

GPT2
前言
GPT2是OPen AI发布的一个预训练语言模型,见论文《Language Models are Unsupervised Multitask Learners》,GPT-2在文本生成上有着惊艳的表现,其生成的文本在上下文连贯性和情感表达上都超过了人们的预期。仅从模型架构而言,GPT-2 并没有特别新颖的架构,GPT-2继续沿用了原来在GPT中使用的单向 Transformer 模型,而这篇文章的目的就是尽可能利用单向Transformer的优势,做一些BERT使用的双向Transformer所做不到的事。那就是通过上文生成下文文本。
相对于模型的庞大尺寸与使用的大量数据,它的思想才是最重要的。GPT2的核心思想就是认为可以用无监督的预训练模型去做有监督任务。GPT2模型的结构还是和GPT一样,它所适用的任务恰好是语言模型,即预测\(p(s_n|s_1,s_2,...,s_{n-1})\),这是大家再熟悉不过的公式。那为什么这个就能做有监督任务呢?平常的套路难道不是语言模型预训练+微调吗?
按照原文的思路,作者是这样论述的:
- 语言模型其实也是在给序列的条件概率建模,即\(p(s_{n-k},...,s_n|s_1,s_2,...,s_{n-k-1})\)
- 任何的有监督任务,其实都是在估计\(p(output|input)\),通常我们会用特定的网络结构去给任务建模,但如果要做通用模型,它需要对\(p(output|input,task)\)建模。对于NLP任务的input和output,我们平常都可以用向量表示,而对于task,其实也是一样的。18年已经有研究对task进行过建模了,这种模型的一条训练样本可以表示为:(translate to french,English text,french text),或者表示为:(answer the question,document,question,answer).也就是说,已经证实了,以这种数据形式可以有监督地训练一个single model,其实也就是对一个模型进行有监督的多任务学习。
- 语言模型=无监督多任务学习。相比于有监督的多任务学习,语言模型只是不需要显示地定义哪些字段是要预测的输出,所以,实际上有监督的输出只是语言模型序列中的一个子集。举个例子,比如我在训练语言模型时,有一句话“The translation of word Machine Learning in chinese is 机器学习”,那在训练完这句话时,语言模型就自然地将翻译任务和任务的输入输出都学到了。再比如,又碰到一句话“美国的总统是特朗普”,这一句话训练完,也就是一个小的问答了。
总的来说,GPT2有以下几个特点:
- 适用于文本生成任务
- 仍然固执地用单向语言模型,而不是双向语言模型,
- 生成内容后续单词这种模式,单向语言模型更方便;
- 想证明通过增加数据量和模型结构,单向模型未必输双向模型。
- 核心是构建通用NLP模型:通常我们会用特定的网络结构去给任务建模,GPT2构建通用NLP模型,对p(output | input, task)建模。output ,input, task三者都用向量表示。
- 在训练的时候,采用了多任务的方式,不单单只在一个任务上进行学习,而是多个,每一个任务都要保证其损失函数能收敛,不同任务是共享主体Transformer参数的,进一步提升模型的泛化能力,因此在即使没有fine-tuning的情况下,依旧有非常不错的表现。
- 在fine-tuning有监督任务阶段,GPT-2根据给定输入与任务来做出相应的输出,那么模型就可以表示成下面这个样子:\(p(output∣input,task)\),例如可以直接输入:(“自然语言处理”, 中文翻译)来得到我们需要的结果(“Nature Language Processing”),因此提出的模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个任务,而不再为每一个子任务单独设计一个模型。
- 用无监督的预训练模型去做有监督任务:把第二阶段替换由Finetuning有监督,换成了无监督做下游任务,因为它扔进去了好多任务数据,且有提示词。GPT2训练好的语言模型,如何无监督适应下游任务,比如文本摘要,怎么知道是在做文本摘要任务呢?
- 首先,所有任务都采取相同的往出蹦字的输出模式。GPT2.0给出了一种新颖的生成式任务的做法,就是一个字一个字往出蹦,然后拼接出输出内容作为翻译结果或者摘要结果。
- GPT-2的输入也会加入提示词,比如输入格式是 文本+TL;DR:,GPT-2模型就会知道是做摘要工作了。
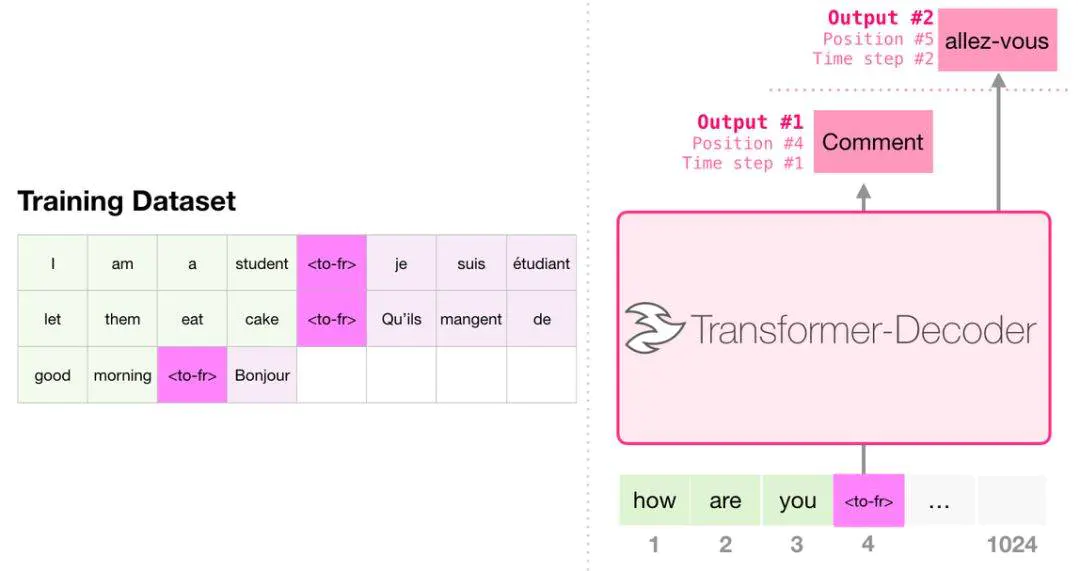
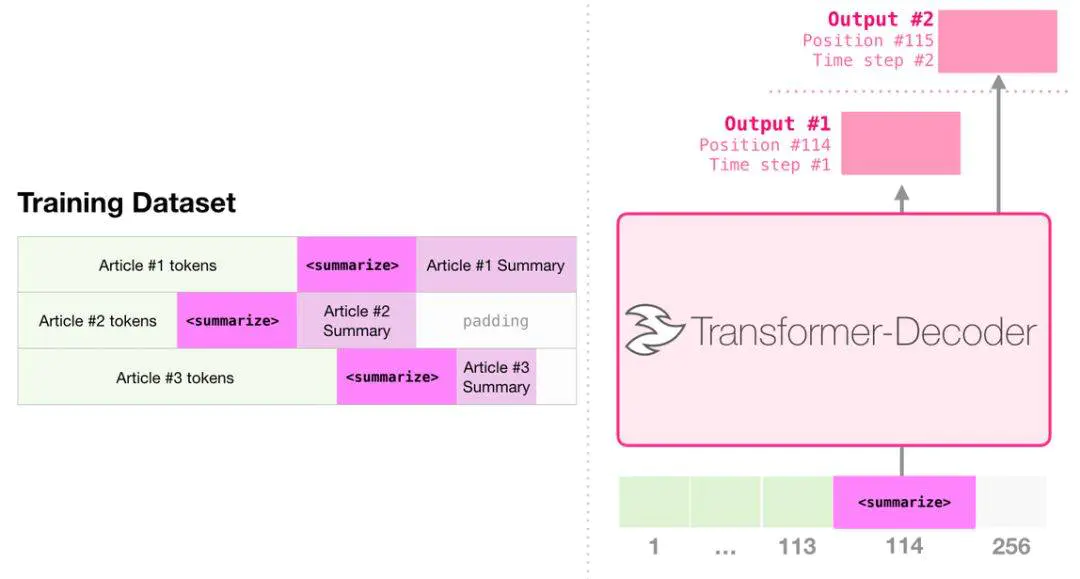
GPT2与GPT的不同点
- GPT-2去掉了fine-tuning训练:只有无监督的pre-training阶段,不再针对不同任务分别进行微调建模,而是不定义这个模型应该做什么任务,模型会自动识别出来需要做什么任务。这就好比一个人博览群书,你问他什么类型的问题,他都可以顺手拈来,GPT-2就是这样一个博览群书的模型。学习的是一个通用NLP模型。
- 增加数据集:既然要博览群书,当然得先有书,所以GPT-2收集了更加广泛、数量更多的语料组成数据集。数据集包含800万个网页,大小为40G。GPT2需要的是带有任务信息的数据。
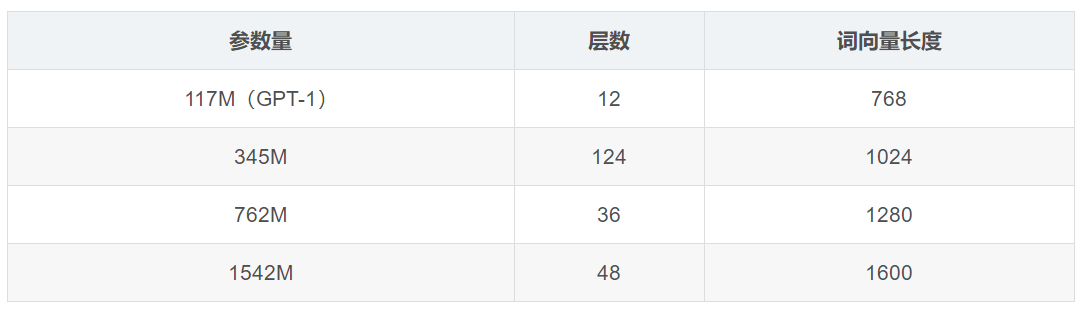
- 增加网络参数:GPT-2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量更是达到了15亿(Bert large是3.4亿)。「小号」12 层,「中号」24 层,「大号」36 层,「特大号」48 层。GPT-2训练了4组不同的层数和词向量的长度的模型,见表:
- 调整transformer:将layernorm放到每个sub-block之前;在最终自注意块之后添加了额外的层标准化;
GPT2:
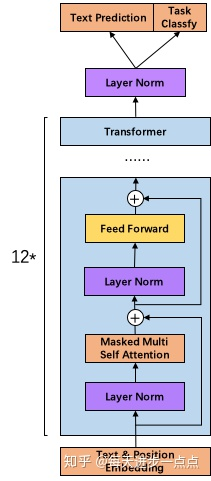
GPT:
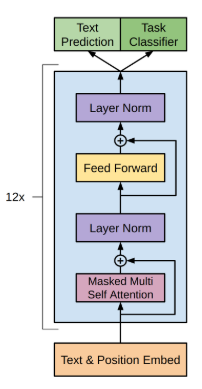
- 将残差层的初始化值用 \(\frac{1}{\sqrt(N)}\) 进行缩放,其中N是残差层的个数
- 其他:GPT-2将词汇表增加到5万(bert英文是3万,中文是2万);embedding size包括768,1024,1280,1600;可处理单词序列长度从GPT的512提升到1024;batchsize增加到512。
