in async/await》
《async/await 在chrome 环境和 node 环境的 执行结果不一致,求解?》
《更快的异步函数和 Promise》
其他内容参考了:
《JS浏览器事件循环机制》
《什么是浏览器的事件循环(Event Loop)?》
《一篇文章教会你Event loop——浏览器和Node》
《不要混淆nodejs和浏览器中的event loop》
《浏览器与Node的事件循环(Event Loop)有何区别?》
《Tasks, microtasks, queues and schedules》
《前端面试之道》
《Node.js介绍5-libuv的基本概念》
《The Node.js Event Loop, Timers, and process.nextTick()》
《node官网》
