


数据采集与融合技术实践作业二
码云链接:数据采集与融合技术码云
下面作业完整代码链接:gitee链接
作业①:
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的 7
日天气预报,并保存在数据库。 - 输出信息:Gitee 文件夹链接
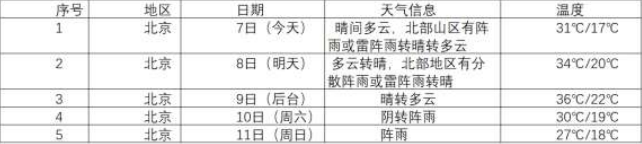
(1)实验过程
代码实现
from bs4 import BeautifulSoup
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
self.cursor.execute("CREATE TABLE IF NOT EXISTS weathers (wCity VARCHAR(16), wDate VARCHAR(16), wWeather VARCHAR(64), wTemp VARCHAR(32), PRIMARY KEY (wCity, wDate))")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("INSERT INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)", (city, date, weather, temp))
except sqlite3.IntegrityError as err:
print(f"Error inserting data: {err}")
def show(self):
self.cursor.execute("SELECT * FROM weathers")
rows = self.cursor.fetchall()
print("%-16s %-16s %-32s %-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s %-16s %-32s %-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode:
print(f"{city} code cannot be found")
return
url = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req).read()
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except IndexError as err:
print(f"Error parsing data: {err}")
except urllib.error.URLError as err:
print(f"Error fetching data: {err}")
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("Completed")
代码实现
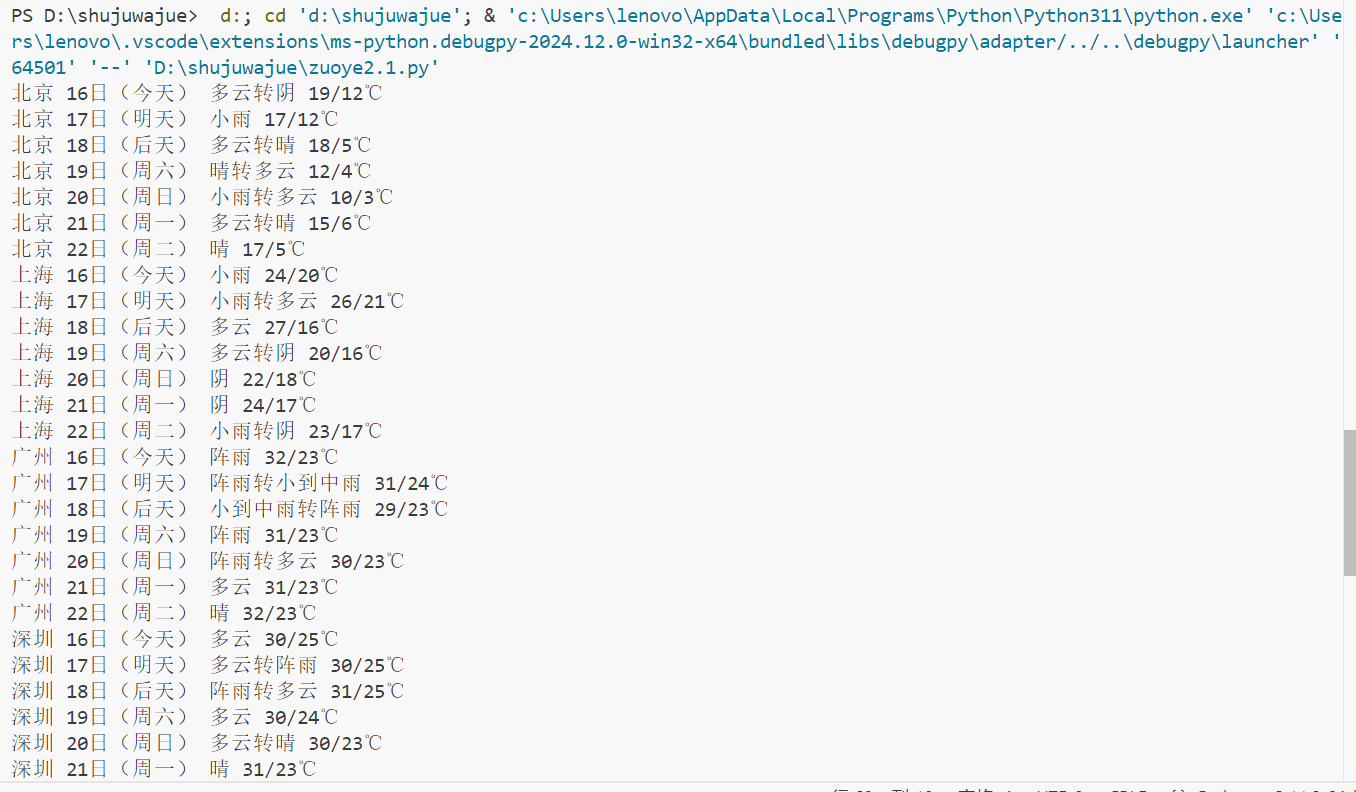
输出:
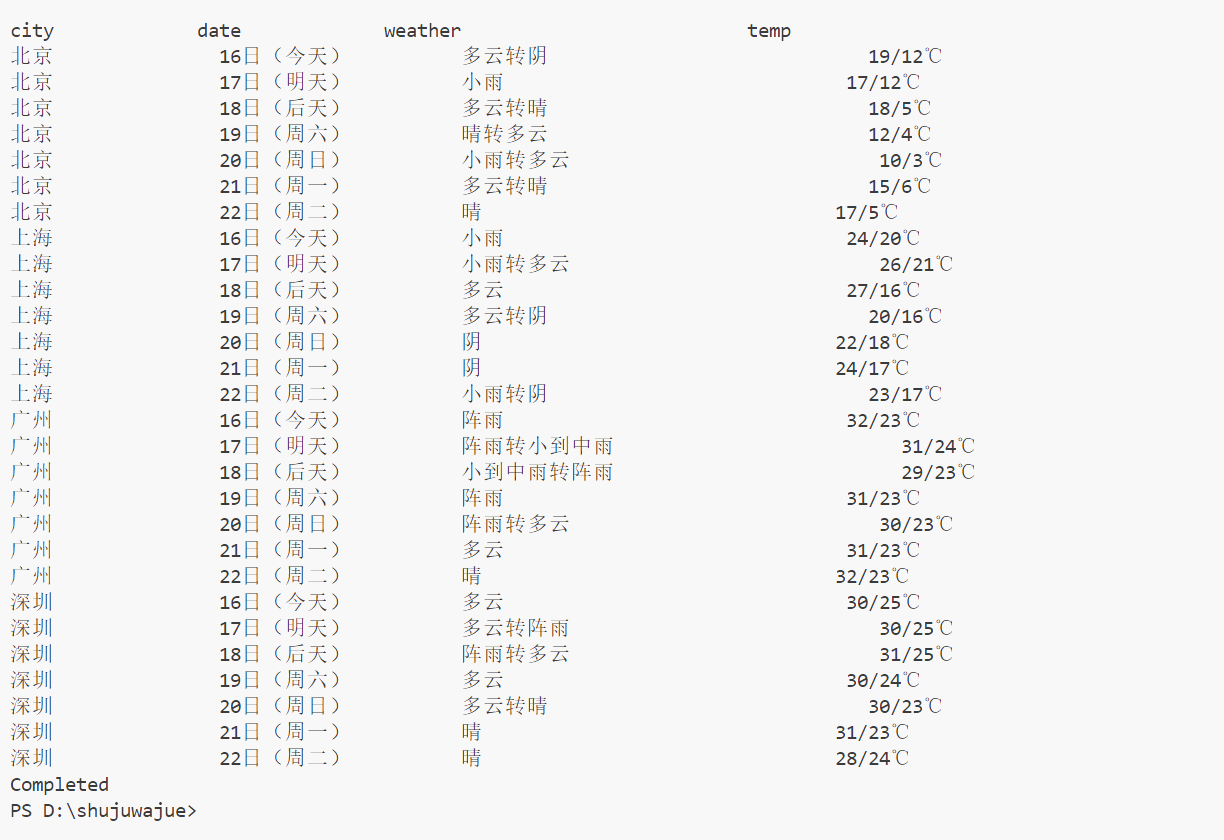
数据库输出:
(2)心得体会
用urllib.request库模拟浏览器请求,获取网页内容。这是数据抓取的第一步,也是获取网页数据的基础。代码中多处使用了try-except块来捕获和处理可能发生的异常,如网络请求失败、HTML解析错误等。这增强了代码的健壮性和容错能力。这次的作业不仅让我学到了网页数据抓取、数据库操作、异常处理等具体技能,更重要的是,它让我更加深入地理解了编程的实用性和问题解决能力的重要性。通过实践这些技能,我能够更自信地应对未来的编程挑战。
作业②:
- 要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并
存储在数据库中。 - 输出信息:Gitee 文件夹链接
(1)实验过程
通过F2抓包结果:
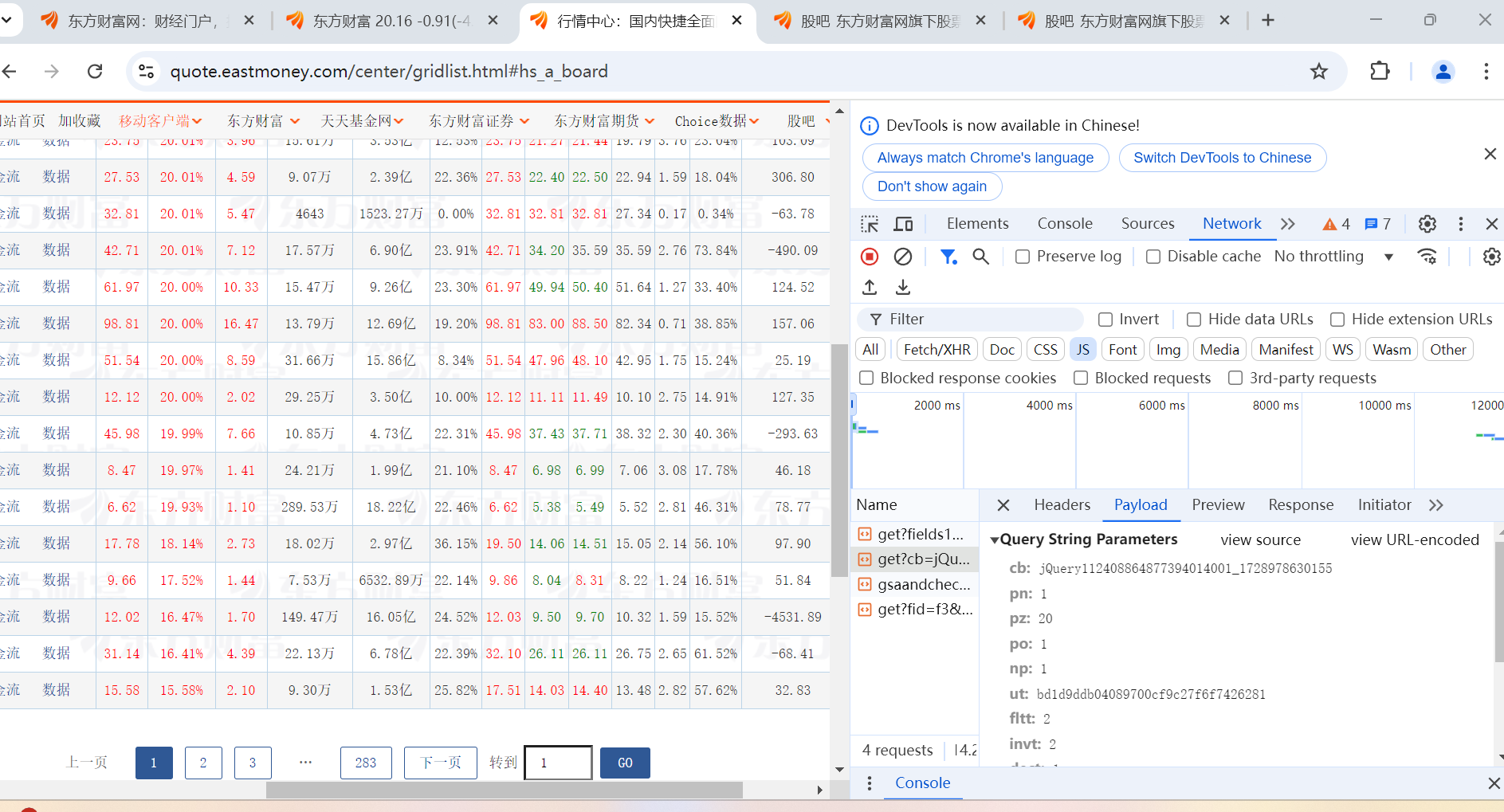
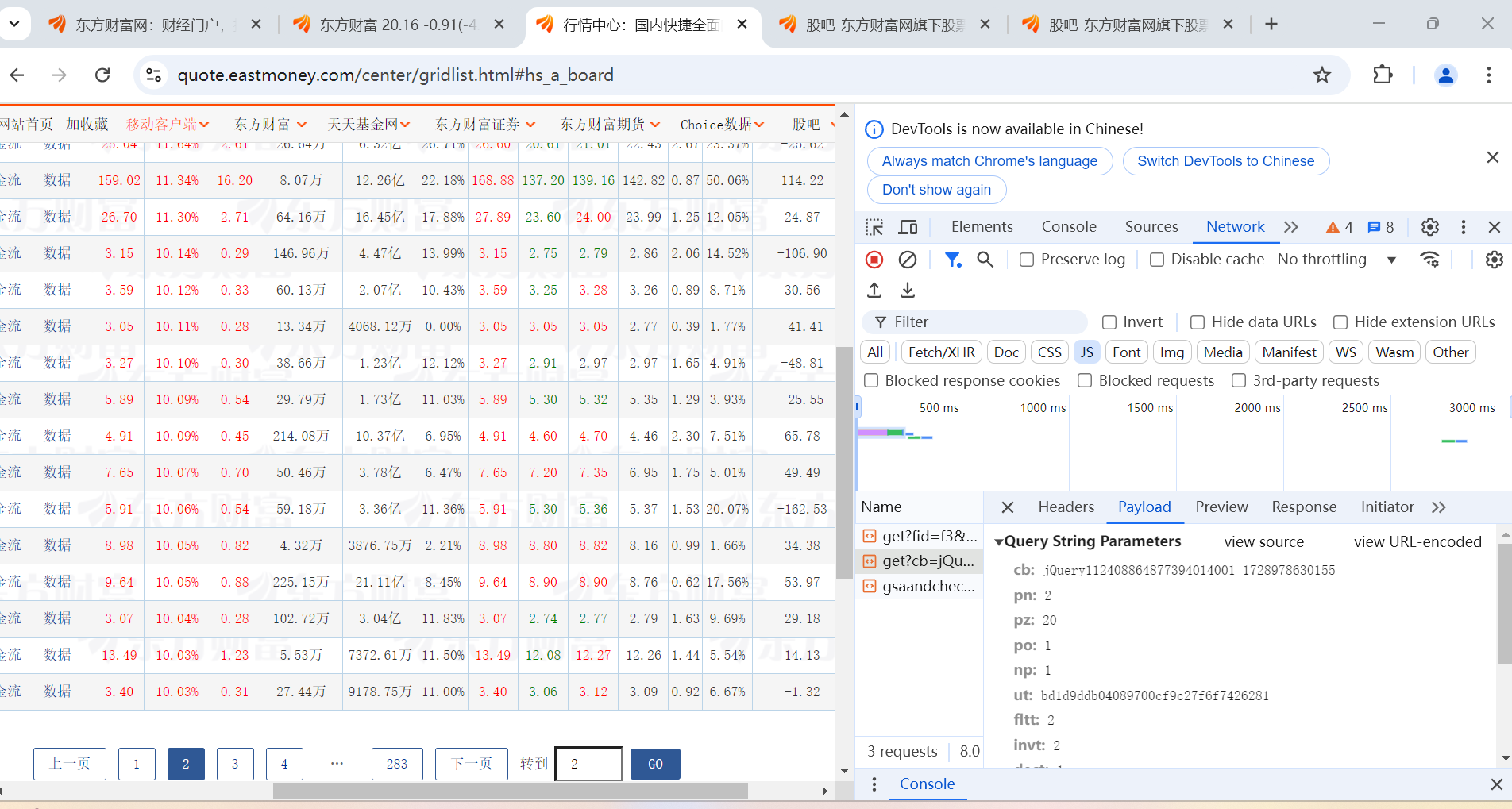
代码实现
import sqlite3
import requests
import json
from tabulate import tabulate
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47",
"Cookie": "qgqp_b_id=4a3c0dd089eb5ffa967fcab7704d27cd; st_si=19699330068294; st_asi=delete; st_pvi=76265126887030; st_sp=2021-12-18%2022%3A56%3A16; st_inirUrl=https%3A%2F%2Fcn.bing.com%2F; st_sn=2; st_psi=20231007141245108-113200301321-7681547675"
}
response = requests.get(url, headers=headers)
return response.text
def parse_html(html):
data = json.loads(html[html.find('(') + 1:html.find(')')])
stocks = data['data']['diff']
result = []
for index, stock in enumerate(stocks, start=1):
stock_code = stock['f12']
stock_name = stock['f14']
new_price = stock['f2']
change_percent = stock['f3']
change_amount = stock['f4']
volume = stock['f5']
turnover = stock['f6']
amplitude = stock['f7']
high = stock['f15']
low = stock['f16']
open_price = stock['f17']
prev_close = stock['f18']
result.append([index, stock_code, stock_name, new_price, change_percent, change_amount, volume, turnover, amplitude, high, low, open_price, prev_close])
return result
class StockDB:
def __init__(self):
self.conn = None
self.cursor = None
def open_connection(self):
self.conn = sqlite3.connect("stocks.db")
self.cursor = self.conn.cursor()
try:
self.cursor.execute("CREATE TABLE IF NOT EXISTS stocks (Num VARCHAR(16), stockCode VARCHAR(16), stockName VARCHAR(16), Newprice VARCHAR(16), RiseFallpercent VARCHAR(16), RiseFall VARCHAR(16), Turnover VARCHAR(16), Dealnum VARCHAR(16), Amplitude VARCHAR(16), max VARCHAR(16), min VARCHAR(16), today VARCHAR(16), yesterday VARCHAR(16))")
except Exception as e:
print(f"创建表失败: {e}")
def close_connection(self):
if self.conn:
self.conn.commit()
self.conn.close()
def insert_stock_data(self, data):
try:
self.cursor.execute("INSERT INTO stocks VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?)", data)
except Exception as e:
print(f"插入数据失败: {e}")
# 表头
headers = ["序号", "股票代码", "股票名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
print(tabulate([], headers=headers, tablefmt="grid"))
db = StockDB()
db.open_connection()
for page in range(1, 3):
url = f"http://45.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124030395806868839914_1696659472380&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696659472381"
html = get_html(url)
stocks = parse_html(html)
for stock in stocks:
print(tabulate([stock], headers=headers, tablefmt="grid"))
db.insert_stock_data(stock)
db.close_connection()
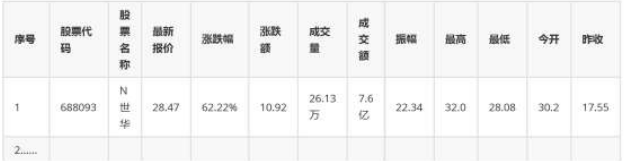
代码结果
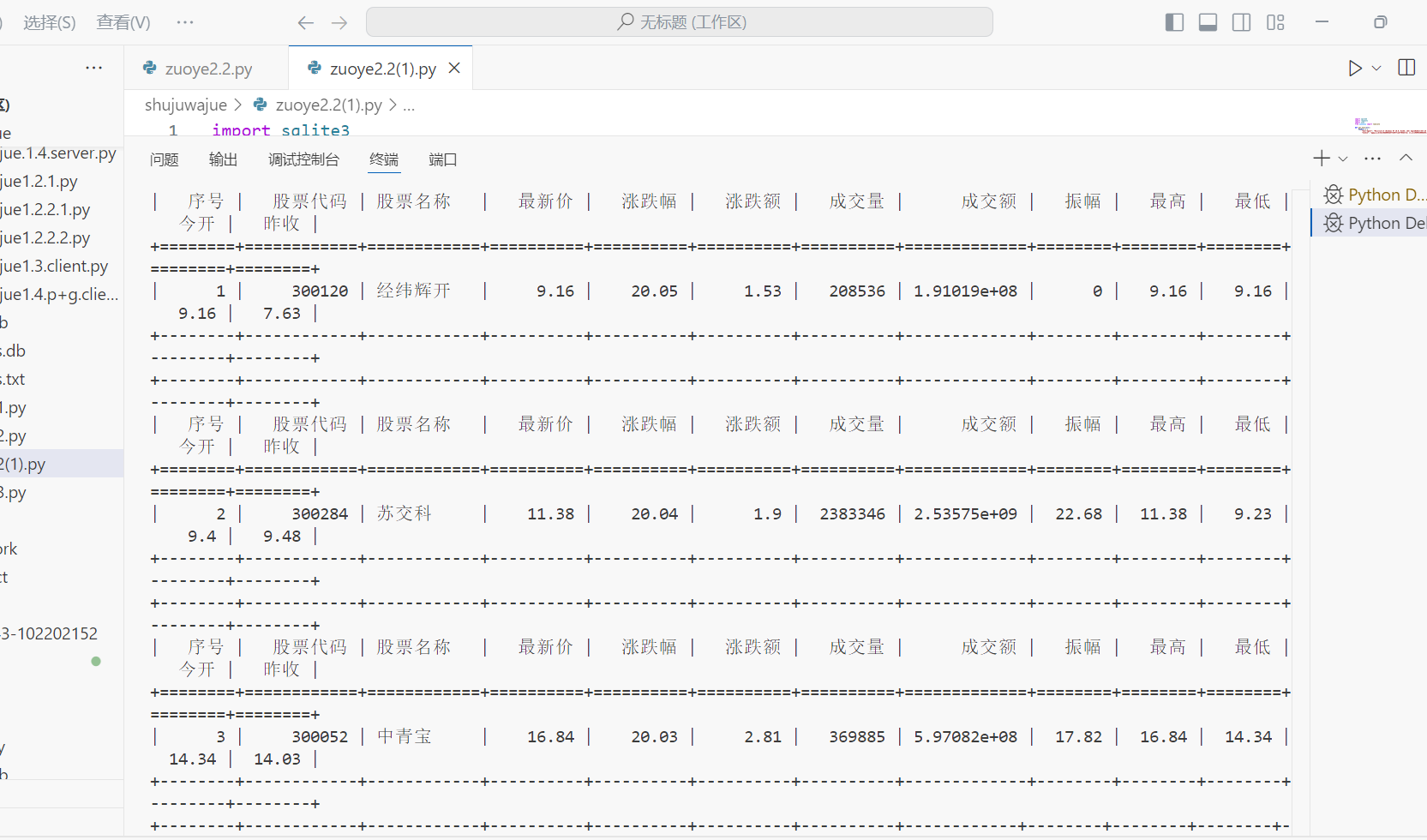
(2)心得体会
在编写代码的过程中,深刻体会到了理论知识与实践操作之间的紧密联系。通过将课堂上学到的知识点应用到实际项目中,不仅加深了对知识的理解,还提高了解决问题的能力。在编写代码的过程中,遇到了许多新的问题和挑战。通过查阅文档、搜索相关资料以及向他人请教,我逐渐找到了解决问题的方法。这次经历让我深刻认识到,编程是一个需要不断学习和进步的过程。
作业③:
- 要求:爬取中国大学 2021 主榜
(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信
息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加
入至博客中 - 输出信息:Gitee 文件夹链接
排名 学校 省市 类型 总分
1 清华大学 北京 综合 969.2
(1)实践过程
通过F12抓包

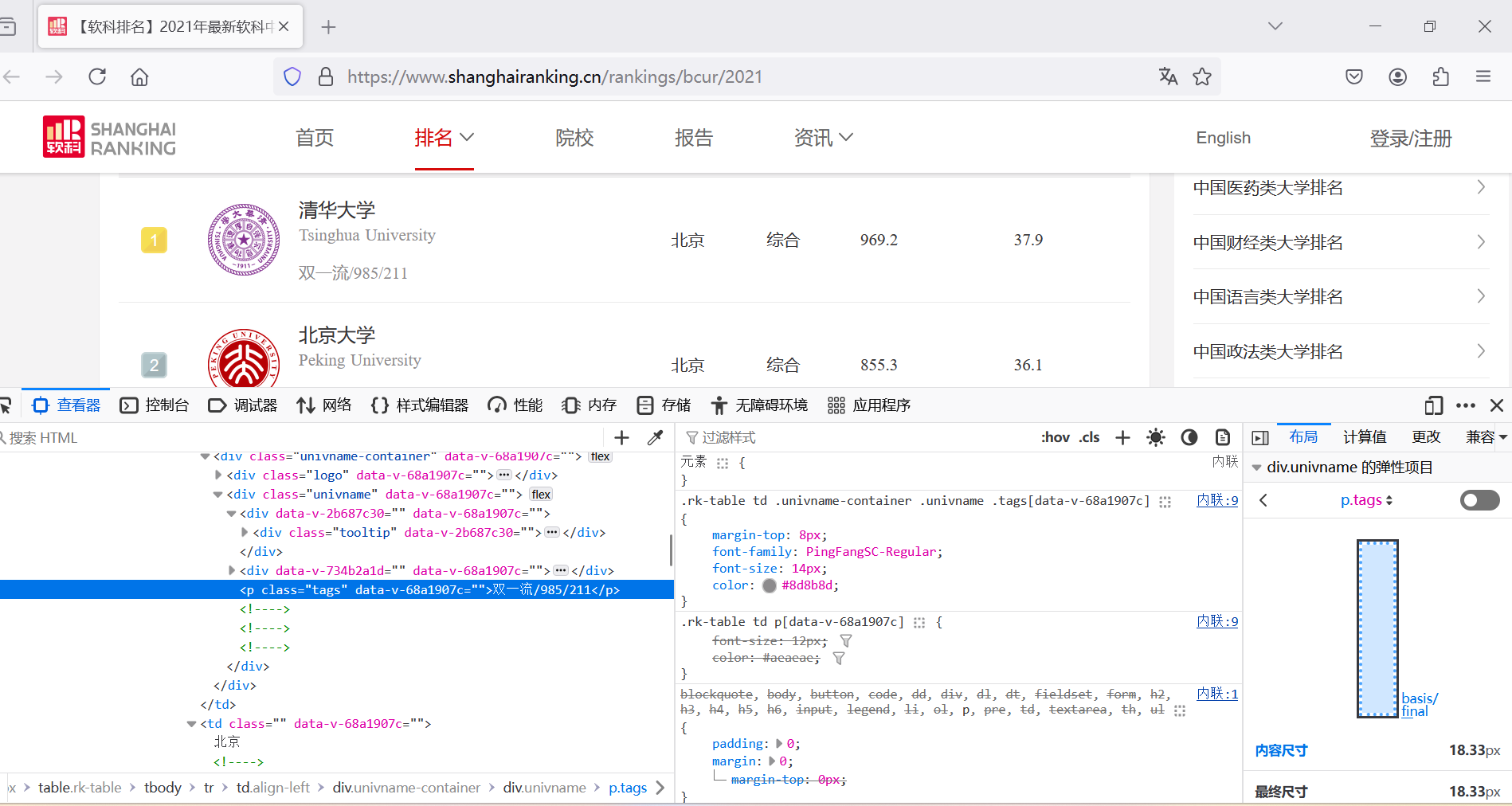
代码实现
import urllib.request
from bs4 import BeautifulSoup
import sqlite3
# 目标网址
url = "https://www.shanghairanking.cn/rankings/bcur/2021"
# 使用urllib.request获取网页内容
response = urllib.request.urlopen(url)
html_content = response.read()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含排名信息的表格
table = soup.find('table')
# 连接到SQLite数据库,如果数据库不存在,将会创建一个新的数据库
conn = sqlite3.connect('university_data_2021.db')
cursor = conn.cursor()
# 创建表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS universities (
rank TEXT,
name TEXT,
province TEXT,
type TEXT,
total_score TEXT
)
''')
# 找到所有的行(tr元素)
rows = table.find_all('tr')
# 跳过表头,从第二行开始遍历
for row in rows[1:]:
# 找到行中的所有单元格(td元素)
cols = row.find_all('td')
if cols:
# 提取排名、学校名称、省市、学校类型、总分
rank = cols[0].text.strip()
school_name = cols[1].text.strip()
province = cols[2].text.strip()
type_of_university = cols[3].text.strip()
total_score = cols[4].text.strip()
# 将数据插入到数据库中
cursor.execute('INSERT INTO universities (rank, name, province, type, total_score) VALUES (?,?,?,?,?)',
(rank, school_name, province, type_of_university, total_score))
# 提交事务
conn.commit()
# 查询数据库并打印结果,使其格式与图片类似
cursor.execute("SELECT * FROM universities")
results = cursor.fetchall()
print("| 排名 | 学校 | | | 总分 |")
print("| --- | --- | --- | --- | --- |")
for result in results:
print(f"| {result[0]} | {result[1]} | | {result[3]} | {result[4]} |")
# 关闭数据库连接
conn.close()
代码结果

(2)心得体会
通过这次作业,对F12开发者工具进行网页抓包的过程更加熟练,并且深刻体会到了理论知识与实践操作之间的紧密联系。将课堂上学到的知识点(如HTML解析、数据库操作等)应用到实际项目中,不仅加深了对知识的理解,还提高了解决问题的能力。在处理网页数据和数据库操作时,需要非常耐心和细心。因为即使是微小的错误(如拼写错误、数据类型不匹配等)也可能导致程序运行失败或数据错误。因此,在以后编写代码时,需要格外注意细节。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了