
C语言整数的取值范围以及数值溢出
在现代操作系统中,short、int、long 的长度分别是 2、4、4 或者 8,它们只能存储有限的数值,当数值过大或者过小时,超出的部分会被直接截掉,数值就不能正确存储了,我们将这种现象称为溢出(Overflow)。要想知道数值什么时候溢出,就得先知道各种整数类型的取值范围。
无符号数的取值范围
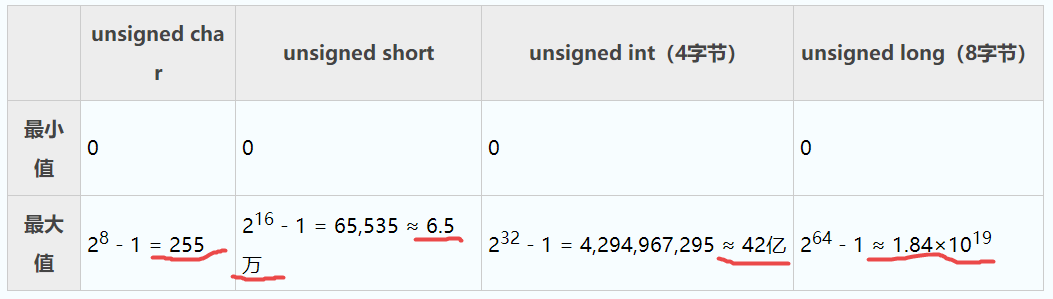
计算无符号数(unsigned 类型)的取值范围(或者说最大值和最小值)很容易,将内存中的所有位(Bit)都置为 1 就是最大值,都置为 0 就是最小值。
以 unsigned char 类型为例,它的长度是 1,占用 8 位的内存,所有位都置为 1 时,它的值为 28 - 1 = 255,所有位都置为 0 时,它的值很显然为 0。由此可得,unsigned char 类型的取值范围是 0~255。
前面我们讲到,char 是一个字符类型,是用来存放字符的,但是它同时也是一个整数类型,也可以用来存放整数,请大家暂时先记住这一点,更多细节我们将在《C语言中的字符(char)》一节中介绍。
有读者可能会对 unsigned char 的最大值有疑问,究竟是怎么计算出来的呢?下面我就讲解一下这个小技巧。
将 unsigned char 的所有位都置为 1,它在内存中的表示形式为1111 1111,最直接的计算方法就是:
这种“按部就班”的计算方法虽然有效,但是比较麻烦,如果是 8 个字节的 long 类型,那足够你计算半个小时的了。
我们不妨换一种思路,先给 1111 1111 加上 1,然后再减去 1,这样一增一减正好抵消掉,不会影响最终的值。
给 1111 1111 加上 1 的计算过程为:
可以发现,1111 1111 加上 1 后需要向前进位(向第 9 位进位),剩下的 8 位都变成了 0,这样一来,只有第 9 位会影响到数值的计算,剩下的 8 位对数值都没有影响。第 9 位的权值计算起来非常容易,就是:
然后再减去 1:
加上 1 是为了便于计算,减去 1 是为了还原本来的值;当内存中所有的位都是 1 时,这种“凑整”的技巧非常实用。按照这种巧妙的方法,我们可以很容易地计算出所有无符号数的取值范围(括号内为假设的长度):
有符号数的取值范围
有符号数以补码的形式存储(无符号也以补码形式存储,但是无符号的补码和原码相同,不需要转换),计算取值范围也要从补码入手。我们以 char 类型为例,从下表中找出它的取值范围:

我们按照从大到小的顺序将补码罗列出来,很容易发现最大值和最小值(个人:也就是最大值、最小值就是这样子观察出来的)。
淡黄色背景的那一行是我要重点说明的。如果按照传统的由补码计算原码的方法,那么 1000 0000 是无法计算的,因为计算反码时要减去 1,1000 0000 需要向高位借位,而高位是符号位,不能借出去,所以这就很矛盾。
是不是该把 1000 0000 作为无效的补码直接丢弃呢?然而,作为无效值就不如作为特殊值,这样还能多存储一个数字。计算机规定,1000 0000 这个特殊的补码就表示 -128。
为什么偏偏是 -128 而不是其它的数字呢?
- 首先,-128 使得 char 类型的取值范围保持连贯,中间没有“空隙”。
- 其次,我们再按照“传统”的方法计算一下 -128 的补码:
- -128($2^{8-1}=128$) 的数值位的原码是 1000 0000,共八位,而 char 的数值位只有七位,所以最高位的 1 会覆盖符号位(个人:其实就是截断,符号位加上最小的符合条件的数值位,而我们只有8位,所以会从低到高截取8位,这样原来的符号位被丢弃了,数值位的最高位充当新的符号位),数值位剩下 000 0000。最终,-128 的原码(个人:也就是在原码这个阶段时,就发生了截断)为 1000 0000。
- 接着很容易计算出反码,为 1111 1111。
- 反码转换为补码时,数值位要加上 1,变为 1000 0000,而 char 的数值位只有七位,所以最高位的 1 会再次覆盖符号位(个人:其实还是发生了截断,符号位1位加上这里产生的数值位8位,而我们总共只有8位,所以会从低到高截取8位,此时新产生的数值位的最高位充当符号位),数值位剩下 000 0000。最终求得的 -128 的补码是 1000 0000。
-128 从原码转换到补码的过程中,符号位被 1 覆盖了两次,而负数的符号位本来就是 1,被 1 覆盖多少次也不会影响到数字的符号。
你看,虽然从 1000 0000 这个补码推算不出 -128,但是从 -128 却能推算出 1000 0000 这个补码,这么多么的奇妙,-128 这个特殊值选得恰到好处。
负数在存储之前要先转换为补码,“从 -128 推算出补码 1000 0000”这一点非常重要,这意味着 -128 能够正确地转换为补码,或者说能够正确的存储。
关于零值和最小值
仔细观察上表可以发现,在 char 的取值范围内只有一个零值,没有+0和-0的区别,并且多存储了一个特殊值,就是 -128,这也是采用补码的另外两个小小的优势。
如果直接采用原码存储,那么
- 0000 0000和1000 0000将分别表示+0和-0,这样在取值范围内就存在两个相同的值,多此一举。
- 另外,虽然最大值没有变,仍然是 127,但是最小值却变了,只能存储到 -127,不能存储 -128 了,因为 -128 的原码为 1000 0000,这个位置已经被-0占用了。
按照上面的方法,我们可以计算出所有有符号数的取值范围(括号内为假设的长度):

上节我们还留下了一个疑问,[1000 0000 …… 0000 0000]补这个 int 类型的补码为什么对应的数值是 -231,有了本节对 char 类型的分析,相信聪明的你会举一反三,自己解开这个谜团。
数值溢出
char、short、int、long 的长度是有限的,当数值过大或者过小时,有限的几个字节就不能表示了,就会发生溢出。发生溢出时,输出结果往往会变得奇怪,请看下面的代码:
#include <stdio.h>
int main()
{
unsigned int a = 0x100000000;
int b = 0xffffffff;
printf("a=%u, b=%d\n", a, b);
return 0;
}

变量 a 为(个人:无符号类型,没有符号位,在内存中存储的01序列都是数值位) unsigned int 类型,长度为 4 个字节,能表示的最大值为 0xFFFFFFFF,而 0x100000000 = 0xFFFFFFFF + 1,占用33位,已超出 a 所能表示的最大值,所以发生了溢出,导致最高位的 1 被截去,剩下的 32 位都是0。也就是说,a 被存储到内存后就变成了 0,printf 从内存中读取到的也是 0。
变量 b 是 int 类型的有符号数,在内存中以补码的形式存储(个人:由于b为一个正数,所以,它的补码与原码相同,即它的原码形式就是它在内存中存储时的补码形式),0xffffffff 的数值位的原码为 1111 1111 …… 1111 1111,共 32 位,而 int 类型的数值位只有 31 位,所以最高位的 1 会覆盖符号位,数值位只留下 31 个 1,所以 b 的原码为:
这也是 b 在内存中的存储形式。
当 printf 读取到 b 时,由于最高位是 1,所以会被判定为负数,要从补码转换为原码:
= [1111 1111 …… 1111 1110]反
= [1000 0000 …… 0000 0001]原
= -1
最终 b 的输出结果为 -1。
