

(转载)GPT-3阅读笔记:Language Models are Few-Shot Learners
论文地址:《Language Models are Few-Shot Learners》
Abstract
- 提出问题:最近的许多研究都表明pre-train模型搭配下游任务fine-tune在许多情况下效果显著,但是微调过程需要大量的样本。这一框架不符合人类的习惯,人类只需要少量的示例或说明便能适应一个新的NLP下游任务。
- 主要贡献:本文证明了通过增大参数量就能让语言模型显著提高下游任务在Few-shot(仅给定任务说明和少量示例)设置下的性能。(笔者注:证明了大规模语言模型使用元学习策略的可能和fine-tune策略的非必要性)
- 具体贡献:
- 训练了包含175billion参数(以往非稀疏语言模型的10倍大小)的GPT3自回归语言模型,并在多个数据集上测试没有fine-tune过程的性能表现。
- 虽然GPT3在文本翻译、问答系统、完型填空、新词使用和代数运算等任务表现不错,但在阅读理解和推理任务数据集上的表现仍有待提高。
- 由于GPT-3的训练依赖于大量的网页语料,所以模型在部分测试数据集上可能出现方法论级别的data contamination问题。
- GPT3能够编写出人类难以区分的新闻文章,本文讨论了该能力的社会影响力。
1 Introduction
- 提出问题:许多基于RNN或Transformer结构的语言模型通过“pre-train + fine-tune”过程在阅读理解、问答系统等任务中有不俗的性能。然而本文认为上述架构最大的问题在于必须拥有大量的下游任务fine-tune样本才能取得很好的性能。因此,本文基于下述原因认为移除fine-tune是必要的:
- 每一个新的任务都需要大量的标记数据是不利于语言模型的应用的。
- 提升模型表征能力的同时降低数据分布的复杂度是不合理的。比如,大模型并不能在样本外推预测时具有好效果,这说明fine-tune导致模型的泛化性降低了。
- 人类在接触一个下游语言任务时不需要大量的样本,只需要一句对新任务的描述或者几个案例。人类这种无缝融合和切换多个任务的能力是我们当前自然语言技术所欠缺的。
- 模型移除fine-tune有2个解决方案:
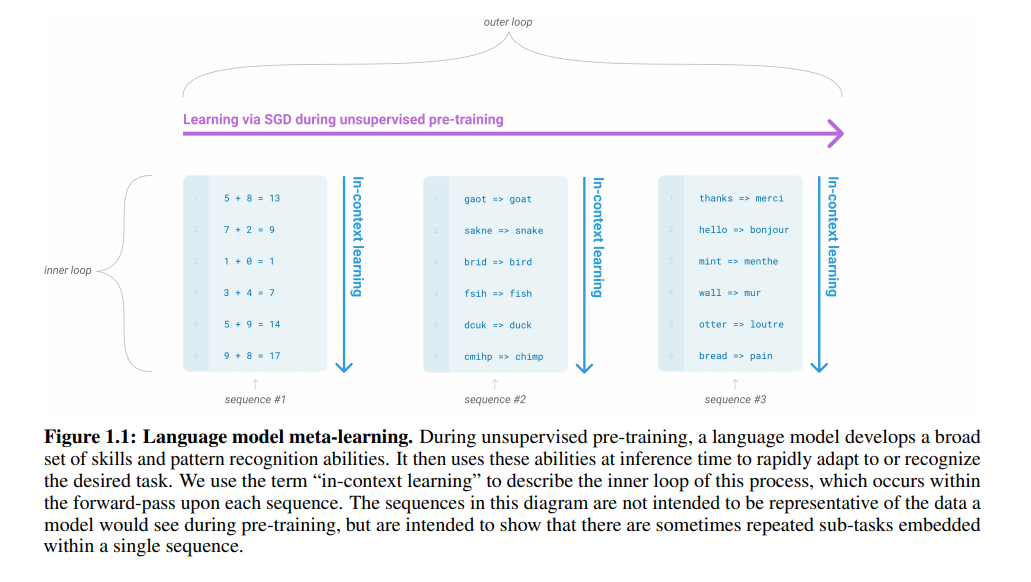
- meta-learning(如图1.1):模型在训练阶段具备了一系列模式识别的能力和方法,并通过在预测过程中利用这些能力和方法以快速适应一个下游任务。最近的一些研究尝试通过称为in-context learning的方法来实现上述过程,然而效果距离期待的相差甚远。
- Large scale transformers:Transformer语言模型参数的每一次增大都会让文本理解能力和其他的NLP下游任务的性能得到提升。此外,有研究指出描述许多下游任务性能的log损失能让模型的性能和参数之间服从一个平滑趋势。考虑到in-context learning会将学习到的知识和方法存在模型的参数中,本文假设:模型的情境学习能力也会随着参数规模的增长而增长。
- 情境学习(in-context learning):在被给定的几个任务示例或一个任务说明的情况下,模型应该能通过简单预测以补全任务中其他的实例。即,情境学习要求预训练模型要对任务本身进行理解。情境学习三种分类的定义和示例如下:
- few-shot learning
- 定义:允许输入数条范例和一则任务说明
- 示例:向模型输入“这个任务要求将中文翻译为英文。你好->hello,再见->goodbye,购买->purchase,销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell”。
- one-shot learning
- 定义:只允许输入一条范例和一则任务说明
- 示例:向模型输入“这个任务要求将中文翻译为英文。你好->hello,销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell”。
- zero-shot learning
- 定义:不允许输入任何范例,只允许输入一则任务说明
- 示例:向模型输入“这个任务要求将中文翻译为英文。销售->”,然后要求模型预测下一个输出应该是什么,正确答案应为“sell”。
- 本文研究内容:本文训练了一个拥有175billion参数的自回归语言模型(GPT-3),并利用两组NLP数据集和一些全新的数据集评估了模型的情境学习能力和快速适应新任务能力。对于每一个任务,作者都测试了模型“few-shot learning”,“one-shot learning”和“zero-shot learning”三种条件的性能。虽然GPT-3也支持fine-tune过程,但本文并未测试。
- 关于GPT-3的研究结果:
- 整体上,GPT-3在zero-shot或one-shot设置下能取得尚可的成绩,在few-shot设置下有可能超越基于fine-tune的SOTA模型。
- zero-shot和one-shot设置的GPT-3能在快速适应和即时推理任务(单词整理、代数运算和利用只出现过一次的单词)中拥有卓越表现。
- few-shot设置的GPT-3能够生成人类难以区分的新闻文章。
- 通常不同参数的模型在三种条件(zero-shot,one-shot和few-shot)下的性能差异变化较为平稳的,但是参数较多的模型在三种条件下的性能差异较为显著。本文猜测:大模型更适合于使用“元学习”框架。
- 本文发现few-shot设置的模型在自然语言推理任务(如ANLI数据集)上和机器阅读理解(如RACE或QuAC数据集)的性能有待提高。未来的研究可以聚焦于语言模型的few-shot learning部分,并关注哪些发展是最需要的。
- 关于data contamination的研究结果:
- 问题定义:因为高性能模型的训练依赖于大量的网页语料如Common Crawl数据集,所以测试集中的语料可能由于已经在网页中出现过而在训练集中被模型看到过。
- 解决方案:本文提出了一个系统化的工具来衡量data contamination情况并量化它的影响。
- 图1.1:语言模型的meta-learning过程
- 在非监督预训练期间,语言模型积累了大量的模式识别能力,并将这些能力用在推理过程中,以求快速适应新的任务。我们用“in-context learning”来描述这个过程中的inner loop,这些inner loop发生在每个序列的正向传递中。图1.1告诉我们许多时候单一的序列中重复包含多个子任务的嵌入。
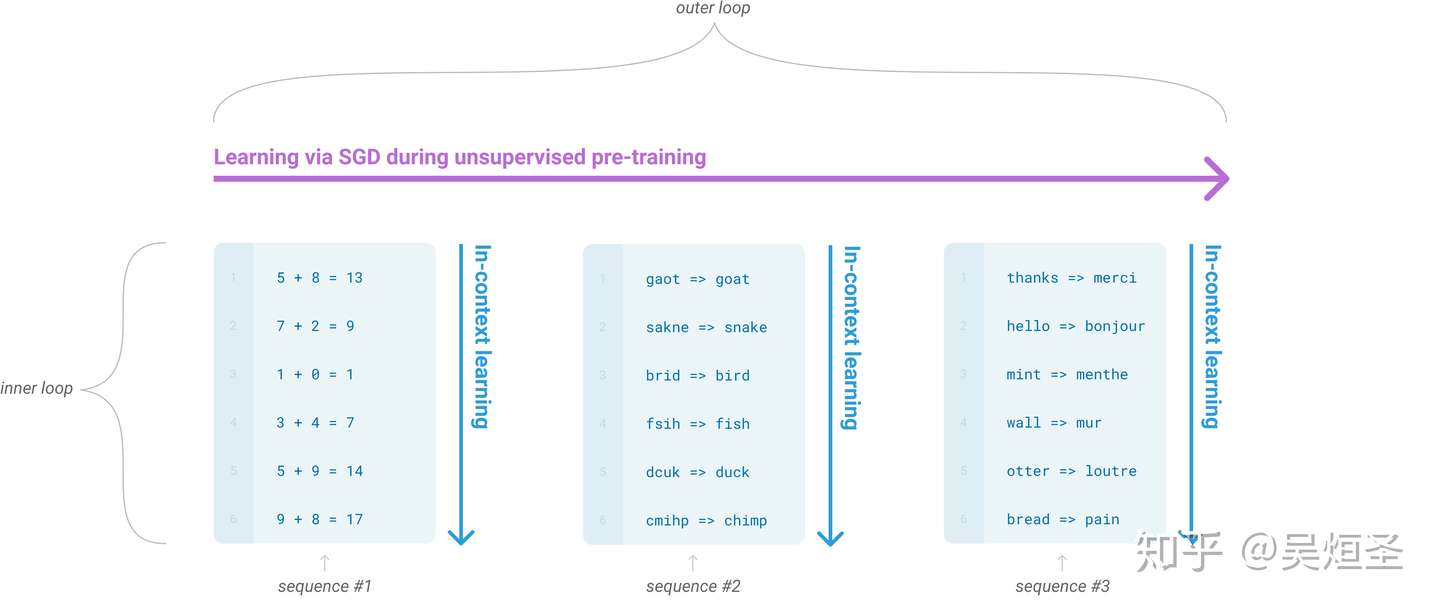
- 图1.2:更大的模型拥有更强的利用情境信息能力
- 我们定义了一个简单的任务,要求模型移除一个单词中的随机符号。图1.2展示了模型在给定或未给定一段文本形式的任务描述下的情境学习性能。
- 那根陡峭的蓝色线告诉我们从环境信息中学习任务的能力。不仅在图1.2中明显可以看出模型的性能随着增加文本形式的任务描述或者增加模型参数而增加,模型性能和模型尺寸与情境样本数关系的趋势在许多其他的任务中都有体现。作者特别强调这几根数据线与finetune无任何关系,仅仅将增加示例数量作为限制条件。
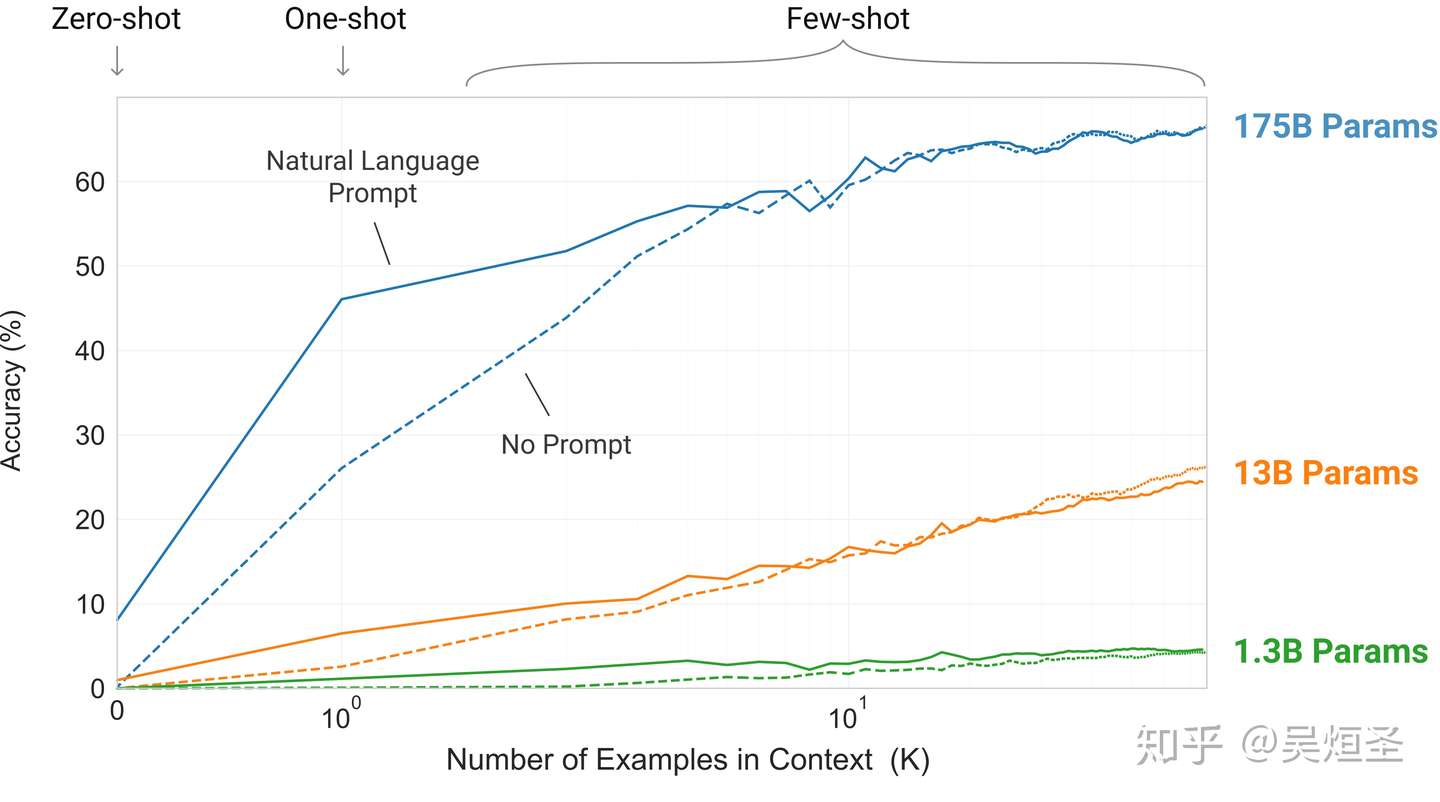
- 图1.3: 聚合了模型在42个基准数据集上的性能
- 因为zero-shot设置下的模型性能随着模型参数的增加稳定上升,few-shot设置下的模型性能随着模型参数的增加急剧增加,所以本文认为大模型适合情境学习。
2 Approach
