

第4章 C++继承与派生总结
面向对象程序设计有4个主要特点:抽象、封装、继承和多态性。
类和对象→数据抽象与封装。
面向对象技术强调软件的可重用性(software reusability)。C++语言提供了类的继承机制,解决了软件重用问题。
继承的一般语法为:
class 派生类名:[继承方式] 基类名{
派生类新增加的成员
};
例如,
class Student: public People{
public:
void setscore(float score);
float getscore();
private:
float m_score;
};
继承方式包括 public(公有的)、private(私有的)和 protected(受保护的),此项是可选的,如果不写,那么默认为 private。
类成员的访问权限由高到低依次为 public --> protected --> private。protected 成员和 private 成员类似,也不能通过对象访问。但是当存在继承关系时,protected 和 private 就不一样了:基类中的 protected 成员可以在派生类中使用,而基类中的private 成员不能在派生类中使用。
不同的继承方式会影响基类成员在派生类中的访问权限(个人:这个访问权限是相对派生类的用户而言的,派生类访问基类成员权限只与基类成员在基类中的访问修饰符有关)。
- public继承方式
- 基类中所有 public 成员在派生类中为 public 属性;
- 基类中所有 protected 成员在派生类中为 protected 属性;
- 基类中所有 private 成员在派生类中为private。
- protected继承方式
-
- 基类中的所有 public 成员在派生类中为 protected 属性;
- 基类中的所有 protected 成员在派生类中为 protected 属性;
- 基类中的所有 private 成员在派生类中为private。
- private继承方式
- 基类中的所有 public 成员在派生类中均为 private 属性;
- 基类中的所有 protected 成员在派生类中均为 private 属性;
- 基类中的所有 private 成员在派生类中为private。
通过上面的分析可以发现:
- 基类成员在派生类中的访问权限不得高于继承方式中指定的权限。(个人:也就是基类成员在派生类中的访问标识符是什么,访问标识符是针对类的用户而言的),例如,当继承方式为 protected 时,那么基类成员在派生类中的访问权限最高也为 protected,高于 protected 的会降级为 protected,但低于 protected 不会升级。再如,当继承方式为 public 时,那么基类成员在派生类中的访问权限将保持不变。也就是说,继承方式中的public、protected、private是用来指明基类成员在派生类中的最高访问权限的。(个人:每个类规定自己的成员的针对自己用户的对外访问权限,一个类的用户不但包括使用这个类创建对象的用户,友元,它的继承类也是它的用户,这个工作由类的设计者指定,不假手于人。针对子类的用户,一个子类的成员包括它自己的成员,和通过继承过来的成员,虽然子类访问继承而来的成员由父类中的说明符决定,但是既然通过继承给了子类,那么再提供给子类的用户时,子类可以通过继承时的继承方式,针对子类的用户说明一下这些继承而来的成员的对外访问说明符)
- 不管继承方式如何,基类中的 private 成员在派生类中始终不能使用(不能在派生类的成员函数中访问或调用,更更不能被派生类的用户所使用),如果希望基类的成员能够被派生类继承并且毫无障碍地使用(个人:这里的使用是指的在派生类内部使用,不是针对派生类的用户而言的),那么这些成员只能声明为 public 或 protected;只有那些不希望在派生类中使用的成员才声明为 private。如果希望基类的成员既不向外暴露(不能通过对象访问),还能在派生类中使用,那么只能声明为 protected。
注意,我们这里说的是基类的 private 成员不能在派生类中使用,并没有说基类的 private 成员不能被继承。实际上,基类的private成员是能够被继承的,并且(成员变量)会占用派生类对象的内存,它只是在派生类中不可见,导致无法使用罢了。private 成员的这种特性,能够很好的对派生类隐藏基类的实现,以体现面向对象的封装性。
下表汇总了不同继承方式对不同属性的成员的影响结果:
| 继承方式\基类成员 | public成员(可见) | protected成员(可见) | private成员(不可见) |
|---|---|---|---|
| public继承 | public | protected | private |
| protected继承 | protected | protected | private |
| private继承 | private | private | private |
由于 private 和 protected 继承方式会改变基类成员在派生类中的访问权限,导致继承关系复杂,所以实际开发中我们一般使用 public。
在派生类中访问基类 private 成员的唯一方法就是借助基类的非 private 成员函数,如果基类没有非 private 成员函数,那么该成员在派生类中将无法访问。
- 有时候我们需要改变派生类继承的某个名字的访问级别,通过使用using声明可以达到这个目的。(个人:其实就是破坏掉继承方式那里指定的原则,将一些继承而来的名字的访问级别使用using声明重新指定,继承方式那里指定的作废,反正继承方式和using声明都是派生类自己指定的)
- 需要注意的是,派生类只能为那些它可以访问的名字提供using声明。(个人:理由1,因为using是派生类中的一条命令语句,一个表达式,既然是一条语句,那么里面使用的名字首先得在派生类中可见吧,如果不可见这条语句首先就是错误的,因为这条语句引用了一个不能访问的名字。)
- (个人:既然这些成员对子类可见,这种可见是父类规定的,授权给子类的,既然授权给了子类可见,那么我子类再重新传递授权给别人没问题吧,通过在派生列表中指定派生访问说明符和在派生类中使用using声明都是干这件事的(派生访问说明符也是针对继承的可见名字而言的),只不过通过using声明可以将它可以访问的名字重新授权成任意级别,对各个可访问名字可以各自声明,而通过派生访问说明符只是针对所有的可访问名字指定了一个统一的最高访问级别,可以看出通过使用using声明比派生访问说明符更灵活,也更宽松)
- using声明语句中名字的访问权限由该using声明语句之前的访问说明符来决定。
using 关键字使用示例:
#include<iostream>
using namespace std;
//基类People
class People {
public:
void show();
protected:
const char * m_name;
int m_age;
};
void People::show() {
cout << m_name << "的年龄是" << m_age << endl;
}
//派生类Student
class Student : private People {
public:
void learning();
public:
using People::m_name; //将protected改为public
using People::m_age; //将protected改为public
float m_score;
private:
using People::show; //将public改为private
};
void Student::learning() {
cout << "我是" << m_name << ",今年" << m_age << "岁,这次考了" << m_score << "分!" << endl;
}
int main() {
Student stu;
/*
*对于Student类的用户而言
*此时的m_name的访问级别为public
*/
stu.m_name = "小明";
/*
*对于Student类的用户而言
*此时的m_age的访问级别为public
*/
stu.m_age = 16;
stu.m_score = 99.5f;
//stu.show(); //compile error
stu.learning();
return 0;
}

#include<iostream>
using namespace std;
//基类People
class People{
public:
void show();
protected:
const char *m_name;
int m_age;
};
void People::show(){
cout<<"嗨,大家好,我叫"<<m_name<<",今年"<<m_age<<"岁"<<endl;
}
//派生类Student
class Student: public People{
public:
Student(const char *name, int age, float score);
public:
void show(); //遮蔽基类的show()
private:
float m_score;
};
Student::Student(const char *name, int age, float score){
m_name = name;
m_age = age;
m_score = score;
}
void Student::show(){
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
int main(){
Student stu("小明", 16, 90.5);
//使用的是派生类新增的成员函数,而不是从基类继承的
stu.show();
//使用的是从基类继承来的成员函数
stu.People::show();
return 0;
}
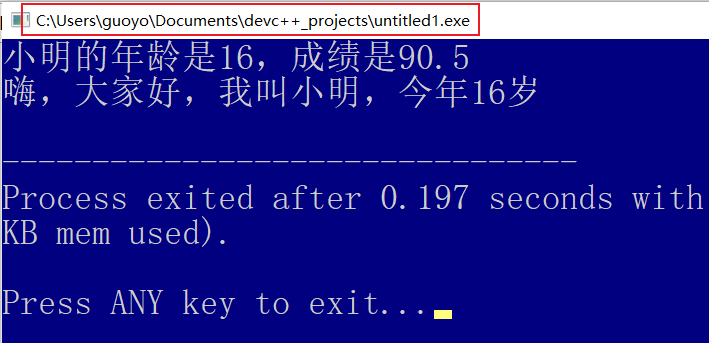
但是,基类 People 中的 show() 函数仍然可以访问,不过要加上类名和域解析符。
基类成员和派生类成员的名字一样时会造成遮蔽,这句话对于成员变量很好理解,对于成员函数要引起注意,不管函数的参数如何,只要名字一样就会造成遮蔽。换句话说,基类成员函数和派生类成员函数不会构成重载,如果派生类有同名函数,那么就会遮蔽基类中的所有同名函数,不管它们的参数是否一样。
类其实也是一种作用域,每个类都会定义它自己的作用域,在这个作用域内我们再定义类的成员,当存在继承关系时,派生类的作用域嵌套在基类的作用域之内,如果一个名字在派生类的作用域内无法找到,编译器会继续到外层的基类作用域中查找该名字的定义。这个过程叫做名字查找(name lookup),也就是在作用域链中寻找与所用名字最匹配的声明(或定义)的过程。换句话说,作用域能够彼此包含,被包含(或者说被嵌套)的作用域称为内层作用域(inner scope),包含着别的作用域的作用域称为外层作用域(outer scope)。一旦在外层作用域中声明(或者定义)了某个名字,那么它所嵌套着的所有内层作用域中都能访问这个名字。同时,允许在内层作用域中重新定义外层作用域中已有的名字。假设 Base 是基类,Derived 是派生类,那么它们的作用域的嵌套关系如下图所示:
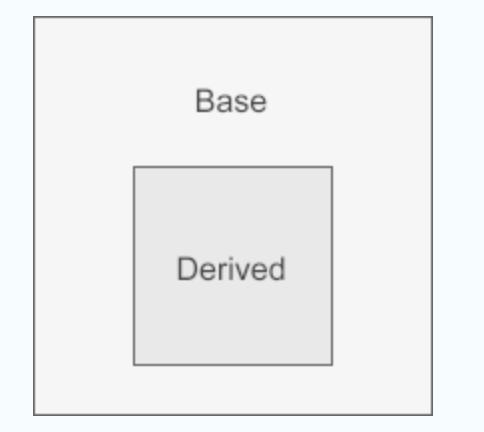
派生类的作用域位于基类作用域之内这一事实可能有点出人意料,毕竟在我们的代码中派生类和基类的定义是相互分离的。不过也恰恰因为类作用域有这种继承嵌套的关系,所以派生类才能像使用自己的成员一样来使用基类的成员。
名字查找(name lookup),对于成员变量这个过程很好理解,对于成员函数要引起注意,编译器仅仅是根据函数的名字来查找的,不会理会函数的参数。换句话说,一旦内层作用域有同名的函数,不管有几个,编译器都不会再到外层作用域中查找,编译器仅把内层作用域中的这些同名函数作为一组候选函数;这组候选函数就是一组重载函数。
说白了,
- 只有同一个作用域内的同名函数才具有重载关系,
- 不同作用域内的同名函数是会造成遮蔽,使得外层函数无效。
- 派生类和基类拥有不同的作用域,所以它们的同名函数不具有重载关系。
没有继承时对象的内存的分布,这时的内存模型很简单,成员变量和成员函数会分开存储:
- 对象的内存中只包含成员变量,存储在栈区或堆区(使用 new 创建对象);
- 成员函数与对象内存分离,存储在代码区。
当存在继承关系时,内存模型会稍微复杂一些。有继承关系时,派生类的内存模型可以看成是基类成员变量和新增成员变量的总和,而所有成员函数仍然存储在另外一个区域——代码区,由所有对象共享。
- 请看下面的代码:
#include <cstdio>
using namespace std;
//基类A
class A{
public:
A(int a, int b);
public:
void display();
protected:
int m_a;
int m_b;
};
A::A(int a, int b): m_a(a), m_b(b){}
void A::display(){
printf("m_a=%d, m_b=%d\n", m_a, m_b);
}
//派生类B
class B: public A{
public:
B(int a, int b, int c);
void display();
private:
int m_c;
};
B::B(int a, int b, int c): A(a, b), m_c(c){ }
void B::display(){
printf("m_a=%d, m_b=%d, m_c=%d\n", m_a, m_b, m_c);
}
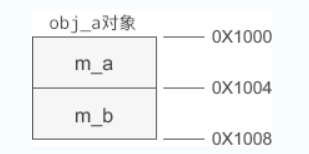
int main(){
A obj_a(99, 10);
B obj_b(84, 23, 95);
obj_a.display();
obj_b.display();
return 0;
}

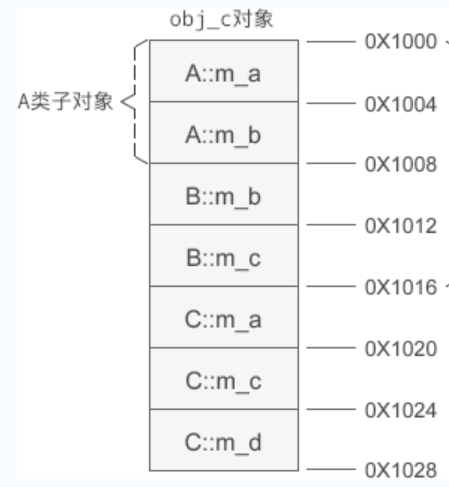
obj_a 是基类对象,obj_b 是派生类对象。假设 obj_a 的起始地址为 0X1000,那么它的内存分布如下图所示:
假设 obj_b 的起始地址为 0X1100,那么它的内存分布如下图所示:
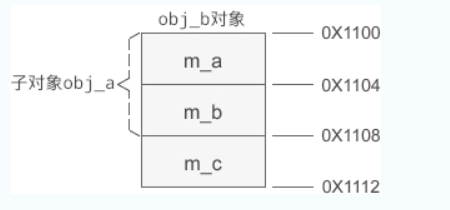
可以发现,基类的成员变量排在前面,派生类的排在后面。
- 为了让大家理解更加透彻,我们不妨再由 B 类派生出一个 C 类:
//声明并定义派生类C
class C: public B{
public:
C(char a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
C::C(char a, int b, int c, int d): B(a, b, c), m_d(d){ }
void C::display(){
printf("m_a=%d, m_b=%d, m_c=%d, m_d=%d\n", m_a, m_b, m_c, m_d);
}
//创建C类对象obj_c
C obj_c(84, 23, 95, 60);
obj_c.display();
假设 obj_c 的起始地址为 0X1200,那么它的内存分布如下图所示:
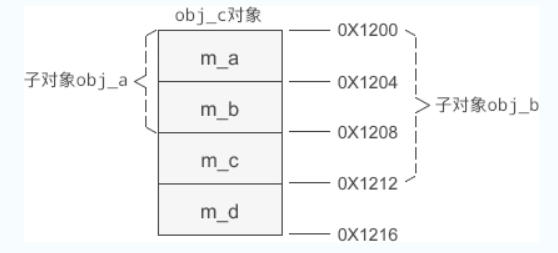
成员变量按照派生的层级依次排列,新增成员变量始终在最后。(个人:按照这种顺序放置,可以方面我们将派生类的指针或者引用当成父类类型的来使用去访问成员)
- 更改上面的 C 类,让它的成员变量遮蔽 A 类和 B 类的成员变量(个人:此时需要将上面的class B代码里的成员变量改为protected访问级别),我们看一下有成员变量遮蔽时的内存分布:
//声明并定义派生类C
class C: public B{
public:
C(char a, int b, int c, int d);
public:
void display();
private:
int m_b; //遮蔽A类的成员变量
int m_c; //遮蔽B类的成员变量
int m_d; //新增成员变量
};
C::C(char a, int b, int c, int d): B(a, b, c), m_b(b), m_c(c), m_d(d){ }
void C::display(){
printf("A::m_a=%d, A::m_b=%d, B::m_c=%d\n", m_a, A::m_b, B::m_c);
printf("C::m_b=%d, C::m_c=%d, C::m_d=%d\n", m_b, m_c, m_d);
}
//创建C类对象obj_c
C obj_c(84, 23, 95, 60);
obj_c.display();
假设 obj_c 的起始地址为 0X1300,那么它的内存分布如下图所示:
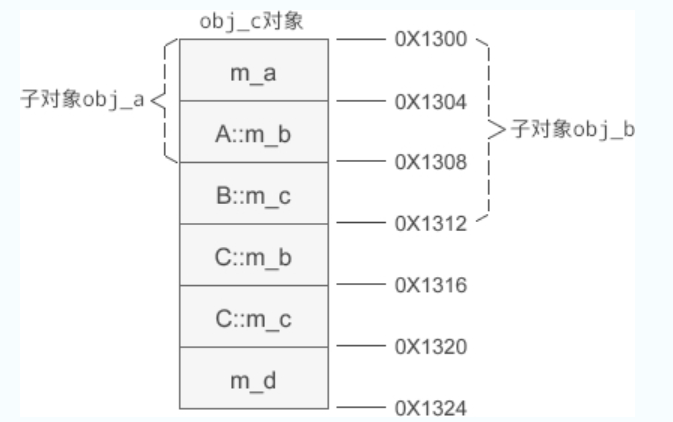
当基类 A、B 的成员变量被遮蔽时,仍然会留在派生类对象 obj_c 的内存中,C 类新增的成员变量始终排在基类 A、B 的后面。
总结:在派生类的对象模型中,会包含所有基类的成员变量。这种设计方案的优点是访问效率高,能够在派生类对象中直接访问基类变量,无需经过好几层间接计算。
在设计派生类时,对继承过来的成员变量的初始化工作在派生类的构造函数的初始化列表中通过调用基类的构造函数来完成。(个人:每个类控制自己成员的初始化工作,对于派生类自己的成员,派生类它自己直接完成它的初始化,对于继承而来的成员,则只能通过调用父类的构造函数让父类的构造函数来完成,派生类无法直接进行父类的初始化工作,只能通过调用基类的构造函数间接完成)
Student::Student(char *name, int age, float score): m_score(score), People(name, age){ }
但是不管它们的顺序如何,派生类构造函数总是先调用基类构造函数再执行其他代码(包括参数初始化表以及函数体中的代码)。
基类构造函数不会被继承。(个人:应该是没有意义吧,构成函数是为了完成创建对象时的初始化工作,子类的初始化由它自己负责,继承基类的构造函数有什么用处?)
创建派生类对象时,会先调用基类构造函数,再调用派生类构造函数,构造函数的调用顺序是按照继承的层次自顶向下、从基类再到派生类的。
还有一点要注意,派生类构造函数只能调用直接基类的构造函数,不能调用间接基类的。事实上,通过派生类创建对象时必须要调用基类的构造函数,这是语法规定。换句话说,定义派生类构造函数时最好指明基类构造函数;如果不指明,就调用基类的默认构造函数(不带参数的构造函数);如果没有默认构造函数,那么编译失败。
和构造函数类似,析构函数也不能被继承。与构造函数不同的是,在派生类的析构函数中不用显式地调用基类的析构函数,因为每个类只有一个析构函数,编译器知道如何选择,无需程序员干涉。
另外析构函数的执行顺序和构造函数的执行顺序也刚好相反:
- 创建派生类对象时,构造函数的执行顺序和继承顺序相同,即先执行基类构造函数,再执行派生类构造函数。(个人:可能和继承类的内存模型有关,顺序是先基类的成员内存,然后是子类的成员内存,按照顺序生成各个成员)
- 而销毁派生类对象时,析构函数的执行顺序和继承顺序相反,即先执行派生类析构函数,再执行基类析构函数。(个人:销毁时和生成时的顺序刚好相反)
C++也支持多继承(Multiple Inheritance),即一个派生类可以有两个或多个基类。多继承容易让代码逻辑复杂、思路混乱,一直备受争议,中小型项目中较少使用,后来的 Java、C#、PHP 等干脆取消了多继承。
多继承的语法也很简单,将多个基类用逗号隔开即可。例如已声明了类A、类B和类C,那么可以这样来声明派生类D:
class D: public A, private B, protected C{
//类D新增加的成员
}
D 是多继承形式的派生类,它以公有的方式继承 A 类,以私有的方式继承 B 类,以保护的方式继承 C 类。D 根据不同的继承方式获取 A、B、C 中的成员,确定它们在派生类中的访问权限(个人:这个访问权限是针对派生类的用户而言的)。
基类构造函数的调用顺序和它们在派生类构造函数中出现的顺序无关,而是和声明派生类时基类出现的顺序相同。
当两个或多个基类中有同名的成员时,如果直接访问该成员,就会产生命名冲突,编译器不知道使用哪个基类的成员。这个时候需要在成员名字前面加上类名和域解析符::,以显式地指明到底使用哪个类的成员,消除二义性。(个人:也就是子类的作用域嵌入了多个基类作用域,如果多个基类中有同名成员时,在子类这个内层作用域中直接使用名字,则有多个外层基类作用域含有这个名字,这几个外层作用域地位是相等的,编译器不知道该选择哪个,所以会报错)
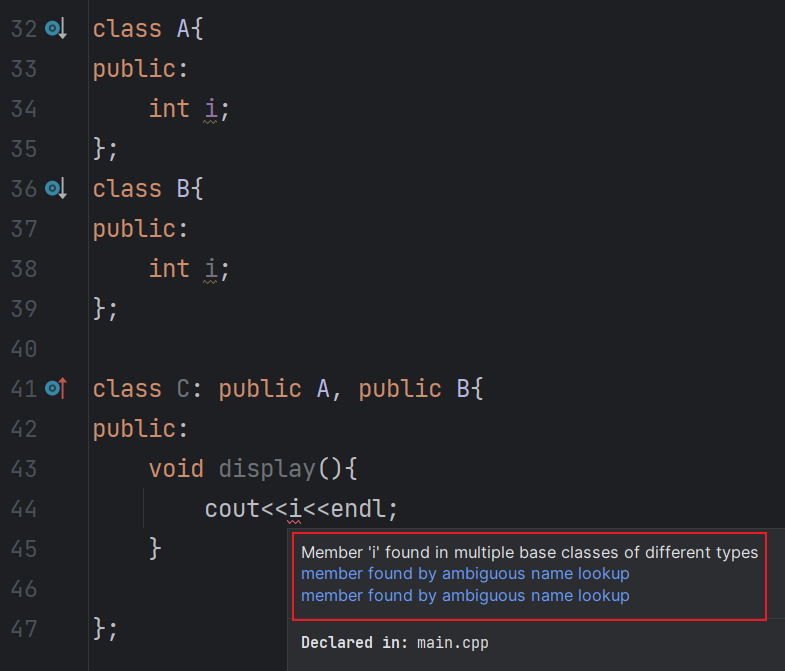
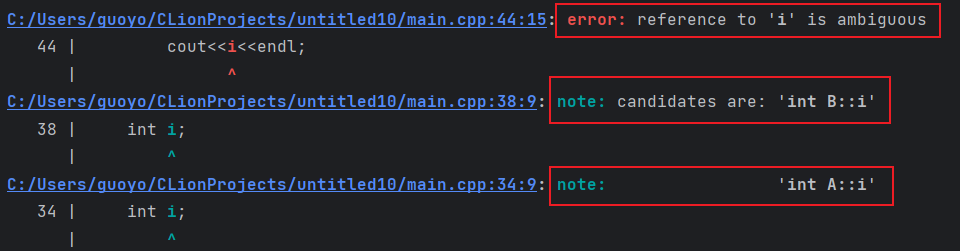
多继承时对象的内存模型,
//基类A
class A{
public:
A(int a, int b);
protected:
int m_a;
int m_b;
};
A::A(int a, int b): m_a(a), m_b(b){ }
//基类B
class B{
public:
B(int b, int c);
protected:
int m_b;
int m_c;
};
B::B(int b, int c): m_b(b), m_c(c){ }
//派生类C
class C: public A, public B{
public:
C(int a, int b, int c, int d);
public:
void display();
private:
int m_a;
int m_c;
int m_d;
};
C::C(int a, int b, int c, int d): A(a, b), B(b, c), m_a(a), m_c(c), m_d(d){ }
void C::display(){
printf("A::m_a=%d, A::m_b=%d\n", A::m_a, A::m_b);
printf("B::m_b=%d, B::m_c=%d\n", B::m_b, B::m_c);
printf("C::m_a=%d, C::m_c=%d, C::m_d=%d\n", C::m_a, C::m_c, m_d);
}
基类对象的排列顺序和继承时声明的顺序相同。(个人:在内存中的排列顺序也是初始化时的顺序,对单独的一个类的成员是如此,对存在多层单继承关系的子类的成员也是如此,对存在多继承的子类的成员也是如此)
我们都知道,C++ 不允许通过对象来访问 private、protected 属性的成员变量,无论通过对象变量还是对象指针,都不能访问 private 属性的成员变量。不过C++ 的这种限制仅仅是语法层面的,通过某种“蹩脚”的方法,我们能够突破访问权限的限制,访问到private、protected 属性的成员变量,赋予我们这种“特异功能”的,正是强大而又灵活的指针(Pointer)。
#include <iostream>
using namespace std;
class A{
public:
A(int a, int b, int c);
private:
int m_a;
int m_b;
int m_c;
};
A::A(int a, int b, int c): m_a(a), m_b(b), m_c(c){ }
int main(){
A obj(10, 20, 30);
int a = obj.m_a; //Compile Error
A *p = new A(40, 50, 60);
int b = p->m_b; //Compile Error
return 0;
}
在对象的内存模型中,成员变量和对象的开头位置会有一定的距离。以上面的 obj 为例,它的内存模型为:
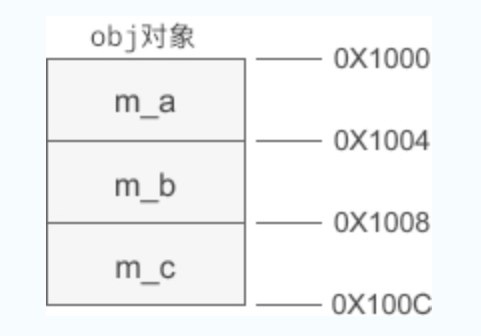
图中假设 obj 对象的起始地址为 0X1000,m_a、m_b、m_c 与对象开头分别相距 0、4、8 个字节,我们将这段距离称为偏移(Offset)。一旦知道了对象的起始地址,再加上偏移就能够求得成员变量的地址,知道了成员变量的地址和类型,也就能够轻而易举地知道它的值。当通过对象指针访问成员变量时,编译器实际上也是使用这种方式来取得它的值。为了说明问题,我们不妨将上例中成员变量的访问权限改为 public,再来执行第 16行的语句:
int b = p->m_b;
此时编译器内部会发生类似下面的转换:
int b = *(int*)( (int)p + sizeof(int) );
- p 是对象 obj 的指针,
- (int)p将指针转换为一个整数,这样才能进行加法运算;(个人:不然,就变成对一个指针做加法,则计算单元是指针所指类型的大小)
- sizeof(int)用来计算 m_b 的偏移;
- (int)p + sizeof(int)得到的就是m_b 的地址,
- 不过因为此时是int类型,所以还需要强制转换为int *类型;(个人:强制转化成的int *是指向m_b的指针类型)
- 开头的*用来获取地址上的数据。
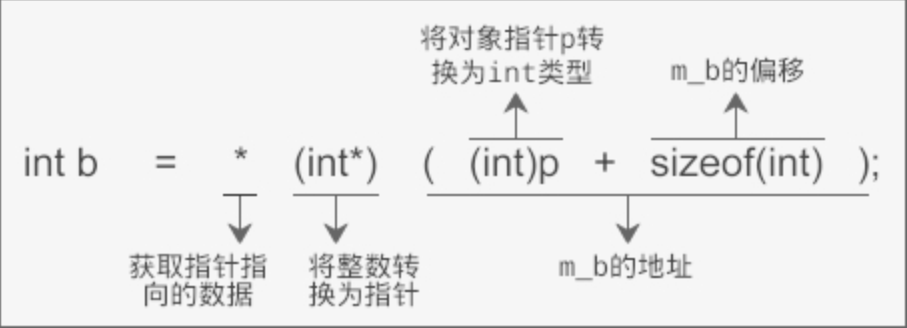
如果通过 p 指针访问 m_a:
int a = p -> m_a;
那么将被转换为下面的形式:
int a = * (int*) ( (int)p + 0 );
经过简化以后为:
int a = *(int*)p;
上述的转换过程是编译器自动完成的,当成员变量的访问权限为 private 时,我们也可以手动转换,只要能正确计算偏移即可,这样就突破了访问权限的限制。(个人:也就是当为private成员时,编译器会拒绝做这样的转换,直接报错,但是我们可以在代码中手工转换)
#include <iostream>
using namespace std;
class A{
public:
A(int a, int b, int c);
private:
int m_a;
int m_b;
int m_c;
};
A::A(int a, int b, int c): m_a(a), m_b(b), m_c(c){ }
int main(){
A obj(10, 20, 30);
int a1 = *(int*)&obj;
int b = *(int*)( (int)&obj + sizeof(int) );
A *p = new A(40, 50, 60);
int a2 = *(int*)p;
int c = *(int*)( (int)p + sizeof(int)*2 );
cout<<"a1="<<a1<<", a2="<<a2<<", b="<<b<<", c="<<c<<endl;
return 0;
}

前面我们说 C++ 的成员访问权限仅仅是语法层面上的,是指访问权限仅对取成员运算符.和->起作用,而无法防止直接通过指针来访问。你可以认为这是指针的强大,也可以认为是 C++ 语言设计的瑕疵。本节主要是让大家明白编译器内部的工作原理,以及指针的灵活运用。
多继承(Multiple Inheritance)是指从多个直接基类中产生派生类的能力,多继承的派生类继承了所有父类的成员。尽管概念上非常简单,但是多个基类的相互交织可能会带来错综复杂的设计问题,命名冲突就是不可回避的一个。(个人:多个基类外部作用域的地位是相同的,在子类这个内嵌内部作用域中,如果使用冲突的这个变量,编译器不知道该选择那个,会报错,当然,不过不引用,这些冲突的变量在各自的外部作用域中,不会报错),
#include <iostream>
using namespace std;
class A{
public:
int i;
};
class B{
public:
int i;
};
class C: public A, public B{
public:
void display(){
// cout<<i<<endl;
cout<<"hello world!"<<endl;
}
};
int main(){
class C obj;
obj.display();
return 0;
};

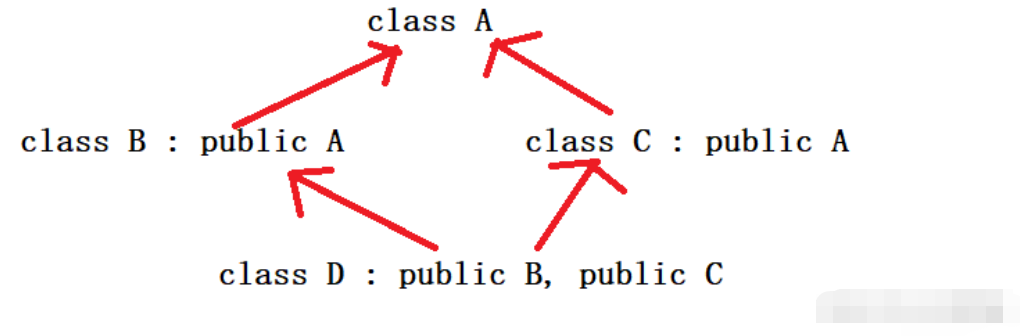
类 A 派生出类 B 和类 C,类 D 继承自类 B 和类 C,这个时候类 A 中的成员变量和成员函数继承到类 D 中变成了两份,一份来自 A-->B-->D 这条路径,另一份来自 A-->C-->D 这条路径。
//间接基类A
class A{
protected:
int m_a;
};
//直接基类B
class B: public A{
protected:
int m_b;
};
//直接基类C
class C: public A{
protected:
int m_c;
};
//派生类D
class D: public B, public C{
public:
void seta(int a){ m_a = a; } //命名冲突
void setb(int b){ m_b = b; } //正确
void setc(int c){ m_c = c; } //正确
void setd(int d){ m_d = d; } //正确
private:
int m_d;
};
int main(){
D d;
return 0;
}

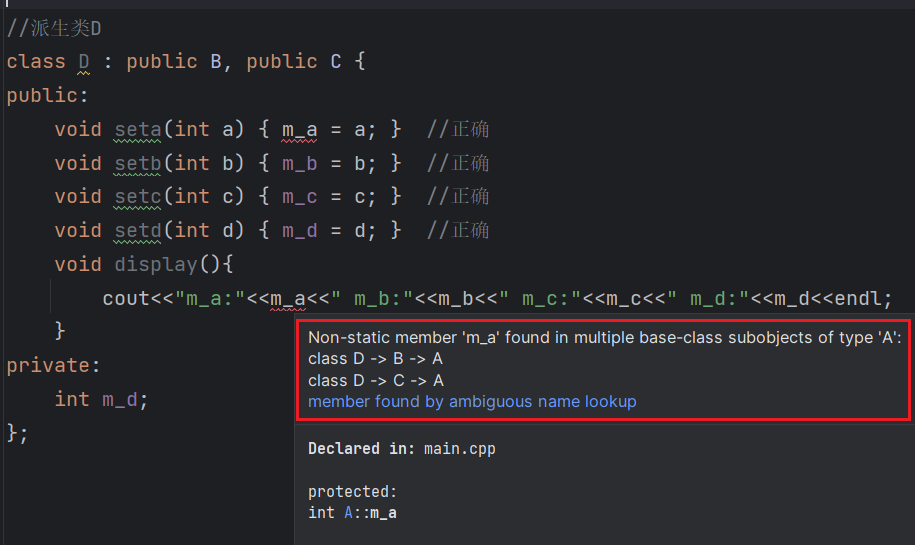
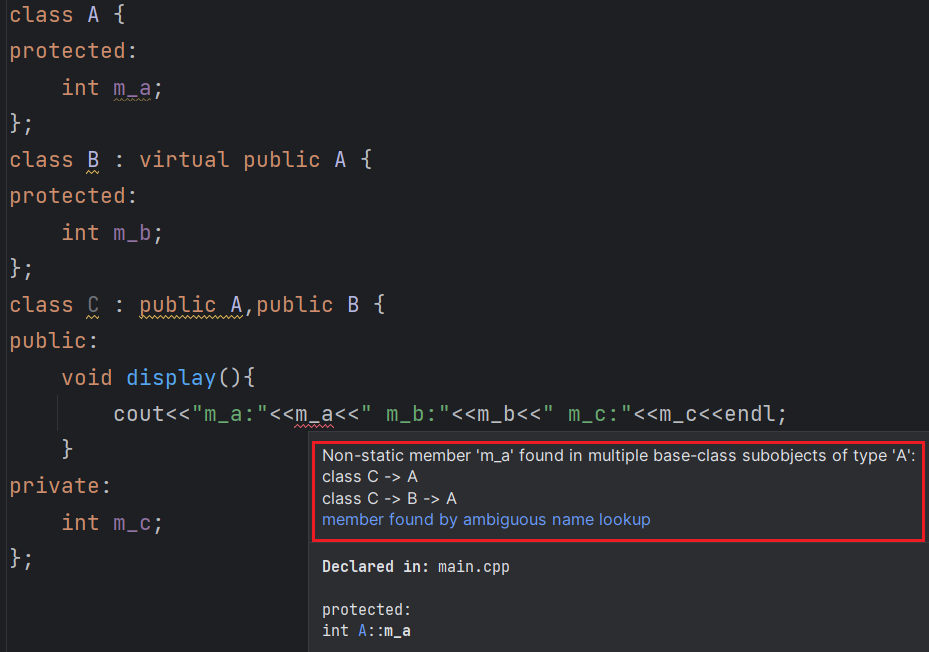
第19行代码试图直接访问成员变量 m_a,结果发生了错误,因为类B和类C中都有成员变量 m_a(从A类继承而来),编译器不知道选用哪一个,所以产生了歧义。
为了消除歧义,我们可以在 m_a 的前面指明它具体来自哪个类:
void seta(int a){ B::m_a = a; }
这样表示使用 B 类的 m_a。(个人:这里的B::m_a的意思是去到外层作用域B中去找m_a,当然在外层作用域B中更会去到更外层的作用域A中去找m_a)
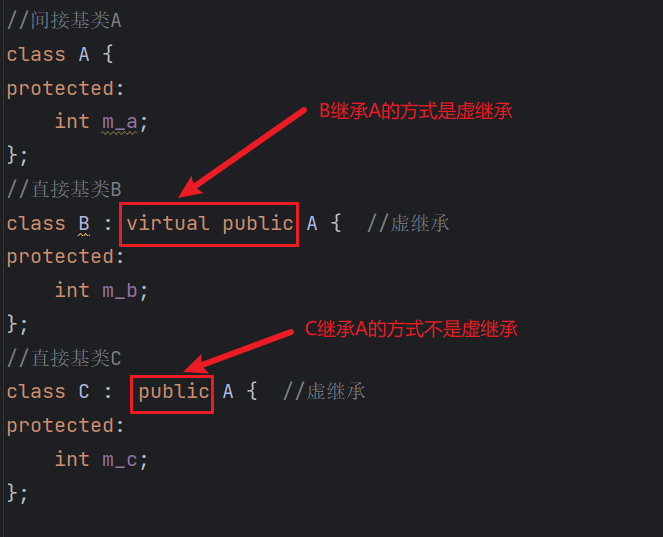
为了解决多继承时的命名冲突和冗余数据问题,C++ 提出了虚继承,使得在派生类中只保留一份间接基类的成员。在继承方式前面加上virtual关键字就是虚继承,请看下面的例子:
#include <iostream>
using namespace std;
//间接基类A
class A {
protected:
int m_a;
};
//直接基类B
class B : virtual public A { //虚继承
protected:
int m_b;
};
//直接基类C
class C : virtual public A { //虚继承
protected:
int m_c;
};
//派生类D
class D : public B, public C {
public:
void seta(int a) { m_a = a; } //正确
void setb(int b) { m_b = b; } //正确
void setc(int c) { m_c = c; } //正确
void setd(int d) { m_d = d; } //正确
void display(){
cout<<"m_a:"<<m_a<<" m_b:"<<m_b<<" m_c:"<<m_c<<" m_d:"<<m_d<<endl;
}
private:
int m_d;
};
int main() {
D d;
d.seta(1);
d.setb(2);
d.setc(3);
d.setd(4);
d.display();
return 0;
}

这段代码使用虚继承重新实现了上图所示的菱形继承,这样在派生类 D 中就只保留了一份成员变量 m_a,直接访问就不会再有歧义了。
(个人:上面的B和C继承A的方式都必须是虚继承,否则还是会有歧义)
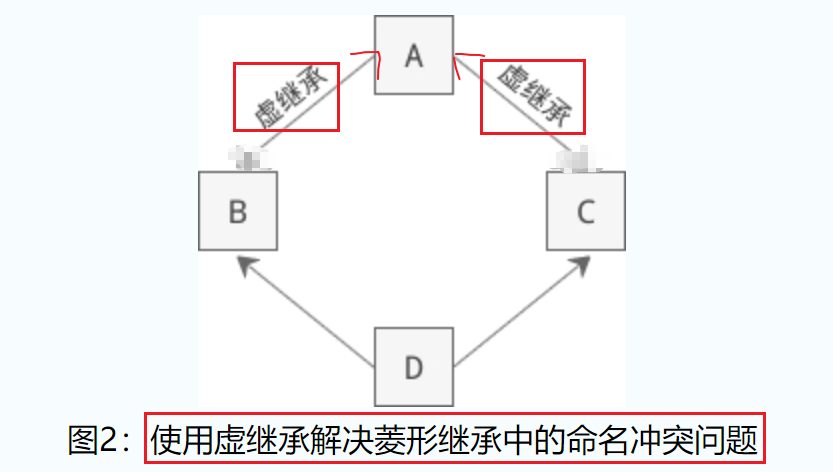
虚继承的目的是让某个类做出声明,承诺愿意共享它的基类。其中,这个被共享的基类就称为虚基类(Virtual Base Class),本例中的 A 就是一个虚基类。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
UML类图
观察这个新的继承体系,我们会发现虚继承的一个不太直观的特征:必须在虚派生的真实需求出现前就已经完成虚派生的操作。在上图中,当定义 D 类时才出现了对虚派生的需求,但是如果 B 类和 C 类不是从 A 类虚派生得到的,那么 D 类还是会保留 A 类的两份成员。



C++标准库中的 iostream 类就是一个虚继承的实际应用案例。
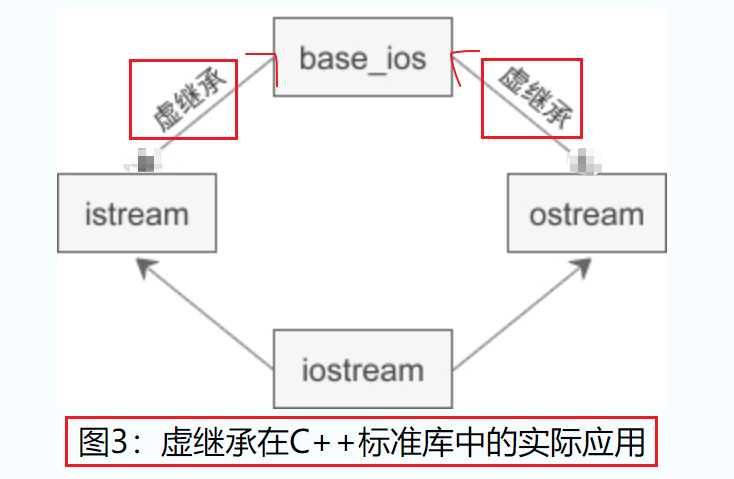
iostream 从 istream 和 ostream 直接继承而来,而 istream和ostream又都继承自一个共同的名为 base_ios 的类,是典型的菱形继承。此时 istream 和 ostream 必须采用虚继承,否则将导致 iostream 类中保留两份 base_ios 类的成员。

(个人:即使是这样,B虚继承A,还是不行)
As an example, the IO library istream and ostream classes each inherit from a
common abstract base class named basic_ios. That class holds the stream’s buffer
and manages the stream’s condition state. The class iostream, which can both read
and write to a stream, inherits directly from both istream and ostream. Because
both types inherit from basic_ios, iostream inherits that base class twice, once
through istream and once through ostream.
By default, a derived object contains a separate subpart corresponding to each class
in its derivation chain. If the same base class appears more than once in the
derivation, then the derived object will have more than one subobject of that type.
This default doesn’t work for a class such as iostream. An iostream object
wants to use the same buffer for both reading and writing, and it wants its condition
state to reflect both input and output operations. If an iostream object has two
copies of its basic_ios class, this sharing isn’t possible.
In C++ we solve this kind of problem by using virtual inheritance. Virtual
inheritance lets a class specify that it is willing to share its base class. The shared
base-class subobject is called a virtual base class. Regardless of how often the
same virtual base appears in an inheritance hierarchy, the derived object contains only
one, shared subobject for that virtual base class.


可以看到,使用多继承经常会出现二义性问题,必须十分小心。上面的例子是简单的,如果继承的层次再多一些,关系更复杂一些,程序员就很容易陷人迷魂阵,程序的编写、调试和维护工作都会变得更加困难,因此我不提倡在程序中使用多继承,只有在比较简单和不易出现二义性的情况或实在必要时才使用多继承,能用单一继承解决的问题就不要使用多继承。也正是由于这个原因,C++之后的很多面向对象的编程语言,例如Java、C#、PHP 等,都不支持多继承。
在虚继承中,虚基类是由最终的派生类初始化的,换句话说,最终派生类的构造函数必须要调用虚基类的构造函数。对最终的派生类来说,虚基类是间接基类,而不是直接基类。这跟普通继承不同,在普通继承中,派生类构造函数中只能调用直接基类的构造函数,不能调用间接基类的。
#include <iostream>
using namespace std;
//虚基类A
class A{
public:
A(int a);
protected:
int m_a;
};
A::A(int a): m_a(a){ }
//直接派生类B
class B: virtual public A{
public:
B(int a, int b);
public:
void display();
protected:
int m_b;
};
B::B(int a, int b): A(a), m_b(b){ }
void B::display(){
cout<<"m_a="<<m_a<<", m_b="<<m_b<<endl;
}
//直接派生类C
class C: virtual public A{
public:
C(int a, int c);
public:
void display();
protected:
int m_c;
};
C::C(int a, int c): A(a), m_c(c){ }
void C::display(){
cout<<"m_a="<<m_a<<", m_c="<<m_c<<endl;
}
//间接派生类D
class D: public B, public C{
public:
D(int a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
D::D(int a, int b, int c, int d): A(a), B(90, b), C(100, c), m_d(d){ }
void D::display(){
cout<<"m_a="<<m_a<<", m_b="<<m_b<<", m_c="<<m_c<<", m_d="<<m_d<<endl;
}
int main(){
B b(10, 20);
b.display();
C c(30, 40);
c.display();
D d(50, 60, 70, 80);
d.display();
return 0;
}
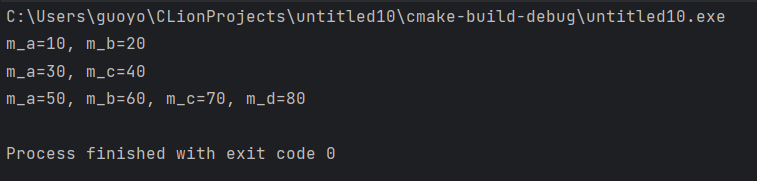
请注意第 50 行代码,在最终派生类 D 的构造函数中,除了调用 B 和 C 的构造函数,还调用了A的构造函数,这说明 D 不但要负责初始化直接基类 B 和 C,还要负责初始化间接基类A。而在以往的普通继承中,派生类的构造函数只负责初始化它的直接基类,再由直接基类的构造函数初始化间接基类,用户尝试调用间接基类的构造函数将导致错误。
现在采用了虚继承,虚基类 A 在最终派生类 D 中只保留了一份成员变量 m_a,如果由 B 和 C 初始化 m_a,那么 B 和 C 在调用 A 的构造函数时很有可能给出不同的实参,这个时候编译器就会犯迷糊,不知道使用哪个实参初始化 m_a。为了避免出现这种矛盾的情况,C++ 干脆规定必须由最终的派生类 D 来初始化虚基类 A,直接派生类 B 和 C 对 A 的构造函数的调用是无效的。在第 50 行代码中,调用 B 的构造函数时试图将 m_a 初始化为 90,调用 C 的构造函数时试图将 m_a 初始化为 100,但是输出结果有力地证明了这些都是无效的,m_a 最终被初始化为 50,这正是在 D 中直接调用 A 的构造函数的结果。
另外需要关注的是构造函数的调用顺序。虚继承时构造函数的执行顺序与普通继承时不同:在最终派生类的构造函数调用列表中,不管各个构造函数出现的顺序如何,编译器总是先调用虚基类的构造函数,再按照多重继承时声明的顺序调用其他的构造函数;
- 简单的面向对象,只有单继承或多继承的情况下,内存模型很好理解,编译器实现起来也容易,C++ 的效率和 C 的效率不相上下。
- 一旦和 virtual 关键字扯上关系,使用到虚继承或虚函数,内存模型就变得混乱起来,各种编译器的实现也不一致,让人抓狂。这是因为 C++ 标准仅对 C++ 的实现做了框架性的概述,并没有规定细节如何实现,所以不同厂商的编译器在具体实现方案上会有所差异,
本节我们只关注虚继承时的内存模式。
对于普通继承,基类子对象始终位于派生类对象的前面(也即基类成员变量始终在派生类成员变量的前面),而且不管继承层次有多深,它相对于派生类对象顶部的偏移量是固定的。请看下面的例子:
class A{
protected:
int m_a1;
int m_a2;
};
class B: public A{
protected:
int b1;
int b2;
};
class C: public B{
protected:
int c1;
int c2;
};
class D: public C{
protected:
int d1;
int d2;
};
int main(){
A obj_a;
B obj_b;
C obj_c;
D obj_d;
return 0;
}
obj_a、obj_b、obj_c、obj_d 的内存模型如下所示:
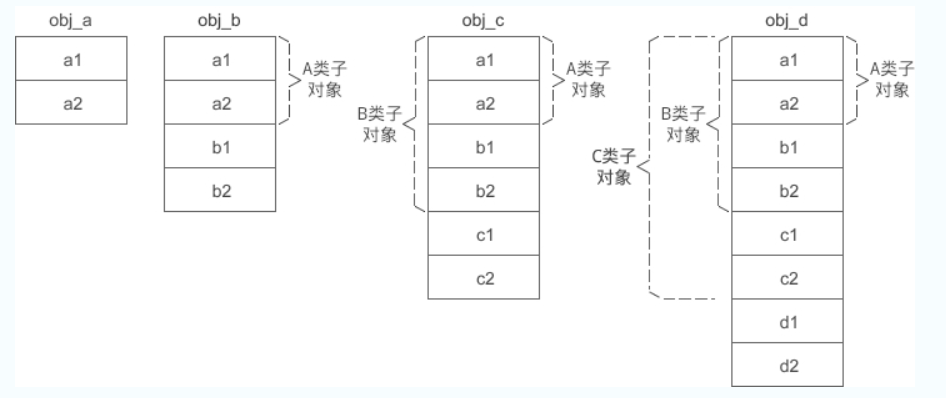
A 是最顶层的基类,在派生类 B、C、D 的对象中,A 类子对象始终位于最前面,偏移量是固定的,为 0。b1、b2 是派生类 B 的新增成员变量,它们的偏移量也是固定的,分别为 8 和 12。c1、c2、d1、d2 也是同样的道理。
前面我们说过,编译器在知道对象首地址的情况下,通过计算偏移来存取成员变量。
- 对于普通继承,基类成员变量的偏移是固定的,不会随着继承层级的增加而改变,存取起来非常方便。
- 而对于虚继承,恰恰和普通继承相反,大部分编译器会把基类成员变量放在派生类成员变量的后面,这样随着继承层级的增加,基类成员变量的偏移就会改变,就得通过其他方案来计算偏移量。
下面我们来一步一步地分析虚继承时的对象内存模型。
- 修改上面的代码,使得 A 是 B 的虚基类:
class B: virtual public A
此时 obj_b、obj_c、obj_d 的内存模型就会发生变化,如下图所示:

不管是虚基类的直接派生类还是间接派生类,虚基类的子对象始终位于派生类对象的最后面。
- 再假设 A 是 B 的虚基类,B 又是 C 的虚基类,那么各个对象的内存模型如下图所示:
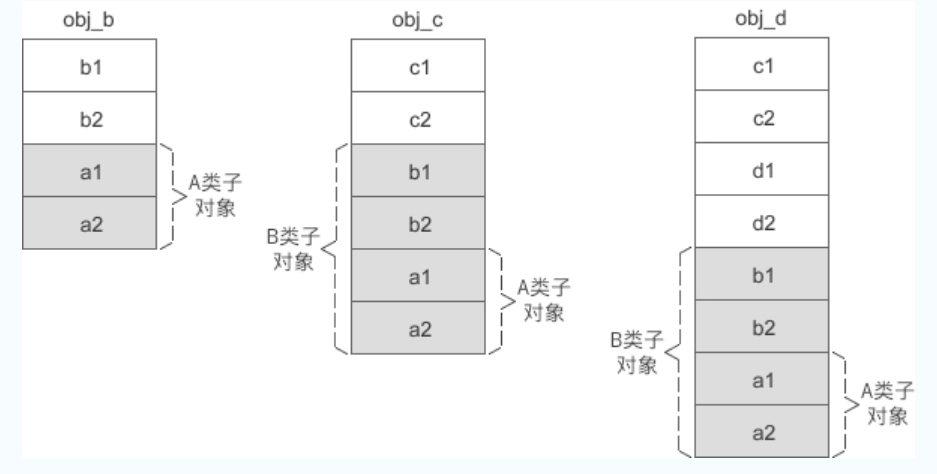
从上面的两张图中可以发现,虚继承时的派生类对象被分成了两部分:
- 不带阴影的一部分偏移量固定,不会随着继承层次的增加而改变,称为固定部分;
- 带有阴影的一部分是虚基类的子对象,偏移量会随着继承层次的增加而改变,称为共享部分。
当要访问对象的成员变量时,需要知道对象的首地址和变量的偏移,对象的首地址很好获得,关键是变量的偏移。
- 对于固定部分,偏移是不变的,很好计算;
- 而对于共享部分,偏移会随着继承层次的增加而改变,这就需要设计一种方案,在偏移不断变化的过程中准确地计算偏移。各个编译器正是在设计这一方案时出现了分歧,不同的编译器设计了不同的方案来计算共享部分的偏移。
- 对于虚继承,将派生类分为固定部分和共享部分,并把共享部分放在最后,几乎所有的编译器都在这一点上达成了共识。主要的分歧就是如何计算共享部分的偏移,可谓是百花齐放,没有统一标准。
早期的cfront编译器会在派生类对象中安插一些指针,每个指针指向一个虚基类的子对象,要存取继承来的成员变量,可以使用指针间接完成。
1) 如果 A 是 B 的虚基类,那么各个对象的实际内存模型如下所示:
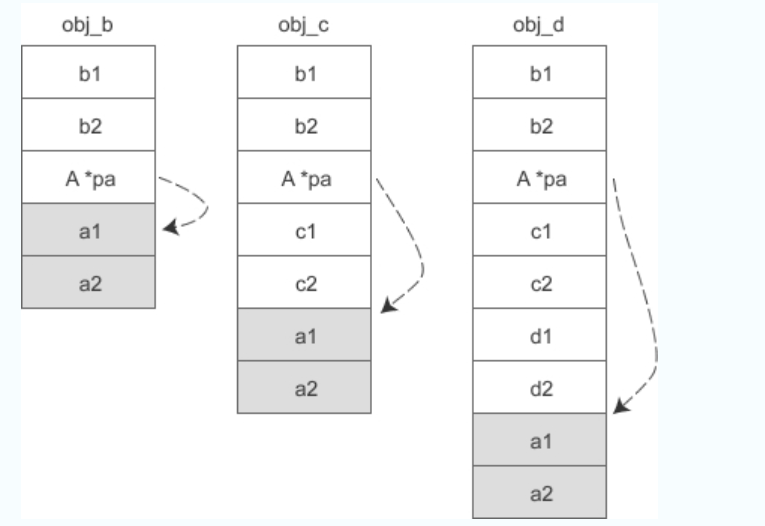
编译器会在直接派生类的对象obj_b中安插一个指针,指向虚基类 A 的起始位置,并且这个指针的偏移是固定的,不会随着继承层次的增加而改变。当要访问 a1、a2 时,要先通过对象指针找到 pa,再通过 pa 找到 a1、a2,这样一来就比没有虚继承时多了一层间接。假设 p 是obj_d 的指针,现在要访问成员变量 a2:
int member_a2 = p -> a2;
那么编译器内部会进行类似下面的转换:
A *pa = (A*)( *(int*)( (int)p + sizeof(int)*2 ) ); int member_a2 = *(int*)( (int)pa + sizeof(int) );
(个人:上面的转换对于pa好像不对,应该是:A *pa = (A*)( (int)p + sizeof(int)*2);)
2) 如果 A 是 B 的虚基类,同时 B 也是 C 的虚基类,那么各个对象的实际内存模型如下所示:
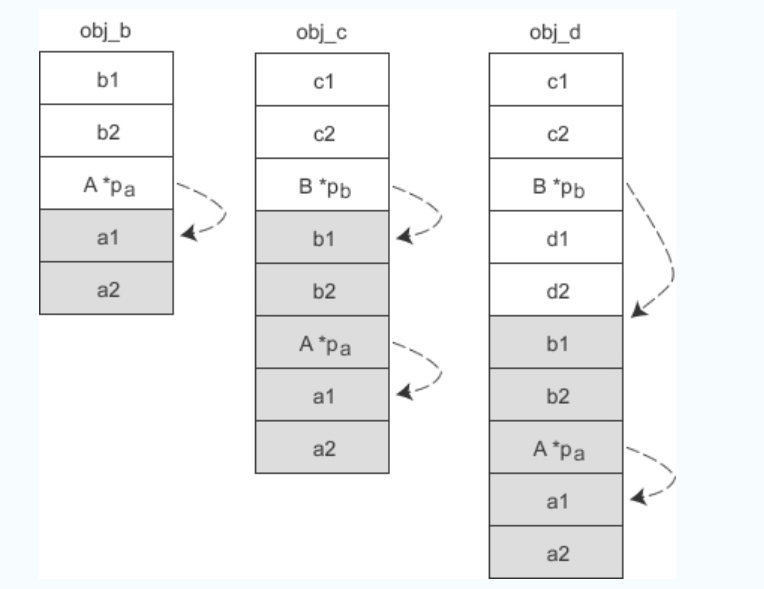
当要访问 a1、a2 时,要先通过对象指针找到 pb,再通过 pb 找到 pa,最后才能通过 pa 找到 a1、a2,这样一来就比没有虚继承时多了两层间接。
通过上面的分析可以发现,
- 这种方案的一个缺点就是,随着虚继承层次的增加,访问顶层基类需要的间接转换会越来越多,效率越来越低。
- 这种方案另外的一个缺点是:当有多个虚基类时,派生类要为每个虚基类都安插一个指针,会增加对象的体积。例如,假设 A、B、C、D 类的继承关系为:
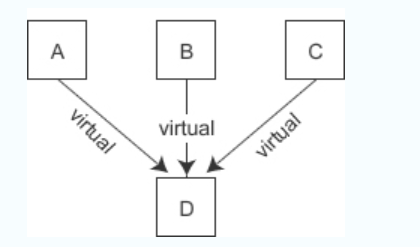
obj_d 的内存模型如下图所示:
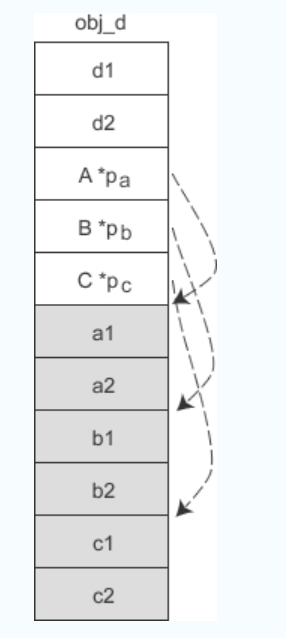
D 有三个虚基类,所以 obj_d 对象要额外背负三个指针 pa、pb、pc。
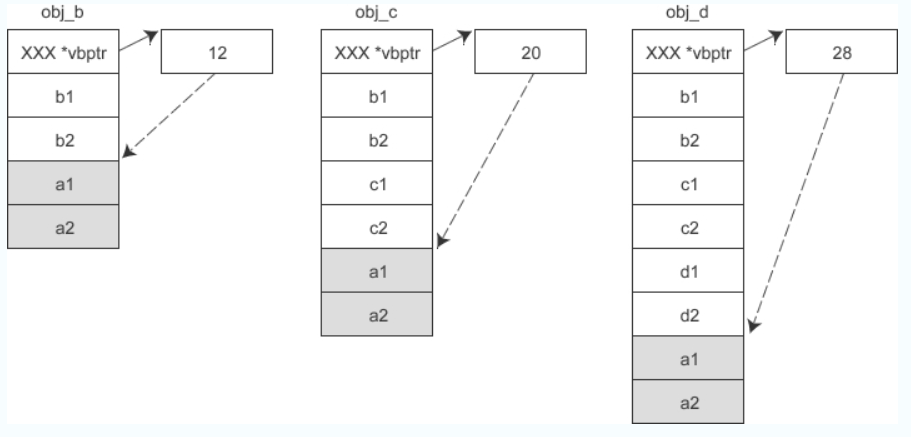
cfront 的后来者VC尝试对上面的方案进行了改进,一定程度上弥补了它的不足。VC 引入了虚基类表,如果某个派生类有一个或多个虚基类,编译器就会在派生类对象开头安插一个指针,指向虚基类表。虚基类表其实就是一个数组,数组中的元素存放的是各个虚基类的偏移。
- 假设 A 是 B 的虚基类,那么各对象的内存模型如下图所示:
- 假设 A 是 B 的虚基类,同时 B 又是 C 的虚基类,那么各对象的内存模型如下图所示:
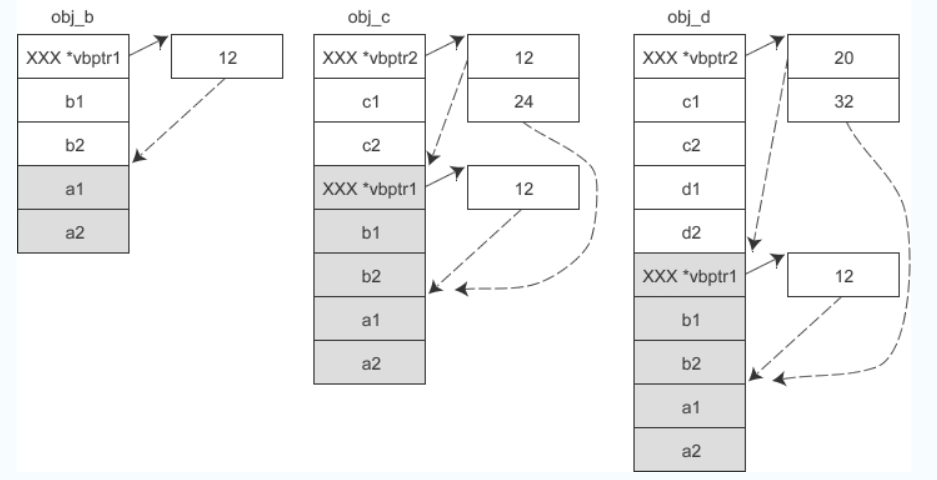
虚继类表中保存的是所有虚基类(包括直接继承和间接继承到的)相对于当前对象的偏移,这样通过派生类指针访问虚基类的成员变量时,不管继承层次都多深,只需要一次间接转换就可以。 (个人:也就是这里一个派生类的开头的指针指向的数组保存的是这个派生类的所有虚基类相对于当前对象的偏移,仅通过这个数组,不需要其他的辅助,就可以找到所有的虚基类的成员变量,这里的vbptr1是作为类B的内存的一部分,是天然存在的,对于类D的对象而言,我们要访问虚基类的成员,只需要依靠类D对象开头的指针vbptr2即可,不需要借助于vbptr1的帮助)
- 另外,这种方案还可以避免有多个虚基类时让派生类对象额外背负过多的指针。例如,假设 A、B、C、D 类的继承关系为:
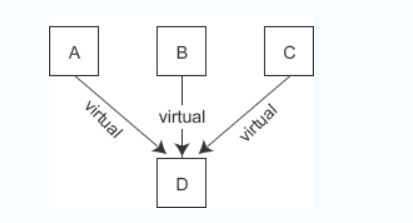
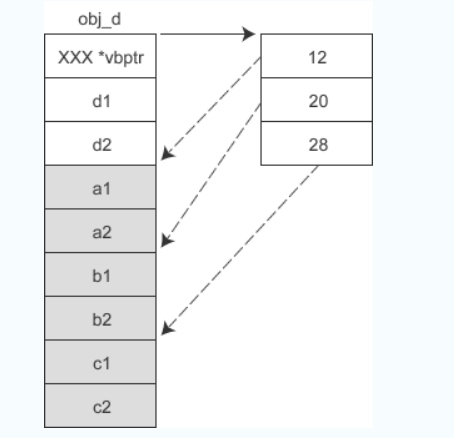
如此一来,D 类虽然有三个虚基类,但它的对象 obj_d 只需要额外背负一个指针。
在 C/C++ 中经常会发生数据类型的转换,例如将 int 类型的数据赋值给 float 类型的变量时,编译器会先把 int 类型的数据转换为 float 类型再赋值;反过来,float 类型的数据在经过类型转换后也可以赋值给 int 类型的变量。
数据类型转换的前提是,编译器知道如何对数据进行取舍。例如:
int a = 10.9;
printf("%d\n", a);
输出结果为 10,编译器会将小数部分直接丢掉(不是四舍五入)。再如:
float b = 10;
printf("%f\n", b);
输出结果为 10.000000,编译器会自动添加小数部分。
类其实也是一种数据类型,也可以发生数据类型转换,不过这种转换只有在基类和派生类之间才有意义,并且只能将派生类赋值给基类,包括将派生类对象赋值给基类对象、将派生类指针赋值给基类指针、将派生类引用赋值给基类引用,这在 C++ 中称为向上转型(Upcasting)。相应地,将基类赋值给派生类称为向下转型(Downcasting)。 向上转型非常安全,可以由编译器自动完成;向下转型有风险,需要程序员手动干预。(个人:对于存在继承关系的类指针,编译器可以自动将子类的指针转换为指向基类的指针,但是对于普通的内置类型指针,指向相近类型的指针则编译器不会自动转换)向上转型和向下转型是面向对象编程的一种通用概念,它们也存在于 Java、C# 等编程语言中。
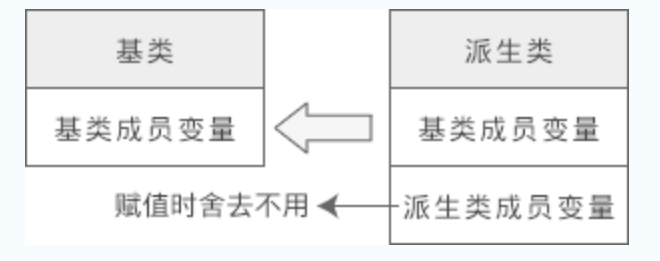
可以发现,即使将派生类对象赋值给基类对象,基类对象也不会包含派生类的成员,所以依然不能通过基类对象来访问派生类的成员。
这种转换关系是不可逆的,只能用派生类对象给基类对象赋值,而不能用基类对象给派生类对象赋值。理由很简单,基类不包含派生类的成员变量,无法对派生类的成员变量赋值。同理,同一基类的不同派生类对象之间也不能赋值。
要理解这个问题,还得从赋值的本质入手。赋值实际上是向内存填充数据,当数据较多时很好处理,舍弃即可;本例中将 b 赋值给 a 时(执行a=b;语句),成员 m_b 是多余的,会被直接丢掉,所以不会发生赋值错误。但当数据较少时,问题就很棘手,编译器不知道如何填充剩下的内存;如果本例中有b= a;这样的语句,编译器就不知道该如何给变量 m_b 赋值,所以会发生错误。
#include <iostream>
using namespace std;
//基类A
class A {
public:
A(int a);
public:
void display();
protected:
int m_a;
};
A::A(int a) : m_a(a) { }
void A::display() {
cout << "Class A: m_a=" << m_a << endl;
}
//中间派生类B
class B : public A {
public:
B(int a, int b);
public:
void display();
protected:
int m_b;
};
B::B(int a, int b) : A(a), m_b(b) { }
void B::display() {
cout << "Class B: m_a=" << m_a << ", m_b=" << m_b << endl;
}
//基类C
class C {
public:
C(int c);
public:
void display();
protected:
int m_c;
};
C::C(int c) : m_c(c) { }
void C::display() {
cout << "Class C: m_c=" << m_c << endl;
}
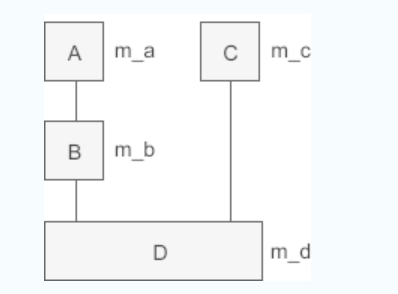
//最终派生类D
class D : public B, public C {
public:
D(int a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
D::D(int a, int b, int c, int d) : B(a, b), C(c), m_d(d) { }
void D::display() {
cout << "Class D: m_a=" << m_a << ", m_b=" << m_b << ", m_c=" << m_c << ", m_d=" << m_d << endl;
}
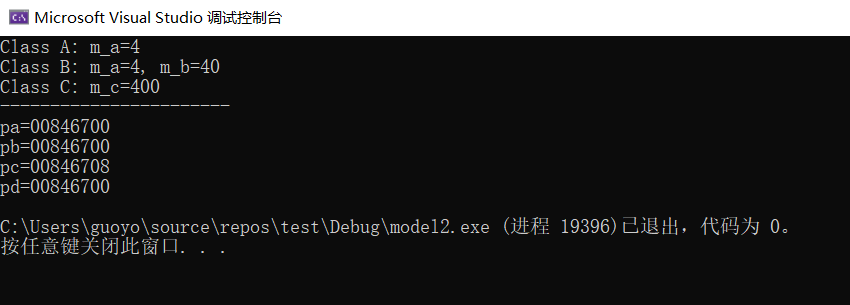
int main() {
A* pa = new A(1);
B* pb = new B(2, 20);
C* pc = new C(3);
D* pd = new D(4, 40, 400, 4000);
pa = pd;
pa->display();
pb = pd;
pb->display();
pc = pd;
pc->display();
cout << "-----------------------" << endl;
cout << "pa=" << pa << endl;
cout << "pb=" << pb << endl;
cout << "pc=" << pc << endl;
cout << "pd=" << pd << endl;
return 0;
}
#include <iostream>
using namespace std;
int main(){
double pi = 3.14159;
int n = pi;
cout<<pi<<", "<<n<<endl;
return 0;
}
将派生类的指针赋值给基类的指针时也是类似的道理,编译器也可能会在赋值前进行处理。要理解这个问题,首先要清楚 D 类对象的内存模型,如下图所示:
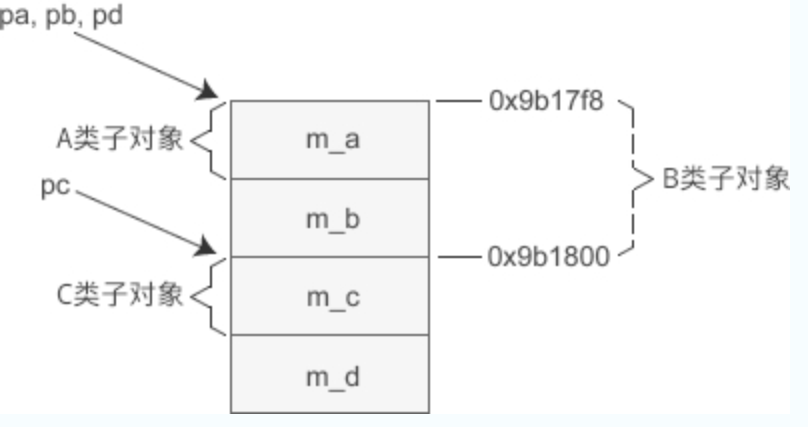
- 首先要明确的一点是,对象的指针必须要指向对象的起始位置。
- 对于 A 类和 B 类来说,它们的子对象的起始地址和 D 类对象一样,所以将 pd 赋值给 pa、pb 时不需要做任何调整,直接传递现有的值即可;
- 而C类子对象距离D类对象的开头有一定的偏移,将 pd 赋值给 pc 时要加上这个偏移,这样pc才能指向C类子对象的起始位置。也就是说,执行pc = pd;语句时编译器对 pd 的值进行了调整,才导致 pc、pd 的值不同。
下面的代码演示了将 pd 赋值给 pc 时编译器的调整过程:
pc = (C*)( (int)pd + sizeof(B) );
如果我们把 B、C 类的继承顺序调整一下,让 C 在 B 前面,如下所示:
class D: public C, public B
那么输出结果就会变为:
pa=0x317fc pb=0x317fc pc=0x317f8 pd=0x317f8
