

基于RNN的Seq2Seq模型pytorch实战
目录:
Vanilla Seq2Seq理论
引言
Seq2Seq网络即sequence to sequence,序列到序列网络,输入一个序列,输出另一个序列。这个架构重要之处在于,输入序列和输出序列的长度是可变的。 Seq2Seq使用的具体方法基本都属于编码器-解码器架构。 其核心思想是:
- 通过编码器(Encoder)将输入序列编码成一个定长的向量表示,也称为具有上下文信息的表示,简称为上下文(context)。
- 然后将上下文向量喂给解码器(Decoder),来生成任务相关的输出序列。
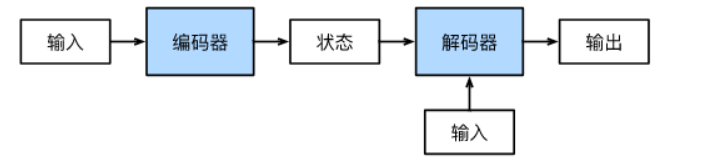
总结一下,编码器-解码器架构包含三个组件:
- 编码器接收一个输入序列,$x^n_1$,然后生成对应的上下文表示,$h^n_1$。常用于编码器的网络可以为RNN、CNN或Transformer等。
- 上下文向量$c$,由一个函数基于$h_1^n$生成,传递输入的核心信息到解码器。
- 解码器接收$c$作为输入,然后生成一个任意长度的隐藏状态序列$h_1^m$,从中可以得到对应的输出$y_1^m$ 。和编码器一样,也有多种实现方案。
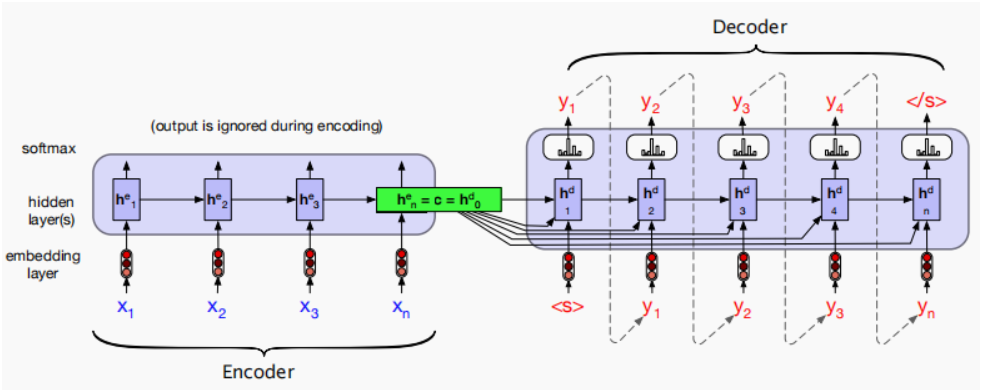
基于RNN实现编码器-解码器
本小节来看如何通过RNN来实现编码器-解码器网络。

实际上会有两个不同的RNN网络,
- 一个作为编码器,将变长的输入序列转换为定长的编码(上下文向量);
- 另一个作为解码器,通过该上下文向量连续生成输出序列,基于输入序列的编码信息和输出序列已经生成的单词来预测下一个单词。
上图演示了如何在机器翻译中使用两个RNN进行序列到序列学习。 这里有两个特殊单词<eos>和<bos>,分别表示序列结束和开始标志。
回顾RNN语言模型计算序列$y$的概率$p(y)$:

即我们先生成输出序列第一个单词$y_1$,然后根据$y_1$生成$y_2$,然后根据$y_1,y_2$生成$y_3$,依此类推,这是典型的自回归(Autoregressive model)模型。自回归模型(英语:Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法,用同一变量例如$x$的之前各期,即$x_1^{t-1}$来预测本期$x_t$的表现,并假设它们为一线性关系。因为这是从线性回归发展而来,不过不用$x$预测$y$,而是用$x$预测$x$(自己)。因此叫做自回归。
g为激活函数(tanh或ReLU),计算时刻$t$的输出和隐藏状态$h_t$的公式为:
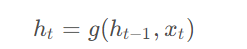
最后,编码器通过特定的函数$q$,将所有时间步的隐藏状态转换为上下文向量$c$:

这里实际上是简单地选择$q(h_1,\cdots,h_t) = h_t$,上下文变量仅仅是输入序列最后时间步的隐状态$h_t$。
而解码器接受$c$作为输入,用于初始化解码器的第一个隐藏状态。即, 第一个解码器RNN单元使用$c$作为初始隐藏状态$ h_0^d$,同时结合本身的输入自回归地生成一系列输出,一次输出一个元素,直到输出了结束符或者达到最大长度限制。每个解码器RNN单元以前一隐藏状态和前一隐藏状态生成的输出作为输入(条件):

但是,这种方法有一个弱点是,随着输出序列的生成,上下文向量c的影响将逐渐减弱。一种常用的解决方法是让解码过程的每个时刻都能看到上下文向量c:

现在,我们看一下解码器的完整公式,每个解码时间步都可看到上下文。g以某种程度上代表RNN,$\hat y_{t-1}$是由上一时刻从softmax生成的输出:
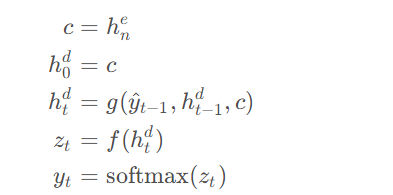
这里f通常为线性层,目的是将$h_t^d$的维度转换到词表大小,以方便通过softmax计算概率分布。
最后,每个时间步的输出$y_t$包含词表中每个单词作为预测单词的概率。我们计算每个时间步最可能的输出,通过:

Vanilla Seq2Seq实现
在上节中了解了Vanilla seq2seq的理论知识,作为实战,本节借助于pytorch,用seq2seq模型来解决机器翻译任务。
首先我们先来导入本文所需要的包:
import torch import torch.nn as nn from torch.utils.data import TensorDataset, DataLoader import math import string import matplotlib.pyplot as plt from tkinter import _flatten from collections import Counter
数据处理
本文使用的数据集是英-法数据集(源语言是英语,目标语言是法语),双语数据集的下载地址:Tab-delimited Bilingual Sentence Pairs。数据集的前十行展示:

数据清洗
为了确认一下这个数据集是以什么分割符分割的,我们先看一下这个数据集的各个的行,
with open('fra.txt', encoding='utf-8') as f:
lines = f.readlines()



可以看到,每一行各个条目(英语,法语,以及以CC-BY的说明信息)都是以"\t为分割符的。
我们需要先清除一些无关的信息,例如以 CC-BY... 开头的字样。首先读入数据并按行分开,
with open('fra.txt', encoding='utf-8') as f:
# 这里稍微多此一举了下,之所以用\t重新连接是为了后面能够更高效地检查字符
content = ['\t'.join(line.strip().split('\t')[:-1]) for line in f.readlines()]
我们看一下处理后的前五行:

为剔除一些无关字符,我们需要查看这个数据集中所有可能的字符种类,

从输出结果可以看出:
- 有一些字符是需要剔除的:\u200b、\xad,
- 还有一些特殊空格:\u2009、\u202f 和 \xa0 需要替换为普通空格。
- 此外,我们还需要将文本全部小写化,
- 以及在单词和标点符号之间插入空格(前提是没有):
def data_cleaning(content):
for i in range(len(content)):
# 剔除无用字符并替换空格
special_chars = ['\u200b', '\xad', '\u2009', '\u202f', '\xa0']
for j, char in enumerate(special_chars):
content[i] = content[i].replace(char, ' ' if j > 1 else '')
content[i] = content[i].lower() # 小写
# 在单词和标点符号之间插入空格
content[i] = ''.join([
' ' + char if j > 0 and char in ',.!?' and content[i][j - 1] != ' ' else char
for j, char in enumerate(content[i])
])
return content
我们打印一下经过处理后的前10条数据:
词元化(分词)
此处我们进行单词级词元化(标点符号也算作一个词元)。
def tokenize(cleaned_content):
# 分别存储源语言和目标语言的词元
src_tokens, tgt_tokens = [], []
for line in cleaned_content:
pair = line.split('\t')
src_tokens.append(pair[0].split(' '))
tgt_tokens.append(pair[1].split(' '))
return src_tokens, tgt_tokens

建立词表
接下来我们需要为两种语言分别建立词表,目的是为了统计词元以及建立词元与索引之间的映射。
class Vocab:
def __init__(self, tokens, min_freq=0):
self.tokens = tokens # 传入的tokens是二维列表
self.min_freq = min_freq # 词元频率低于min_freq时会被视为未知次元:<unk>
self.token2idx = {'<unk>': 0, '<pad>': 1, '<bos>': 2, '<eos>': 3} # 先存好特殊词元
self.token2idx.update({
token: idx + 4
for idx, (token, freq) in enumerate(
sorted(Counter(_flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))
if freq >= self.min_freq
}) # 将统计结果更新到词典中
self.idx2token = {idx: token for token, idx in self.token2idx.items()}
def __getitem__(self, tokens_or_indices):
# 我们需要让Vocab支持正反向查找和序列索引
# 单个索引情形
if isinstance(tokens_or_indices, (str, int)):
# 找不到指定的键值时返回未知词元(索引)
return self.token2idx.get(tokens_or_indices, 0) if isinstance(
tokens_or_indices, str) else self.idx2token.get(tokens_or_indices, '<unk>')
# 多个索引情形
elif isinstance(tokens_or_indices, (list, tuple)):
return [self.__getitem__(item) for item in tokens_or_indices]
else:
raise TypeError
def __len__(self):
return len(self.idx2token)
关于里面用到的_flatten函数,
from tkinter import _flatten lst = [1, 2, [3, [4], [5, 6], 7], 8] print(_flatten(lst))
(1, 2, 3, 4, 5, 6, 7, 8)
假设词元出现次数低于2就丢弃,相应的效果:
src_vocab, tgt_vocab = Vocab(src_tokens, min_freq=2), Vocab(tgt_tokens, min_freq=2)
print(len(src_vocab))
# 11170
print(len(tgt_vocab))
# 19565
print(src_vocab.token2idx) # 仅展示前10行
# {'<unk>': 0,
# '<pad>': 1,
# '<bos>': 2,
# '<eos>': 3,
# '.': 4,
# 'i': 5,
# 'you': 6,
# 'to': 7,
# 'the': 8,
# '?': 9,
print(src_vocab['the'])
# 8
print(src_vocab[['i', 'to', 'the']])
# [5, 7, 8]
print(tgt_vocab[66])
# pense
print(tgt_vocab[[66, 137, 218]])
# ['pense', 'là', 'simplement']
print(src_vocab[[3, 'love', 7]])
# ['<eos>', 146, 'to']
print(src_vocab['aaabbbccc'])
# 0
print(src_vocab[999999999])
# <unk>
截断与填充
我们知道,送给 nn.Embedding 层的数据通常是词元在词表中的索引,并且是批量送入的,形状为 (batch_size, seq_len)。而 src_tokens 中的数据都是以词元的形式存在并且句子不等长,因此我们需要做些处理以让其能够批量加载。 将词元转化为索引非常简单,这里我们需要关注的是如何让句子等长。通常是设定一个长度,超过这个长度的句子进行截断,不到这个长度的句子用 <pad> 进行填充。
def truncate_pad(line, seq_len):
# 该函数针对单个句子进行处理
# 传入的句子是词元形式
return line[:seq_len] if len(line) > seq_len else line + ['<pad>'] * (seq_len - len(line))
接下来,我们需要在 src_tokens 和 tgt_tokens 中的所有句子的末尾添加 <eos> 以代表句子的结束,然后再将它们处理成等长的形式,之后将其中的词元转化为其在词表中的索引,最后以张量的形式返回。 这些操作仅需一行代码即可完成:
def build_data(tokens, vocab, seq_len):
return torch.tensor([vocab[truncate_pad(line + ['<eos>'], seq_len)] for line in tokens])
效果:
src_data = build_data(src_tokens, src_vocab, 10) print(src_data[:8]) # tensor([[ 47, 4, 3, 1, 1, 1, 1, 1, 1, 1], # [ 47, 4, 3, 1, 1, 1, 1, 1, 1, 1], # [ 47, 4, 3, 1, 1, 1, 1, 1, 1, 1], # [2427, 4, 3, 1, 1, 1, 1, 1, 1, 1], # [2427, 4, 3, 1, 1, 1, 1, 1, 1, 1], # [ 426, 114, 3, 1, 1, 1, 1, 1, 1, 1], # [ 426, 114, 3, 1, 1, 1, 1, 1, 1, 1], # [ 426, 114, 3, 1, 1, 1, 1, 1, 1, 1]])
构建数据集
经过计算可知,源语言中句子的最大长度为 51,目标语言中句子的最大长度为 59,我们选择 45 (大约为最大长度的80%∼90%)作为阈值进行截断或填充。 我们使用 TensorDataset 来构建数据集。为充分利用原有数据集不妨设训练集大小为190K,测试集大小为4K,并且两者没有交集。
# 参数设置 TRAIN_SIZE = 190000 TEST_SIZE = 4000 BATCH_SIZE = 512 SEQ_LEN = 45 # 将tokens转化成张量 src_data, tgt_data = build_data(src_tokens, src_vocab, SEQ_LEN), build_data(tgt_tokens, tgt_vocab, SEQ_LEN) # 打乱数据以方便分割 indices = torch.randperm(len(src_data)) # 这样能够保证打乱后,句子是一一对应的关系 src_data, tgt_data = src_data[indices], tgt_data[indices] # 划分出训练集和测试集(总数据量为194513) src_train_data, src_test_data = src_data[:TRAIN_SIZE], src_data[-TEST_SIZE:] tgt_train_data, tgt_test_data = tgt_data[:TRAIN_SIZE], tgt_data[-TEST_SIZE:] train_data = TensorDataset(src_train_data, tgt_train_data) test_data = TensorDataset(src_test_data, tgt_test_data) # 设置DataLoader train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) test_loader = DataLoader(test_data, batch_size=1)
代码中的torch.randperm(n):将0~n-1(包括0和n-1)随机打乱后获得的数字序列,函数名是random permutation缩写
>>>torch.randperm(10) >>>tensor([2, 3, 6, 7, 8, 9, 1, 5, 0, 4])
模型实现
Encoder部分
class Seq2SeqEncoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers, dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.rnn = nn.GRU(emb_size, hidden_size, num_layers=num_layers, dropout=dropout)
def forward(self, encoder_inputs):
# encoder_inputs 的初始形状为 (batch_size, seq_len)
# 形状的变化:(batch_size, seq_len) -> (batch_size, seq_len, emb_size) -> (seq_len, batch_size, emb_size)
encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)
output, h_n = self.rnn(encoder_inputs)
# h_n 的形状为 (num_layers, batch_size, hidden_size)
# 最后一个时刻最后一个隐层的输出的隐状态即为上下文向量,即h_n[-1],其形状为 (batch_size, hidden_size)
return h_n
Decoder部分
- 首先我们需要为 embedding 层指定 padding_idx,这样 <pad> 词元不会对梯度有任何贡献。
- 此外,我们将编码器在最后一个时刻的输出用作解码器的初始隐状态,
- 编码器在最后一个时刻的最后一个隐藏层的输出用作上下文向量,它将和解码器的输入拼接起来作为 RNN 的输入。
class Seq2SeqDecoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers, dropout=0):
super().__init__()
# 务必设置padding_idx
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
# 之所以是emb_size + hidden_size是因为我们在每个时间步需要将当前的输入和编码器输出的上下文向量拼在一起
self.rnn = nn.GRU(emb_size + hidden_size, hidden_size, num_layers=num_layers, dropout=dropout)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, decoder_inputs, encoder_states):
# decoder_inputs 为目标序列偏移一位的结果
# decoder_inputs 的初始形状: (batch_size, seq_len)
# decoder_inputs 形状变化: (batch_size, seq_len) -> (batch_size, seq_len, emb_size) -> (seq_len, batch_size, emb_size)
decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2)
# encoder_states 为编码器在最后一个时刻所有隐藏层的隐状态,最后一个隐层的状态才是我们需要的context
context = encoder_states[-1]
# context 初始形状为 (batch_size, hidden_size),需要复制成 (seq_len, batch_size, hidden_size) 的形状才能连接
context = context.repeat(decoder_inputs.shape[0], 1, 1)
output, h_n = self.rnn(torch.cat((decoder_inputs, context), -1), encoder_states)
# logits 的形状为 (seq_len, batch_size, vocab_size)
logits = self.fc(output)
return logits, h_n
整个encoder-decoder架构
class Seq2SeqModel(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, encoder_inputs, decoder_inputs):
return self.decoder(decoder_inputs, self.encoder(encoder_inputs))
模型训练及预测
训练
在训练阶段,我们不采用上一个时间步的输出作为下一个时间步的输入,而是将目标序列偏移一位作为输入,这被称为 Teacher-forcing。具体而言,设目标序列为(为简便起见不考虑 padding)

我们将其偏移一位并在序列起始处加上 <bos> :

在训练阶段,
- (1)式相当于 target,
- (2)式相当于 input,
- 从而有关系:input = [<bos>] + target[:-1]。
在计算单个序列的损失时,其损失定义为所有词元的平均损失。而一个 batch 的损失定义为所有序列的平均损失。此外还需注意设置 ignore_index 以忽略 <pad> 词元对损失的贡献。
我们采用两个隐藏层的GRU,其中词向量的维度和输出层的神经元个数一样:
LR = 0.001 EPOCHS = 50 device = 'cuda' if torch.cuda.is_available() else 'cpu' encoder = Seq2SeqEncoder(len(src_vocab), len(src_vocab), 256, num_layers=2, dropout=0.1) decoder = Seq2SeqDecoder(len(tgt_vocab), len(tgt_vocab), 256, num_layers=2, dropout=0.1) net = Seq2SeqModel(encoder, decoder) net.to(device) # 注意需要指定ignore_index criterion = nn.CrossEntropyLoss(reduction='none', ignore_index=1) optimizer = torch.optim.Adam(net.parameters(), lr=LR)
接下来定义训练函数,具体请看注释:
def train(train_loader, model, criterion, optimizer, num_epochs):
train_loss = []
model.train()
for epoch in range(num_epochs):
for batch_idx, (encoder_inputs, decoder_targets) in enumerate(train_loader):
encoder_inputs, decoder_targets = encoder_inputs.to(device), decoder_targets.to(device)
# 偏移一位作为decoder的输入
# bos_column:[batch_size,1]
bos_column = torch.tensor([tgt_vocab['<bos>']] * decoder_targets.shape[0]).reshape(-1, 1).to(device)
decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)
# pred的形状为 (seq_len, batch_size, vocab_size)
pred, _ = model(encoder_inputs, decoder_inputs)
# decoder_targets 的形状为 (batch_size, seq_len),我们需要改变pred的形状以保证它能够正确输入
# 至于为什么这样改变,请参考CrossEntropyLoss的官方文档
# all_loss 的形状为 (batch_size, seq_len),其中的每个元素都代表了一个词元的损失
all_loss = criterion(pred.permute(1, 2, 0), decoder_targets)
# 每个序列的损失是其所有词元的损失的平均,每个batch的损失是其所有序列的损失的平均
# 因此等价于每个batch里所有词元的损失的平均
loss = all_loss.mean()
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
# 每隔50个batch输出一次
if (batch_idx + 1) % 50 == 0:
print(
f'[Epoch {epoch + 1}] [{(batch_idx + 1) * len(encoder_inputs)}/{len(train_loader.dataset)}] loss: {loss:.4f}'
)
print()
return train_loss
因为训练时间较久,为节省后续时间,训练结束后我们保存模型的参数(大概有 2GB),然后绘制损失函数的曲线。
train_loss = train(train_loader, net, criterion, optimizer, EPOCHS)
torch.save(net.state_dict(), 'seq2seq_params.pt')
plt.plot(train_loss)
plt.ylabel('train loss')
plt.show()

预测
评估阶段,我们每次只从测试集中抽取一个样本并将其翻译成法语序列,然后采用BLEU 进行评估。
首先定义评估函数,它用来计算测试集中所有样本的 BLEU 得分,还需要将翻译结果保存下来以便后续展示:
def evaluate(test_loader, model):
bleu_scores = []
translation_results = []
model.eval()
# 因为batch_size是1,所以每次取出来的都是单个句子
for src_seq, tgt_seq in test_loader:
encoder_inputs = src_seq.to(device)
h_n = model.encoder(encoder_inputs)
pred_seq = [tgt_vocab['<bos>']]
# 因为训练过程中使用的是长度为SEQ_LEN的序列进行训练,所以预测阶段输出序列的长度不应超过SEQ_LEN,当遇到<eos>时停止输出
for _ in range(SEQ_LEN):
# 因为要一步一步地输出,所以decoder的输入的形状为(batch_size, seq_len)=(1,1)
decoder_inputs = torch.tensor(pred_seq[-1]).reshape(1, 1).to(device)
# pred形状为 (seq_len, batch_size, vocab_size) = (1, 1, vocab_size)
pred, h_n = model.decoder(decoder_inputs, h_n)
next_token_idx = pred.squeeze().argmax().item()
if next_token_idx == tgt_vocab['<eos>']:
break
pred_seq.append(next_token_idx)
# 去掉开头的<bos>
pred_seq = tgt_vocab[pred_seq[1:]]
# 因为tgt_seq的形状为(1, seq_len),我们需要将其转化成(seq_len, )的形状
tgt_seq = tgt_seq.squeeze().tolist()
# 需要注意在<eos>之前截断
if tgt_vocab['<eos>'] in tgt_seq:
eos_idx = tgt_seq.index(tgt_vocab['<eos>'])
tgt_seq = tgt_vocab[tgt_seq[:eos_idx]]
else:
tgt_seq = tgt_vocab[tgt_seq]
translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))
bleu_scores.append(bleu(tgt_seq, pred_seq, k=2))
return bleu_scores, translation_results
导入先前的参数进行评估,将评估结果绘制成柱状图:
net.load_state_dict(torch.load('seq2seq_params.pt'))
bleu_scores = evaluate(test_loader, net)
plt.bar(range(len(bleu_scores)), bleu_scores)
plt.ylabel('BLEU Score')
plt.show()
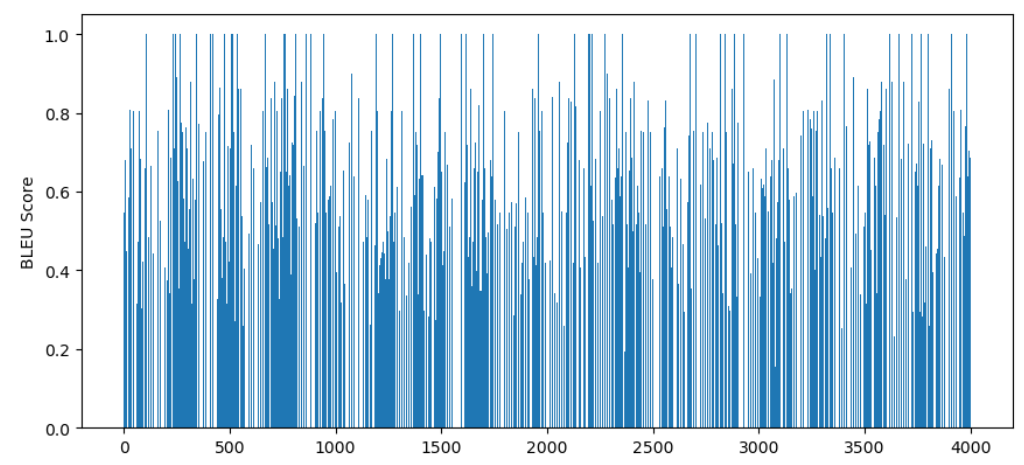
4000 个样本 BLEU 的均值:
print(sum(bleu_scores) / 4000) # 0.4854190351773753
翻译效果部分展示:
import random
for _ in range(10):
tgt, pred = random.choice(translation_results)
print(f'target: {tgt}')
print(f'prediction: {pred}')
print()
target: nous jouions aux chaises musicales à l'école primaire . prediction: nous jouions à vendre de la plage à vendre à l'école . target: il était très bon au tennis . prediction: il était très doué au parc déjeuner . target: je n'ai entendu sonner que trois coups . prediction: je n'ai eu que trois <unk> <unk> . target: reconnaissez-vous l'orge du blé ? prediction: pouvez-vous distinguer le dimanche de l'orge remettre en train de nager ? target: la vie est injuste . <unk> toi . prediction: la vie n'est pas solide que la pluie . target: c'est à toi de décider ce que tu veux faire . prediction: c'est à toi de décider quoi faire . target: il a essayé en vain de m'ouvrir les yeux . prediction: il a essayé de contrôler les yeux dans les yeux <unk> . target: vous pourriez dormir dans le hamac . prediction: vous pourriez dormir dans le hamac . target: ça va faire 30 euros . prediction: ça <unk> coûtera une <unk> . target: ils savaient exactement quel risque elles prendraient . prediction: ils savaient exactement quel risque risque ils prendraient prendraient veulent veulent récupérer .
完整代码
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
import math
import matplotlib.pyplot as plt
from tkinter import _flatten
from collections import Counter
import random
import numpy as np
class Vocab:
def __init__(self, tokens, min_freq=0):
self.tokens = tokens
self.min_freq = min_freq
self.token2idx = {'<unk>': 0, '<pad>': 1, '<bos>': 2, '<eos>': 3}
self.token2idx.update({
token: idx + 4
for idx, (token, freq) in enumerate(
sorted(Counter(_flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))
if freq >= self.min_freq
})
self.idx2token = {idx: token for token, idx in self.token2idx.items()}
def __getitem__(self, tokens_or_indices):
if isinstance(tokens_or_indices, (str, int)):
return self.token2idx.get(tokens_or_indices, 0) if isinstance(
tokens_or_indices, str) else self.idx2token.get(tokens_or_indices, '<unk>')
elif isinstance(tokens_or_indices, (list, tuple)):
return [self.__getitem__(item) for item in tokens_or_indices]
else:
raise TypeError
def __len__(self):
return len(self.idx2token)
def data_cleaning(content):
for i in range(len(content)):
special_chars = ['\u200b', '\xad', '\u2009', '\u202f', '\xa0']
for j, char in enumerate(special_chars):
content[i] = content[i].replace(char, ' ' if j > 1 else '')
content[i] = content[i].lower()
content[i] = ''.join([
' ' + char if j > 0 and char in ',.!?' and content[i][j - 1] != ' ' else char
for j, char in enumerate(content[i])
])
return content
def tokenize(cleaned_content):
src_tokens, tgt_tokens = [], []
for line in cleaned_content:
pair = line.split('\t')
src_tokens.append(pair[0].split(' '))
tgt_tokens.append(pair[1].split(' '))
return src_tokens, tgt_tokens
def truncate_pad(line, seq_len):
return line[:seq_len] if len(line) > seq_len else line + ['<pad>'] * (seq_len - len(line))
def build_data(tokens, vocab, seq_len):
return torch.tensor([vocab[truncate_pad(line + ['<eos>'], seq_len)] for line in tokens])
class Seq2SeqEncoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers, dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.rnn = nn.GRU(emb_size, hidden_size, num_layers=num_layers, dropout=dropout)
def forward(self, encoder_inputs):
encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)
output, h_n = self.rnn(encoder_inputs)
return h_n
class Seq2SeqDecoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers, dropout=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.rnn = nn.GRU(emb_size + hidden_size, hidden_size, num_layers=num_layers, dropout=dropout)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, decoder_inputs, encoder_states):
decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2)
context = encoder_states[-1]
context = context.repeat(decoder_inputs.shape[0], 1, 1)
output, h_n = self.rnn(torch.cat((decoder_inputs, context), -1), encoder_states)
logits = self.fc(output)
return logits, h_n
class Seq2SeqModel(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, encoder_inputs, decoder_inputs):
return self.decoder(decoder_inputs, self.encoder(encoder_inputs))
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def bleu(label, pred, k=4):
score = math.exp(min(0, 1 - len(label) / len(pred)))
for n in range(1, k + 1):
hashtable = Counter([' '.join(label[i:i + n]) for i in range(len(label) - n + 1)])
num_matches = 0
for i in range(len(pred) - n + 1):
ngram = ' '.join(pred[i:i + n])
if ngram in hashtable and hashtable[ngram] > 0:
num_matches += 1
hashtable[ngram] -= 1
score *= math.pow(num_matches / (len(pred) - n + 1), math.pow(0.5, n))
return score
def train(train_loader, model, criterion, optimizer, num_epochs):
train_loss = []
model.train()
for epoch in range(num_epochs):
for batch_idx, (encoder_inputs, decoder_targets) in enumerate(train_loader):
encoder_inputs, decoder_targets = encoder_inputs.to(device), decoder_targets.to(device)
bos_column = torch.tensor([tgt_vocab['<bos>']] * decoder_targets.shape[0]).reshape(-1, 1).to(device)
decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)
pred, _ = model(encoder_inputs, decoder_inputs)
loss = criterion(pred.permute(1, 2, 0), decoder_targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if (batch_idx + 1) % 50 == 0:
print(
f'[Epoch {epoch + 1}] [{(batch_idx + 1) * len(encoder_inputs)}/{len(train_loader.dataset)}] loss: {loss:.4f}'
)
print()
return train_loss
def evaluate(test_loader, model):
bleu_scores = []
translation_results = []
model.eval()
for src_seq, tgt_seq in test_loader:
encoder_inputs = src_seq.to(device)
h_n = model.encoder(encoder_inputs)
pred_seq = [tgt_vocab['<bos>']]
for _ in range(SEQ_LEN):
decoder_inputs = torch.tensor(pred_seq[-1]).reshape(1, 1).to(device)
pred, h_n = model.decoder(decoder_inputs, h_n)
next_token_idx = pred.squeeze().argmax().item()
if next_token_idx == tgt_vocab['<eos>']:
break
pred_seq.append(next_token_idx)
pred_seq = tgt_vocab[pred_seq[1:]]
tgt_seq = tgt_seq.squeeze().tolist()
tgt_seq = tgt_vocab[
tgt_seq[:tgt_seq.index(tgt_vocab['<eos>'])]] if tgt_vocab['<eos>'] in tgt_seq else tgt_vocab[tgt_seq]
translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))
bleu_scores.append(bleu(tgt_seq, pred_seq, k=2))
return bleu_scores, translation_results
# Seed settings (for reproducibility)
setup_seed(42)
# Parameter settings
TRAIN_SIZE = 190000
TEST_SIZE = 4000
BATCH_SIZE = 512
SEQ_LEN = 45
LR = 0.001
EPOCHS = 50
# Read file
with open('fra.txt', encoding='utf-8') as f:
content = ['\t'.join(line.strip().split('\t')[:-1]) for line in f.readlines()]
# Data preprocessing
src_tokens, tgt_tokens = tokenize(data_cleaning(content))
src_vocab, tgt_vocab = Vocab(src_tokens, min_freq=2), Vocab(tgt_tokens, min_freq=2)
src_data, tgt_data = build_data(src_tokens, src_vocab, SEQ_LEN), build_data(tgt_tokens, tgt_vocab, SEQ_LEN)
indices = torch.randperm(len(src_data))
src_data, tgt_data = src_data[indices], tgt_data[indices]
src_train_data, src_test_data = src_data[:TRAIN_SIZE], src_data[-TEST_SIZE:]
tgt_train_data, tgt_test_data = tgt_data[:TRAIN_SIZE], tgt_data[-TEST_SIZE:]
train_data = TensorDataset(src_train_data, tgt_train_data)
test_data = TensorDataset(src_test_data, tgt_test_data)
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1)
# Model building
device = 'cuda' if torch.cuda.is_available() else 'cpu'
encoder = Seq2SeqEncoder(len(src_vocab), len(src_vocab), 256, num_layers=2, dropout=0.1)
decoder = Seq2SeqDecoder(len(tgt_vocab), len(tgt_vocab), 256, num_layers=2, dropout=0.1)
net = Seq2SeqModel(encoder, decoder).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=1)
optimizer = torch.optim.Adam(net.parameters(), lr=LR)
# Training phase
# When training, please comment out the code in the test phase
train_loss = train(train_loader, net, criterion, optimizer, EPOCHS)
torch.save(net.state_dict(), 'seq2seq_params.pt')
plt.plot(train_loss)
plt.ylabel('train loss')
plt.show()
# Test phase
# When training, please comment out the code in the training phase
net.load_state_dict(torch.load('seq2seq_params.pt'))
bleu_scores, translation_results = evaluate(test_loader, net)
plt.bar(range(len(bleu_scores)), bleu_scores)
plt.show()
改进:Attention-based Seq2Seq
上面,我们实现了最普通的seq2seq模型,这里我们将基于注意力机制改进之前的seq2seq模型,其中编码器采用两层双向的LSTM,解码器采用含有注意力机制的两层单向LSTM。

Encoder部分
编码器我们采用两层双向LSTM。编码器的输入形状为$(N,L)$,输出 output 的形状为$(L,N,2h)$,它是正向LSTM和反向LSTM输出进行了concat后的结果,包含了正反向的信息。编码器输出的 h_n 和 c_n的形状均为$(2n,N,h)$,需要将其形状改变为$(n,N,2h)$后才可作为解码器的初始隐状态。
class Seq2SeqEncoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers=2, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.rnn = nn.LSTM(emb_size, hidden_size, num_layers=num_layers, dropout=dropout, bidirectional=True)
def forward(self, encoder_inputs):
encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)
output, (h_n, c_n) = self.rnn(encoder_inputs) # output shape: (seq_len, batch_size, 2 * hidden_size)
h_n = torch.cat((h_n[::2], h_n[1::2]), dim=2) # (num_layers, batch_size, 2 * hidden_size)
c_n = torch.cat((c_n[::2], c_n[1::2]), dim=2) # (num_layers, batch_size, 2 * hidden_size)
return output, h_n, c_n
这里h_n:(num_layers * num_directions, batch, hidden_size),Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size) and similarly for c_n.
AttentionMechanism部分
原先的seq2seq模型中,解码器在每一个时间步所使用的上下文向量均相同。现在我们希望解码器在不同的时间步上能够注意到源序列中不同的信息,因此考虑采用注意力机制。 解码器的核心架构为两层单向的LSTM(只能是单向),在$t$时刻,我们采用解码器在$t−1$ 时刻最后一个隐层的输出作为查询,每个 output[t] 既作为键也作为值,相应的计算上下文向量的公式如下:

其中$α(q,k)$ 是注意力权重。
假设编码器所采用的LSTM的隐层大小为 $h$,解码器所采用的LSTM的隐层大小为 $h'$ 。因 output[t] 的形状为$(N,2h)$,decoder_state[t - 1] 的形状为$ (N,h')$,要使用缩放点积注意力,则必须有$h'=2h$,否则无法进行内积操作,所以可以得出:解码器隐层大小是编码器的两倍。
class AttentionMechanism(nn.Module):
def __init__(self):
super().__init__()
def forward(self, decoder_state, encoder_output):
# 解码器的隐藏层大小必须是编码器的两倍,否则无法进行接下来的内积操作
# decoder_state shape: (batch_size, 2 * hidden_size)
# encoder_output shape: (seq_len, batch_size, 2 * hidden_size)
decoder_state = decoder_state.unsqueeze(1) # (batch_size, 1, 2 * hidden_size)
encoder_output = encoder_output.transpose(0, 1) # (batch_size, seq_len, 2 * hidden_size)
# scores shape: (batch_size, seq_len)
# 两个张量对应元素相乘,在PyTorch中可以通过torch.mul函数(或*运算符)实现;
# 两个张量矩阵相乘,在PyTorch中可以通过torch.matmul函数实现;
scores = torch.sum(decoder_state * encoder_output, dim=-1) / math.sqrt(decoder_state.shape[2]) # 广播机制
# attn_weights shape: (batch_size, seq_len)
attn_weights = F.softmax(scores, dim=-1)
# context shape: (batch_size, 2 * hidden_size)
context = torch.sum(attn_weights.unsqueeze(-1) * encoder_output, dim=1) # 广播机制
return context
Decoder部分
解码器的原始输入的形状为$(N,L)$,通过嵌入以及 permute 操作后其形状变为$(L,N,d)$,而上下文的形状为$(N,2h)$。$(L,N,d)$ 与$(N,2h)$进行concat后才会作为其内部LSTM的输入。因此解码器采用的LSTM的 input_size 为$d+2h$。为了保证注意力机制正常运作,其隐藏层大小也应为编码器的两倍,即$2h$。 从编码器我们得到了形状为 $ (2n,N,h)$的 h_n,而解码器采用的LSTM是单向的,从而其接受的 h_0 的形状应为$ (n,N,2h)$。一个很自然的想法是直接使用 reshape 完成形状的转化,但这样做会带来一个问题,即无法保证 h_0[-1] 对应的是正反向编码器在最后一个时间步最后一个隐层的输出的拼接,为此可考虑采用如下方式解决:

在评估阶段中,我们往往需要利用模型的解码器一步一步地输出,每一时刻都会利用上一时刻解码器输出的隐状态,类似于下面的伪代码:
decoder_output, hidden_state = decoder(decoder_input, hidden_state)
这要求输入到解码器中的隐状态和解码器输出的隐状态的形状必须相同,因此 h_n 和 c_n 的形状转化必须在编码器中完成。
class Seq2SeqDecoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers=2, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.attn = AttentionMechanism()
self.rnn = nn.LSTM(emb_size + 2 * hidden_size, 2 * hidden_size, num_layers=num_layers, dropout=dropout)
self.fc = nn.Linear(2 * hidden_size, vocab_size)
# h_n,c_n形状:[n,batch_size, 2*h]
# encoder_output形状:[seq_len, batch_size, 2*h]
def forward(self, decoder_inputs, encoder_output, h_n, c_n):
decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2) # (seq_len, batch_size, emb_size)
# 注意将其移动到GPU上
decoder_output = torch.zeros(decoder_inputs.shape[0], *h_n.shape[1:]).to(device) # (seq_len, batch_size, 2*h)
#由于我们每个时间步都需要计算这个时间步的上下文向量,而这个上下文向量我们无法在
#这个时间步之前计算出来,所以这里需要一个时间步一个时间步的来进行
for i in range(len(decoder_inputs)):
# h_n[-1]上个时间步最高层的隐藏状态向量
context = self.attn(h_n[-1], encoder_output) # (batch_size, 2*h)
# single_step_output shape: (1, batch_size, 2*h)
single_step_output, (h_n, c_n) = self.rnn(torch.cat((decoder_inputs[i], context), -1).unsqueeze(0), (h_n, c_n))
decoder_output[i] = single_step_output.squeeze()
logits = self.fc(decoder_output) # (seq_len, batch_size, vocab_size)
return logits, h_n, c_n
整个encoder-decoder架构
class Seq2SeqModel(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, encoder_inputs, decoder_inputs):
return self.decoder(decoder_inputs, *self.encoder(encoder_inputs))
模型训练与预测
因为输入输出发生了一些变化,我们只需要对原先的 train 函数和 evaluate 函数稍作修改:
def train(train_loader, model, criterion, optimizer, num_epochs):
train_loss = []
model.train()
for epoch in range(num_epochs):
for batch_idx, (encoder_inputs, decoder_targets) in enumerate(train_loader):
encoder_inputs, decoder_targets = encoder_inputs.to(device), decoder_targets.to(device)
# bos_column shape:[batch_size,1]
bos_column = torch.tensor([tgt_vocab['<bos>']] * decoder_targets.shape[0]).reshape(-1, 1).to(device)
decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)
pred, _, _ = model(encoder_inputs, decoder_inputs)
loss = criterion(pred.permute(1, 2, 0), decoder_targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if (batch_idx + 1) % 50 == 0:
print(
f'[Epoch {epoch + 1}] [{(batch_idx + 1) * len(encoder_inputs)}/{len(train_loader.dataset)}] loss: {loss:.4f}')
print()
return train_loss
def evaluate(test_loader, model, bleu_k):
bleu_scores = []
translation_results = []
model.eval()
for src_seq, tgt_seq in test_loader:#预测时,批的大小为1
encoder_inputs = src_seq.to(device)
encoder_output, h_n, c_n = model.encoder(encoder_inputs)
pred_seq = [tgt_vocab['<bos>']]
for _ in range(SEQ_LEN):
decoder_inputs = torch.tensor(pred_seq[-1]).reshape(1, 1).to(device)
pred, h_n, c_n = model.decoder(decoder_inputs, encoder_output, h_n, c_n)
next_token_idx = pred.squeeze().argmax().item()
if next_token_idx == tgt_vocab['<eos>']:
break
pred_seq.append(next_token_idx)
pred_seq = tgt_vocab[pred_seq[1:]]
tgt_seq = tgt_seq.squeeze().tolist()
tgt_seq = tgt_vocab[tgt_seq[:tgt_seq.index(tgt_vocab['<eos>'])]] if tgt_vocab['<eos>'] in tgt_seq else tgt_vocab[tgt_seq]
translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))
if len(pred_seq) >= bleu_k:
bleu_scores.append(bleu(tgt_seq, pred_seq, k=bleu_k))
return bleu_scores, translation_results
保持其他超参数不变,使用 NVIDIA A40 进行训练(亲测 RTX 3090 会爆掉显存),大概需要6个小时,损失函数曲线如下:

整个代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from data_process import *
from utils.setup import set_seed
from utils.metrics import bleu
import numpy as np
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def bleu(label, pred, k=4):
assert len(pred) >= k
score = math.exp(min(0, 1 - len(label) / len(pred)))
for n in range(1, k + 1):
hashtable = Counter([' '.join(label[i:i + n]) for i in range(len(label) - n + 1)])
num_matches = 0
for i in range(len(pred) - n + 1):
ngram = ' '.join(pred[i:i + n])
if ngram in hashtable and hashtable[ngram] > 0:
num_matches += 1
hashtable[ngram] -= 1
score *= math.pow(num_matches / (len(pred) - n + 1), math.pow(0.5, n))
return score
from collections import Counter
from tkinter import _flatten
class Vocab:
def __init__(self, tokens, min_count=2, special_tokens=['<unk>', '<pad>', '<bos>', '<eos>']):
assert min_count >= 2 and '<unk>' in special_tokens
self.tokens = tokens
self.min_count = min_count
self.token2idx = {token: idx for idx, token in enumerate(special_tokens)}
self.token2idx.update({
token: idx + len(special_tokens)
for idx, (token, count) in enumerate(
sorted(Counter(_flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))
if count >= self.min_count
})
self.idx2token = {idx: token for token, idx in self.token2idx.items()}
def __getitem__(self, tokens_or_indices):
if isinstance(tokens_or_indices, (str, int)):
return self.token2idx.get(tokens_or_indices, self.token2idx['<unk>']) if isinstance(
tokens_or_indices, str) else self.idx2token.get(tokens_or_indices, '<unk>')
elif isinstance(tokens_or_indices, (list, tuple)):
return [self.__getitem__(item) for item in tokens_or_indices]
else:
raise TypeError
def __len__(self):
return len(self.idx2token)
class Seq2SeqEncoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers=2, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.rnn = nn.LSTM(emb_size, hidden_size, num_layers=num_layers, dropout=dropout, bidirectional=True)
def forward(self, encoder_inputs):
encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)
output, (h_n, c_n) = self.rnn(encoder_inputs) # output shape: (seq_len, batch_size, 2 * hidden_size)
h_n = torch.cat((h_n[::2], h_n[1::2]), dim=2) # (num_layers, batch_size, 2 * hidden_size)
c_n = torch.cat((c_n[::2], c_n[1::2]), dim=2) # (num_layers, batch_size, 2 * hidden_size)
return output, h_n, c_n
class AttentionMechanism(nn.Module):
def __init__(self):
super().__init__()
def forward(self, decoder_state, encoder_output):
# decoder_state shape: (batch_size, 2 * hidden_size)
# encoder_output shape: (seq_len, batch_size, 2 * hidden_size)
decoder_state = decoder_state.unsqueeze(1) # (batch_size, 1, 2 * hidden_size)
encoder_output = encoder_output.transpose(0, 1) # (batch_size, seq_len, 2 * hidden_size)
# scores shape: (batch_size, seq_len)
scores = torch.sum(decoder_state * encoder_output, dim=-1) / math.sqrt(decoder_state.shape[2])
attn_weights = F.softmax(scores, dim=-1)
# context shape: (batch_size, 2 * hidden_size)
context = torch.sum(attn_weights.unsqueeze(-1) * encoder_output, dim=1)
return context
class Seq2SeqDecoder(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, num_layers=2, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, emb_size, padding_idx=1)
self.attn = AttentionMechanism()
self.rnn = nn.LSTM(emb_size + 2 * hidden_size, 2 * hidden_size, num_layers=num_layers, dropout=dropout)
self.fc = nn.Linear(2 * hidden_size, vocab_size)
def forward(self, decoder_inputs, encoder_output, h_n, c_n):
decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2) # (seq_len, batch_size, emb_size)
decoder_output = torch.zeros(decoder_inputs.shape[0], *h_n.shape[1:]).to(device) # (seq_len, batch_size, 2 * hidden_size)
for i in range(len(decoder_inputs)):
context = self.attn(h_n[-1], encoder_output) # (batch_size, 2 * hidden_size)
# single_step_output shape: (1, batch_size, 2 * hidden_size)
single_step_output, (h_n, c_n) = self.rnn(torch.cat((decoder_inputs[i], context), -1).unsqueeze(0), (h_n, c_n))
decoder_output[i] = single_step_output.squeeze()
logits = self.fc(decoder_output) # (seq_len, batch_size, vocab_size)
return logits, h_n, c_n
class Seq2SeqModel(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, encoder_inputs, decoder_inputs):
return self.decoder(decoder_inputs, *self.encoder(encoder_inputs))
def train(train_loader, model, criterion, optimizer, num_epochs):
train_loss = []
model.train()
for epoch in range(num_epochs):
for batch_idx, (encoder_inputs, decoder_targets) in enumerate(train_loader):
encoder_inputs, decoder_targets = encoder_inputs.to(device), decoder_targets.to(device)
bos_column = torch.tensor([tgt_vocab['<bos>']] * decoder_targets.shape[0]).reshape(-1, 1).to(device)
decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)
pred, _, _ = model(encoder_inputs, decoder_inputs)
loss = criterion(pred.permute(1, 2, 0), decoder_targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if (batch_idx + 1) % 50 == 0:
print(
f'[Epoch {epoch + 1}] [{(batch_idx + 1) * len(encoder_inputs)}/{len(train_loader.dataset)}] loss: {loss:.4f}')
print()
return train_loss
def evaluate(test_loader, model, bleu_k):
bleu_scores = []
translation_results = []
model.eval()
for src_seq, tgt_seq in test_loader:
encoder_inputs = src_seq.to(device)
encoder_output, h_n, c_n = model.encoder(encoder_inputs)
pred_seq = [tgt_vocab['<bos>']]
for _ in range(SEQ_LEN):
decoder_inputs = torch.tensor(pred_seq[-1]).reshape(1, 1).to(device)
pred, h_n, c_n = model.decoder(decoder_inputs, encoder_output, h_n, c_n)
next_token_idx = pred.squeeze().argmax().item()
if next_token_idx == tgt_vocab['<eos>']:
break
pred_seq.append(next_token_idx)
pred_seq = tgt_vocab[pred_seq[1:]]
tgt_seq = tgt_seq.squeeze().tolist()
tgt_seq = tgt_vocab[tgt_seq[:tgt_seq.index(tgt_vocab['<eos>'])]] if tgt_vocab['<eos>'] in tgt_seq else tgt_vocab[tgt_seq]
translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))
if len(pred_seq) >= bleu_k:
bleu_scores.append(bleu(tgt_seq, pred_seq, k=bleu_k))
return bleu_scores, translation_results
def data_cleaning(content):
for i in range(len(content)):
special_chars = ['\u200b', '\xad', '\u2009', '\u202f', '\xa0']
for j, char in enumerate(special_chars):
content[i] = content[i].replace(char, ' ' if j > 1 else '')
content[i] = content[i].lower()
content[i] = ''.join([
' ' + char if j > 0 and char in ',.!?' and content[i][j - 1] != ' ' else char
for j, char in enumerate(content[i])
])
return content
def tokenize(cleaned_content):
src_tokens, tgt_tokens = [], []
for line in cleaned_content:
pair = line.split('\t')
src_tokens.append(pair[0].split(' '))
tgt_tokens.append(pair[1].split(' '))
return src_tokens, tgt_tokens
def truncate_pad(line, seq_len):
return line[:seq_len] if len(line) > seq_len else line + ['<pad>'] * (seq_len - len(line))
def build_data(tokens, vocab, seq_len):
return torch.tensor([vocab[truncate_pad(line + ['<eos>'], seq_len)] for line in tokens])
# Parameter settings
set_seed()
TRAIN_SIZE = 190000
TEST_SIZE = 4000
SEQ_LEN = 45
# Read file
with open('./data/eng-fra.txt', encoding='utf-8') as f:
content = ['\t'.join(line.strip().split('\t')[:-1]) for line in f.readlines()]
# Get vocabulary
src_tokens, tgt_tokens = tokenize(data_cleaning(content))
src_vocab, tgt_vocab = Vocab(src_tokens), Vocab(tgt_tokens)
# Shuffle data
src_data, tgt_data = build_data(src_tokens, src_vocab, SEQ_LEN), build_data(tgt_tokens, tgt_vocab, SEQ_LEN)
random_indices = torch.randperm(len(src_data))
src_data, tgt_data = src_data[random_indices], tgt_data[random_indices]
# Divide training set and test set
src_train_data, src_test_data = src_data[:TRAIN_SIZE], src_data[-TEST_SIZE:]
tgt_train_data, tgt_test_data = tgt_data[:TRAIN_SIZE], tgt_data[-TEST_SIZE:]
# Build the dataset
train_data = TensorDataset(src_train_data, tgt_train_data)
test_data = TensorDataset(src_test_data, tgt_test_data)
# Parameter settings
set_seed()
BATCH_SIZE = 512
LEARNING_RATE = 0.001
NUM_EPOCHS = 50
# Dataloader
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1)
# Model building
device = 'cuda'
encoder = Seq2SeqEncoder(len(src_vocab), len(src_vocab), 256)
decoder = Seq2SeqDecoder(len(tgt_vocab), len(tgt_vocab), 256)
net = Seq2SeqModel(encoder, decoder).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=1)
optimizer = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE)
# Training phase
train_loss = train(train_loader, net, criterion, optimizer, NUM_EPOCHS)
torch.save(net.state_dict(), './params/attn_seq2seq.pt')
plt.plot(train_loss)
plt.ylabel('train loss')
plt.savefig('./output/loss.png')
# Evaluation
bleu_2_scores, _ = evaluate(test_loader, net, bleu_k=2)
bleu_3_scores, _ = evaluate(test_loader, net, bleu_k=3)
bleu_4_scores, _ = evaluate(test_loader, net, bleu_k=4)
print(f"BLEU-2: {np.mean(bleu_2_scores)} | BLEU-3: {np.mean(bleu_3_scores)} | BLEU-4: {np.mean(bleu_4_scores)}")

