


数据采集与融合技术实践作业一
码云链接:数据采集与融合技术-码云
代码链接:gitee代码链接
作业①:
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
- 输出信息:
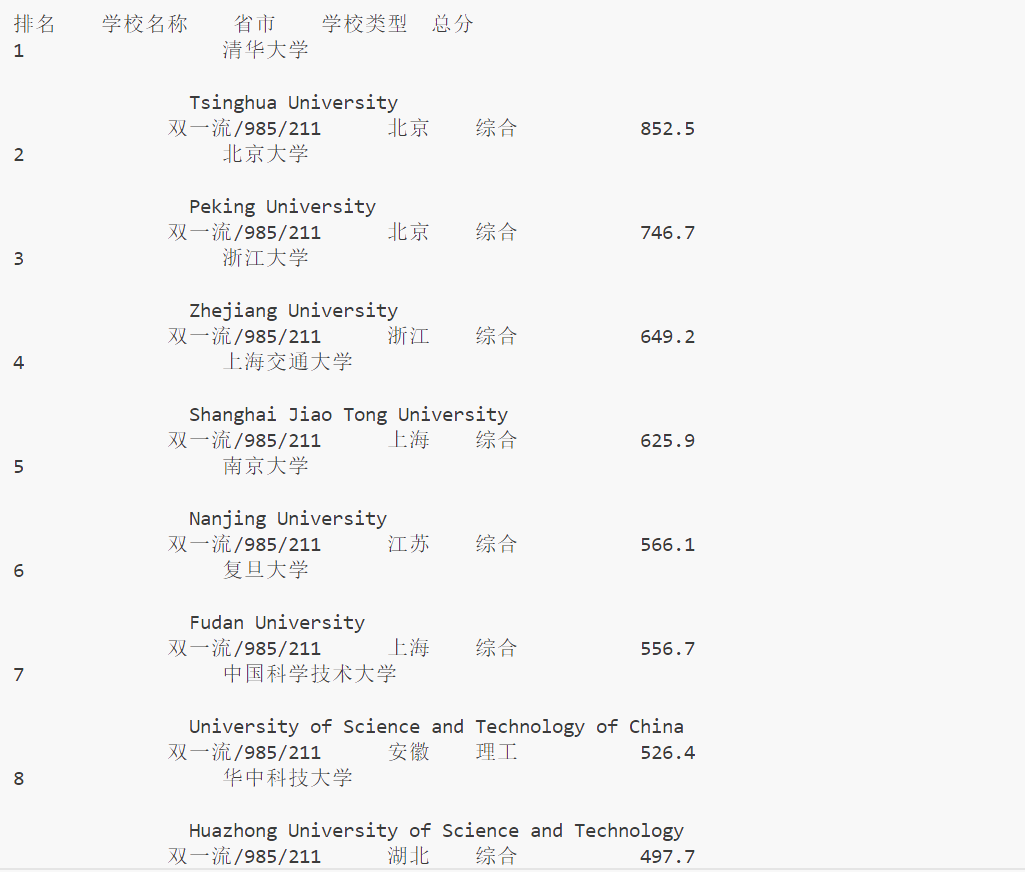
(1)实验过程
代码实现
import urllib.request
from bs4 import BeautifulSoup
# 目标网址
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 使用urllib.request获取网页内容
response = urllib.request.urlopen(url)
html_content = response.read()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含排名信息的表格
table = soup.find('table')
# 打印标题
print("排名 学校名称 省市 学校类型 总分")
# 找到所有的行(tr元素)
rows = table.find_all('tr')
# 跳过表头,从第二行开始遍历
for row in rows[1:]:
# 找到行中的所有单元格(td元素)
cols = row.find_all('td')
if cols:
# 提取排名、学校名称、省市、学校类型、总分
rank = cols[0].text.strip()
school_name = cols[1].text.strip()
province = cols[2].text.strip()
type_of_university = cols[3].text.strip()
total_score = cols[4].text.strip()
# 打印信息
print(f"{rank} {school_name} {province} {type_of_university} {total_score}")
结果展示
(2)心得体会
通过本次作业,我学习到了如何使用BeautifulSoup库来解析HTML文档。这涉及到如何定位HTML中的特定元素,提取所需数据。掌握HTML解析对于数据抓取、网页自动化测试等领域至关重要。而且,我可以将所学知识应用到实际问题中,加深了理解;而且我发现在实际操作中,可能会遇到预料之外的问题,这锻炼了我解决问题的能力。
作业②:
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 输出信息:
(1)实验过程
代码实现
import urllib.request
from bs4 import UnicodeDammit, BeautifulSoup
import re
import urllib.parse
import sqlite3
class ProductDB:
def openDB(self):
self.con = sqlite3.connect(r"D:\\shujuwajue\\products.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("CREATE TABLE IF NOT EXISTS products (id INTEGER PRIMARY KEY AUTOINCREMENT, name varchar(64), price varchar(64))")
except:
self.cursor.execute("DELETE FROM products")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, name, price):
try:
self.cursor.execute("INSERT INTO products (name, price) VALUES (?,?)", (name, price))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("SELECT * FROM products")
rows = self.cursor.fetchall()
print("%-16s%-32s%-16s" % ("id", "name", "price"))
for row in rows:
print("%-16s%-32s%-16s" % (row[0], row[1], row[2]))
db = ProductDB()
db.openDB()
keyword = "书包"
url = f"http://search.dangdang.com/?key={urllib.parse.quote(keyword)}&act=input&page_index=1"
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
html = response.read()
# 使用 UnicodeDammit 来确定编码并转换为 Unicode
dammit = UnicodeDammit(html, ["utf-8"])
data = dammit.unicode_markup
# 编写正则表达式来提取商品名称和价格
pattern = re.compile(r'<a[^>]*title="([^"]*)"[^>]*>.*?<span class="price_n">([^<]+)</span>', re.S)
matches = pattern.findall(data)
# 打印结果
for title, price in matches:
print("价格:", price.strip())
print("商品名称:", title.strip())
print("------")
db.insert(title, price)
db.show()
db.closeDB()
代码结果

(2)心得体会
通过这次作业,我加深了对正则表达式的理解和应用,这对于文本处理非常有用。同时,这个任务提高了我的编程实践能力,让我更加熟悉Python语言。而且,通过使用requests库,我学会了如何发送HTTP请求,包括GET和POST请求。总的来说,这次的作业令我收获颇丰,不仅提高我的编程能力也提高了我解决问题的能力。
作业③:
- 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
- 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
(1)实验过程
代码实现
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 指定要爬取的网页
url = "https://news.fzu.edu.cn/yxfd.htm"
# 创建文件夹以保存图片,使用绝对路径
folder_name = r"D:\shujuwajue\shijian1.3"
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 获取网页内容
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 查找所有JPEG和JPG文件
for img in soup.find_all('img'):
img_url = img.get('src')
if img_url and (img_url.endswith('.jpg') or img_url.endswith('.jpeg')):
# 获取完整的图片URL
full_url = urljoin(url, img_url)
# 下载图片
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
img_response = requests.get(full_url, headers=headers, verify=False)
img_name = os.path.join(folder_name, os.path.basename(full_url))
with open(img_name, 'wb') as f:
f.write(img_response.content)
print(f"Downloaded: {img_name}")
except Exception as e:
print(f"Failed to download {full_url}: {e}")
代码结果
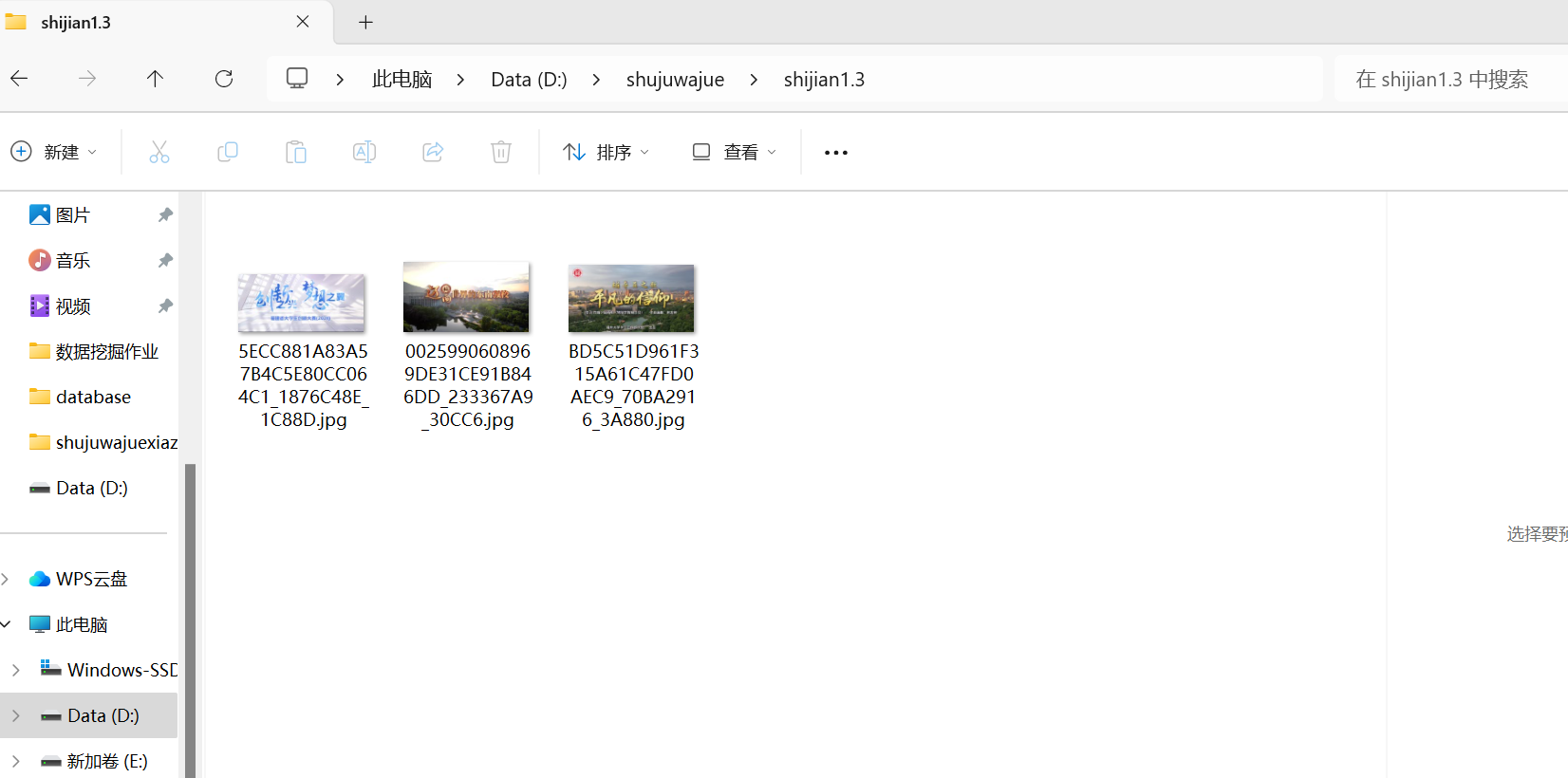
只有三张图片满足JPEG和JPG格式,符合实验要求。其他都为PNG格式,不符合实验要求。
(2)心得体会
通过这次作业我学会了如何确保下载的图片数据是完整的,通过添加异常处理来捕获和处理可能发生的错误。在实现过程中,我遇到了如何处理相对路径的图片链接的挑战。通过使用urljoin函数,我成功地将相对路径转换为绝对路径,确保了图片链接的有效性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了