

LSTM负荷预测pytorch实现版本
LSTM pytorch官网api

我们首先看一下参数:
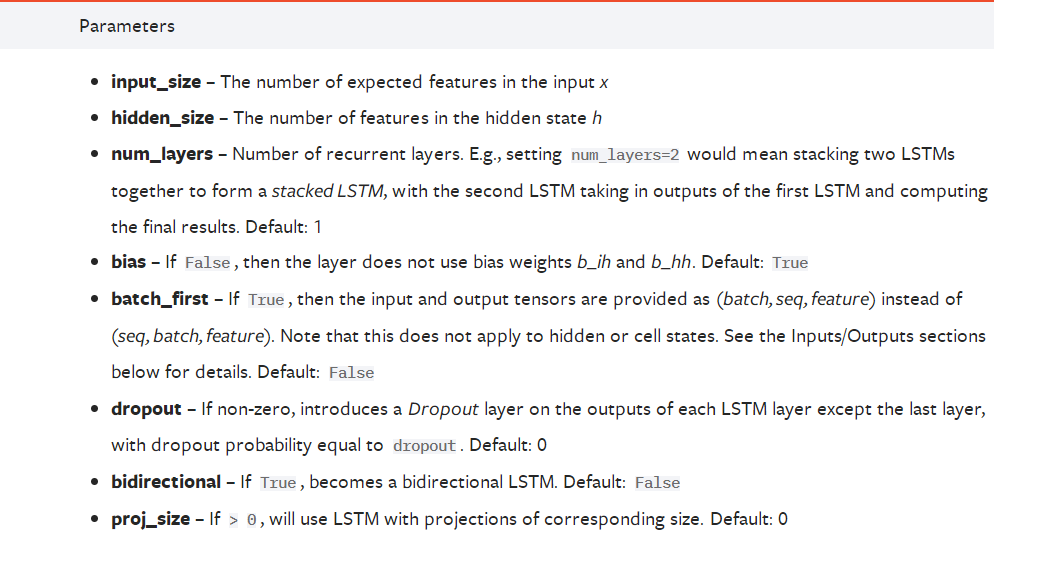
LSTM的两个常见的应用场景为文本处理和时序预测,因此下面对一些参数我都会从这两个方面来进行具体解释。
- input_size:
- 在文本处理中,由于一个单词没法参与运算,因此我们得通过Word2Vec来对单词进行嵌入表示,将每一个单词表示成一个向量,此时input_size=embedding_size。比如每个句子中有五个单词,每个单词用一个100维向量来表示,那么这里input_size=100;
- 在时间序列预测中,比如需要预测负荷,每一个负荷都是一个单独的值,都可以直接参与运算,因此并不需要将每一个负荷表示成一个向量,此时input_size=1。 但如果我们使用多变量进行预测,比如我们利用前24小时每一时刻的[负荷、风速、温度、压强、湿度、天气、节假日信息]来预测下一时刻的负荷,那么此时input_size=7。
- batch_first:默认为False,由于大家普遍使用PyTorch的DataLoader来形成批量数据,因此batch_first也比较重要。
我们再看一下LSTM的输入,

可以看到,输入由两部分组成:input、(初始的隐状态h_0,初始的单元内部状态c_0)
input(seq_len, batch_size, input_size)
- seq_len:
- 在文本处理中,如果一个句子有7个单词,则seq_len=7;
- 在时间序列预测中,假设我们用前24个小时的负荷来预测下一时刻负荷,则seq_len=24。
- batch_size:一次性输入LSTM中的样本个数。在文本处理中,可以一次性输入很多个句子;在时间序列预测中,也可以一次性输入很多条数据。
h_0(num_directions * num_layers, batch_size, hidden_size) c_0(num_directions * num_layers, batch_size, hidden_size)
h_0和c_0的shape一致。

可以看到,输出也由两部分组成:output、(隐状态h_n,内部单元状态c_n)
output(seq_len, batch_size, num_directions * hidden_size)
h_n和c_n的shape保持不变。
如果在初始化LSTM时令batch_first=True,那么input和output的shape将由:
input(seq_len, batch_size, input_size) output(seq_len, batch_size, num_directions * hidden_size)
变为:
input(batch_size, seq_len, input_size) output(batch_size, seq_len, num_directions * hidden_size)
LSTM单步长时间序列预测
单变量单步长预测
下面我们用pytorch搭建一个简单的LSTM网络:
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1 # 单向LSTM
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0)) # output(5, 30, 64)
pred = self.linear(output) # (5, 30, 1)
pred = pred[:, -1, :] # (5, 1)
return pred
假设用前30个预测下一个,则seq_len=30,batch_size=5,由于设置了batch_first=True,因此,输入到LSTM中的input的shape应该为:
input(batch_size, seq_len, input_size) = input(5, 30, 1)
由于输出是输入右移,我们只需要取pred第二维度(time)中的最后一个数据:
pred = pred[:, -1, :] # (5, 1)
这样,我们就得到了预测值,然后与label求loss,然后再反向更新参数即可。
数据集为某个地区某段时间内的电力负荷数据,除了负荷以外,还包括温度、湿度等信息。
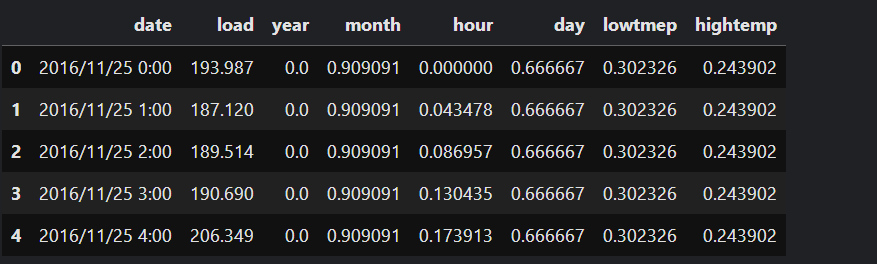
本篇文章暂时不考虑其它变量,只考虑用历史负荷来预测未来负荷。本文中,我们根据前24个时刻的负荷预测下一时刻的负荷。
数据处理:
def load_data(file_name):
df = pd.read_csv('data/new_data/' + file_name, encoding='gbk')
columns = df.columns
df.fillna(df.mean(), inplace=True)
return df
class MyDataset(Dataset):
def __init__(self, data):
#实际的样本元组
self.data = data
def __getitem__(self, item):
return self.data[item]
def __len__(self):
return len(self.data)
def nn_seq_us(B):
print('data processing...')
dataset = load_data()
# split
train = dataset[:int(len(dataset) * 0.6)]#前60%作为线下训练集
val = dataset[int(len(dataset) * 0.6):int(len(dataset) * 0.8)]#20%作为线下验证集
test = dataset[int(len(dataset) * 0.8):len(dataset)]#最后剩下的20%作为测试集
#得出线下训练集的load字段的最大值,最小值,方便后面进行归一化处理
m, n = np.max(train[train.columns[1]]), np.min(train[train.columns[1]])
def process(data, batch_size, shuffle):
load = data[data.columns[1]]
load = load.tolist()
data = data.values.tolist()
load = (load - n) / (m - n)#归一化操作
seq = []
for i in range(len(data) - 24):
train_seq = []#shape:24*1
train_label = []
for j in range(i, i + 24):
x = [load[j]]
train_seq.append(x)
# for c in range(2, 8):
# train_seq.append(data[i + 24][c])
train_label.append(load[i + 24])
train_seq = torch.FloatTensor(train_seq)
train_label = torch.FloatTensor(train_label).view(-1)
seq.append((train_seq, train_label))
# print(seq[-1])
seq = MyDataset(seq)
#drop_last会使最后不够一整批的样本被丢弃
seq = DataLoader(dataset=seq, batch_size=batch_size, shuffle=shuffle, num_workers=0, drop_last=True)
return seq
Dtr = process(train, B, True)
Val = process(val, B, True)
Dte = process(test, B, False)
return Dtr, Val, Dte, m, n
上面代码用了DataLoader来对原始数据进行处理,最终得到了batch_size=B的数据集Dtr、Val以及Dte,Dtr为训练集,Val为验证集,Dte为测试集。
训练:
def train(args, Dtr, Val, path):
input_size, hidden_size, num_layers = args.input_size, args.hidden_size, args.num_layers
output_size = args.output_size
if args.bidirectional:
model = BiLSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
else:
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
loss_function = nn.MSELoss().to(device)
if args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr,
weight_decay=args.weight_decay)
else:
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr,
momentum=0.9, weight_decay=args.weight_decay)
#学习率定制器
scheduler = StepLR(optimizer, step_size=args.step_size, gamma=args.gamma)
# training
min_epochs = 10
best_model = None
min_val_loss = 5
for epoch in tqdm(range(args.epochs)):
train_loss = []
for (seq, label) in Dtr:
seq = seq.to(device)
label = label.to(device)
y_pred = model(seq)
loss = loss_function(y_pred, label)
train_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
# validation
val_loss = get_val_loss(args, model, Val)
if epoch > min_epochs and val_loss < min_val_loss:
min_val_loss = val_loss
best_model = copy.deepcopy(model)
print('epoch {:03d} train_loss {:.8f} val_loss {:.8f}'.format(epoch, np.mean(train_loss), val_loss))
model.train()
state = {'models': best_model.state_dict()}
torch.save(state, path)
测试:
def test(args, Dte, path, m, n):
pred = []
y = []
print('loading models...')
input_size, hidden_size, num_layers = args.input_size, args.hidden_size, args.num_layers
output_size = args.output_size
if args.bidirectional:
model = BiLSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
else:
model = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
# models = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
model.load_state_dict(torch.load(path)['models'])
model.eval()
print('predicting...')
for (seq, target) in tqdm(Dte):
target = list(chain.from_iterable(target.data.tolist()))
y.extend(target)
seq = seq.to(device)
with torch.no_grad():
y_pred = model(seq)
y_pred = list(chain.from_iterable(y_pred.data.tolist()))
pred.extend(y_pred)
y, pred = np.array(y), np.array(pred)
y = (m - n) * y + n
pred = (m - n) * pred + n
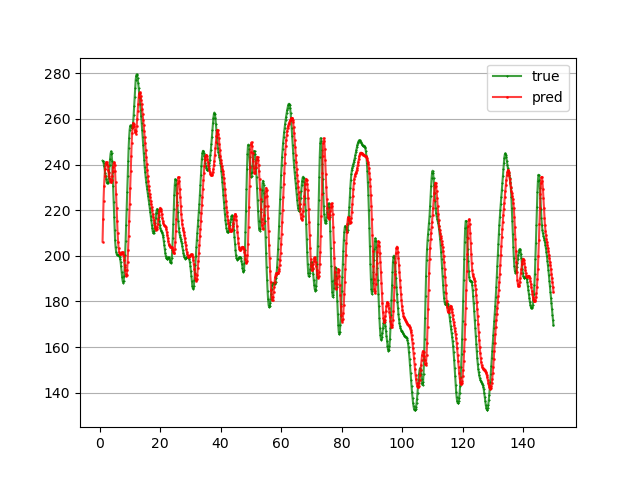
print('mape:', get_mape(y, pred))
# plot
x = [i for i in range(1, 151)]
x_smooth = np.linspace(np.min(x), np.max(x), 900)
y_smooth = make_interp_spline(x, y[150:300])(x_smooth)
plt.plot(x_smooth, y_smooth, c='green', marker='*', ms=1, alpha=0.75, label='true')
y_smooth = make_interp_spline(x, pred[150:300])(x_smooth)
plt.plot(x_smooth, y_smooth, c='red', marker='o', ms=1, alpha=0.75, label='pred')
plt.grid(axis='y')
plt.legend()
plt.show()
chain.from_iterable()是一种迭代器,对象为可迭代的数据结构,用于拆分与合并一些迭代对象。



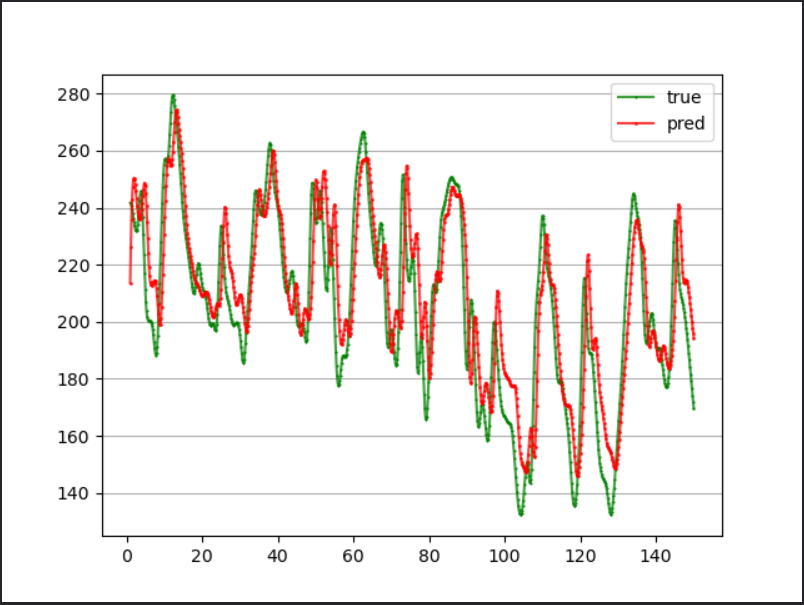
简单训练30轮,MSE为5.77%:
多变量单步长预测
在前面,我们利用LSTM实现了负荷预测,但我们只是简单利用负荷预测负荷,并没有利用到其他一些环境变量,比如温度、湿度等。这里我们实现多变量时间序列预测。
我们根据前24个时刻的负荷以及该时刻的环境变量来预测下一时刻的负荷。最终得到了batch_size=B的数据集Dtr、Val以及Dte,Dtr为训练集,Val为验证集,Dte为测试集。
任意输出Dte中的一条数据:
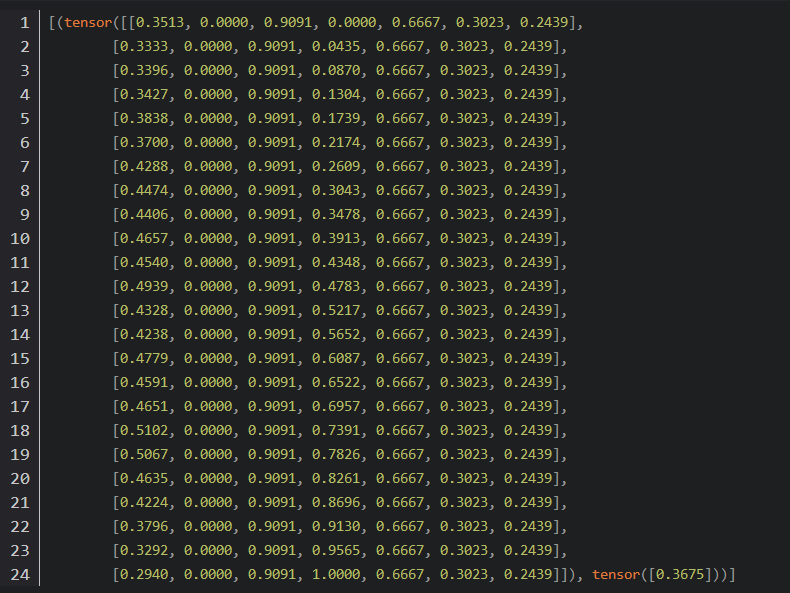
可以看到一条样本的seq_len为24,说明我们利用历史前24小时的信息去预测下一个时刻,每一个时刻我们利用了维度为7的信息,其中一维为此时刻的负荷值,另外6维为温度,湿度等环境变量。每一行对应一个时刻点的负荷以及环境变量,此时input_size=7。
简单训练了30轮,MSE为6.01%:
双向LSTM实现预测
假设最后我们得到了output(batch_size, seq_len, 2 * hidden_size),我们需要将其输入到线性层,有以下两种方法可以参考:
- 直接输入
和单向一样,我们可以将output直接输入到Linear。在单向LSTM中:
self.linear = nn.Linear(self.hidden_size, self.output_size)
而在双向LSTM中:
self.linear = nn.Linear(2 * self.hidden_size, self.output_size)
此时的模型为:
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 2
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=True)
self.linear = nn.Linear(self.num_directions * self.hidden_size, self.output_size)
def forward(self, input_seq):
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# print(input_seq.size())
seq_len = input_seq.shape[1]
# input(batch_size, seq_len, input_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
pred = self.linear(output) # pred()
pred = pred[:, -1, :]
return pred
- 处理后再输入
在LSTM中,经过线性层后的output的shape为(batch_size, seq_len, output_size)。假设我们用前24个小时(1 to 24)预测后2个小时的负荷(25 to 26),那么seq_len=24, output_size=2。根据LSTM的原理,最终的线性层的输出中包含了所有位置的预测值,也就是((2 3), (3 4), (4 5)…(25 26))。很显然我们只需要最后一个预测值,即output[:, -1, :]。 而在双向LSTM中,一开始output(batch_size, seq_len, 2 * hidden_size),这里面包含了所有位置的两个方向的输出。简单来说,output[0]为序列从左往右第一个隐藏层状态输出和序列从右往左最后一个隐藏层状态输出的拼接;output[-1]为序列从左往右最后一个隐藏层状态输出和序列从右往左第一个隐藏层状态输出的拼接。 如果我们想要同时利用前向和后向的输出,我们可以将它们从中间切割,然后求平均(个人:也就是第一种方法是拼接,这里的第二种方法是求平均)。比如output的shape为(30, 24, 2 * 64),我们将其变成(30, 24, 2, 64),然后在dim=2上求平均,得到一个shape为(30, 24, 64)的输出,此时就与单向LSTM的输出一致了。
此时模型为:
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 2
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# print(input_seq.size())
seq_len = input_seq.shape[1]
# input(batch_size, seq_len, input_size)
input_seq = input_seq.view(self.batch_size, seq_len, self.input_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
output = output.contiguous().view(self.batch_size, seq_len, self.num_directions, self.hidden_size)
output = torch.mean(output, dim=2)
pred = self.linear(output)
# print('pred=', pred.shape)
pred = pred[:, -1, :]
return pred
这里对多变量单步长的预测进行对比,在其他条件保持一致的情况下,得到的实验结果如下所示:

可以看到,对于前面提到的两种方法,貌似差异不大。
LSTM多变量多步长时间序列预测
直接多输出预测
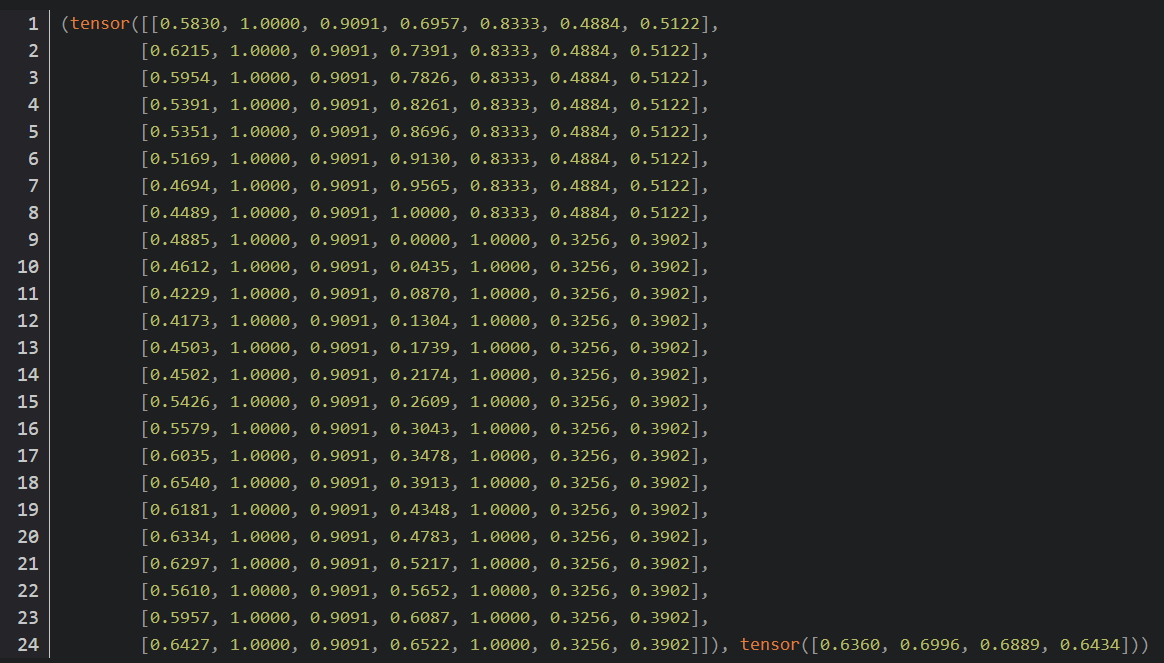
数据格式为(X, Y)。其中X一共24行,表示前24个时刻的负荷值和该时刻的环境变量。Y一共四个值,表示需要预测的四个负荷值。需要注意的是,此时input_size=7,output_size=4。
模型不变,只是此时的output_size=4,训练和预测代码和前几篇都差不多,只是需要注意input_size和output_size的大小。 训练了50轮,预测接下来4个时刻的负荷值,MAPE为7.62%: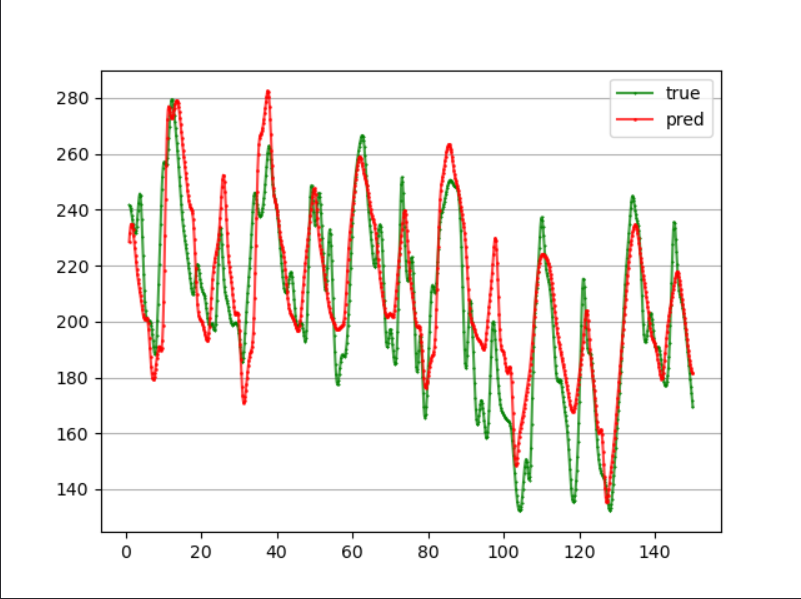
可以看到,在得到output之后,我们直接将其经过一个线性层,将单个输出转成了多个输出,这种方法的优点是比较简单,但可能没有考虑到时间序列之间的相关性。
单步滚动预测实现多步预测
比如前10个预测后3个:我们首先利用[1…10]预测[11’],然后利用[2…10 11’]预测[12’],最后再利用[3…10 11’ 12’]预测[13’],也就是为了得到多个预测输出,我们直接预测多次,并且在每次预测时将之前的预测值带入。
这种方法的缺点是显而易见的:
- 由于每一步的预测都有误差,将有误差的预测值带入进行预测后往往会造成更大的误差,让误差传递。
- 利用这种方式预测到后面,通常预测值就完全不变了。
训练了50轮,前24个时刻预测未来12个负荷值,单步滚动预测,MAPE为10.62%:
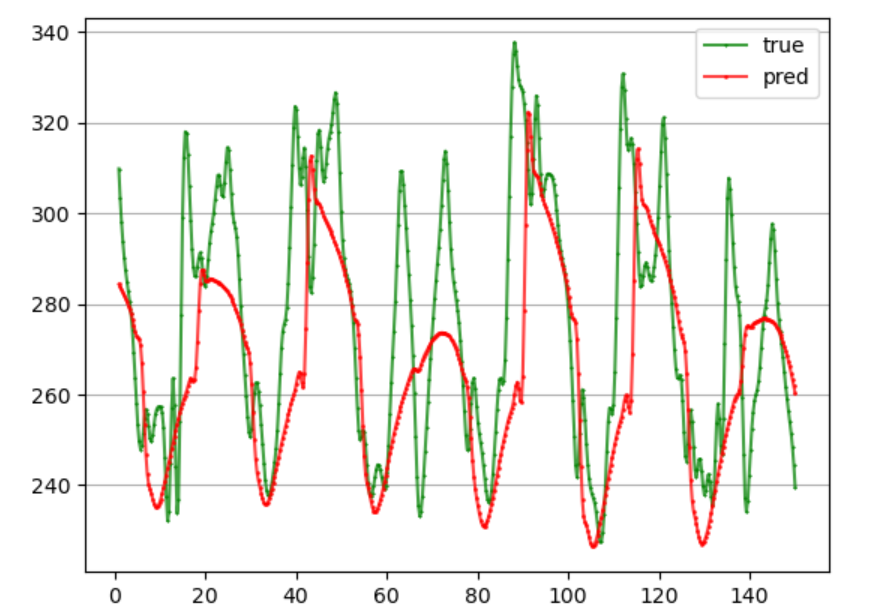
多模型单步预测
所谓多模型单步预测:比如前10个预测后3个,那么我们可以训练三个模型,分别根据[1…10],预测[11]、[12]以及[13]。也就是说如果需要进行n步预测,那么我们一共需要训练n个LSTM模型,缺点很突出。
前24个预测未来12个,每个模型训练50轮,MAPE为10.03%,还需要进一步完善。
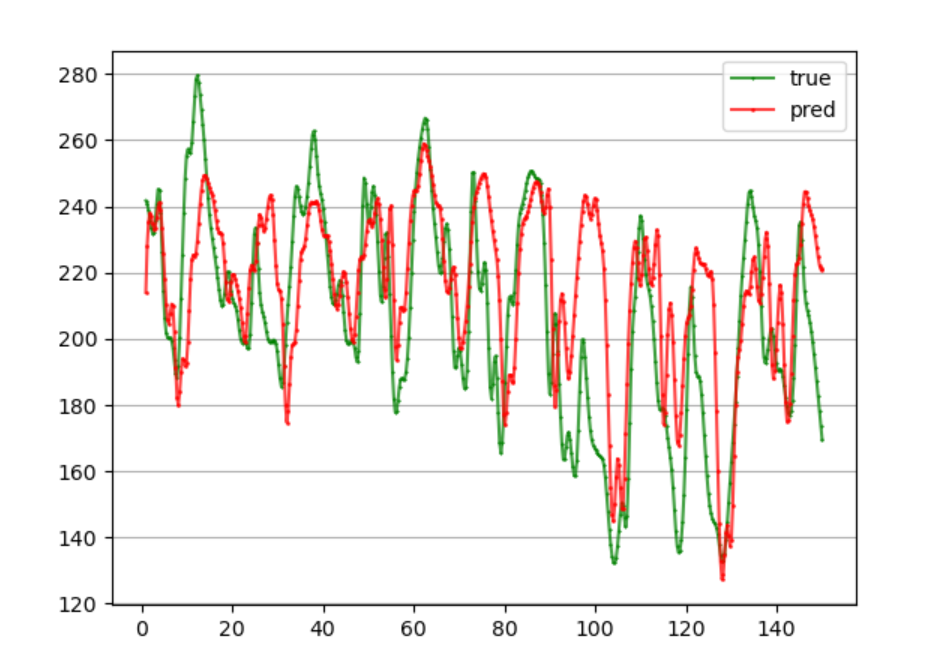
多模型滚动预测
所谓多模型滚动预测是单模型多步预测和多模型单步预测的结合,还是以前10个预测后3个为例:首先需要按照多模型单步预测的方式训练3个模型,模型1利用[1…10]预测[11’],然后模型2利用[2…10 11’]预测[12’],最后由模型3利用[3…10 11’ 12’]预测[13’]。
模型训练与多模型单步预测一致。 模型测试与单步滚动预测有些类似,但每一步都由不同的模型来进行预测。
前24个预测未来12个,每个模型训练50轮,效果很差,MAPE为13.26%,还需要进一步完善。
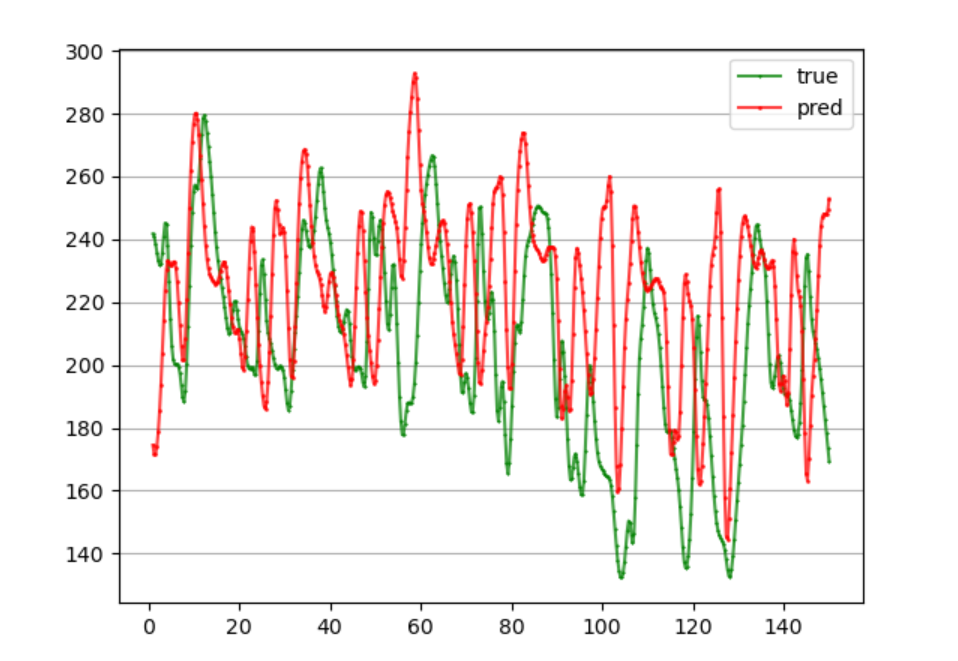
LSTM架构的seq2seq
seq2seq由两部分组成:Encoder和Decoder。seq2seq的输入是一个序列,输出也是一个序列,经常用于时间序列预测。
我们根据前24个时刻的负荷以及该时刻的环境变量来预测接下来12个时刻的负荷(步长pred_step_size可调)。数据处理代码和前面的直接多输出预测一致。
模型搭建分为三个步骤:编码器、解码器以及seq2seq。
首先是Encoder:
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_directions = 1
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=False)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
output, (h, c) = self.lstm(input_seq, (h_0, c_0))
return h, c
一般来讲编码器采用的就是RNN网络,这里采用了LSTM将原始数据进行编码,然后将LSTM的最后的隐状态和内部单元状态返回。
接着是解码器Decoder:
class Decoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=False)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq, h, c):
# input_seq(batch_size, input_size)
batch_size = input_seq.shape[0]
input_seq = input_seq.view(batch_size, 1, self.input_size)
# output(batch_size, 1, hidden_size)
output, (h, c) = self.lstm(input_seq, (h, c))
pred = self.linear(output) # pred(batch_size, 1, output_size)
pred = pred[:, -1, :]
return pred, h, c
解码器同样也由LSTM组成,不过解码器的初始的隐状态和单元状态是编码器的输出。此外,解码器每次只输入seq_len中的一个。
最后定义seq2seq:
class Seq2Seq(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.output_size = output_size
self.Encoder = Encoder(input_size, hidden_size, num_layers, batch_size)
self.Decoder = Decoder(input_size, hidden_size, num_layers, output_size, batch_size)
def forward(self, input_seq):
batch_size, seq_len, _ = input_seq.shape[0], input_seq.shape[1], input_seq.shape[2]
h, c = self.Encoder(input_seq)
outputs = torch.zeros(batch_size, seq_len, self.output_size).to(device)
for t in range(seq_len):
_input = input_seq[:, t, :]
output, h, c = self.Decoder(_input, h, c)
outputs[:, t, :] = output
return outputs[:, -1, :]
seq2seq中,将24个时刻的的数据依次迭代输入解码器(个人:这一点存疑)。
前24个预测未来12个,每个模型训练50轮,MAPE为9.09%,还需要进一步完善。
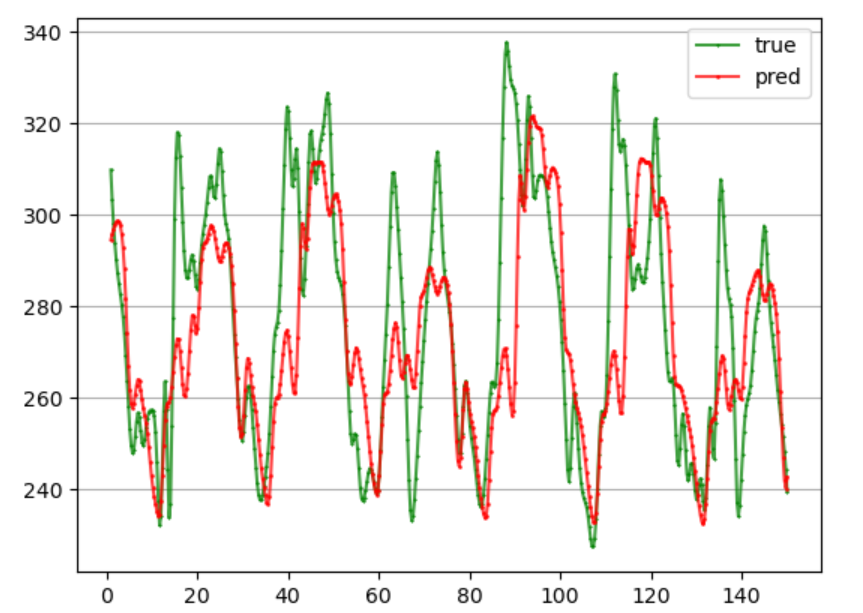
和直接多输出有点类似,但采用编码器-解码器结构来进行训练。
实际生产环境中如何预测未来值
当在生产环境中时,我们应该如何预测未来值呢?比如说,我们用前24个小时的负荷值预测未来12个小时的负荷值。现在假设当前时间为2022/9/8的21:00,现在我们需要预测22:00到9/9 9:00的负荷值。根据模型的需求,我们需要构造一个seq,seq里面包含了9/8 21:00往前24个时刻的负荷值,这个是真实存在的。我们可以直接将seq喂进我们的模型,预测得到今晚22:00到9/9 9:00的负荷值。
需要注意的是,我们是用训练集数据上得到的归一化算子对seq进行归一化操作。
如果我们想接着预测9/9 10:00~21:00的负荷值又该如何操作呢?一般来讲,有以下三种可能:
- 假设电网有能力实时收集到真实用电负荷值,到明天9:00时,我们已经观测到了今晚22:00到明天9:00的真实值,且这些真实值保存在了数据库中,那么我们完全可以利用明天9:00之前24个小时的真实值预测未来12小时的负荷值。
- 在现实生活中,往往很难及时收集到用电负荷信息,比如我们预测到了明天9:00,在明天9:00时,我们收集不到今晚22:00到明天9:00间的真实负荷值,此时我们就需要利用预测值来进行预测。
- 在明天9:00时,我们也不是一点真实值都没收集到,比如我们收集到了今晚22:00到明早3:00的负荷值,4:00到9:00的真实负荷值虽然已经产生,但电网还没有收集到数据库中。此时我们拥有6个真实值以及6个预测值,那么此时我们就可以用6个真实值加6个预测值,以及今晚9:00之前的12个真实值组成1个seq进行预测。一个大的前提:尽量使用真实值进行预测。
上面的例子都是单变量预测,如果是多变量预测,情况将变得复杂一点。假设我们利用负荷值、温度、湿度以及压强四个变量来预测负荷。在我们预测今晚22:00到明早9:00的负荷值时,我们可以利用测试集中的数据进行预测。
但当我们需要预测明早9:00之后的负荷值时,我们需要同时考虑是否收集到了真实的温度、湿度以及压强值。
- 一般来讲,这些环境变量的收集比负荷数据的收集更加容易,也就是上述中的第一种情况。
- 如果我们无法及时收集到负荷值,我们可以利用预测值进行预测;如果我们无法及时收集到温度、湿度以及压强值,我们也只能利用预测值进行预测。这就意味着,我们需要额外训练三个模型来分别预测温度、湿度以及压强,由于这三个变量和负荷一一对应,也属于时序数据,我们也可以采用LSTM进行预测,如果其变化幅度不大也可以采用传统的机器学习算法进行预测。
多变量输入多变量输出预测(多任务学习)
前面介绍的都是“单变量输出”,虽然某些地方提到了“多变量”,但这个多变量只是输入多变量,而不是输出多变量。比如我们利用前24个时刻的[负荷、温度、湿度、压强]预测接下来12个时刻的负荷,此时输入为多变量,虽然有多个输出(多步长),但输出的都是同一变量。 那么有没有办法一次性输出多个变量呢?当然是可以的,这样做效果很不好,不建议这么做。多变量输出是指:我们一次性输出多个变量的预测值。比如我们利用前24小时的[负荷、温度、湿度、压强]预测接下来12个时刻的[负荷、温度、湿度、压强]。实际上,我们可以将多个变量的输出分解开来,看成多个任务,也就是多任务学习,其中每一个任务都是前面提到的多变量输入单变量输出。 具体来讲,假设需要预测四个变量,输入在经过LSTM后得到output,我们将output分别通过四个全连接层,就能得到四个输出。得到四个输出后,我们就可以计算出四个损失函数,对这四个损失函数,本文将其简单求平均以得到最终的损失函数。关于如何组合多任务学习中的损失,已经有很多文献探讨过,感兴趣的可以自行了解。
这里我们用到了两个数据集:
- 数据集1包含某个地区的负荷、湿度以及能见度三个特征。
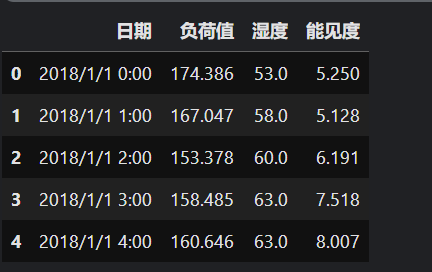
- 数据集2中包含三个地区的负荷值。
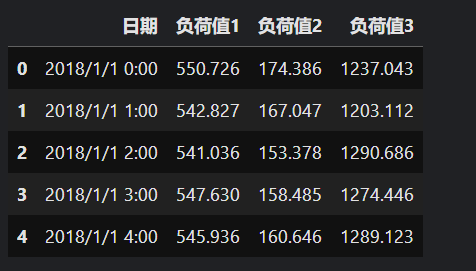
依旧使用前24个时刻的三个变量预测后12个时刻的三个变量,数据处理同前面介绍的一致。
多输入多输出LSTM模型搭建如下:
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size, n_outputs):
super().__init__()
self.input_size = input_size #输入的维度
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size #要预测的时间步长数
self.num_directions = 1
self.n_outputs = n_outputs #多变量输出的变量数
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
# self.fcs = [nn.Linear(self.hidden_size, self.output_size).to(device) for i in range(self.n_outputs)]
self.fc1 = nn.Linear(self.hidden_size, self.output_size)
self.fc2 = nn.Linear(self.hidden_size, self.output_size)
self.fc3 = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
# print(input_seq.shape)
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, batch_size, self.hidden_size).to(device)
# print(input_seq.size())
# input(batch_size, seq_len, input_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
preds = []
pred1, pred2, pred3 = self.fc1(output), self.fc2(output), self.fc3(output)
pred1, pred2, pred3 = pred1[:, -1, :], pred2[:, -1, :], pred3[:, -1, :]
# pred = torch.cat([pred1, pred2], dim=0)
# predict(n_outputs, batch_size, output_size)
pred = torch.stack([pred1, pred2, pred3], dim=0)
# print(pred.shape)
return pred
模型训练中,经过预测后,我们得到的label和pred的shape分别为:
label(batch_size, n_outputs, pred_step_size) pred((n_outputs, batch_size, pred_step_size))
由于需要对每一个output计算损失然后相加求平均,所以我们的损失函数求解如下:
total_loss = 0
for k in range(args.n_outputs):
total_loss = total_loss + loss_function(preds[k, :, :], labels[:, k, :])
total_loss /= args.n_outputs
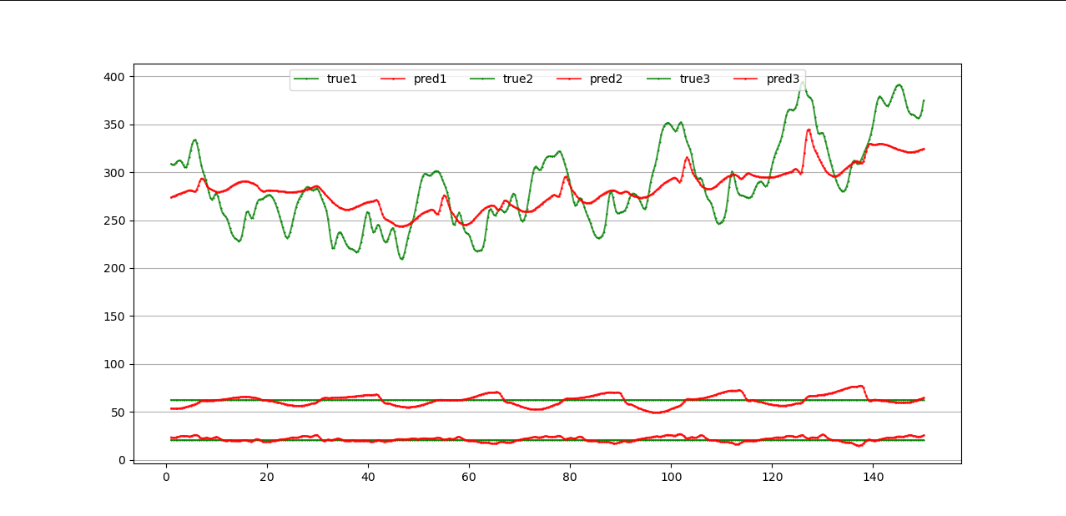
- 数据集1的预测结果如下所示:

- 数据集2的预测结果如下所示:

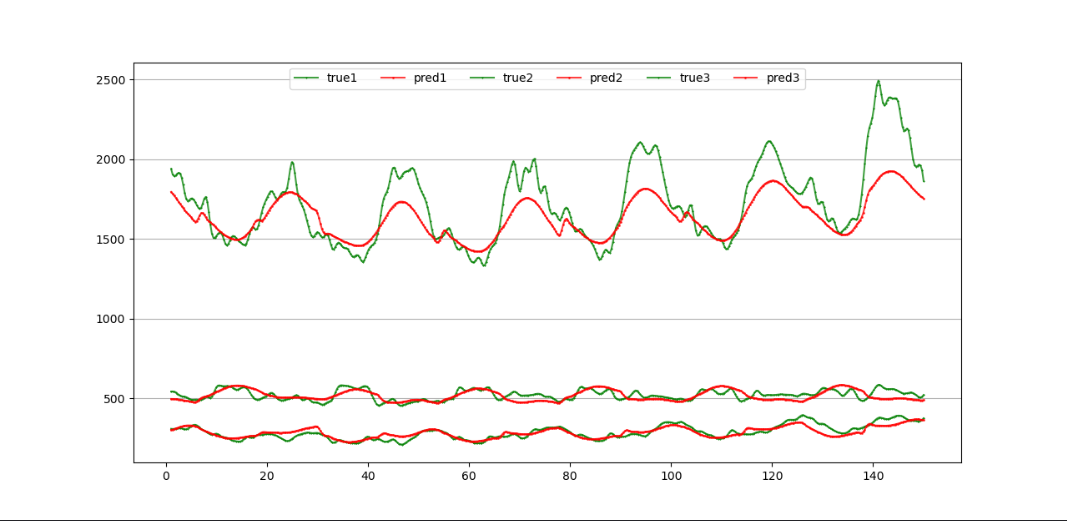
观察上述结果我们可以发现,数据集2上的预测效果明显更好,这可能是因为三个负荷变量之间相关性较强。
参考
https://blog.csdn.net/Cyril_KI/article/details/122557880
