

paddlenlp的tokenizer中的__call__()函数
函数原型
def __call__(self,
text: Union[str, List[str], List[List[str]]],
text_pair: Optional[Union[str, List[str],
List[List[str]]]] = None,
max_length: Optional[int] = None,
stride: int = 0,
is_split_into_words: Union[bool, str] = False,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = False,
return_position_ids: bool = False,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_length: bool = False,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_dict: bool = True,
return_offsets_mapping: bool = False,
add_special_tokens: bool = True,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
verbose: bool = True,
**kwargs):
函数含义
Performs tokenization and uses the tokenized tokens to prepare model inputs. It supports sequence or sequence pair as input, and batch input is allowed. self.encode() or self.batch_encode() would be called separately for single or batch input depending on input format andis_split_into_words argument.
参数(Args)含义
-
text (str, List[str] or List[List[str]]):
The sequence or batch of sequences to be processed. One sequence is a string or a list of strings depending on whether it has been pretokenized. If each sequence is provided as a list of strings(pretokenized), you must setis_split_into_wordsasTrueto disambiguate with a batch of sequences. -
text_pair (str, List[str] or List[List[str]], optional):
Same astextargument, while it represents for the latter sequence of the sequence pair. -
max_length (int, optional):
If set to a number, will limit the total sequence returned so that it has a maximum length. If there are overflowing tokens,those overflowing tokens will be added to the returned dictionary whenreturn_overflowing_tokensisTrue. Defaults toNone. -
stride (int, optional):
Only available for batch input of sequence pair and mainly for question answering usage. When for QA,textrepresents questions andtext_pairrepresents contexts. Ifstrideis set to a positive number, the context will be split into multiple spans wherestridedefines the number of (tokenized) tokens to skip from the start of one span to get the next span, thus will produce a bigger batch than inputs to include all spans. Moreover, 'overflow_to_sample' and 'offset_mapping' preserving the original example and position information will be added to the returned dictionary. Defaults to 0.
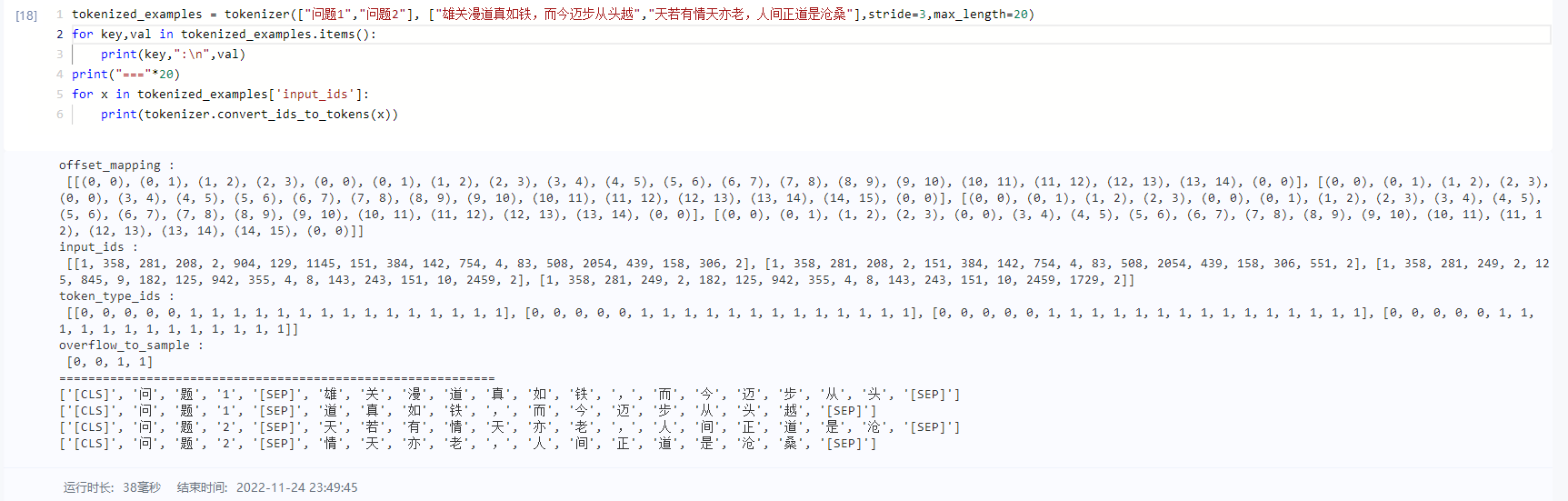
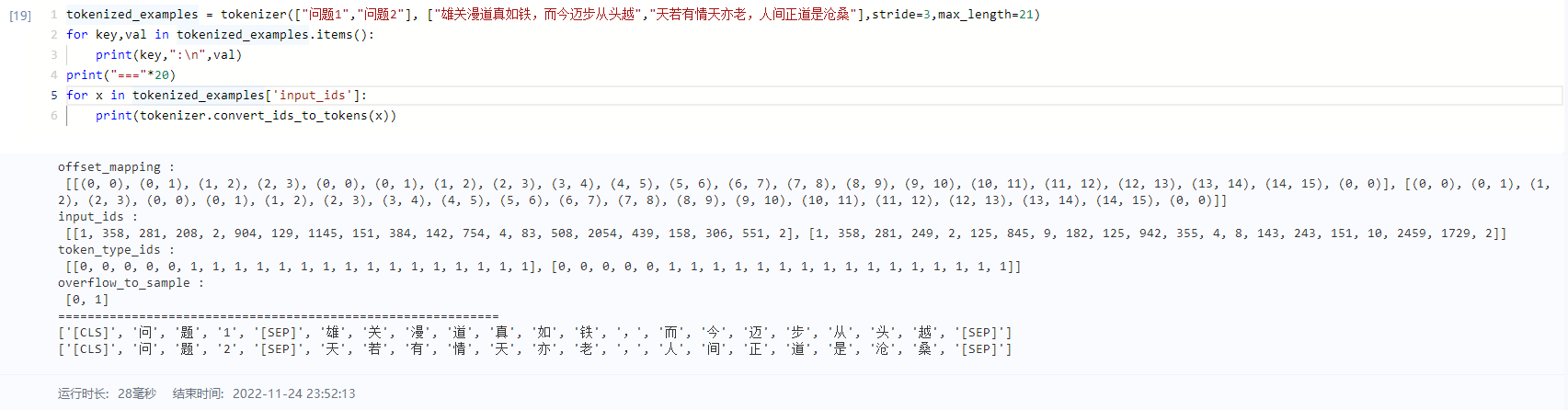
-
is_split_into_words (Union[bool, str], optional):
when the text is words or tokens,is_split_into_wordsshould be True ortoken.True: means that the text should be words which should be tokenized.token: means that the text should be tokens which already be tokenized, so it should not be tokenized again.
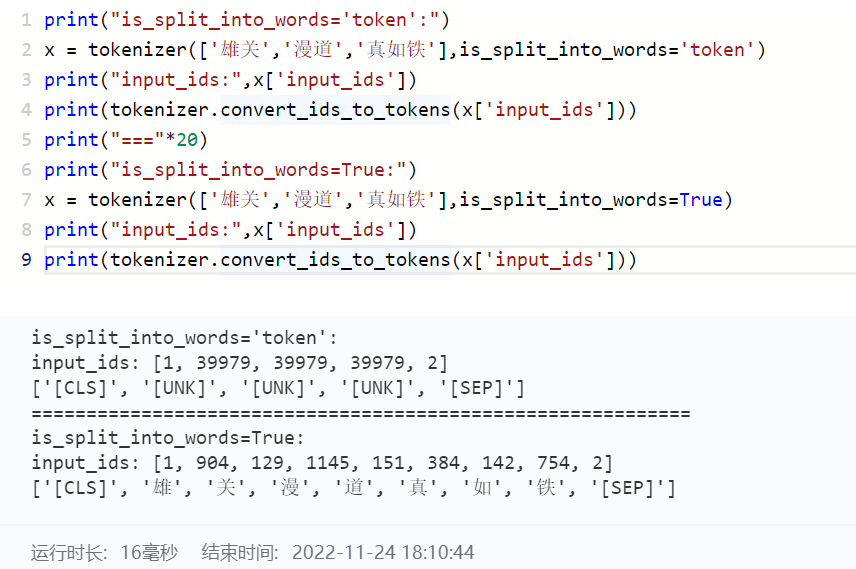
-
padding(填充) (bool, str or [PaddingStrategy], optional):
Activates and controls padding. Accepts the following values:- True or 'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).
- 'max_length': Pad to a maximum length specified with the argument
max_lengthor to the maximum acceptable input length for the model if that argument is not provided. - False or 'do_not_pad' (default): No padding (i.e., can output a batch with sequences of different lengths).
Defaults toFalse.
-
truncation(截断) (bool, str or [TruncationStrategy], optional):
Activates and controls truncation. Accepts the following values:- True or 'longest_first': Truncate to a maximum length specified with the argument
max_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided. - 'only_first': Truncate to a maximum length specified with the argument
max_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided. - 'only_second': Truncate to a maximum length specified with the argument
max_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided. - False or 'do_not_truncate' (default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
Defaults toFalse.
- True or 'longest_first': Truncate to a maximum length specified with the argument
-
return_position_ids (bool, optional):
Whether to include tokens position ids in the returned dictionary.
Defaults toFalse. -
return_token_type_ids (bool, optional):
Whether to include token type ids in the returned dictionary.
Defaults toTrue. -
return_attention_mask (bool, optional):
Whether to include the attention mask in the returned dictionary.
Defaults toFalse. -
return_length (bool, optional):
Whether to include the length of each encoded inputs in the returned dictionary.
Defaults toFalse. -
return_overflowing_tokens (bool, optional):
Whether to include overflowing token information in the returned dictionary.
Defaults toFalse.
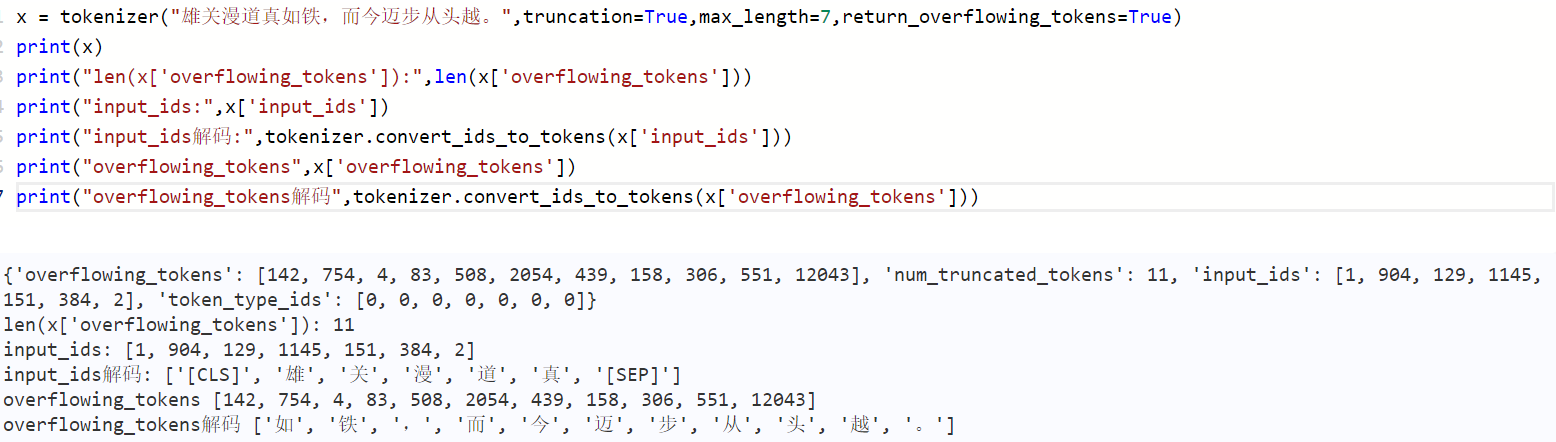
-
return_special_tokens_mask (bool, optional):
Whether to include special tokens mask information in the returned dictionary.
Defaults toFalse.
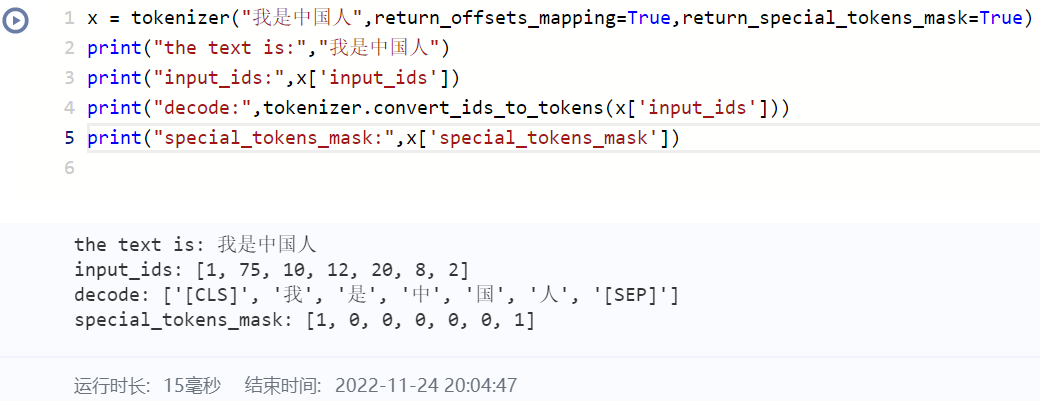
-
return_dict (bool, optional):
Decide the format for returned encoded batch inputs. Only works when input is a batch of data.- If True, encoded inputs would be a dictionary like:
{ 'input_ids': [[1, 4444, 4385, 1545, 6712],[1, 4444, 4385]], 'token_type_ids': [[0, 0, 0, 0, 0], [0, 0, 0]] }- If False, encoded inputs would be a list like:
[ { 'input_ids': [1, 4444, 4385, 1545, 6712], 'token_type_ids': [0, 0, 0, 0, 0] }, { 'input_ids': [1, 4444, 4385], 'token_type_ids': [0, 0, 0] } ]
Defaults to True.
-
return_offsets_mapping (bool, optional):
Whether to include the list of pair preserving the index of start and end char in original input for each token in the returned dictionary. Would be automatically set toTruewhenstride> 0.
Defaults toFalse.
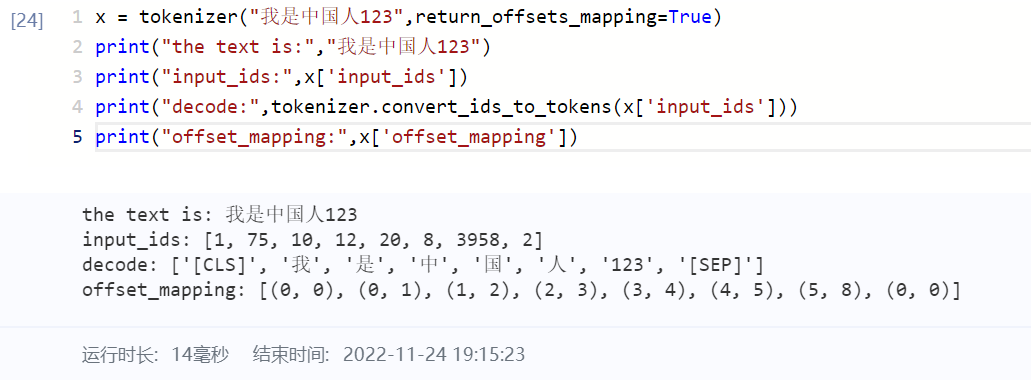
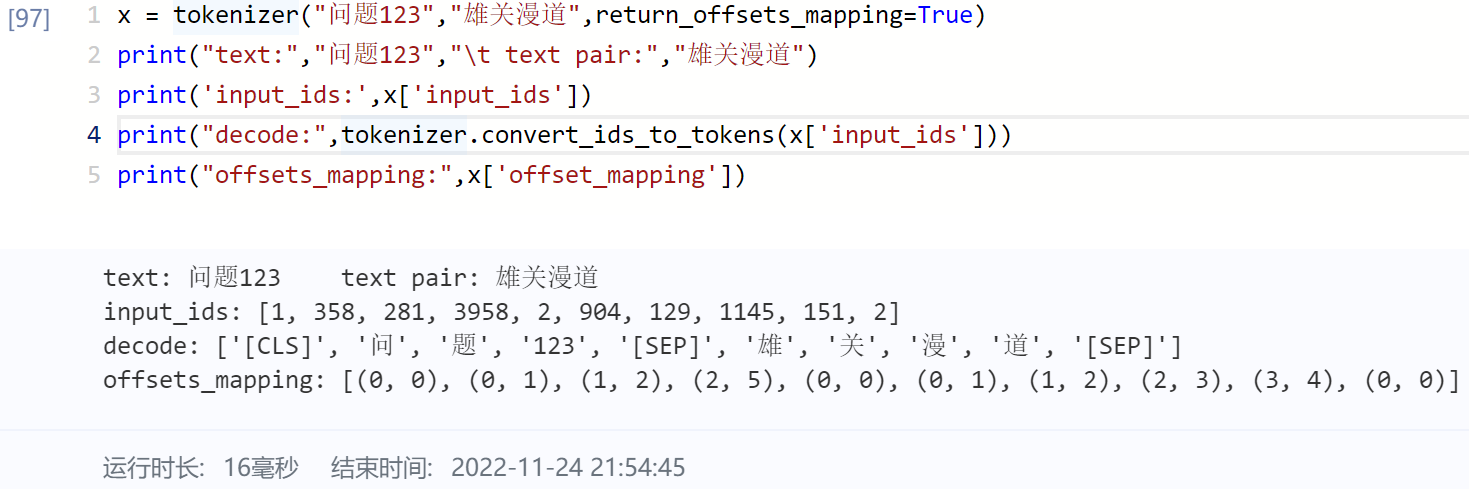
-
add_special_tokens (bool, optional):
Whether to add the special tokens associated with the corresponding model to the encoded inputs. Defaults toTrue -
pad_to_multiple_of (int, optional):
If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
Defaults toNone. -
return_tensors (str or [TensorType], optional):
If set, will return tensors instead of list of python integers. Acceptable values are:- 'pd': Return Paddle
paddle.Tensorobjects. - 'np': Return Numpy
np.ndarrayobjects.
Defaults toNone.
- 'pd': Return Paddle
-
verbose (bool, optional):
Whether or not to print more information and warnings.
Defaults to True.
返回值(Returns)含义
dict or list[dict] (for batch input),The dict has the following optional items:
-
input_ids (list[int] or list[list[int]]):
List of token ids to be fed to a model. -
position_ids (list[int] or list[list[int]], optional):
List of token position ids to be fed to a model. Included whenreturn_position_idsisTrue -
token_type_ids (list[int] or list[list[int]], optional):
List of token type ids to be fed to a model. Included whenreturn_token_type_idsisTrue. -
attention_mask (list[int] or list[list[int]], optional):
List of integers valued 0 or 1,where 0 specifies paddings and should not be attended to by the model. Included whenreturn_attention_maskisTrue. -
seq_len (int or list[int], optional):
The input_ids length. Included whenreturn_lengthisTrue. -
overflowing_tokens (list[int] or list[list[int]], optional):
List of overflowing tokens.Included when ifmax_lengthis specified andreturn_overflowing_tokensis True. -
num_truncated_tokens (int or list[int], optional):
The number of overflowing tokens.Included when ifmax_lengthis specified andreturn_overflowing_tokensis True. -
special_tokens_mask (list[int] or list[list[int]], optional):
List of integers valued 0 or 1,with 0 specifying special added tokens and 1 specifying sequence tokens.Included whenreturn_special_tokens_maskisTrue. -
offset_mapping (list[int], optional):
list of pair preserving the index of start and end char in original input for each token.For a sqecial token, the index pair is (0, 0). Included when return_offsets_mapping is True or stride > 0. -
overflow_to_sample (int or list[int], optional):
Index of example from which this feature is generated. Included whenstrideworks.
