
ERNIE 1.0
前言
ERNIE(知识增强语义表示模型),是百度发布一个预训练模型,论文全称及链接:《ERNIE: Enhanced Representation through Knowledge Integration》,ERNIE1.0采用与BERT一样的Transformer encoder架构,与BERT不同在于预训练任务,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。
Knowledge Masking Task
训练语料中蕴含着大量的语言知识,例如词法,句法,语义信息,如何让模型有效地学习这些复杂的语言知识是一件有挑战的事情。BERT使用了MLM(masked language-model)和NSP(Next Sentence Prediction)两个预训练任务来进行训练,这两个任务可能并不足以让BERT学到那么多复杂的语言知识,特别是后来多个研究人士提到NSP任务是比较简单的任务,它实际的作用不是很大。
masked language-model(MLM)是指在训练的时候随机从输入语料上mask掉一些单词,然后通过上下文预测这些单词,该任务非常像我们在中学时期经常做的完形填空。
Next Sentence Prediction(NSP)的任务是判断两个句子是否是具有前后顺承关系的两句话。
例如,可看下面这幅图:
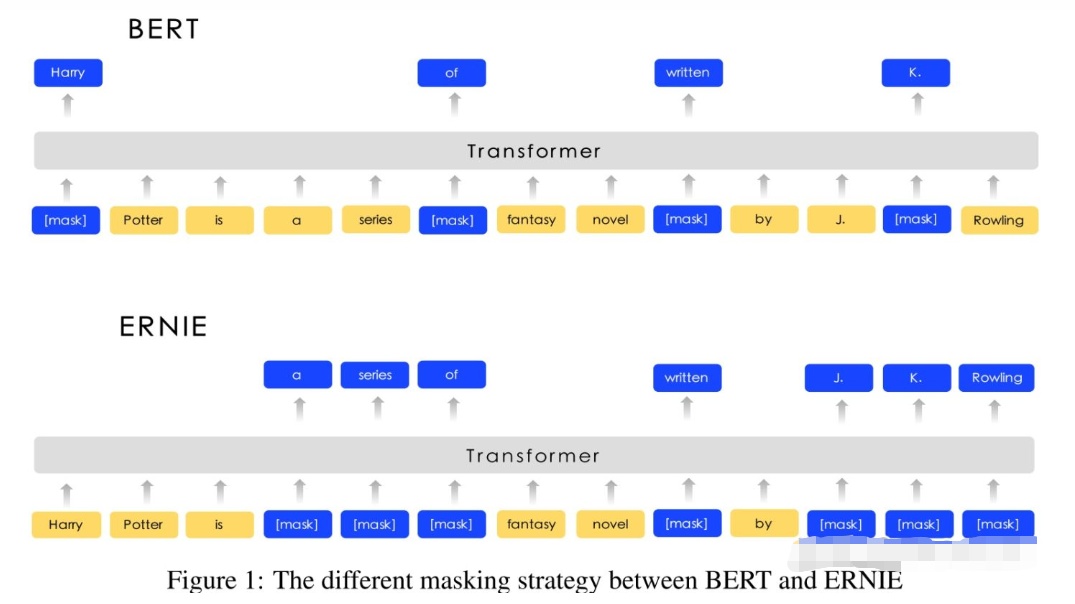
原生BERT是采用随机【MASK】,ERIENE1.0 论文里提到这会让模型不能充分学习到语义信息,降低学习难度。
具体的如上图,Harry Potter的Harry被【MASK】掉,这时候让模型去预测被【MASK】掉的token,这种情况下,模型很可能是根据Potter从而预测Harry(毕竟Harry Potter在语料中共同出现频率的比较高),在这种情况下,模型也许并不是根据Harry Potter和J.K.Rowling的关系来预测出Harry的,换个角度,这样BERT学到的是规则,而并非语义信息。
考虑到这一点,ERNIE提出了Knowledge Masking的策略,其包含三个级别:ERNIE将Knowledge分成了三个类别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行Masking,提高模型对字词、短语的知识理解。
具体的,把MASK分成三部分
- Basic-level Masking:与BERT一样;
- Entity-level Masking:把实体作为一个整体【MASK】,例如 J.K.Rowling 这个词作为一个实体,被一起【MASK】;
- Phrase-Level Masking:把短语作为一个整体【MASK】,如 a series of 作为一个短语整体,被一起【MASK】。
不过论文好像没有详细讲这三种Masking的比例。

Dialogue Language Model(DLM)
增加了对话数据的任务,如下图所示,
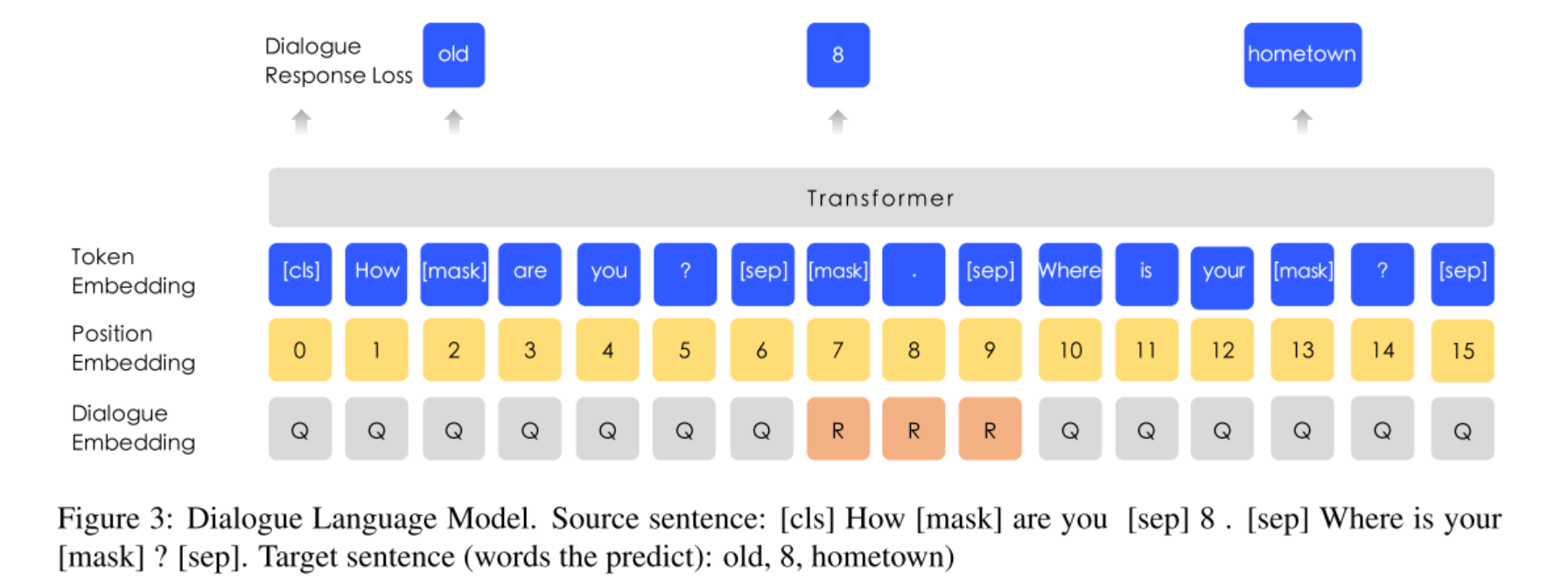
数据不是单轮问答的形式(即问题+答案),而是多轮问答的数据,即可以是QQR、QRQ等等。同上面一样,也是把里面的单个token、实体、短语【MASK】掉,然后预测它们,另外在生成预训练数据的时候,有一定几率用另外的句子替代里面的问题和答案,所以模型还要预测是否是真实的问答对。论文提到DLM任务能让ERNIE学习到对话中的隐含关系,增加模型的语义表达能力。
注意看Segment Embedding被Dialogue Embedding代替了,但其它结构跟MLM模型是一样的,所以DLM任务可以和MLM任务联合训练,即Dialogue Embedding只会跟随DLM任务更新,Segment Embedding只会跟随MLM任务跟新,而模型其它参数是随着DLM任务和MLM任务一起更新。
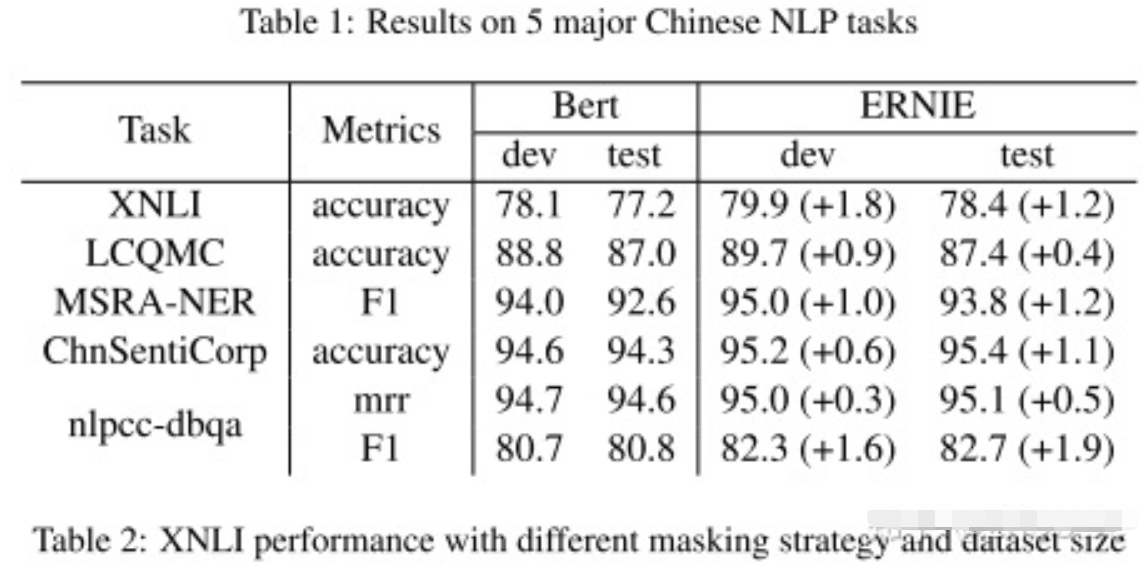
实验结果
ERNIE还采用多个异源语料帮助模型训练,例如对话数据,新闻数据,百科数据等等。
异源语料 :来自不同源头的数据,比如百度贴吧,百度新闻,维基百科等等
具体地,用了四个数据集,分别是中文维基百科、百度百科、百度新闻、百度贴吧,其中百度贴吧的每个帖子可以认为是对话数据,所以百度贴吧的数据用于DLM任务。
优点
善于捕获词语之间相互关系,在完型填空等类型的任务中的表现良好。
