

第5章 C++多态与虚函数总结
这一章,关于多态和虚函数的论述,不太准确,鉴于此,这里使用C++primer第五版中的总结。
15.1 OOP:概述
面向对象程序设计的核心思想是:
- 数据抽象,通过使用数据抽象,我们可以将类的接口与实现分离;
- 继承,使用继承,可以定义相似的类型并对其相似关系建模;(个人:也就是复用)
- 动态绑定,(个人:也就是多态),使用动态绑定,可以在一定程度上忽略相似类型的区别,而以统一的方式使用它们的对象。
在C++语言中,基类将类型相关的函数与派生类不做改变直接继承的函数区分对待。(个人:也就是在基类中,将它里面的函数,这些函数能够被派生类继承,分为了两种类型,一种是普通的不需要修改的,直接被派生类继承,另一种是希望派生类可以定义自己的版本,基类将这类函数声明为虚函数,当然了,如果派生类的定义中没有再次的声明基类中的相同原型的虚函数,则基类的虚函数也被继承下来,作为派生类的虚函数,如果派生类声明了,则派生类里的这个声明,是告诉编译器,我们要override基类的版本,定义自己的版本,这个派生类自己定义的版本一定得有实现)
- 对于某些函数,基类希望它的派生类各自定义适合自身的版本,此时基类就将这些函数声明成虚函数。
- 派生类必须在其内部对所有重新定义的虚函数进行声明。(个人:也就是在C++中,派生类中如果想要override基类的虚函数,定义自己的版本,必须在派生类中再次进行声明,此外,当然要在派生类中声明,否则我们无法定义派生类自己的版本,因为派生类中没有这个函数的声明,我们无法定义一个没有在类的定义中声明过的成员函数
而派生类没有再次声明,则通过继承的基类的虚函数,它的版权归属于基类,已经在基类由它自己定义过了,派生类无权再次定义别人的函数,但是如果在派生类中再次进行声明,情况就不一样了,因为这是个虚函数,就是告诉编译器我要定义属于自己的版本)派生类可以在这样的函数之前加上virtual关键字,但是并不是非得这么做。(个人:如果函数原型写对,加上不加上virtual关键字这个成员函数都是派生类重新定义自己版本的声明;如果函数原型写错,则不加virtual,则这个成员函数是派生类声明的普通成员函数,加上virtual,则这个成员函数是派生类单独声明的自己的虚函数)C++11新标准允许派生类显示地注明它将使用哪个成员函数改写基类的虚函数,具体措施是在函数的形参列表之后增加一个override关键字。(个人:override关键字是告诉编译器,派生类中的这个成员函数一定会覆盖基类中的某个虚函数,这是为了防止如果我们手误,写错了函数原型,则这个成员函数就不符合我们想要覆盖基类的某个虚函数的目的了)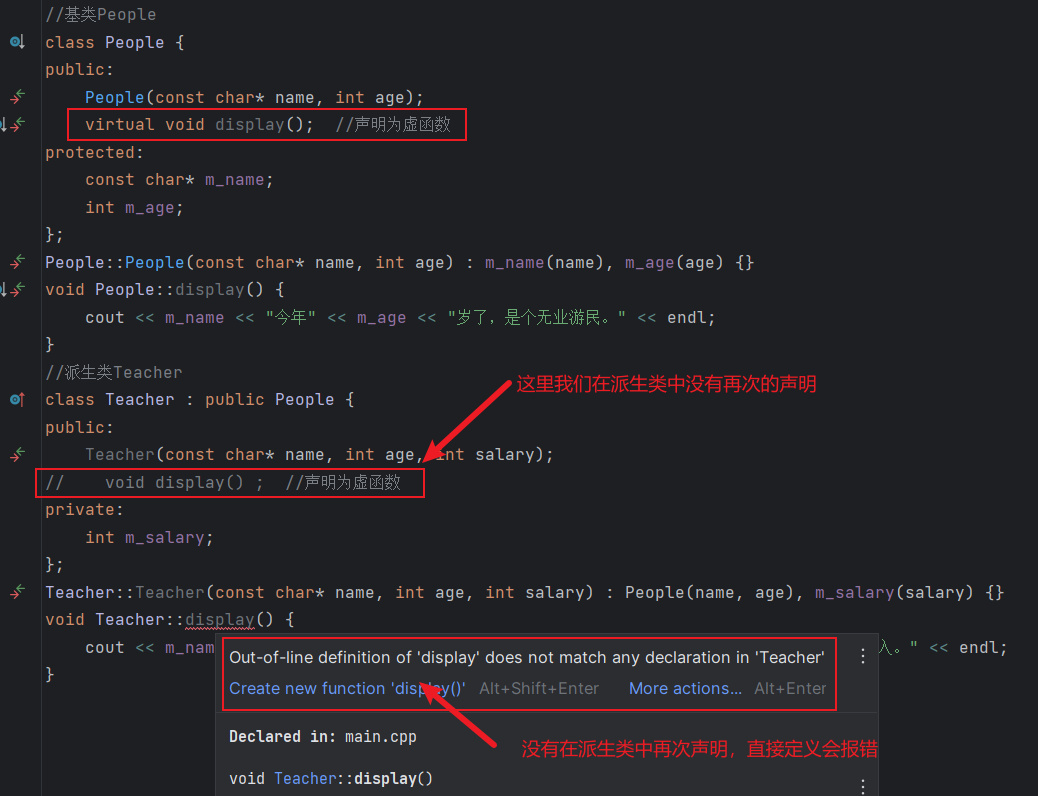
通过使用动态绑定,我们能用同一段代码分别处理Quote和Bulk_quote的对象。(个人:quote报价)
15.2 定义基类和派生类
15.2.1 定义基类
作为继承关系中根节点的类通常都会定义一个虚析构函数。(个人:当然,这是肯定的,因为基类的引用或者指针实际绑定的类型可能是派生类,所以当基类的引用或者指针绑定的对象要销毁时,需要调用析构函数,当然要调用对象的动态实际类型的析构函数,要不然,不调用实现对象的析构函数版本,就无法销毁对象)
基类通常都应该定义一个虚析构函数,即使该函数不执行任何实际操作也是如此。
在C ++中,基类必须将它的两种成员函数区分开来:
- 一种是基类希望其派生类进行覆盖的函数;对于此类函数,基类通常将其定义为虚函数。当我们使用指针或者引用调用虚函数时,该调用将被动态绑定。(个人:也就是是我们对于指针或者引用所调用的成员函数版本的解析放在运行时),根据引用或者指针所绑定的对象类型不同,该调用可能执行基类的版本,也可能执行某个派生类的版本。
- 另一种是基类希望派生类直接继承而不要改变的函数;
============================================================
- 基类通过在其成员函数的声明语句之前加上关键字virtual使得该函数执行动态绑定。(个人:例如,virtual void display(); //声明为虚函数)
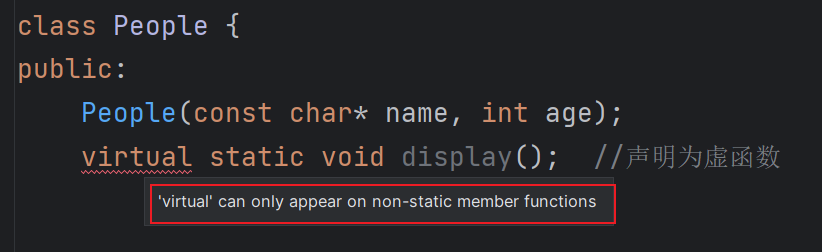
- 任何构造函数之外的非静态函数都可以是虚函数。(个人:显而易见,对于构造函数,每个类都控制的自己成员的初始化,所以构造函数不需要继承,设置为虚函数也完全没有意义;多态是通过基类的指针或者引用来调用成员函数的,这里的基类的指针或者指针要绑定到成员函数的this指针,而对于静态成员函数,它没有this指针)
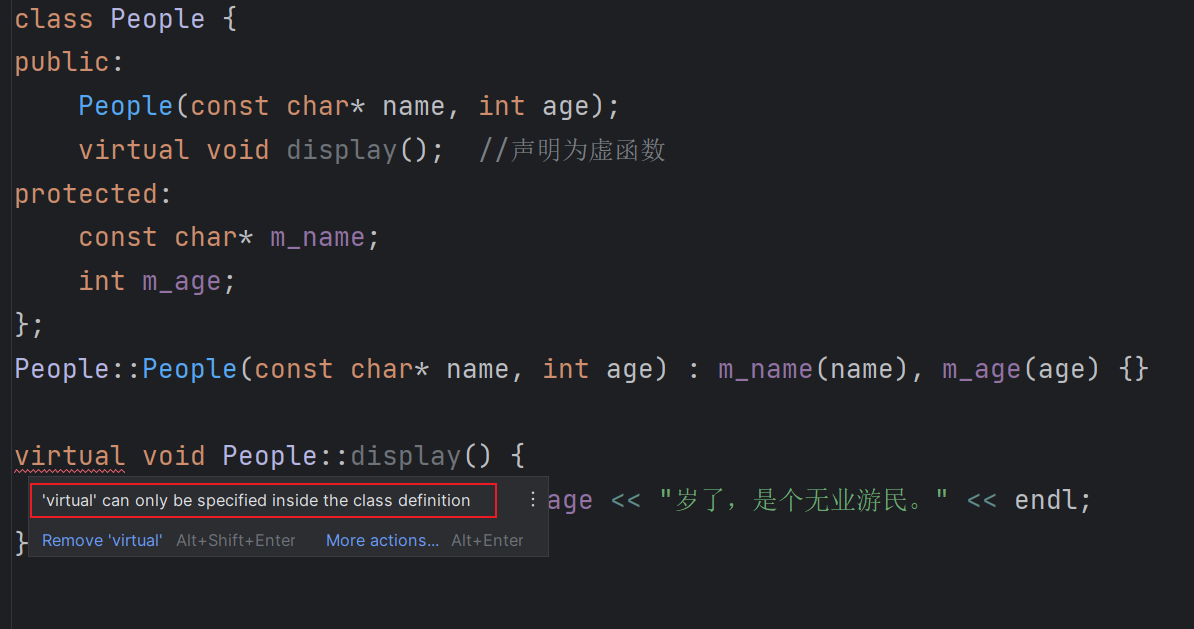
- 关键字virtual只能出现在类内部的声明语句之前而不能用于类外部的函数定义。(个人:在类的定义内部的声明处出现virtual,告诉编译器这个函数可以被派生类override,执行动态绑定,如果出现在类外部的定义处,也就是实现处,没有意义,实现的方式,如何实现根virtual有毛线关系)
- 如果基类把一个函数声明成虚函数,则该函数在派生类中隐式地也是虚函数。(个人:在派生类中可以选择override或者不改写,无论是否override,它在派生类中都隐式地也是虚函数,继续对派生类继承,在派生类的派生类中可以继续定义override的版本)
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455
#include <iostream>usingnamespacestd;//基类PeopleclassPeople {public:People(constchar* name,intage);virtualvoiddisplay();//声明为虚函数protected:constchar* m_name;intm_age;};People::People(constchar* name,intage) : m_name(name), m_age(age) {}voidPeople::display() {cout << m_name <<"今年"<< m_age <<"岁了,是个无业游民。"<< endl;}//派生类TeacherclassTeacher :publicPeople {public:Teacher(constchar* name,intage,intsalary);voiddisplay() ;//声明为虚函数protected:intm_salary;};Teacher::Teacher(constchar* name,intage,intsalary) : People(name, age), m_salary(salary) {}voidTeacher::display() {cout << m_name <<"今年"<< m_age <<"岁了,是一名教师,每月有"<< m_salary <<"元的收入。"<< endl;}//派生类TeacherclassTeacher_derived :publicTeacher {public:Teacher_derived(constchar* name,intage,intsalary,inti);voiddisplay() ;//声明为虚函数private:intexplicit_virtual;};Teacher_derived::Teacher_derived(constchar* name,intage,intsalary,inti) : Teacher(name, age,salary), explicit_virtual(i) {}voidTeacher_derived::display() {cout << m_name <<"今年"<< m_age <<"岁了,是一名Teacher_derived,每月有"<< m_salary <<"元的收入。"<<"隐式虚函数为:"<<explicit_virtual<< endl;}intmain() {// auto temp = People("王志刚", 23);// People* p = &temp;// p->display();autotemp = Teacher_derived("赵宏佳", 45, 8200,1);People & p = temp;p.display();return0;}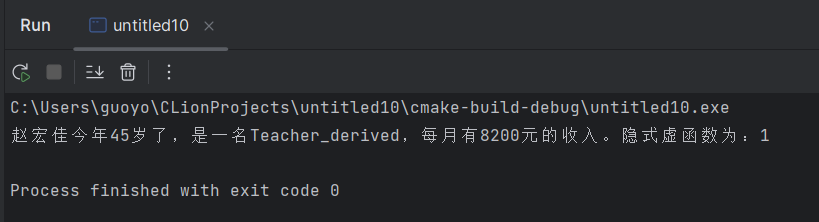
-
成员函数如果没被声明为虚函数,则其解析过程发生在编译时而非运行时。
15.2.2 定义派生类
- 派生类必须将其继承而来的虚成员函数中需要覆盖的那些重新声明。(个人:就是告诉编译器,我要自定义我自己的版本,不重新声明的话,则派生类会继承基类版本的这个虚函数,如果需要重新定义,就得在派生类中重新声明,C++语法中覆盖就是这样用的)
- 派生类经常(但不总是)覆盖它继承的虚函数。如果派生类没有覆盖其基类中的某个虚函数,则该虚函数的行为类似于其他的普通成员,派生类会直接继承其在基类中的版本。(个人:但是这个继承过来的在派生类中还是虚函数,可以继续被派生类的派生类所覆盖)
- 派生类可以在它覆盖的函数前使用virtual关键字,但不是非得这么做。(个人:如果函数原型写错了,加上virtual就是派生类自己声明的新的虚函数,不加就是派生类自己声明的它的新的普通成员函数;如果函数原型写对了,加不加virtual都是声明我们覆盖基类的那个虚函数版本,而不是又搞出一个新的东西,只是对原来的那个的改正)
- C++11新标准允许派生类显示地注明它使用某个成员函数覆盖了它继承的虚函数。集体做法是:在形参列表后面,或者在const成员函数的const关键字后面,或者在引用成员函数的引用限定符后面添加一个关键字override。(个人:无论哪种,override都是在最后面,override的作用就是让编译器替我们做函数原型检查,表明这个成员函数声明一定会覆盖基类的某个虚函数,如果函数原型写错了,编译器会直接报错,不加override时,不会报错,只是当成是派生类又定义的一个新的成员函数,这显然不是我们的代码目的所在)
因为在派生类对象中含有与基类对应的组成部分,所以我们能把派生类的对象当成基类对象来使用,而且我们也能将基类的指针或者引用绑定到派生类对象中的基类部分
(个人:正因为绑定到派生类的基类部分,所以,当多继承时,此时绑定到的基类指针和派生类的地址可能不一致)。
这种转换通常称为派生类到基类的类型转换。和其他类型转换一样,编译器会隐式地执行派生类到基类的转换。这种隐式特性意味着我们可以把派生类对象或者派生类对象的引用用在需要基类引用的地方。同样的,我们也可以把派生类对象的指针用在需要基类指针的地方。在派生类对象中含有与基类对应的组成部分,这一事实是继承的关键所在。
- 尽管在派生类对象中含有从基类继承而来的成员,但是派生类并不能直接初始化这些成员。和其他创建了基类对象的代码一样,派生类也必须使用基类的构造函数来初始化它的基类部分。每个类控制它自己的成员初始化过程。
- 派生类对象的基类部分与派生类对象自己的数据成员都是在构造函数的初始化阶段执行初始化操作的。(个人:构造函数的初始化阶段是在初始化列表那里)
- 类似于我们初始化成员的过程,派生类构造函数同样是通过构造函数初始化列表来将实参传递给基类构造函数的。
- 除非我们特别指出,否则派生类对象的基类部分会像数据成员一样执行默认初始化。如果想使用其他的基类构造函数,我们需要以类名加圆括号内的实参列表的形式为构造函数提供初始值。这些实参将帮助编译器决定到底应该选用哪个构造函数来初始化派生类对象的基类部分。
- 首先初始化基类的部分,然后按照声明的顺序依次初始化派生类的成员。
- 必须明确一点:每个类负责定义各自的接口。要想与类的对象交互必须使用该类的接口,即使这个对象是派生类的基类部分也是如此。因此派生类对象不能直接初始化基类的成员。尽管从语法上来说我们可以在派生类构造函数体内给它的公有或受保护的基类成员赋值,但是最好不要这么做。和使用基类的其他场合一样,派生类应该遵循基类的接口,并且通过调用基类的构造函数来初始化那些从基类中继承而来的成员。
如果基类定义了一个静态成员,则在整个继承体系中只存在该成员的唯一定义。不论从基类中派生出多少个派生类,对于每个静态成员来说都只存在唯一的实例。静态成员遵循通用的访问控制规则,如果基类中的成员是private的,则派生类无权访问它,假设某静态成员是可访问的,则我们既能通过基类使用它也能通过派生类使用它。(个人:也就是如果此静态成员是派生类可访问的,那么派生类可以像这个静态成员是自己的静态成员一样的方式使用它)
- 派生类声明与其他类差别不大,声明中包含类名但是不包含它的派生列表。一条声明语句的目的是令程序知晓某个名字的存在以及该名字表示一个什么样的实体,如一个类,一个函数,一个变量等。(个人:class a;是声明了一个名字a,它的实体是一个类,仅此而已,此时类a可以没有定义,可以是一个不完全定义的类)
- 如果我们想将某个类用作基类,则该类必须已经定义而非仅仅声明。这一规定的原因显而易见:派生类中包含并且可以使用他从基类继承而来的成员,为了使用这些成员,派生类当然要知道他们是什么。因此,该规定还有一隐含的意思,即一个类不能派生它本身。(个人:也就定义派生类时,它的基类必须已经定义,必须是一个完全定义的类,而不能是一个不完全类)
有时我们会定义这样一种类,我们不希望其他类继承他,或者不想考虑他是否适合作为一个基类,为了实现这一目的,C++11新标准提供了一种防止继承发生的办法,即在类名后跟一个关键字final。

15.2.3 类型转换与继承
和内置指针一样,智能指针类也支持派生类向基类的类型转换,这意味着我们可以将一个派生类对象的指针存储在一个基类的智能指针内。
理解基类与派生类之间的类型转换是理解C++语言面向对象编程的关键所在。
- 表达式的静态类型在编译时总是已知的,它是变量声明时的类型或表达式生成的类型,
- 动态类型则是变量或表达式表示的内存中的对象的类型,动态类型直到运行时才可知。
- 如果表达式既不是引用也不是指针,则它的动态类型永远与静态类型一致。
之所以存在派生类到基类的类型转换是因为每个派生类对象都包含一个基类部分,而基类的引用或者指针可以绑定到该基类部分上。
- 一个基类的对象既可以以独立的形式存在,也可以作为派生类的一部分而存在。如果基类对象不是派生类对象的一部分,则它只含有基类定义的成员,而不含有派生类定义的成员。
- 因为一个基类对象可能是派生类的一部分,也可能不是,所以,不存在从基类向派生类的自动类型转换。即使一个基类指针或者引用绑定到一个派生类对象上,我们也不能执行从基类到派生类的转换。
- 编译器在编译时无法确定某个特定的转换在运行时是否安全,这是因为编译器只能通过检查指针或者引用的静态类型来推断该转换是否合法。
- 如果在基类中含有一个或者多个虚函数(个人理解如果不是为了通过虚函数使用多态,如果没有虚函数,则这样的的转换是没有意义的),我们可以使用dynamic_cast请求一个类型转换,该转换的安全检查在运行时执行,(个人:也就是在编译阶段,编译器不检查这个转换的正确性,这个转换的安全性检查推迟到在运行时进行)
- 同样,如果我们已知某个基类向派生类的转换是安全的,则我们可以使用static_cast来强制覆盖掉编译器的检查工作。(个人:因为在编译阶段,编译器只会根据静态类型来判断转换是否合法,如果是派生类指针到基类指针,编译器可以自动转换,但是反转之,则编译器不知道,不会自动转换,会报错,而我们使用static_cast则会在编译阶段强制编译器转换,也就是以前我们使用的()类型转换符,现在在C++里面可以使用static_cast代替,二者都是在编译阶段强制进行转换)
在对象之间不存在类型转换。派生类向基类的自动类型转换只对指针或者应用类型有效,在派生类类型和基类类型之间不存在这样的转换。很多时候,我们确实希望将派生类对象转换成它的基类类型,但是这种转换的实际发生过程往往与我们期望的有所差别。(个人:这里会发生截断,丢弃派生类部分,这里其实发生的是调用的成员函数,例如拷贝构造函数,赋值运算符)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #include <iostream>using namespace std;//基类Peopleclass People {public: People(const char* name, int age); virtual void display(); //声明为虚函数protected: const char* m_name; int m_age;};People::People(const char* name, int age) : m_name(name), m_age(age) {}void People::display() { cout << m_name << "今年" << m_age << "岁了,是个无业游民。" << endl;}//派生类Teacherclass Teacher : public People {public: Teacher(const char* name, int age, int salary); void display()override ; //声明为虚函数protected: int m_salary;};Teacher::Teacher(const char* name, int age, int salary) : People(name, age), m_salary(salary) {}void Teacher::display() { cout << m_name << "今年" << m_age << "岁了,是一名教师,每月有" << m_salary << "元的收入。" << endl;}int main() { auto p = People("王志刚", 23); auto temp = Teacher("赵宏佳", 45, 8200); p = temp; p.display(); return 0;} |

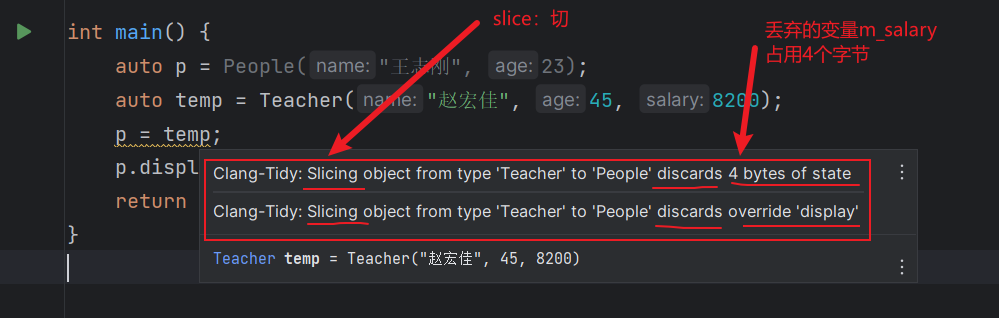
请注意,当我们初始化或者赋值一个类类型的对象时实际上是在调用某个函数。当执行初始化时,我们调用构造函数,而当执行赋值操作时,我们调用赋值运算符,这些成员通常都包含一个参数,该参数的类型是类类型的const版本的引用。因为这些成员接受引用作为参数,所以参数部分派生类向基类引用的转换(个人:派生类绑定到一个基类的引用是允许的,所以这里的参数部分是允许这样绑定的)允许我们给基类的拷贝,移动操作传递一个派生类对象,
这些操作不是虚函数。
- 当我们给基类的构造函数传递一个派生类对象时,实际运行的构造函数是基类中定义的那个,显然该构造函数只能处理基类自己的成员。(个人:因为这些函数不是虚函数,所以只能运行基类的构造函数,基类的构造函数中当然不会去初始化派生类的成员,它也不知道派生类的存在)
- 类似的,如果我们将一个派生类对象赋值给一个基类对象时,实际运行的赋值运算符也是基类中定义的那个,该运算符同样只能处理基类自己的成员。

当我们用一个派生类对象为一个基类对象初始化或者赋值时,只有该派生类对象中的基类部分会被拷贝,移动,赋值,它的派生类部分将被忽略掉。
要想理解在具有继承关系的类之间发生的类型转换,有三点非常重要:
- 从派生类向基类的类型转换只对指针或引用类型有效,(个人:这个转换编译器不需要借助外力)
- 基类向派生类不存在隐式类型转换,
- 和任何其他成员一样,派生类向基类的类型转换也可能会由于访问受限而变得不可行。
尽管自动类型转换只对指针或者引用类型有效,但是继承体系中的大多数类仍然(显式或者隐式地)定义了拷贝控制成员。因此我们通常能够将一个派生类对象拷贝,移动或者赋值给一个基类对象,不过要注意的是,这种操作只处理派生类对象的基类部分。(个人:正是由于这些显示的或者隐式的拷贝控制成员的存在,我们才能将一个派生类对象赋值给一个基类对象,不过不像派生类对象的指针编译器能够自动转化为基类对象的指针,不损失东西,不借助于任何拷贝控制成员函数外力的帮助,这里这种操作只会处理派生类对象的基类部分)
15.3:虚函数
- 通常情况下,如果我们不使用某个函数,则无须为该函数提供定义,
- 但是我们必须为每一个虚函数都提供定义,而不管它是否被用到了,这是因为连编译器也无法确定到底会使用哪个虚函数。因为我们直到运行时才知道到底调用了那个版本的虚函数,所以所有的虚函数都必须有定义。(个人:不定义的话,编译时会报错)
引用或者指针的静态类型与动态类型不同这一事实正是C++语言支持多态性的根本所在。
- 当我们在派生类中覆盖了某个虚函数时,可以再一次使用virtual关键字指出该函数的性质。然而这么做并非必须,因为一旦某个函数被声明成虚函数,则在所有派生类中它都是虚函数。(个人:我们在派生类中的再次声明可以看成是要覆盖的声明,函数还是基类的那个函数)
- 一个派生类中的函数如果覆盖了某个继承而来的虚函数,则它的形参类型必须与被覆盖基类函数完全一致。同样,派生类中的虚函数的返回类型也必须与基类函数匹配。该规则有一个例外,当类的虚函数返回类型是类本身的指针或者引用时,上述规则无效。也就是说,如果D由B派生得到,则基类的虚函数可以返回B*而派生类的对应函数可以返回D*,只不过这样的返回类型要求从 D到B的类型转换是可访问的。
- 基类中的虚函数在派生类中隐含地也是一个虚函数(个人:也就是说,我们在派生类也可以不覆盖这个虚函数,派生类的这个虚函数版本还是它继承自基类的版本,我们可以在派生类的派生类中继续覆盖)。
- 当派生类覆盖了某个虚函数时,该函数在基类中的形参必须与派生类中的形参严格匹配。派生类如果定义了一个函数与基类中虚函数的名字相同但是形参列表不同,这任然是合法的行为。编译器将认为新定义的这个函数与基类中原有的函数是相互独立的。这时派生类的函数并没有覆盖掉基类中的版本。就实际的编程习惯而言,这种声明往往发生了错误,因为我们可能原本希望派生类能覆盖掉基类中的虚函数,但是一不小心把形参列表弄错了。要想调试并发现这样的错误显然非常困难。在C++11新标准中我们可以使用override关键字说明派生类中的虚函数,这么做的好处是在使得程序员的意图更加清晰的同时让编译器可以为我们发现一些错误,后者在编程实践中显得更加重要。如果我们使用override标记了某个函数,但是该函数并没有覆盖已存在的虚函数,此时编译器将报错。我们使用override所表达的意思是我们希望能覆盖基类中的虚函数而实际上并未做到,所以编译器会报错。
- 只有虚函数才能被覆盖。(个人:普通的成员函数名字一样,会发生遮掩)
- 我们还能把某个虚函数函数指定为final(个人:这里的final指定显然是针对虚函数而言的),如果我们已经把函数定义成final了,则之后任何尝试覆盖该函数的操作都将引发错误。final和override说明符出现在形参列表(包括任何const或引用修饰符)以及尾置返回类型之后。


- 虚函数也可以拥有默认实参,如果某次函数调用使用了默认实参,则该实参值由本次调用的静态类型决定。如果虚函数使用默认实参,则基类和派生类中定义的默认实参最好一致。
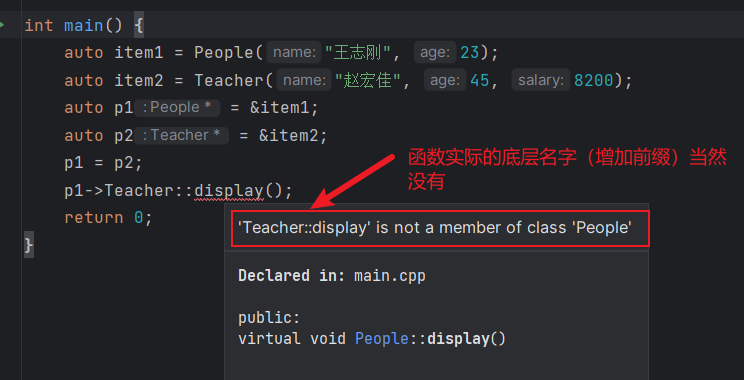
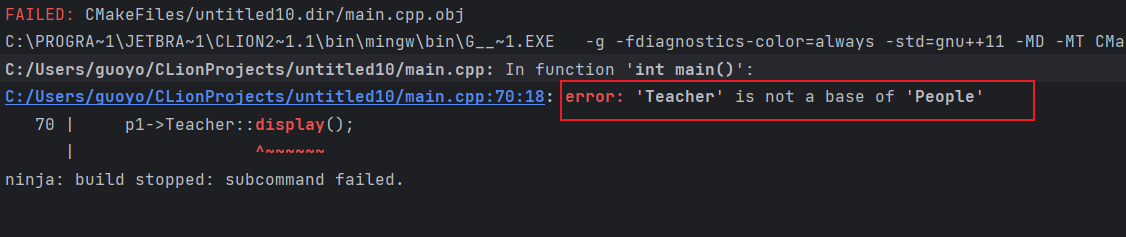
- 在某些情况下,我们希望对虚函数的调用不要进行动态绑定,而是强迫其执行虚函数的某个特定版本。使用作用域运算符可以实现这一目的(个人:使用作用域运算符,可以明确的指出我们使用的是哪个名字,还有一点是,由于这种回避机制,直接明白无误的告诉了编译器使用的名字是哪个版本的,并且该调用是在编译时完成的解析,所以,强制调用的版本得在指针的静态类型所在的类中有定义,要不然会报错,当然,在派生类的成员函数中,派生类对象的this指针是派生类类型的,并且派生类中确实有基类的虚函数版本,只不过被override了,我们只要使用作用域运算符就可调用基类的版本,但是一个基类的指针是无论如何不可能使用作用域运算符调用派生类的覆盖版本的,不过这个基类指针的实际类型是什么,因为静态类型时基类的,但是基类中没有派生类的这个覆盖版本),


15.4:抽象基类
- 和普通的虚函数不一样,一个纯虚函数无须定义。
- 我们通过在函数体的位置(即在声明语句的分号之前)书写=0就可以将一个虚函数说明为纯虚函数。其中,=0只能出现在类内部的虚函数声明处。(个人:一个纯虚函数还是虚函数,继承类照样可以override它进行动态绑定,=0的设置只能对于一个虚函数进行,对于一个普通函数不能这么做),语法格式为:
1
virtual返回值类型 函数名 (函数参数) = 0;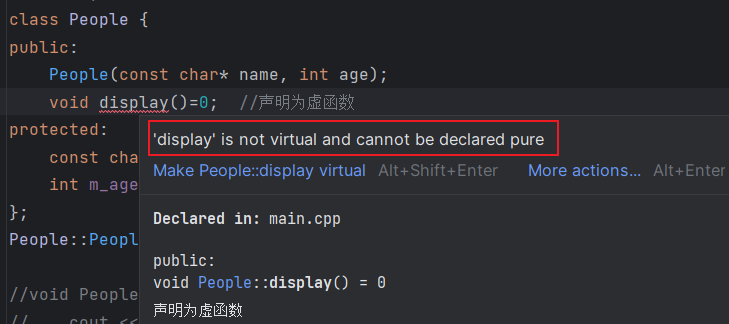
- 值得注意的是,我们也可以为纯虚函数提供定义,不过函数体必须定义在类的外部。也就是说,我们不能在类的内部为一个=0的函数提供函数体。(个人:也就是=0不能出现在函数定义处,好像没有什么用,这样还是不能类实例化)
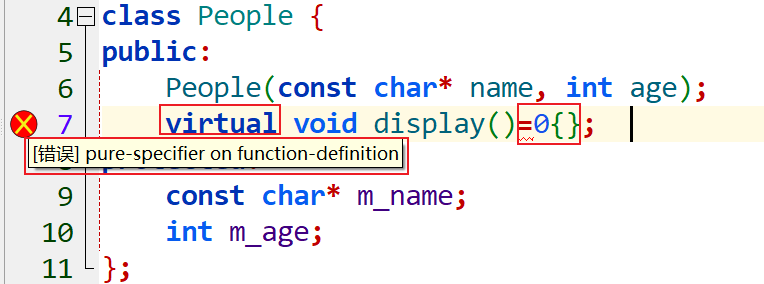
- 含有(或者未经覆盖直接继承)纯虚函数的类是抽象基类。抽象基类负责定义接口,而后续的其他类可以覆盖该接口,我们不能直接创建一个抽象基类的对象。(个人:一个基类声明了纯虚函数,无论这个纯虚函数是否定义,这个基类都是抽象基类,都不能实例化,但是如果它的继承类override了这个纯虚函数,则这个继承类可以实例化)
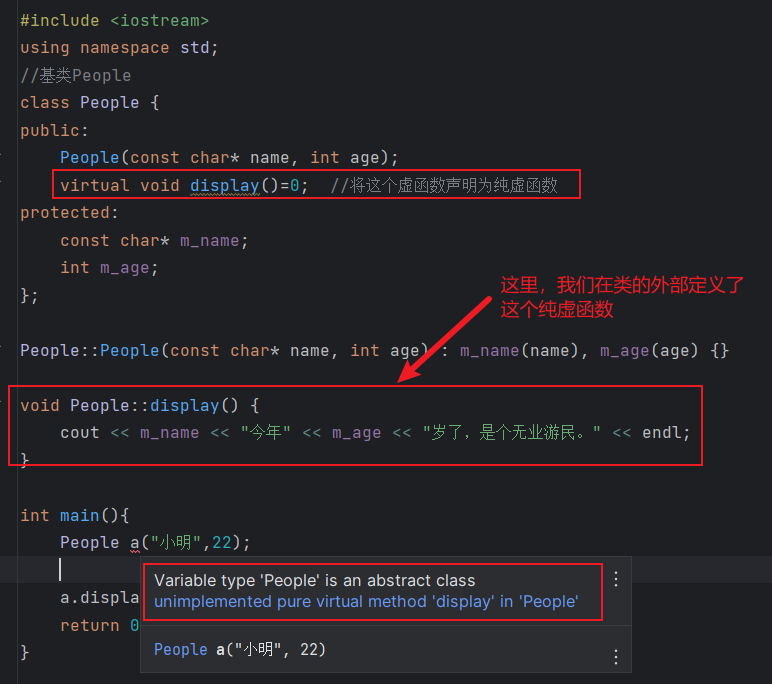
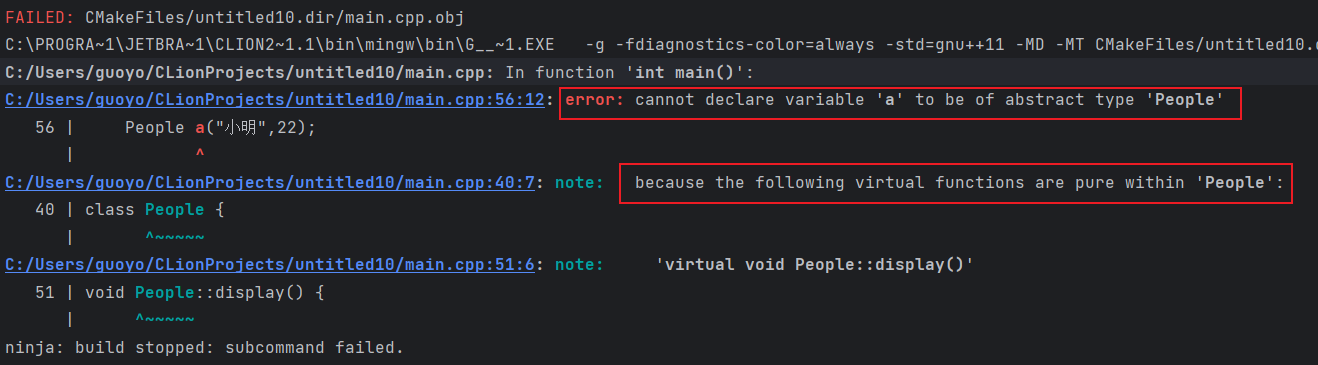
派生类构造函数只能初始化它的直接基类,每个类各自控制其对象的初始化过程。
抽象类通常是作为基类,让派生类去实现纯虚函数。派生类必须实现纯虚函数才能被实例化。
- 在实际开发中,你可以定义一个抽象基类,只完成部分功能,未完成的功能交给派生类去实现(谁派生谁实现)。这部分未完成的功能,往往是基类不需要的,或者在基类中无法实现的。虽然抽象基类没有完成,但是却强制要求派生类完成,这就是抽象基类的“霸王条款”。
- 抽象基类除了约束派生类的功能,还可以实现多态。指针 p 的类型是 Line,但是它却可以访问派生类中的 area() 和 volume() 函数,正是由于在 Line 类中将这两个函数定义为纯虚函数;
关于纯虚函数的几点说明:
- 一个纯虚函数就可以使类成为抽象基类,但是抽象基类中除了包含纯虚函数外,还可以包含其它的成员函数(虚函数或普通函数)和成员变量。
- 只有类中的虚函数才能被声明为纯虚函数,普通成员函数和顶层函数均不能声明为纯虚函数。
1234567
//顶层函数不能被声明为纯虚函数voidfun() = 0;//compile errorclassbase{public://普通成员函数不能被声明为纯虚函数voiddisplay() = 0;//compile error};
C++虚析构函数的必要性
上节我们讲到,构造函数不能是虚函数,
- 因为派生类不能继承基类的构造函数,将构造函数声明为虚函数没有意义。
- 这是原因之一,另外还有一个原因:C++中的构造函数用于在创建对象时进行初始化工作,在执行构造函数之前对象尚未创建完成,虚函数表尚不存在,也没有指向虚函数表的指针,所以此时无法查询虚函数表,也就不知道要调用哪一个构造函数。
析构函数用于在销毁对象时进行清理工作,可以声明为虚函数,而且有时候必须要声明为虚函数。
- 这里的析构函数是非虚函数,通过指针访问非虚函数时,编译器会根据指针的类型来确定要调用的函数;pb是基类的指针,所以不管它指向基类的对象还是派生类的对象,始终都是调用基类的析构函数。pd 是派生类的指针,编译器会根据它的类型匹配到派生类的析构函数,在执行派生类的析构函数的过程中,又会调用基类的析构函数。派生类析构函数始终会调用基类的析构函数,并且这个过程是隐式完成的。
- 将基类的析构函数声明为虚函数后,派生类的析构函数也会自动成为虚函数。这个时候编译器会忽略指针的类型,而根据指针的实际指向来选择函数;也就是说,指针实际指向哪个类的对象就调用哪个类的函数。pb、pd 都指向了派生类的对象,所以会调用派生类的析构函数,继而再调用基类的析构函数。如此一来也就解决了内存泄露的问题。
在实际开发中,一旦我们自己定义了析构函数,就是希望在对象销毁时用它来进行清理工作,比如释放内存、关闭文件等,(个人:也就是如果我们在基类中定义了一个析构函数,那么就是我们有特殊的析构需求,此时继承类也往往需要自己的析构函数版本)
- 如果这个类又是一个基类,那么我们就必须将该析构函数声明为虚函数,否则就有内存泄露的风险。也就是说,大部分情况下都应该将基类的析构函数声明为虚函数。
- 注意,这里强调的是基类,如果一个类是最终的类,那就没必要再声明为虚函数了。(个人:虚函数要维持一个虚函数表,开销比较大,如果一个类是final类,就没有必要了)
C++虚函数表,多态的实现机制
当通过指针访问类的成员函数时:
- 如果该函数是非虚函数,那么编译器会根据指针的类型找到该函数;也就是说,指针是哪个类的类型就调用哪个类的函数。其原理已在《C++函数编译原理和成员函数的实现》中讲到。
- 如果该函数是虚函数,并且派生类有同名的函数遮蔽它,那么编译器会根据指针的指向找到该函数;也就是说,指针指向的对象属于哪个类就调用哪个类的函数。这就是多态。
编译器之所以能通过指针指向的对象找到虚函数,是因为在创建对象时额外地增加了虚函数表。
- 如果一个类包含了虚函数,那么在创建该类的对象时,就会额外地增加一个数组,数组中的每一个元素都是虚函数的入口地址。这里的数组就是虚函数表(Virtual function table),简写为vtable。
- 不过,数组和对象是分开存储的,为了将对象和数组关联起来,编译器还要在对象中安插一个指针,指向数组的起始位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | #include <iostream>#include <string>using namespace std;//People类class People {public: People(string name, int age);public: virtual void display(); virtual void eating();protected: string m_name; int m_age;};People::People(string name, int age) : m_name(name), m_age(age) { }void People::display() { cout << "Class People:" << m_name << "今年" << m_age << "岁了。" << endl;}void People::eating() { cout << "Class People:我正在吃饭,请不要跟我说话..." << endl;}//Student类class Student : public People {public: Student(string name, int age, float score);public: virtual void display(); virtual void examing();protected: float m_score;};Student::Student(string name, int age, float score) : People(name, age), m_score(score) { }void Student::display() { cout << "Class Student:" << m_name << "今年" << m_age << "岁了,考了" << m_score << "分。" << endl;}void Student::examing() { cout << "Class Student:" << m_name << "正在考试,请不要打扰T啊!" << endl;}//Senior类class Senior : public Student {public: Senior(string name, int age, float score, bool hasJob);public: virtual void display(); virtual void partying();private: bool m_hasJob;};Senior::Senior(string name, int age, float score, bool hasJob) : Student(name, age, score), m_hasJob(hasJob) { }void Senior::display() { if (m_hasJob) { cout << "Class Senior:" << m_name << "以" << m_score << "的成绩从大学毕业了,并且顺利找到了工作,Ta今年" << m_age << "岁。" << endl; } else { cout << "Class Senior:" << m_name << "以" << m_score << "的成绩从大学毕业了,不过找工作不顺利,Ta今年" << m_age << "岁。" << endl; }}void Senior::partying() { cout << "Class Senior:快毕业了,大家都在吃散伙饭..." << endl;}int main() { People* p = new People("赵红", 29); p->display(); p = new Student("王刚", 16, 84.5); p->display(); p = new Senior("李智", 22, 92.0, true); p->display(); return 0;} |
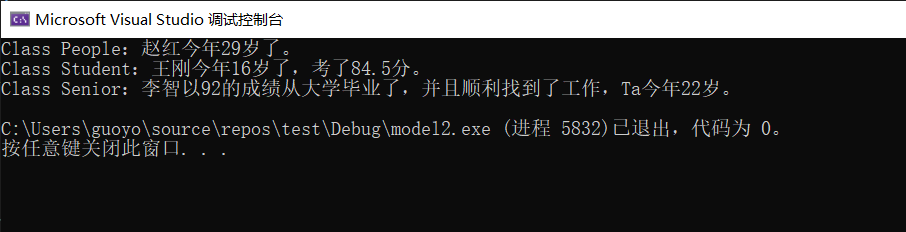
各个类的对象内存模型如下所示:
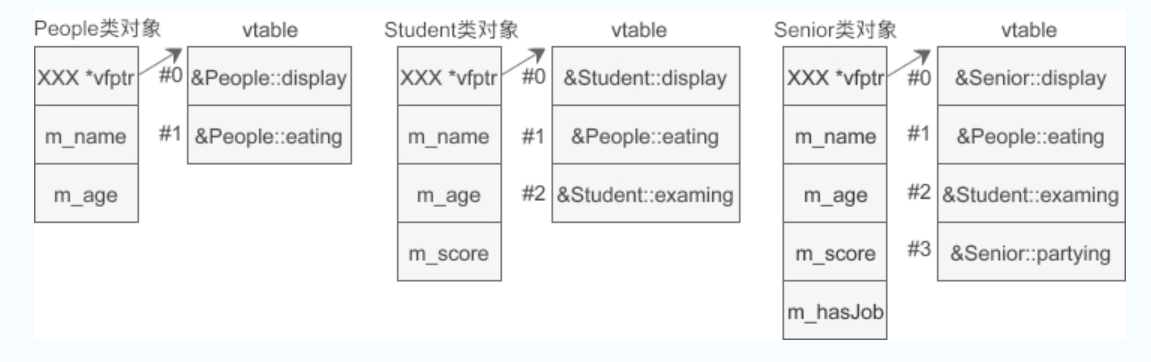
图中左半部分是对象占用的内存,右半部分是虚函数表 vtable。在对象的开头位置有一个指针vfptr,指向虚函数表,并且这个指针始终位于对象的开头位置。
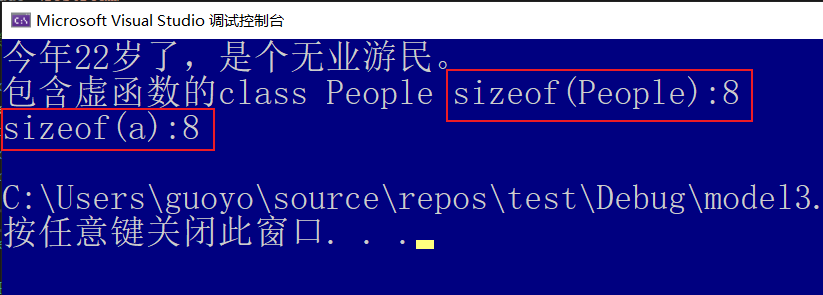
(个人:我们可以打印一下一个包含虚函数的类的对象所占的内存大小)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #include <iostream>using namespace std;//基类Peopleclass People {public: People(int age); virtual void display(); //将这个虚函数声明为纯虚函数protected: int m_age;};People::People(int age) : m_age(age) {}void People::display() { cout << "今年" << m_age << "岁了,是个无业游民。" << endl;}int main() { People a(22); a.display(); cout << "包含虚函数的class People sizeof(People):" << sizeof(People) <<"\nsizeof(a):"<<sizeof(a)<<endl; return 0;} |
仔细观察虚函数表,可以发现
- 基类的虚函数在vtable中的索引(下标)是固定的,不会随着继承层次的增加而改变,(个人:虚函数表中,按照继承层次,先排基类的虚函数,再排派生类的虚函数)
- 派生类新增的虚函数放在vtable的最后。
- 如果派生类有同名的虚函数覆盖了基类的虚函数,那么将使用派生类的虚函数替换基类的虚函数,这样具有override关系的虚函数在vtable中只会出现一次。
当通过指针调用虚函数时,
- 先根据指针找到vfptr,
- 再根据vfptr找到虚函数的入口地址。
以虚函数display() 为例,它在 vtable 中的索引为 0,通过 p 调用时:
1 | p -> display(); |
编译器内部会发生类似下面的转换:
1 | ( *( *(p+0) + 0 ) )(p); |
(个人:这里的转化不对,应该为:(*(XXX **)( int(p)+0) + 0)(p);,这里的XXX为虚函数表vtable中
保存的虚函数类型)
下面我们一步一步来分析这个表达式:(个人:下面经过)
- 0是vfptr在对象中的偏移,int(p)+0是vfptr的地址;(个人:也就是存储这个指针变量的地址)
- *(XXX **)(int(p)+0)是vfptr的值(个人:将这个地址转化为一个指针,然后再取这个指针的值),而vfptr是指向vtable的指针,所以*(XXX **)(int(p)+0)也就是vtable的地址;
- display() 在vtable中的索引(下标)是 0,所以*(XXX **)( int(p)+0) + 0也就是 display() 的地址;
- 知道了display() 的地址,(*(XXX **)( int(p)+0) + 0)(p)也就是对 display() 的调用了,这里的p就是传递的实参,它会赋值给 this 指针。
可以看到,转换后的表达式是固定的,只要调用 display() 函数,不管它是哪个类的,都会使用这个表达式。换句话说,编译器不管 p 指向哪里,一律转换为相同的表达式。
转换后的表达式没有用到与p的类型有关的信息,只要知道 p的指向就可以调用函数,这跟名字编码(Name Mangling)算法有着本质上的区别。
再来看一下 eating() 函数,它在 vtable 中的索引为 1,通过 p 调用时:
1 | p -> eating(); |
编译器内部会发生类似下面的转换:
1 | (*(XXX **)( int(p)+0) + 1)(p); |
对于不同的虚函数,仅仅改变索引(下标)即可。
以上是针对单继承进行的讲解。当存在多继承时,虚函数表的结构就会变得复杂,尤其是有虚继承时,还会增加虚基类表,更加让人抓狂,这里我们就不分析了,有兴趣的读者可以自行研究。
C++ typeid运算符
typeid 运算符用来获取一个表达式的类型信息。类型信息对于编程语言非常重要,它描述了数据的各种属性:
- 对于基本类型(int、float 等C++内置类型)的数据,类型信息所包含的内容比较简单,主要是指数据的类型。
- 对于类类型的数据(也就是对象),类型信息是指:
- 对象所属的类、
- 所包含的成员、
- 所在的继承关系等。
类型信息是创建数据的模板,数据占用多大内存、能进行什么样的操作、该如何操作等,这些都由它的类型信息决定。(个人:例如,对于一个类对象,能够获得这个类对象所属的类定义时的信息)
typeid的操作对象既可以是表达式,也可以是数据类型,下面是它的两种使用方法:
1 2 | typeid( dataType )typeid( expression ) |
dataType是数据类型,expression是表达式,这和sizeof 运算符非常类似,只不过 sizeof 有时候可以省略括号( ),而 typeid必须带上括号。
- typeid 会把获取到的类型信息保存到一个 type_info 类型的对象里面,
- 并返回该对象的常引用;
- 当需要具体的类型信息时,可以通过成员函数来提取。
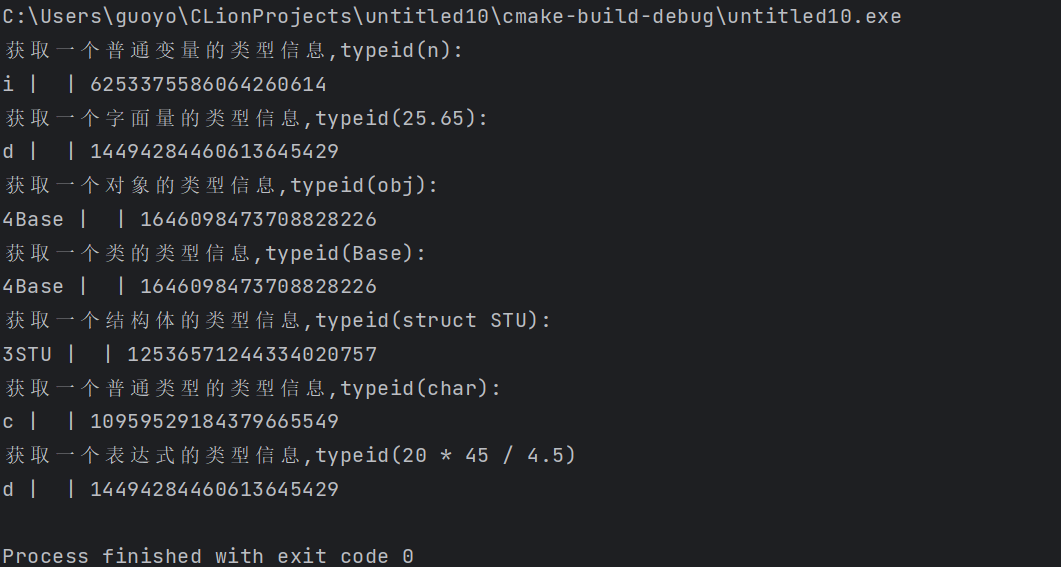
typeid 的使用非常灵活,请看下面的例子(只能在 VC/VS 下运行):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #include <iostream>#include <typeinfo>using namespace std;class Base { };struct STU { };int main() { //获取一个普通变量的类型信息 int n = 100; const type_info& nInfo = typeid(n); cout << "获取一个普通变量的类型信息,typeid(n):" << endl; cout << nInfo.name() << " | " << nInfo.raw_name() << " | " << nInfo.hash_code() << endl; //获取一个字面量的类型信息 const type_info& dInfo = typeid(25.65); cout << "获取一个字面量的类型信息,typeid(25.65):" << endl; cout << dInfo.name() << " | " << dInfo.raw_name() << " | " << dInfo.hash_code() << endl; //获取一个对象的类型信息 Base obj; const type_info& objInfo = typeid(obj); cout << "获取一个对象的类型信息,typeid(obj):" << endl; cout << objInfo.name() << " | " << objInfo.raw_name() << " | " << objInfo.hash_code() << endl; //获取一个类的类型信息 const type_info& baseInfo = typeid(Base); cout << "获取一个类的类型信息,typeid(Base):" << endl; cout << baseInfo.name() << " | " << baseInfo.raw_name() << " | " << baseInfo.hash_code() << endl; //获取一个结构体的类型信息 const type_info& stuInfo = typeid(struct STU); cout << "获取一个结构体的类型信息,typeid(struct STU):" << endl; cout << stuInfo.name() << " | " << stuInfo.raw_name() << " | " << stuInfo.hash_code() << endl; //获取一个普通类型的类型信息 const type_info& charInfo = typeid(char); cout << "获取一个普通类型的类型信息,typeid(char):" << endl; cout << charInfo.name() << " | " << charInfo.raw_name() << " | " << charInfo.hash_code() << endl; //获取一个表达式的类型信息 const type_info& expInfo = typeid(20 * 45 / 4.5); cout << "获取一个表达式的类型信息,typeid(20 * 45 / 4.5)" << endl; cout << expInfo.name() << " | " << expInfo.raw_name() << " | " << expInfo.hash_code() << endl; return 0;} |
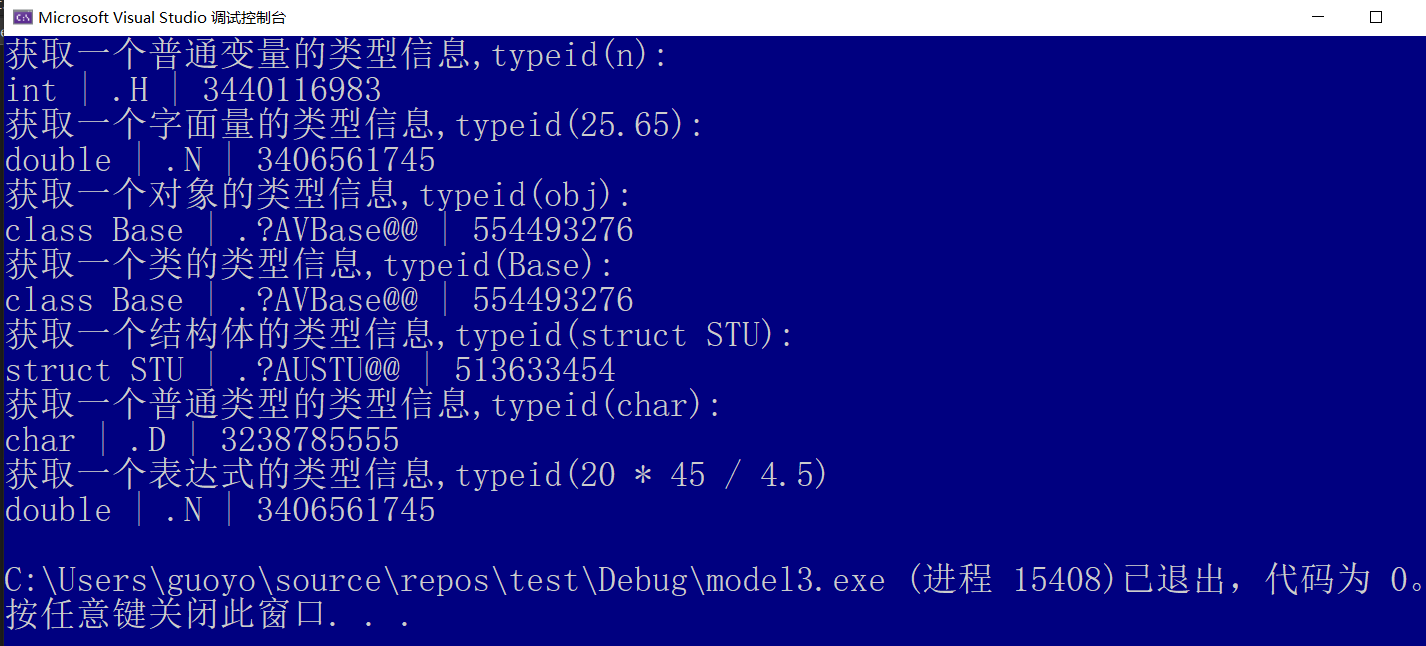
typeid 的使用非常灵活,它的操作数可以是普通变量、对象、内置类型(int、float等)、自定义类型(结构体和类),还可以是一个表达式。
type_info 类的几个成员函数,下面是对它们的介绍:
- name() 用来返回类型的名称。
- raw_name() 用来返回名字编码(Name Mangling)算法产生的新名称。关于名字编码的概念,我们已在《C++函数编译原理和成员函数的实现》中讲到。
- hash_code() 用来返回当前类型对应的hash值。hash 值是一个可以用来标志当前类型的整数,有点类似学生的学号、公民的身份证号、银行卡号等。不过 hash 值有赖于编译器的实现,在不同的编译器下可能会有不同的整数,但它们都能唯一地标识某个类型。
遗憾的是,C++ 标准只对 type_info 类做了很有限的规定,不仅成员函数少,功能弱,而且各个平台的实现不一致。例如上面代码中的 name() 函数,nInfo.name()、objInfo.name()在 VC/VS 下的输出结果分别是int和class Base,而在 GCC 下的输出结果分别是i和4Base。(个人:并且gcc下raw_name()成员函数不存在)
C++ 标准规定,type_info 类至少要有如下所示的 4 个 public 属性的成员函数,其他的扩展函数编译器开发者可以自由发挥,不做限制。
- 原型:
1
constchar* name()const;
返回一个能表示类型名称的字符串。但是C++标准并没有规定这个字符串是什么形式的,例如对于上面的objInfo.name()语句,VC/VS 下返回“class Base”,但 GCC 下返回“4Base”。
- 原型:
1 | bool before (const type_info& rhs) const; |
判断一个类型是否位于另一个类型的前面,rhs 参数是一个 type_info 对象的引用。但是C++标准并没有规定类型的排列顺序,不同的编译器有不同的排列规则,程序员也可以自定义。要特别注意的是,这个排列顺序和继承顺序没有关系,基类并不一定位于派生类的前面。
- 原型:
1 | bool operator== (const type_info& rhs) const; |
重载运算符“==”,判断两个类型是否相同,rhs 参数是一个 type_info 对象的引用。
- 原型:
1 | bool operator!= (const type_info& rhs) const; |
重载运算符“!=”,判断两个类型是否不同,rhs 参数是一个 type_info 对象的引用。
- raw_name() 是 VC/VS 独有的一个成员函数,
- hash_code() 在 VC/VS 和较新的 GCC 下有效。
可以发现,不像 Java、C# 等动态性较强的语言,C++ 能获取到的类型信息非常有限,也没有统一的标准,如同“鸡肋”一般,大部分情况下我们只是使用重载过的“==”运算符来判断两个类型是否相同。
typeid 运算符经常被用来判断两个类型是否相等,
- 内置类型的比较
1 2 3 4 | char *str;int a = 2;int b = 10;float f; |
类型判断结果为:
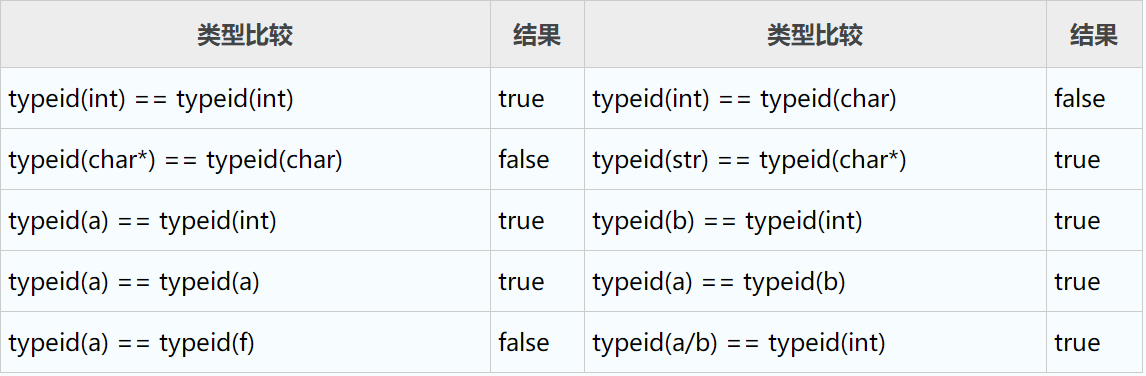
typeid 返回type_info对象的引用,而表达式typeid(a) == typeid(b)的结果为 true,可以说明,一个类型不管使用了多少次,编译器都只为它创建一个对象,所有 typeid 都返回这个对象的引用。
需要提醒的是,为了减小编译后文件的体积,编译器不会为所有的类型创建type_info对象,只会为使用了typeid运算符的类型创建。不过有一种特殊情况,就是带虚函数的类(包括继承来的),不管有没有使用typeid运算符,编译器都会为带虚函数的类创建type_info对象。
- 类的比较
例如有下面的定义:
1 2 3 4 5 6 7 | class Base{};class Derived: public Base{};Base obj1;Base *p1;Derived obj2;Derived *p2 = new Derived;p1 = p2; |
类型判断结果为:
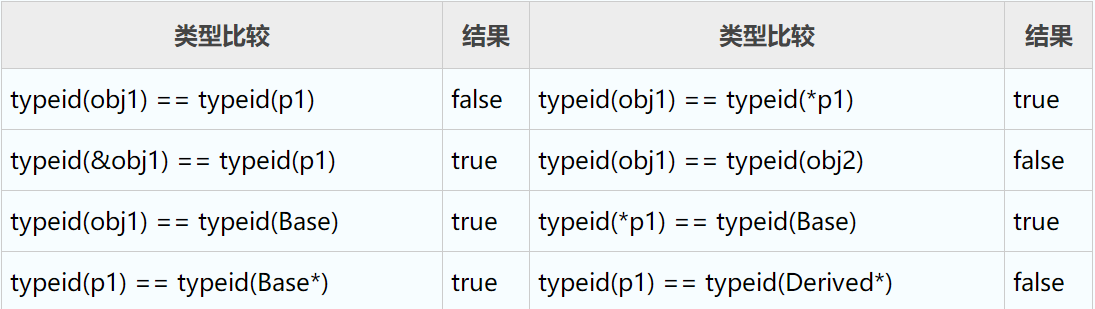
表达式typeid(*p1) == typeid(Base)和typeid(p1) == typeid(Base*)的结果为 true 可以说明:即使将派生类指针 p2 赋值给基类指针 p1,p1 的类型仍然为 Base*。
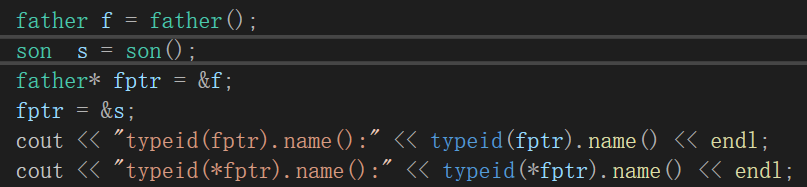

(个人:我们再在类中加入虚函数,)
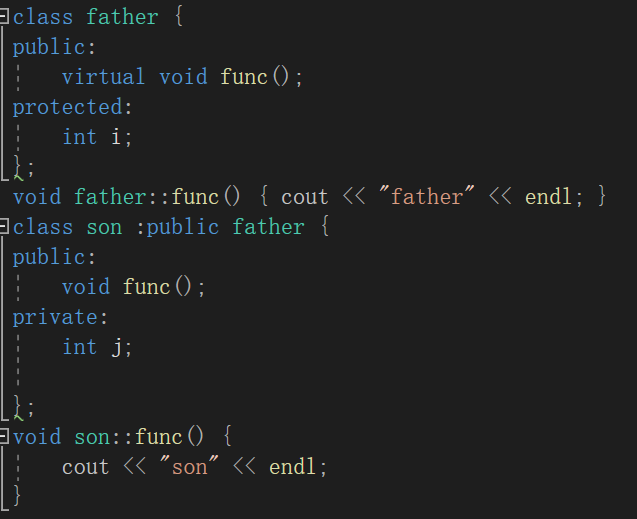
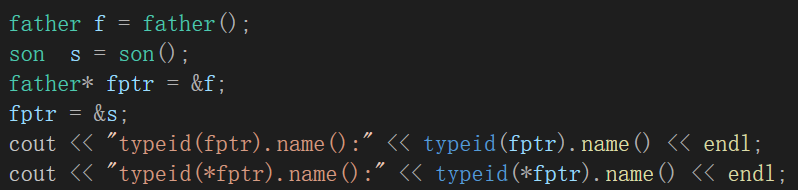

最后我们再来看一下 type_info 类的定义,以进一步了解它所包含的成员函数以及这些函数的访问权限。type_info 类位于typeinfo头文件,定义形式类似于:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | class type_info {public: virtual ~type_info(); int operator==(const type_info& rhs) const; int operator!=(const type_info& rhs) const; int before(const type_info& rhs) const; const char* name() const; const char* raw_name() const;private: void *_m_data; char _m_d_name[1]; type_info(const type_info& rhs); type_info& operator=(const type_info& rhs);}; |
它的构造函数是 private 属性的,所以不能在代码中直接实例化,只能由编译器在内部实例化(借助友元)。而且还重载了“=”运算符,也是 private 属性的,所以也不能赋值。
C++ RTTI机制(C++运行时类型识别)
- 一般情况下,在编译期间就能确定一个表达式的类型,
- 但是当存在多态时,有些表达式的类型在编译期间就无法确定了,必须等到程序运行后根据实际的环境来确定。(个人:这里针对的是一个表达式)
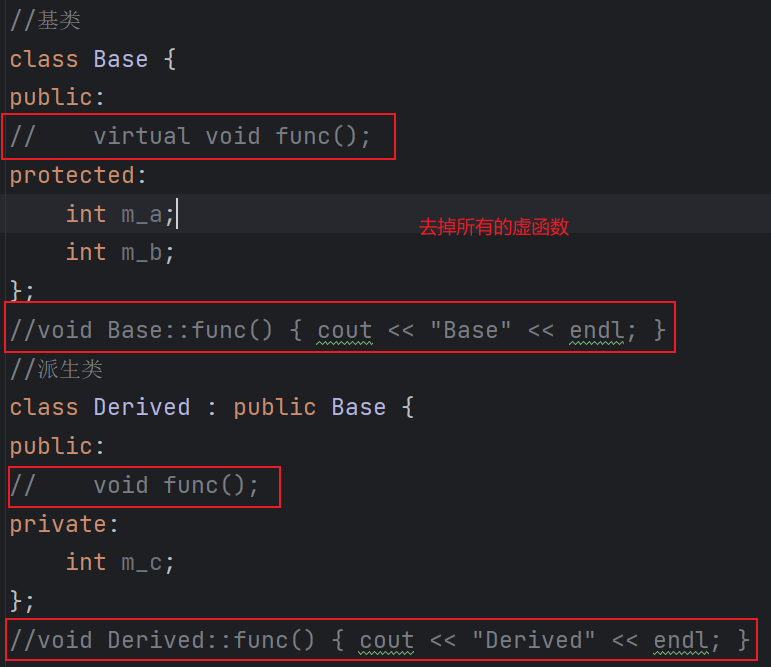
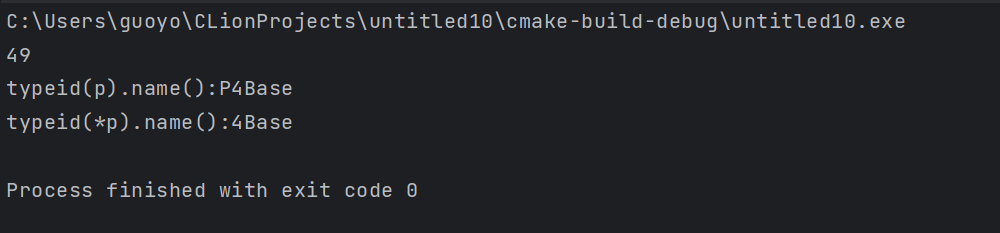
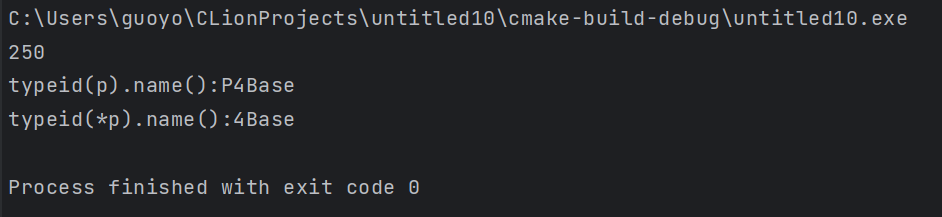
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | #include <iostream>using namespace std;//基类class Base {public: virtual void func();protected: int m_a; int m_b;};void Base::func() { cout << "Base" << endl; }//派生类class Derived : public Base {public: void func();private: int m_c;};void Derived::func() { cout << "Derived" << endl; }int main() { Base* p; int n; cin >> n; if (n <= 100) { p = new Base(); } else { p = new Derived(); } cout << typeid(*p).name() << endl; return 0;} |
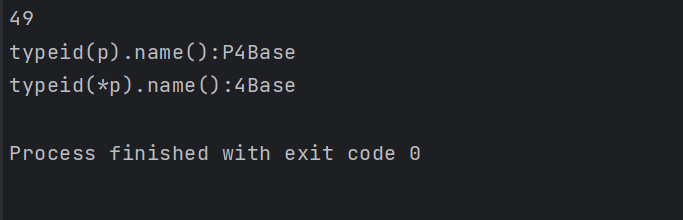
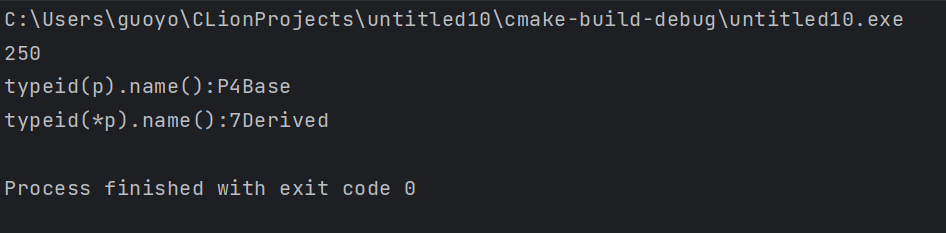
(个人:我们去掉类中的虚函数之后,再看看输出结果)
=======================================================================
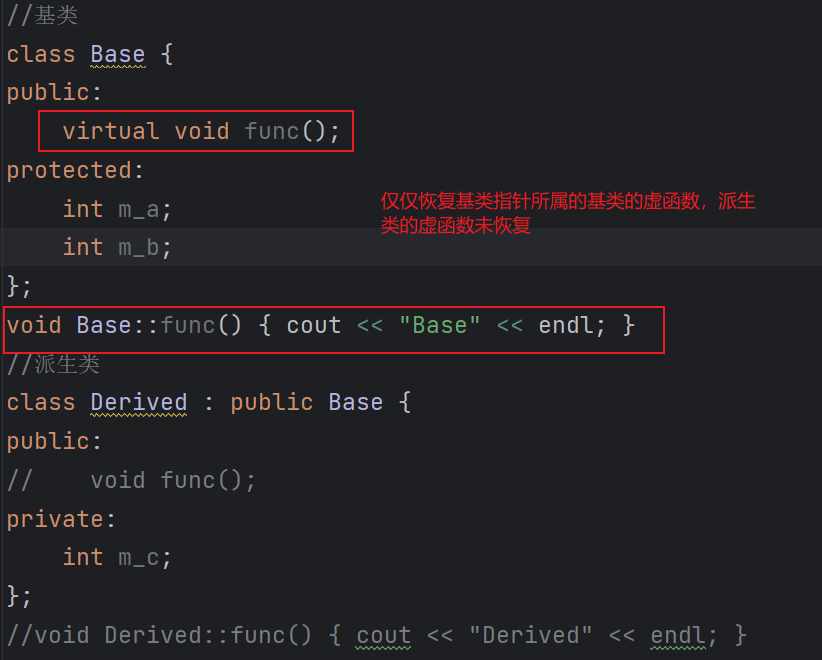
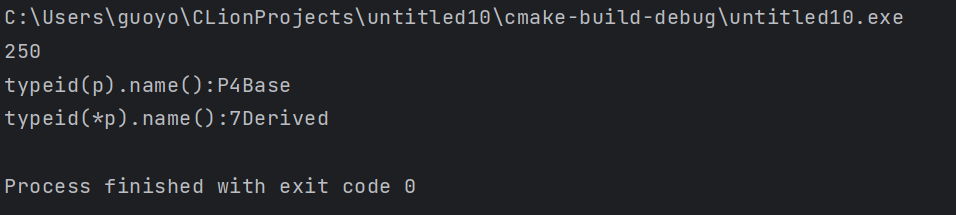
=============================================================
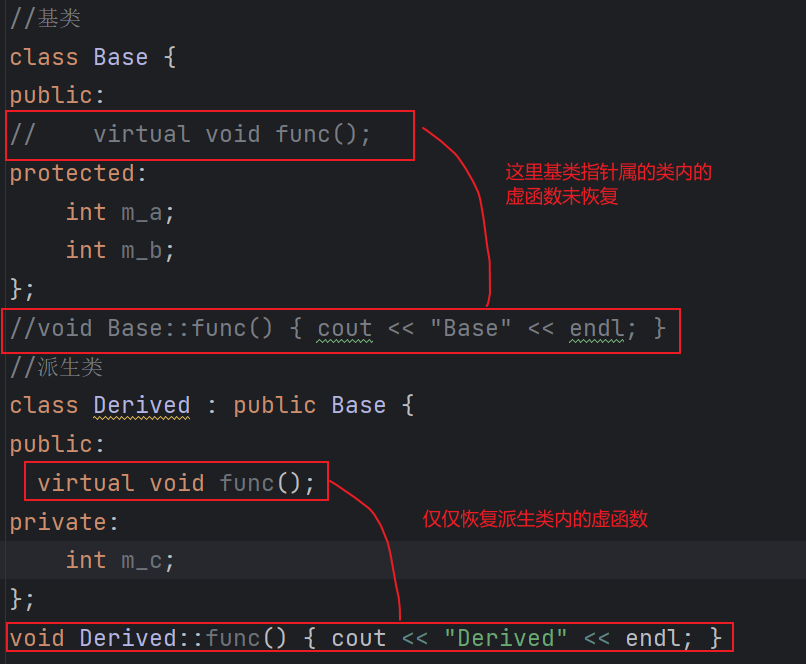
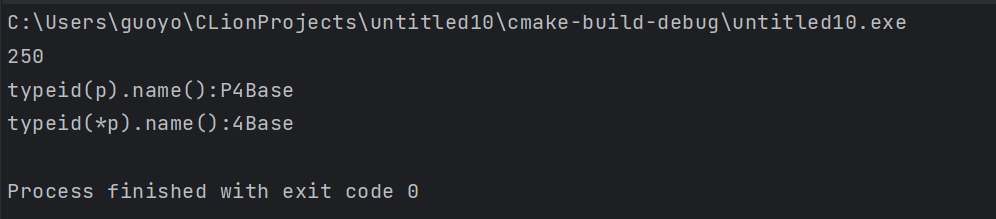
(个人:可见,只要表达式所在的变量的类内有虚函数,涉及到多态,才行)
根据前面讲过的知识,C++ 的对象内存模型主要包含了以下几个方面的内容:
- 如果没有虚函数也没有虚继承,那么对象内存模型中只有成员变量。
- 如果类包含了虚函数,那么会额外添加一个虚函数表,并在对象内存中插入一个指针,指向这个虚函数表。
- 如果类包含了虚继承,那么会额外添加一个虚基类表,并在对象内存中插入一个指针,指向这个虚基类表。
现在我们要补充的一点是,如果类包含了虚函数,那么还会额外增加类型信息,也即 type_info 对象。以上面的代码为例,Base 和 Derived 的对象内存模型如下图所示:
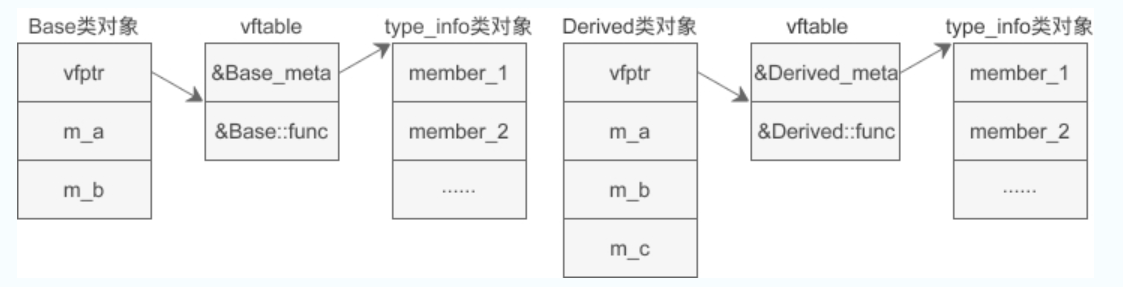
编译器会在虚函数表vftable的开头插入一个指针,指向当前类对应的type_info对象。当程序在运行阶段获取类型信息时,可以通过对象指针p找到虚函数表指针 vfptr,再通过vfptr找到type_info对象的指针,进而取得类型信息。
下面的代码演示了这种转换过程:(个人:这里演示了*p的转换过程,对于typeid(p),只有一个p,p的类型是确定的,是基类指针,只是这个基类指针可以指向派生类对象,是说这个基类指针可以指向派生类,没说实际是一个派生类指针指向派生类对象,没有这个转化过程)
1 | **(p->vfptr - 1) |
注(个人): vfptr指向vftable的第二个元素,即虚函数开始处,vfptr-1即得vftable的第一个元素的地址,
程序运行后,不管 p 指向 Base 类对象还是指向 Derived 类对象,只要执行这条语句就可以取得 type_info 对象。
编译器在编译阶段无法确定p指向哪个对象,也就无法获取*p的类型信息,但是编译器可以在编译阶段做好各种准备,这样程序在运行后可以借助这些准备好的数据来获取类型信息。这些准备包括:
- 创建 type_info 对象,并在 vftable 的开头插入一个指针,指向 type_info 对象。
- 将获取类型信息的操作转换成类似**(p->vfptr - 1)这样的语句。
这样做虽然会占用更多的内存,效率也降低了,但这是没办法的事情,编译器实在是无能为力了。
这种在程序运行后确定对象的类型信息的机制称为运行时类型识别(Run-Time Type Identification,RTTI)。
在 C++ 中,只有类中包含了虚函数时才会启用 RTTI 机制,其他所有情况都可以在编译阶段确定类型信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream>using namespace std;//基类class People {public: virtual void func() { }};//派生类class Student : public People { };int main() { People* p; int n; cin >> n; if (n <= 100) { p = new People(); } else { p = new Student(); } //根据不同的类型进行不同的操作 if (typeid(*p) == typeid(People)) { cout << "I am human." << endl; } else { cout << "I am a student." << endl; } return 0;} |
多态(Polymorphism)是面向对象编程的一个重要特征,它极大地增加了程序的灵活性,C++、C#、Java 等“正统的”面向对象编程语言都支持多态。但是支持多态的代价也是很大的,有些信息在编译阶段无法确定下来,必须提前做好充足的准备,让程序运行后再执行一段代码获取,这会消耗更多的内存和 CPU 资源。
C++静态绑定和动态绑定,彻底理解多态
CPU 访问内存时需要的是地址,而不是变量名和函数名!变量名和函数名只是地址的一种助记符,当源文件被编译和链接成可执行程序后,它们都会被替换成地址。编译和链接过程的一项重要任务就是找到这些名称所对应的地址。
假设变量 a、b、c 在内存中的地址分别是 0X1000、0X2000、0X3000,那么加法运算c = a + b;将会被转换成类似下面的形式:
1 | 0X3000 = (0X1000) + (0X2000); |
( )表示取值操作,整个表达式的意思是,取出地址 0X1000 和 0X2000 上的值,将它们相加,把相加的结果赋值给地址为 0X3000 的内存。
变量名和函数名为我们提供了方便,让我们在编写代码的过程中可以使用易于阅读和理解的英文字符串,不用直接面对二进制地址,那场景简直让人崩溃。
我们不妨将变量名和函数名统称为符号(Symbol),找到符号对应的地址的过程叫做符号绑定。本节只讨论函数名和地址的绑定,变量名也是类似的道理。
我们知道,函数调用实际上是执行函数体中的代码。函数体是内存中的一个代码段,函数名就表示该代码段的首地址,函数执行时就从这里开始。说得简单一点,就是必须要知道函数的入口地址,才能成功调用函数。找到函数名对应的地址,然后将函数调用处用该地址替换,这称为函数绑定。
- 一般情况下,在编译期间(包括链接期间)就能找到函数名对应的地址,完成函数的绑定,程序运行后直接使用这个地址即可。这称为静态绑定(Static binding)。
- 但是,有时候在编译期间想尽所有办法都不能确定使用哪个函数,必须要等到程序运行后根据具体的环境或者用户操作才能决定。这称为动态绑定(dynamic binding)。
C++ 是一门静态性的语言,会尽力在编译期间找到函数的地址,以提高程序的运行效率,但是有时候实在没办法,只能等到程序运行后再执行一段代码(很少的代码)才能找到函数的地址。
上节我们讲到,通过p -> display();语句调用 display() 函数时会转换为下面的表达式:
1 | ( *( *(p+0) + 0 ) )(p); |
这里的 p 有可能指向 People 类的对象,也可能指向 Student 或 Senior 类的对象,编译器不能提前假设p指向哪个对象,也就不能确定调用哪个函数,所以编译器干脆不管了,p 爱指向哪个对象就指向哪个对象,等到程序运行后执行一下这个表达式自然就知道了。
有读者可能会问,对于下面的语句:
1 2 | p = new Senior("李智", 22, 92.0, true);p -> display(); |
p 不是已经确定了指向 Senior 类的对象吗,难道编译器不知道吗?对,编译器编译到第二条语句的时候如果向前逆推一下,确实能够知道 p 指向 Senior 类的对象。但是,如果是下面的情况呢?
1 2 3 4 5 6 7 8 | int n;cin>>n;if(n > 100){ p = new Student("王刚", 16, 84.5);}else{ p = new Senior("李智", 22, 92.0, true);}p -> display(); |
如果用户输入的数字大于 100,那么 p 指向 Student 类的对象,否则就指向 Senior 类的对象,这种情况编译器如何逆推呢?鬼知道用户输入什么数字!所以编译器干脆不会向前逆推,因为编译器不知道前方是什么情况,可能会很复杂,它也无能为力。
这就是动态绑定的本质:编译器在编译期间不能确定指针指向哪个对象,只能等到程序运行后根据具体的情况再决定。
C++ RTTI机制下的对象内存模型
上节所示的 Base 和 Derived 的对象内存模型非常简单,读者也很容易理解,它满足了 typeid 运算符在程序运行期间动态地获取表达式的类型信息的需求。在 C++ 中,除了 typeid 运算符,dynamic_cast 运算符和异常处理也依赖于 RTTI 机制,并且要能够通过派生类获取基类的信息,或者说要能够判断一个类是否是另一个类的基类,这样上节讲到的内存模型就不够用了,我们必须要在基类和派生类之间再增加一条绳索,把它们连接起来,形成一条通路,让程序在各个对象之间游走。在面向对象的编程语言中,我们称此为继承链(Inheritance Chain)。
然而考虑到多继承、降低内存使用等诸多方面的因素,真正的对象内存模型比上节讲到的要复杂很多,并且不同的编译器有不同的实现,C++标准并没有对对象内存模型的细节做出规定。 我们以下面的代码为例来展示 Visual C++ 下真正的对象内存模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | class A{protected: int a1;public: virtual int A_virt1(); virtual int A_virt2(); static void A_static1(); void A_simple1();};class B{protected: int b1; int b2;public: virtual int B_virt1(); virtual int B_virt2();};class C: public A, public B{protected: int c1;public: virtual int A_virt2(); virtual int B_virt2();}; |
最终的内存模型如下所示:
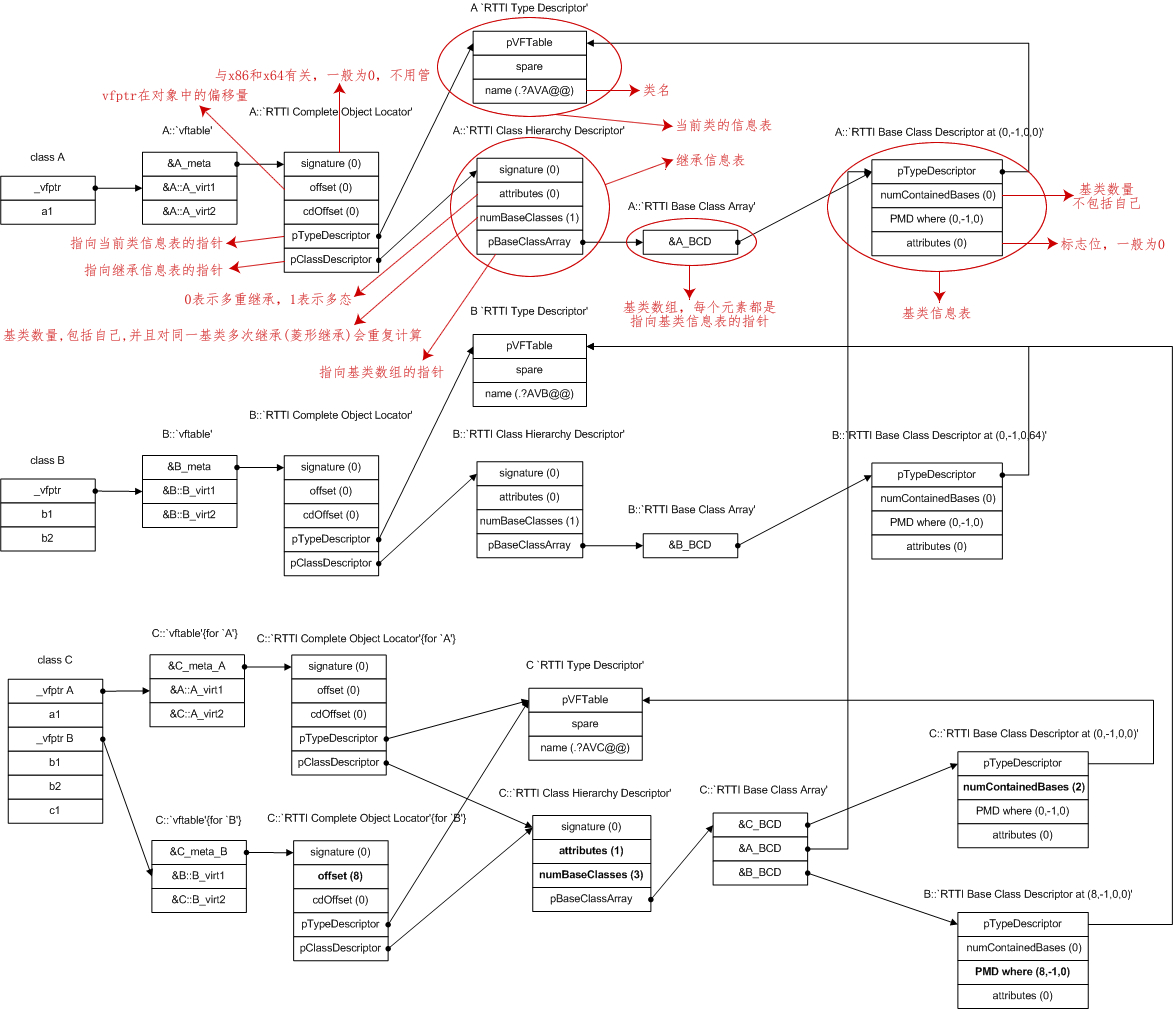
图片来源于 http://www.openrce.org/articles/full_view/23,
从图中可以看出,对于有虚函数的类,内存模型中除了有虚函数表,还会额外增加好几个表,以维护当前类和基类的信息,空间上的开销不小。typeid(type).name() 方法返回的类名就来自“当前类的信息表”。
如果你希望深入了解上图的结构,请查看下面几篇文章:
- VC++逆向:类、方法和 RTTI
- (译)MSVC++ 逆向(二)—— 类、方法和 RTTI
- RTTI结构详细分析(VC++)
- C++中RTTI机制剖析
- C++ dynamic_cast实现原理
- dynamic_cast, RTTI, 整理
=========================================================================
- typeid经过固定次数的间接转换返回type_info对象,间接次数不会随着继承层次的增加而增加,对效率的影响很小,读者可以放心使用。
- 而dynamic_cast 运算符和异常处理不仅要经过数次间接转换,还要遍历继承链,如果继承层次较深,那么它们的性能堪忧,读者应当谨慎使用!
类型是表达式的一个属性,不同的类型支持不同的操作,例如class Student类型的表达式可以调用 display() 方法,int类型的表达式就不行。类型对于编程语言来说非常重要,编译器内部有一个类型系统来维护表达式的各种信息。
- 在 C/C++ 中,变量、函数参数、函数返回值等在定义时都必须显式地指明类型,并且一旦指明类型后就不能再更改了,所以大部分表达式的类型都能够精确的推测出来,编译器在编译期间就能够搞定这些事情,这样的编程语言称为静态语言(Static Language)。除了 C/C++,典型的静态语言还有 Java、C#、Haskell、Scala 等。
- 静态语言在定义变量时通常需要显式地指明类型,并且在编译期间会拼尽全力来确定表达式的类型信息,只有在万不得已时才让程序等到运行后动态地获取类型信息(例如多态),这样做可以提高程序运行效率,降低内存消耗。
- 与静态语言(Static Language)相对的是动态语言(Dynamic Language)。动态语言在定义变量时往往不需要指明类型,并且变量的类型可以随时改变(赋给它不同类型的数据),编译器在编译期间也不容易确定表达式的类型信息,只能等到程序运行后再动态地获取。典型的动态语言有 JavaScript、Python、PHP、Perl、Ruby 等。
- 动态语言为了能够使用灵活,部署简单,往往是一边编译一边执行,模糊了传统的编译和运行的过程。例如 JavaScript 主要用来给网页添加各种特效(这是一种简单的理解),浏览器访问一个页面时会从服务器上下载 JavaScript 源文件,并负责编译和运行它。如果我们提前将 JavaScript 源码编译成可执行文件,那么这个文件就会比较大,下载就会更加耗时,结果就是网页打开速度非常慢,这在网络不发达的早期是不能忍受的。
总起来说,
- 静态语言由于类型的限制会降低编码的速度,但是它的执行效率高,适合开发大型的、系统级的程序;
- 动态语言则比较灵活,编码简单,部署容易,在 Web 开发中大显身手。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了