
工作中C语言相关问题总结
- 说明
- 陷阱1:静态库有两个同名函数
- 陷阱2:C编译器遇到未声明的函数不报错,仅仅提示implicit declaration
- 3. Visual Studio的C编译器的warning C4113,不能忽略
- 4.函数没有返回值,C编译器不报错
- 5. printf()的格式串格式与实参类型不匹配,导致segmentation fault
- 6.Visual Studio建立的console32+静态库工程,console工程依赖于静态库,debug时库代码debug进不去?
- 7. null pointer dereference
- 8. 有符号类型变量与无符号类型变量,不应当混合在一个表达式中,例如int和unsigned int的比较
- 9. C语言为何不能在头文件里写定义?
- 10. 静态库中没有函数实现,编译阶段不报错
- 11. 头文件避免被多次include
- 12. 各种条件编译相关的语法
- 13. ncnn为什么要16字节对齐
- 14. C调用C++函数。C/C++混编
- 15. 卷积网络中浮点精度问题
- 16. 要改变一个结构体对象的值,就应该用指针指向它,然后用指针去修改它
- 17. 不停的做字符串追加,会发生什么?
- 17. 谨慎的使用数据类型
- 18. 移植tensorflow代码遭遇protobuf库内置变量
- 19.
string::difference_type类型的使用 - 20. depthwise convolution的cuda kernel,我感觉tensorflow写的是错的
- 21. 数据类型再遇一坑
- 22. 类型转换再次遇到一个坑: opencv IplImage读取到的数据放在char类型而不是unsigned char类型,转float时候必须先转unsigned char再转float否则结果不对
- 23. 用fread/fwrite时注意fp的模式
- 24. 链接时找不到标识符(符号)的原因
- 25. C语言没有max/min函数,C++才有。在C中,需要自行定义
- 26. error C2055: expected formal parameter list, not a type list
- 27. 避免把指针和0比较大小
- 28. 大小端对于结果的影响
- 28. 在.c文件中,使用malloc()/free()但是没有#include<stdlib.h>会怎样?
- 29. ifstream读取文件内容也会导致segment fault吗?
- 30. Visual Studio中排查内存泄漏问题
- 31. 为什么不使用using namespace std
- 32. 学会使用backtrace来捕获与分析crash
- 33. 某个版本的VS编译出的库,给另一个版本的VS调用
- 34. calling convention
- 35. 图像二维遍历时避免使用x,y作为循环变量
- 36. 再次遭遇segment fault
- 37. error C2061: 语法错误: 标识符“std”
- 38. 使用局部匿名数组
- 39. 使用私有头文件/内部头文件
- 40. extern "C" const 数组,不能修改
- 41. WinDBG TTD
- 42. opencv保存video
- 43. 一次cuda、cmake配置不当导致的segmentation fault问题排查
- 44. sqrt()函数:math.h和cmath里的实现不一样
- 45. 代码中没有
#include<cmath.h>,为什么sqrt()调用的是cmath里的而不是math.h里的? - 46. Linux下查看C/C++中某函数对应的头文件
- 47. Linux下链接库的顺序问题
- 48. static functions with block scope are illegal
- 49. .cu文件报错,VS不识别blockIdx等变量
- 50. VS代码区域不识别cmake中开启的宏,代码暗色显示
- 50. 懒人方式定义枚举类型,以及对应的遍历操作
- 51. Windows下不要在cmd中使用gcc/g++
- 52. 无法解析的外部符号:cuInit()
- 53. 实现gettimeofday时,clang编译器的一个智障报错
- 54. 内存访问越界问题
- 55. 链接顺序问题
- 56. 利用valgrind快速排查内存泄漏
- 57.利用AddressSanitizer快速排查内存访问越界
- 58. 到底什么是segment fault
- 59. segment fault举例
- 60. VS2019 Preview使用AddressSanitizer
- 61. Android NDK使用AddressSanitizer
- 62. 用二分法排查segfault的思路
- 63. exit()是标准库函数,而不是C语言内置函数
- 64. NDK r17 (clang)使用
unordered_map报错: error: implicit instantiation of undefined template ... - 65. -fPIC, -fpic, -fPIE, -fpie的含义和区别
- 66. C/C++代码重构:使用结构体对象相互赋值,可以吗?
- 67. 字符串常量之间用空格分隔,仍然是一个整体
- 68. error: expected primary-expression before ‘[’ token
- 69. volatile关键字
- 70. 缺少返回值导致android arm console crash
- 71. 警惕整数乘法
- 72. C和C++的标准库头文件并不等同
- 73. 位运算一定要注意操作符优先级,最好是完备的使用小括号
- 74. Visual Studio调试时监视变量显示了错误值
- 75. Visual Studio监视窗口查看寄存器
- 76. Visual Studio监视窗口显示字符串,UTF-8格式显示
- 77. Visual Studio监视窗口显示16进制数字
- 78. 少用printf,多用fprintf(stdout
- 79. sprintf会自动追加 NULL 字符 (
\0) - 80. strlen 的判断,依赖于NULL(
\0) - ref
说明
这里列举个人在使用C语言或C/C++混编的工程中,遇到的一些问题,以及解决方法。觉得讲的不对的,欢迎指正。
陷阱1:静态库有两个同名函数
例如A.c和B.c两个源码文件中都实现了play()函数,整个工程是编译成一个静态库。gcc其实除了编译,还会调用链接器ld执行链接,如果ld没有指定--no-whole-archive参数,那么就不会发现重复定义的函数。当然,也可以用nm或objdump来检查编译好的静态库是否存在多个同名symbol来达到同样目的。
实际开发中,用CMake构建的工程,使用了glob找出src目录下的所有.c/.cpp文件,有时候为了调试方便而同时存在同一份源码文件的两个版本(例如play.c和play_old.c),则整个静态库工程编译产生的库文件里面同时又这两个版本的函数,导致使用这个库的函数中引发混乱。
具体例子移步Chris的技术博客 - 检查静态库中的同名函数
经验总结
-
在开发阶段,CMakeLists.txt中的源码文件的组织,最好不要用glob
-
对于一个库工程,链接器ld应当传入
--no-whole-archive参数,避免重复的symbol出现
陷阱2:C编译器遇到未声明的函数不报错,仅仅提示implicit declaration
这是实际开发中遇到的一个问题。简化后的例子:
main.c:
int main() {
play();
}
play.h:
#include <stdio.h>
void play();
play.c
#include "play.h"
void play() {
printf("This is play function\n");
}
编译:gcc main.c play.c -o run。
发现编译器并不报错,仅仅提示implicit declaration。这看起来似乎没什么大问题,毕竟也能执行。但实际开发中忽视这个警告后,产生一种计算结果;如果对相关变量执行printf输出,则又产生另一种计算结果。通过引入相应头文件来去除这一警告,则计算结果稳定下来,不受printf影响。
除了后知后觉的根据编译器的警告逐条找到这个问题并解决,倒不如编译时候就开启检查的开关。在GCC下,使用:“-Wimplicit-function-declaration”.
CSDN网友遇到过类似的情况,相关文章1:万恶之源:C语言中的隐式函数声明,相关文章2:C语言隐式函数声明带来的错误实例(当隐式声明遇到printf)
经验总结
-
- 不要忽略任何可以的编译器警告
-
- C编译器和C++编译器对同样的代码内容(仅仅是文件名从.c到.cpp的不同)可能有不同的表现,不能想当然
3. Visual Studio的C编译器的warning C4113,不能忽略
我的情况是,函数指针声明时和赋值时的参数列表不一样,导致的。
VS2013不报错(是在.c文件中),clang3.8(NDK17b)报错。
4.函数没有返回值,C编译器不报错
warning C4716
5. printf()的格式串格式与实参类型不匹配,导致segmentation fault
这个错误,编译器似乎无法发现,理由是:
由于printf(char *, ...)是个变参函数,所以调用它时,编译器不会检查可变参数的数据类型,而是按照实参类型进行准备参数入栈。
网友的例子:https://www.jianshu.com/p/8c9a224b31df
我的例子:
printf("!! Running %s\n", layer_base->layer_derived_type); //其中被打印输出的type其实是int类型。然后排查了大半天的segmentation fault
网上相关的一个博客,或许和bus error更相关:http://gad.qq.com/article/detail/28088
6.Visual Studio建立的console32+静态库工程,console工程依赖于静态库,debug时库代码debug进不去?
首先勾选solution的项目之间的依赖关系;
然后在库工程属性->配置属性->库管理器->常规->输出文件,修改为具体的值,比如../../../lib/win32\Arcsoft_Liveface.lib
以及,console工程配置库的包含目录,以及用#pragma commnet("xx.lib")或添加附加库的方式引入。
最后,debug的时候就可以断到库工程的代码里面了。
7. null pointer dereference
这个问题在活体检测用gpu库的项目中出现。该问题的一般形式是:编译一个C语言程序,arm32下正常运行,放到Apk中作为ndk程序,就会crash,报错说null pointer dereference。
主要参考https://stackoverflow.com/questions/49893910/why-do-i-have-a-null-pointer-dereference-in-c,这个提问虽然被downvote,个人觉得其实还是挺有用的。
所谓null pointer dereference,这个问题中就是因为用了data[xxx],但是data[xxx]其实是非法的。(但是为啥不是segmentation error?)
8. 有符号类型变量与无符号类型变量,不应当混合在一个表达式中,例如int和unsigned int的比较
有时候报错,有时候不报错。本质原因是编译器执行时候会进行类型提升,具体可以参考《c程序设计奥秘》chap1关于integral promotion部分。
举个例子:
#include <stdio.h>
void foo(const char* str) {
printf("%s\n", str);
}
int arr[] = {23, 34, 12, 17, 204, 99, 16};
#define TOTAL_ELEMENTS (sizeof(arr)/sizeof(arr[0]))
int main(void) {
int d = -1, x;
if (d<=TOTAL_ELEMENTS-2){
x=arr[d+1];
printf("well, in the if branch\n");
}else {
printf("fuck, in the else branch!\n");
}
return 0;
}
输出的结果,是“fuck, in the else branch!".
9. C语言为何不能在头文件里写定义?
假定函数fun定义在header.h中,预编译阶段会把#include "header.h"展开为具体内容,则每一个包含"header.h"的.c/.cpp文件中都有函数fun()的定义:这在编译阶段是OK的,因为每个.c/.cpp文件独立编译;但在连接阶段会产生同名函数冲突,也就是redefinition了。
参考:https://blog.csdn.net/a445849497/article/details/80512814
10. 静态库中没有函数实现,编译阶段不报错
比如在header.h中声明了play( )函数,但是并没有在相应的.c文件中实现play( )函数。呵呵,至少对于静态库,编译阶段是不报错的,警告都没有。并且,这个现象,无论是C代码还是C++代码,也就是无论是C编译器还是C++编译器,都没有报错也都没有警告的。
可是一旦别的可执行文件(以及库文件?)中链接了这个库,就会报错提示说play( )是个undefined reference,也就是函数定义没找到。
所以,个人现在觉得,静态库应当搭配有配套的可执行程序,也就是测试程序,要确保库里面的每个函数都被调用到:首先它能保证头文件中声明的函数都有实现(而不是漏掉实现),其次在搭配预期测试输出的前提下能检验正确性,最后是作为其他开发者使用的一个demo、tutorial。
11. 头文件避免被多次include
首推#ifndef/#define/#endif,如果确定目标编译器不会改变则不妨使用#pragma once方式。#ifdef/#define/#endif是标准所支持的。
例如test.h,应当使用:
#ifndef _TEST_H_
#define _TEST_H_
// 若干行,test.h的实质内容
#endif
#pragma once不是标准所支持的,网上很多博客只是说“有些老版本编译器不支持”,但具体多老呢?查看wikipedia上的数据,主流编译器现在都支持的#pragma once的:

12. 各种条件编译相关的语法
#if
#ifdef xx //相当于#if defined(xx),意思是“如果定义了xx这个宏”。
#ifndef
#if defined(xx)
#if defined(xx) && defined(yy) //#ifdef只能用于单个宏的判断,而#if defined(xx) && defined(yy)则可以判断两个宏。其实#if后是表达式,可以用&&、||等来连接多个
#if !defined(xx) //相当于#ifndef xx,但是#if后面可以有多个表达式用&&、||来连接
#else
#endif
#undef
#define
#define
有两种用法:
#define xxx: 定义一个宏,名字是xxx#define xxx yyy:用xxx替代yyy
13. ncnn为什么要16字节对齐
因为用了arm neon加速,其中float32x4_t类型的数据,意思是4个float32一起。一个float32是4字节,4个float32就是16字节。float32x4_t出现在各种conv的计算阶段,因此需要把feature map的起始地址设定为16的倍数,因而,cstep需要设定为16字节的倍数。
为什么用float32x4_t可以加速,不妨看看这个例子:https://blog.csdn.net/may0324/article/details/72847800。个人测试的结果表明,这个O(N)到O(N/4)的加速往往得不到,但是2倍的加速还是有的。
14. C调用C++函数。C/C++混编
需要把C++函数的声明和定义,用如下的宏包裹:
#ifdef __cplusplus
extern "C" {
#endif
void my_function(){
//your code here
}
#ifdef __cplusplus
}
#endif
则在C的函数中,可以愉快的调用my_function了。
说明:
- 即使
my_function中使用了C++特有的string,vector什么的,也都没有问题的; - 如果不使用上述宏块包裹,则编译阶段不报错,链接阶段报错(编译静态库的话,只有编译阶段,无法发现链接错误,testbed中链接会报错),错误类型是” error: undefined reference to 'xxx'"
15. 卷积网络中浮点精度问题
caffe和ncnn默认用float类型存储数据(bottom/top blob和weight/bias)。根据具体使用的卷积实现,比如底层矩阵计算框架openblas或者手写的(ncnn这种),计算结果有所不同:
网络结构为input->conv1,也就是第一个计算层是卷积层,则输出blob的精度,在小数点第6位就可能不同,也可能相同。
16. 要改变一个结构体对象的值,就应该用指针指向它,然后用指针去修改它
而如果只是把这个结构体对象,赋值到同样的结构体类型的变量上,其实发生的是拷贝。。
e.g:
CAFFECNN_LAYER_BASE* layer_base = &net->layers_ptr[layer_idx]; //则后续可以利用layer_base来修改net->layers_ptr[layer_idx]
17. 不停的做字符串追加,会发生什么?
是用C++的string类做实验的,任务管理器中发现内存在不断增加。
原理:小于16个字符,string放在栈上,大于等于16的时候放在栈上。anyway,不停地放在栈上会不够。
ref: https://bbs.csdn.net/topics/390355334
ref: https://blog.csdn.net/cny901111/article/details/7771668
17. 谨慎的使用数据类型
虽然可以使用强制数据类型转换,但保不齐什么时候在代码中插入一句memcpy,两种类型的size如果不一样,就会产生错误。
举例:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(){
const int n = 10;
size_t* src_data = (size_t*)malloc(sizeof(size_t) * n);
for(int i=0; i<n; i++){
src_data[i] = (size_t)(i);
}
for(int i=0; i<n; i++){
printf("%lu, ", src_data[i]);
}
printf("\n=========================\n");
int* dst_data = (int*)malloc(sizeof(int) * n);
memcpy(dst_data, src_data, sizeof(int) * n);
for(int i=0; i<n; i++){
printf("%d, ", dst_data[i]);
}
return 0;
}
输出结果:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
=========================
0, 0, 1, 0, 2, 0, 3, 0, 4, 0,
这个例子看起来很傻比,但是谁能保证不会犯这个错误呢?看看大名鼎鼎的Structured Edge Detection Toolbox和Piotr Dollar's Matlab Toolbox,在用matlab2017a或更高版本时都有这个问题:
https://github.com/pdollar/edges/issues/26
究其原因,是在.c/.cpp文件中混用了int和mwSize类型,而mwSize类型突然从int变为size_t类型,导致在64位系统下结果不对。
数据类型,能保持正确类型就不要用两种或多种看似等同的类型
18. 移植tensorflow代码遭遇protobuf库内置变量
caffe/tensorflow都用到了protobuf,其中C/C++代码的一些东西,用vim+ctags无法跳转到定义,因为是protobuf库里面定义的。
例如:proto3对于枚举类型,定义了最小最大,使得枚举类型都是32-bit的长度。参考https://stackoverflow.com/questions/33185719/replace-c-enumeration-with-protobuf-enumeration
相应的,protoc编译后产生的C++代码,产生了两个sentinel变量:kint32min和kint32min,例如:
enum Code {
OK = 0,
CANCELLED = 1,
UNKNOWN = 2,
INVALID_ARGUMENT = 3,
DEADLINE_EXCEEDED = 4,
NOT_FOUND = 5,
ALREADY_EXISTS = 6,
PERMISSION_DENIED = 7,
UNAUTHENTICATED = 16,
RESOURCE_EXHAUSTED = 8,
FAILED_PRECONDITION = 9,
ABORTED = 10,
OUT_OF_RANGE = 11,
UNIMPLEMENTED = 12,
INTERNAL = 13,
UNAVAILABLE = 14,
DATA_LOSS = 15,
DO_NOT_USE_RESERVED_FOR_FUTURE_EXPANSION_USE_DEFAULT_IN_SWITCH_INSTEAD_ = 20,
Code_INT_MIN_SENTINEL_DO_NOT_USE_ = ::google::protobuf::kint32min,
Code_INT_MAX_SENTINEL_DO_NOT_USE_ = ::google::protobuf::kint32max
};
这两个变量是Protobuf库里面定义的,具体找到的源码是:
//https://github.com/protocolbuffers/protobuf/blob/master/src/google/protobuf/stubs/port.h
static const int32 kint32max = 0x7FFFFFFF;
static const int32 kint32min = -kint32max - 1;
19. string::difference_type类型的使用
当成signed int用就好了
#include <iostream>
#include <string>
using namespace std;
int main(){
string str = "hello world";
string::iterator iter1 = str.begin();
string::iterator iter2 = str.begin();
iter2++;
iter2++;
string::difference_type dis = iter2 - iter1;
cout << "dis=" << dis << endl;
return 0;
}
20. depthwise convolution的cuda kernel,我感觉tensorflow写的是错的
主要是weight的偏移量的计算上:
//const int filter_offset =
// multiplier +
// depth_multiplier *
// (in_channel + in_depth * (filter_col + filter_offset_temp));
const int filter_offset =
in_channel * filter_height*filter_width + filter_offset_temp + filter_col;
21. 数据类型再遇一坑
在调adas_detection_sdk时再次拆分afq代码(用来查另一个seg fault问题。。)。
然后发现一个int类型的参数,传入其指针时,对应的函数形参是size_t*类型的话,最终导致程序crash(估计也是seg fault?)Win64运行的。
确实很奇怪了,因为sizeof(int)=8,sizeof(size_t)=8,看不出区别。而且用这个变量max_col_buffer_size时没有问题,程序到后面会crash。
实际上,VS2013有报warning,奈何是.c代码,估计c++可能报error吧;这是一个严重的warning,不应该忽略:
warning C4133: 'function' : incompatible types - from 'int *' to 'size_t *'
具体表现:如果我把如下代码(conv层net info loader)就地执行,程序能正常运行;如果封装为一个函数然后调用,就导致crash:
int read_temp;
int readptr = *_readptr;
int demand_memory = *_demand_memory;
size_t max_col_data_size = *_max_col_data_size;
CAFFECNN_LAYER_CONV * convlayer = NULL;
CAFFECNN_LAYER_BASE_CONV *base_convlayer = NULL;
convlayer = (CAFFECNN_LAYER_CONV*)fastMalloc(hMemMgr, sizeof(CAFFECNN_LAYER_CONV));
AFQ_ADDMEM_ASSERT_MEMSET(convlayer, sizeof(CAFFECNN_LAYER_CONV), demand_memory);
convlayer->layer_base = layer_base;
layer_base->layer_derived = convlayer;
convlayer->base_conv_layer = (CAFFECNN_LAYER_BASE_CONV*)fastMalloc(hMemMgr, sizeof(CAFFECNN_LAYER_BASE_CONV));
AFQ_ADDMEM_ASSERT_MEMSET(convlayer->base_conv_layer, sizeof(CAFFECNN_LAYER_CONV), demand_memory);
layer_base->forward = caffecnn_forward_layer_conv;
base_convlayer = convlayer->base_conv_layer;
base_convlayer->group = (int)(pModelInfo[readptr++]);
base_convlayer->num_output = (int)(pModelInfo[readptr++]);
base_convlayer->kernel_h = (int)(pModelInfo[readptr++]);
base_convlayer->kernel_w = (int)(pModelInfo[readptr++]);
base_convlayer->pad_h = (int)(pModelInfo[readptr++]);
base_convlayer->pad_w = (int)(pModelInfo[readptr++]);
base_convlayer->stride_h = (int)(pModelInfo[readptr++]);
base_convlayer->stride_w = (int)(pModelInfo[readptr++]);
base_convlayer->bias_term = (int)(pModelInfo[readptr++]);
base_convlayer->is_1x1 = base_convlayer->kernel_w == 1 && base_convlayer->kernel_h == 1
&& base_convlayer->stride_h == 1 && base_convlayer->stride_w == 1 && base_convlayer->pad_h == 0 && base_convlayer->pad_w == 0;
base_convlayer->forward_gemm = forward_gemm;
base_convlayer->forward_bias = forward_bias;
base_convlayer->conv_im2col = NULL;// im2col;
base_convlayer->conv_col2im = NULL; //to do
while (((read_temp = pModelInfo[readptr + layer_base->bottom_blobs_num]) >= BOTTOM_BASE) && (read_temp < TOP_BASE))
{
int blob_idx = read_temp - BOTTOM_BASE;
base_convlayer->channels = net->blobs_ptr[blob_idx].channel;
base_convlayer->height = net->blobs_ptr[blob_idx].height;
base_convlayer->width = net->blobs_ptr[blob_idx].width;
//base_convlayer->num = ALIGN_IMG(base_convlayer->height_out * base_convlayer->width_out, MC_IMG_ALIGN);
base_convlayer->num = base_convlayer->height_out * base_convlayer->width_out;
layer_base->bottom_blobs_num++;
}
readptr += layer_base->bottom_blobs_num;
base_convlayer->height_out = (base_convlayer->height + 2 * base_convlayer->pad_h
- base_convlayer->kernel_h) / base_convlayer->stride_h + 1;
base_convlayer->width_out = (base_convlayer->width + 2 * base_convlayer->pad_w
- base_convlayer->kernel_w) / base_convlayer->stride_w + 1;
//base_convlayer->count_out = base_convlayer->num_output
//* ALIGN_IMG(base_convlayer->height_out*base_convlayer->width_out, MC_IMG_ALIGN);
base_convlayer->count_out = base_convlayer->num_output
*base_convlayer->height_out*base_convlayer->width_out;
base_convlayer->conv_out_channels = base_convlayer->num_output;
base_convlayer->conv_in_channels = base_convlayer->channels;
base_convlayer->conv_in_height = base_convlayer->height;
base_convlayer->conv_in_width = base_convlayer->width;
//base_convlayer->conv_out_spatial_dim = ALIGN_IMG(base_convlayer->height_out * base_convlayer->width_out, MC_IMG_ALIGN);
base_convlayer->conv_out_spatial_dim = base_convlayer->height_out * base_convlayer->width_out;
base_convlayer->kernel_dim = base_convlayer->conv_in_channels * base_convlayer->kernel_h * base_convlayer->kernel_w;
base_convlayer->weight_offset = base_convlayer->num_output * base_convlayer->kernel_dim
/ base_convlayer->group / base_convlayer->group;
base_convlayer->col_offset = base_convlayer->kernel_dim * base_convlayer->conv_out_spatial_dim
/ base_convlayer->group;
base_convlayer->output_offset = base_convlayer->count_out / base_convlayer->group;
base_convlayer->col_buffer = &net->net_col_buffer;
max_col_data_size = AFQ_MAX(max_col_data_size, sizeof(DATATYPE)*(base_convlayer->kernel_dim*base_convlayer->conv_out_spatial_dim + MC_PTR_ALIGN*base_convlayer->conv_out_channels));
while ((read_temp = pModelInfo[readptr + layer_base->top_blobs_num]) >= TOP_BASE)
{
int blob_idx = read_temp - TOP_BASE;
net->blobs_ptr[blob_idx].channel = base_convlayer->num_output;
net->blobs_ptr[blob_idx].height = base_convlayer->height_out;
net->blobs_ptr[blob_idx].width = base_convlayer->width_out;
net->blobs_ptr[blob_idx].num = base_convlayer->count_out;
layer_base->top_blobs_num++;
}
readptr += layer_base->top_blobs_num;
*_readptr = readptr;
*_demand_memory = demand_memory;
*_max_col_data_size = max_col_data_size;
return MOK;
22. 类型转换再次遇到一个坑: opencv IplImage读取到的数据放在char类型而不是unsigned char类型,转float时候必须先转unsigned char再转float否则结果不对
IplImage* img = cvLoadImage(im_pth.c_str(), CV_LOAD_IMAGE_COLOR);
float* input_data_b = (float*)malloc(sizeof(float) * ht * wt);
float* input_data_g = (float*)malloc(sizeof(float) * ht * wt);
float* input_data_r = (float*)malloc(sizeof(float) * ht * wt);
// ok:像素值都是非负数
//input_data_b[i / 3] = (float)(int)(unsigned char)(img->imageData[i]);
//input_data_g[i / 3] = (float)(int)(unsigned char)(img->imageData[i+1]);
//input_data_r[i / 3] = (float)(int)(unsigned char)(img->imageData[i+2]);
// ok像素值都是非负数
//input_data_b[i / 3] = (float)(unsigned char)(img->imageData[i]);
//input_data_g[i / 3] = (float)(unsigned char)(img->imageData[i + 1]);
//input_data_r[i / 3] = (float)(unsigned char)(img->imageData[i + 2]);
// not ok:像素值出现负数
input_data_b[i / 3] = (float)(img->imageData[i]);
input_data_g[i / 3] = (float)(img->imageData[i + 1]);
input_data_r[i / 3] = (float)(img->imageData[i + 2]);
23. 用fread/fwrite时注意fp的模式
写入字符的话,w和r即可
但是如果非字符,例如float数组、int数组,应当用wb和rb。
尽管你可能在linux、mac下测试后,发现w和r也没错。
但是windows下很可能会跪。
https://www.cnblogs.com/zjutzz/p/10500353.html
24. 链接时找不到标识符(符号)的原因
报错例如:error LNK2019: 无法解析的外部符号 "void __cdecl function_name()" 该符号在函数...中被引用
原因:链接阶段没有找到函数的定义。具体又可以分成如下几类:
-
没有链接对应的库
-
链接了对应的库,但是库里面没有函数实现
- 完全忘记写实现了
- 写了实现,但是忘记把对应的c/cpp文件放到库的依赖列表中
-
C++调用C函数,C函数没有用
extern "C" {}包裹
25. C语言没有max/min函数,C++才有。在C中,需要自行定义
具体解释见 https://stackoverflow.com/questions/3437404/min-and-max-in-c
26. error C2055: expected formal parameter list, not a type list
一种可能的原因是:函数定义的参数列表中,有一个只写了参数类型而没有写参数名。
我的情况:opencv1.0.0里面很多这种情况(.cpp文件),不报错;我移植到.c文件,VS下报错。
27. 避免把指针和0比较大小
我从来都不这么写;是在OpenCV1.0.0源码中看到的,把指针类型变量和0比较大小,看起来是判断指针是否为空的。例如:
if( marginalProbability>0 )
marginalProbabilityEntropy += marginalProbability[ actualSideLoop1 ]*log(marginalProbability[ actualSideLoop1 ]);
这种写法,在VS2013中编译通过;在我的mac上编译过不去,提示:
error: ordered comparison
between pointer and zero ('double *' and 'int')
if( marginalProbability>0 )
我的mac下的编译器信息:
⚡ gcc --version
Configured with: --prefix=/Applications/Xcode.app/Contents/Developer/usr --with-gxx-include-dir=/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.14.sdk/usr/include/c++/4.2.1
Apple LLVM version 10.0.0 (clang-1000.11.45.5)
Target: x86_64-apple-darwin18.2.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
28. 大小端对于结果的影响
一个多字节变量(sizeof(类型)>1的,例如int, short),在内存中具体的表示,依赖于字节序(byte order): 假设我们看内存是从内存地址由低到高的看,那么变量自身的多个字节有两种顺序:从低到高地放到内存,还是从高到低地放到内存?
例如,定义int a = 0x12345678,其中0x78是最低位字节,0x12是最高位字节,显然a在内存中占据的空间大小是固定的,是4字节。假设这段内存空间的地址是从0x4000到0x4003,那么有两种排布方式:
// big endian
0x4000: 0x12
0x4001: 0x34
0x4002: 0x56
0x4003: 0x78
以及:
// little endian
0x4000: 0x78
0x4001: 0x56
0x4002: 0x34
0x4003: 0x12
0x78在0x12345678中是低位,0x12在0x12345678中是高位。变量的高位0x12放到内存地址的低位0x4000,这是big endian;变量的低位0x78放到内存地址的低位0x4000,这是little endian。
这其实和big endian / little endian这对名词的起源含义是一致的:手剥茶叶蛋的时候,从较小的一端开始剥,叫做little endian;从较大的一端开始剥,叫做big endian。只不过现在把鸡蛋换成了多字节变量,小端指的是这个变量的低位0x78,大端指的是这个变量的高位0x12。
Linux是little endian字节序(执行命令lscpu | grep -i byte查看)。在Linux下,执行如下一段代码:
#include <stdio.h>
int main() {
int a = 0x12345678;
char b = *(char*)(&a);
printf("b=%d\n", b);
return 0;
}
输出结果为120,也就是0x78(7*16+8=120),而不是0x12。理由是,变量a的值0x12345678,在内存中从低地址到高地址的顺序下排布为:0x78, 0x56, 0x34, 0x12,也就是little endian序,那么它的首地址被解释为char类型时,得到的是0x78。
在Linux下,通过xxd、hexdump等工具能够查看二进制文件的内容。例如,用C语言代码,将0x12345678和36这两个值写入二进制文件:
#include <stdio.h>
int main() {
FILE* fp = fopen("1.bin", "wb");
int a = 0x12345678;
int b = 36;
fwrite(&a, sizeof(int), 1, fp);
fwrite(&b, sizeof(int), 1, fp);
fclose(fp);
return 0;
}
由于Linux是little endian字节序,这时候可以认为输出的二进制文件1.bin也是按照little endian来存储变量的:查看1.bin内容,从头到尾的而看,相当于从内存低地址到高地址的看。
⚡ xxd 1.bin
00000000: 7856 3412 2400 0000 xV4.$...
可以看到,xxd的结果符合我们的预期,的确是little endian字节序:先0x78,最后是0x56。
再来看看hexdump命令:
⚡ hexdump 1.bin
0000000 5678 1234 0024 0000 5678 1234 0024 0000
没错,这个结果看起来确实很扯淡:为什么要两个字节为一组、然后组内字节序又给换掉了?
通常hexdump -C,或者hd命令,得到的才是我们想要的结果:(ubuntu上有hd,mac上没有。。)
⚡ hd 1.bin
00000000 78 56 34 12 24 00 00 00 78 56 34 12 24 00 00 00 |xV4.$...xV4.$...|
比较下来,还是用xxd命令才能确保输出是预期的结果。
28. 在.c文件中,使用malloc()/free()但是没有#include<stdlib.h>会怎样?
.c文件默认被C编译器(而不是C++编译器)编译;在C编译器看来,如果一个函数没有定义过就被使用,那么会假设它返回的是int类型(当成是“它已经被定义了”),并且默认情况下仅仅抛出警告而不是错误。没错,cl.exe和gcc都是这样的。
肯定有人会说,有没有问题,跑一下就知道了啊,你看它只是warning而不是error,说明它可能没那么严重。嗯,好的,不妨跑一下如下这段样例代码:
#include <stdio.h>
//#include <stdlib.h>
int main() {
int image_size_bytes = 12;
unsigned char* data = (unsigned char*)malloc(image_size_bytes);
if (data == NULL) {
fprintf(stderr, "!! malloc failed\n");
return 1;
}
FILE* fin = fopen("D:/work/fcnn/ece264/img/6x6_24bit.bmp", "rb");
if (fin == NULL) {
fprintf(stderr, "!! fopen failed\n");
return 2;
}
int ret = fread(data, image_size_bytes, 1, fin);
if (ret != 1) {
fprintf(stderr, "!! fread(data, ..) failed\n");
return 3;
}
ret = fclose(fin);
if (ret!=0) {
fprintf(stderr, "!! fclose(fin) failed\n");
return 4;
}
printf("malloc + fread + fclose OK\n");
return 0;
}
在ubuntu下的gcc:可以正常运行,提示open file failed,用ltrace看一下:

在mac下我也用gcc进行了编译,注意mac下的gcc实际上是LLVM系列。也是输出警告,然后运行OK。
好的,很多人这个时候就要说了,瞎搞啥JB玩意儿呢,你看明明没有报错,就是个warning,运行没有问题,别整这个了,赶紧帮我解决我代码运行结果不正确的关键代码吧。
但其实如果是在Windows下运行上述代码,Visual Studio下会直接crash:
如果是调试模式,运行得到的是:

这个现象,VS2013和VS2017都是一样的。而如果是Windows下的TDMGCC,和linux下的表现是一致的,尽管编译生成的是a.exe(2333)
这个
29. ifstream读取文件内容也会导致segment fault吗?
首先明确一下:如果执行的代码只有ifstream读取txt内容,并且被读取的文件存在&&权限正确,基本上不会出现segment fault。但是如果被执行的代码,除了ifstream读取txt的操作read_data()外,还有其他操作(例如执行一个在线学习算法)online_train(),并且:
- 关掉
read_data()执行online_train(),程序不报segment fault - 关掉
online_train()执行read_data(),程序不报segment fault - 同时开启
read_data()和online_train(),程序报segment fault
根据这三个现象,能否说明哪个函数有问题??如果这两个函数都是同一个人写的,代码都在自己手里,那么仔细查查,一个下午,基本还是能找出bug原因的;而如果这两个函数分别是两个team各自实现的,并且互相看不到对方源码,这就很糟糕了,互相甩锅,说:你看,关掉你的函数,我的函数运行正常,肯定是你的实现有问题。从这个现象以及最终debug出的原因来看,如果要用二分法来排查问题,必须要保证“过零点”,也就是其中一部分程序必然crash,而另一部分程序必然不crash,如果两边都不crash,那么并不能确定哪部分有问题,而不是简单粗暴的根据一方的代码和没有crash的现象来断定另一方的代码一定有问题。
OK,具体说一下这个bug的排查过程:
- 代码是C/C++混编,环境是Linux G++,纯终端运行而没有IDE
- 首先添加了必要的CFLAGS和 CXXFLAGS来避免:函数没定义就使用、缺少头文件、返回值类型不匹配、指针变量类型不匹配问题
- 其次利用valgraind检查出了所有的内存没有释放的问题,逐一
free() - 抱着用GDB查找到触发segment fault那行代码的乐观想法,用cgdb运行了程序(说“乐观”是因为内存写越界往往案发现场并不是问题的根本原因)
- 在某个函数内发现malloc()失败,一脸懵逼,印象中分配的内存大小没有问题、buffer大小也没有问题(写这个代码的同事是这么说的,因为在外面定义的buffer大小,然后传进这个函数的)
- 我凭直觉认为传入函数的参数有问题,printf %p打印,果然出现NULL、NIL
- 出现的NULL、NIL显然不是预期的值,逐步往回排查,同事发现有个变量没有赋初值,它的垃圾值导致后续的
memset()调用会写越界(目测是这个垃圾直作为memset要写入的长度,这个长度远超buffer大小) - 赋予初值后问题果然消失
虽然是排查到了问题,但明显低效,最开始就应该使用GDB而不是在两个函数是否调用是否触发seg fault实际上浪费不少时间;个人认为虽然添加free()确保没有内存泄漏看起来并没有解决问题的核心,但已然是我编写合格C语言代码的必备检查步骤了。
至于如何避免内存写越界?如何快速排查内存写越界?如何排查堆栈损坏的问题?目前还缺少经验,后续考虑从这里 https://stackoverflow.com/questions/1010106/how-to-debug-heap-corruption-errors 学习一下。
30. Visual Studio中排查内存泄漏问题
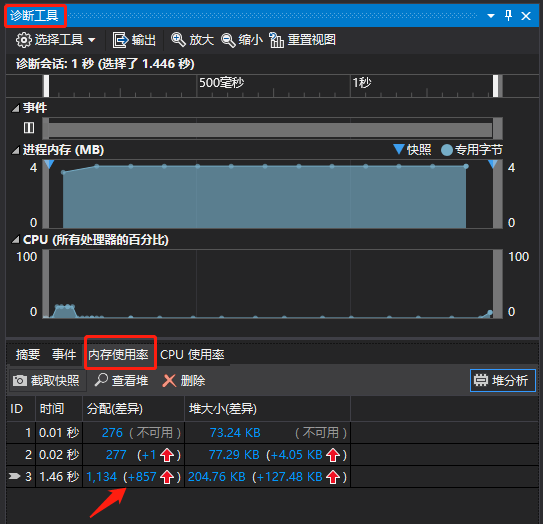
看视频来学习吧:https://www.youtube.com/watch?v=HUZW8m_3XvE 讲解的很详细了,需要>=VS2015的版本,调试时多设几个断点,然后打开诊断工具,对当前断点处的内存做快照,然后注意程序最后面要有个断点,这个断点到来的时候再次对内存取快照,并和前面的快照进行对比,能否发现内存泄漏,定位到具体的代码行。
根据这个教程,我用的VS2017,在编写的libfc程序中尝试调用GDI和libpng来实现imshow显示png图像,担心有内存泄漏问题,但是因为整份代码是网上搜集拼凑起来而不是完全手工打造的,细节并不深刻;用诊断工具内存快照迅速找出了内存泄漏并进行了修复,提升了效率。

31. 为什么不使用using namespace std
今天(2019-05-11 20:13:04)看了cherno系列教程视频,其中讲到了不用using namespace std的问题。cherno是EA公司的dev,录制的视频挺详细的。cherno不用namespace的原因是怕引起冲突;我以前也看到一些人说怕引起冲突,但是到底什么是“引起冲突”?
比如说整份代码是一个大工程,并非全部函数都是你写的;你发现有个函数叫for_each(),那么如果使用了using namespace std,而std里面如果有个函数叫做if_each(),那么当我看到if_each()的时候,我就不知道这个函数到底是哪里的,是std里的,还是同事实现的?
因此,不使用using namespace std的原因,并不仅仅在于“防止引起冲突”,更重要的在于当你看到一个函数调用的时候,能区分开来它是谁实现的,是std里的还是我们自己实现的,而不仅仅是“当两个namespace下有同名函数而编译阶段报错或运行时crash然后找了很久才发现是同名冲突导致”。嗯,预防为主。
32. 学会使用backtrace来捕获与分析crash
主要看 在Linux中如何利用backtrace信息解决问题 这篇学习的。
其实调试过的NDK程序crash时手机上显示的报告就是backtrace了。
33. 某个版本的VS编译出的库,给另一个版本的VS调用
看起来,不同版本的VS用的C Runtime Library是相同的,C++ Runtime Library则不同,因此如果是纯C编译出的静态库,是可以给不同版本的VS使用的。
34. calling convention
这里只考虑__cdecl修饰的情况,也就是C函数默认的修饰。一个函数被调用,产生调用栈帧。这个栈帧里面装了一堆东西,分别是什么?或者说,这个被调用函数相关的:实参、局部变量、返回位置、返回值,是按什么顺序压栈的?
首先明确一点,ESP表示的地方是当前栈帧的栈顶。因此不要被某些图表迷惑以为上方的才是栈顶。
- 压栈顺序level1:局部变量存在的话,
最后一个局部变量最先入栈,直到第一个局部变量C标准并没有规定局部变量在函数作用域内的排布顺序,《C语言实用教程》虽然是用gcc的N到1的顺序,但还是不能确保的。ref: C语言函数调用栈(一) - 压栈顺序level2:函数实参存在的话,最右边实参先入栈,直到第一个实参
首先执行level1,然后执行level2.
ref: Results of Calling Example
P.S. 在windows下通过VS的反汇编来查看:进入调试模式->鼠标右键"调用堆栈"->反汇编
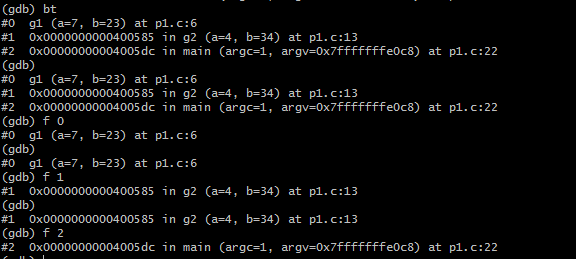
而如果是在Linux+GCC的组合下,通过gdb的bt命令来查看调用堆栈:

实际上,bt命令打印出来的是所有的调用栈帧,第一列是栈帧编号。通过frame
参考:https://en.wikibooks.org/wiki/X86_Disassembly/Calling_Convention_Examples
35. 图像二维遍历时避免使用x,y作为循环变量
在用DFS+并查集求解连通域(https://www.cnblogs.com/zjutzz/p/11017619.html),期间debug好几个小时,2维坐标转到1维模拟id时出现结果不对。
应当使用row, col来替代,减少犯错可能。
36. 再次遭遇segment fault
2019年7月16日21:18:00
调试基于SNPE做SSD网络前向的代码。代码可以分成三部分:预处理、网络预测、后处理。每个部分对应一个函数调用。
因为换了网络模型以及对应的输出layer的名字,但是后处理函数中把两个输出层名字写死了,导致取不到东西。实际上,这时取这两层的行为是非法的。
现象:网络预处理函数中某行代码(记做第n行)后就无法继续运行下去。
比较有意思的是,此时预处理函数中第n+1行本来是printf输出语句,无法输出;换成cout就可以输出。看来printf能够更早的触发segment fault,而cout的机制和printf的机制是不一样的。
发生segment fault,可以是在B函数中写了bug,而B之前的A函数中就触发segment fault,其中A、B同处于一个函数C
37. error C2061: 语法错误: 标识符“std”
是因为在.c文件中使用了C++特有的东西,或者在.h文件中使用了C++特有的东西并且该.h文件被.c文件包含。
排查方法:VS的编译输出窗口,找到第一个错误,找到它对应的编译单元(某个.c文件),在这个.c文件头部的include当中寻找:
- C++特有的头文件,通常是不带.h的系统文件,例如
、 - 包含了自定义的.h文件,该.h文件中又包含了C++特有的文件。也就是间接的引入了C++特有的头文件,需要递归查找并清除
- 代码中使用了std命令空间的东西,例如
std::string。
38. 使用局部匿名数组
processArray(4, (int[]){0, 1, 2, 3});
完整例子:
#include <stdio.h>
static void processArray(int n, int arr[])
{
for (int i = 0; i < n; i++)
printf(" %d", arr[i]);
putchar('\n');
}
int main(void)
{
processArray(4, (int[]){0, 1, 2, 3});
return 0;
}
https://stackoverflow.com/questions/14669412/is-it-possible-to-have-anonymous-ad-hoc-arrays-in-c
39. 使用私有头文件/内部头文件
举个例子,比较直观:
inferface.h
void hello();
interface.c
#include "interface.h"
#include "private_interface.h"
void hello(){
private_hello();
}
private_interface.h
void private_hello();
private_interface.c
#include "private_interface.h"
void private_hello(){
}
40. extern "C" const 数组,不能修改
例如,model.afq.c中定义:
const float model[] = {2.0, 3.0, 4.0, 5.0, 6.0};
在main.c中:
extern float model;
int main(){
float* data = model;
data[0] *= 0.5; //运行报错,提示非法访问内存!
return 0;
}
41. WinDBG TTD
知乎上有个ID为Belleve的人,回答C语言的问题不着调,但是赞同数量远超过我。好吧,有空我也试用下:https://blogs.msdn.microsoft.com/windbg/2017/09/25/time-travel-debugging-in-windbg-preview/
42. opencv保存video
#include <iostream>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
int main(){
//string video_pth = "F:/zhangzhuo/debug/save_video/src.mp4";
string video_pth = "F:/zhangzhuo/debug/save_video/Megamind.avi";
VideoCapture capture(video_pth);
vector<Mat> res;
Mat frame;
int cnt = 0;
while(capture.isOpened()) {
capture >> frame;
if (frame.empty()){
break;
}
imshow("src", frame);
waitKey(10);
res.push_back(frame.clone());
printf("pushing %d frame\n", cnt);
cnt++;
}
if (res.size()>0) {
frame = res[0];
int ht = frame.rows;
int wt = frame.cols;
VideoWriter writer("F:/zhangzhuo/debug/save_video/test.avi", CV_FOURCC('M', 'J', 'P', 'G'), 25, Size(wt, ht));
for(size_t i=0; i<res.size(); i++) {
frame = res[i];
if (!frame.empty()){
writer.write(frame);
}
printf("saving %d/%d frame\n", i, res.size());
}
writer.release();
}
return 0;
}
43. 一次cuda、cmake配置不当导致的segmentation fault问题排查
我维护的CNN推理库,提供普通的CPU版本,以及带CUDA加速的版本。后者需要通过一个宏USE_NVIDIA_GPU,开启相应的设定,包括结构体中cuda/cublas的handle、设备上的内存指针、相应的函数等。
排查的问题描述:执行一个网络前向,报crash,发现是第1层(从第0层开始计数),top blob出现异常,有时候它的c,h,w和data字段的值没有初始化,显然这时候访存非法;有时候这几个字段的值看起来正常,但是仅限于在layer0的那次for循环时是正常的,到layer1这一次for循环时就不正常;还有的,c,h,w,data几个字段都正常,但是执行到layer1的前向函数里面第二句话,就莫名其妙访存非法。。。
排查经过:
0. 观察具体是哪行代码crash,是在VS下调试,发现位置不稳定;
-
代码git push到remote,然后到Linux下git pull代码;尝试使用Address Sanitizer(俗称ASan,阿三),按官网样例配置了CMake中编译选项。但是没用,输出的信息太少了,就一行,用addr2line也看不到(也许这样看,本身就不对)。对阿三很失望。垃圾。
-
按照在Linux中如何利用backtrace信息解决问题这篇文章,土法造backtrace工具,非常管用。这是第三次用这个方法了。打印出来的信息,其实并没有如源博客中提到的可以addr2line的一个地址,而只有segment fault:
00400000-0125f000 r-xp 00000000 08:11 28443752 /home/zz/work/afq/build/linux-x64-cuda/examples/upsample/upsample
0145f000-01462000 r--p 00e5f000 08:11 28443752 /home/zz/work/afq/build/linux-x64-cuda/examples/upsample/upsample
01462000-01463000 rw-p 00e62000 08:11 28443752 /home/zz/work/afq/build/linux-x64-cuda/examples/upsample/upsample
01463000-01465000 rw-p 00000000 00:00 0
01c4d000-01eb0000 rw-p 00000000 00:00 0 [heap]
7fc5008e5000-7fc53f0e6000 rw-p 00000000 00:00 0
7fc53f0e6000-7fc540fba000 r-xp 00000000 08:21 8669608 /usr/lib/x86_64-linux-gnu/libcublasLt.so.10.2.0.168
7fc540fba000-7fc5411ba000 ---p 01ed4000 08:21 8669608 /usr/lib/x86_64-linux-gnu/libcublasLt.so.10.2.0.168
7fc5411ba000-7fc54122e000 rw-p 01ed4000 08:21 8669608 /usr/lib/x86_64-linux-gnu/libcublasLt.so.10.2.0.168
7fc54122e000-7fc541237000 rw-p 00000000 00:00 0
7fc541237000-7fc54127e000 r-xp 00000000 08:21 8654174 /usr/lib/x86_64-linux-gnu/libnvidia-fatbinaryloader.so.418.67
7fc54127e000-7fc54147e000 ---p 00047000 08:21 8654174 /usr/lib/x86_64-linux-gnu/libnvidia-fatbinaryloader.so.418.67
7fc54147e000-7fc541480000 rw-p 00047000 08:21 8654174 /usr/lib/x86_64-linux-gnu/libnvidia-fatbinaryloader.so.418.67
7fc541480000-7fc541485000 rw-p 00000000 00:00 0
7fc541485000-7fc541645000 r-xp 00000000 08:21 7079221 /lib/x86_64-linux-gnu/libc-2.23.so
7fc541645000-7fc541845000 ---p 001c0000 08:21 7079221 /lib/x86_64-linux-gnu/libc-2.23.so
7fc541845000-7fc541849000 r--p 001c0000 08:21 7079221 /lib/x86_64-linux-gnu/libc-2.23.so
7fc541849000-7fc54184b000 rw-p 001c4000 08:21 7079221 /lib/x86_64-linux-gnu/libc-2.23.so
7fc54184b000-7fc54184f000 rw-p 00000000 00:00 0
7fc54184f000-7fc541865000 r-xp 00000000 08:21 7082403 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fc541865000-7fc541a64000 ---p 00016000 08:21 7082403 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fc541a64000-7fc541a65000 rw-p 00015000 08:21 7082403 /lib/x86_64-linux-gnu/libgcc_s.so.1
7fc541a65000-7fc541b6d000 r-xp 00000000 08:21 7079216 /lib/x86_64-linux-gnu/libm-2.23.so
7fc541b6d000-7fc541d6c000 ---p 00108000 08:21 7079216 /lib/x86_64-linux-gnu/libm-2.23.so
7fc541d6c000-7fc541d6d000 r--p 00107000 08:21 7079216 /lib/x86_64-linux-gnu/libm-2.23.so
7fc541d6d000-7fc541d6e000 rw-p 00108000 08:21 7079216 /lib/x86_64-linux-gnu/libm-2.23.so
...
7fc55f846000-7fc55f851000 rw-p 00000000 00:00 0
7fc55f87b000-7fc55f87c000 r--p 00025000 08:21 7079219 /lib/x86_64-linux-gnu/ld-2.23.so
7fc55f87c000-7fc55f87d000 rw-p 00026000 08:21 7079219 /lib/x86_64-linux-gnu/ld-2.23.so
7fc55f87d000-7fc55f87e000 rw-p 00000000 00:00 0
7ffe409a5000-7ffe409c7000 rw-p 00000000 00:00 0 [stack]
7ffe409cb000-7ffe409ce000 r--p 00000000 00:00 0 [vvar]
7ffe409ce000-7ffe409d0000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
==========>>> catch signal 11 <<<===========
Dump stack start...
[1] 31738 segmentation fault (core dumped) ./upsample
(base) zz@43 ~/work/afq/build/linux-x64-cuda/examples/upsample %
从log大概猜测了一下,感觉是cuda的库的问题。我的测试代码本身没有用到cuda,仅仅是开启了CNN库的USE_NVIDIA_GPU宏支持。随后想到,如果库的编译选项去掉USE_NVIDIA_GPU,也许就不会crash了。验证果然如此。
- 到VS里确认了一下,testbed工程的预处理器中确实没有USE_NVIDIA_CUDA选项,而CNN库里面则有这个选项。这导致一个结构体的赋值出现问题:
layer_base = &engine->net->layers_ptr[i];
其中,后者是从CNN库中返回的东西,库在编译时有开启USE_NVIDIA_GPU宏,因此返回的layers_ptr[i]是有cublas和cudnn的handle的字段的;而layer_base是在testbed中定义的,是没有这两个字段的。这样的结构体赋值,会写越界。。。非常隐蔽了。
罪魁祸首:
if(USE_NVIDIA_GPU)
afq_cuda_add_library(afq STATIC ${AFQ_SRCS} ${AFQ_INCS})
target_compile_definitions(afq PRIVATE -DUSE_NVIDIA_GPU) #这句!应该改成PUBLIC,不然的话调用testbed的人就掉坑里了。
target_include_directories(afq PUBLIC ${AFQ_CUDA_INCLUDE_DIRS})
target_link_libraries(afq ${AFQ_CUDA_LIBS})
else()
afq_add_library(afq STATIC ${AFQ_SRCS} ${AFQ_INCS})
endif()
44. sqrt()函数:math.h和cmath里的实现不一样
先前一直以为math.h和cmath仅仅是加入了namespace的差别。然而在比对CNN前向输出结果时发现某layer输出不一致,被比较的两个VS工程都是VS2015 64位 Debug模式。
后来发现,当鼠标移到两个函数上时,显示的函数声明并不一致。
#include<math.h>后使用sqrt(float)和#include<cmath.h>后使用sqrt(float),结果有可能不一致!。
cmath的:
_Check_return_ inline float sqrt(_In_ float _Xx) _NOEXCEPT
{
return (_CSTD sqrtf(_Xx));
}
math.h的:
_Check_return_ _CRT_JIT_INTRINSIC double __cdecl sqrt(_In_ double _X);
简单想了一下,区别应该就是参数类型不一样,C里面只有double作为输入参数的这一个函数,所以会被类型转换:float->double,再计算sqrt;而C++则提供了重载的float的sqrt函数,其内部算法实现时如果是多次迭代,那么double和float很可能会有不一样结果。
45. 代码中没有#include<cmath.h>,为什么sqrt()调用的是cmath里的而不是math.h里的?
在多个代码文件的工程中,sqrt()到底用了math.h的还是cmath的,首先要grep一下'math.h'和'cmath';然而并没有找到。
从整个代码被编译时的角度看,.h文件是被替换到.c/.cpp文件中的。我的case是.cpp文件,那就看该.h文件被#include之前,还包含了哪些文件。发现#include的一个头文件,里面#include
至于
ref:https://stackoverflow.com/questions/29454488/does-algorithm-include-cmath
46. Linux下查看C/C++中某函数对应的头文件
man -S2 write() #系统函数
man -S3 printf() #库函数
47. Linux下链接库的顺序问题
如果连接的库之间也有依赖关系,则被依赖的库应当放到后面。
参考:https://www.cnblogs.com/zhangxuan/p/5382959.html
具体案例:公司的face detection库被landmark库依赖,也被face quality库依赖,则需要把face detection放在链接库列表的最后。如果不放到最后,理论上会出现什么我不确定,我们这里出现的情况是face quality算法变慢,结果也不对。。。
48. static functions with block scope are illegal
被自己写的一个bug给坑到了。这个报错大概是说,在一个大括号里面你不能定义函数。问题是,正常人没有人在C/C++里这么写的。
贴一下出错代码吧:
static void release_pooling_layer(CAFFECNN_LAYER_BASE* layer_base, MHandle hMemMgr) {
CAFFECNN_LAYER_POOLING* pooling_layer = (CAFFECNN_LAYER_POOLING*)layer_base->layer_derived;
if (pooling_layer) {
#if defined(USE_NVIDIA_GPU)
if (layer_base->device.type == DEVICE_CUDA) {
cudaErrCheck(cudaFree(pooling_layer->padded_gpu_bottom_blob));
}
MMemFree(hMemMgr, pooling_layer);
}
#endif
}
USE_NVIDIA_GPU宏是没有开启的,会导致少一个}。应该把倒数第二个}拿到#endif外面。
49. .cu文件报错,VS不识别blockIdx等变量
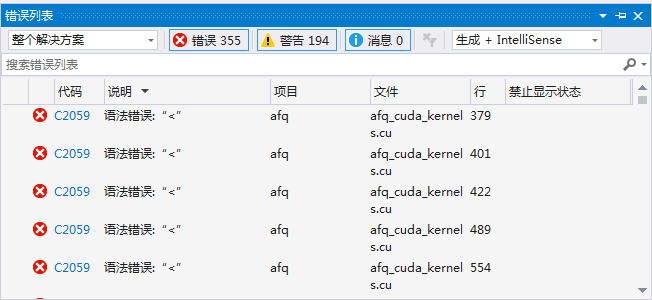
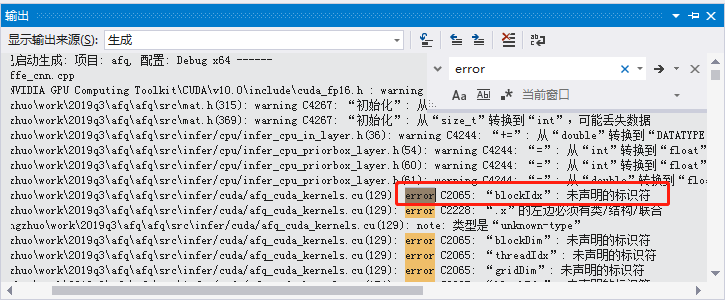
这个问题排查了半个下午,还以为遇到什么重大bug,还换了cmake最新版,2333。
错误原因是,头文件中包含了.cu文件:
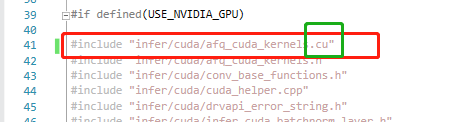
显然,.h文件会被其他.c/.cpp文件包含,而这些文件不会被nvcc编译,自然就无法识别blockIdx等预设变量了。
50. VS代码区域不识别cmake中开启的宏,代码暗色显示
用cmake生成了.sln工程文件,用VS打开后发现cmake里开启的宏,比如USE_NVIDIA_GPU,在#if defined(USE_NVIDIA_GPU)判断下的代码是暗色的,显示不正常。
但是查看项目属性,包括库项目、可执行项目,都能在预处理器区域看到这个宏。
VS2015update3有点智障。重启VS就好了。
50. 懒人方式定义枚举类型,以及对应的遍历操作
typedef enum XX_Type{
XX_BEGIN=-1,
XX_ENUM0,
XX_ENUM1,
XX_ENUM2,
...
XX_ENUMn,
XX_TYPE_COUNT
} XX_Type;
其中XX_BEGIN为-1,XX_TYPE_COUNT相当于是哨兵变量,用来获取总共有多少个有效枚举变量(不含XX_BEGIN和XX_TYPE_COUNT)。遍历的时候for循环采坑,主要是起始元素应该等于XX_BEGIN+1而不是XX_BEGIN。
51. Windows下不要在cmd中使用gcc/g++
在windows下安装了TDM-GCC。最好的使用体验应当是在git-bash中。
如果是cmd中使用g++,运行a.exe会无法捕捉到segment fault。
52. 无法解析的外部符号:cuInit()
cuInit()是nvcuda.dll中的符号。nvcuda.dll是安装cuda显卡驱动时安装的;又或者,安装cuda的时候也可以装上显卡驱动,也就装上了nvcuda.dll。我这里是win10,发现c:/windows/system32目录下已经有nvidia-smi.exe和nvcuda.dll了。
这个无法解析的符号,我这里情况是:CMakelists中配置cuda的时候没有配置正确导致的(win下忘记配置cuda10.1了。。),也就是说链接阶段没有链接cuda的库导致的。
53. 实现gettimeofday时,clang编译器的一个智障报错
G:/dev/AISF/ObjectDetection/ObjectDetection_Processor/src/main/cpp/jni/source/../objectdetection_inc\fc_log.h:17:29: warning: declaration of 'struct timeval' will not be visible outside of this function [-Wvisibility]
int fc_gettimeofday(struct timeval* tp, void* tzp);
^
G:\dev\AISF\ObjectDetection\ObjectDetection_Processor\src\main\cpp\jni\objectdetection_source\fc_log.c:16:5: error: conflicting types for 'fc_gettimeofday'
int fc_gettimeofday(struct timeval* tp, void* tzp) {
^
G:/dev/AISF/ObjectDetection/ObjectDetection_Processor/src/main/cpp/jni/source/../objectdetection_inc\fc_log.h:17:6: note: previous declaration is here
int fc_gettimeofday(struct timeval* tp, void* tzp);
^
G:\dev\AISF\ObjectDetection\ObjectDetection_Processor\src\main\cpp\jni\objectdetection_source\fc_log.c:43:18: warning: incompatible pointer types passing 'struct timeval *' to parameter of type 'struct timeval *' [-Wincompatible-pointer-types]
fc_gettimeofday(&time, (struct timeval*)NULL);
^~~~~
G:/dev/AISF/ObjectDetection/ObjectDetection_Processor/src/main/cpp/jni/source/../objectdetection_inc\fc_log.h:17:38: note: passing argument to parameter 'tp' here
int fc_gettimeofday(struct timeval* tp, void* tzp);
^
从Andriod Studio中看到这个报错,看了半天才明白,是说fc_log.h中函数声明里的struct timeval类别没有被识别,以至于和fc_log.c中在包含了<time.h>后的函数定义的参数struct timeval类别不一致。
这简直是智障一样的报错了。直接说头文件中类型未定义,多直观啊。
解决:在fc_log.h中添加#include <time.h>
54. 内存访问越界问题
内存访问越界,简单说就是访问了不能访问的地址,“非法访问”。会触发segment fault,但是往往crash的地方往往又不是真的案发现场。排查Segfault问题,我简单总结这几条 “可以”和“不可以”:
- Linux下,valgrind可以检查出动态数组(malloc/new分配)的访问越界(复杂的例子没有试过):
#include <stdlib.h>
int main()
{
char* p = new char[10];
for (int i = 0; i != 11; ++i)
p[i] = i;
return 0;
}
clang++ main.cpp -g
valgrind ./a.out
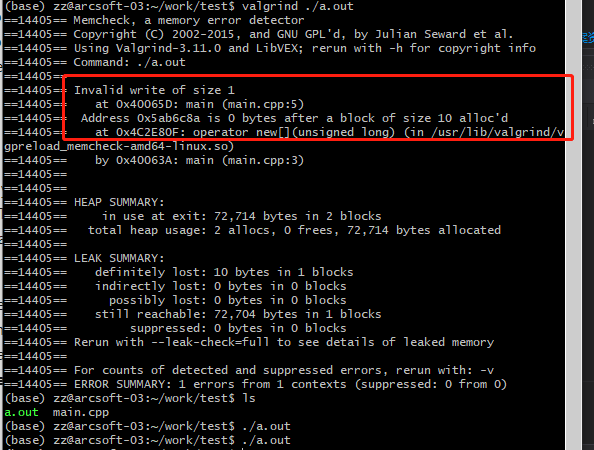
- Windows下,VS2019,能检查到简单代码中堆内存数组访问越界(复杂的例子没有试过):
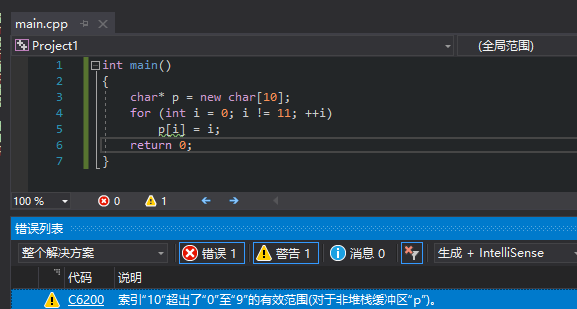
- Linux下,Valgrind无法检查到静态数组的访问越界:

(ref: Valgrind内存泄漏和内存越界访问检查工具 )
- Visual Studio中debug模式下,查看内存,显示的内存地址上的值有几种类型:
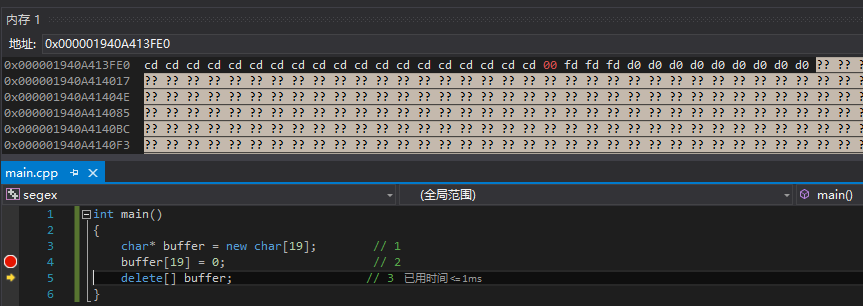
-
其中前19个元素取值为"cd",是debug模式下的“垃圾值”;
-
4个fd(其中第一个fd被改写为0了,是赋值后导致的),是debug模式下追加的;
-
剩余的d0,是内存字节对齐而填充的。
-
显示为"?"的内存地址,是不能访问的,如果访问则触发“invalid memory access"
ref:【除錯:除錯工具】 Windbg的gflags.exe 和 pageheap的使用和原理分析
55. 链接顺序问题
如果testbed依赖于a库和b库,并且a库也依赖于b库,那么,链接a和b的时候是否要:先a再b?(被依赖的库放在最后)
简单的结论(常识)是:
- clang不需要考虑链接库的顺序问题
- gcc需要考虑链接库的链接顺序问题
如果a和b是相互依赖,则需要的链接顺序为:a,b,a(a出现两次) - windows??
56. 利用valgrind快速排查内存泄漏
首先要明确,内存泄漏存在两个方面:一个是自己写的代码,另一个是用到的第三方库,比如臭名昭著的opencv。
其次,要善于利用valgrind来排查每一个内存泄漏对应的调用栈:利用--gen-suppressions生成opencv等第三方库的supp文件。
以opencv为例,枚举所有用到的opencv函数、包含相应的头文件(最好是放在一个单独的文件或几个文件中),然后用valgrind找出里面所有的泄漏,放到opencv.supp文件中:
//show.c
#include <stdio.h>
#include "opencv2/highgui/highgui_c.h"
#include "opencv2/imgproc/imgproc_c.h"
int main()
{
const char* im_pth = "/home/zz/work/rocknet/cat.jpg";
IplImage* im = cvLoadImage(im_pth, -1);
cvShowImage("image", im);
cvWaitKey(0);
cvDestroyAllWindows();
cvReleaseImage(&im);
return 0;
}
gcc show.c `pkg-config --libs opencv` `pkg-config --cflags opencv` -g
valgrind --gen-suppressions=all --leak-check=yes ./a.out 2>&1 | tee valgrind.out
sed '/==/ d' valgrind.out > opencv.supp
valgrind --gen-suppressions=all --leak-check=yes --suppressions=opencv.supp ./a.out
并没有明显的内存泄漏:
25511 LEAK SUMMARY:
25511 definitely lost: 0 bytes in 0 blocks
25511 indirectly lost: 0 bytes in 0 blocks
25511 possibly lost: 0 bytes in 0 blocks
25511 still reachable: 942,729 bytes in 10,220 blocks
然后再利用这个得到的opencv.supp文件,在完整的、正式的需要测试的代码中,使用valgrind并且指定opencv.supp文件,从而找出opencv内存泄漏之外的其他内存泄漏。这里简单起见,在show.c中添加一句malloc调用,但没有配套的free,从而造成内存泄漏:
//show.c
#include <stdio.h>
#include <stdlib.h> //新增
#include "opencv2/highgui/highgui_c.h"
#include "opencv2/imgproc/imgproc_c.h"
int main()
{
const char* im_pth = "/home/zz/work/rocknet/cat.jpg";
IplImage* im = cvLoadImage(im_pth, -1);
cvShowImage("image", im);
cvWaitKey(0);
cvDestroyAllWindows();
cvReleaseImage(&im);
float* data = (float*)malloc(sizeof(float)*10); //新增
return 0;
}
重新编译,然后valgrind运行时,同时指定supp文件和输出详细的内存泄露:
gcc show.c `pkg-config --libs opencv` `pkg-config --cflags opencv` -g
valgrind --gen-suppressions=all --leak-check=yes --suppressions=opencv.supp ./a.out
{
<insert_a_suppression_name_here>
Memcheck:Leak
match-leak-kinds: definite
fun:malloc
fun:main
}
25548 LEAK SUMMARY:
25548 definitely lost: 40 bytes in 1 blocks
25548 indirectly lost: 0 bytes in 0 blocks
25548 possibly lost: 0 bytes in 0 blocks
25548 still reachable: 942,729 bytes in 10,220 blocks
可以看到,增加了40个字节的definitely lost,具体怎么增加的,是来自于main函数中的malloc函数调用。找到泄漏的原因了,修复起来就显而易见了。
好吧,搞了这么半天,似乎重新发明了Visual Studio 2015起内置的内存泄漏检查功能。VS不愧是宇宙第一强的IDE!
57.利用AddressSanitizer快速排查内存访问越界
在mac osx下测试的。Linux平台没有测试过。Windows上没有搞过clang-llvm。
堆内存的访问越界
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
int n = 10;
float* data = (float*)malloc(sizeof(float)*n);
memset(data, 0, sizeof(float)*n);
data[11] = 2.0f; // invalid access
return 0;
}
gcc -fsanitize=address -g main.c
(注意,不要用任何优化!否则很可能查不到访问越界)
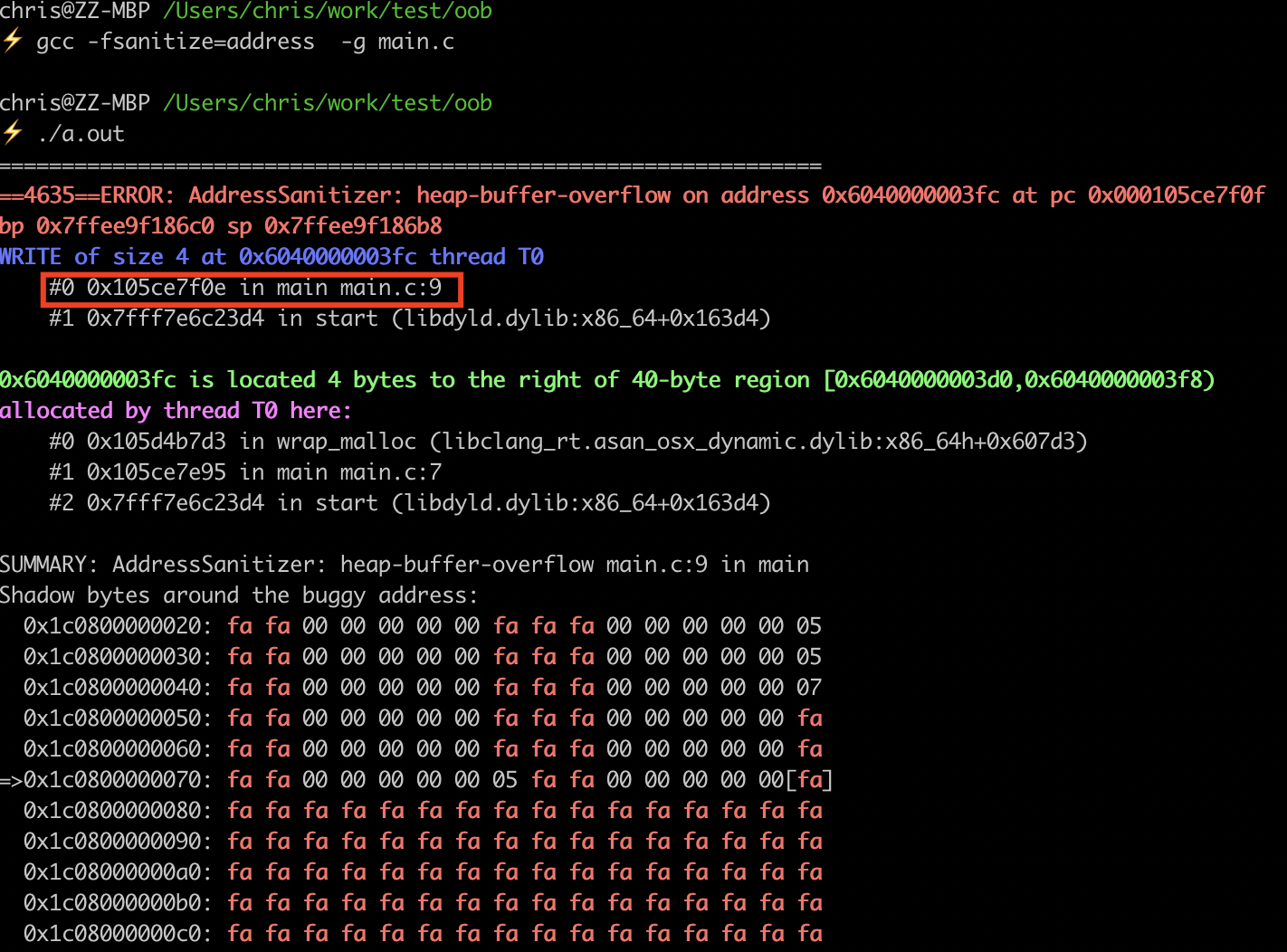
可以看到,准确的定位到了main.c第9行的访问越界。
栈内存的访问越界
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
//int n = 10;
//float* data = (float*)malloc(sizeof(float)*n);
//memset(data, 0, sizeof(float)*n);
float data[10];
memset(data, 0, sizeof(data));
data[11] = 2.0f;
return 0;
}
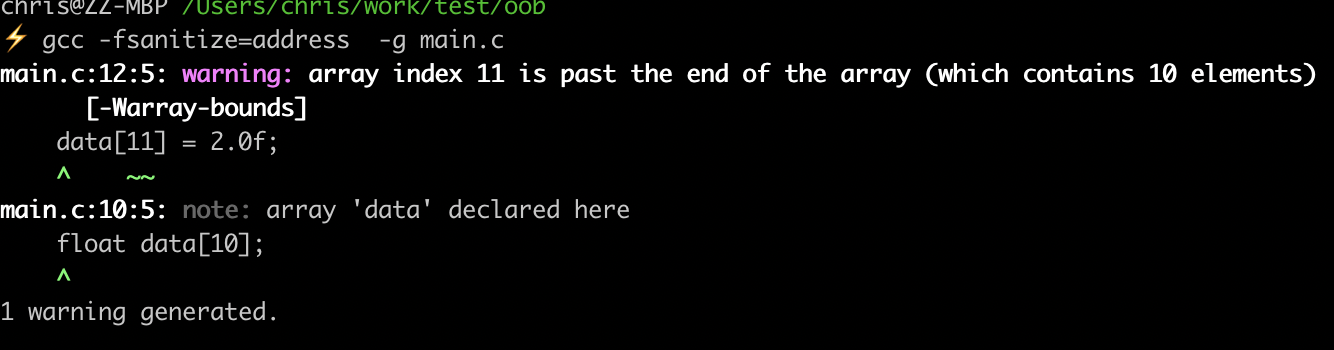
没错,编译阶段,ASAN就能报告栈上的内存访问越界。
58. 到底什么是segment fault
这篇帖子中科普了什么是段错误:
进程的堆空间也是以每页大小进行映射的,在malloc时,如果申请的大小加上原来的位置brk指针,没超过当前映射的页边界,就只是简单的修改brk的值,如果超出,才进行缺页异常处理。
使用malloc的空间时,会存在虽然超出brk指针,但使用位置仍在该页映射的虚拟地址空间内,便不会产生segment fault。
因此,segfault的样例代码,也许换台机器就不行了,也许同一台机器上也无法稳定复现。尝试找了一些segmentfault的样例代码:
59. segment fault举例
segment fault 例子1
#include<stdio.h>
#include<string.h>
int main()
{
char str[10] = {};
char arr[10] = "012345678";
printf("str:%p\narr:%p\n", str, arr);
puts(str);
puts(arr);
strcpy(str, "abcdef123456");
puts(str);
puts(arr);
printf("len=%zu\n", strlen(str));
printf("size=%zu\n", sizeof(str) / sizeof(str[0]));
}
VS2017,release模式下运行竟然不报错也不crash:

VS2017,debug模式下运行会crash:
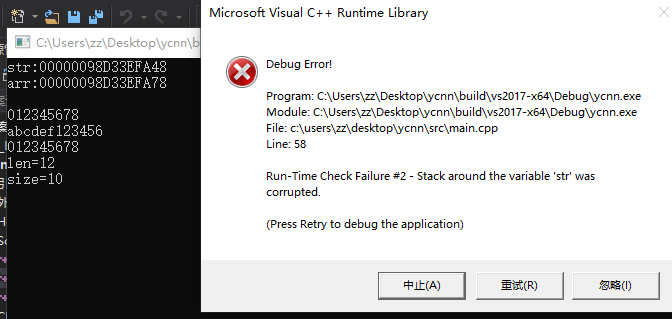
显然,这和C语言学习笔记04——程序在内存中的分布以及内存越界问题这篇博客中ubuntu下运行的结果是不一样的。
在WSL的Ubuntu18.04中跑出来的结果:
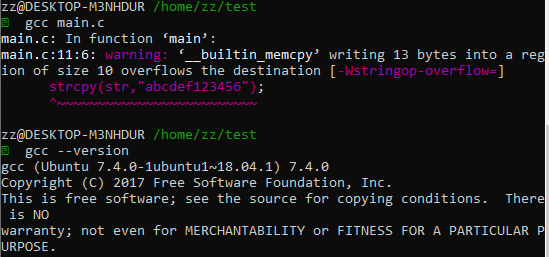
然而WSL的Ubuntu16.04中,gcc是5.4版本,跑出来“一切正常”:
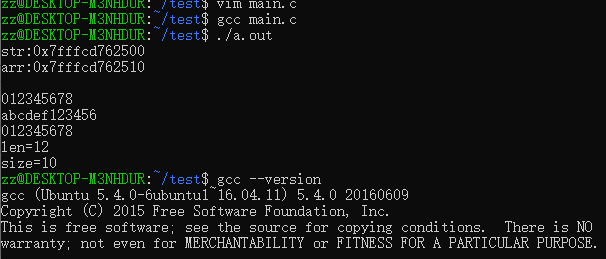
segment fault 例子2
来源:越界访问内存的问题
int main() {
int a;
char b[16] = "abcd";
int c;
a = 1;
c = 2;
printf("a=%d,c=%d\n", a, c);
memset(b, 0, 32); //注意这里访问越界了,你只有16字节空间,却修改了32字节
printf("a=%d,c=%d\n", a, c);
}
现象:VS2017 Debug模式,运行crash;VS2017 Release模式,运行正常,返回值为0。Debug模式的crash报错是怎样的呢?
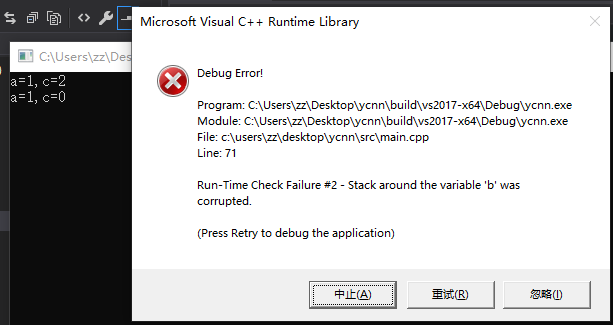
Run-Time Check Failure #2 - Stack around the variable 'b' was corrupted.
显然,Debug模式下的CRT,通过多分配若干空间,来记录和检查非法的内存访问,进而检测到了上述错误。
Ubuntu16.04+GCC5.4,运行会segfault:
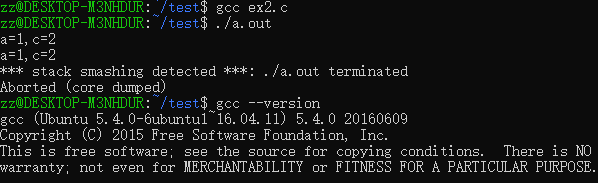
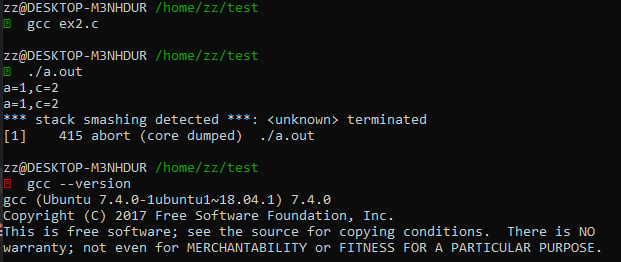
Ubuntu18.04+GCC7,运行segfault:
segment fault 例子3
样例代码来源:内存访问越界在哪里崩溃
代码:
int main() {
char test[100] = { 0 };
memset(test, 0, 200);
printf("yes\n");
int data;
scanf("%d", &data);
}
VS2017 Debug模式运行,在输入data的值之后会crash:
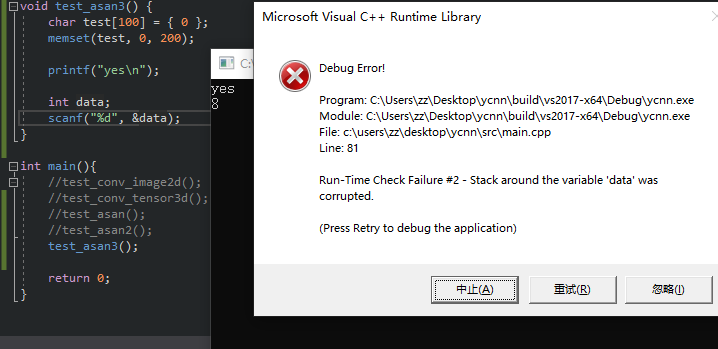
想想为什么不是memset会crash?为什么直到scanf才会crash?
实际上,在工作中使用SNPE库做CNN前向的工程中,遇到crash是,各种printf语句会crash,而如果注释掉crash对应的printf那行后,下一个printf语句会crash。
显然,这两种case是有共同点:scanf和printf的内部实现上,都和“缓冲区”相关。目前猜测是,它们的内部实现都需要使用内存,而前面代码的访问越界会和这块内存(缓冲区)冲突。但是具体是stack上的还是heap上的?似乎是stack上的缓冲区才说的过去?
60. VS2019 Preview使用AddressSanitizer
目前(2019年10月26日),只有VS2019 Preview版本有这个功能。注意,使用的编译器是MSVC编译器,而不是clang编译器。
官方链接:AddressSanitizer (ASan) for Windows with MSVC
配置使用:项目属性中配置:
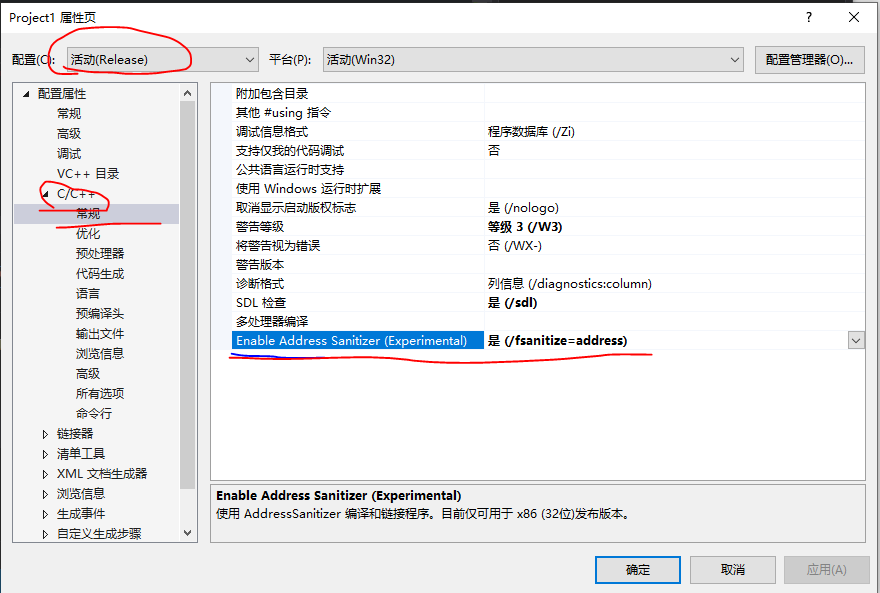
注意:必须是Release模式,Debug模式用不了ASan。
测试代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
int n = 10;
float* data = (float*)malloc(sizeof(float) * n);
memset(data, 0, sizeof(float) * n);
data[11] = 2.0f; // invalid access
return 0;
}
运行输出:
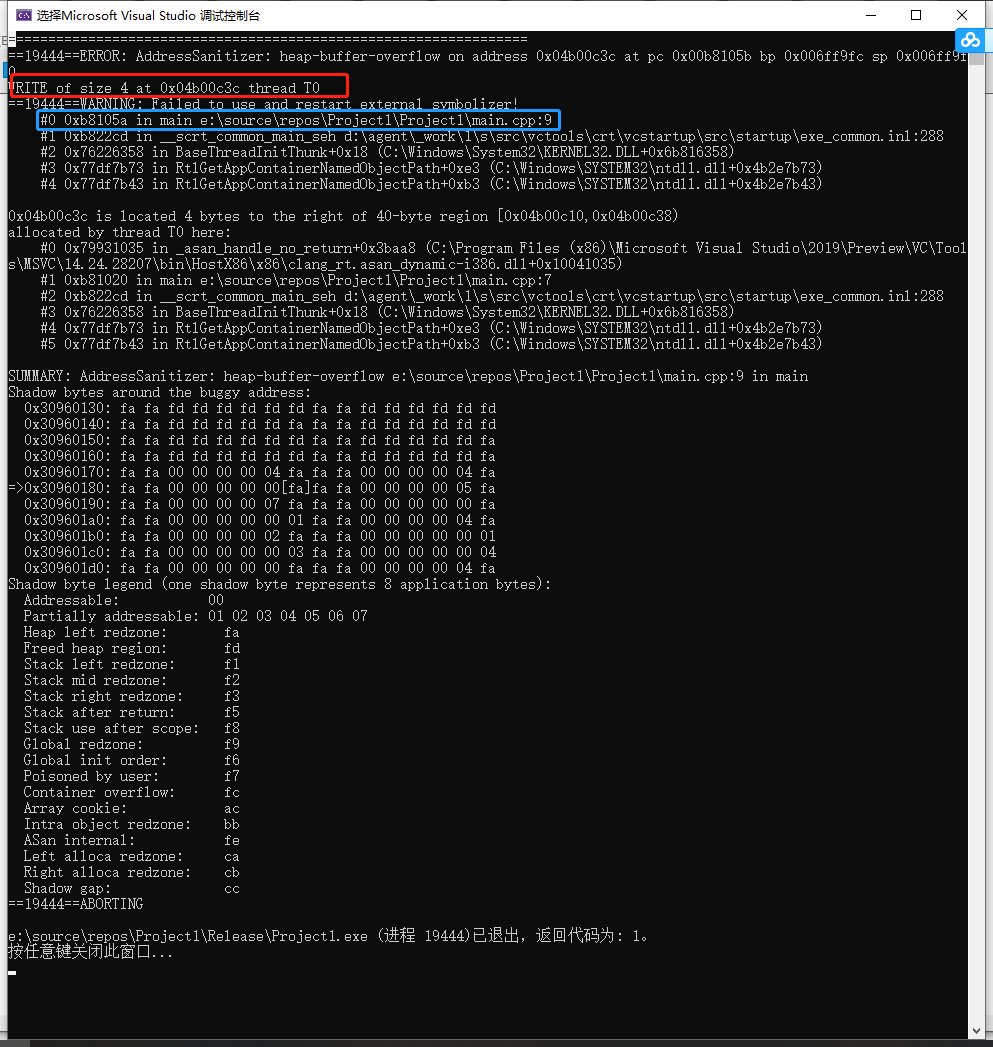
和前面在Mac OSX上用Clang的ASan输出基本一致。完整的文本:
=================================================================
==19444==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x04b00c3c at pc 0x00b8105b bp 0x006ff9fc sp 0x006ff9f0
WRITE of size 4 at 0x04b00c3c thread T0
==19444==WARNING: Failed to use and restart external symbolizer!
#0 0xb8105a in main e:\source\repos\Project1\Project1\main.cpp:9
#1 0xb822cd in __scrt_common_main_seh d:\agent\_work\1\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl:288
#2 0x76226358 in BaseThreadInitThunk+0x18 (C:\Windows\System32\KERNEL32.DLL+0x6b816358)
#3 0x77df7b73 in RtlGetAppContainerNamedObjectPath+0xe3 (C:\Windows\SYSTEM32\ntdll.dll+0x4b2e7b73)
#4 0x77df7b43 in RtlGetAppContainerNamedObjectPath+0xb3 (C:\Windows\SYSTEM32\ntdll.dll+0x4b2e7b43)
0x04b00c3c is located 4 bytes to the right of 40-byte region [0x04b00c10,0x04b00c38)
allocated by thread T0 here:
#0 0x79931035 in _asan_handle_no_return+0x3baa8 (C:\Program Files (x86)\Microsoft Visual Studio\2019\Preview\VC\Tools\MSVC\14.24.28207\bin\HostX86\x86\clang_rt.asan_dynamic-i386.dll+0x10041035)
#1 0xb81020 in main e:\source\repos\Project1\Project1\main.cpp:7
#2 0xb822cd in __scrt_common_main_seh d:\agent\_work\1\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl:288
#3 0x76226358 in BaseThreadInitThunk+0x18 (C:\Windows\System32\KERNEL32.DLL+0x6b816358)
#4 0x77df7b73 in RtlGetAppContainerNamedObjectPath+0xe3 (C:\Windows\SYSTEM32\ntdll.dll+0x4b2e7b73)
#5 0x77df7b43 in RtlGetAppContainerNamedObjectPath+0xb3 (C:\Windows\SYSTEM32\ntdll.dll+0x4b2e7b43)
SUMMARY: AddressSanitizer: heap-buffer-overflow e:\source\repos\Project1\Project1\main.cpp:9 in main
Shadow bytes around the buggy address:
0x30960130: fa fa fd fd fd fd fd fd fa fa fd fd fd fd fd fd
0x30960140: fa fa fd fd fd fd fd fa fa fa fd fd fd fd fd fd
0x30960150: fa fa fd fd fd fd fd fd fa fa fd fd fd fd fd fa
0x30960160: fa fa fd fd fd fd fd fd fa fa fd fd fd fd fd fa
0x30960170: fa fa 00 00 00 00 04 fa fa fa 00 00 00 00 04 fa
=>0x30960180: fa fa 00 00 00 00 00[fa]fa fa 00 00 00 00 05 fa
0x30960190: fa fa 00 00 00 00 07 fa fa fa 00 00 00 00 00 fa
0x309601a0: fa fa 00 00 00 00 00 01 fa fa 00 00 00 00 04 fa
0x309601b0: fa fa 00 00 00 00 02 fa fa fa 00 00 00 00 00 01
0x309601c0: fa fa 00 00 00 00 00 03 fa fa 00 00 00 00 00 04
0x309601d0: fa fa 00 00 00 00 00 fa fa fa 00 00 00 00 04 fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
Shadow gap: cc
==19444==ABORTING
e:\source\repos\Project1\Release\Project1.exe (进程 19444)已退出,返回代码为: 1。
按任意键关闭此窗口...
61. Android NDK使用AddressSanitizer
官方文档:Address Sanitizer | Android NDK | Android Developers
我的实践:
CMakeLists.txt中,库目标和可执行文件目标,都添加:
target_compile_options(bench PUBLIC -fsanitize=address -fno-omit-frame-pointer)
set_target_properties(bench PROPERTIES LINK_FLAGS -fsanitize=address)
执行的时候,其实是用了asan的动态库,所以需要先到ndk目录下找到libclang_rt.asan-arm-android.so,然后执行的脚本写成这样:
@echo off
adb shell mkdir -p /data/afq/images/humanbodyattr
adb shell mkdir -p /data/afq/debug/arm
adb push "E:/dev/optimize/data/images/humanbodyattr/resize_1.png" /data/afq/images/humanbodyattr/
adb push "E:/dev/optimize/data/images/cat_224.bmp" /data/afq/images/
adb push armeabi-v7a/testbed/testbed /data/afq
adb push e:/soft/Android/ndk-r17b/toolchains/llvm/prebuilt/windows-x86_64/lib64/clang/6.0.2/lib/linux/libclang_rt.asan-arm-android.so /data/afq/
adb shell "cd /data/afq; chmod +x ./testbed; export LD_LIBRARY_PATH=`pwd`; ./testbed"
::adb pull /data/afq/debug/arm "E:/dev/optimize/debug/"
用如上配置编译运行afq的android testbed,并没有有效的输出提示。wired。
62. 用二分法排查segfault的思路
一段程序,如果callstack看成一个数轴,那么可能是第n个点就踩坏内存了,但是第n+m个点才报segfault,或者第n-m个点就报segfault。
让后半段程序不执行(注释掉,或者干脆exit(1)),如果能正确运行,则让exit(1)的位置再往后一些。
结合代码本身,很容易判断出问题:比如我这次是syset_words.txt文件的路径是windows路径而不是android上的路径。。
63. exit()是标准库函数,而不是C语言内置函数
需要#include <stdlib.h>。在MSVC下不会报错,但是Clang下会暴露此问题。
64. NDK r17 (clang)使用unordered_map报错: error: implicit instantiation of undefined template ...
完整报错:
Line 18: E:/soft/Android/ndk-r17b/sources/cxx-stl/llvm-libc++/include\type_traits:1491:38: error: implicit instantiation of undefined template 'std::__ndk1::hash<std::__ndk1::basic_string<char, std::__ndk1::char_traits
, std::__ndk1::allocator > >'
查看CMakeLists.txt,已经开启C++11和-stdlib=libc++,还是有如上错误。最后发现,是自己的使用中,Visual Studio会自动添加string, iostream等头文件导致的。可以说,这个例子我感觉clang的编译提示有时候也不怎么友好。
问题解决:因为我用的是unordered_map<string, int>,因此需要#include <string>,又因为用了std命名空间,因此还需要#include <iostream>
反倒是,c++11和libc++不需要手动指定,就可以的。
65. -fPIC, -fpic, -fPIE, -fpie的含义和区别
-fPIC与-fpic都是在编译时加入的选项,用于生成位置无关的代码(Position-Independent-Code)。这两个选项都是可以使代码在加载到内存时使用相对地址,所有对固定地址的访问都通过全局偏移表(GOT)来实现。-fPIC和-fpic最大的区别在于是否对GOT的大小有限制。-fPIC对GOT表大小无限制,所以如果在不确定的情况下,使用-fPIC是更好的选择。
-fPIE与-fpie是等价的。这个选项与-fPIC/-fpic大致相同,不同点在于:-fPIC用于生成动态库,-fPIE用与生成可执行文件。再说得直白一点:-fPIE用来生成位置无关的可执行代码。
ref:关于-fPIC, -fpic, -fpie, -fPIE的一点理解
66. C/C++代码重构:使用结构体对象相互赋值,可以吗?
如果不是指针类型,而是原生的结构体类型对象,那么完全可以,而且应该这么做:
typedef strct Rect {
int left, right, top, bottom;
}Rect;
Rect rect;
rect.left = 1;
left.right = 2;
left.top = 3;
left.bottom = 4;
Rect shadow = rect; //直接赋值,而不是每个字段分别赋值。类型相同,每个字段会分别复制的,不需要程序员给编译器献殷勤。
但如果需要逐个字段挨个赋值的对象,是结构体指针对象,那么呵呵,显然要用memcpy,而不是直接赋值。直接赋值是指针之间的赋值啊!来看一个实际例子:
//===== 如下几行代码,感觉很长,很想重构:
pHumanBodyRes->lBodyNumber = pBodyRes->nObj;
pHumanBodyRes->pBodyGenderResultArray = pAERealEngine->pHumanBodyRes->pBodyGenderResultArray;
pHumanBodyRes->pBodyGenderConfArray = pAERealEngine->pHumanBodyRes->pBodyGenderConfArray;
pHumanBodyRes->pBodyClothUpperColorConfArray = pAERealEngine->pHumanBodyRes->pBodyClothUpperColorConfArray;
pHumanBodyRes->pBodyClothUpperColorResultArray = pAERealEngine->pHumanBodyRes->pBodyClothUpperColorResultArray;
pHumanBodyRes->pBodyClothLowerColorConfArray = pAERealEngine->pHumanBodyRes->pBodyClothLowerColorConfArray;
pHumanBodyRes->pBodyClothLowerColorResultArray = pAERealEngine->pHumanBodyRes->pBodyClothLowerColorResultArray;
pHumanBodyRes->pBodyClothSleeveLengthConfArray = pAERealEngine->pHumanBodyRes->pBodyClothSleeveLengthConfArray;
pHumanBodyRes->pBodyClothSleeveLengthResultArray = pAERealEngine->pHumanBodyRes->pBodyClothSleeveLengthResultArray;
pHumanBodyRes->pBodyClothLowerLengthConfArray = pAERealEngine->pHumanBodyRes->pBodyClothLowerLengthConfArray;
pHumanBodyRes->pBodyClothLowerLengthResultArray = pAERealEngine->pHumanBodyRes->pBodyClothLowerLengthResultArray;
第一次尝试,结果会产生segfault:
pHumanBodyRes = pAERealEngine->pHumanBodyRes;
pHumanBodyRes->lBodyNumber = pBodyRes->nObj;
第二次尝试,终于写对了(记得#include <stringh>)
memcpy(pHumanBodyRes, pAERealEngine->pHumanBodyRes, sizeof(ASHA_HUMANBODYATTRIRESULT));
pHumanBodyRes->lBodyNumber = pBodyRes->nObj;
67. 字符串常量之间用空格分隔,仍然是一个整体
e.g.
const char* hh = "123" "345";
printf("%s\n", hh);
输出:
123345
68. error: expected primary-expression before ‘[’ token
这个错误在写一道oj题目hdu1233的时候遇到。完整报错:
1233.cpp: In function ‘int main()’:
1233.cpp:30:33: error: expected primary-expression before ‘[’ token
scanf("%d %d %d", &a[i].u, &a[i].v, &a[i].w);
对应的源码文件:
#include <stdio.h>
#include <iostream>
#include <algorithm>
using namespace std;
typedef struct ss {
int u, v, w;
}a[5000];
int p[103];
bool cmp(const ss& a, const ss& b) {
return a.w < b.w;
}
int find(int x) {
return p[x]==x?x:p[x]=find(p[x]);
}
int main() {
int n; // number of nodes
while(scanf("%d", &n)!=EOF && n) {
int sum = 0;
int m = n*(n-1)/2; //number of edges
for(int i=1; i<=m; i++) {
p[i] = i;
}
for(int i=1; i<=m; i++) {
scanf("%d %d %d", &a[i].u, &a[i].v, &a[i].w);
}
sort(a+1, a+1+n, cmp);
for(int i=1; i<=n; i++) {
int b = find(a[i].u);
int c = find(a[i].v);
if (b==c) continue;
Union(b, c);
sum += a[i].w;
}
printf("%d\n", sum);
}
return 0;
}
问题的原因是,我习惯性的写能同时兼容C和C++的代码,定义结构体的时候同时使用了typedef和顺带定义的变量的名字,然而这样子其实是错误的:
typedef struct ss {
int u, v, w;
}a[MAXN];
应该另行定义a,而不是在这里偷懒直接写。
69. volatile关键字
C语言:关键字volatile详解! 这篇博客讲的比较清楚。简单来说,volatile是一个修饰符,(同样作为修饰符的还有const关键字,可以用来类比),volatile关键字的作用是,告诉编译器生成二进制码的时候,对于volatile关键字修饰的变量,不要从寄存器去取它的值,而是只能从内存去取。
volatile有什么用呢?典型例子是多线程场景中多个线程同时需要访问的变量,每个线程随时都可能修改这个变量的取值,读到不一样的结果,再分别根据这个变量的值,执行不同的代码。
还有一个是asm volatile,例如NCNN中的汇编优化,就是这样修饰的,作用是不让编译器去优化,而是执行手工写出来的优化指令。
并行编程之多线程共享非volatile变量,会不会可能导致线程while死循环 这篇文章则具体说了 “cache” 是否会影响到volatile修饰的变量,答案是不会,因为遵循MESI协议。
然而看到这篇问答 Safe to use volatile bool to force another thread to wait? (C++) 后,我发现我在考虑的代码(age gender race 或 liveface 的SDK中,preview接口的实现方式),不是线程安全的。所谓线程安全,是说不管线程按照什么顺序执行,结果都一样。为什么用volatile修饰的变量,并不能做到线程安全呢?因为需要确保cache-coherent,也就是cache一致性。而x86平台恰好提供了这个性质,但其他平台不一定。如果一定要线程安全,需要把volatile修饰改成C++11的std::atomic
好吧,看来这个小领域我不太了解,前面搜到的几篇文章估计也有问题。C++多线程有必要加volatile么? 知乎上的大V们明确说了,volatile和多线程没有关系,并且用volatile来实现线程安全完全是错的。
ok,现在需要搞懂两个问题:
1)什么是线程安全?公司的SDK的preview接口,是否需要保证线程安全?不保证线程安全的话,会有什么问题?
2)不使用volatile的话,用什么方式实现线程安全?不要动辄就提std::atomic
举一个例子:
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
static int vvv = 1;
void* thread1(void* args) {
sleep(2);
printf("sss\n");
vvv = -1;
return NULL;
}
int main() {
pthread_t t;
int re = pthread_create(&t, NULL, &thread1, NULL);
if (re<0) {
perror("thread");
}
while(vvv>0) {
//sleep(1);
}
return 0;
}
这样编译:
gcc -c thread3.c -pthread
则运行”符合预期“:2秒后主线程结束,整个进程结束。
如果这样编译:
gcc -c thread3.c -thread -O3
则主线程一直处于阻塞状态,并没有从子线程切换过来。这是因为变量vvv被优化了。
好,我们现在用volatile来修饰vvv的定义:
static volatile int vvv = 1;
然后编译:gcc -c thread3.c -thread -O3,Linux x86_64下运行没有问题。这是侥幸吗?
C/C++ Volatile关键词深度剖析 这篇文章其实已经说的比较清楚了(奈何图像都挂了):volatile修饰的变量state,当state的状态发生变化,是否一定说明state状态改变的语句之前的语句都被执行了?显然不是!编译器可以自行优化,如果优化后 非volatile修饰的变量 和 volatile修饰的变量 所在语句按照反序执行,那么state变量的取值无法用来判断前一个线程是否结束!
通过将flag变量声明为volatile属性,很好的利用了本文前面提到的C/C++ Volatile的两个特性:”易变”性;”不可优化”性。按理说,这是一个对于volatile关键词的很好应用,而且看到这里的朋友,也可以去检查检查自己的代码,我相信肯定会有这样的使用存在。
但是,这个多线程下看似对于C/C++ Volatile关键词完美的应用,实际上却是有大问题的。问题的关键,就在于前面标红的文字:由于flag = true,那么假设Thread1中的something操作一定已经完成了。flag == true,为什么能够推断出Thread1中的something一定完成了?其实既然我把这作为一个错误的用例,答案是一目了然的:这个推断不能成立,你不能假设看到flag == true后,flag = true;这条语句前面的something一定已经执行完成了。这就引出了C/C++ Volatile关键词的第三个特性:顺序性。
也就是说,即使在当前代码中用了多线程、用了volatile、结果正确,但是有可能某个瞬间产生莫名的crash,单就x86架构来说它运行store-load乱序,也就是先读取再写入。呵呵。所以说,用volatile来保证线程安全,其实是利用UB来搞事情,最终是要坑到自己的,一般人查都查不到哪里出错。
取代“使用volatile来保证线程安全"的正确做法是:确保happens-before语义:

volatile关键字无法确保happens-before语义。Mutex、Spinlock、RWLock则可以保证
(但是,Java中的volatile关键字,相比于C/C++的volatile关键字,有新增其他特性,使得Java中的volatile关键字能保证提供happens-before语义)。
70. 缺少返回值导致android arm console crash
int Landmark_Processor::detect_face_and_landmark_(ASVLOFFSCREEN* asvl){
long t_start = fc_gettime();
int ret = ALT_LandmarkTracking(mem_handle_, face_tracker_, asvl, face_input_mode_, ALT_OPF_0_HIGHER_EXT, face_info_);
if (ret != 0) {
fprintf(stderr, "failed to detect face\n");
return ret;
}
printf("--- landmark cost %lu ms\n", fc_gettime() - t_start);
}
如上,这个函数看起来非常平凡,并且VS2013下,debug/release模式都能正常运行。偏偏到arm android上会crash。为啥?因为没有返回值!!
血泪教训,以后每个工程还是必须要包含utils.cmake。
71. 警惕整数乘法
size_t buffer_size = 1024 * 1024 * 2048;
printf("buffer_size: %zu", buffer_size);
输出:

正确的做法是,整数后面添加U,表示unsigned int,确保不会溢出:
size_t buffer_size = 1024U * 1024 * 2048;
printf("buffer_size: %zu", buffer_size);

72. C和C++的标准库头文件并不等同
例如使用std::clock_t,遭遇报错提示:
'clock_t' was not declared in this scope
排查发现,当前是.cpp文件,用g++编译,但是#include <math.h>而不是#include <cmath>。注意,cmath里面包了一层std命令空间,而math.h则显然没有。
73. 位运算一定要注意操作符优先级,最好是完备的使用小括号
举例:想判断数字data是否是整数N(2的幂次)的倍数。来看这个实现:
template<int N, typename T> static inline
bool isAligned(const T& data)
{
assert( N&(N-1) == 0 ); //ensure N is power of 2
return (((size_t)data) & (N-1))==0;
}
实际执行发现,结果不对,需要用括号把N&(N-1)括起来:
template<int N, typename T> static inline
bool isAligned(const T& data)
{
assert( (N&(N-1)) == 0 ); //ensure N is power of 2
return (((size_t)data) & (N-1))==0;
}
74. Visual Studio调试时监视变量显示了错误值
调试自行移植的OpenCV源码时发现的:
template<typename ST, typename DT> struct FixedPtCastEx
{
typedef ST type1;
typedef DT rtype;
FixedPtCastEx() : SHIFT(0), DELTA(0) {}
FixedPtCastEx(int bits) : SHIFT(bits), DELTA(bits ? 1 << (bits - 1) : 0) {
printf("wait for debug\n"); //----(1)
}
DT operator()(ST val) const {
printf("wait for debug\n"); //---(2)
return saturate_cast<DT>((val + DELTA) >> SHIFT);
}
int SHIFT, DELTA;
};
其中(1)和(2)原本没有print语句;原本的实现下,断点到(2)对应的函数时,监视到SHIFT取值为128;而实际上SHIFT根据bit赋值的,bits等于16。
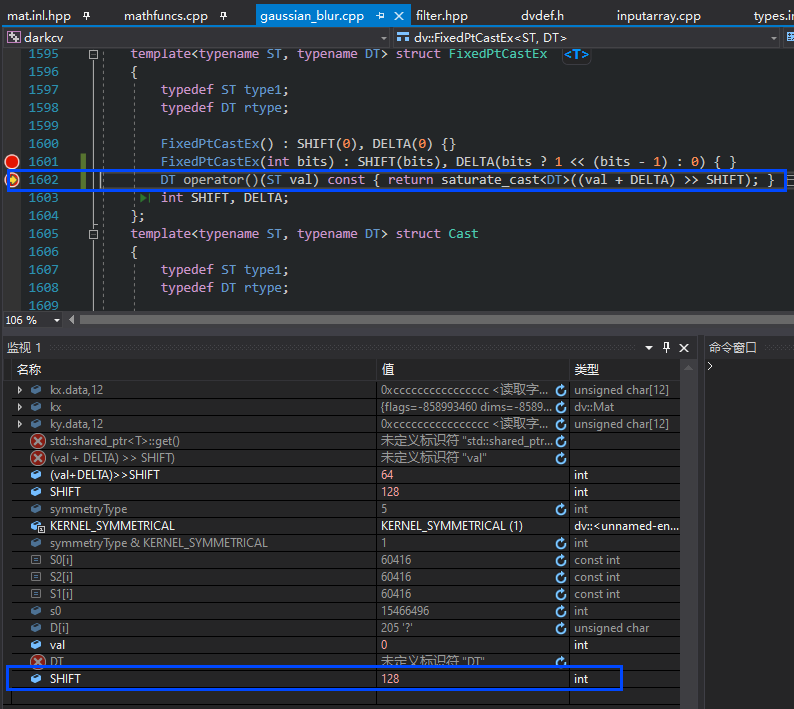

而添加了(1)和(2)的打印语句后,监视到SHIFT取值为16,总算正常了。
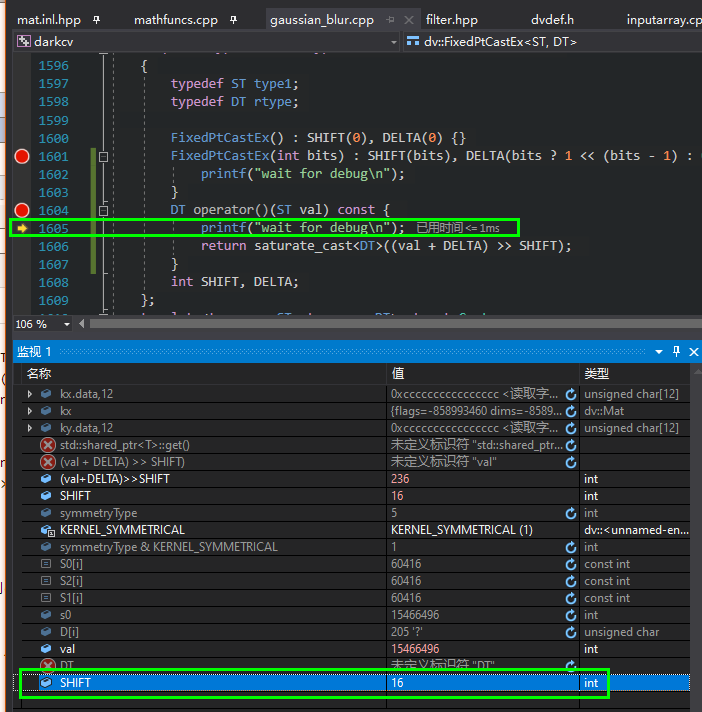
其实这是因为函数体只有一行语句,和左右大括号{}放在同一行了,而如果此时没有“step in”到那一行代码对应的调用(saturate_cast)再出来,SHIFT的值就显示的不正确。。。问题是,我初始化的时候给SHIFT赋值了啊!
看到这个帖子:Debugging shows wrong values in popups.,MSFT官方人员说最新VS版本已经修复。这个回复的时间是2018年,显然说的不可能是VS2019,说的肯定是VS2017。但是我现在用的就是最新版VS2017,

VS2017还是需要改进。
75. Visual Studio监视窗口查看寄存器
最近学习x86汇编,发现可以在监视窗口查看寄存器里的值,例如ebp里的,就输入ebp即可。如果有和寄存器同名变量,则watch窗口显示的是变量的名字;此时用$ebp或@ebp就可以查看寄存器里的值。
寄存器算是“伪变量”,Visual Studio 调试器中的伪变量
76. Visual Studio监视窗口显示字符串,UTF-8格式显示
变量名,str
例如变量名为str,则使用:
str,s8
即可以UTF-8编码形式显示。某些时候对于乱码的中文有帮助。
77. Visual Studio监视窗口显示16进制数字
变量名,H或变量名,X
例如变量名为data,则使用:
data,H
显示data的16进制。对于寄存器、指针等类型,调试阶段挺有帮助的。
78. 少用printf,多用fprintf(stdout
在写内存追踪/报告工具lufter的时候,发现printf函数会调用malloc:重写的malloc函数里,没有加锁,然后调用了printf,产生了无限递归从而segment fault。
根据这个经验,遇到内存相关的错误时,应当避免使用任何和内存分配相关的函数,包括隐式分配和显示分配的;而printf就是隐式申请堆内存的,应该避免。
而今天(2020-05-28 16:21:30)这个经验得以应用:帮张永昌调试BSD的某个版本,在YUV420上执行cropresize函数,发现在Windows上结果正确,在ARM上结果不对。
首先排查避免了链接时多个同名符号的问题。(##)
其次使用utils.cmake,使用了严格的编译选项检查。
然后是在ARM Android上复现问题。期间一直pthread链接有问题,发现是CMake忘记传入-DANDROID_PLATFORM=android-24 ^导致。
再后面就是用fprintf(stdout替代printf。替换后,Windows下结果也不对了,而这则利于进一步排查问题:可以用Visual Studio做单步debug了。
其实这个时候逐渐替换printf为fprint时,发现结果会不稳定。这是典型的写入内存越界了。如果有良好的直觉,就可以知道是写入到不该写的地方,并且被写入的地方是堆空间:由于ASLR机制的存在,每次堆空间都会变。当然,这里也可以考虑固定地址。不过永昌这里没接触这么底层,选择不设置。
再后面水到渠成,对方对于自己代码中写了bug的假设有了进一步的信心(而不是一开始的:“我肯定没写错”)。最后发现是ASVL数据结构上获取UV数据时,偏移量写错了。应该是asvl[0]+offset,写成了asvl[1]+offset。
这个问答中提到说fprintf(stderr是没有每次重新申请buffer的,不过我测试下来并不正确,而是stdout没有buffer。。。
79. sprintf会自动追加 NULL 字符 (\0)
sprintf
int sprintf ( char * str, const char * format, ... );
Write formatted data to string
Composes a string with the same text that would be printed if format was used on printf, but instead of being printed, the content is stored as a C string in the buffer pointed by str.
The size of the buffer should be large enough to contain the entire resulting string (see snprintf for a safer version).
A terminating null character is automatically appended after the content.
例如调试阶段设两个端点,分别看time数组的内存,就能看出确实追加了\0
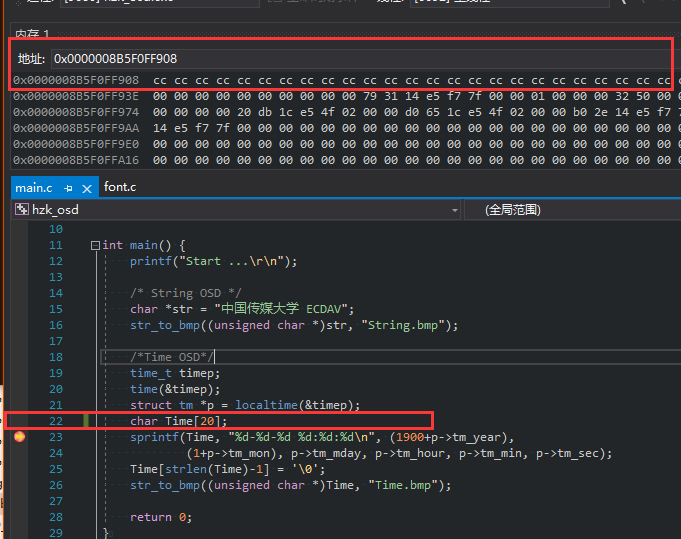
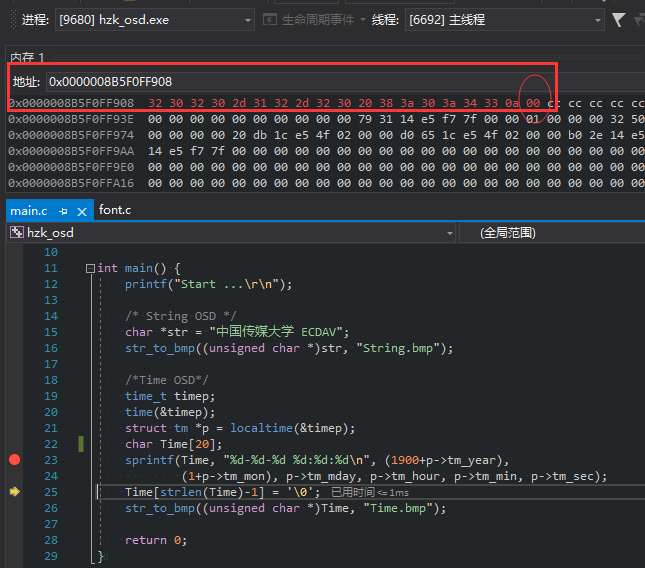
80. strlen 的判断,依赖于NULL(\0)
因此如果是 sprintf 后,调用strlen,可以得到结果;
而如果用单个字符的数组初始化字符串数组,则不会自动添加'\0',会导致strlen越界:
char data[] = { 'H', 'e', 'l', 'l', 'o' };
而如果是如下方式的初始化则会自动追加\0:
char data[] = { "Hello" };
