

Git使用总结
Git 概述
何为版本控制?
版本控制是一种记录文件内容变化,以便将来查阅特定版本修订情况的系统。版本控制其实最重要的是可以记录文件修改历史记录,从而让用户能够查看历史版本,方便版本切换。
为什么需要版本控制?
个人开发过渡到团队协作。
版本控制工具
集中式版本控制工具
代表:CVS、 SVN(Subversion)、 VSS……
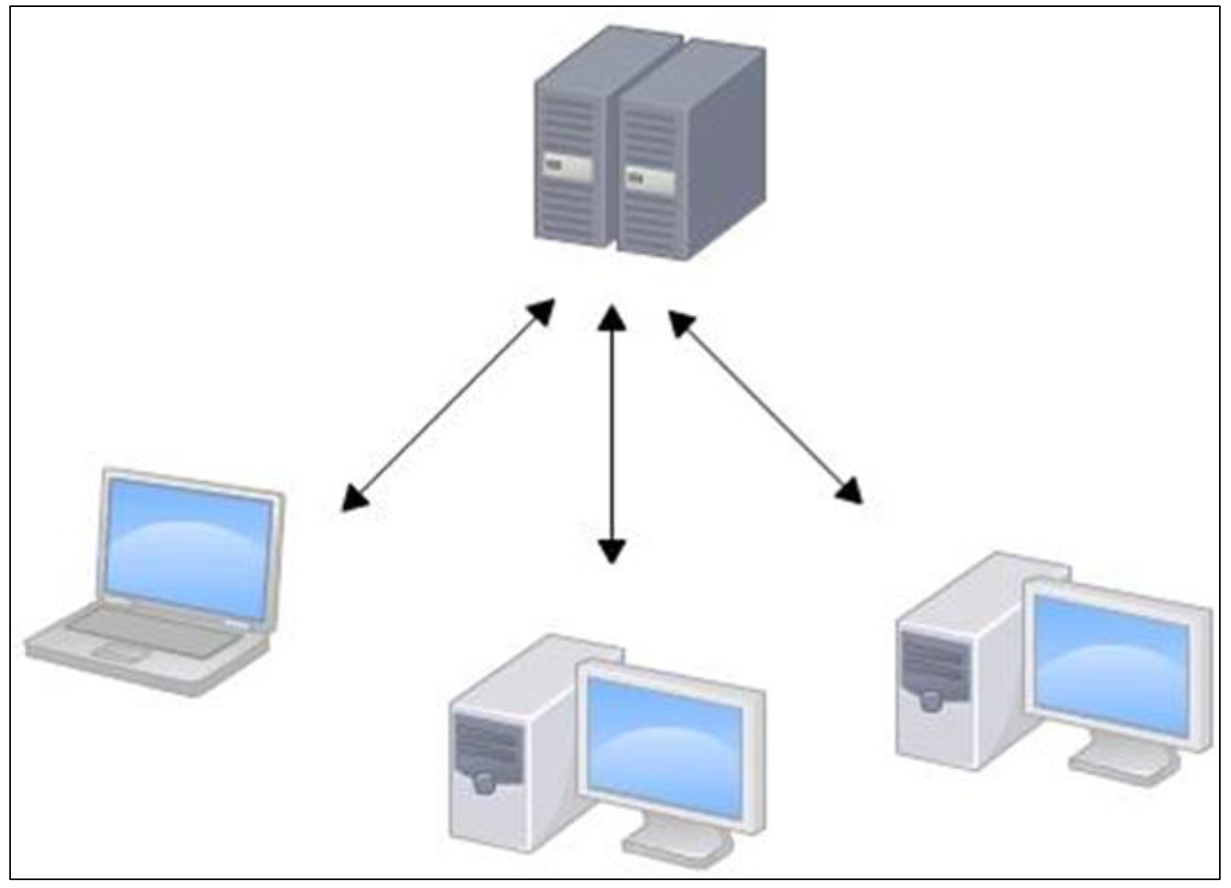
集中化的版本控制系统诸如 CVS、 SVN 等,
- 都有一个单一的集中管理的服务器,保存所有文件的修订版本,
- 而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
多年以来,这已成为版本控制系统的标准做法。
优点:
- 每个人都可以在一定程度上看到项目中的其他人正在做些什么。
- 而管理员也可以轻松掌控每个开发者的权限,
- 并且管理一个集中化的版本控制系统, 要远比在各个客户端上维护本地数据库来得轻松容易。
缺点:
中央服务器的单点故障。如果服务器宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。
分布式版本控制工具
代表:Git、 Mercurial、 Bazaar、 Darcs……
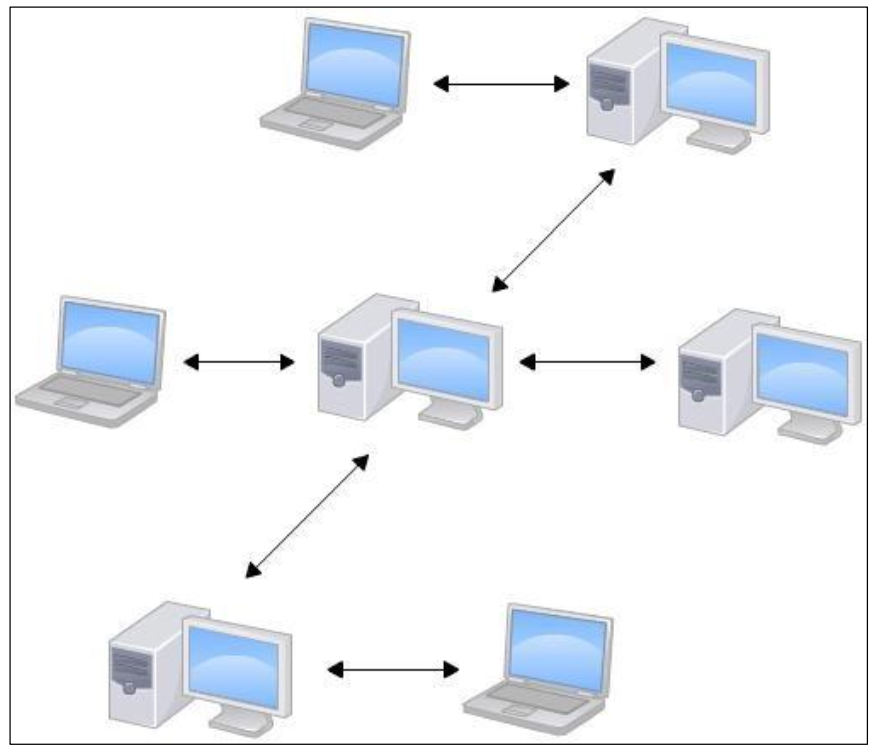
像 Git 这种分布式版本控制工具,
- 客户端提取的不是最新版本的文件快照,而是把代码仓库完整地镜像下来(本地库)。
- 这样任何一处协同工作用的文件发生故障,事后都可以用其他客户端的本地仓库进行恢复。因为每个客户端的每一次文件提取操作,实际上都是一次对整个文件仓库的完整备份。
分布式的版本控制系统出现之后,解决了集中式版本控制系统的缺陷:
- 服务器断网的情况下也可以进行开发(因为版本控制是在本地进行的)
- 每个客户端保存的也都是整个完整的项目(包含历史记录, 更加安全)
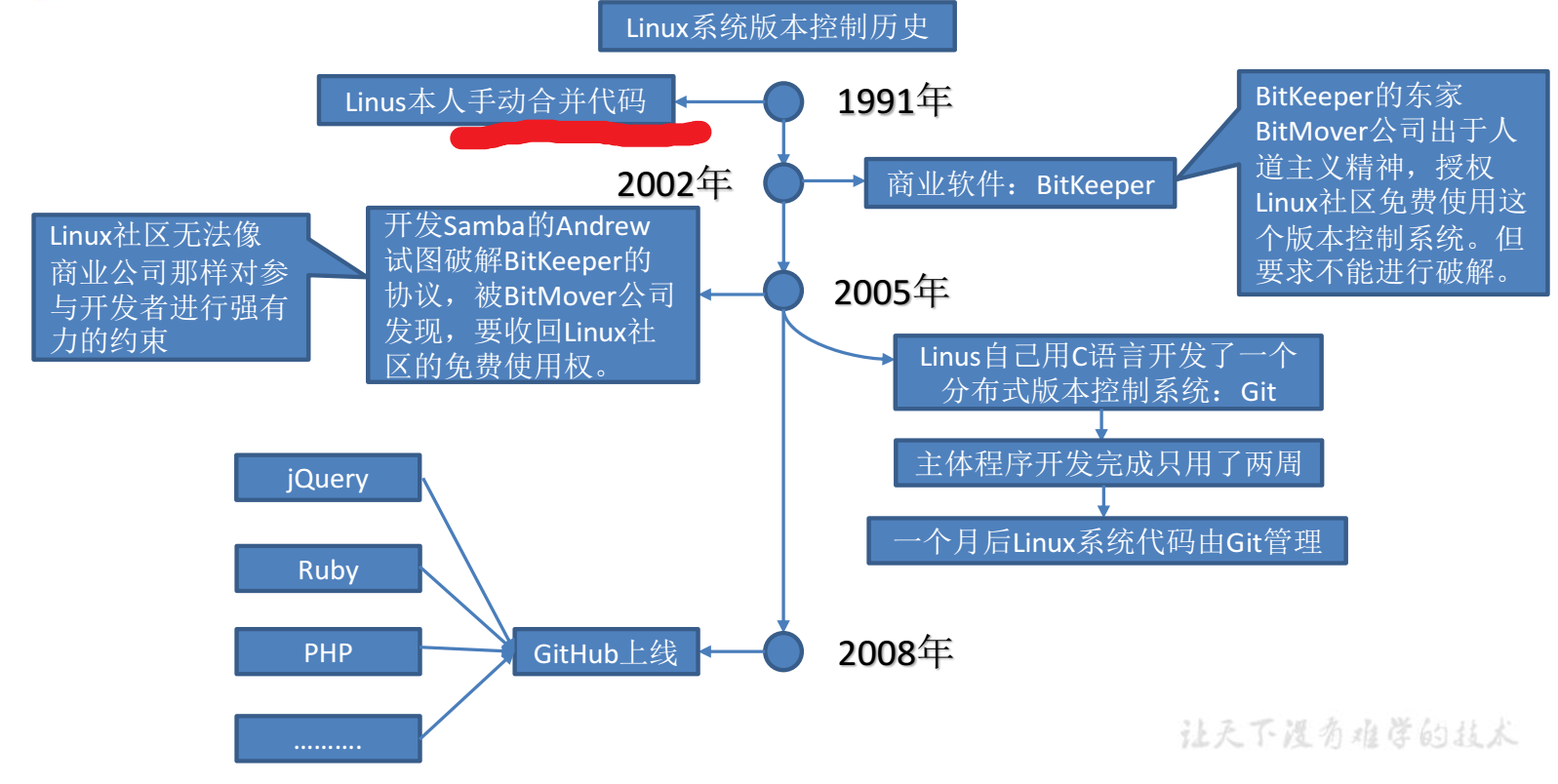
Git 简史
Git 工作机制
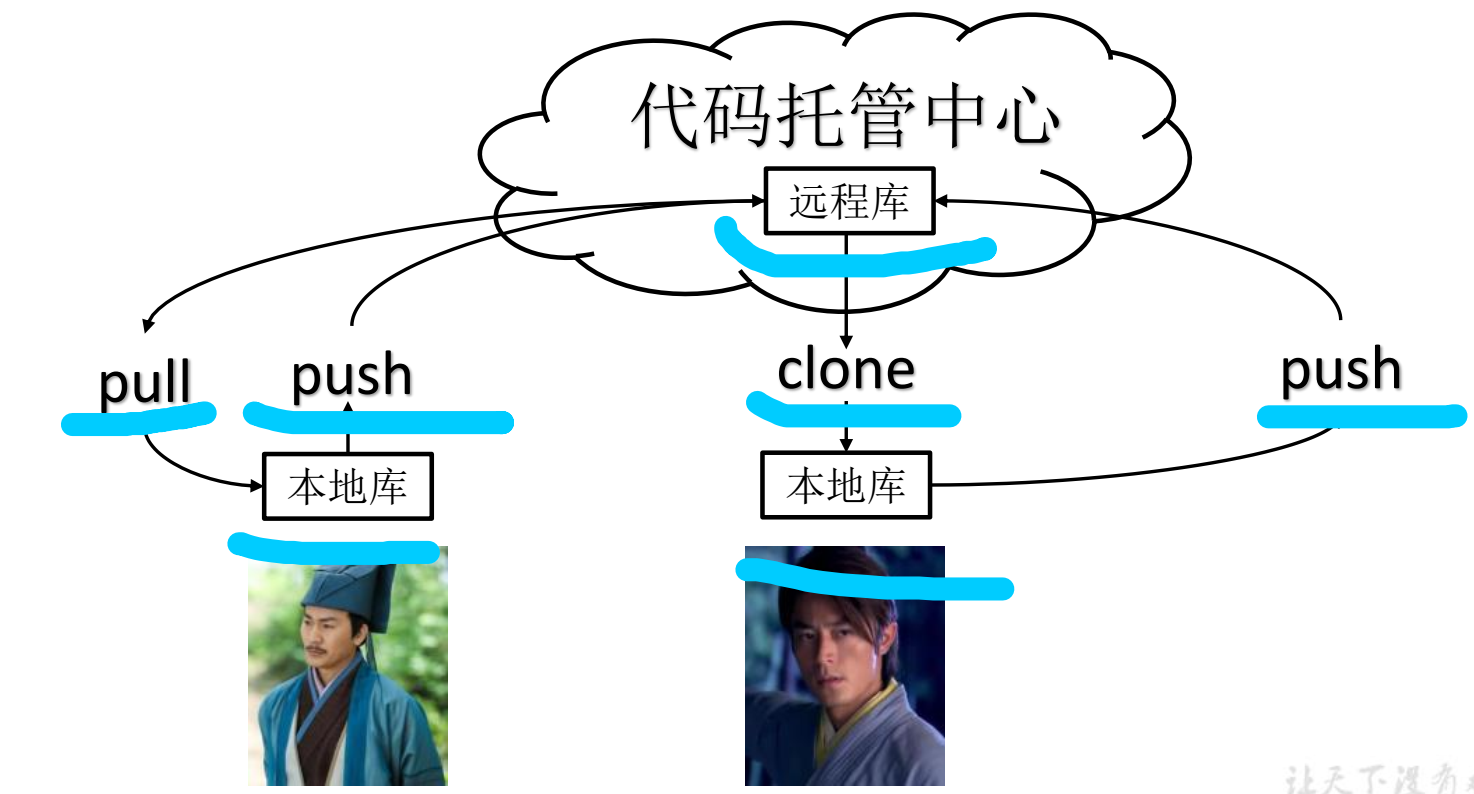
Git 和代码托管中心
代码托管中心是基于网络服务器的远程代码仓库,一般我们简单称为远程库。

Git 的核心概念理论
保存的是文件的完整快照
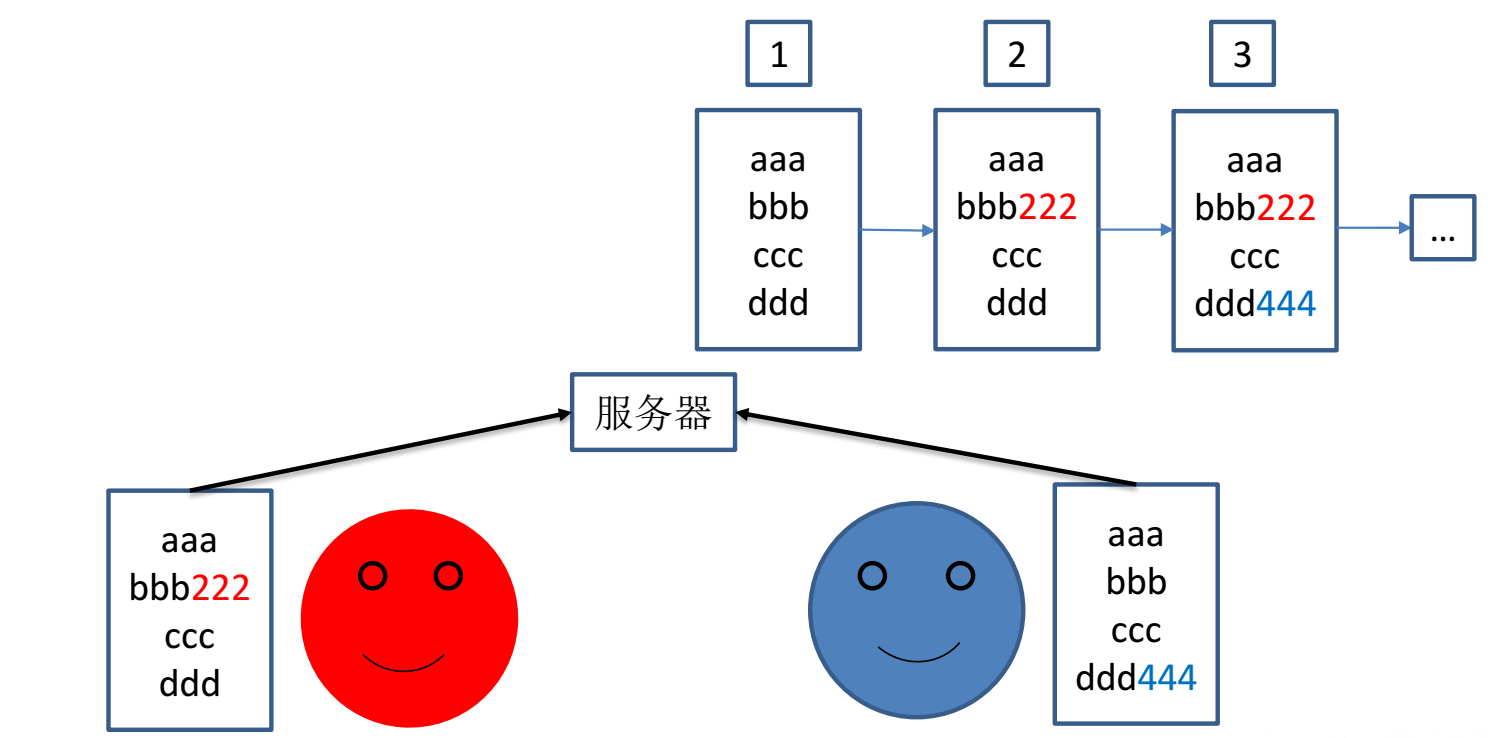
Git是一个分布式版本控制系统,保存的是文件的完整快照,而不是差异变化或者文件补丁。
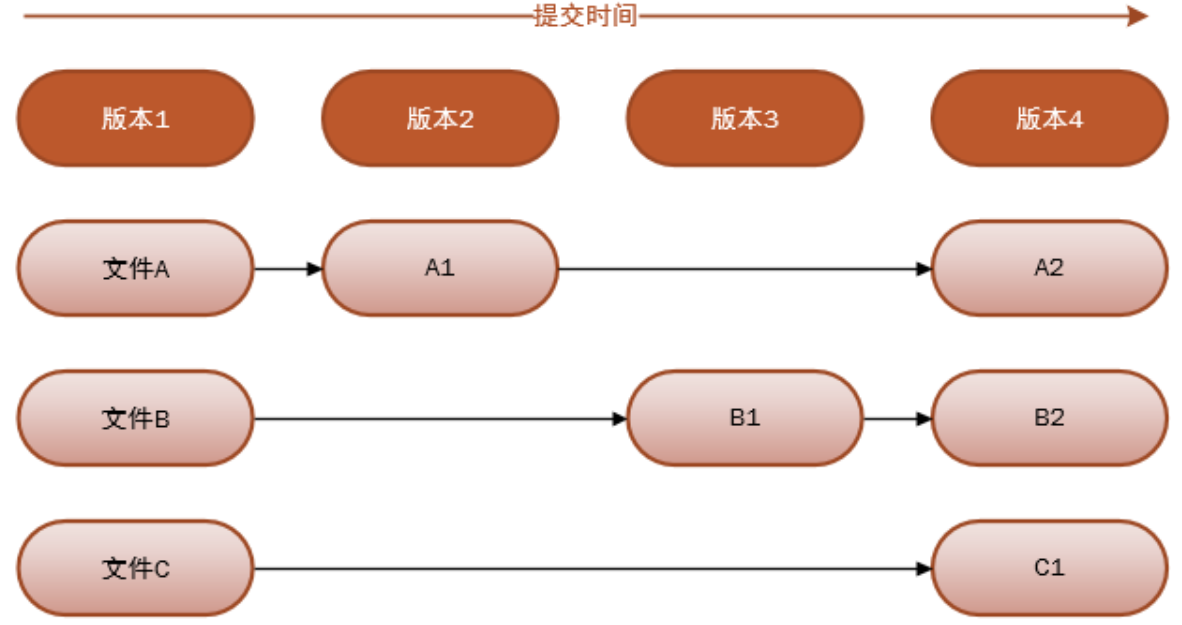
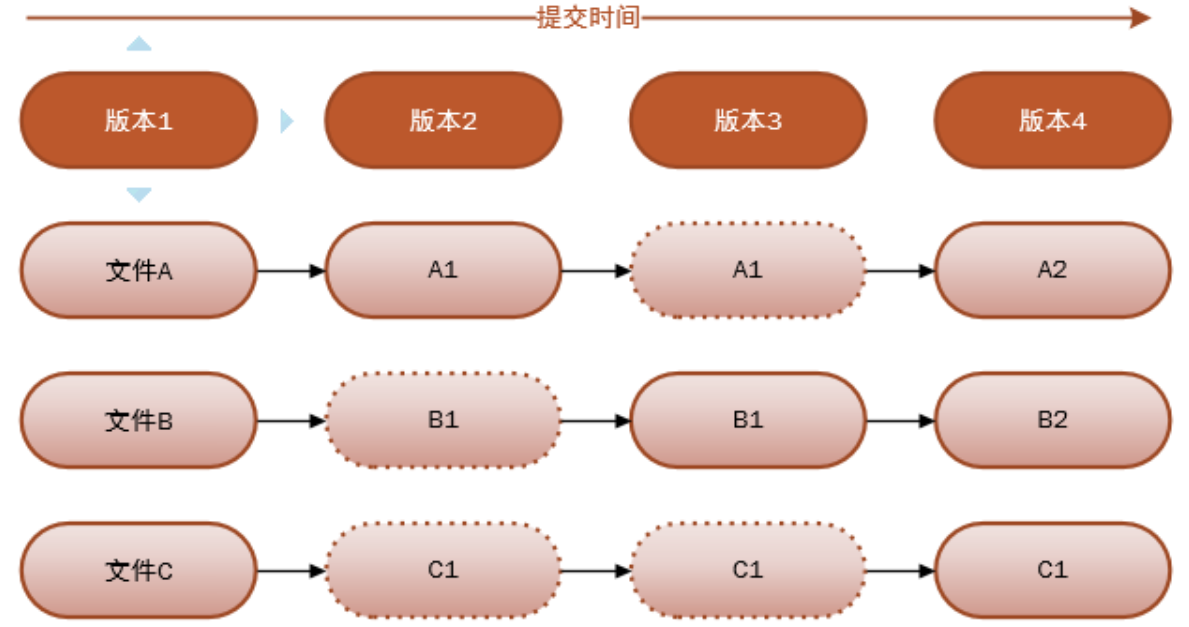
Git每一次提交都是对项目文件的一个完整拷贝,因此你可以完全恢复到以前的任一个提交而不会发生任何问题。这里有一个问题:如果我的项目大小是10M,那Git占用的空间是不是随着提交次数的增加线性增加呢?我提交(commit)了10次,占用空间是不是100M呢?很显然不是,Git是很智能的,如果文件没有变化,它只会保存一个指向上一个版本的文件的指针,即,对于一个特定版本的文件,Git只会保存一个副本,但可以有多个指向该文件的指针。
另外注意,
- Git最适合保存文本文件,事实上Git被设计出来就是为了保存文本文件的,例如各种语言的源代码,因为Git可以对文本文件进行很好的压缩和差异分析(大家都见识过了,Git的差异分析可以精确到你添加或者删除了某个字母)。
- 而二进制文件像视频,图片等,Git也能管理,但不能取得较好的效果(压缩比率低,不能差异分析)。
实验证明,一个 500k 的文本文件经Git压缩后仅 50k 左右,稍微改变内容后两次提交,会有两个 50k 左右的文件,没错的,保存的是完整快照。而对于二进制文件,像视频,图片,压缩率非常小, Git 占用空间几乎随着提交次数线性增长。
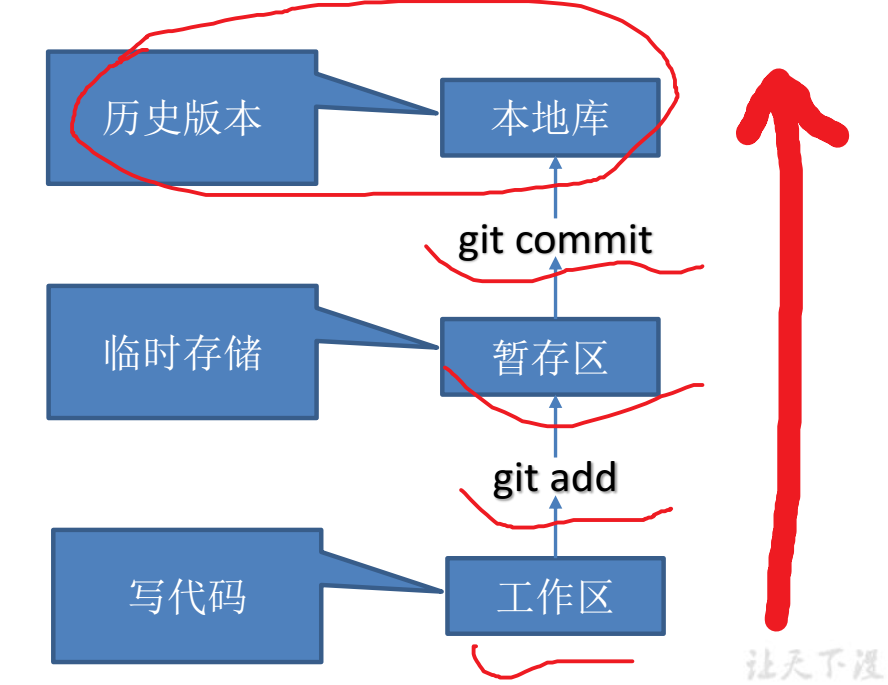
Git的基本流程
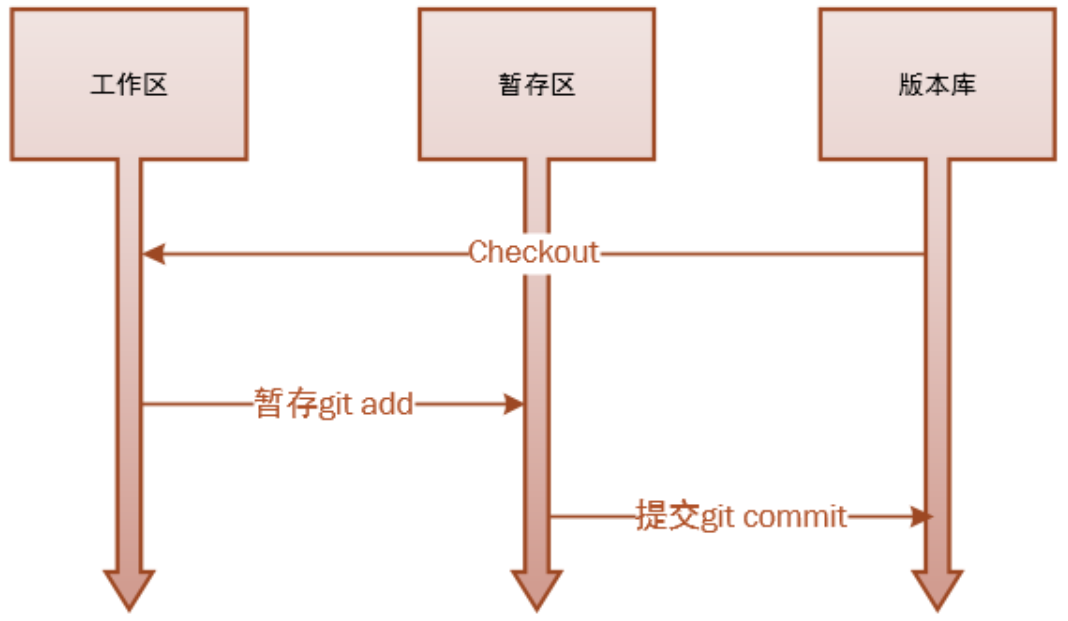
Git工程有三个工作区域:
- 工作目录,工作目录是你当前进行工作的区域;
- 暂存区域,暂存区域是你运行git add命令后文件保存的区域,Git提交实际读取的是暂存区域的内容,而与工作区域的文件无关;
- 本地仓库。本地仓库就是版本库,记录了你的工程某次提交的完整状态和内容,这意味着你的数据永远不会丢失。
相应的,文件也有三种状态:
- 已提交(committed),已提交表示该文件已经被安全地保存在本地版本库中了;
- 已修改(modified),已修改表示修改了某个文件,但还没有提交保存;
- 已暂存(staged),已暂存表示把已修改的文件放在下次提交时要保存的清单中,即暂存区域。
所以使用Git的基本工作流程就是:
- 在工作区域增加,删除或者修改文件。
- 运行git add,将文件快照保存到暂存区域。
- 提交更新,将文件永久版保存到版本库中。
Git对象
现在已经明白Git的基本流程,但Git是怎么完成的呢?Git怎么区分文件是否发生变化?下面简单介绍一下Git的基本原理。
SHA-1 校验和
Git 是一套内容寻址文件系统。意思就是Git从核心上来看不过是简单地存储键值对(key-value),value是文件的内容,而key是文件内容与文件头信息的40个字符长度的 SHA-1 校验和,例如:5453545dccd33565a585ffe5f53fda3e067b84d8。Git使用该校验和不是为了加密,而是为了数据的完整性,它可以保证,在很多年后,你重新checkout某个commit时,一定是它多年前的当时的状态,完全一摸一样。当你对文件进行了哪怕一丁点儿的修改,也会计算出完全不同的 SHA-1 校验和,这种现象叫做“雪崩效应”(Avalanche effect)。
SHA-1 校验和因此就是上文提到的文件的指针,这和C语言中的指针很有些不同:C语言将数据在内存中的地址作为指针,Git将文件的 SHA-1 校验和作为指针,目的都是为了唯一区分不同的对象。但是当C语言指针指向的内存中的内容发生变化时,指针并不发生变化,但Git指针指向的文件内容发生变化时,指针也会发生变化。所以,Git中每一个版本的文件,都有一个唯一的指针指向它。(个人:也就是都有一个唯一的SHA-1校验和)
文件(blob)对象,树(tree)对象,提交(commit)对象
blob 对象保存的仅仅是文件的内容,tree 对象更像是操作系统中的目录,它可以保存blob对象和tree 对象。一个单独的 tree 对象包含一条或多条 tree 记录,每一条记录含有一个指向 blob 对象或子 tree 对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息等:
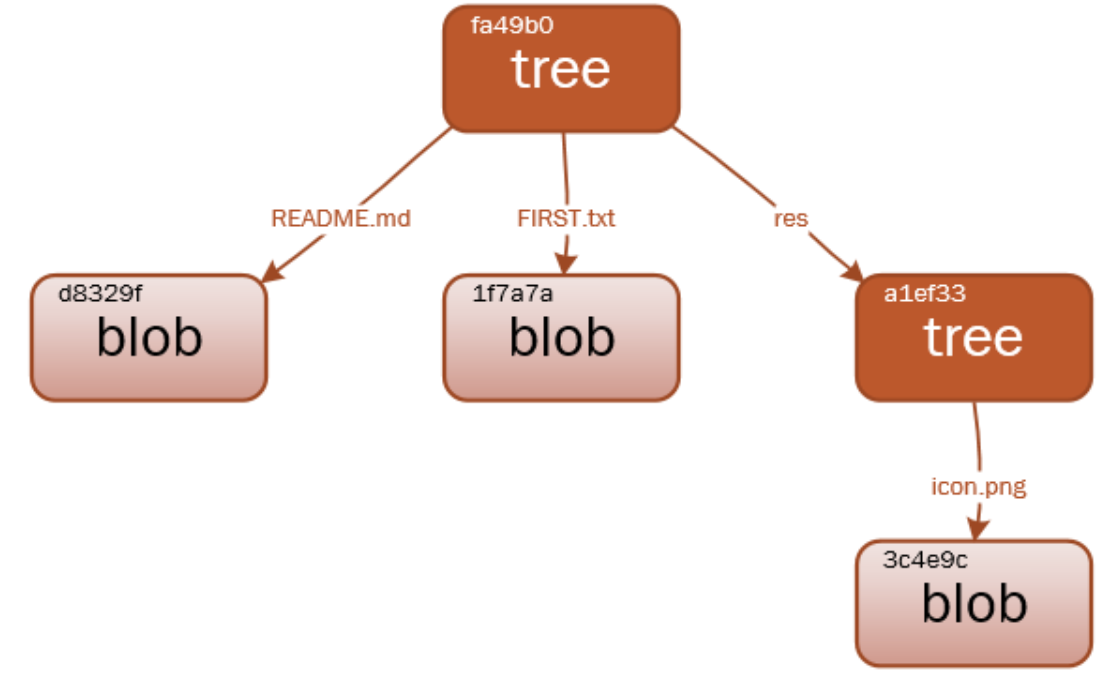
当你对文件进行修改并提交时,变化的文件会生成一个新的blob对象,记录文件的完整内容(是全部内容,不是变化内容),然后针对该文件有一个唯一的 SHA-1 校验和,修改此次提交该文件的指针为该 SHA-1 校验和,而对于没有变化的文件,简单拷贝上一次版本的指针即 SHA-1 校验和,而不会生成一个全新的blob对象,这也解释了10M大小的项目进行10次提交总大小远远小于100M的原因。
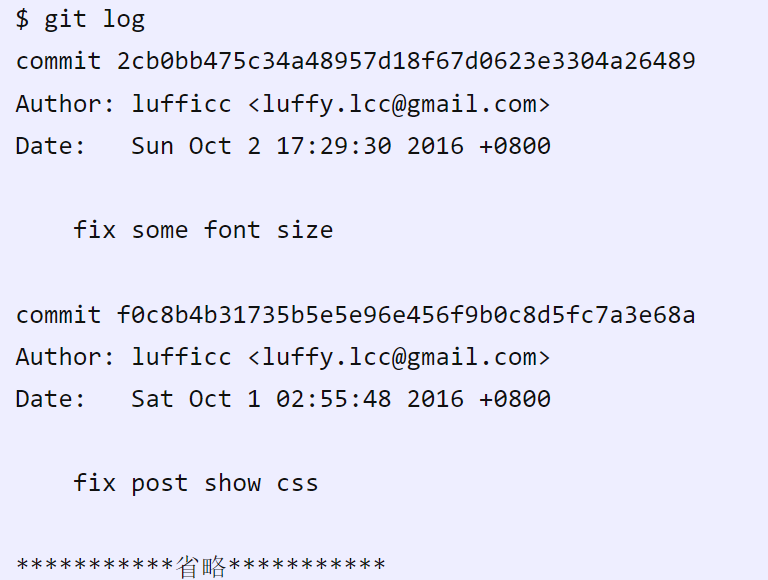
另外,每次提交可能不仅仅只有一个 tree 对象,它们指明了项目的不同快照,但你必须记住所有对象的 SHA-1 校验和才能获得完整的快照,而且没有作者,何时,为什么保存这些快照的原因等信息。commit对象就是为了解决这些问题诞生的,commit 对象的格式很简单:指明了该时间点项目快照的顶层tree对象、作者/提交者信息(从 Git 设置的 user.name 和 user.email中获得)以及当前时间戳、一个空行,上一次的提交对象的ID以及提交注释信息。你可以简单的运行git log来获取这新信息:
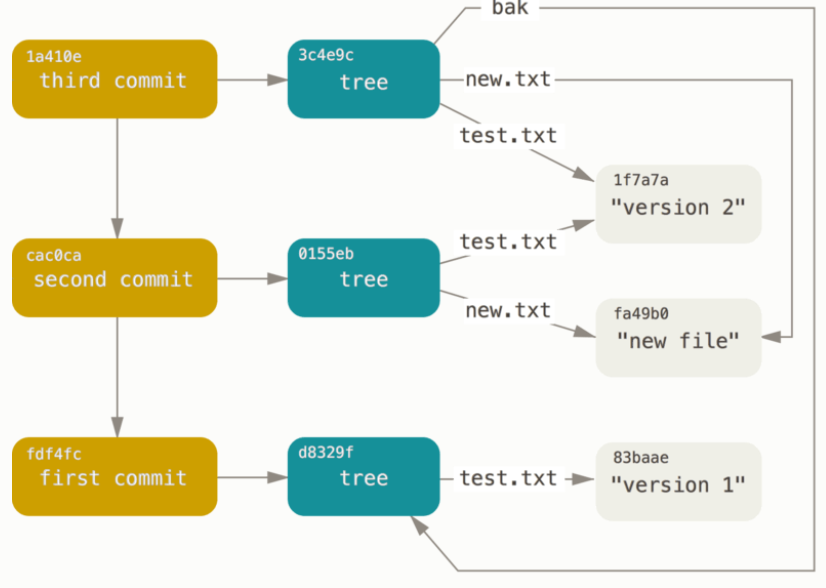
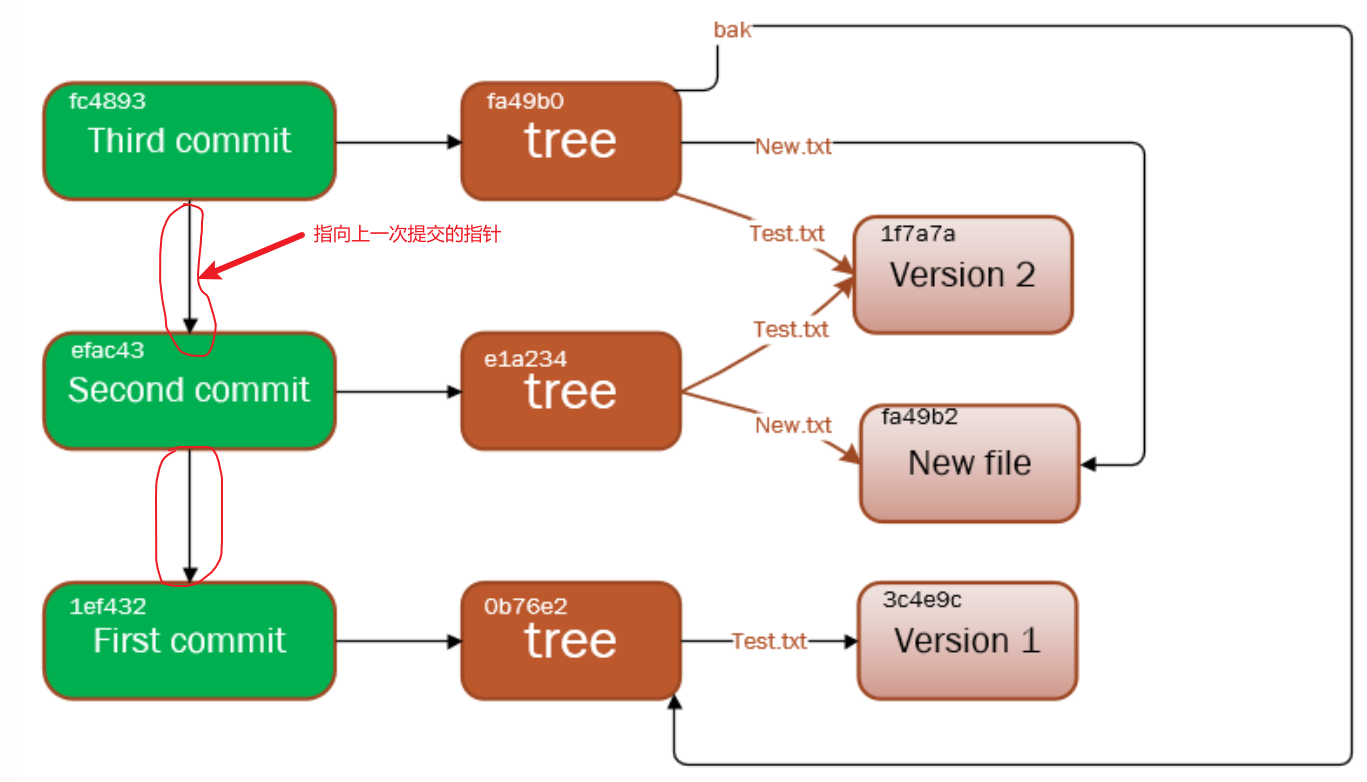
上图的Test.txt是第一次提交之前生成的,第一次它的初始 SHA-1 校验和以3c4e9c开头。随后对它进行了修改,所以第二次提交时生成了一个全新blob对象,校验和以1f7a7a开头。而第三次提交时Test.txt并没有变化,所以只是保存最近版本的 SHA-1 校验和而不生成全新的blob对象。在项目开发过程中新增加的文件在提交后都会生成一个全新的blob对象来保存它。注意,除了第一次每个提交对象都有一个指向上一次提交对象的指针。
因此简单来说,
- blob对象保存文件的内容;
- tree对象类似文件夹,保存blob对象和其它tree对象;
- commit对象保存tree对象,提交信息,作者,邮箱以及上一次的提交对象的ID(第一次提交没有)。
而Git就是通过组织和管理这些对象的状态以及复杂的关系实现的版本控制以及其他功能如分支。
Git引用
现在再来看引用,就会很简单了。如果我们想要看某个提交记录之前的完整历史,就必须记住这个提交ID,但提交ID是一个40位的 SHA-1 校验和,难记。所以引用就是SHA-1 校验和的别名,存储在.git/refs文件夹中。
最常见的引用也许就是master了,因为这是Git默认创建的(可以修改,但一般不修改),它始终指向你项目主分支的最后一次提交记录。如果在项目根目录运行cat .git/refs/heads/master,会输出一个SHA-1 校验和,例如:

因此,master只是一个40位SHA-1 校验和的别名罢了。
还有一个问题,Git如何知道你当前分支的最后一次的提交ID?在.git文件夹下有一个HEAD文件,像这样:

HEAD文件其实并不包含 SHA-1 值,而是一个指向当前分支的引用,内容会随着切换分支而变化,内容格式像这样:ref: refs/heads/<branch-name>。当你执行 git commit 命令时,它就创建了一个 commit 对象,把这个 commit 对象的父级设置为 HEAD 指向的引用的 SHA-1 值。
再来说说 Git 的 tag,标签。标签从某种意义上像是一个引用, 它指向一个commit对象而不是一个 tree,包含一个标签,一组数据,一个消息和一个commit对象的指针。但是区别就是引用随着项目进行它的值在不断向前推进变化,但是标签不会变化——永远指向同一个 commit,仅仅是提供一个更加友好的名字。
Git分支原理
分支是Git的杀手级特征,而且Git鼓励在工作流程中频繁使用分支与合并,哪怕一天之内进行许多次都没有关系。因为Git分支非常轻量级,不像其他的版本控制,创建分支意味着要把项目完整的拷贝一份,而Git创建分支是在瞬间完成的,而与你工程的复杂程度无关。
因为在上文中已经说到,Git保存文件的最基本的对象是blob对象,Git本质上只是一棵巨大的文件树,树的每一个节点就是blob对象,而分支只是树的一个分叉。说白了,分支就是一个有名字的引用,它包含一个提交对象的的40位校验和,所以创建分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,所以自然就快了,而且与项目的复杂程度无关。
Git的默认分支是master,存储在.git\refs\heads\master文件中,假设你在master分支运行git branch dev创建了一个名字为dev的分支,那么git所做的实际操作是:
- 在.git\refs\heads文件夹下新建一个文件名为dev(没有扩展名)的文本文件。
- 将HEAD指向的当前分支(当前为master)的40位SHA-1 校验和外加一个换行符写入dev文件。
- 结束。

创建分支就是这么简单,那么切换分支呢?更简单:
- 修改.git文件下的HEAD文件为ref: refs/heads/<分支名称>。
- 按照分支指向的提交记录将工作区的文件恢复至一模一样。
- 结束。
记住,HEAD文件指向当前分支的最后一次提交,同时,它也是以当前分支再次创建一个分支时,将要写入的内容。
分支合并
Fast-forward
再来说一说合并,首先是Fast-forward,换句话说,如果顺着一个分支走下去可以到达另一个分支的话,那么 Git 在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。比如:
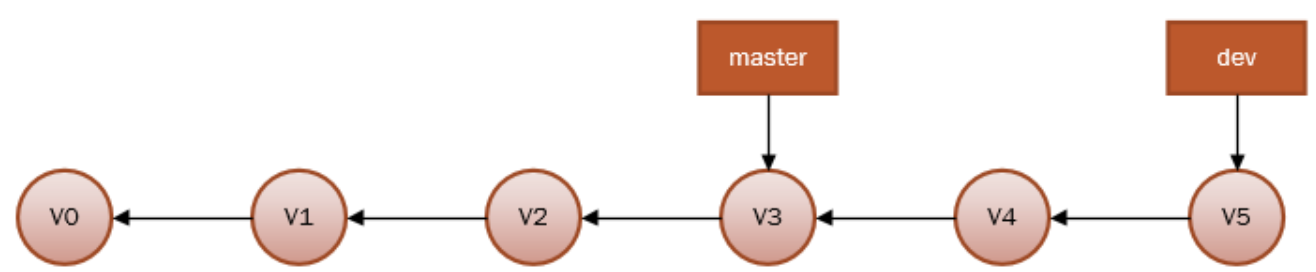
注意箭头方向,因为每一次提交都有一个指向上一次提交的指针,所以箭头方向向左,更为合理.
当在master分支合并dev分支时,因为他们在一条线上,这种单线的历史分支不存在任何需要解决的分歧,所以只需要master分支指向dev分支即可,所以非常快。
merge
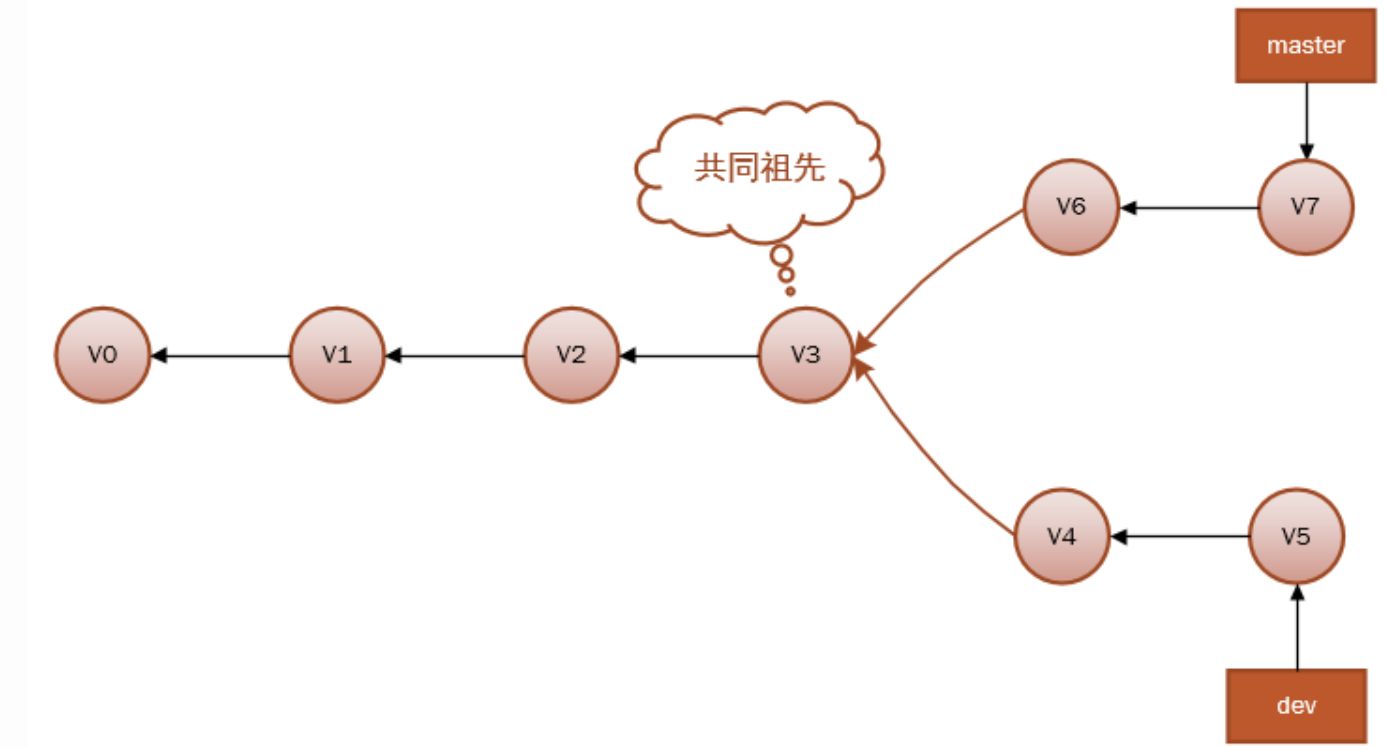
当分支出现分叉时,就有可能出现冲突,而这时Git就会要求你去解决冲突,比如像下面的历史:
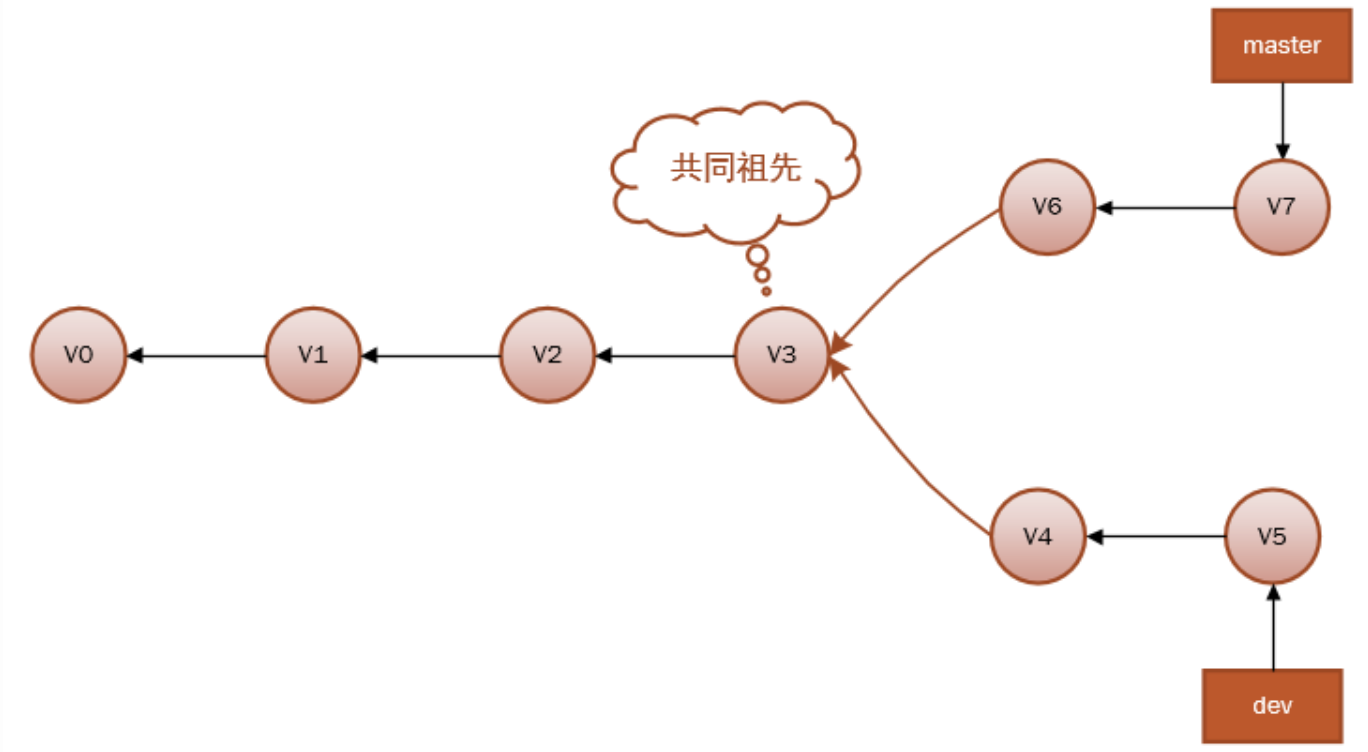
因为master分支和dev分支不在一条线上,即v7不是v5的直接祖先,Git 不得不进行一些额外处理。就此例而言,Git 会用两个分支的末端(v7 和 v5)以及它们的共同祖先(v3)进行一次简单的三方合并计算。合并之后会生成一个和并提交v8:
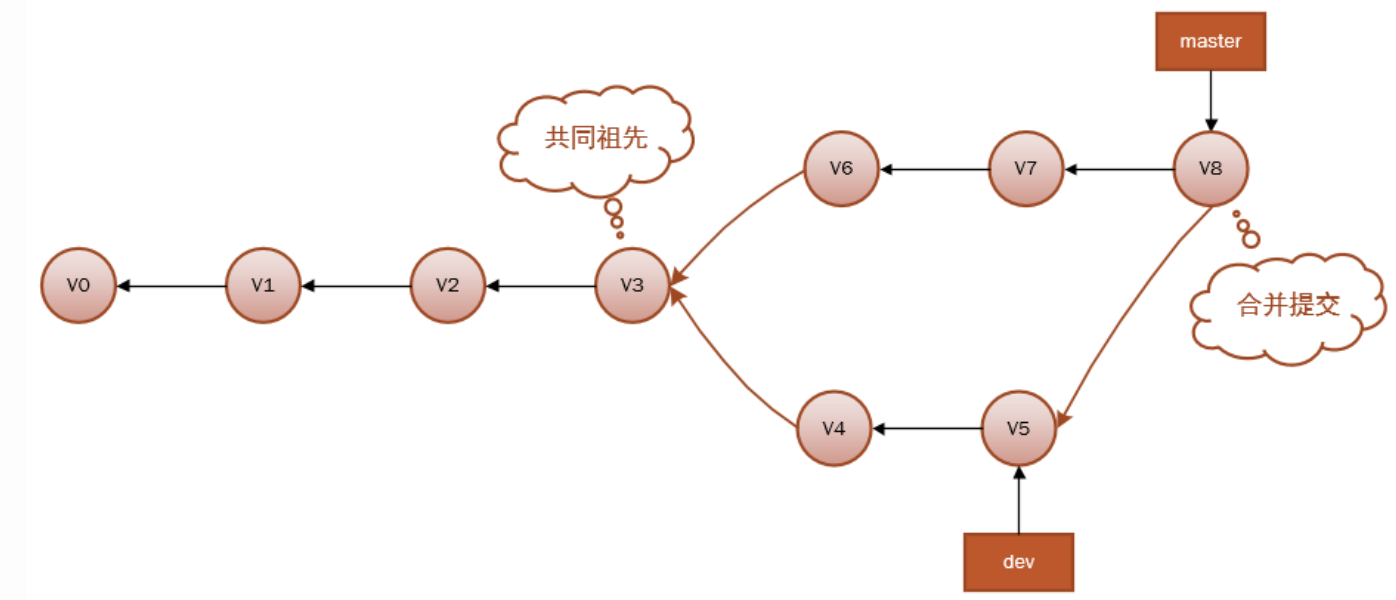
注意:和并提交有两个祖先(v7和v5)。
变基rebase
把一个分支中的修改整合到另一个分支的办法有两种:merge 和 rebase。首先merge 和 rebase最终的结果是一样的,但 rebase能产生一个更为整洁的提交历史。仍然以上图为例,如果简单的merge,会生成一个提交对象v8,现在我们尝试使用变基合并分支,切换到dev:
$ git checkout dev
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged command
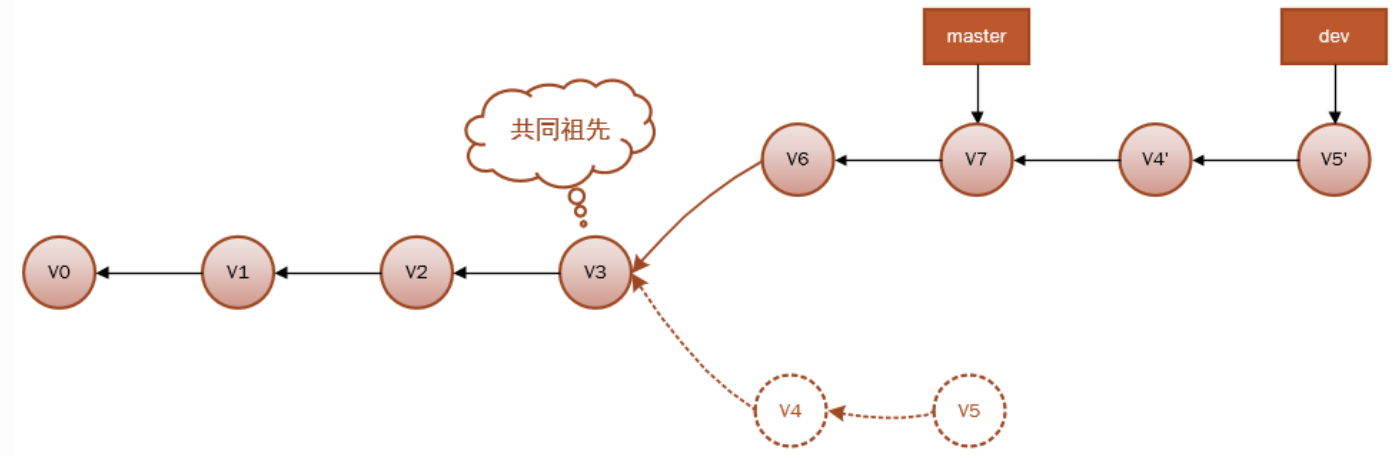
这段代码的意思是:回到两个分支最近的共同祖先v3,根据当前分支(也就是要进行变基的分支 dev)后续的历次提交对象(包括v4,v5),生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象(v7)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成两个新的合并提交对象(v4',v5'),从而改写 dev 的提交历史,使它成为 master 分支的直接下游,如下图:
现在,就可以回到master分支进行快速合并Fast-forward了,因为master分支和dev分支在一条线上:
$ git checkout master
$ git merge dev
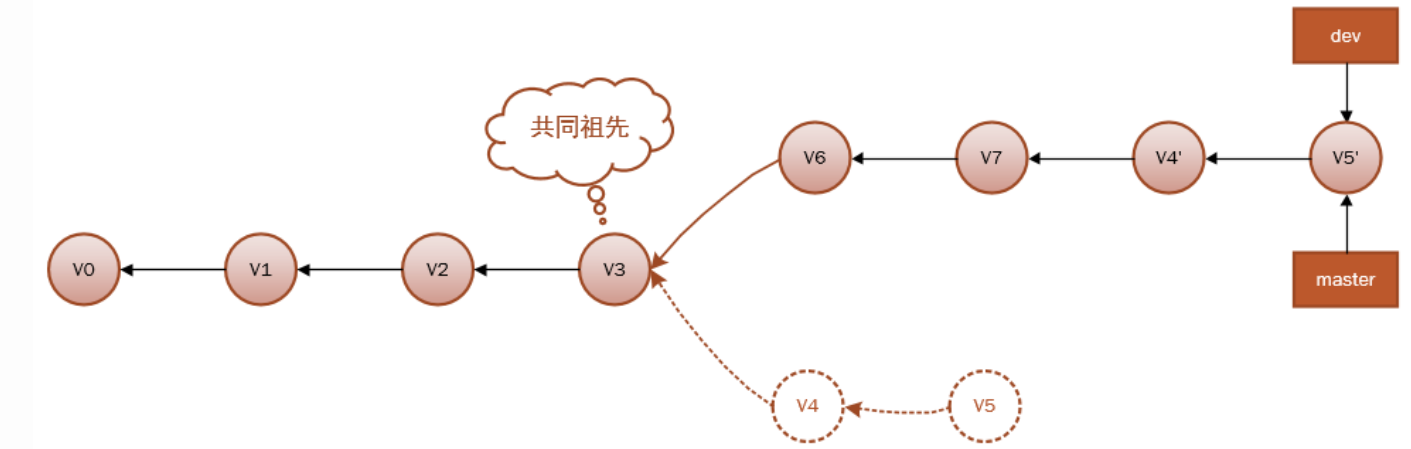
现在的 v5' 对应的快照,其实和普通的三方合并,即上个例子中的 v8 对应的快照内容一模一样。虽然最后整合得到的结果没有任何区别,但变基能产生一个更为整洁的提交历史。如果视察一个变基过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。
总结
- Git保存文件的完整内容,不保存差量变化。
- Git以储键值对(key-value)的方式保存文件。
- 每一个文件,相同文件的不同版本,都有一个唯一的40位的 SHA-1 校验和与之对应。
- SHA-1 校验和是文件的指针,Git依靠它来区分文件。
- 每一个文件都会在Git的版本库里生成blob对象来保存。
- 对于没有变化的文件,Git只会保留上一个版本的指针。
- Git实际上是通过维持复杂的文件树来实现版本控制的。
- 使用Git的工作流程基本上就是就是文件在三个工作区域之间的流动。
- 应该大量使用分支进行团队协作。
- 分支只是对提交对象的一个引用。
Git 安装
参看官方文档,基本上都是下一步下一步,安装成功后,右键点击桌面任意位置,在右键菜单里选择 Git Bash Here 即可打开 Git Bash 命令行终端。
在 Git Bash 终端里输入 git --version 查看 git 版本,如图所示,说明 Git 安装成功。
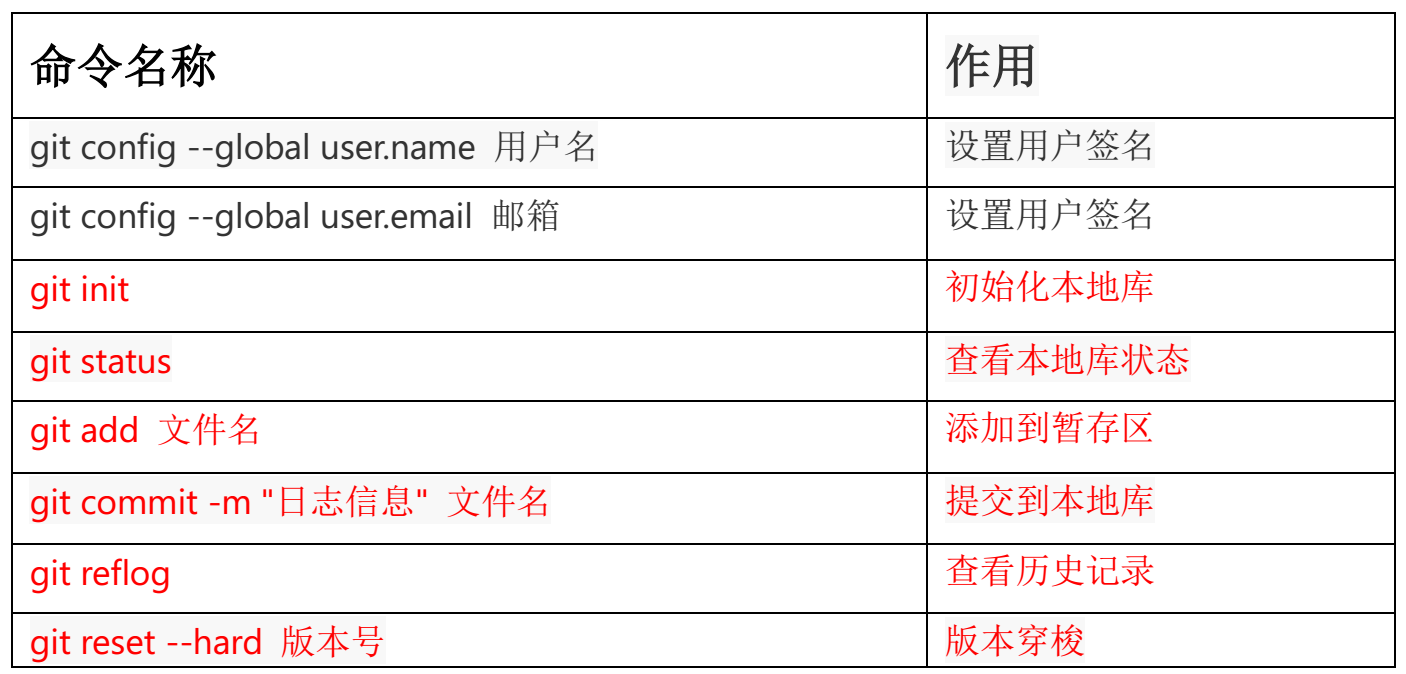
Git 常用命令
设置用户签名(git config --global user.name 用户名,git config --global user.email 邮箱)
全局范围的签名设置基本语法:
git config --global user.name 用户名
git config --global user.email 邮箱
注意:这个邮箱可以是一个虚拟的邮箱,现实中这个邮箱可以不存在,对于这一点,git不会进行验证
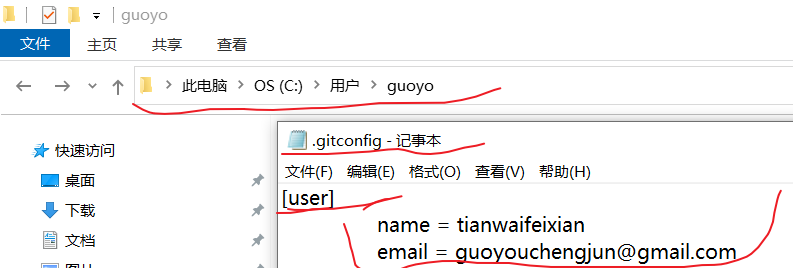
这里我们在git bash命令行中分别输入git config --global user.name tianwaifeixian和git config --global user.email guoyouchengjun@gmail.com
我们可以在用户目录下的.gitconfig文件中看到这个设置:
注意:
- 签名的作用是区分不同操作者身份。用户的签名信息在每一个版本的提交信息中能够看到,以此确认本次提交是谁做的。
- Git 首次安装必须设置一下用户签名,否则无法提交代码。
- 这里设置用户签名和将来登录 GitHub(或其他代码托管中心)的账号没有任何关系
初始化本地库(git init)
基本语法:
git init
我们新建一个文件夹git_demo,作为本地仓库,然后在这个目录下右键点击打开git bash,然后输入:
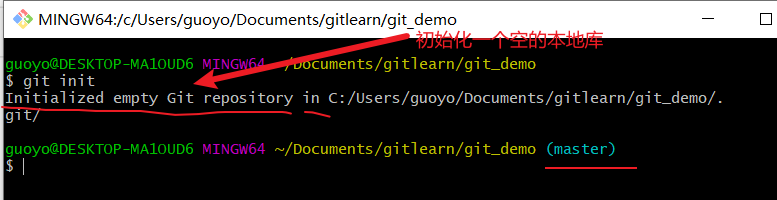
我们可以看到git_demo这个本地库下生成了一个.git文件夹:

查看本地库状态(git status)
基本语法:
git status
首次查看(工作区没有任何文件)
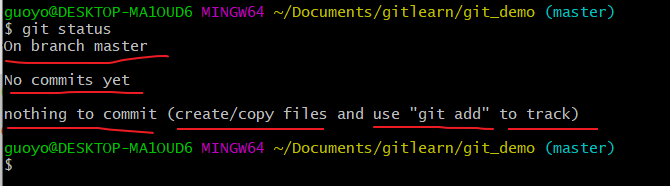
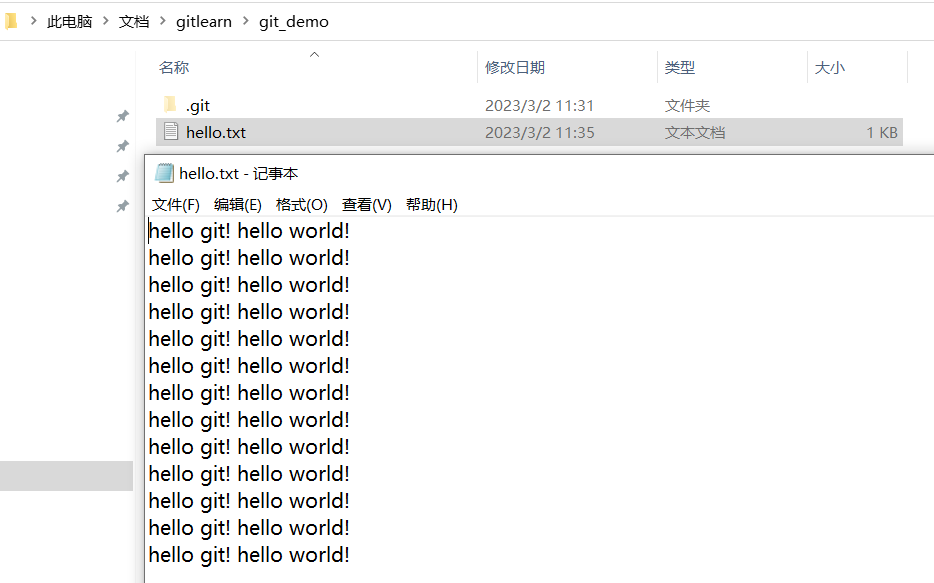
新增文件(hello.txt)
我们在git_demo下新建一个txt文件hello.txt,并写入以下内容:
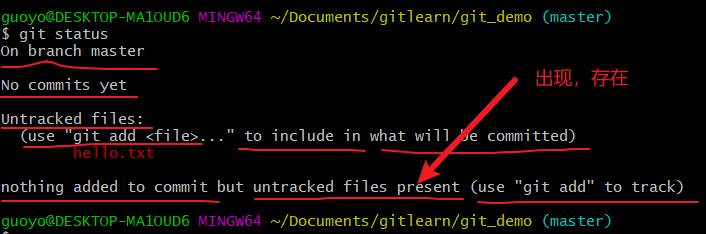
再次查看(检测到未追踪的文件)
添加暂存区(git add 文件名)
将工作区的文件添加到暂存区
基本语法:
git add 文件名

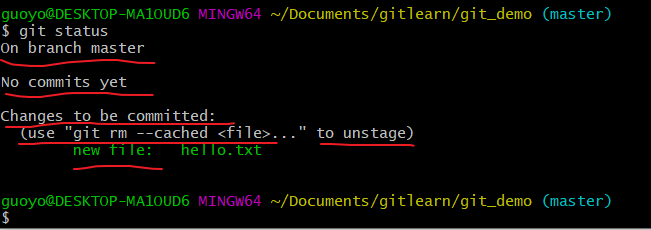
查看状态(检测到暂存区有新文件)
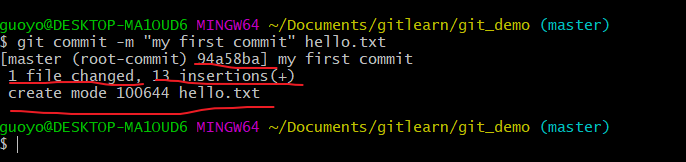
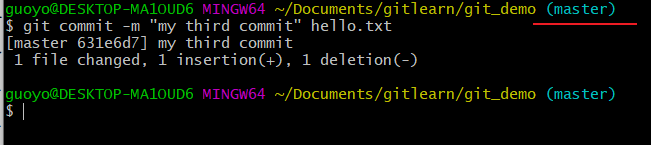
提交本地库(git commit -m "日志信息" 文件名)
将暂存区的文件提交到本地库
将暂存区的文件提交到本地库,形成自己的本地历史版本。
基本语法:
git commit -m "日志信息" 文件名
查看状态(没有文件需要提交)
修改文件(hello.txt)
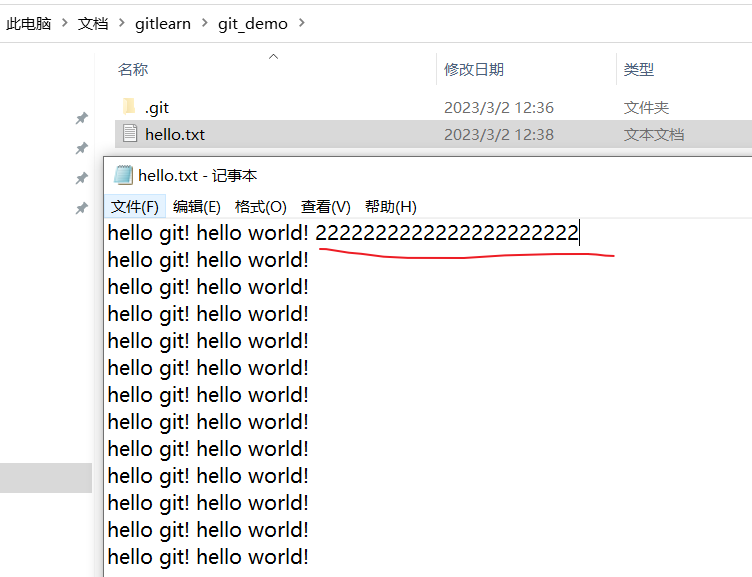
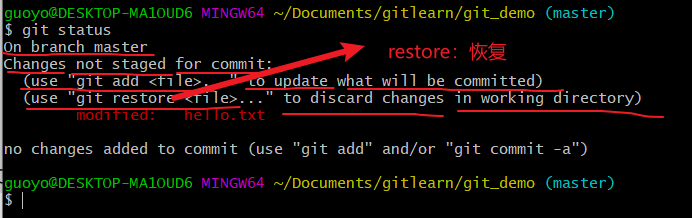
查看状态(检测到工作区有文件被修改)
将修改的文件再次添加暂存区

查看状态(工作区的修改添加到了暂存区)
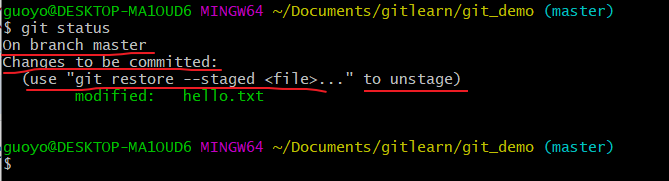
我们看到,to unstage,我们有两种方式:
git restore --staged <file>,git restore命令不加附加参数--stagedgit restore <file>为to discard changes in working directory,git rm --cached <file>,
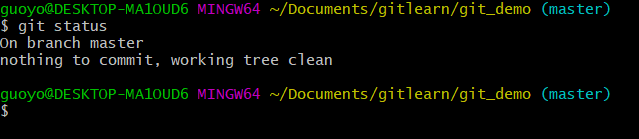
再次将暂存区的文件提交到本地库

再次查看状态(没有文件需要提交)
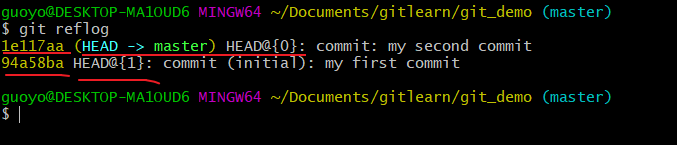
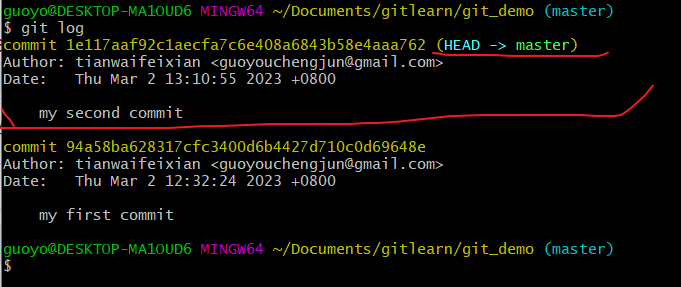
历史版本
查看历史版本(git reflog查看版本信息,git log查看版本详细信息)
基本语法:
git reflog 查看版本信息
git log 查看版本详细信息
版本穿梭(git reset --hard 版本号)
基本语法:
git reset --hard 版本号
- 首先查看当前的历史记录, 可以看到当前是在1e117aa这个版本,

- 切换到94a58ba版本,也就是我们第一次提交的版本,

- 切换完毕之后再查看历史记录,当前成功切换到了94a58ba版本,
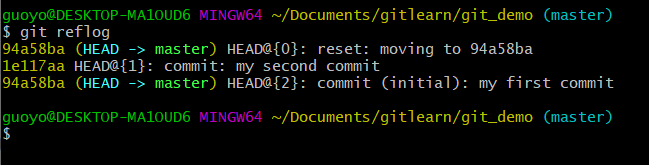
- 然后查看本地硬盘上的文件 hello.txt,发现文件内容已经自动发生了变化,
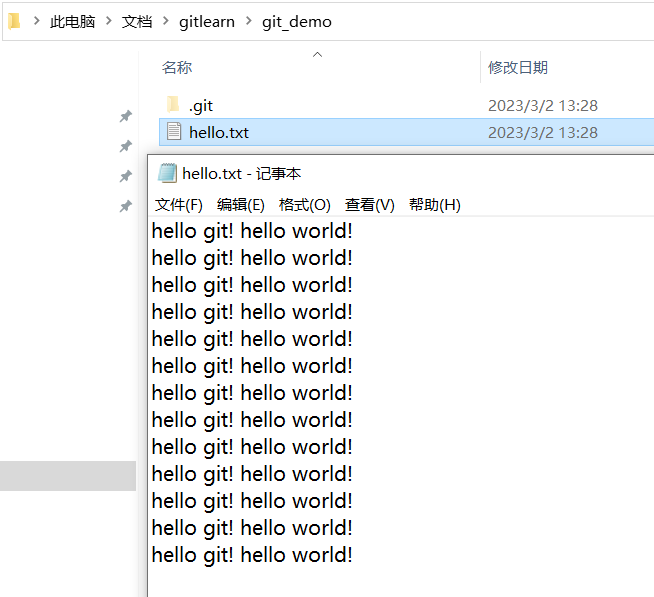
注意,在工作区中永远只会显示一个文件,git控制版本不是通过副本,它底层是通过指针来控制的,随着我们在git bash命令行的某些操作,在硬盘上存储的文件内容可能会自动发生变化。
Git 切换版本, 底层其实是移动的 HEAD 指针,具体原理如下图所示。

Git 分支操作
git的主打特性就是分支,
什么是分支?
在版本控制过程中,
- 同时推进多个任务,为每个任务,我们就可以创建每个任务的单独分支。
- 使用分支意味着程序员可以把自己的工作从开发主线上分离开来, 开发自己分支的时候,不会影响主线分支的运行。
- 对于初学者而言,分支可以简单理解为副本,一个分支就是一个单独的副本。(分支底层其实也是指针的引用)
分支的好处
- 同时并行推进多个功能开发,提高开发效率。
- 各个分支在开发过程中,如果某一个分支开发失败,不会对其他分支有任何影响。失败的分支删除重新开始即可。
分支的操作
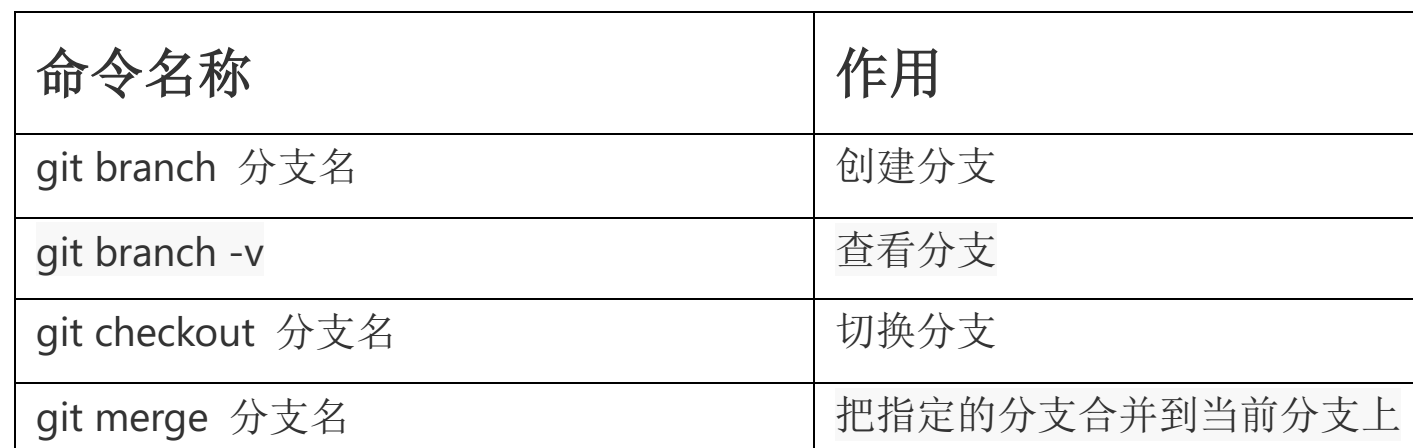
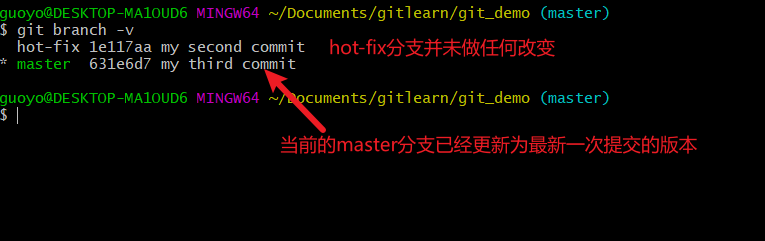
查看分支(git branch -v)
基本语法:
git branch -v
为了方便以后操作的演示,我们先在我们当前所在的master分支上切换到第二次提交的版本,git reset --hard 1e117aa,
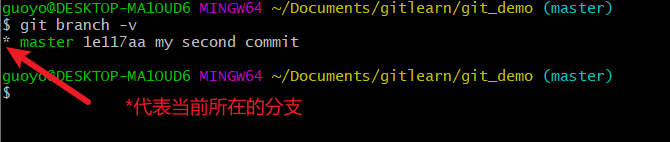
然后查看当前分支,
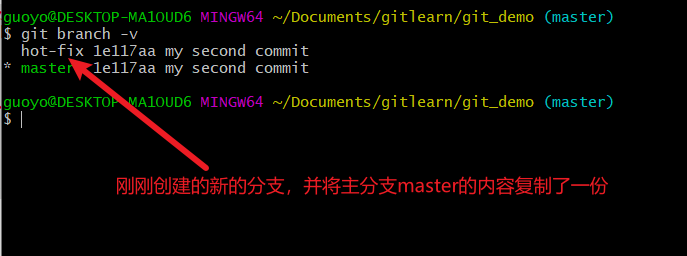
创建分支(git branch 分支名)
基本语法:
git branch 分支名
修改分支
- 在当前的master分支上做修改,
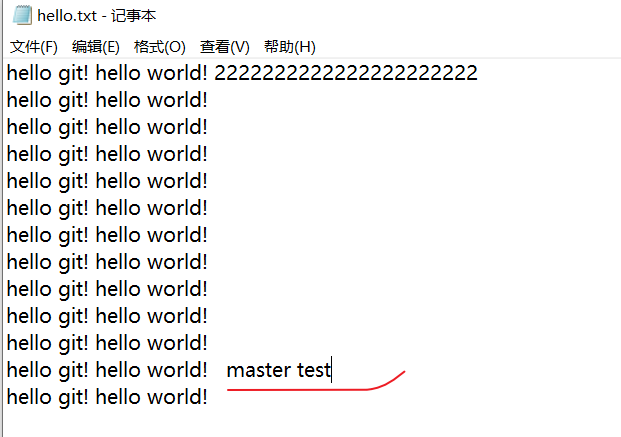
- 添加暂存区,

- 提交本地库,
- 查看分支,
切换分支(git checkout 分支名)
基本语法:
git checkout 分支名
- 在切换之前,我们先看一下 master 分支上的文件内容,
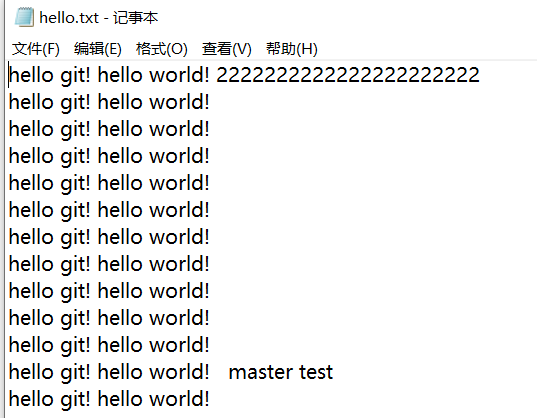
- 然后我们切换到hot-fix分支,
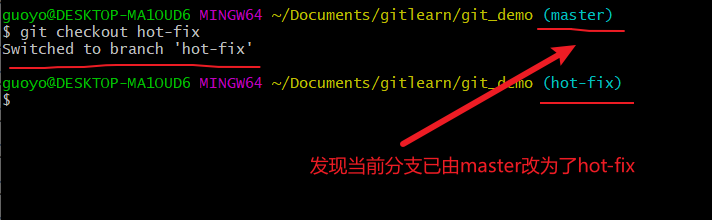
- 查看 hot-fix 分支上的文件内容发现与 master 分支上的内容不同,

git工作区只有一个文件,没有副本,当切换分支时,工作区的文件会自动变成切换到的分支的最新版本。 - 在 hot-fix 分支上做修改,
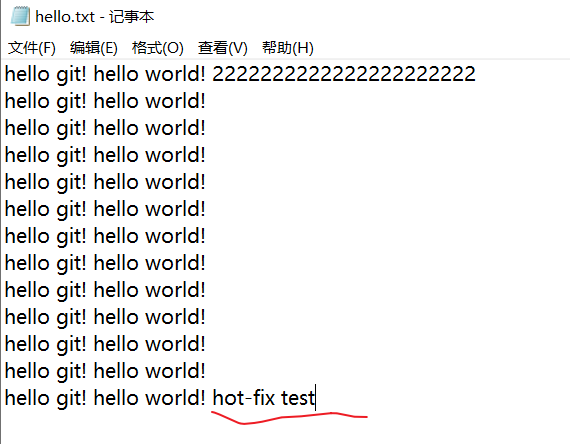
- 添加暂存区,

- 提交本地库,
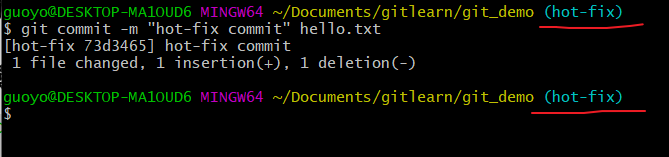
合并分支(合并指定分支到当前分支上,git merge 分支名)
在企业里,比较常见的是代码冲突问题,以及冲突合并问题
基本语法:
git merge 分支名
我们先切换到master分支,然后在master 分支上合并 hot-fix 分支,
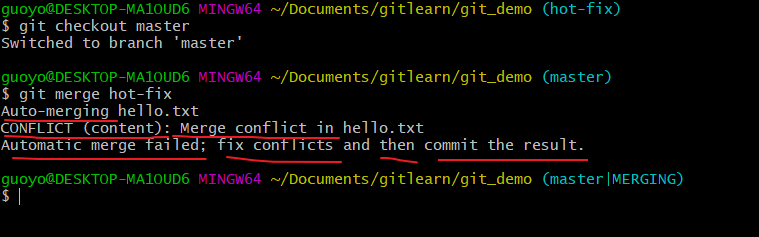
产生冲突
冲突产生的表现:
- 后面状态为 MERGING,

- 另外,我们硬盘上保存的文件会自动变为:
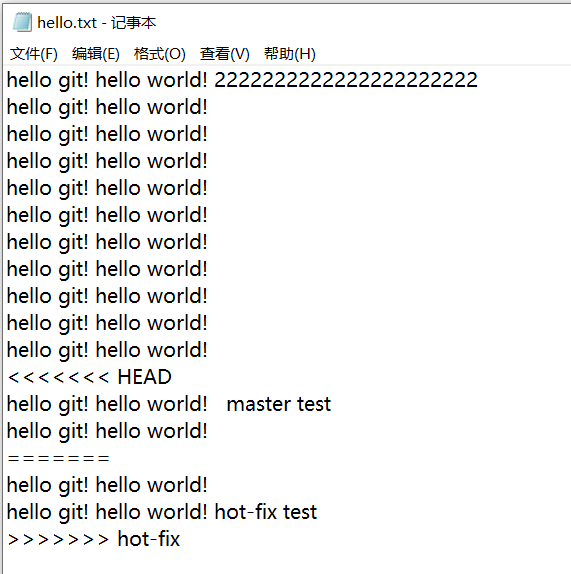
冲突产生的原因:
合并分支时,两个分支在同一个文件的同一个位置有两套完全不同的修改。 Git无法替我们决定使用哪一个。必须人为决定新代码内容。
查看状态(检测到有文件有两处修改),
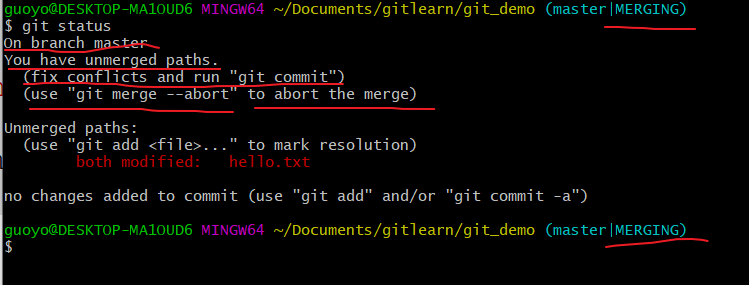
解决冲突
- 编辑有冲突的文件,删除特殊符号,决定要使用的内容,
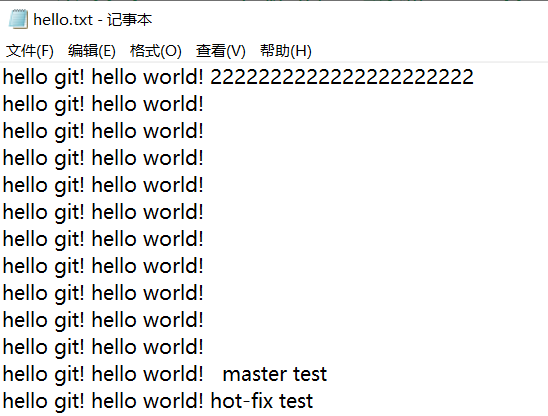
- 添加到暂存区,

- 执行提交(注意: 此时使用 git commit 命令时不能带文件名),
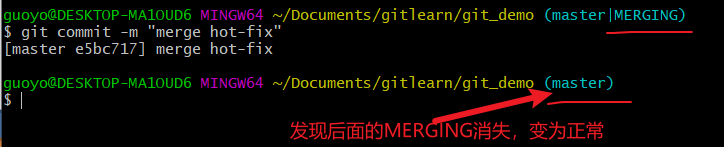
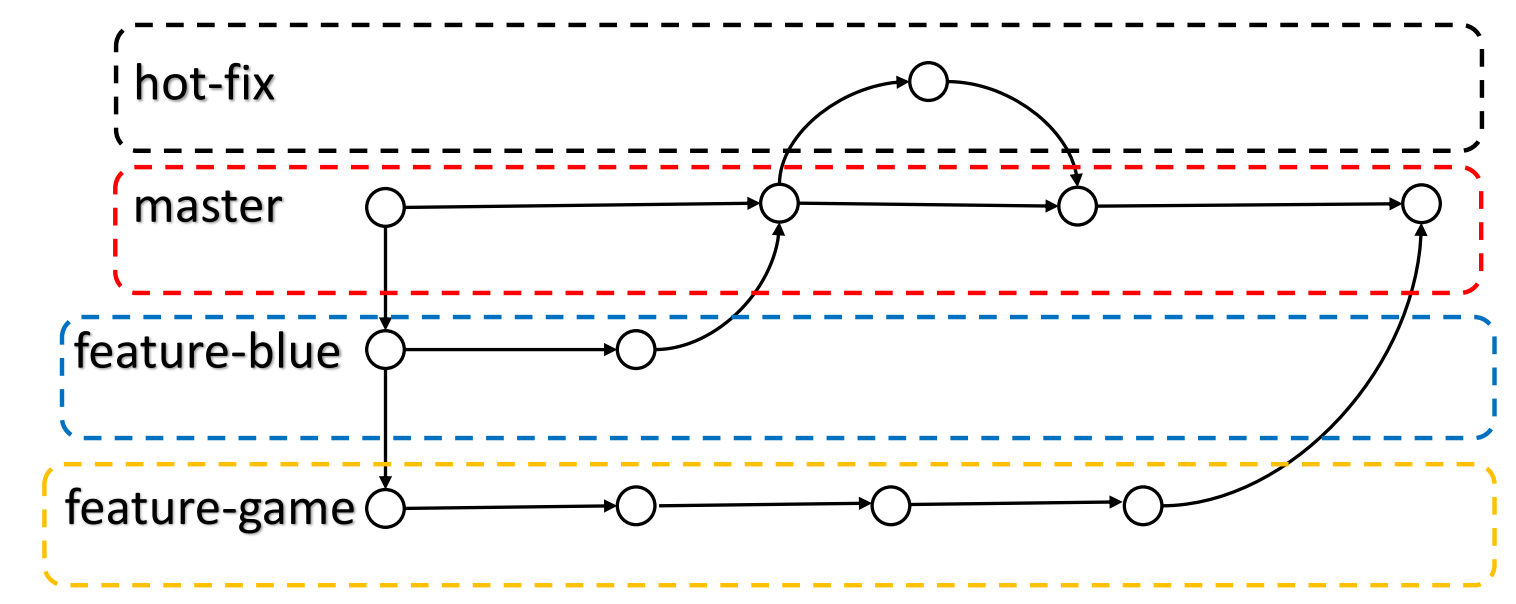
创建分支和切换分支图解
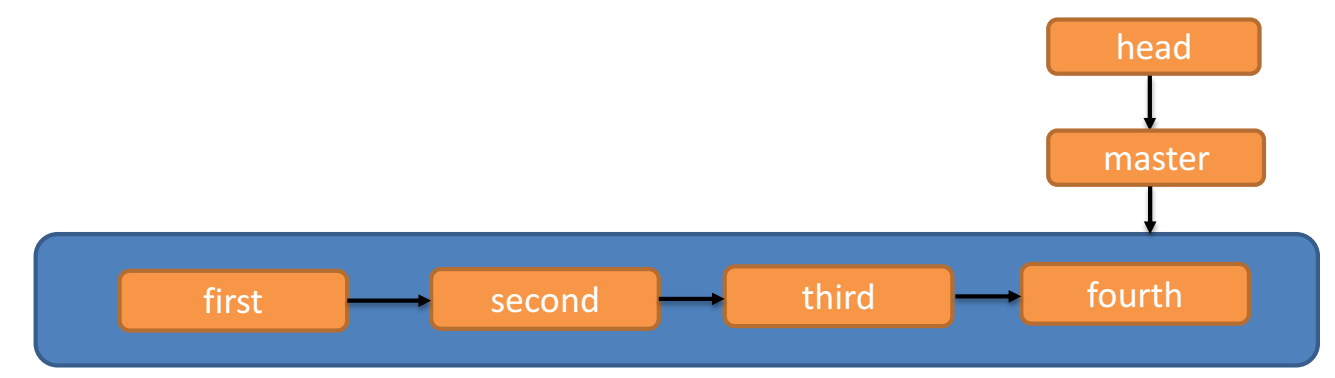
master、 hot-fix 其实都是指向具体版本记录的指针。当前所在的分支,其实是由HEAD决定的。所以创建分支的本质就是多创建一个指针。
- HEAD 如果指向 master,那么我们现在就在 master 分支上。
- HEAD 如果执向 hot-fix,那么我们现在就在 hot-fix 分支上。
所以切换分支的本质就是移动 HEAD 指针。
GitHub 操作
创建远程仓库
登录GitHub账号:jiuzhuanjinshenhuiyanggong,然后
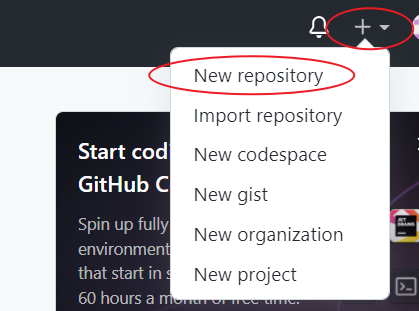
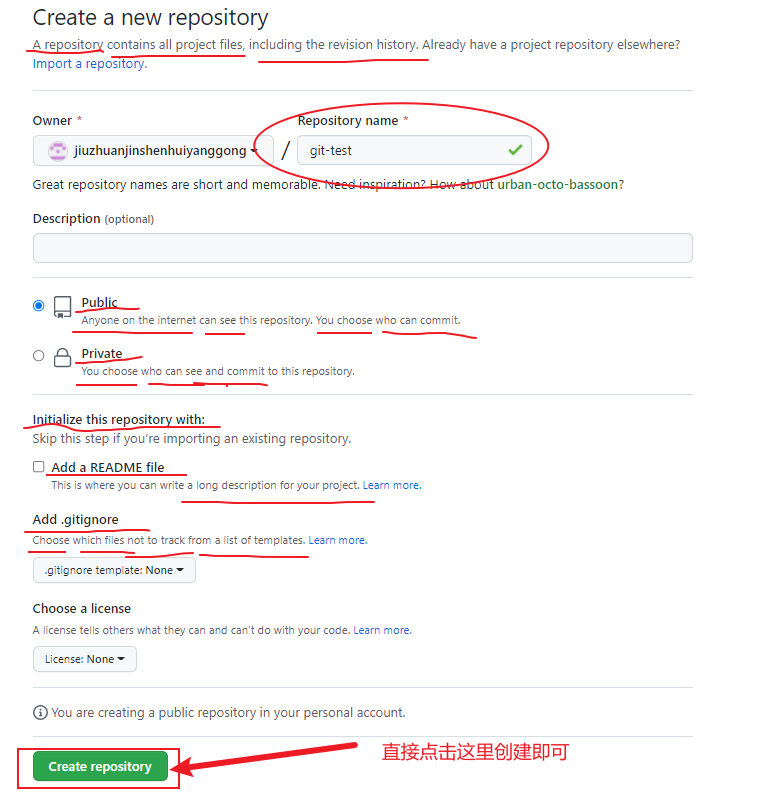
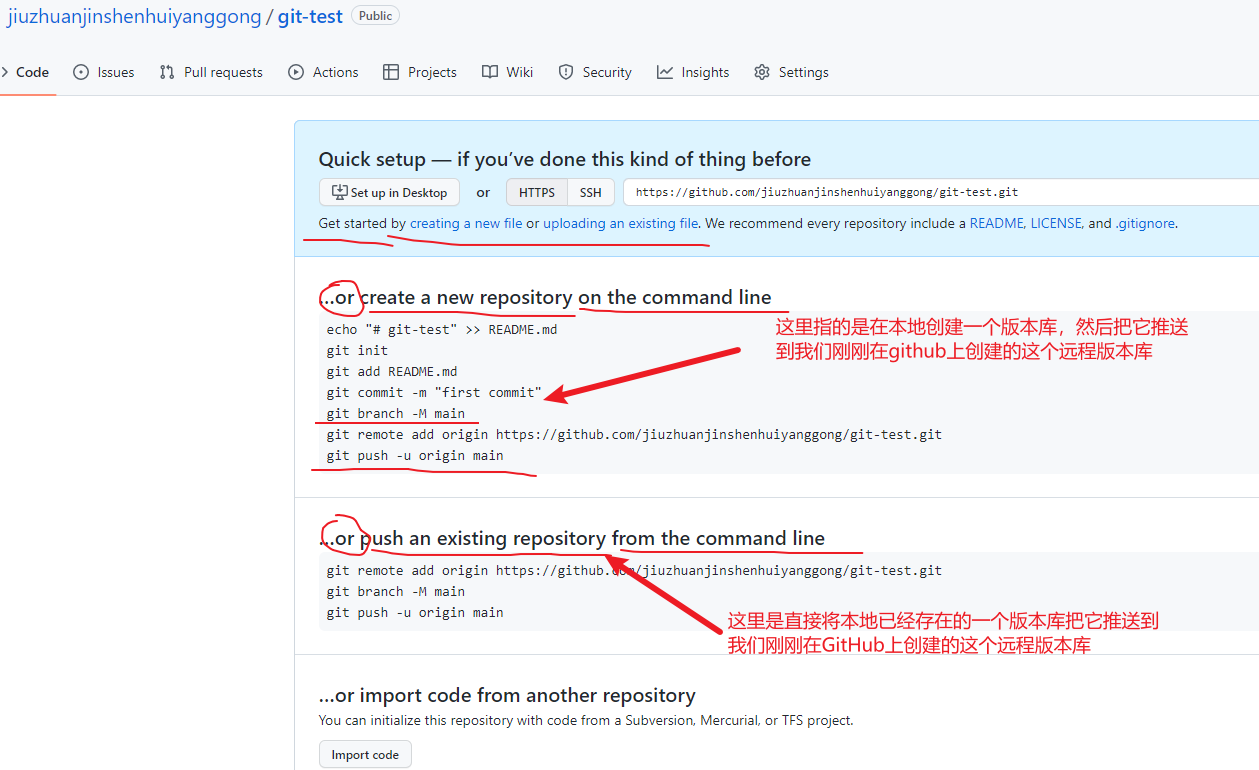
远程仓库操作
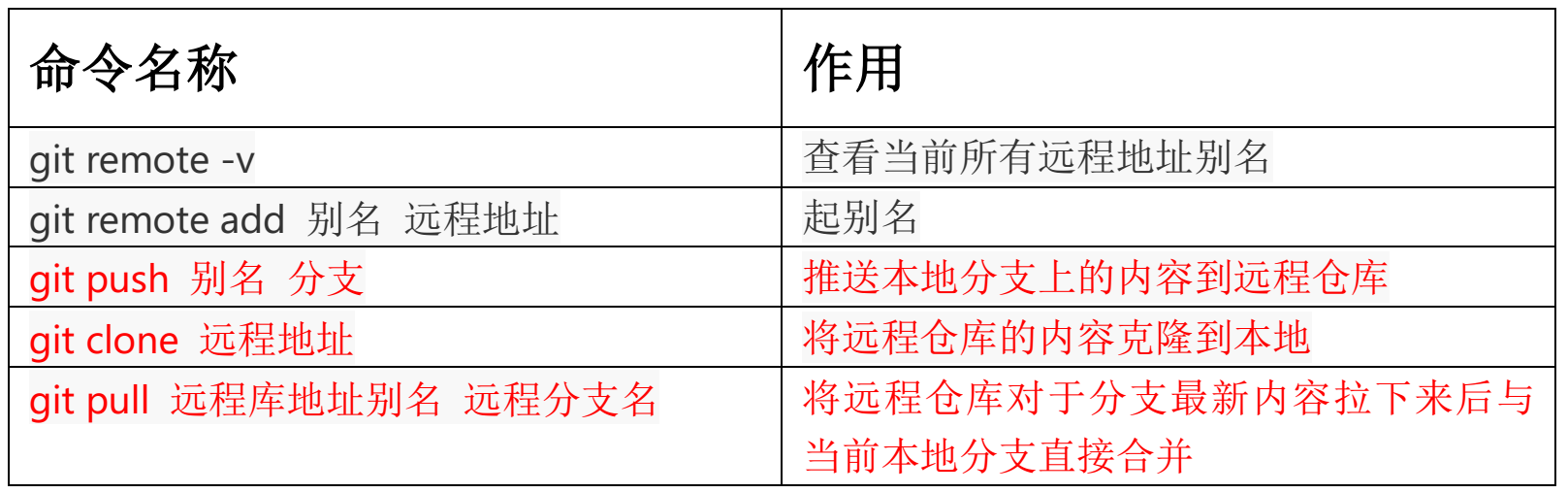
查看当前所有远程地址别名(git remote -v)
基本语法:
git remote -v

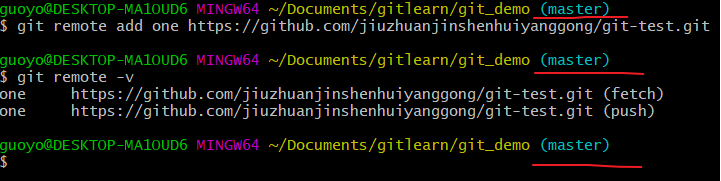
创建远程仓库别名(git remote add 别名 远程地址)
基本语法:
python
git remote add 别名 远程地址
这个地址是在创建完远程仓库后生成的连接, 如图所示
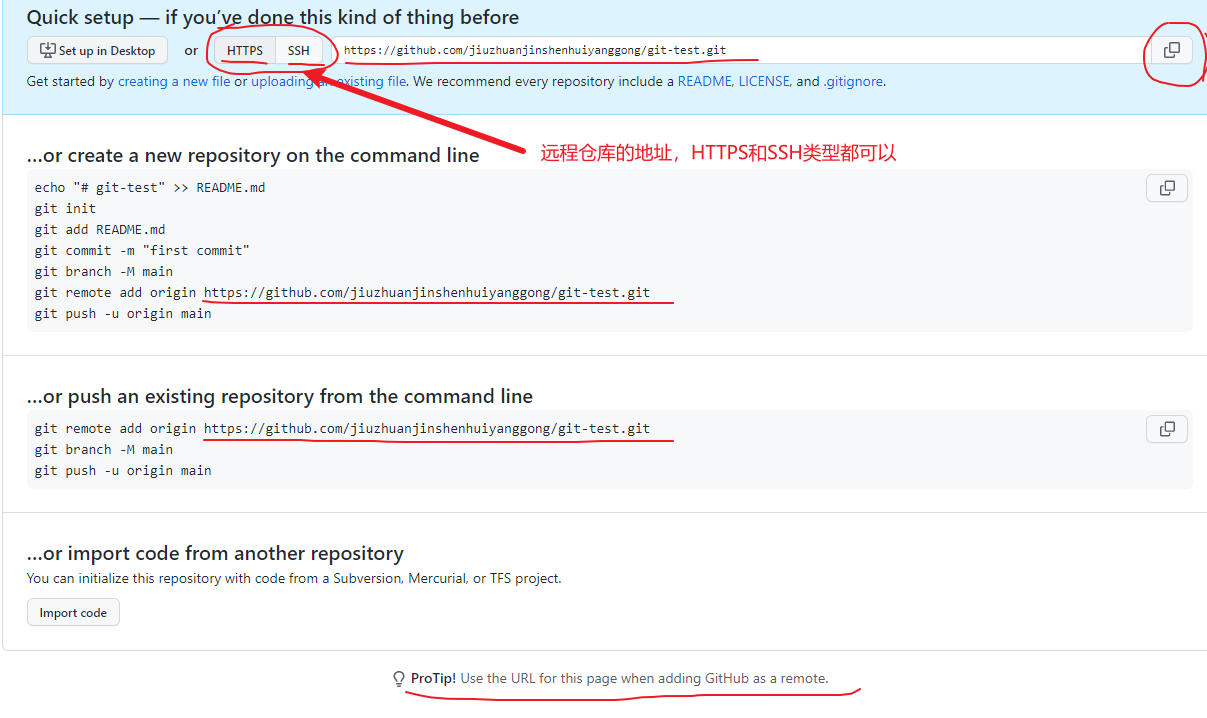
推送本地当前分支到远程仓库(git push 别名 远程分支)
基本语法:
git push 别名 分支

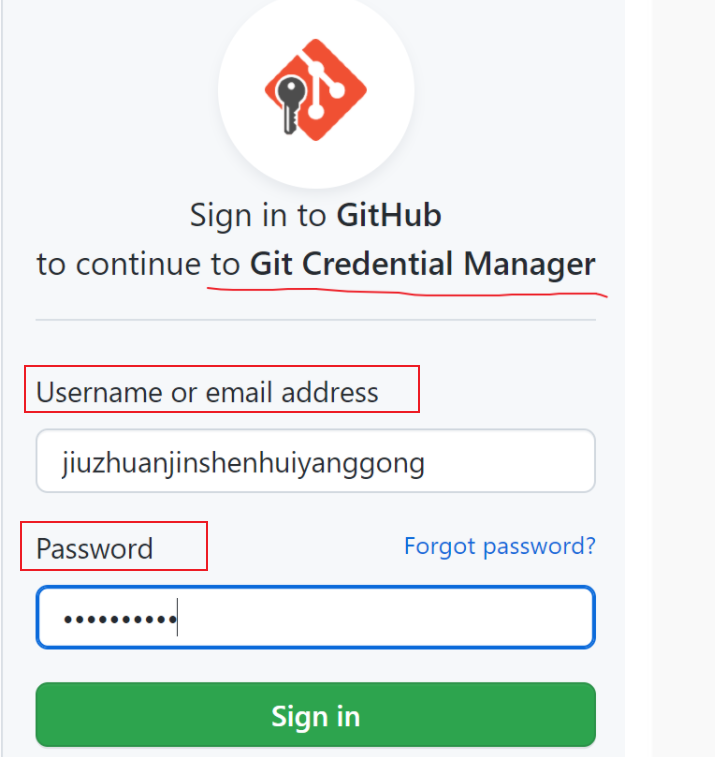
报错了(可能是以前登录推送过我的其它的GitHub账号),我们可以查看一下Windows的凭据管理器,

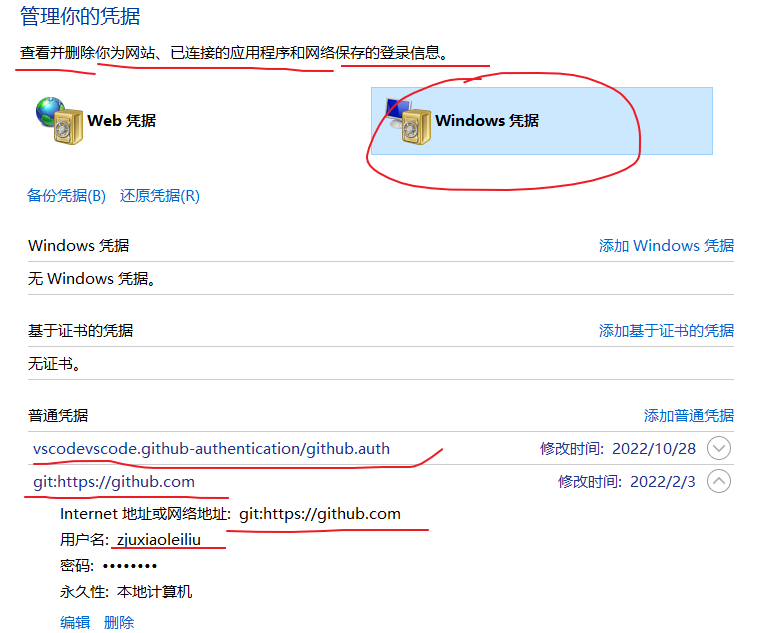
这能是这个原因,我们删除GitHub的凭据,再试一下,好了,这次弹出连接GitHub如下对话框:
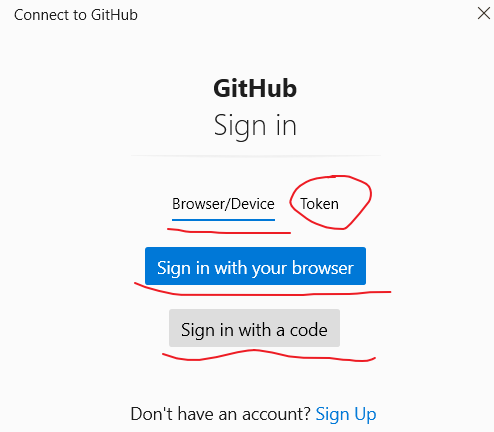
可以看到在这个对话框中,我们有三种方式连接到GitHub:
-
sign in with your brower(浏览器),在浏览器中输入GitHub账号,密码,
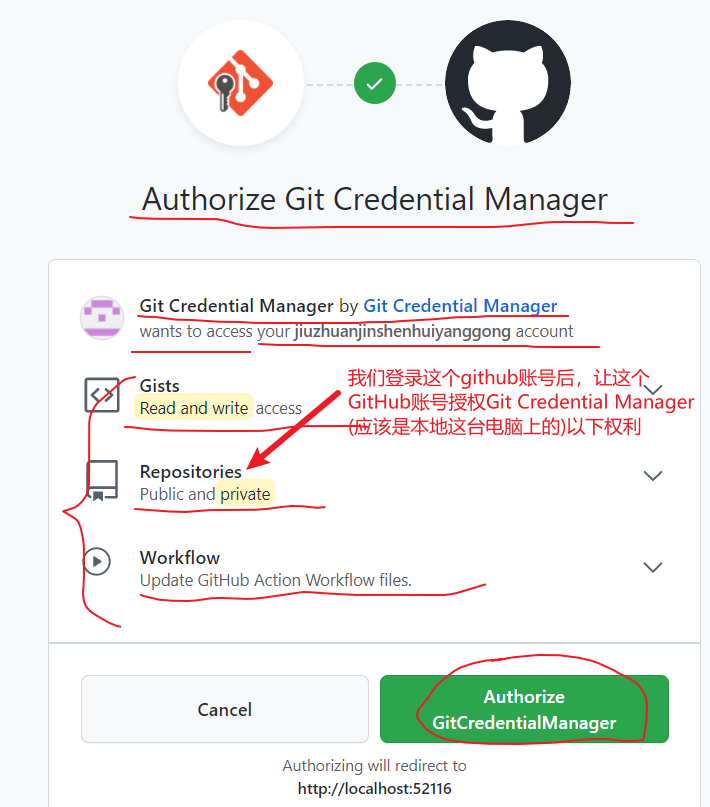
这次我们推送成功了,
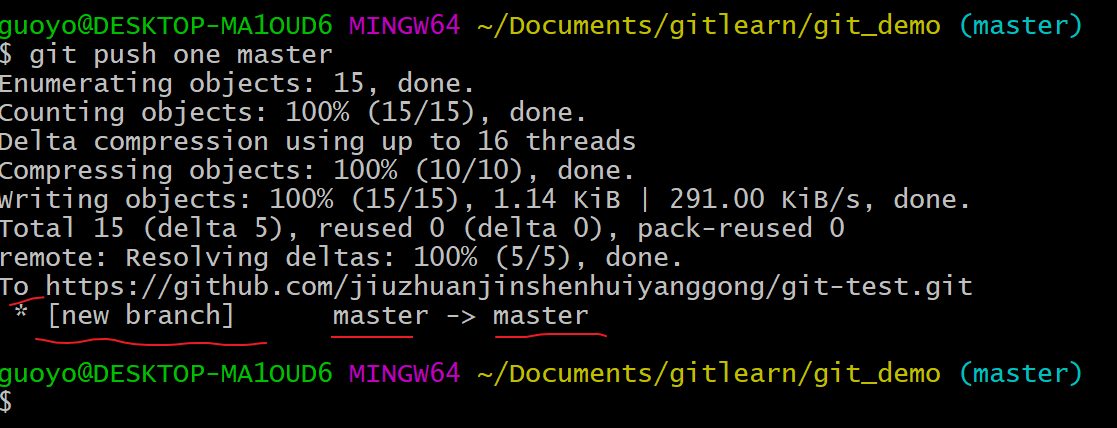
我们在我们的GitHub远程仓库中此时发现已将我们本地仓库的master 分支上的内容推送到 GitHub 创建的远程仓库的master上,
我们再一次查看Windows的凭据管理器,可以发现自动添加了这个GitHub账号的凭据,
我们在本地的仓库修改文件,
并再次推送,这次看看会发生什么,
这次什么也不需要做,直接推送成功,说明Windows评估管理器里面保存的GitHub网站的账号,密码,这些似乎是通过Git Credential Manager保存的,因此当下一次我们通过git访问GitHub时,Git Credential Manager会直接把这里保存的账号,密码填进下面的对话框中,也就是Windows保存这个账号凭据主要是为了方面我们下次免输入,否则的话我们推送一次就要输入一次账号,密码,太麻烦,
Windows的凭据管理器网上查到的似乎只能保存一个GitHub的账号密码凭据,而不管保存的账号的是不是与我们要推送的GitHub远程仓库地址账号匹配,当然,如果不匹配,是肯定不能推送的,因此才发生了我们上面的问题,如果是团队内协作,成员自己电脑上保存的自己的GitHub账号凭证(要使用GitHub的远程仓库服务,当然得注册一个账号,才能使用它的服务,类似于微信),应该是经过了创建远程仓库的人的账号的设置,得到了许可(相当于加入了微信群,使用自己的微信号就能在群里发消息),因此即使不匹配,也允许推送,这是我的猜测。 -
sign in with a code
-
token,
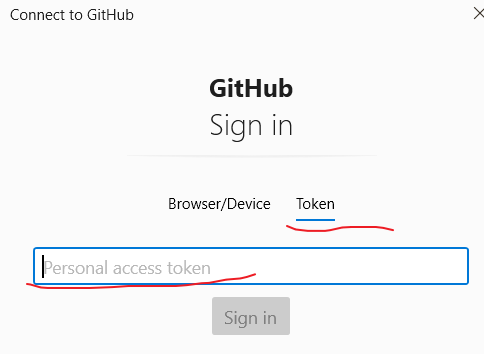
克隆远程仓库到本地(git clone 远程地址)
基本语法:
git clone 远程地址
由于我这里只有一台电脑,所以为了模仿另一个成员,我们还是在这个电脑上创建另一个目录,然后在这个目录下右键单击打开git bash命令行,然后执行以下命令将远程仓库克隆到这个目录下,
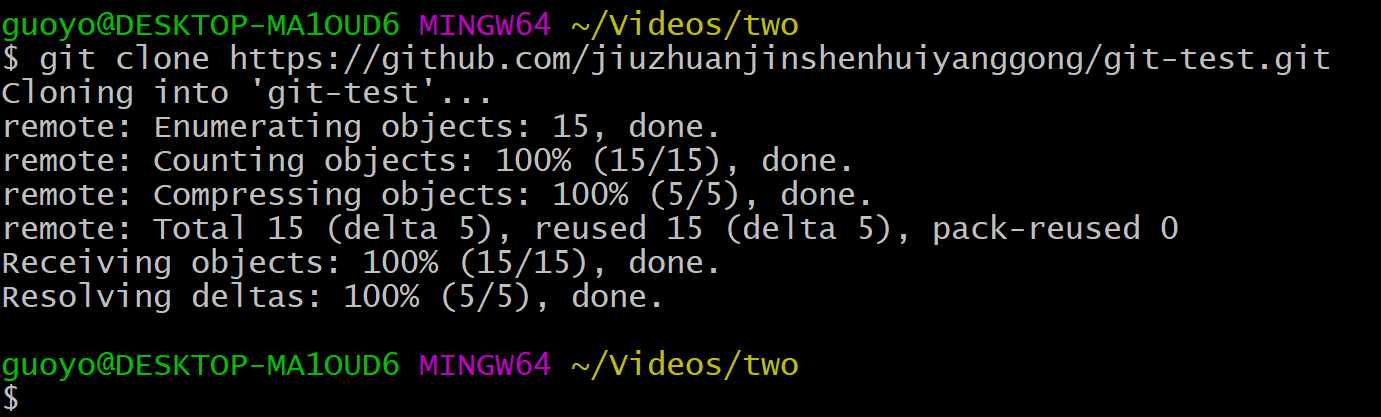
我们可以看到,本地这个目录下确实克隆成功了,

我们cd到这个克隆下来的仓库中,查看一下这个克隆下来的仓库的远程地址别名有哪些,
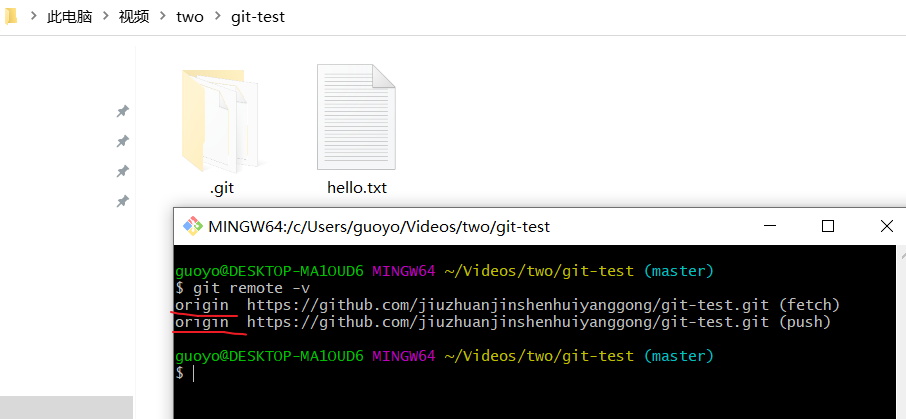
可以看到,原来绑定的远程地址也克隆下来了,只是别名默认为origin,
注意:
一个常识,克隆代码是不需要登录账号的,当初我们在GitHub上创建库的时候选择的是创建public公共库,是没有读权限限制的,任何人都可以浏览查看这个public仓库的代码,对于这一点我们可以删除刚刚产生的Windows的凭证管理器下的GitHub账号信息来验证这一点。
clone 会做如下操作,
- 1、拉取代码。
- 2、初始化本地仓库。
- 3、创建默认别名orign
团队内协作
我们现在将我们上面clone下面的本地仓库two里面的文件进行修改,
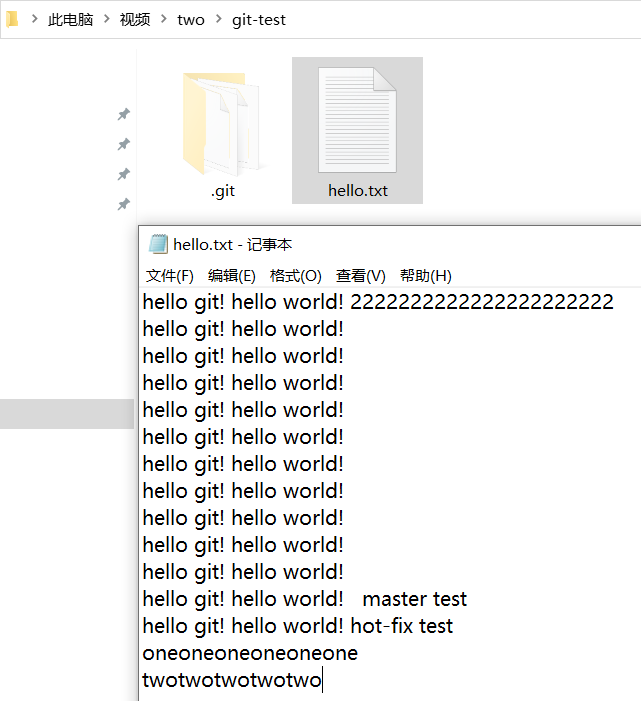
然后在本地仓库commit,
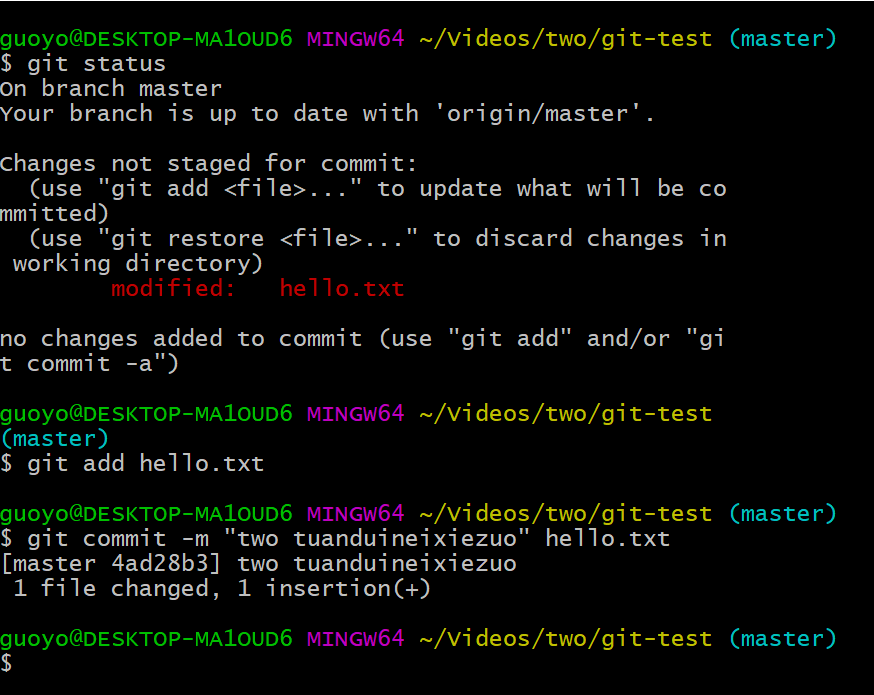
由于我们上面猜测的原因,two员工在本地仓库的修改是无法push到远程仓库的,在我们自己的电脑上,
- 我们Windows凭据管理器下如果没有保存过GitHub的账号密码,则我们push时,会弹出对话框,要求我们输入账号密码,我们只能输入自己的GitHub账号密码,肯定的,因为我们怎么可能知道别人的账号密码,看什么国际玩笑,我们填入自己的GitHub账号密码后,显然的,与我们要推送的远程仓库的账号是不匹配的,当然push不了
- 如果我们的Windows凭据管理器下保存有GitHub账号密码,那么这个账号密码肯定不会是远程仓库的那个账号密码(这还有疑问吗?),则不会弹出对话框要求我们填入账号密码,Windows凭据管理器已经自动帮我们干了,不用我们再手工填了,结果是很显然的,不匹配!(当然了,无论是手工填还是自动填都是不匹配的)
那么如果我们在一个团队中,应该如何协作呢?
很简答,像微信群主邀请人拉人进群一样的道理,远程仓库的创建者在自己的GitHub账号这个仓库的settings中要求员工加入这个项目,进行团队协作开发。
邀请加入团队
-
在远程仓库的创建者的这个项目的settings页面,发出邀请,
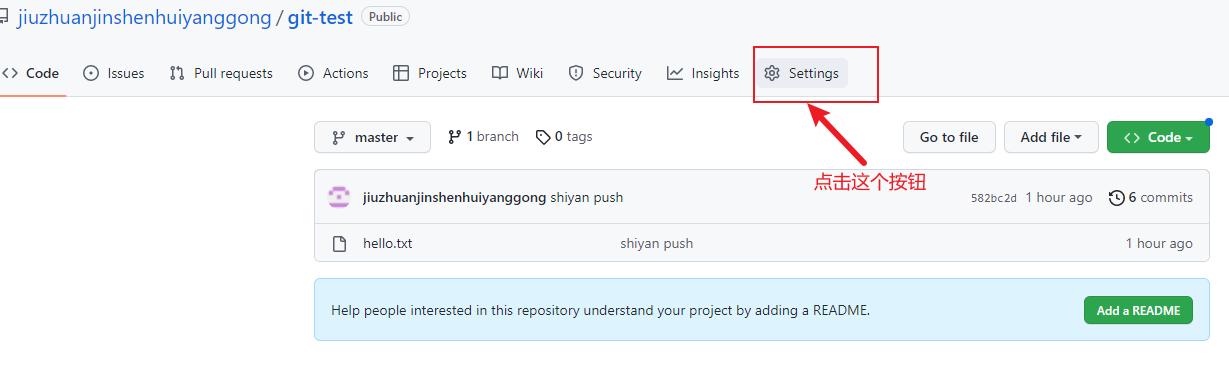
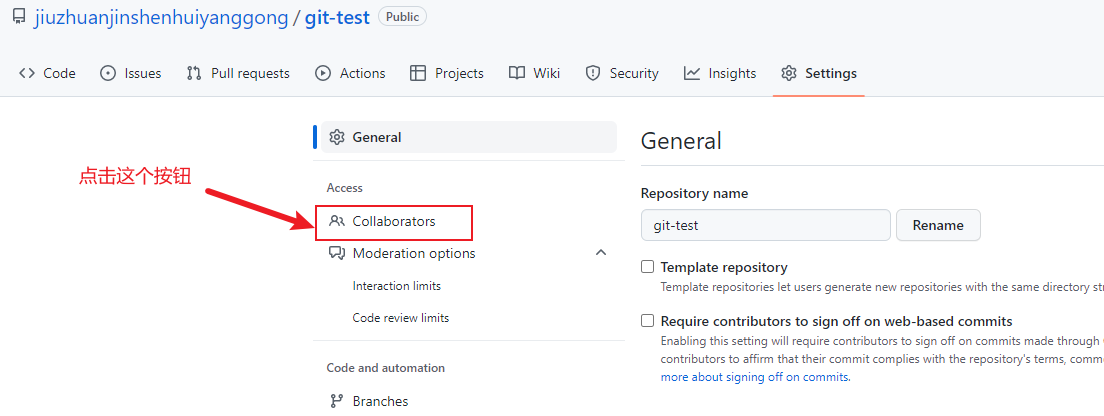
这个操作会要求我们再次的输入账号密码,
输入密码,然后在接下来的页面中发出邀请,
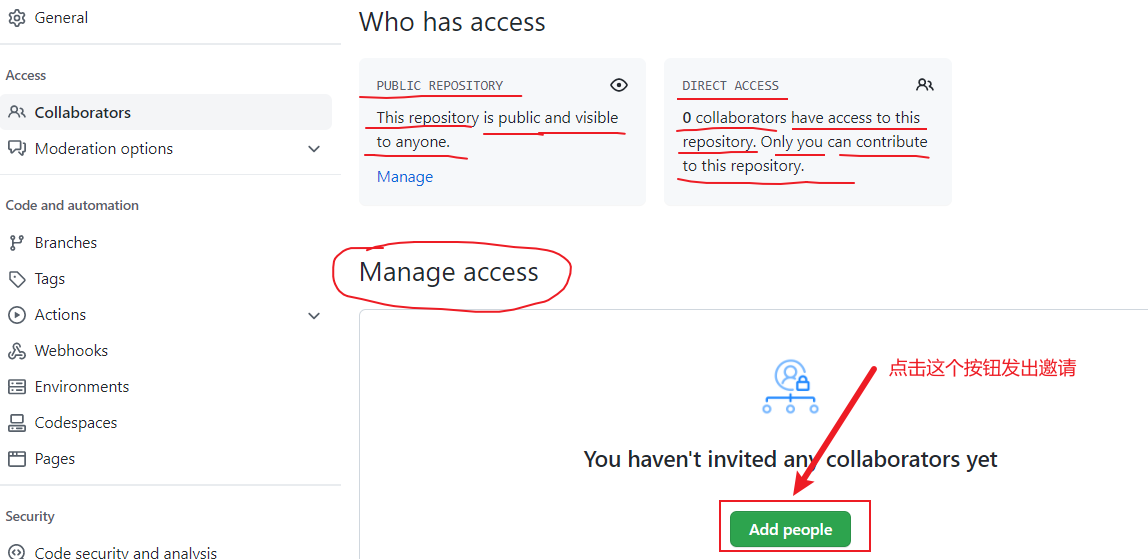
-
填入想要合作的人,
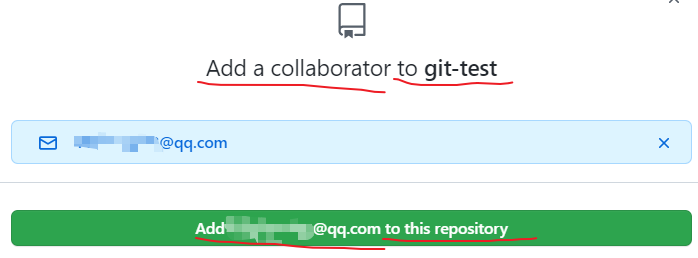
-
合作者的GitHub账号受到邀请信息后,点击接受邀请,
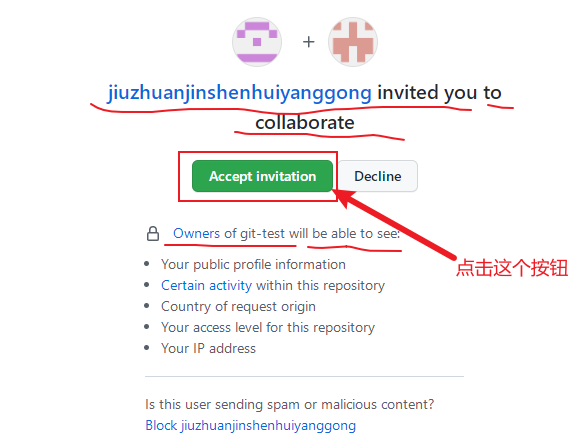
-
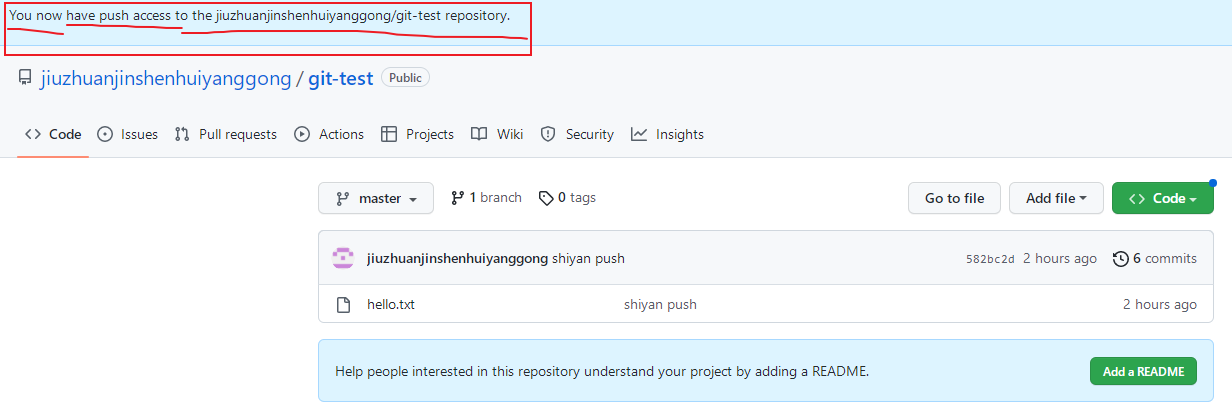
成功后,我们可以看到,
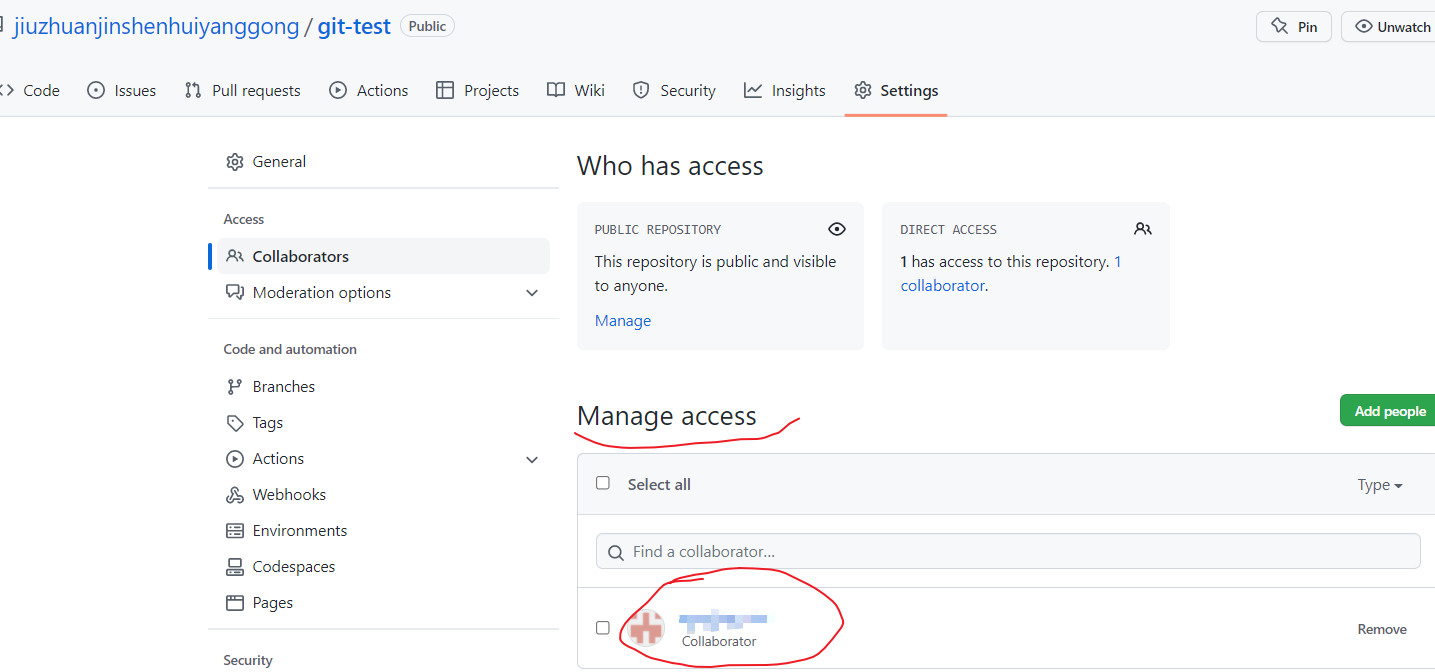
同时,我们可以在远程仓库的拥有者那里看到,现在员工也是这个项目的一员了,
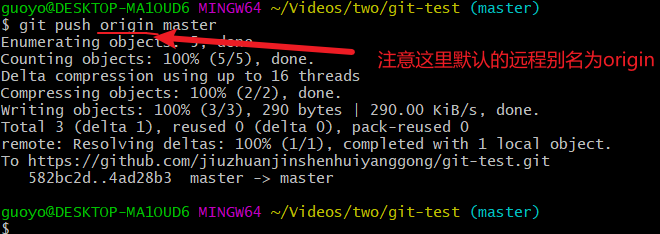
现在我们就可以push到远程仓库了,由于我这里只有一台电脑,要模拟两个人的团队内协作,首先现将上面保存的Windows凭据管理器里面的远程仓库的GitHub账号,密码删除,push时,在弹出的对话框中输入自己的GitHub账号密码,试了好几次,开的梯子push成功了,
我们在远程仓库的项目主界面,看到我们最近的一次提交,
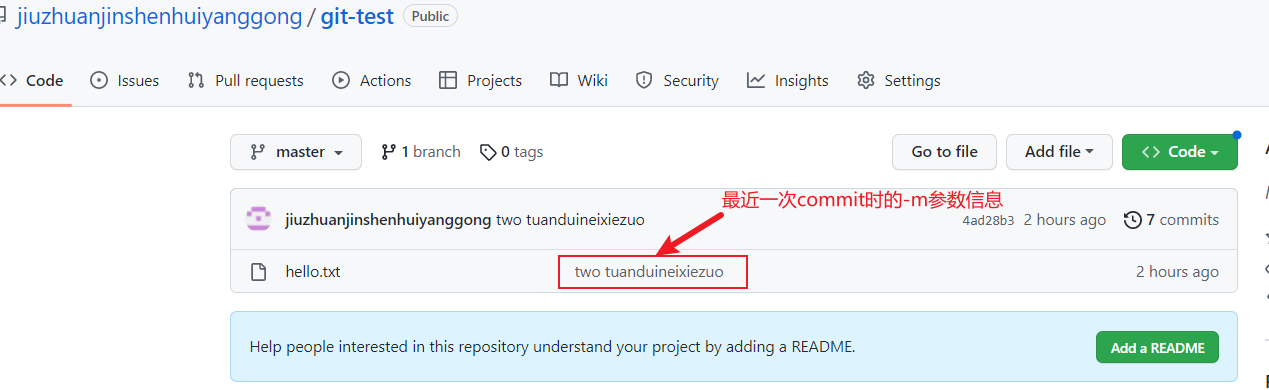
我们可以进一步验证一下文件内容,
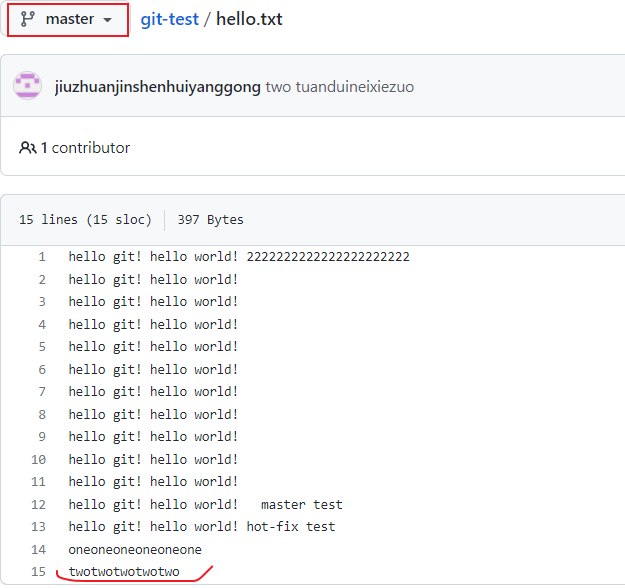
拉取远程库内容(git pull 远程库地址别名 远程分支名)
员工two的本地更新push后,现在远程仓库和本地的git-demo已经不是同步的了,我们这是需要pull命令。
基本语法:
git pull 远程库地址别名 远程分支名
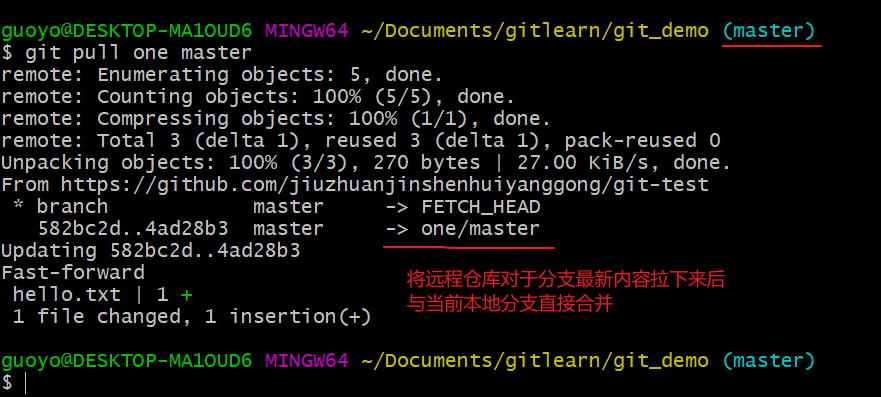
我们看一下本地git-demo仓库里面的文件内容,
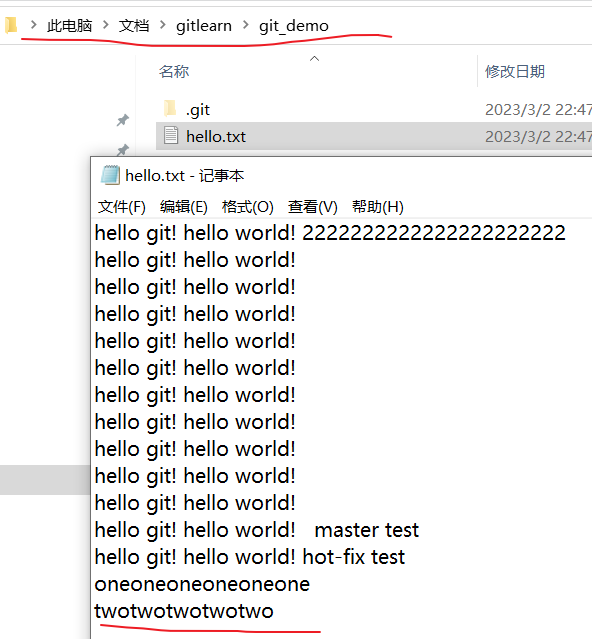
注意:
在上面的拉取操作之前,我删除了Windows凭据管理器下保存的GitHub账号,密码,上面的pull操作没有要求我们有额外的输入账号,密码等操作,说明,pull操作和clone操作一样,都是不需要登录账号的,pull和clone都是读权限,对于public库,这是对所有人可见的。
跨团队协作
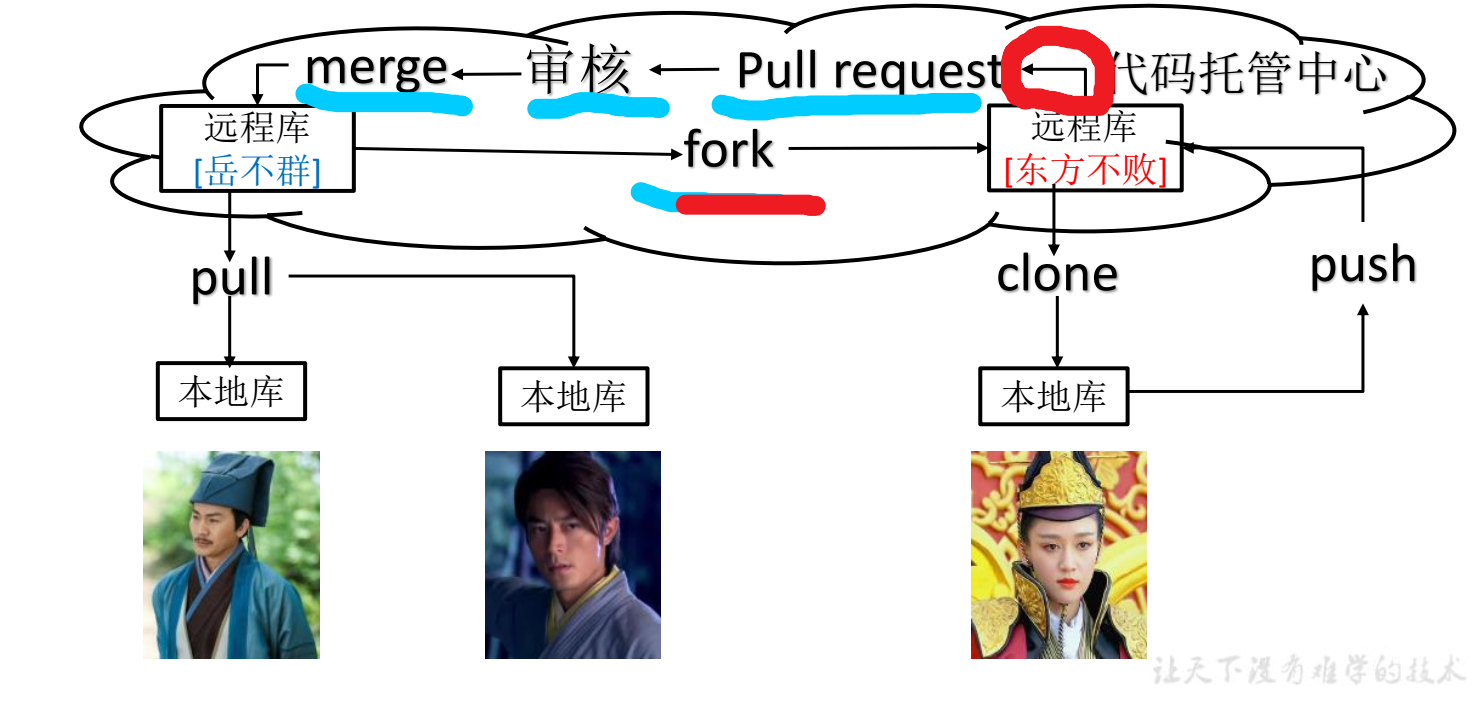
- 团队内协作,项目的创建者,通过在这个项目的远程仓库进行设置,对团队内的成员发出邀请(类似于微信群主邀请人拉人进群),团队内的成员接受邀请后,团队内的成员获得了这个项目仓库的access权限(例如写权限,直接push操作)。创建者和团队内成员面对的是同一个项目仓库,
- 而跨团队协作,团队外不在这个项目仓库中(也就是类似于没有进微信群),团队外需要fork一个这个项目,团队外拥有的只是这个项目的一个副本,团队外的修改开发只是在这个fork的副本上进行的,两者是没有关系的,团队外开发好了,需要对原来项目创建者发出一个pull request请求,希望创建者接受自己的修改,创建者同意后团队外的修改就会pull merge上。这也符合实际情形,团队内的情形,是为了完成公司的一个任务而成立的,团队内彼此熟悉,知根知底,直接建一个群即可,要求团队内的成员进群共同开发,团队的成员都拥有这个项目。而跨团队协作,适用于网上的开源软件,开源软件的作者,网上人人都可以浏览这个项目的代码,开源软件的作者不可能把所有的网上的网友都要求到一个群里去开发这个项目,创建者也不认识这么多的网友,也没必要,众多的网友可以通过fork这个项目的方式,自己可以在自己拥有的fork过来副本上开发(fork之后这个副本就是自己的了,和原来的没有关系),修改一个功能后,自己觉得修改的好,可以向原作者发出一个pull request请求(我修改了一个功能,你来拉取吧),对于团队外网友的修改,原作者得经过审核,决定要不要接受,肯定的,网友的水平参差不齐,不是什么阿猫阿狗的修改都会接受的,因此决定权在于原作者,原作者可以决定要不要拉取pull,并merge到自己的项目中,
为了演示的方便,这里我们在jiuzhuanjinshenhuiyanggong这个账号上,再创建一个项目,
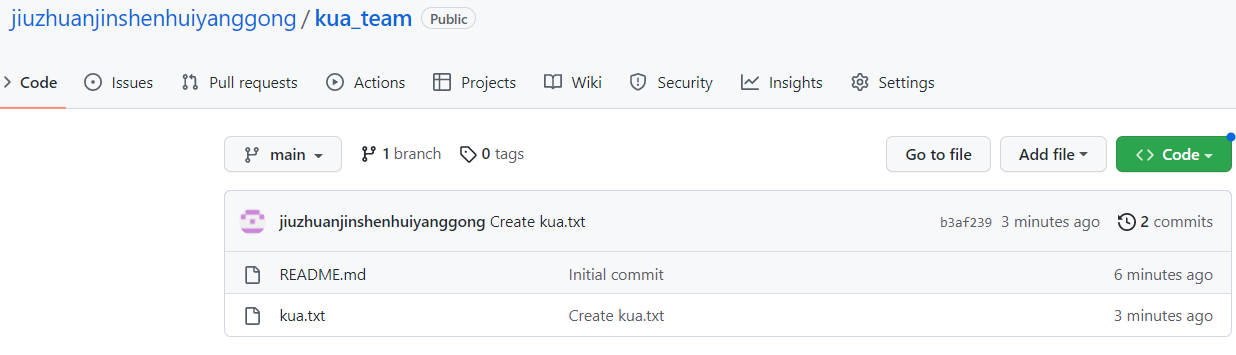
下面,我们在另一个账号上,fork这个项目(通过GitHub搜索框找到这个项目主页),
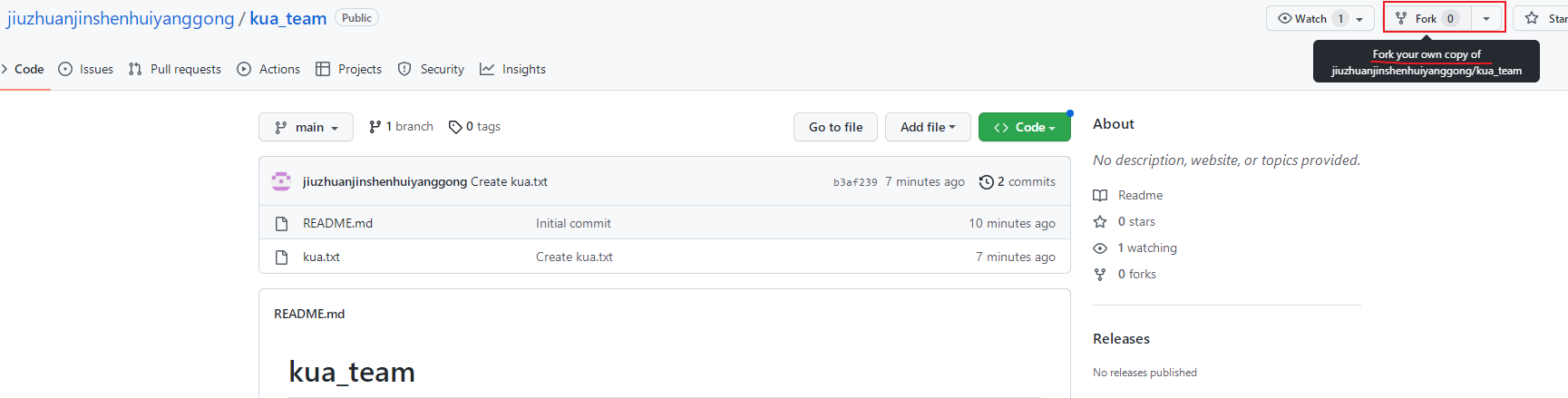
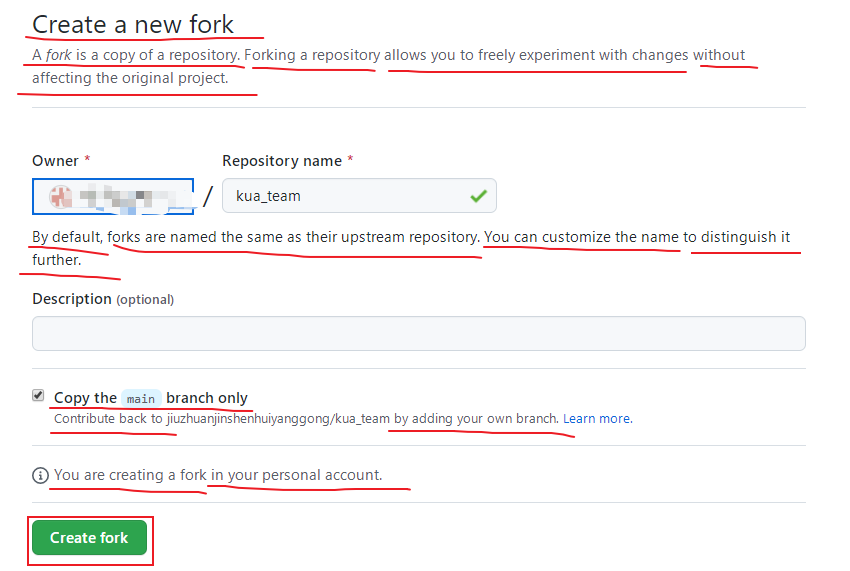
fork成功后,可以看到当前仓库的信息,
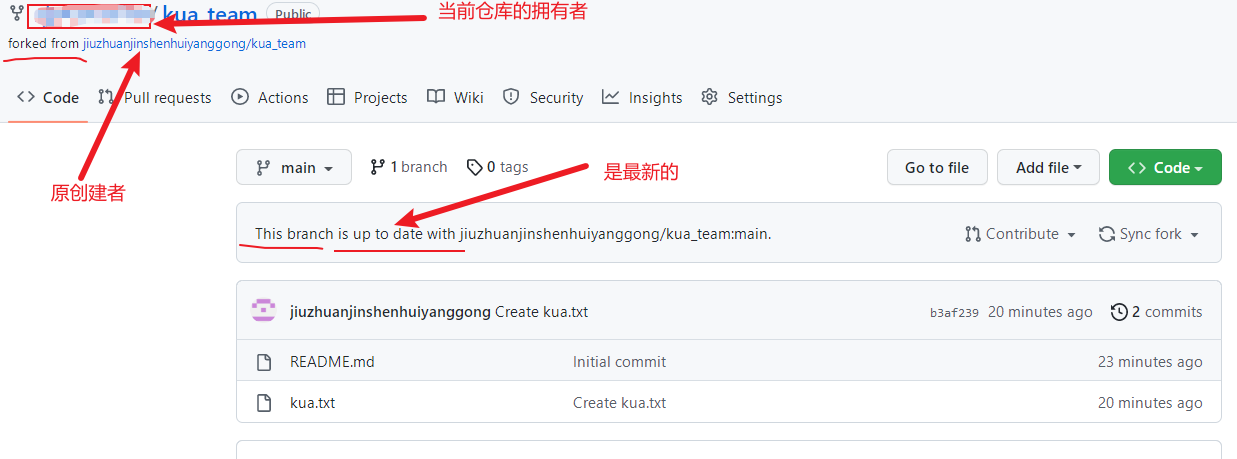
由于这里只是为了演示,所以我们直接在github账号上直接修改fork过来的项目,
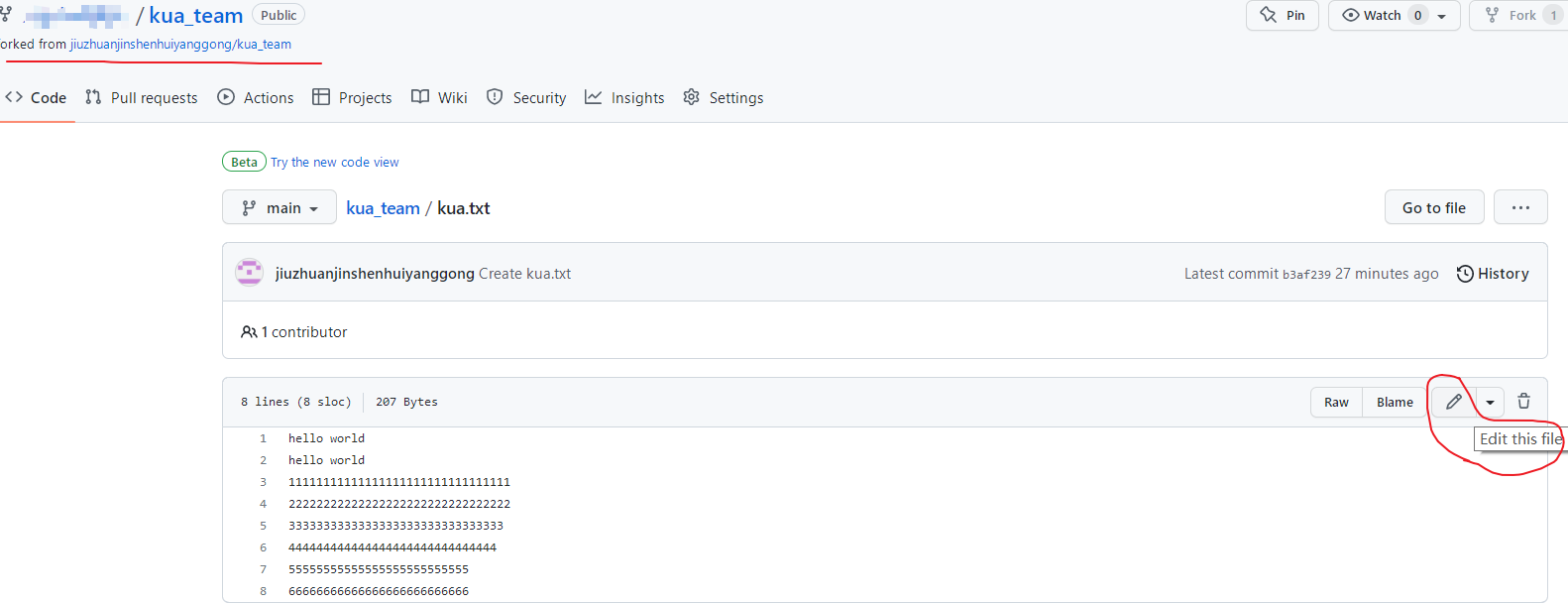
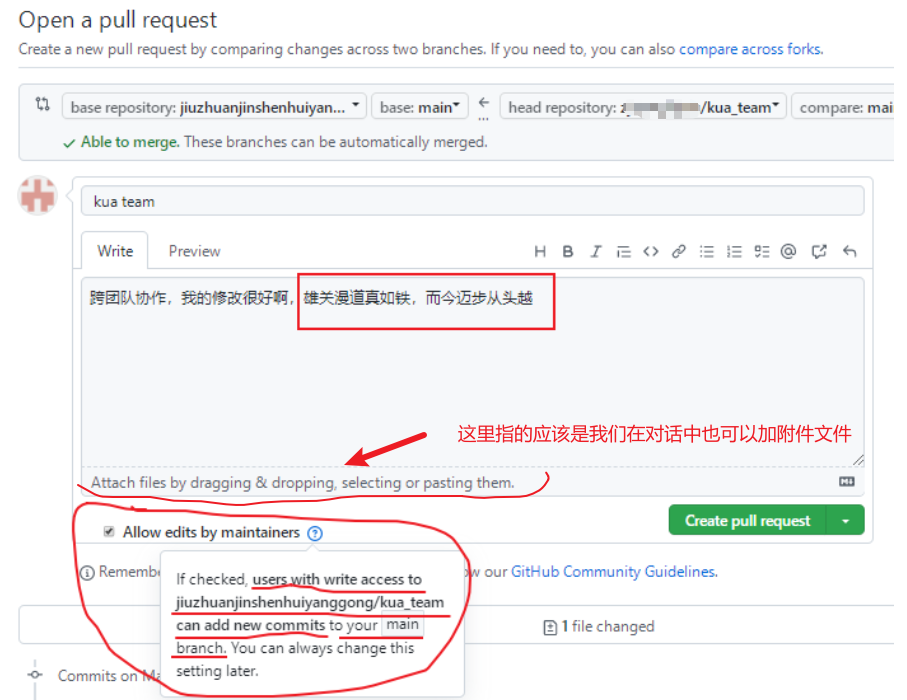
编辑完毕后,填写描述信息并点击左下角绿色按钮提交,
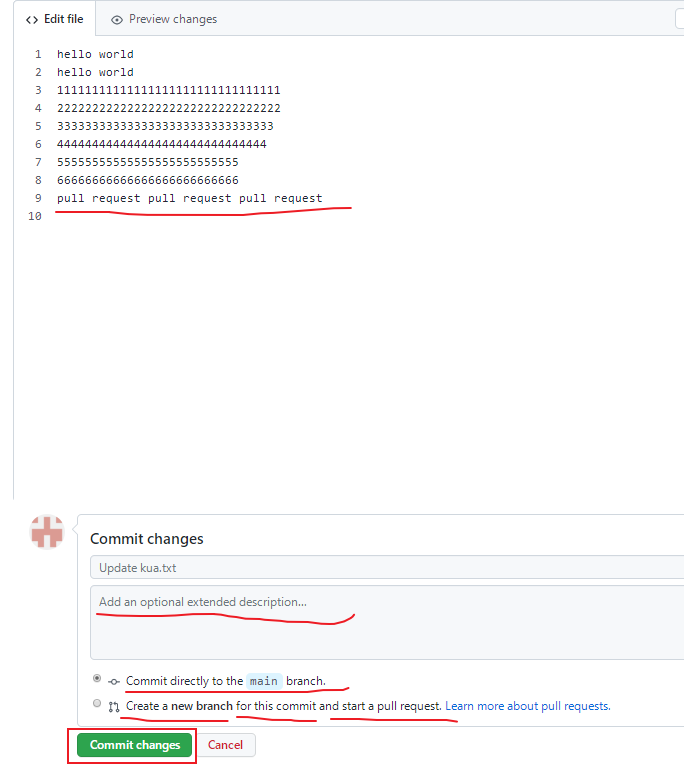
接下来点击上方的 Pull requests按钮,并创建一个新的请求,
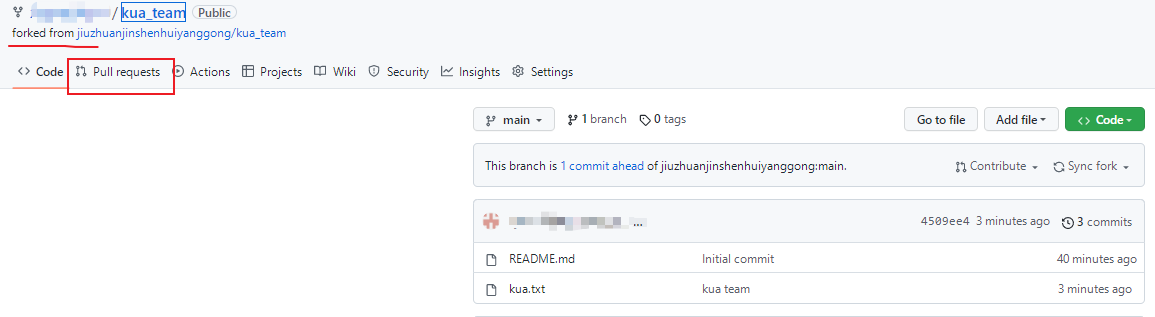
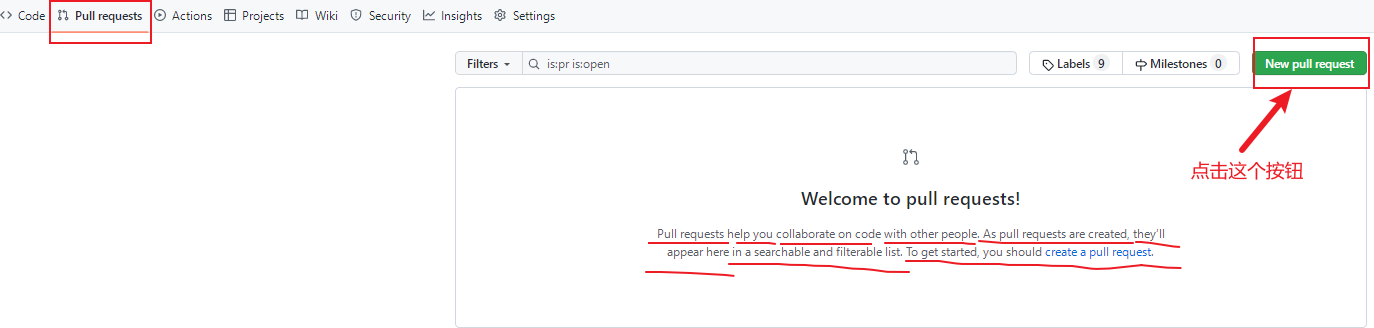
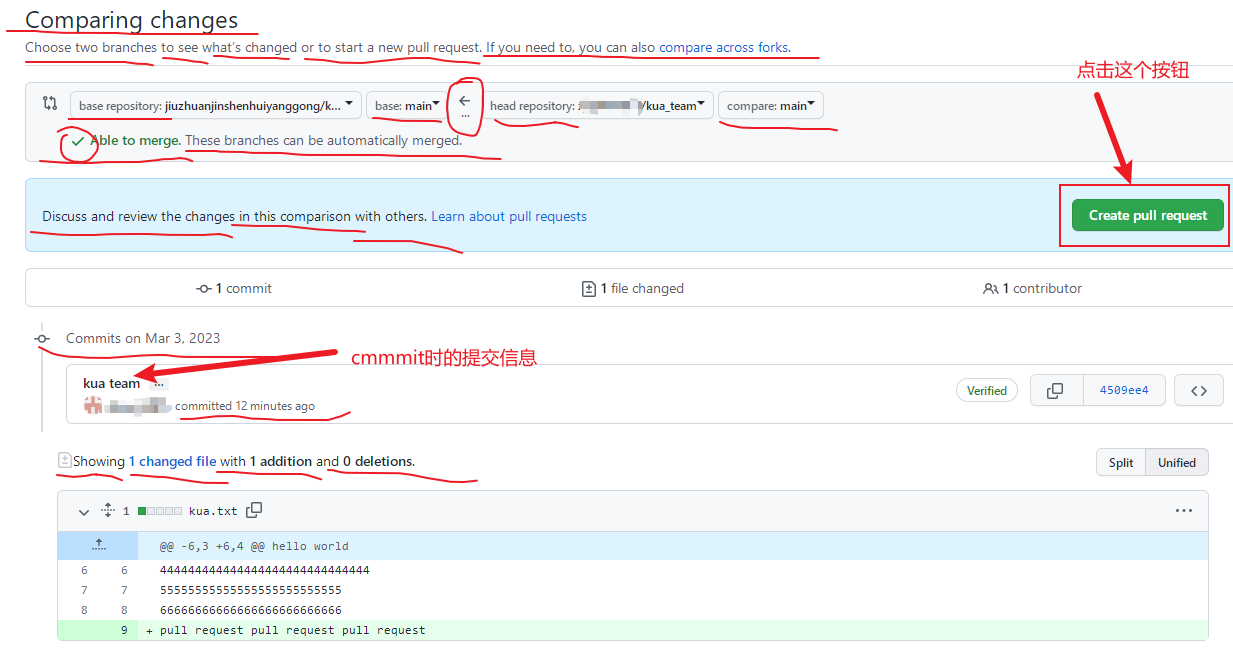
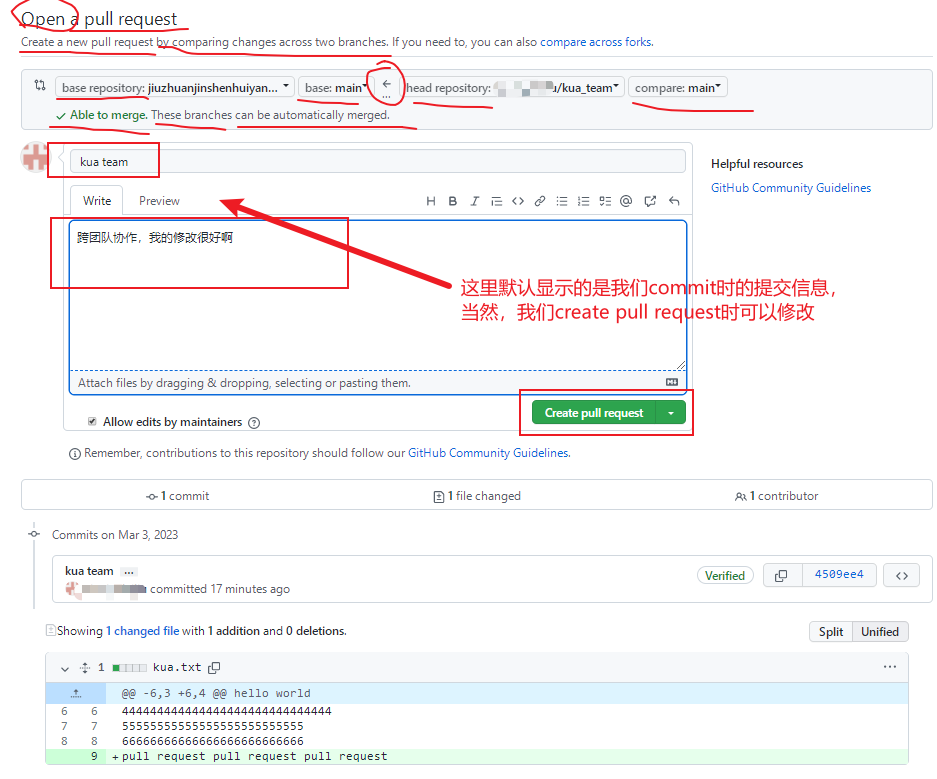
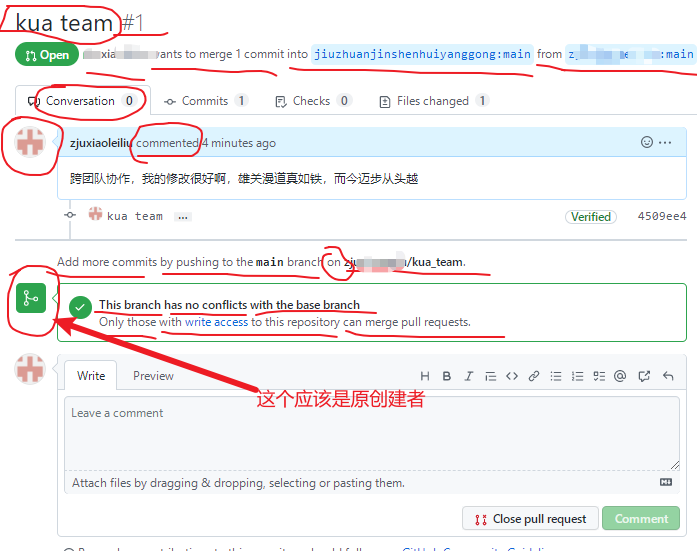
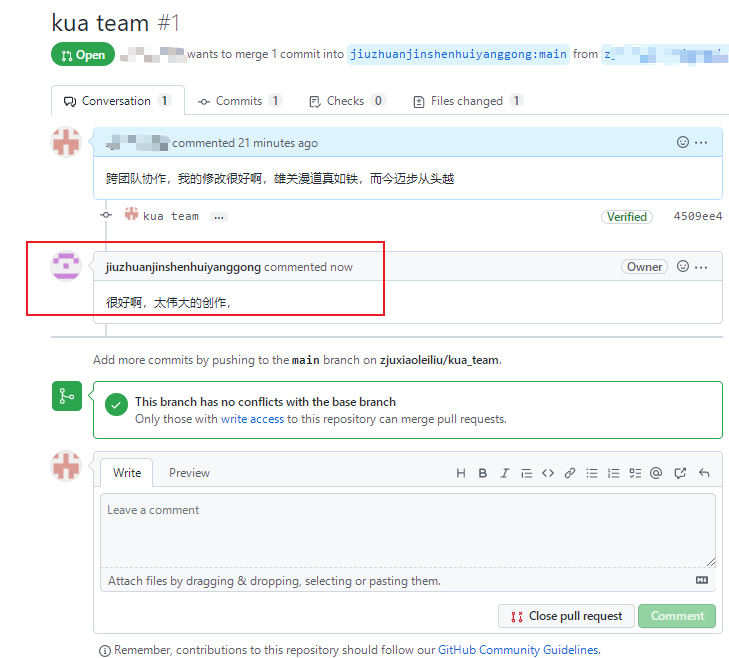
回到创建者账号,可以看到有一个 Pull request 请求,
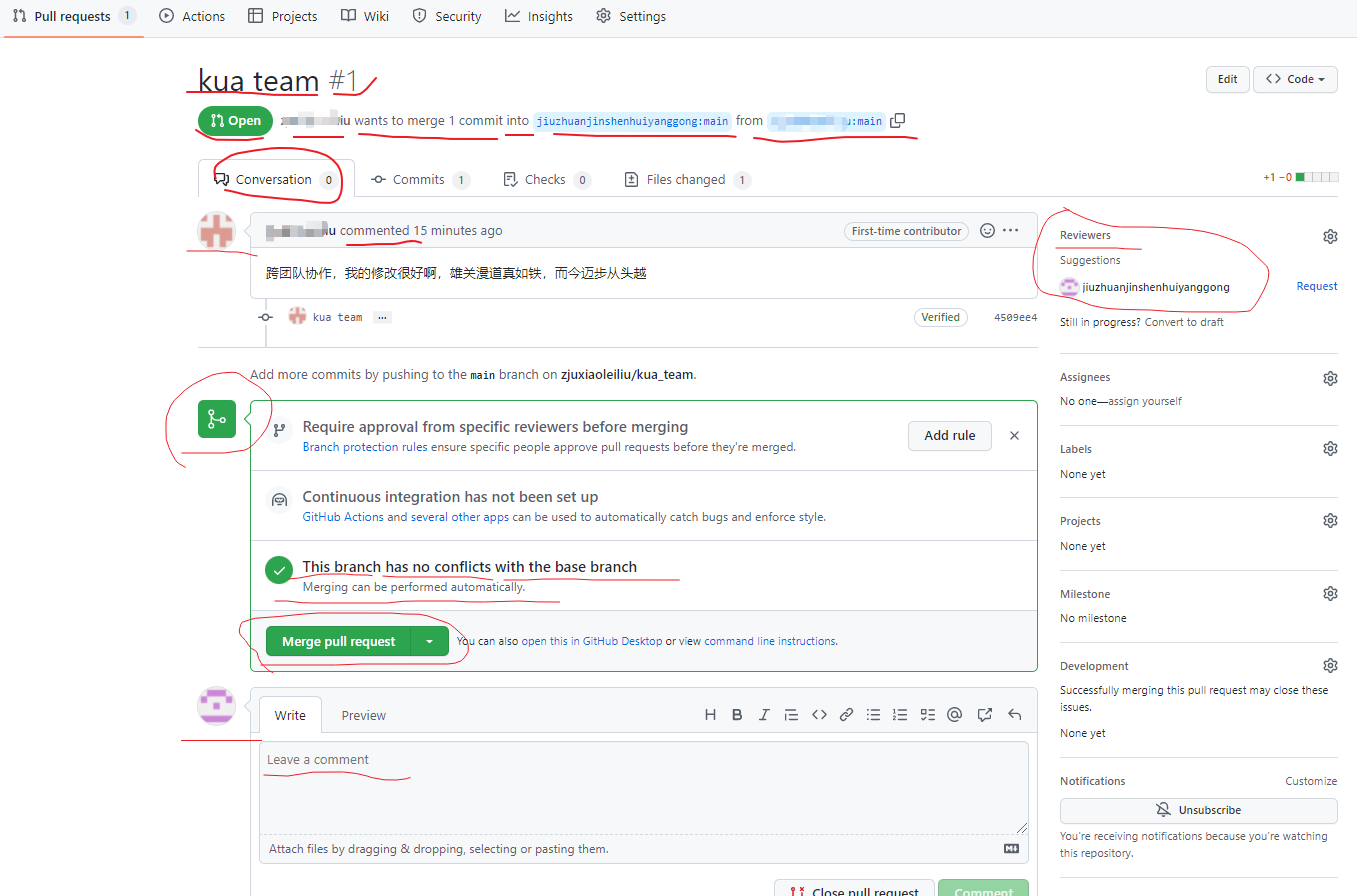
进入到聊天室,可以讨论代码相关内容,
简单回复一下,
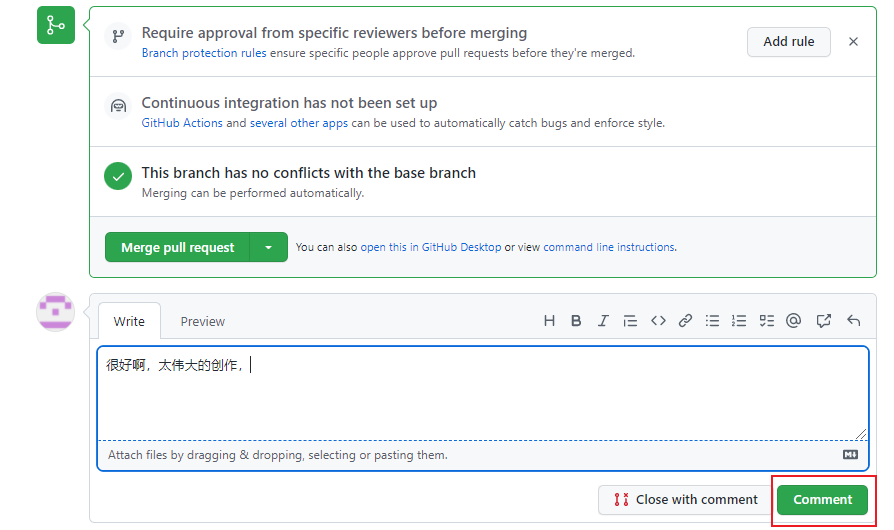
返回另一个账号,我们可以看到回复,
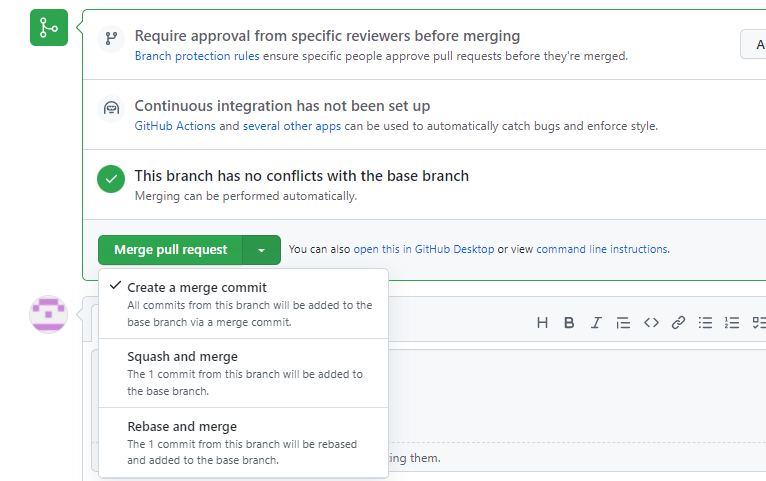
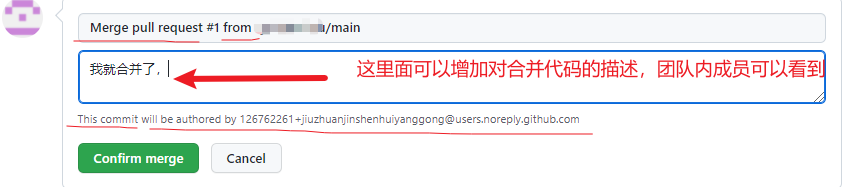
如果代码没有问题,可以点击 Merge pull reque 合并代码,
SSH 免密登录
我们可以看到远程仓库中还有一个 SSH 的地址,因此我们也可以使用 SSH 进行访问,通过设置,我们在远程SSH访问的时候不用重复输入密码,实现免密登陆,这里主要是结合github免密登录讲解下免密登陆的原理,当然不止在github上有免密登录,比如在使用XShell远程登录、VSCode远程登录,这些都可以设置免密登录。
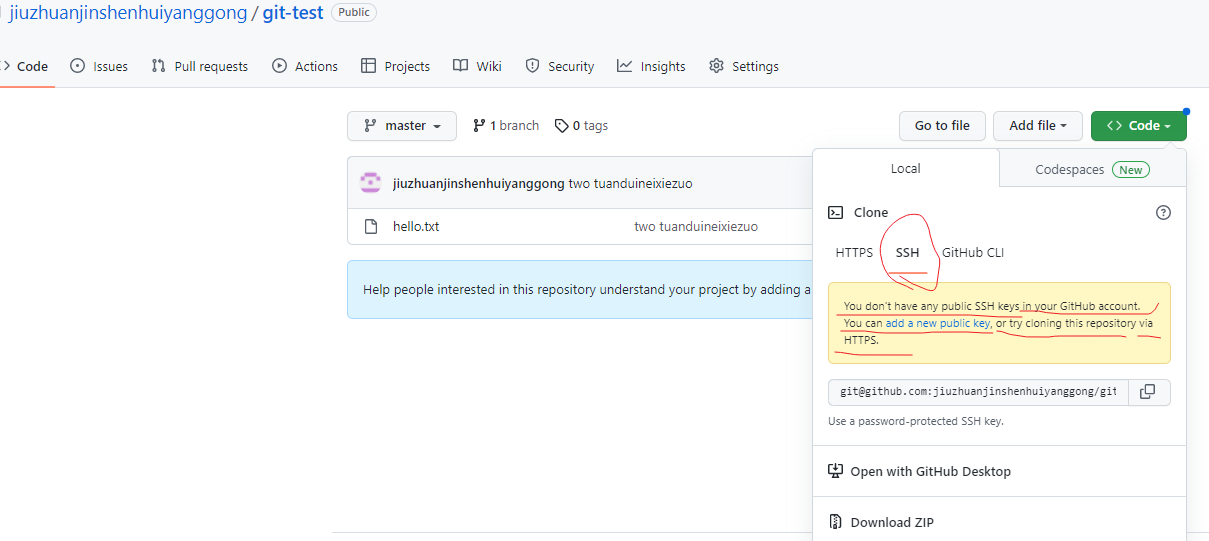
具体操作步骤如下:
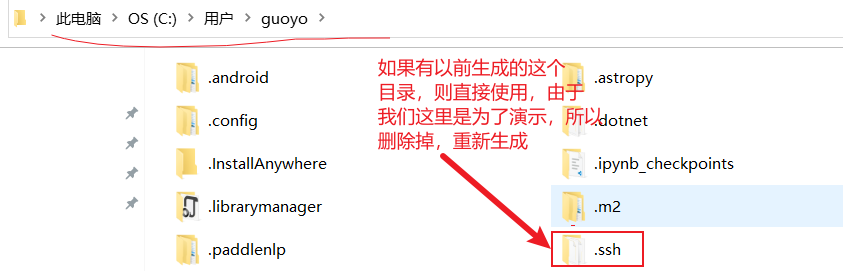
- 进入当前用户的家目录,如果有以前的.ssh文件夹,删除掉,
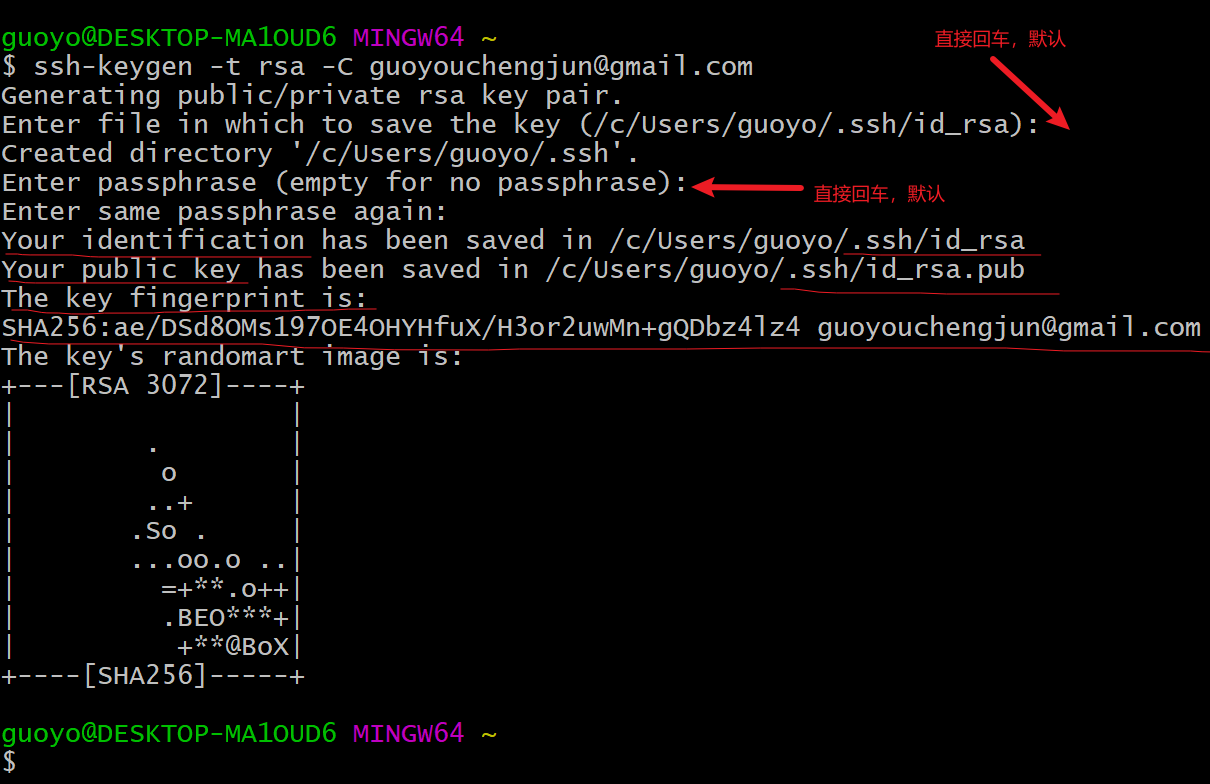
- 右键单击打开git bash,运行命令
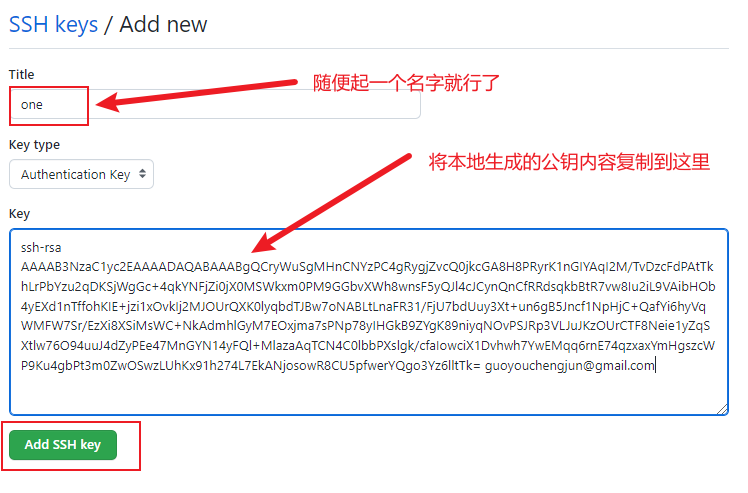
ssh-keygen -t rsa -C guoyouchengjun@gmail.com在当前目录中生成公钥私钥,
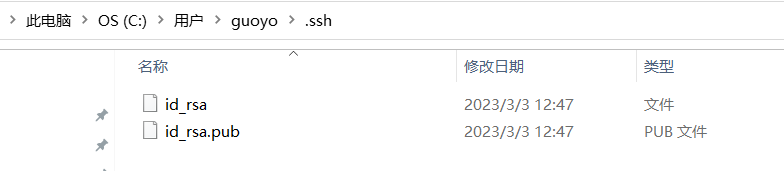
我们可以在本地硬盘上,看到生成的.ssh目录,
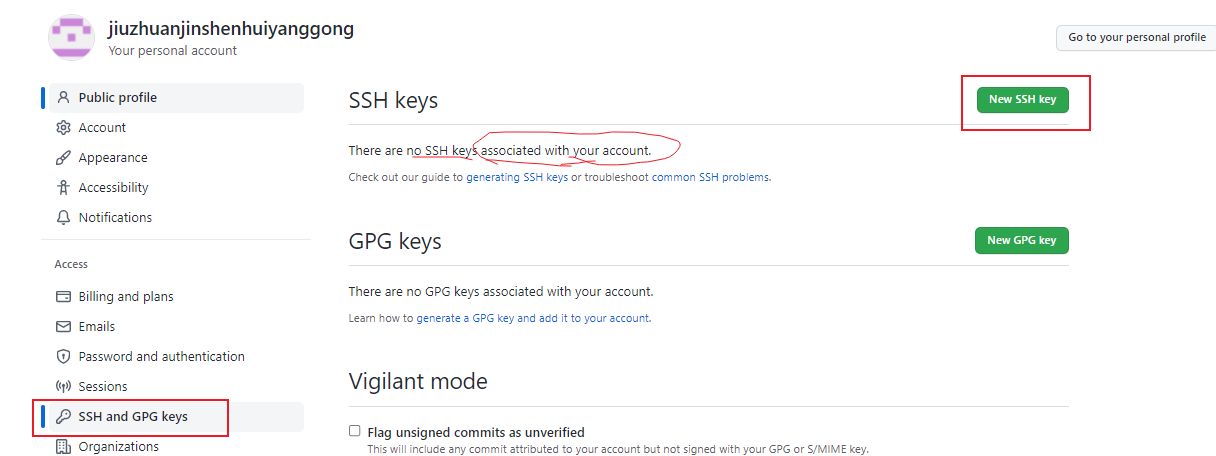
- 复制id_rsa.pub 文件内容,登录 GitHub,点击用户头像→Settings→SSH and GPG keys,
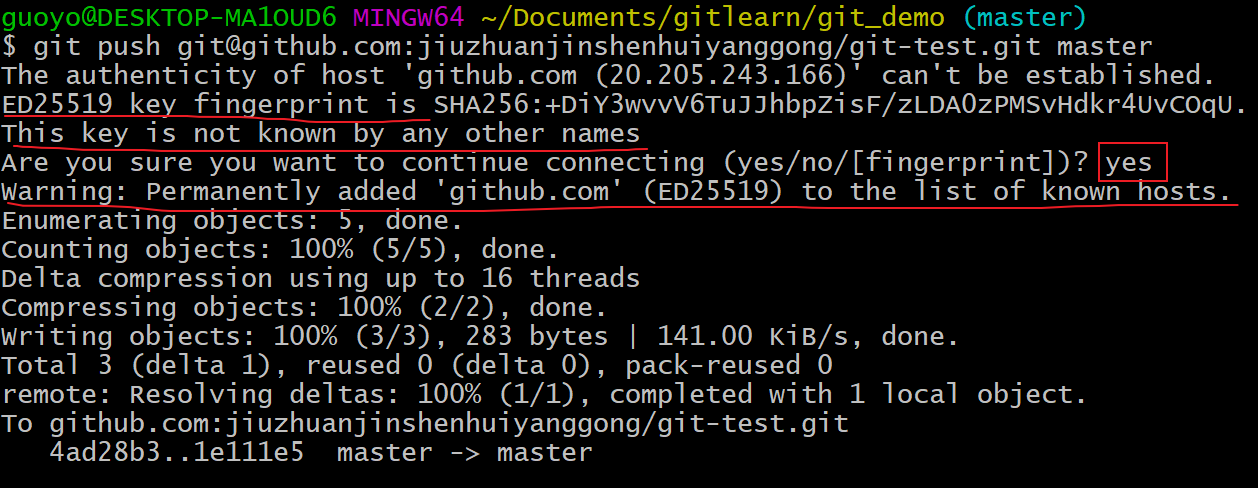
接下来再往远程仓库 push 东西的时候使用 SSH 连接就不需要登录了,我们可以试一下。
- 修改本地文件内容,
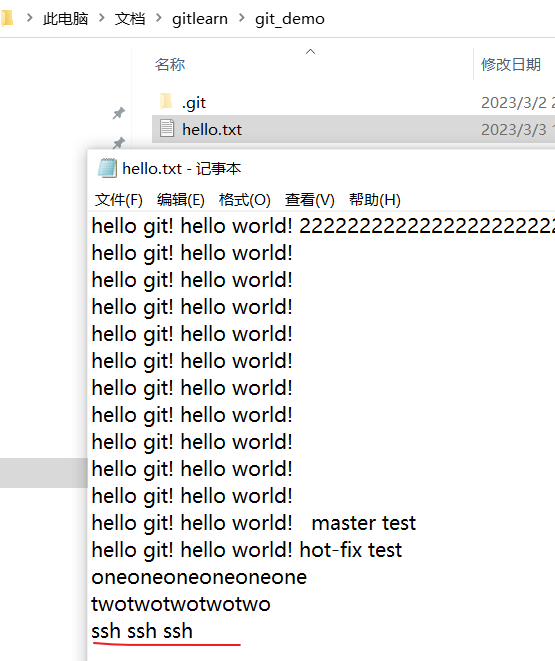
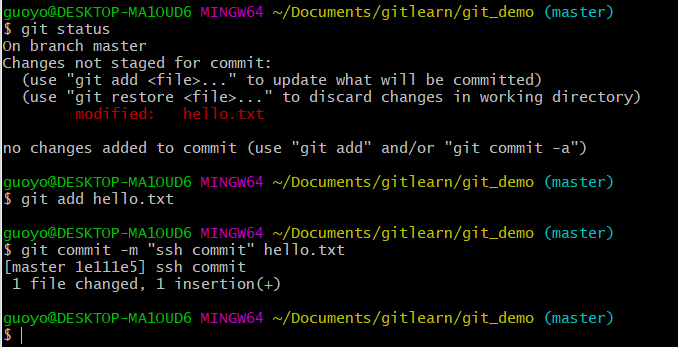
- 本地提交,
- 使用ssh推送,
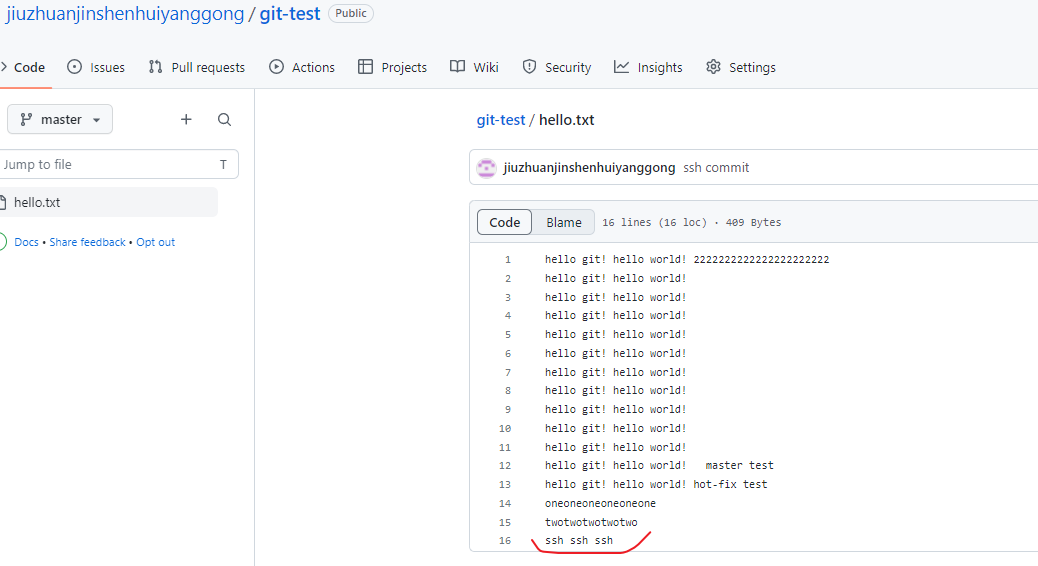
- 查看远程仓库,可以发现确实使用ssh方式推送成功了,
GitHub ssh免密登录原理:
-
SSH协议,即Sercure Shell协议。该协议的兔密登录机制,要求主机之间采用SSH-key,即SSH密钥的方式进行身份验证。SSH密钥包含“公钥与私钥",所以我们首先要了解什么是“公钥与私钥”,然后还要理解“公钥与私钥”在免密登录中的作用,即免密登录的工作原理。对于公钥与私钥,要了解以下三点:
- “公钥与私钥加密”是一种“不对称的加密方式”,是传统“对称加密方式”功能的增强。
- 公钥与私钥是成对的,即一个公钥对应一个私钥。使用公钥加密后,只能使用私钥进行解密。
- 公钥与私钥的关系:就好比“锁与钥匙”的关系。公钥相当于“锁”,锁是可以被他人看到的,是要发送给别人的,所以称为公钥。私钥相当于“钥匙”,它是不能公开的,只能有公钥发出者保存。
-
我们生成的公钥和私钥的fingerprint是一模一样的,事实上,fingerprint就是密钥的指纹,是一种hash摘要算法生成的摘要字符串,最为关键的是在ssh的密钥对中,公钥和私钥的指纹是一样的,在ssh-keygen命令中有一个l参数(小写字母l),可以列出密钥文件的fingerprint,我们来试一下,
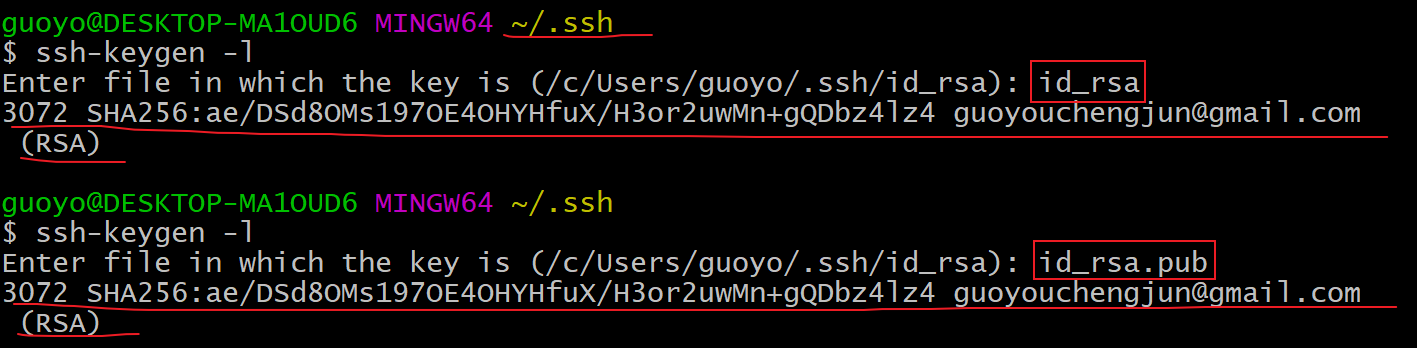
-
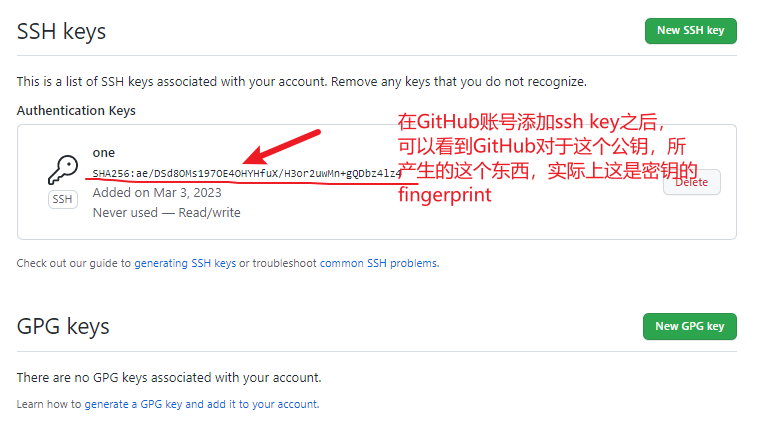
我们在GitHub账号添加ssh key后,可以看到一个字符串,那就是这个公钥的fingerprint,
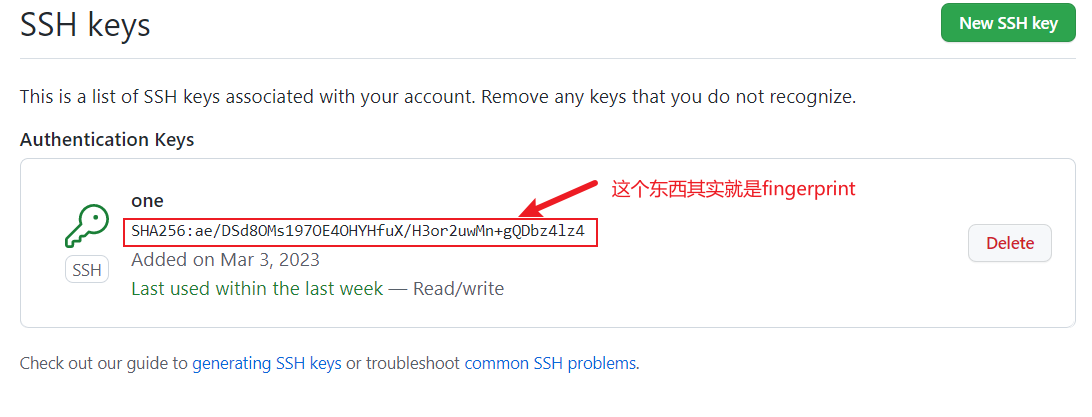
-
在github的ssh登录验证中,客户端在向github请求连接时,上送私钥生成的fingerprint(也就是说,在本地机器上删除公钥完全没有影响)。服务端收到fingerprint之后,通过这个fingerprint在公钥库中查询对应的公钥。若找不到则拒绝访问。若找到,则随机生成一个字符串,然后用此公钥加密验证字符串发给客户端,客户端收到后用私钥解密,再将该字符串返回服务端,服务端对比原始串成功则证明客户端的身份,从而代替了github登录时的用户名和密码。
对于"github后台是如何匹配git客户端发上来的连接请求,从而找到账户内设置的公钥,再通过公钥进行加密的?"这个问题,以下几点都是错误的,
- A同学说:客户端在第一次请求时把.ssh目录下的id_rsa.pub公钥文件上送到github,github到公钥库内匹配找到以前维护的公钥。可事实上,你把id_rsa.pub文件删除,然后用ssh -T git@github.com 命令测试,仍可以验证通过。所以上送公钥的说法不成立。
- B同学说:客户端在生成密钥对的时候,将客户端硬件识别信息(诸如MAC)加入到了公钥中,在验证链接时将此信息发送到了github,github通过这个信息匹配到公钥。可实际上是,你把id_rsa私钥文件复制到其他机器上做测试,仍可以验证通过。所以这种说法也不成立。
- C同学说:客户端在用ssh-keygen -t rsa -C "test@163.com"命令生成密钥对的时候,在C参数后跟了个邮箱名,这个邮箱名必须和github的注册用户邮箱一致,所以在连接时会匹配到这个邮箱,找到对应的公钥。可经过试验,你改成任何一个邮箱或者字符串,连接仍旧测试成功。事实上这个C参数只是一个密钥对的备注信息,和github注册邮箱毫无关系。仍旧不成立。
