

MacBERT
前言
相信做中文NLP的朋友们,对哈工大和科大讯飞发布的一系列中文预训练模型(https://github.com/ymcui/)
并不陌生。它们在各个预训练原论文的基础上,基于中文语料,发布了诸如BERT、RoBERTa、ELECTRA、XLNet等模型,极大推动了中文NLP的发展。
不同的预训练模型用了不同的tricks,但由于论文的发表是以英文为主的,这些tricks移植到中文,是否还是有效的?于是,他们在2020年也发表了一个新的预训练模型,叫MacBERT,只针对中文,在各种中文评测任务都取得SOTA的效果。
下图很好地概述了各种预训练模型的区别。
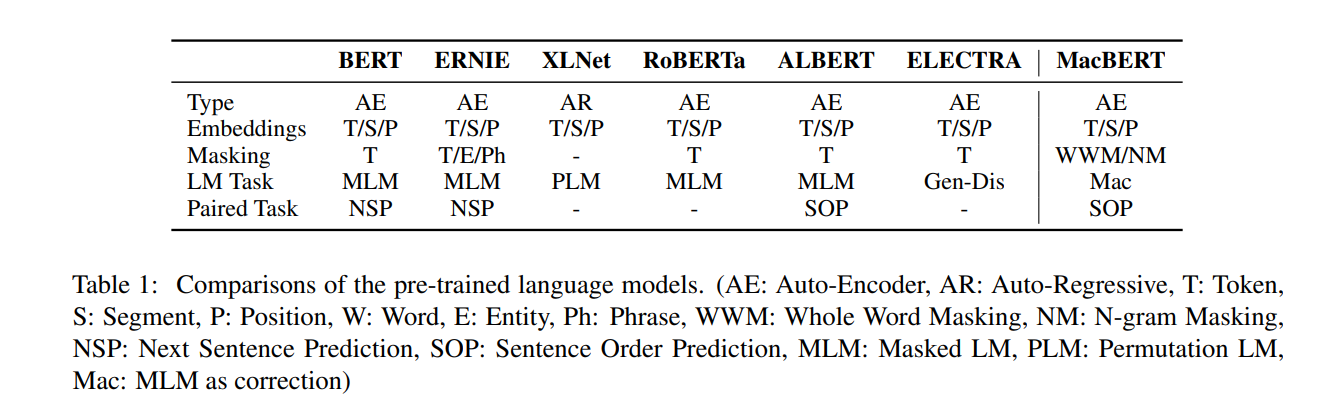
MacBERT,全称:MLM as correction BERT,从全称可以看出,MacBERT主要是修改的是BERT的MLM任务。
MacBERT

WordPiece:在BERT和RoBERTa的英文版里面,都采用的是WordPiece,具体的看上图,最小的token切分单位并不是单个英文词,而是更细粒度的切分,如图中 predict 这个词被切分成pre、##di、##ct三个token(##表示非完整单词,而且是某个单词的非开头部分),这种切分方式的好处在于能缓解未见词的问题,也更加丰富了词表的表征能力。但对于中文来说,并没有WordPiece的切分法,因为中文最小单位就是字,并不能像英文一样,再把词切分成字母的组合,也有人讨论把中文字按照偏旁或拼音进行更细的切分,这个就不在本次的讨论范围内了。
Whole word masking(wwm):虽然token是最小的单位,但在[MASK]的时候是基于分词的,例如,"使用语言模型来预测下一个词的概率。"进行tokenizer后,变成"使 用 语 言 模 型 来 预 测 下 一 个 词 的 概 率 。"。论文中,使用中文分词工具LTP来决定词的边界,如分词后,变成"使用 语言 模型 来 预测 下一个 词 的 概率 。",在【MASK】的时候,是对分词后的结构进行【MASK】的(如不能只【MASK】掉"语"这个token,要不就把“语 言”都【MASK】掉),
N-gram Masking的意思是对连续n个词进行【MASK】,如图中把“语 言 模 型”都【MASK】了,就是一个2-gram Masking。虽然【MASK】是对分词后的结果进行,但在输入的时候还是单个的token。
MacBERT采用基于分词的n-gram masking,1-gram~4gram Masking的概率分别是40%、30%、20%、10%。
用相似词代替【MASK】
大家吐槽BERT的其中一点是预训练的输入和应用于下游任务时不一样,预训练时有【MASK】作为输入,但在下游任务时,并没有【MASK】,这种差异会极大影响模型的应用效果。
作者采用了利用近义词来代替被【MASK】掉的词。
Q:怎么选择近义词?
用的是叫Synonyms这款工具,这款工具也是基于word2vec计算的。举个例子,现在"语 言"这两个token作为一个词,被挑选到进行【MASK】,用Synonyms计算与它欧氏距离最近的词向量,为"言语",那在输入的时候,就用“言 语”来代替。当然也存在一种情况,被【MASK】掉的词没有近义词(这里可能有人有疑问,用word2vec计算余弦相似度的时候一定会能返回最近的一个啊,也就是所有词都能找出离它距离最近的一个词。但是假如就算最近,但是它们的距离也很远的情况下,我们就认为这个词没有近义词,我们可以通过阈值来判断这个词有没有近义词),这种情况下,我们用随机词代替【MASK】。
最终,MacBERT的输入如下,对基于分词后的结果随机挑选15%的词进行【MASK】,其中
- 80%用同义词代替;
- 10%用随机词代替;
- 10%保持不变。
然后预测这15%的词,可以看到,预训练的时候,再也没有【MASK】的身影了。
对于NSP任务,采用同ALBERT一样的sentence-order predicion(SOP)任务,预测这两个句子对是正序还是逆序。
实验设置
作者除了采用中文维基百科外(这也是原生中文BERT采用的训练语料),还采用了其它中文百科全书、新闻、问答网站,加起来一共5.8B个词。
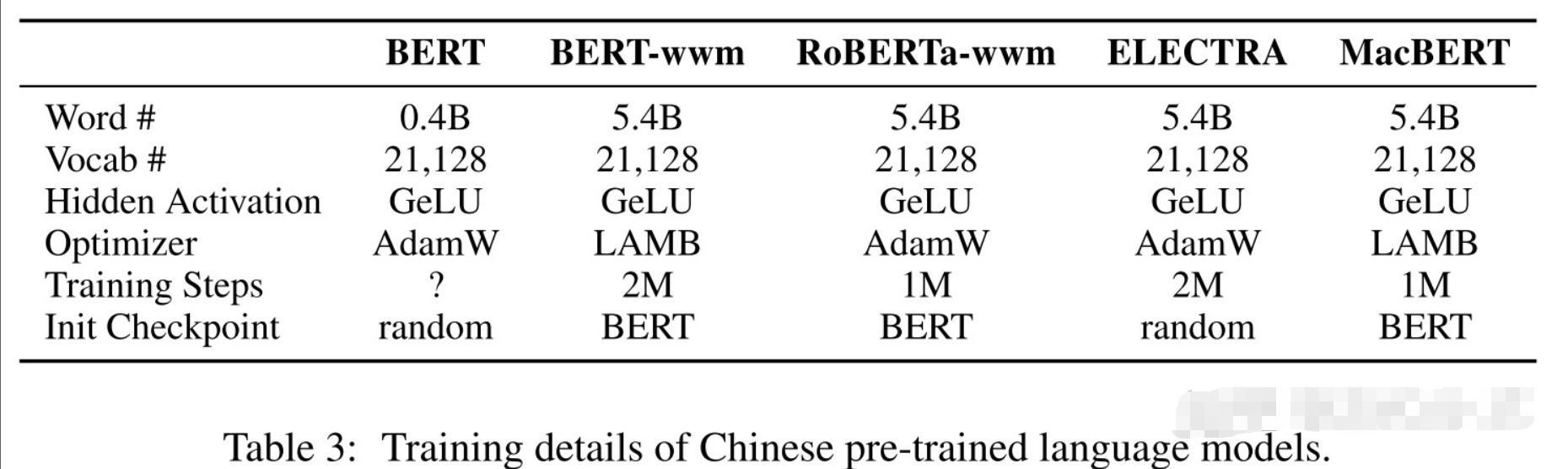
为了能利用到其它预训练模型的信息,MacBERT并不是从头开始训练的,而是用谷歌官方的Chinese BERT-base进行参数初始化,但是对于large版本,是重新训练的,因为谷歌官方没有发布Chinese BERT的large版本。下图为MacBERT与其它预训练模型的细节对比。
分别采用了三种类型的任务来进行评测,包括机器阅读理解、单句文本分类和文本对分类,结果自然都是非常不错的,这里就不把实验结果post出来了。
消融实验
我认为这篇论文里面,消融实验是很重要的部分,因为它能再次显示出作者提出方法的动机。
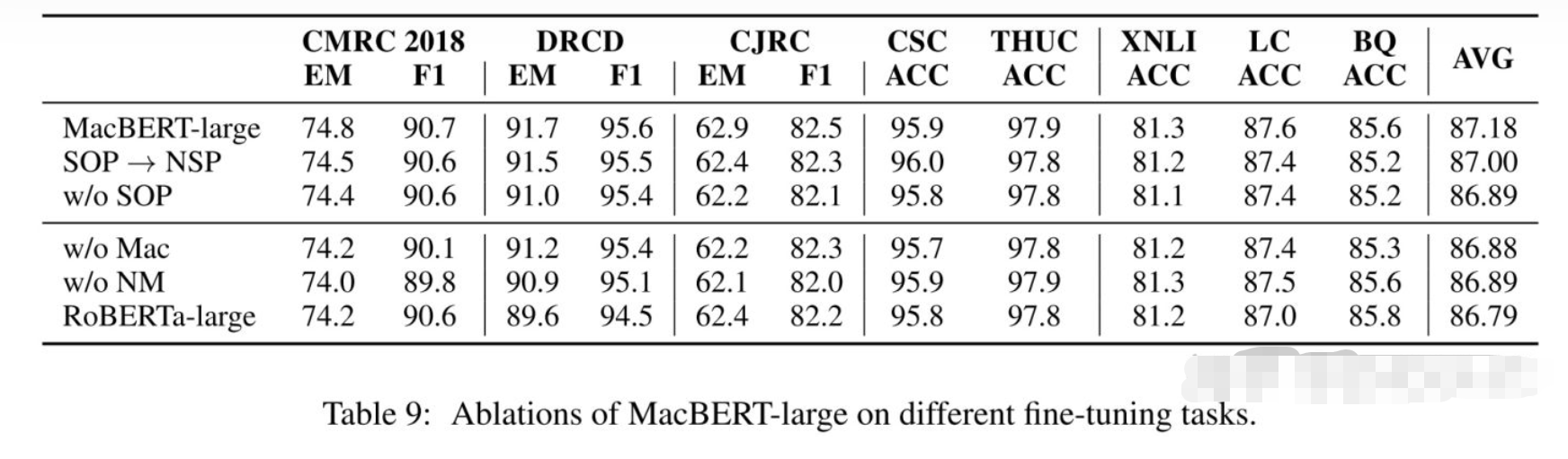
这里w/o Mac表示去掉同义词替换,w/o NM表示去掉N-gram masking,
- 实验表明,去掉它们都会损害性能。
- 除此之外,实验还表明NSP-like任务相对MLM任务来说,对模型没那么重要(这也提醒我们应该花更多时间研究改进MLM任务上),SOP任务要比NSP任务要好。
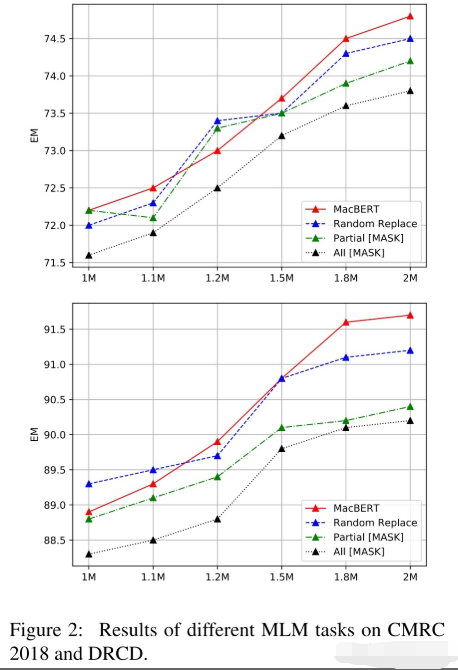
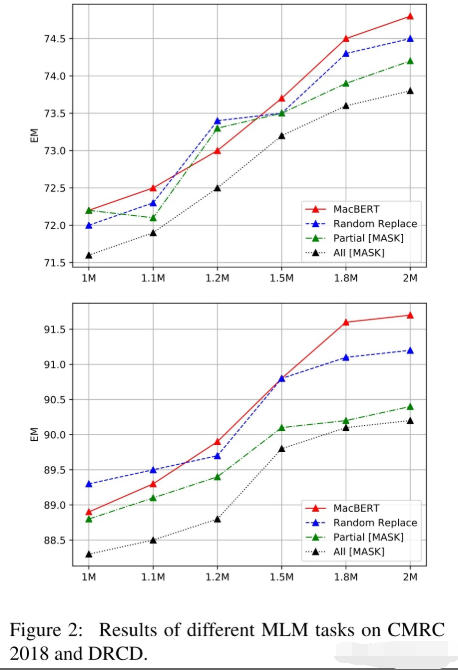
为了讨论改进MLM任务的影响,采用了下面四种对比,首先我们沿用前面的对15%词进行【MASK】,其中的10%用原来的token代替
- MacBERT:80%用同义词代替,10%用随机词;
- Random Replace:90%用随机词代替;
- Partial Mask:同原生的BERT一样,80%用【MASK】代替,10%用随机词;
- ALL Mask:90%用【MASK】代替。
实验结果MacBERT表现最好,除此之外,预训练时,保留【MASK】作为输入会极大地影响下游任务的性能。甚至把【MASK】用随机的token代替(Random Replace),都会比原生BERT(Partial Mask)要好。
参考
Revisiting Pre-Trained Models for Chinese Natural Language Processing
