

ERNIE 2.0
前言
ERNIE 2.0见论文《ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding》,ERNIE2.0的结构与 ERNIE1.0 、BERT 一样,ERNIE2.0主要是从修改预训练任务来提升效果。
从BERT推出,到现在被广泛使用也有近三年的时间,这几年也有不少其它预训练模型的出现,它们大部分干的一件事就是提出难度更大、更多样化的预训练任务,从而增加模型的学习难度,让模型有更好的词语、语法、语义的表征能力!ERNIE2.0 正是如此,构建了三种类型的无监督任务。为了完成多任务的训练,又提出了连续多任务学习,整体框架见下图。
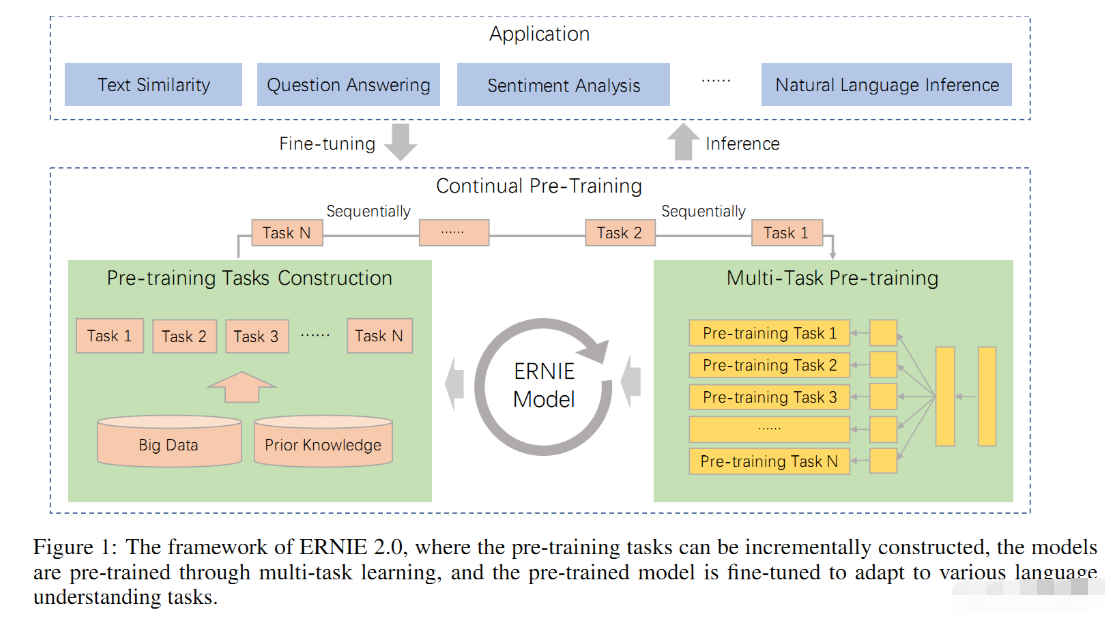
改进1:连续多任务学习
假如让模型同时学3个任务(即目前比较火的联合训练),你会怎么训练?这里提供三种策略:
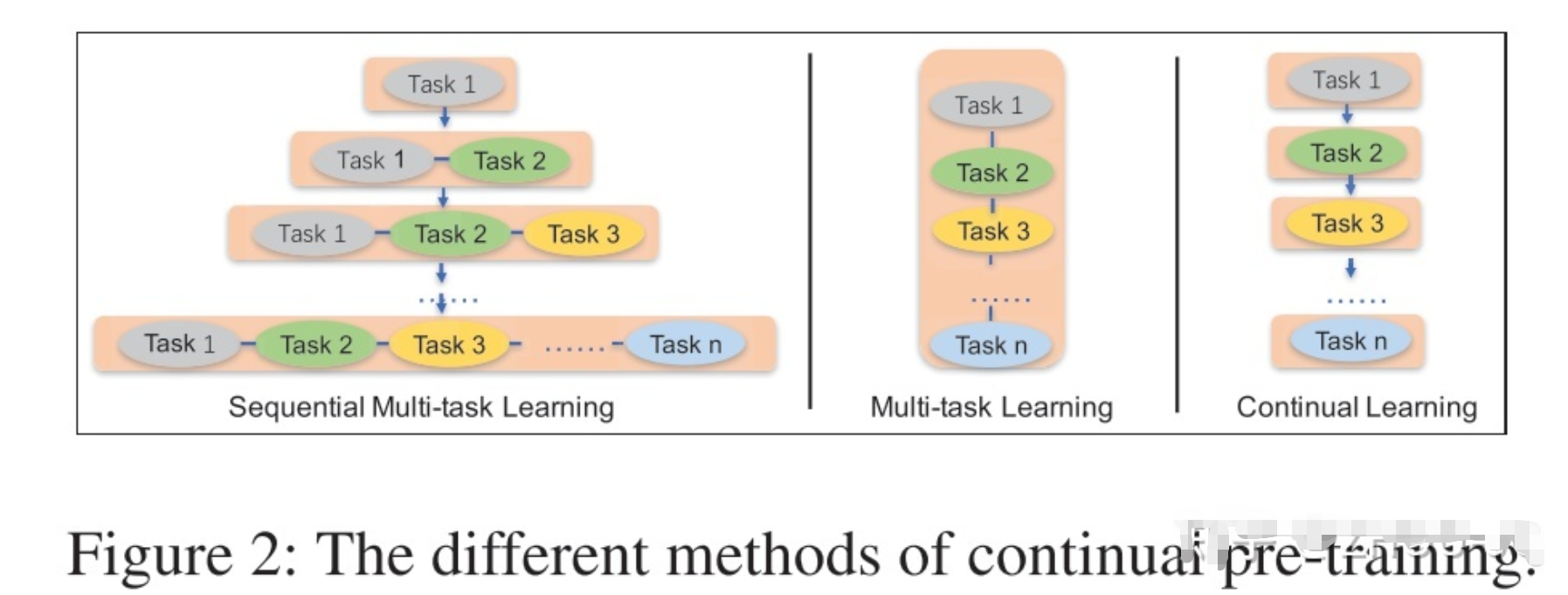
- 策略一:Multi-task Learning,就是让模型同时学这3个任务,具体的让这3个任务的损失函数权重相加,然后一起反向传播更新参数;
- 策略二:Continual Learning,先训练任务1,再训练任务2,再训练任务3,这种策略的缺点是容易遗忘前面任务的训练结果,最后训练出的模型容易对最后一个任务过拟合;
- 策略三:Sequential Multi-task Learning,连续多任务学习,即第一轮的时候,先训练任务1,但不完全让它收敛训练完,第二轮,一起训练任务1和任务2,同样不让模型收敛完,第三轮,一起训练三个任务,直到模型收敛完。
论文采用策略三的思想。
具体的,如下图所示,每个任务有独立的损失函数,句子级别的任务可以和词级别的任务一起训练,相信做过联合训练的同学并不陌生。
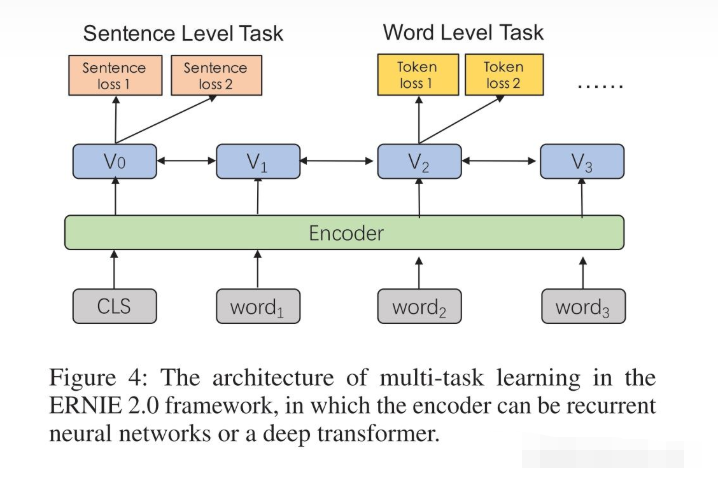
改进2:更多的无监督预训练任务
模型的结构如下图所示,由于是多任务学习,模型输入的时候额外多了一个Task embedding。
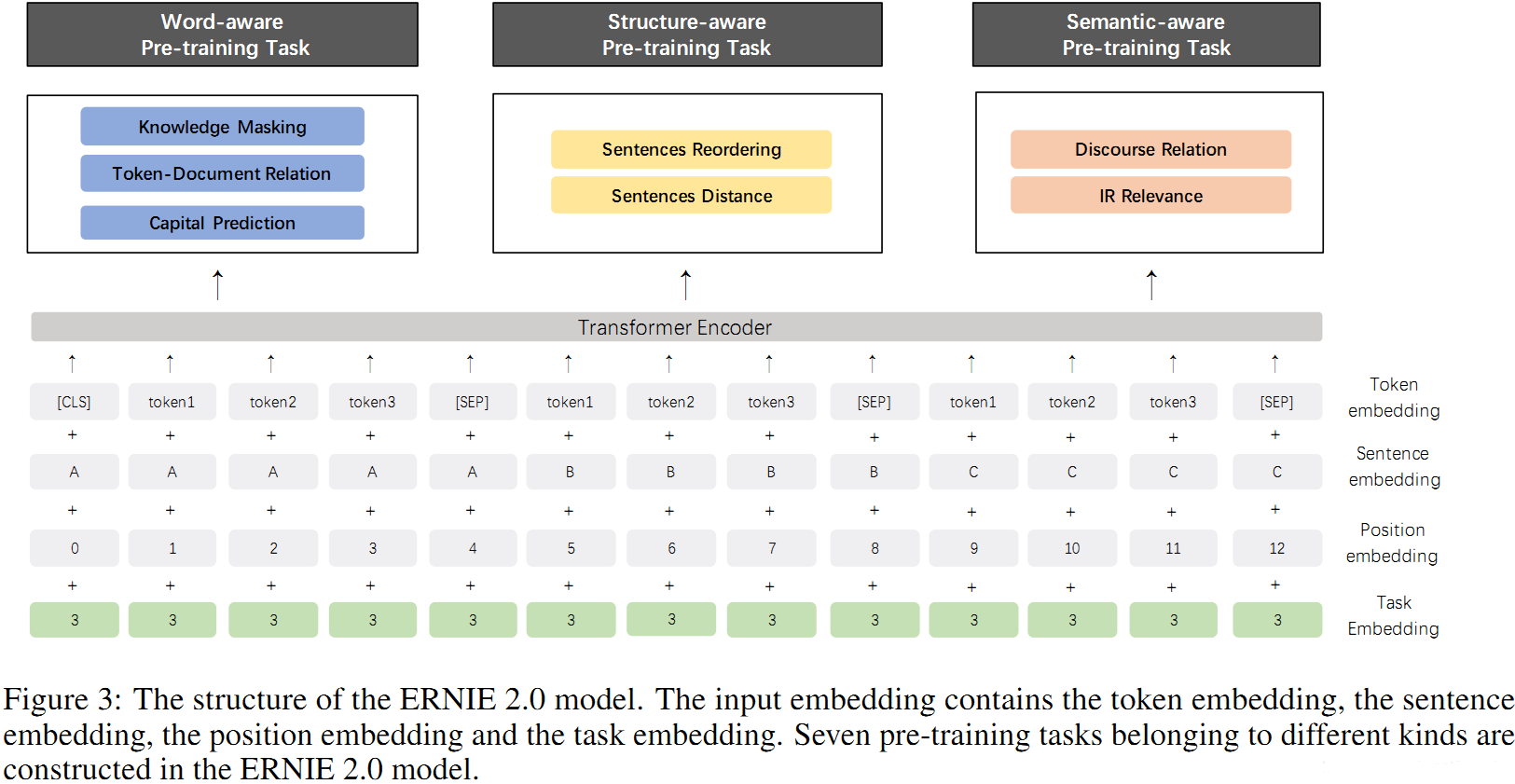
具体的三种类型的无监督训练任务是哪三种呢?每种里面又包括什么任务呢?
- Knowledge Masking Task:这任务同ERNIE 1.0一样,把一些字、短语、实体【MASK】掉,预测【MASK】词语;
- Capitalization Prediction Task:预测单词是大写还是小写;
- Token-Document Relation Prediction Task:预测在段落A中出现的token,是否在文档的段落B中出现。
2. 任务二:语言结构级别预训练任务
- Sentence Reordering Task:把文档中的句子打乱,预测正确顺序;
- Sentence Distance Task:分类句子间的距离(0:相连的句子,1:同一文档中不相连的句子,2:两篇文档间的句子)。
3. 任务三:语句级别预训练任务
- Discourse Relation Task:计算两句间的语义和修辞关系;
- IR Relevance Task:短文本信息检索关系,搜索数据(0:搜索并点击,1:搜素并展现,2:无关)。
实验
各任务用到的数据集:
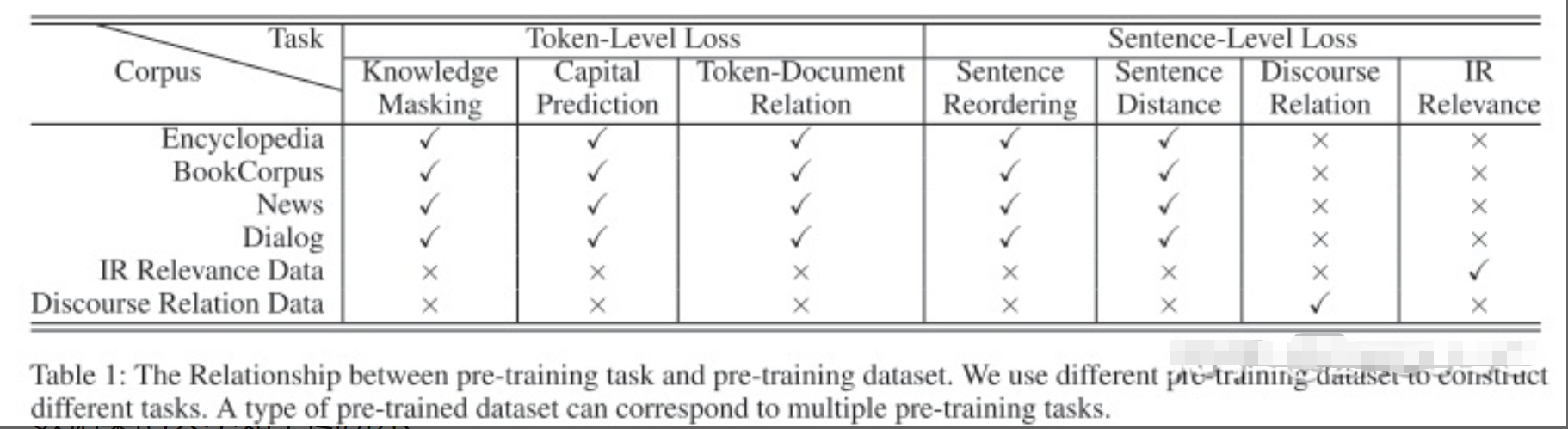
数据集包括百科、书籍、新闻、对话、检索数据、修辞关系数据。可以看到相对于ERNIE1.0,所用的数据更多样化了。注意的是,并非每类型数据都应用到所有任务,如百科数据,就不用于训练语句级别的任务。
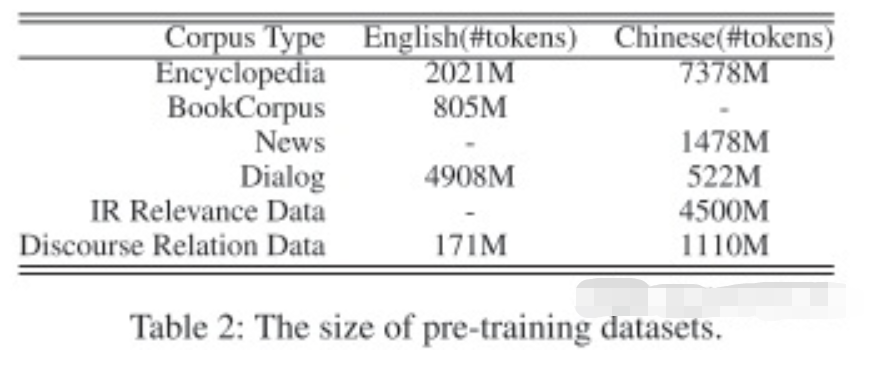
数据集的大小如下图所示:
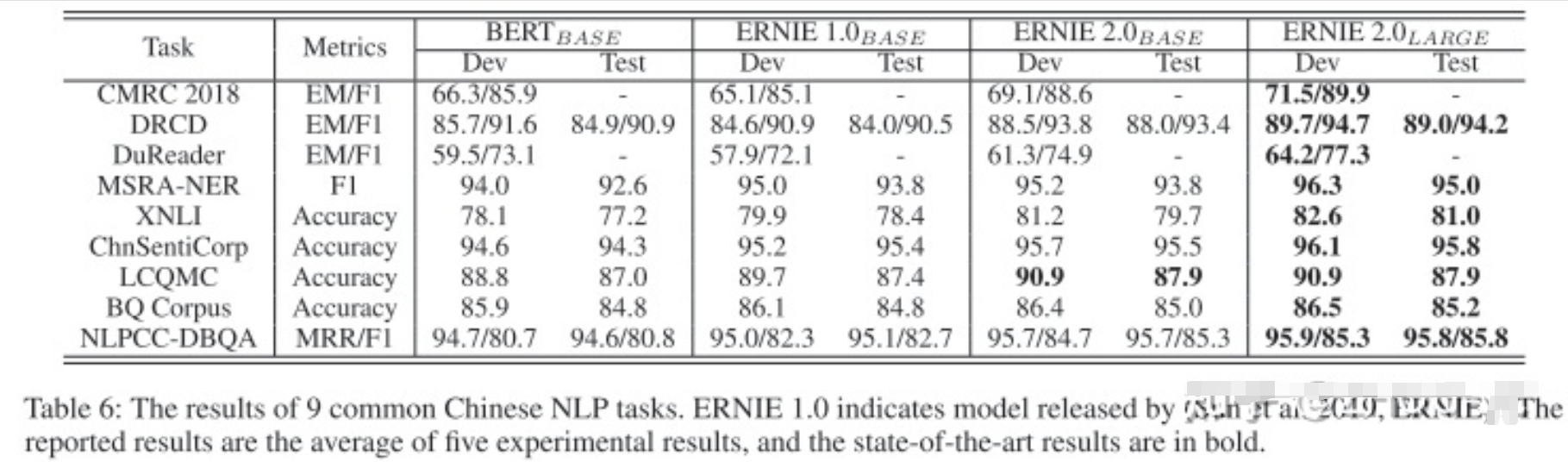
训练完后,在9个中文下游任务上分别进行fine-tunning,结果比 BERT 和 ERNIE1.0 要好。
连续多任务学习的效果:
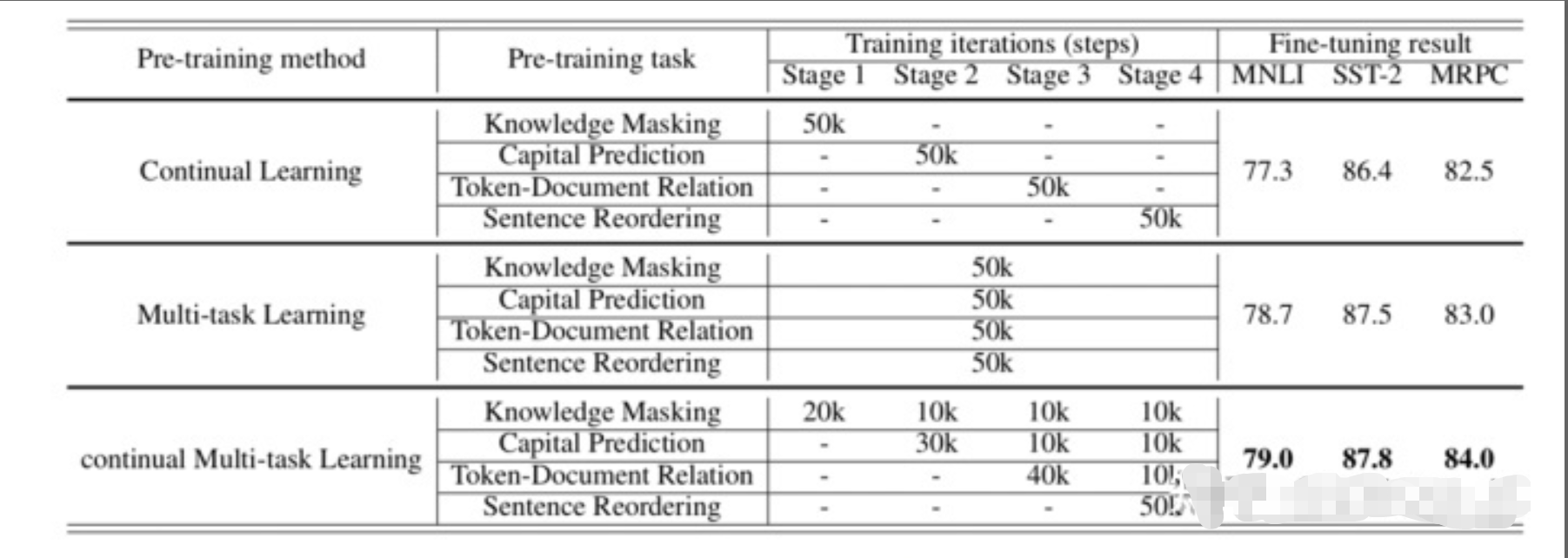
上表展示的就是连续多任务学习,看 continual Multi-task Learing 那一行所示,对于具体的某个任务,不是把它放在一个stage里面就让模型学习收敛完,而是一个连续学习的过程,避免模型遗忘。可以看到,连续多任务学习相比 Continual Learing 和 Multi-task Learning 的效果都要好。
