

数据采集与融合技术作业四
码云链接
完整代码链接:gitte
作业①:
- 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。 - 候选网站:东方财富网:
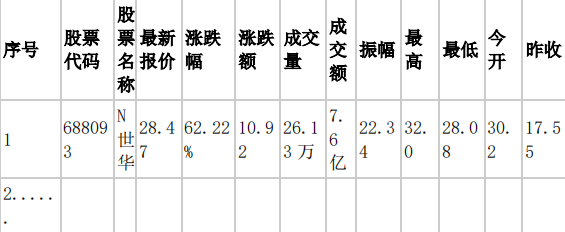
http://quote.eastmoney.com/center/gridlist.html#hs_a_board - 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头:
(1)实验过程
部分代码
- gupiao.py
import sqlite3
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import random
# 声明一个谷歌驱动器
options = webdriver.ChromeOptions()
browser = webdriver.Chrome(options=options)
class stockDB:
def openDB(self):
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("CREATE TABLE stocks (Num VARCHAR(16), stockCode VARCHAR(16), stockName VARCHAR(16), Newprice VARCHAR(16), RiseFallpercent VARCHAR(16), RiseFall VARCHAR(16), Turnover VARCHAR(16), Dealnum VARCHAR(16), Amplitude VARCHAR(16), max VARCHAR(16), min VARCHAR(16), today VARCHAR(16), yesterday VARCHAR(16))")
except sqlite3.OperationalError:
self.cursor.execute("DELETE FROM stocks")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, Num, stockcode, stockname, newprice, risefallpercent, risefall, turnover, dealnum, amplitude, max_price, min_price, today, yesterday):
try:
self.cursor.execute("INSERT INTO stocks (Num, stockCode, stockName, Newprice, RiseFallpercent, RiseFall, Turnover, Dealnum, Amplitude, max, min, today, yesterday) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",
(Num, stockcode, stockname, newprice, risefallpercent, risefall, turnover, dealnum, amplitude, max_price, min_price, today, yesterday))
except Exception as err:
print(err)
def start_spider(url, stockdb):
# 请求url
browser.get(url)
# 开始提取信息
count = 0
markets = ['hs', 'sh', 'sz'] # 将 'str' 改为 'markets'
for i in markets:
WebDriverWait(browser, 1000).until(
EC.presence_of_all_elements_located(
(By.ID, "table_wrapper-table")
)
)
# 随机延迟,等待元素刷新
time.sleep(random.randint(3, 6))
browser.execute_script('document.documentElement.scrollTop=0')
for link in browser.find_elements(By.XPATH, '//tbody/tr'):
count += 1
# 提取数据
id_stock = link.find_element(By.XPATH, './td[position()=2]').text
name = link.find_element(By.XPATH, './/td[@class="mywidth"]').text
new_price = link.find_element(By.XPATH, './/td[@class="mywidth2"]').text
ud_range = link.find_element(By.XPATH, './/td[@class="mywidth"]').text
ud_num = link.find_element(By.XPATH, './td[position()=6]').text
deal_count = link.find_element(By.XPATH, './td[position()=8]').text
turnover = link.find_element(By.XPATH, './td[position()=9]').text
amplitude = link.find_element(By.XPATH, './td[position()=10]').text
high = link.find_element(By.XPATH, './td[position()=11]').text
low = link.find_element(By.XPATH, './td[position()=12]').text
today = link.find_element(By.XPATH, './td[position()=13]').text
yesterday = link.find_element(By.XPATH, './td[position()=14]').text
# 插入数据并打印提取到的数据
print(f"Inserting data: {count}, {id_stock}, {name}, {new_price}, {ud_range}, {ud_num}, {deal_count}, {turnover}, {amplitude}, {high}, {low}, {today}, {yesterday}")
stockdb.insert(count, id_stock, name, new_price, ud_range, str(ud_num), deal_count, turnover, amplitude, high, low, today, yesterday)
item = browser.find_element(By.XPATH, f'//li[@id="nav_{i}_a_board"]')
print(f"Clicking on item: {item}")
item.click()
def main():
stockdb = stockDB() # 创建数据库对象
stockdb.openDB() # 开启数据库
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
start_spider(url, stockdb)
stockdb.closeDB()
if __name__ == '__main__':
main()
# 退出浏览器
browser.quit()
- 说明:这段 Python 代码主要实现了从东方财富网的股票行情页面抓取股票相关信息,并将这些信息存储到 SQLite 数据库中的功能。通过使用 Selenium 库来驱动浏览器进行网页数据的提取,结合 SQLite 数据库操作来保存数据。
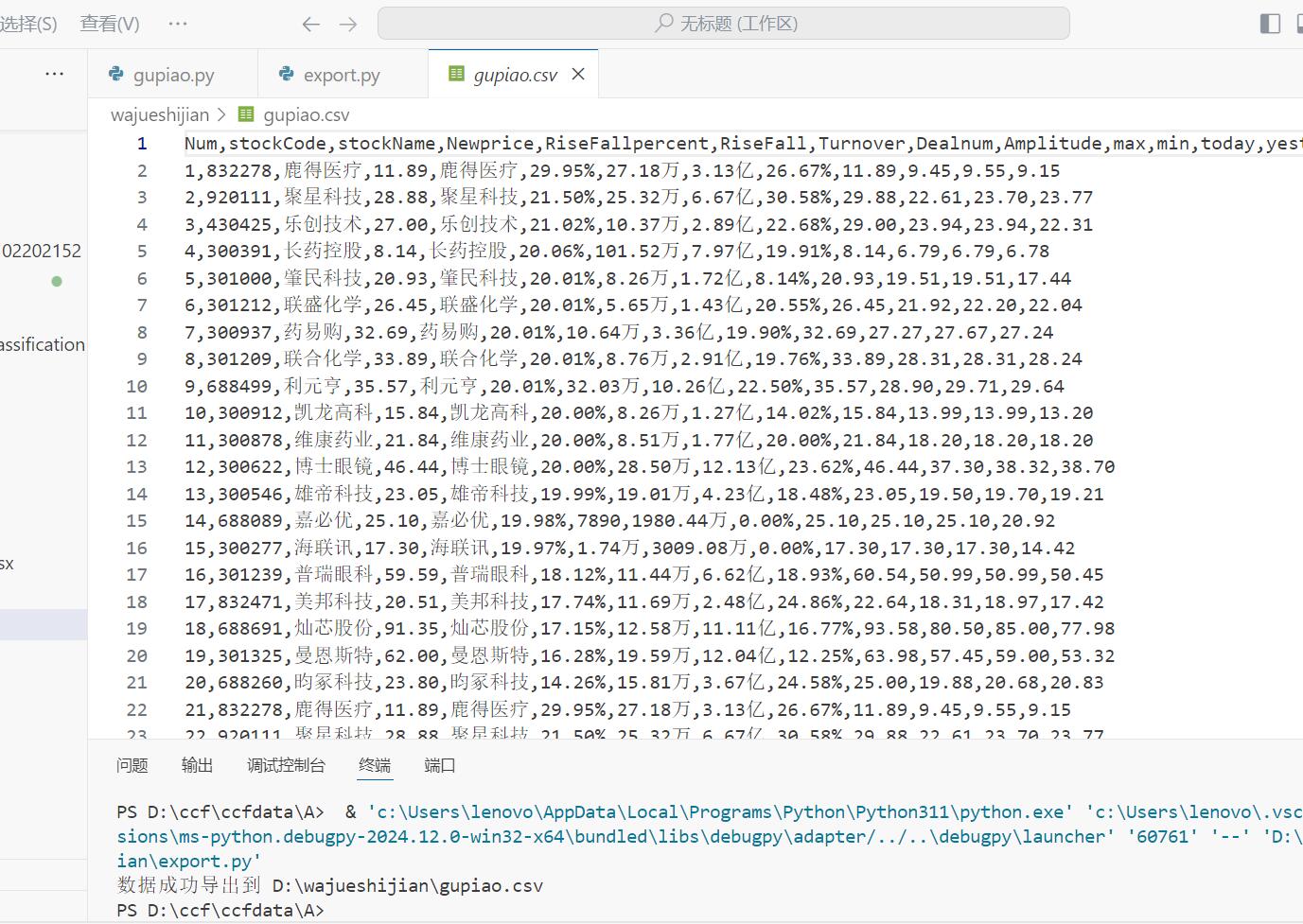
输出结果

(2)心得体会
通过这次作业,深刻体会到 Selenium 在网页数据爬取方面的强大功能。它能够模拟真实用户在浏览器中的操作,轻松地查找各种 HTML 元素,无论是通过 ID、XPATH 还是其他定位方式。比如在最初爬取东方财富网股票数据时,能够准确地定位到包含股票信息的表格行、列等元素,从而提取出所需的详细数据,这让我认识到掌握多种元素定位方法的重要性,以便应对不同网页结构的情况。而且,等待 HTML 元素加载完成的机制也非常关键,避免了因页面加载不及时而导致的数据提取错误或程序异常,确保了整个爬取过程的稳定性。
作业②:
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
- 候选网站:中国 mooc 网:https://www.icourse163.org
- 输出信息:MYSQL 数据库存储和输出格式
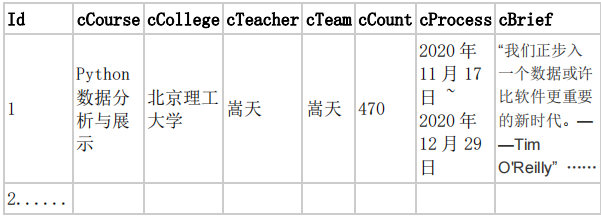
(1)实验过程
部分代码
export2.py
import sqlite3
import csv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
import random
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
url = "https://www.icourse163.org/search.htm?search=%E6%95%B0%E5%80%BC%E5%88%86%E6%9E%90#/"
class moocDB:
def openDB(self):
self.con = sqlite3.connect("mooc.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("CREATE TABLE mooc (Num VARCHAR(16), Name VARCHAR(16), School VARCHAR(16), Teacher VARCHAR(16), Team VARCHAR(16), Person VARCHAR(16), Jindu VARCHAR(16), Jianjie VARCHAR(16))")
except sqlite3.OperationalError:
self.cursor.execute("DELETE FROM mooc")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, count, name, school, teacher, team, person, jindu, jianjie):
print(f"Inserting record {count}: Name={name}, School={school}, Teacher={teacher}, Team={team}, Person={person}, Jindu={jindu}, Jianjie={jianjie}")
self.cursor.execute("INSERT INTO mooc (Num, Name, School, Teacher, Team, Person, Jindu, Jianjie) VALUES (?, ?, ?, ?, ?, ?, ?, ?)",
(count, name, school, teacher, team, person, jindu, jianjie))
def export_to_csv(self, csv_path):
# 导出数据库数据到 CSV 文件
self.cursor.execute("SELECT * FROM mooc")
rows = self.cursor.fetchall()
# 写入 CSV 文件
with open(csv_path, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Num', 'Name', 'School', 'Teacher', 'Team', 'Person', 'Jindu', 'Jianjie']) # Header
writer.writerows(rows)
print(f"Data exported to {csv_path}")
def login():
login_button = browser.find_element(By.XPATH, '//a[@class="f-f0 navLoginBtn"]')
login_button.click()
frame = browser.find_element(By.XPATH, '//div[@class="ux-login-set-container"]/iframe')
browser.switch_to.frame(frame)
inputUserName = browser.find_element(By.XPATH, '//div[@class="u-input box"][1]/input')
inputUserName.send_keys("13850627483")
inputPasswd = browser.find_element(By.XPATH, '//div[@class="inputbox"]/div[2]/input[2]')
inputPasswd.send_keys("Yying0201.")
login_button = browser.find_element(By.XPATH, '//*[@id="submitBtn"]')
login_button.click()
time.sleep(5)
def next_page():
next_button = browser.find_element(By.XPATH, '//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
next_button.click()
def start_spider(moocdb):
browser.get(url)
count = 0
for i in range(2):
WebDriverWait(browser, 1000).until(EC.presence_of_all_elements_located((By.ID, "j-courseCardListBox")))
time.sleep(random.randint(3, 6))
browser.execute_script('document.documentElement.scrollTop=0')
for link in browser.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
count += 1
try:
name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
except:
name = 'none'
try:
school = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
except:
school = 'none'
try:
teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text
except:
teacher = 'none'
try:
team = link.find_element(By.XPATH, './/span[@class="f-fc9"]').text
except:
team = 'none'
try:
person = link.find_element(By.XPATH, './/span[@class="hot"]').text
except:
person = 'none'
try:
jindu = link.find_element(By.XPATH, './/span[@class="txt"]').text
except:
jindu = 'none'
try:
jianjie = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
except:
jianjie = 'none'
moocdb.insert(count, name, school, teacher, team, person, jindu, jianjie)
next_page()
login()
def main():
moocdb = moocDB()
moocdb.openDB()
start_spider(moocdb)
# 将数据库导出到CSV
csv_path = r"D:\wajueshijian\mooc.csv"
moocdb.export_to_csv(csv_path)
moocdb.closeDB()
if __name__ == '__main__':
main()
browser.quit()
- 说明:
这段代码主要实现了从网易云课堂(根据给定的网址推测)搜索页面爬取课程相关信息,将这些信息存储到 SQLite 数据库中,之后再把数据库中的数据导出为 CSV 文件的功能。同时,代码中还包含了登录操作,可能是用于获取更多完整信息或者满足后续某种操作的权限需求(虽然在当前代码逻辑下,登录操作在数据爬取完成两轮循环后才执行,可能存在一些不合理之处,后续可根据实际需求调整顺序)
程序结果
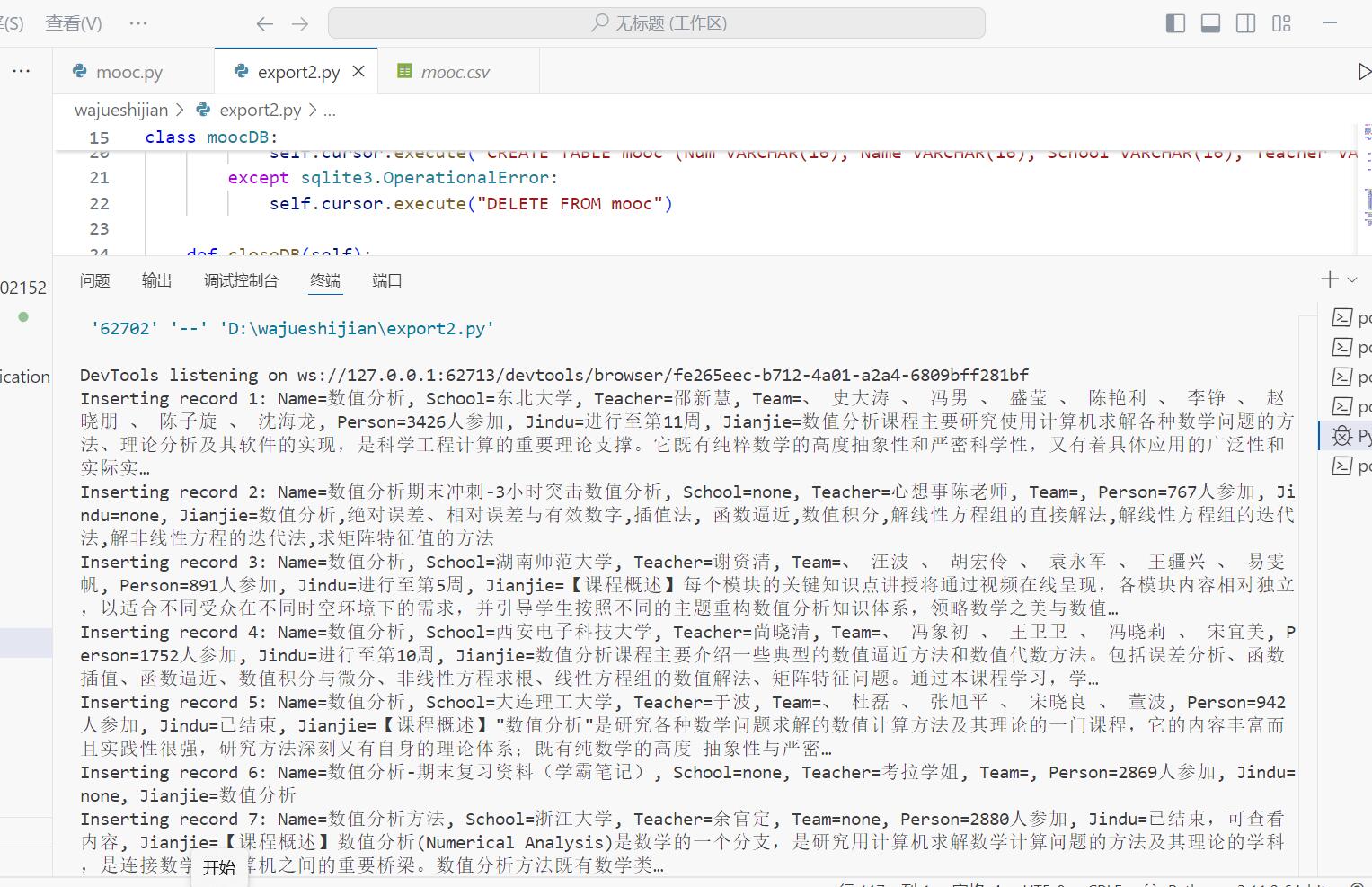
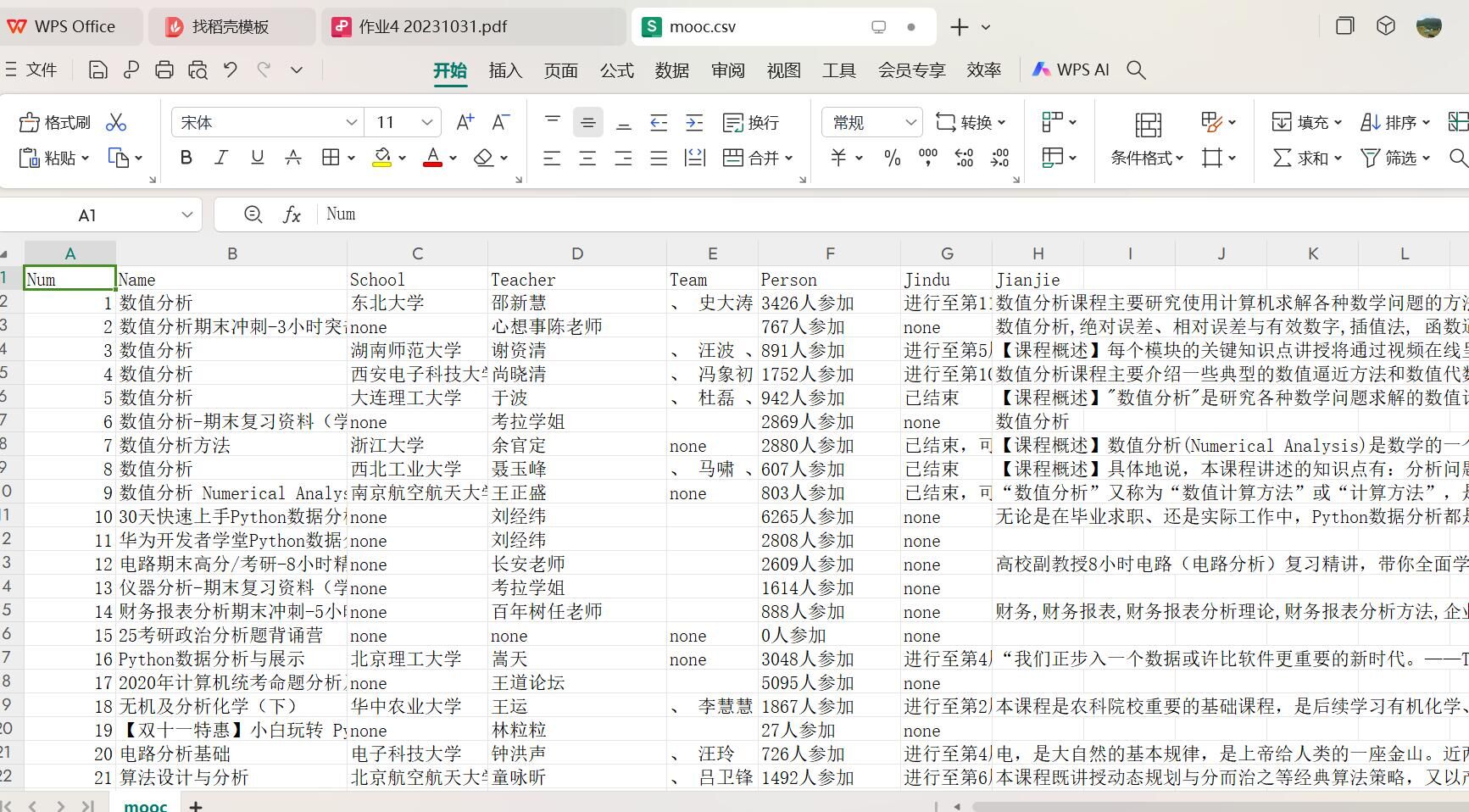
(2)心得体会
实现用户模拟登录是一个重要环节。在代码中,通过模拟点击登录按钮、切换到登录 iframe 框架,然后输入用户名和密码的操作,成功实现了登录功能。这让我明白了如何处理网站的登录机制,特别是在有 iframe 嵌套的情况下。了解到要在正确的页面上下文(如 iframe 内部)中进行操作,才能准确地与登录相关的元素进行交互,这对于获取需要登录才能查看的信息至关重要。

