

第6章 C语言数组总结
数组的定义方式:
dataType arrayName[length];
dataType 为数据类型,arrayName 为数组名称,length 为数组长度。
#include <stdio.h>
int main(){
int nums[10];
//依次输出数组元素
for(int i=0; i<10; i++){
printf("%d ", nums[i]);
}
return 0;
}
- vs2022+64下的运行结果为:

这里局部数组没有初始化直接使用,在vstudio2022下能够直接运行,没有报错,不像前面的对一个局部变量没有初始化直接使用,在vstudio2022上会直接编译报错(如果对这个没有初始化的局部变量不使用,程序编译,运行还是不会报错的),而这里能够直接编译运行,没法发生错误(推测对于局部数组,数组名是一个指针,我们使用这个没有初始化的局部数组的元素,是通过数组名+下标即通过指针的方式访问,所以才没有报错,不知道推测对不对),但是vstudio2022会有警告信息:

- clion+64下的运行结果为:

#include <stdio.h>
int main(){
int nums[10];
int i;
//从控制台读取用户输入
for(i=0; i<10; i++){
scanf("%d", &nums[i]); //注意取地址符 &,不要遗忘哦
}
//依次输出数组元素
for(i=0; i<10; i++){
printf("%d ", nums[i]);
}
return 0;
}

注意,上面代码里的scanf函数,在vstudio2022里面,要替换成scanf_s,不然会报错。

数组是一个整体,它的内存是连续的;也就是说,数组元素之间是相互挨着的,彼此之间没有一点点缝隙。下图演示了int a[4];在内存中的存储情形:
 「数组内存是连续的」这一点很重要,连续的内存为指针操作(通过指针来访问数组元素)和内存处理(整块内存的复制、写入等)提供了便利,这使得数组可以作为缓存(临时存储数据的一块内存)使用。
「数组内存是连续的」这一点很重要,连续的内存为指针操作(通过指针来访问数组元素)和内存处理(整块内存的复制、写入等)提供了便利,这使得数组可以作为缓存(临时存储数据的一块内存)使用。
上面的代码是先定义数组再给数组赋值,我们也可以在定义数组的同时赋值,例如:
int a[4] = {20, 345, 700, 22};
对于数组的初始化需要注意以下几点:
- 可以只给部分元素赋值。当{ }中值的个数少于元素个数时,只给前面部分元素赋值。当赋值的元素少于数组总体元素的时候,剩余的元素自动初始化为 0:
- 对于short、int、long,就是整数 0;
- 对于char,就是字符 '\0';
- 对于float、double,就是小数 0.0。
int a[10]={12, 19, 22 , 993, 344};
表示只给 a[0]~a[4] 5个元素赋值,而后面 5 个元素自动初始化为 0。
- 只能给元素逐个赋值,不能给数组整体赋值。例如给 10 个元素全部赋值为 1,只能写作:
int a[10] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
而不能写作:
int a[10] = 1;
- 如给全部元素赋值,那么在定义数组时可以不给出数组长度。例如:
int a[] = {1, 2, 3, 4, 5};
等价于:
int a[5] = {1, 2, 3, 4, 5};
二维数组定义的一般形式是:
dataType arrayName[length1][length2];
其中,dataType 为数据类型,arrayName 为数组名,length1 为第一维下标的长度,length2 为第二维下标的长度。
二维数组在概念上是二维的,但在内存中是连续存放的;换句话说,二维数组的各个元素是相互挨着的,彼此之间没有缝隙。那么,如何在线性内存中存放二维数组呢?有两种方式:
- 一种是按行排列, 即放完一行之后再放入第二行;
- 另一种是按列排列, 即放完一列之后再放入第二列。
在C语言中,二维数组是按行排列的。也就是先存放 a[0] 行,再存放 a[1] 行,最后存放 a[2] 行;每行中的 4 个元素也是依次存放。数组 a 为 int 类型,每个元素占用 4 个字节,整个数组共占用 4×(3×4)=48 个字节。 你可以这样认为,二维数组是由多个长度相同的一维数组构成的。
#include <stdio.h>
int main() {
int i, j; //二维数组下标
int sum = 0; //当前科目的总成绩
int average; //总平均分
int v[3]; //各科平均分
int a[5][3]; //用来保存每个同学各科成绩的二维数组
printf("Input score:\n");
for (i = 0; i < 3; i++) {
for (j = 0; j < 5; j++) {
scanf_s("%d", &a[j][i]); //输入每个同学的各科成绩
sum += a[j][i]; //计算当前科目的总成绩
}
v[i] = sum / 5; // 当前科目的平均分
sum = 0;
}
average = (v[0] + v[1] + v[2]) / 3;
printf("Math: %d\nC Languag: %d\nEnglish: %d\n", v[0], v[1], v[2]);
printf("Total: %d\n", average);
return 0;
}

二维数组的初始化可以按行分段赋值,也可按行连续赋值。例如,对于数组 a[5][3],
- 按行分段赋值应该写作:
int a[5][3]={ {80,75,92}, {61,65,71}, {59,63,70}, {85,87,90}, {76,77,85} };
- 按行连续赋值应该写作:
int a[5][3]={80, 75, 92, 61, 65, 71, 59, 63, 70, 85, 87, 90, 76, 77, 85};
这两种赋初值的结果是完全相同的。
对于二维数组的初始化还要注意以下几点:
- 可以只对部分元素赋值,未赋值的元素自动取“零”值。例如:
int a[3][3] = {{1}, {2}, {3}};
是对每一行的第一列元素赋值,未赋值的元素的值为 0。赋值后各元素的值为:

再如:
int a[3][3] = {{0,1}, {0,0,2}, {3}};
赋值后各元素的值为:

- 如果对全部元素赋值,那么第一维的长度可以不给出。例如:
int a[3][3] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
可以写为:
int a[][3] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
- 二维数组可以看作是由一维数组嵌套而成的;如果一个数组的每个元素又是一个数组,那么它就是二维数组。当然,前提是各个元素的类型必须相同。根据这样的分析,一个二维数组也可以分解为多个一维数组,C语言允许这种分解。例如,二维数组a[3][4]可分解为三个一维数组,它们的数组名分别为 a[0]、a[1]、a[2]。这三个一维数组可以直接拿来使用。这三个一维数组都有 4 个元素,比如,一维数组 a[0] 的元素为 a[0][0]、a[0][1]、a[0][2]、a[0][3]。
字符数组实际上是一系列字符的集合,也就是字符串(String)。在C语言中,没有专门的字符串变量,没有string类型,通常就用一个字符数组来存放一个字符串。C语言规定,可以将字符串直接赋值给字符数组,例如:
char str[30] = {"www.baidu.xyz"};
char str[30] = "www.baidu.xyz"; //这种形式更加简洁,实际开发中常用
为了方便,你也可以不指定数组长度,从而写作:
char str[] = {"www.baidu.xyz"};
char str[] = "www.baidu.xyz"; //这种形式更加简洁,实际开发中常用
给字符数组赋值时,我们通常使用这种写法,将字符串一次性地赋值(可以指明数组长度,也可以不指明),而不是一个字符一个字符地赋值,那样做太麻烦了。
char a[10]; //一维字符数组
char b[5][10]; //二维字符数组
char c[20]={'c', ' ', 'p', 'r', 'o', 'g', 'r', 'a','m'}; // 给部分数组元素赋值
char d[]={'c', ' ', 'p', 'r', 'o', 'g', 'r', 'a', 'm' }; //对全体元素赋值时可以省去长度
这里需要留意一个坑,字符数组只有在定义时才能将整个字符串一次性地赋值给它,一旦定义完了,就只能一个字符一个字符地赋值了。请看下面的例子:
char str[7]; str = "abc123"; //错误 //正确 str[0] = 'a'; str[1] = 'b'; str[2] = 'c'; str[3] = '1'; str[4] = '2'; str[5] = '3';
字符串是一系列连续的字符的组合,要想在内存中定位一个字符串,除了要知道它的开头,还要知道它的结尾。找到字符串的开头很容易,知道它的名字(字符数组名或者字符串名)就可以;然而,如何找到字符串的结尾呢?C语言的解决方案有点奇妙,或者说有点奇葩。 在C语言中,字符串总是以'\0'作为结尾,所以'\0'也被称为字符串结束标志,或者字符串结束符。'\0'是 ASCII 码表中的第 0 个字符,英文称为 NUL,中文称为“空字符”。该字符既不能显示,也没有控制功能,输出该字符不会有任何效果,它在C语言中唯一的作用就是作为字符串结束标志。
- C语言在处理字符串时,会从前往后逐个扫描字符,一旦遇到'\0'就认为到达了字符串的末尾,就结束处理。'\0'至关重要,没有'\0'就意味着永远也到达不了字符串的结尾。
- 由" "包围的字符串会自动在末尾添加'\0'。(个人:这应该是编译器自动干的)例如,"abc123"从表面看起来只包含了 6 个字符,其实不然,C语言会在最后隐式地添加一个'\0',这个过程是在后台默默地进行的,所以我们感受不到。下图演示了"C program"在内存中的存储情形:

- 需要注意的是,逐个字符地给数组赋值并不会自动添加'\0',例如:
char str[] = {'a', 'b', 'c'};
数组 str 的长度为 3,而不是 4,因为最后没有'\0'。
- 当用字符数组存储字符串时,要特别注意'\0',要为'\0'留个位置;这意味着,字符数组的长度至少要比字符串的长度大 1。请看下面的例子:
char str[7] = "abc123";
"abc123"看起来只包含了 6 个字符,我们却将 str 的长度定义为 7,就是为了能够容纳最后的'\0'。如果将 str 的长度定义为 6,它就无法容纳'\0'了。
有些时候,程序的逻辑要求我们必须逐个字符地为数组赋值,这个时候就很容易遗忘字符串结束标志'\0'。下面的代码中,我们将 26 个大写英文字符存入字符数组,并以字符串的形式输出:
#include <stdio.h>
int main(){
char str[30];
char c;
int i;
for(c=65,i=0; c<=90; c++,i++){
str[i] = c;
}
printf("%s\n", str);
return 0;
}

在函数内部定义的变量、数组、结构体、共用体等都称为局部数据。在很多编译器下,局部数据的初始值都是随机的、无意义的,而不是我们通常认为的“零”值。本例中的 str 数组在定义完成以后并没有立即初始化,所以它所包含的元素的值都是随机的,只有很小的概率会是“零”值。循环结束以后,str 的前 26 个元素被赋值了,剩下的 4 个元素的值依然是随机的,不知道是什么。
printf() 输出字符串时,会从第 0 个元素开始往后检索,直到遇见'\0'才停止,然后把'\0'前面的字符全部输出,这就是 printf() 输出字符串的原理。本例中我们使用 printf() 输出 str,按理说到了第 26 个元素就能检索到'\0',就到达了字符串的末尾,然而事实却不是这样,由于我们并未对最后 4 个元素赋值,所以第 26 个元素不是'\0',第 27 个也不是,第 28 个也不是……可能到了第 50 个元素才遇到'\0',printf() 把这 50 个字符全部输出出来,就是上面的样子,多出来的字符毫无意义,甚至不能显示。
数组总共才 30 个元素,到了第 50 个元素不早就超出数组范围了吗?是的,的确超出范围了!然而,数组后面依然有其它的数据,printf() 也会将这些数据作为字符串输出。
你看,不注意'\0'的后果有多严重,不但不能正确处理字符串,甚至还会毁坏其它数据。要想避免这些问题也很容易,在字符串的最后手动添加'\0'即可。修改上面的代码,在循环结束后添加'\0':
#include <stdio.h>
int main(){
char str[30];
char c;
int i;
for(c=65,i=0; c<=90; c++,i++){
str[i] = c;
}
str[i] = 0; //此处为添加的代码,也可以写作 str[i] = '\0';根据 ASCII 码表,字符'\0'的编码值就是 0。
printf("%s\n", str);
return 0;
}
如果只初始化部分数组元素,那么剩余的数组元素也会自动初始化为“零”值,所以我们只需要将 str 的第 0 个元素赋值为 0,剩下的元素就都是 0 了。
所谓字符串长度,就是字符串包含了多少个字符(不包括最后的结束符'\0')。例如"abc"的长度是 3,而不是 4。 在C语言中,我们使用string.h头文件中的 strlen() 函数来求字符串的长度,它的用法为:
length strlen(strname);
strname 是字符串的名字,或者字符数组的名字;length 是使用 strlen() 后得到的字符串长度,是一个整数。
#include <stdio.h>
#include <string.h> //记得引入该头文件
int main(){
char str[] = "https://www.baidu.com";
long len = strlen(str);
printf("The lenth of the string is %ld.\n", len);
return 0;
}

在C语言中,有两个函数可以在控制台(显示器)上输出字符串,它们分别是:
- puts():输出字符串并自动换行,该函数只能输出字符串。
- printf():通过格式控制符%s输出字符串,不能自动换行。除了字符串,printf() 还能输出其他类型的数据。
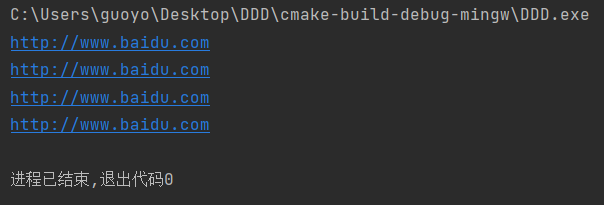
#include <stdio.h>
int main(){
char str[] = "http://www.baidu.com";
printf("%s\n", str); //通过字符串名字输出
printf("%s\n", "http://www.baidu.com"); //直接输出
puts(str); //通过字符串名字输出
puts("http://www.baidu.com"); //直接输出
return 0;
}
注意,输出字符串时只需要给出名字,不能带后边的[ ],例如,下面的两种写法都是错误的:
printf("%s\n", str[]);
puts(str[10]);
在C语言中,有两个函数可以让用户从键盘上输入字符串,它们分别是:
- scanf():通过格式控制符%s输入字符串。除了字符串,scanf() 还能输入其他类型的数据。
- gets():直接输入字符串,并且只能输入字符串。
- scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串。(个人实操:遇到空格应该是当前要读取的字符串结束了,按下回车键应该是当前在控制台的手工输入结束,scanf执行结束,空格之前的作为当前的scanf要读取的字符串,而空格之后的我们多输入的字符串作为这个scanf函数功能的一部分被保存到缓冲区,按下回车键标志着我们结束这个scanf函数的执行,程序逻辑继续执行下一条代码)
- gets() 认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对 gets() 来说就是一个完整的字符串。换句话说,gets() 用来读取一整行字符串。
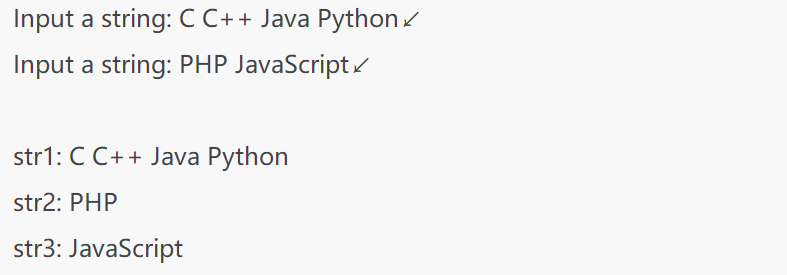
#include <stdio.h>
int main(){
char str1[30] = {0};
char str2[30] = {0};
char str3[30] = {0};
//gets() 用法
printf("Input a string: ");
gets(str1);
//scanf() 用法
printf("Input a string: ");
scanf("%s", str2);
scanf("%s", str3);
printf("\nstr1: %s\n", str1);
printf("str2: %s\n", str2);
printf("str3: %s\n", str3);
return 0;
}
注意,scanf() 在读取数据时需要的是数据的地址,这一点是恒定不变的,所以,
- 对于 int、char、float 等类型的变量都要在前边添加&以获取它们的地址。
- 字符串名字或者数组名字在使用的过程中一般都会转换为地址,所以再添加&就是多此一举,甚至会导致错误了。
以上是 scanf() 和 gets() 的一般用法,很多教材也是这样讲解的,所以大部分初学者都认为 scanf() 不能读取包含空格的字符串,不能替代 gets()。其实不然,scanf() 的用法还可以更加复杂和灵活,它不但可以完全替代 gets() 读取一整行字符串,而且比 gets() 的功能更加强大。比如,以下功能都是 gets() 不具备的:
- scanf() 可以控制读取字符的数目;
- scanf() 可以只读取指定的字符;
- scanf() 可以不读取某些字符;
- scanf() 可以把读取到的字符丢弃。
C语言提供了丰富的字符串处理函数,可以对字符串进行输入、输出、合并、修改、比较、转换、复制、搜索等操作,使用这些现成的函数可以大大减轻我们的编程负担。
- 用于输入输出的字符串函数,例如printf、puts、scanf、gets等,使用时要包含头文件stdio.h,
- 而使用其它字符串函数要包含头文件string.h。string.h是一个专门用来处理字符串的头文件,它包含了很多字符串处理函数,点击这里查阅所有函数。
字符串连接函数 strcat():
strcat 是 string catenate 的缩写,意思是把两个字符串拼接在一起,语法格式为:
strcat(arrayName1, arrayName2);
- strcat() 将把 arrayName2 连接到 arrayName1 后面,并删除原来 arrayName1 最后的结束标志'\0'。这意味着,arrayName1 必须足够长,要能够同时容纳 arrayName1 和 arrayName2,否则会越界(超出范围)。
- strcat() 的返回值为 arrayName1 的地址。
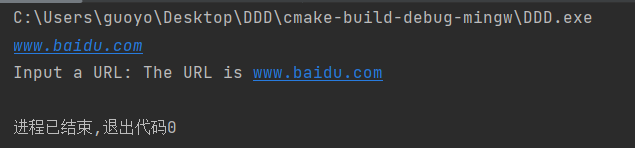
#include <stdio.h>
#include <string.h>
int main(){
char str1[100]="The URL is ";
char str2[60];
printf("Input a URL: ");
gets(str2);
strcat(str1, str2);
puts(str1);
return 0;
}
字符串复制函数 strcpy():
strcpy 是 string copy 的缩写,意思是字符串复制,也即将字符串从一个地方复制到另外一个地方,语法格式为:
strcpy(arrayName1, arrayName2);
strcpy() 会把 arrayName2 中的字符串拷贝到 arrayName1 中,字符串结束标志'\0'也一同拷贝。请看下面的例子:
#include <stdio.h>
#include <string.h>
int main(){
char str1[50] = "雄关漫道真如铁,abcdefghijklmn";
char str2[50] = "www.baidu.com/";
strcpy(str1, str2);
printf("str1: %s\n", str1);
return 0;
}

将 str2 复制到 str1 后,str1 中原来的内容就被覆盖了。 另外,strcat() 要求 arrayName1 要有足够的长度,否则不能全部装入所拷贝的字符串。
字符串比较函数 strcmp():
strcmp 是 string compare 的缩写,意思是字符串比较,语法格式为:
strcmp(arrayName1, arrayName2);
arrayName1 和 arrayName2 是需要比较的两个字符串。
字符本身没有大小之分,strcmp() 以各个字符对应的 ASCII 码值进行比较。strcmp() 从两个字符串的第 0 个字符开始比较,如果它们相等,就继续比较下一个字符,直到遇见不同的字符,或者到字符串的末尾。
返回值:
- 若 arrayName1 和 arrayName2 相同,则返回0;
- 若 arrayName1 大于 arrayName2,则返回大于 0 的值;
- 若 arrayName1 小于 arrayName2,则返回小于0 的值。
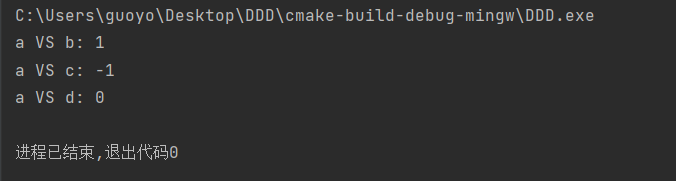
#include <stdio.h>
#include <string.h>
int main(){
char a[] = "aBcDeF";
char b[] = "AbCdEf";
char c[] = "aacdef";
char d[] = "aBcDeF";
printf("a VS b: %d\n", strcmp(a, b));
printf("a VS c: %d\n", strcmp(a, c));
printf("a VS d: %d\n", strcmp(a, d));
return 0;
}
- 插入和删除数组元素都要移动内存,甚至重新开辟一块内存,这是相当消耗资源的。如果一个程序中有大量的此类操作,那么程序的性能将堪忧,这有悖于「C语言非常高效」的初衷,所以C语言并不支持动态数组。
- 另外,很多时候我们需要把数组的地址保存到一个变量里面(等大家学到指针时就会见到这种情况),如果数组重新开辟了内存,而变量里面的地址不跟着改变的话,后续再使用该变量就会导致错误。让C语言本身去维护这些变量的值,以保持同步更新,这又是不可能做到的,所以这个矛盾无法从根本上解决。
总之,为了保证程序执行效率,为了防止操作错误,C语言只支持静态数组,不支持动态数组。
C语言为了提高效率,保证操作的灵活性,并不会对越界行为进行检查,即使越界了,也能够正常编译,只有在运行期间才可能会发生问题。请看下面的代码:
#include <stdio.h>
int main()
{
int a[3] = {10, 20, 30}, i;
for(i=-2; i<=4; i++){
printf("a[%d]=%d\n", i, a[i]);
}
return 0;
}
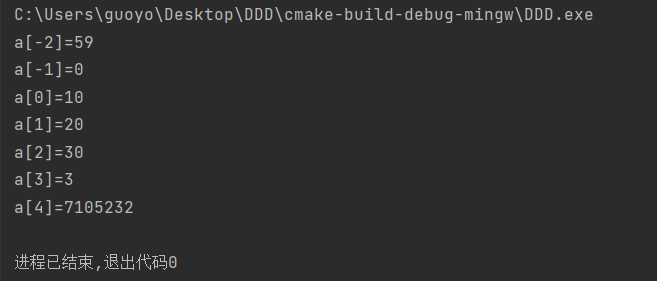
越界访问的数组元素的值都是不确定的,没有实际的含义,因为数组之外的内存我们并不知道是什么,可能是其它变量的值,可能是函数参数,可能是一个地址,这些都是不可控的。
- 由于C语言的”放任“,我们访问数组时必须非常小心,要确保不会发生越界。 当发生数组越界时,如果我们对该内存有使用权限,那么程序将正常运行,但会出现不可控的结果(如上例所示);
- 如果我们对该内存没有使用权限,或者该内存压根就没有被分配,那么程序将会崩溃。
请看下面的例子:
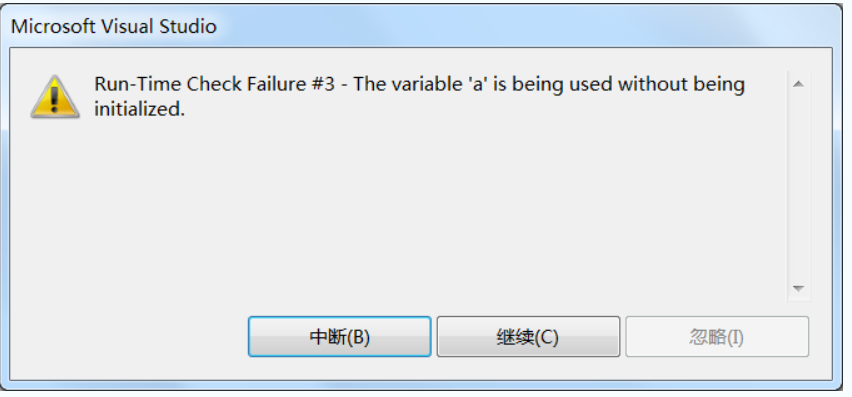
#include <stdio.h>
int main()
{
int a[3];
printf("%d", a[10000]);
return 0;
}
在 VS2010 下运行,会出现运行时错误:
在 C-Free 5.0 下运行,会弹出程序停止工作的对话框:
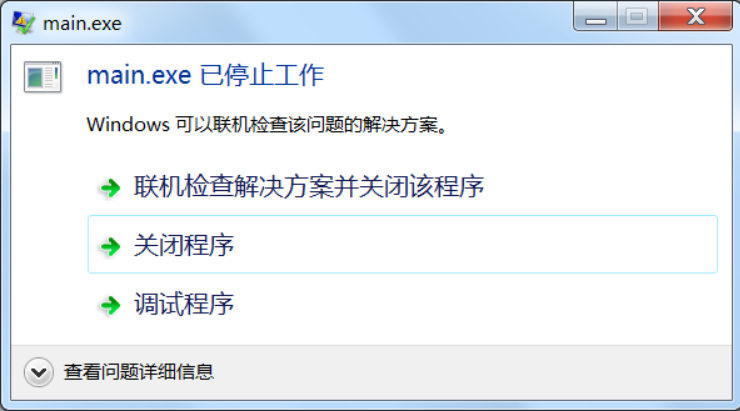
每个程序能使用的内存都是有限的,该程序要访问 4*10000 字节处的内存,显然太远了,超出了程序的访问范围。这个地方的内存可能没有被分配,可能是系统本身占用的内存,可能是其它数据的内存,如果放任这种行为,将带来非常危险的后果,操作系统只能让程序停止运行。
当赋予数组的元素个数超过数组长度时,就会发生溢出(Overflow)。如下所示:
int a[3] = {1, 2, 3, 4, 5};
发现数组溢出时会报错,禁止编译通过。
