
Python虎扑爬取球员生涯数据
一、网络爬虫设计方案
1、爬虫名称:虎扑爬取球员生涯数据
2、内容:虎扑爬取球员生涯数据
3、概述:首先分析页面结构,使用requests模块获取网页源代码,再使用BeautifulSoup解析得到所需要的数据
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
球员生涯数据页面,F12打开审查元素进行分析


通过 devTool工具可以分析网页,找到对应的标签属性
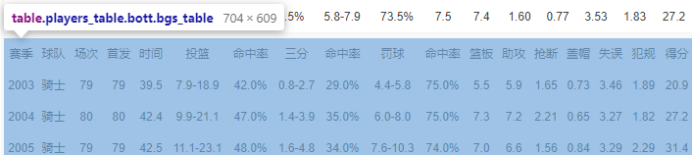
标签;<table class="players_table bott bgs_table">
即 table.players_table.bott.bgs_table 可以获取到整个表格。

第一行是表格的题头,采集数据的时候是不需要。

标签:<tr class="color_font1 borders_btm">
在属性一样的情况下,想要取出生涯数据,必须过滤掉第一个tr标签,才是最后想要的数据!

整理后的选择器代码 table.players_table.bott.bgs_table > tbody > tr.color_font1.borders_btm
三、网络爬虫程序设计
1.数据爬取与采集
读取页面
# -*- coding: utf-8 -*- import requests def duqu(): try: r = requests.get("https://nba.hupu.com/players/lebronjames-650.html") r.raise_for_status() return r.text except: return "打不开"

分析采集
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup
list = [] #数据数组
def getdata(html): #初始化 soup = BeautifulSoup(html, "html.parser") #选择器 table = soup.select("table.players_table.bott.bgs_table > tbody > tr.color_font1.borders_btm") #循环取出每组数据 for tables in table: datas = tables.get_text().split('\n') #去掉数据里的空元素 for i in datas: if len(i) == 0: datas.remove(i) #加入数据组 list.append(datas)
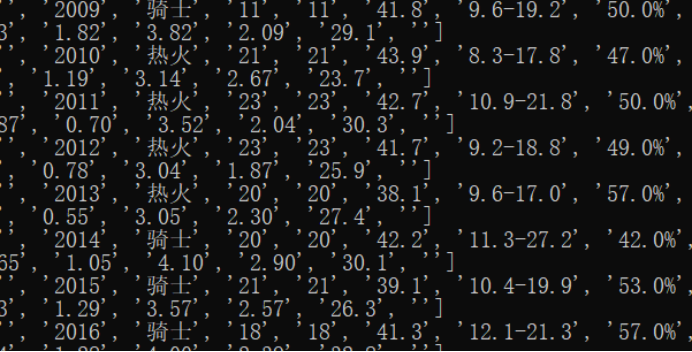
有个问题,有的数据中含有空的成员,要先去掉:

保存数据
#保存数据 fo = open("data.txt", "w+") #循环取出每组数据 for datas in list: #内循环单数据 for i in datas: fo.writelines(i + " ") #大循环换行 fo.writelines("\n") fo.close()

完整代码:
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup list = [] #数据数组 def duqu(): #获取网页数据 try: r = requests.get("https://nba.hupu.com/players/lebronjames-650.html") r.raise_for_status() return r.text except: return "打不开" def getdata(html): #初始化 soup = BeautifulSoup(html, "html.parser") #选择器 table = soup.select("table.players_table.bott.bgs_table > tbody > tr.color_font1.borders_btm") #循环取出每组数据 for tables in table: datas = tables.get_text().split('\n') #去掉数据里的空元素 for i in datas: if len(i) == 0: datas.remove(i) #加入数据组 list.append(datas) #保存数据 fo = open("lebronjames.txt", "w+") #循环取出每组数据 for datas in list: #内循环单数据 for i in datas: fo.writelines(i + " ") #大循环换行 fo.writelines("\n") fo.close() html = duqu() getdata(html)
