


数据采集与融合技术作业三
码云链接
完整代码链接:gitte
作业①:
- 要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 - 输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
- 我爬取的是亚马逊网站
(1)实验过程
部分代码
- pipeline.py
import urllib.request
import time
class Work1Pipeline2:
def __init__(self):
self.counter = 1
def process_item(self, item, spider):
urls = item.get('src')
urls.pop()
urls.pop(0)
# print(urls)
for url in urls:
filename = 'D:\wajueshijian\images' + str(self.counter) + '.jpg'
print('第'+str(self.counter)+'张图片:'+url)
urllib.request.urlretrieve(url=url, filename=filename)
self.counter += 1
if(self.counter > 102):
break
return item
- 说明:这段代码主要就是从 item 获取图片链接,下载并计数保存到本地
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Work1Item(scrapy.Item):
src = scrapy.Field()
- 说明:定义 Scrapy 的 Item,包含一个 src 字段用于图片链接
MySpider_amazon.py
import scrapy
from..items import Work1Item
class MySpider(scrapy.Spider):
# 爬虫的名字
name = 'MySpider_amazon'
start_urls = []
# 构造start_urls
for i in range(1, 101):
url = f"https://www.amazon.cn/s?k=%E4%B9%A6%E5%8C%85&page={i}&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A&crid=1RAID9NTPCARM&qid=1698238172&sprefix=%E4%B9%A6%E5%8C%85%2Caps%2C154&ref=sr_pg_{i}"
start_urls.append(url)
def parse(self, response):
# 提取图片URL
src = response.xpath('//img/@src').extract()
img = Work1Item(src=src)
yield img
# 提取下一页链接并继续爬取
next_page = response.xpath('//a[@class="s-pagination-item s-pagination-next s-pagination-button s-pagination-disabled"]/@href').extract_first()
if next_page:
yield scrapy.Request(next_page, callback=self.parse)
- 说明:此段代码构造多页搜索书包的起始网址,提取图片链接并通过下一页链接持续爬取
输出结果
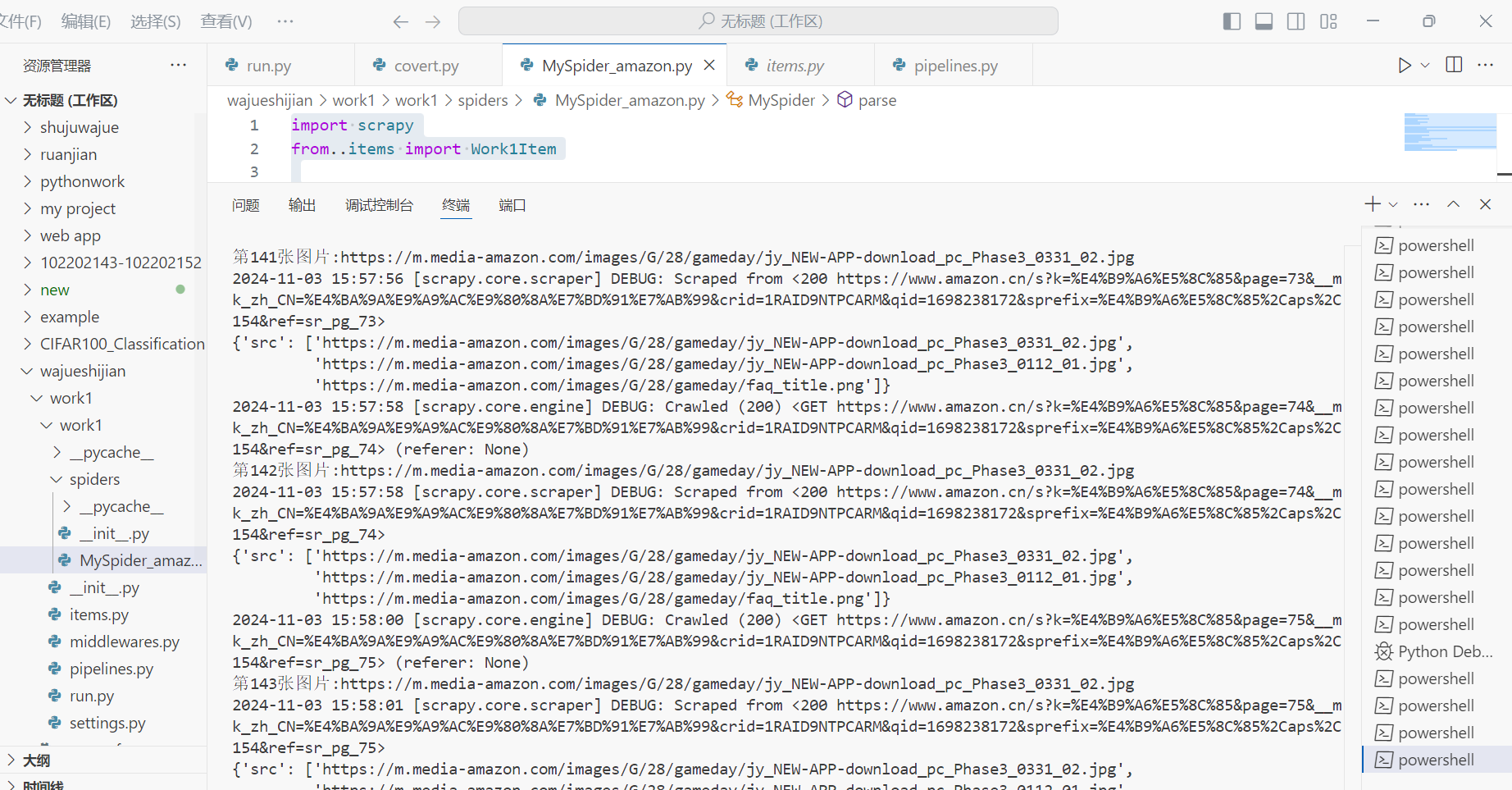

- 总页数52(学号尾数2位)、总下载的图片数量152(尾数后3位)
(2)心得体会
在本次作业中,我成功地使用Scrapy框架爬取了亚马逊网站上的信息。在这次实践中Scrapy 框架展现出了强大的功能和高效性。它的模块化设计使得代码结构清晰,易于理解和维护。例如,在定义Item时,能够清晰地规划要爬取的数据结构,如Work1Item中的src字段用于存储图片链接,这种结构化的设计为后续的数据处理提供了极大的便利。在Work1Pipeline2中,对爬取到的数据进行了进一步的处理。不仅对图片链接进行了筛选和整理,还通过urllib.request.urlretrieve方法将图片下载到本地,并进行了计数和文件名的设置,实现了数据从网页到本地的有效迁移和整理。通过本次使用 Scrapy 框架爬取亚马逊网站信息的实践,我不仅掌握了 Scrapy 框架的基本使用方法和技巧,还对网络爬虫的整个流程有了更深入的理解。在未来的学习和实践中,我将继续探索 Scrapy 框架的更多功能和应用场景,尝试解决更大规模和更复杂的数据爬取问题,同时也会关注网络爬虫的合法性和道德规范,确保在合法合规的前提下充分发挥网络爬虫的价值。
作业②:
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
- 候选网站:东方财富网:https://www.eastmoney.com/
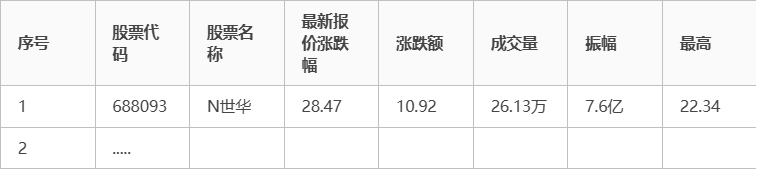
新浪股票:http://finance.sina.com.cn/stock/ - 输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
(1)实验过程
部分代码
- items.py
- 说明:这段代码定义 Work2Item 类,用于 Scrapy 框架爬取数据。包含多种字段,如价格、成交量等,以结构化存储爬取信息。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Work2Item(scrapy.Item):
Num = scrapy.Field()
daima = scrapy.Field()
name = scrapy.Field()
newprice = scrapy.Field()
diefu = scrapy.Field()
dieer = scrapy.Field()
chengjiaoliang = scrapy.Field()
chengjiaoer = scrapy.Field()
zhenfu = scrapy.Field()
max = scrapy.Field()
min = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
pass
- pipelines.py
- 说明:这段代码定义 Work2Pipeline 类,用于处理数据并存储到 SQLite 数据库,包括数据库操作方法。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import sqlite3
class Work2Pipeline:
def openDB(self, spider):
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("create table if not exists stocks (Num varchar(16), stockCode varchar(16),stockName varchar(16),Newprice varchar(16),RiseFallpercent varchar(16),RiseFall varchar(16),Turnover varchar(16),Dealnum varchar(16),Amplitude varchar(16),max varchar(16),min varchar(16),today varchar(16),yesterday varchar(16))")
except:
self.cursor.execute("delete from stocks")
def process_item(self, item, spider):
sql = "insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
params = list()
params.append(item['Num'])
params.append(['daima'])
params.append(item['name'])
params.append(item['newprice'])
params.append(item['diefu'])
params.append(item['dieer'])
params.append(item['chengjiaoliang'])
params.append(item['chengjiaoer'])
params.append(item['zhenfu'])
params.append(item['max'])
params.append(item['min'])
params.append(item['today'])
params.append(item['yesterday'])
self.cursor.execute(sql, tuple(params))
self.con.commit()
return item
def closeDB(self, spider):
self.con.commit()
self.con.close()
- export_to_csv.py
- 说明:这段代码是进行把输出的.db文件转化.csv文件,用excel打开
import sqlite3
import csv
# 连接到SQLite数据库
conn = sqlite3.connect('stocks.db')
cursor = conn.cursor()
# 指定要导出的表名和CSV文件名
table_name = 'stocks'
csv_file_name = '股票1.csv'
# 使用CSV模块将数据写入CSV文件
with open(csv_file_name, 'w', newline='', encoding='utf-8') as csvfile:
cursor.execute(f'SELECT * FROM "{table_name}"')
headers = [description[0] for description in cursor.description]
writer = csv.writer(csvfile)
writer.writerow(headers)
for row in cursor.fetchall():
writer.writerow(row)
# 关闭连接
conn.close()
print(f"数据已成功导出到 {csv_file_name}")
- MySpider.py
- 说明:这段代码通过Scrapy 爬虫,爬取股票信息网页,处理数据并存入数据库,包括获取内容和解析响应的方法。
import scrapy
import re
from work2.items import Work2Item
from work2.pipelines import Work2Pipeline
class MySpider(scrapy.Spider):
name = 'MySpider'
start_urls = []
for i in range(1,3):
url =f"http://45.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124030395806868839914_1696659472380&pn={i}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696659472381"
start_urls.append(url)
global num
print("序号", "股票代码", "股票名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收", chr(12288))
def getContent(html):
stocks = re.findall("\"diff\":\[(.*?)]", html)
print(stocks)
stocks = list(eval(stocks[0]))
print(stocks)
num = 0
result = []
for stock in stocks:
num += 1
daima = stock["f12"]
name = stock["f14"]
newprice = stock["f2"]
diefu = stock["f3"]
dieer = stock["f4"]
chengjiaoliang = stock["f5"]
chengjiaoer = stock["f6"]
zhenfu = stock["f7"]
max = stock["f15"]
min = stock["f16"]
today = stock["f17"]
yesterday = stock["f18"]
result.append(
[num, daima, name, newprice, diefu, dieer, chengjiaoliang, chengjiaoer, zhenfu, max, min, today,
yesterday])
#print(result)
return result
def parse(self, response):
stockdb = Work2Pipeline()
stockdb.openDB(MySpider)
html = response.text
stocks = MySpider.getContent(html)
print(stocks)
for stock in stocks:
item = Work2Item()
item['Num'] = stock[0]
item['daima'] = stock[1]
item['name']= stock[2]
item['newprice']= stock[3]
item['diefu']=stock[4]
item['dieer']=stock[5]
item['chengjiaoliang']=stock[6]
item['chengjiaoer']=stock[7]
item['zhenfu']=stock[8]
item['max']=stock[9]
item['min']=stock[10]
item['today']=stock[11]
item['yesterday']=stock[12]
print(stock[0], stock[1], stock[2], stock[3], stock[4], stock[5], stock[6], stock[7], stock[8],stock[9], stock[10], stock[11], stock[12], chr(12288))
stockdb.process_item(item,MySpider)
yield item
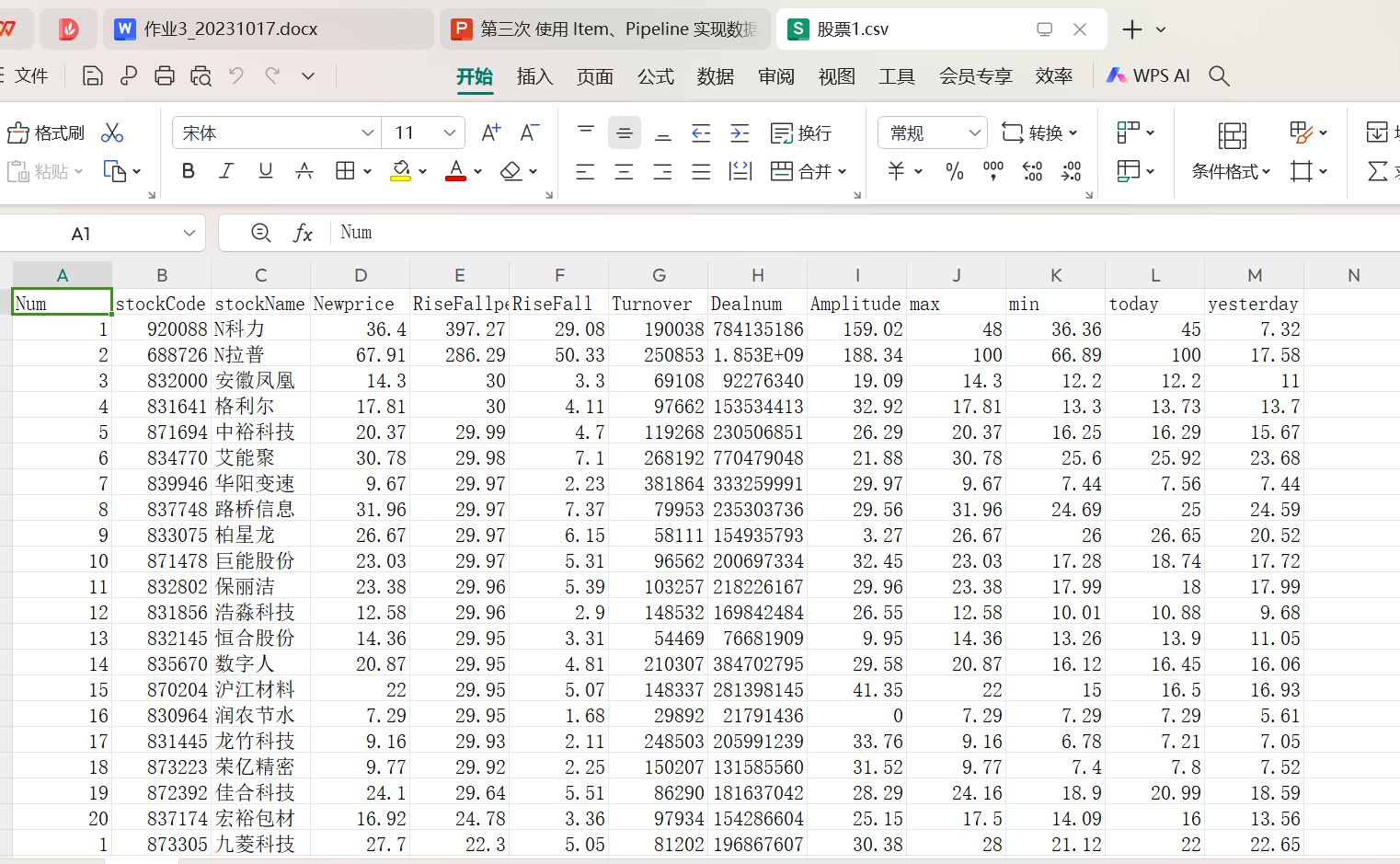
程序结果
(2)心得体会
在这次的实践中。我学会了如何处理动态网页数据。在爬取股票信息的过程中,面对通过 API 获取数据的网页,学会了使用正则表达式提取关键信息,并将其转化为可用的数据格式。同时也遇到了一些问题,股票信息网页的结构较为复杂,需要仔细分析页面的请求和响应,找到关键数据的位置。通过查看网页源代码、使用开发者工具以及不断尝试不同的 XPath 和正则表达式,最终成功提取到了所需的数据。
作业③:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
-
输出信息:

(1)实验过程
部分代码
- pipelines.py
- 说明:这段代码主要就是定义处理外汇数据的管道类,连接到 SQLite 数据库,创建表并存储外汇数据项
# useful for handling different item types with a single interface
import sqlite3
from itemadapter import ItemAdapter
class Work3Pipeline:
def openDB(self, spider):
self.con = sqlite3.connect("waihui.db")
self.cursor = self.con.cursor()
try:
print("尝试创建表...")
self.cursor.execute("create table if not exists waihui (Currency varchar(16), TBP varchar(16),CBP varchar(16),TSP varchar(16),CSP varchar(16),Time varchar(16))")
print("表创建成功")
except:
print("创建表出现异常,尝试删除数据")
self.cursor.execute("delete from waihui")
def process_item(self, item, spider):
sql = "insert into waihui(Currency,TBP,CBP,TSP,CSP,Time) values (?,?,?,?,?,?)"
params = list()
params.append(item['Currency'])
params.append(item['TBP'])
params.append(item['CBP'])
params.append(item['TSP'])
params.append(item['CSP'])
params.append(item['Time'])
self.cursor.execute(sql, tuple(params))
self.con.commit()
return item
def closeDB(self, spider):
self.con.commit()
self.con.close()
- run.py
- 说明:通过命令行执行名为 “MySpider” 的爬虫,并关闭日志输出,用于启动爬虫程序。
from scrapy import cmdline
cmdline.execute("scrapy crawl MySpider -s LOG_ENABLED=False".split())
- Myspider.py
- 说明:这段代码通过Scrapy 爬虫爬取中国银行外汇牌价网页,将数据存入数据库,定义了解析方法和数据项。
import scrapy
from work3.items import Work3Item
from work3.pipelines import Work3Pipeline
class MySpider(scrapy.Spider):
name = 'MySpider'
start_urls =["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
waihuidb = Work3Pipeline()
waihuidb.openDB(MySpider)
items = response.xpath('//tr[position()>1]')
for i in items:
item = Work3Item()
item['Currency'] = i.xpath('.//td[1]/text()').get()
item['TBP'] = i.xpath('.//td[2]/text()').get()
item['CBP']= i.xpath('.//td[3]/text()').get()
item['TSP']= i.xpath('.//td[4]/text()').get()
item['CSP']=i.xpath('.//td[5]/text()').get()
item['Time']=i.xpath('.//td[8]/text()').get()
print(item)
waihuidb.process_item(item,MySpider)
yield item
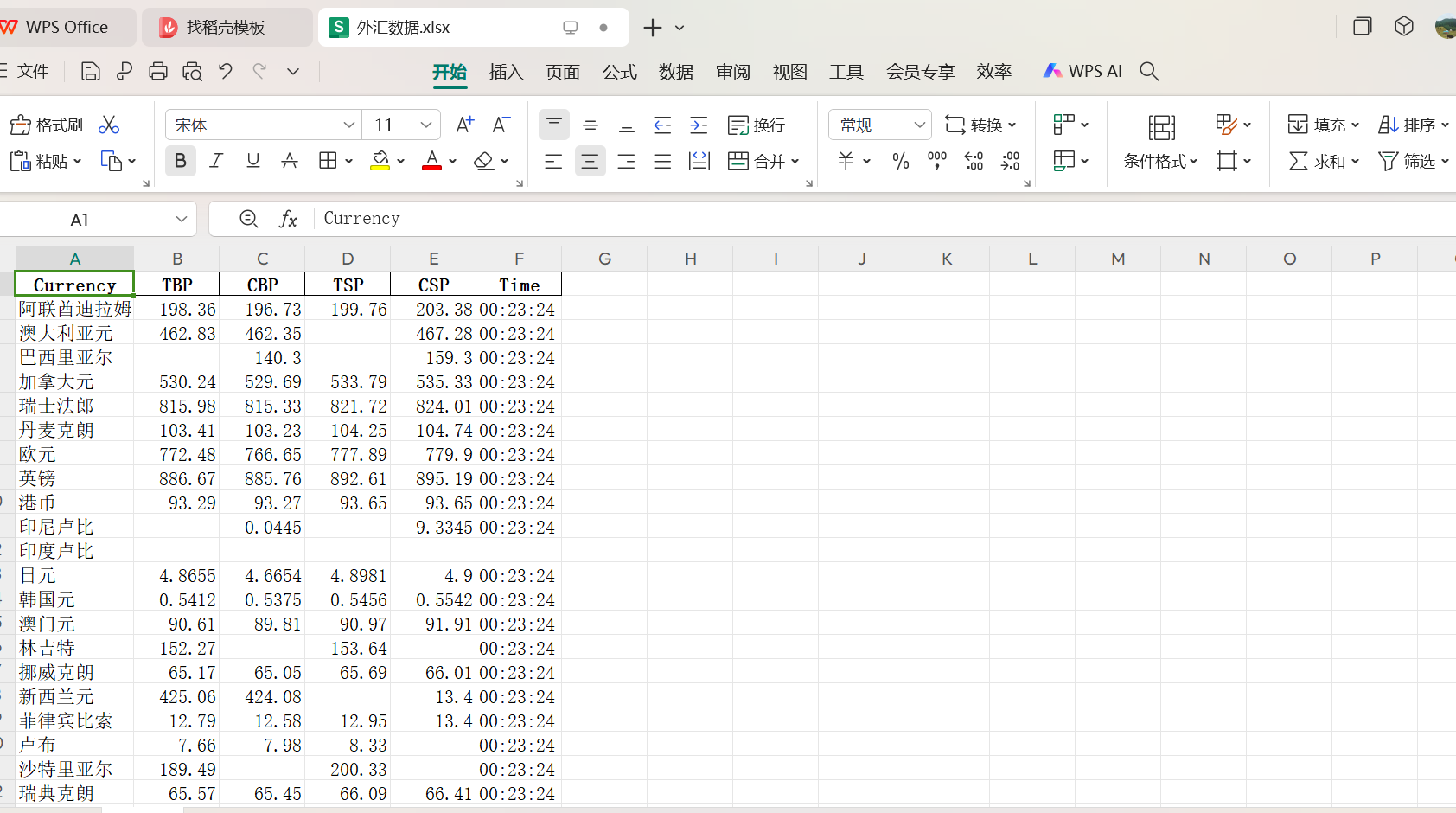
输出结果
(2)心得体会
在这次的实践中,我学会了处理复杂网页结构。在爬取外汇信息的过程中,面对中国银行外汇牌价网页的特定结构,运用 XPath 进行数据定位和提取,提高了对网页解析技术的掌握程度。并且在这次的实践中我遇到了一个比较难排查的问题,就是表创建不成功,通过不断尝试和排查,获得了很多宝贵的经验。首先就是问题排查过程:仔细检查了代码中的数据库操作部分,包括表创建语句的语法是否正确、数据库连接是否正常等。同时,也考虑了可能的权限问题和数据库版本兼容性问题。而后就是学习与探索:在解决问题的过程中,查阅了大量的文档和资料,学习了 SQLite 的更多特性和使用方法。尝试了不同的解决方案,如在不同的环境下运行代码、调整表创建语句的参数等。最后终于解决了这个问题。
