

NLP中的几个对抗训练方法
目录
前言
对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,提升模型鲁棒性和泛化能力。
对抗训练的假设是:给输入加上扰动之后,输出分布和原Y的分布一致
- 有监督的数据下使用交叉熵作为损失:
- 半监督数据下可计算KL散度:
扰动如何得来呢?这需要对抗的思想,即往增大损失的方向增加扰动
- 有监督下:
- 半监督下:
$\theta$上面一个尖儿代表的是常数。目的是说在计算对抗扰动时虽然计算了梯度,但不对参数进行更新,因为当前得到的对抗扰动是对旧参数最优的。不理解的同学可以自己看下伪代码体会一下。
用一句话形容对抗训练的思路,就是:
- 在输入上进行梯度上升(增大loss),
- 在参数上进行梯度下降(减小loss)。
由于输入会进行embedding lookup,所以实际的做法是在embedding table上进行梯度上升。
主要方法介绍
接下来介绍不同的方法,后续方法优化的主要方向有两点:
- 得到更优的扰动
- 提升训练速度
FGSM (Fast Gradient Sign Method): ICLR2015
FGSM是Goodfellow提出对抗训练时的方法,假设对于输入的梯度为:
那扰动肯定是沿着梯度的方向往损失函数的极大值走:
pytorch代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
# FGSM
class FGSM:
def __init__(self, model: nn.Module, eps=0.1):
#等号右边应该是一个括号,并把括号里面的这个唯一的值赋给model
#注意:等号右边不是只包含一个元素的元组,如果是只包含一个元素的
#元组,应该这样写:(123,),这时赋值时,左边的变量也为一个只包含
#一个元素的元组
self.model = (
model.module if hasattr(model, "module") else model
)
self.eps = eps
self.backup = {}
# only attack word embedding
def attack(self, emb_name='embedding'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
r_at = self.eps * param.grad.sign()
param.data.add_(r_at)
def restore(self, emb_name='embedding'):
for name, para in self.model.named_parameters():
if para.requires_grad and emb_name in name:
assert name in self.backup
para.data = self.backup[name]
self.backup = {}
FGM (Fast Gradient Method): ICLR2017
FGSM是每个方向上都走相同的一步,Goodfellow后续提出的FGM则是根据具体的梯度进行scale,得到更好的对抗样本:
伪代码:
对于每个x: 1.计算x的前向loss、反向传播得到梯度 2.根据embedding矩阵的梯度计算出r,并加到当前embedding上,相当于x+r 3.计算x+r的前向loss,反向传播得到对抗的梯度,累加到(1)的梯度上 4.将embedding恢复为(1)时的值 5.根据(3)的梯度对参数进行更新
个人的一个疑问:以这样的方式进行embedding参数的更新,是否正确?正常样本得到的embedding梯度g_1是针对x的,而对抗样本得到的embedding梯度g_2是针对x+r的,而pytorch不清空梯度的情况下,会进行梯度累加,即embedding参数的梯度为g_1+g_2,最后embedding参数的值恢复成正常样本时的参数值,并在这个值上进行embedding参数更新,这样是否正确?
pytorch代码实现:
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
需要使用对抗训练的时候,只需要添加五行代码:
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
FGM和FGSM的区别在于采用的归一化的方法不同,
- FGSM是通过sign函数对梯度采取max归一化,max归一化是说如果梯度某个维度上的值为正,则设为1;如果为负,则设为-1;如果为0,则设为0。
- FGM则采用的是$L_2$归一化。$L_2$归一化则将梯度的每个维度的值除以梯度的$L_2$范数。
- 理论上$L_2$归一化更严格的保留了梯度的方向,但是max归一化则不一定和原始梯度的方向相同。
当然,FGM和FGSM这两种方法都有个假设,就是损失函数是线性的或者至少是局部线性的。如果不是(局部)线性的,那梯度提升的方向就不一定是最优方向了。
PGD (Projected Gradient Descent): ICLR2018
FGM直接通过$\epsilon$参数一下子算出了对抗扰动,这样得到的可能不是最优的。为了解决FGSM和FGM中的线性假设问题,提出了使用PGD方法来求解内部的最大值问题。
PGD是一种迭代攻击,
- 相比于普通的FGSM和FGM仅做一次迭代,
- PGD是做多次迭代,每次走一小步,每次迭代都会将扰动投射到规定范围内。
引用[1]:
FGM简单粗暴的“一步到位”,可能走不到约束内的最优点。PGD则是“小步走,多走几步,如果走出了扰动半径为$\epsilon$的空间,就映射回“球面”上,以保证扰动不要过大
且

t+1时刻输入根据t时刻的输入及t时刻的梯度求出。$\prod_{x+S}$的意思是,如果扰动超过一定的范围,就要映射回规定的范围$S$内,这里的$x$为原始的正常的样本输入值。
伪代码:
对于每个x: 1.计算x的前向loss、反向传播得到梯度并备份 对于每步t: 2.根据embedding矩阵的梯度计算出r,并加到当前embedding上,相当于x+r(超出范围则投影回epsilon内) 3.t不是最后一步: 将梯度归0,根据1的x+r计算前后向并得到梯度 4.t是最后一步: 恢复(1)的梯度,计算最后的x+r并将梯度累加到(1)上 5.将embedding恢复为(1)时的值 6.根据(4)的梯度对参数进行更新
pytorch代码实现:
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}#保存的是正常样本反向传播得到的梯度值
#epsilon:扰动空间的约束半径,alpha:小步的步长
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
#如果是首次产生对抗样本时,保存embedding参数的值(是参数值不是梯度值)
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):#将模型参数的梯度值恢复为正常样本反向传播时得到的梯度值
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
使用的时候麻烦一点:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()# 保存正常样本的梯度
# 对抗训练
for t in range(K):
#产生已经存在的embedding梯度,产生对抗样本(即在embedding上添加对抗扰动)
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
可以看到,在循环中$r$是逐渐累加的,要注意的是最后更新参数只使用最后一个$x+r$算出来的梯度。
PGD的优点:
- 由于每次只走很小的一步,所以局部线性假设基本成立的。经过多步之后就可以达到最优解了,也就是达到最强的攻击效果。
- 论文还证明用PGD算法得到的攻击样本,是一阶对抗样本中最强的了。这里所说的一阶对抗样本是指依据一阶梯度的对抗样本。
- 如果模型对PGD产生的样本鲁棒,那基本上就对所有的一阶对抗样本都鲁棒。
- 实验也证明,利用PGD算法进行对抗训练的模型确实具有很好的鲁棒性。
PGD的缺点:
- PGD虽然简单,也很有效,但是存在一个问题是计算效率不高。不采用对抗训练的方法m次迭代只会有m次梯度的计算,但是对于PGD而言,每做一次梯度下降(获取模型参数的梯度,训练模型),都要对应有K步的梯度提升(获取输入的梯度,寻找扰动)。所以相比不采用对抗训练的方法,PGD需要做m(K+1)次梯度计算。
FreeAT (Free Adversarial Training): NIPS2019
从FGSM到PGD,主要是优化对抗扰动的计算,虽然取得了更好的效果,但计算量也一步步增加。
- 对于每个样本,FGSM和FGM都只用计算两次,一次是计算$x$的前后向,一次是计算$x+r$的前后向。
- 而PGD则计算了$K+1$次,消耗了更多的计算资源。
因此FreeAT被提了出来,在PGD的基础上进行训练速度的优化。
在PGD的计算过程中,每次做前向后向计算时,不管是参数的梯度还是输入的梯度,都会计算出来,只不过在梯度下降的过程中只利用参数的梯度,在梯度提升的过程中只利用输入的梯度,这实际上有很大的浪费。 我们能不能在一次前向后向计算过程中,把计算出来的参数的梯度和输入的梯度同时利用上?这就是FreeAT[4]这篇文章的核心思想。
如何做呢?
- FreeAT仍然采用了PGD这种训练方式,但对于每个min-batch的样本,会求K次梯度,每次求得梯度,我们既用来更新扰动,也用来更新参数。原始的PGD训练方法,每次内层计算只用梯度来更新扰动,等K步走完之后,才重新再计算一次梯度,更新参数。这个不同可以用下图形象的表示。
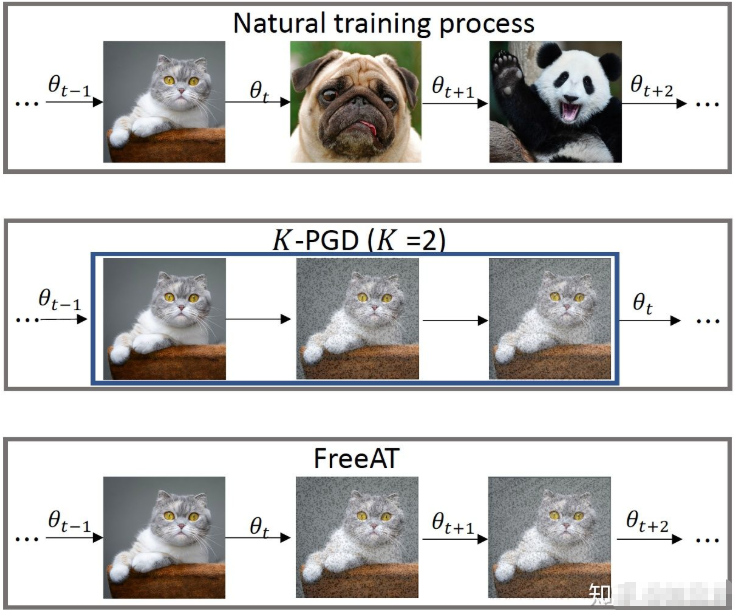
- 需要注意的是,如果内层做K次迭代的化,对于外层计算,FreeAT会把总体的迭代epoch除以K,这样保证总体的梯度计算的次数跟普通训练一样。从外层训练的视角来看,每个min-batch被训练的次数和普通训练是相同的,只不过其被训练的顺序有些变化,K个相同的min-batch会被顺序的训练。 这样带来的问题是连续相同的mini-batch对参数更新,不如随机mini-batch带来的扰动大,这有可能影响到最终模型收敛的效果。但是论文用实验证明,这种担心不太必要。
FreeAT的思想是:
- 在对每个样本$x$连续重复$m$次训练,
- 计算$\delta$时复用上一步的梯度,
- 为了保证速度,整体epoch会除以$m$。

缺点:FreeLB指出,FreeAT的问题在于每次的$\delta$对于当前的参数$\theta$都是次优的(无法最大化loss),因为当前$\delta$是由$\delta_{t-1}$和$\theta_{t-1}$计算出来的,是对于$\theta_{t-1}$的最优。这从上面的算法步骤中内层的循环是先更新的参数$\theta$,后更新的扰动$\delta$可以看出来。
注:
1.论文中提供伪代码,但源码中好像对1步输入做了归一化论文中并没有提到
2.个人认为可以把FreeAT当成执行$m$次的FGSM,最开始$\delta=0$,第一次更新的是$x$的梯度,之后开始迭代更新$\delta$,则根据$x+\delta$的梯度更新参数。但代码中有个问题是$\delta$只在最开始初始化,如果迭代到新的样本$x_2$,也是根据上个样本的$\delta$进行更新的,这里我有些疑问,希望懂的大佬赐教~
YOPO (You Only Propagate Once): NIPS2019
YOPO的目标也是提升PGD的效率,这篇文章需要的理论知识比较雄厚,这里只简要介绍一下。
我们先看一下PGD-r算法,它的具体步骤如下:

它的思路很简单,就是先对$\eta$执行$r$次梯度上升,然后再对$\theta$做一次梯度下降,完成一次权重更新。这样一来,每更新一次$\theta$,就需要先对$\eta$做$r$次正向和反向传播,这就导致了PGD-r的训练速度非常慢。
极大值原理PMP(Pontryagin's maximum principle)是optimizer的一种,它将神经网络看作动力学系统。这个方法的优点是在优化网络参数时,层之间是解藕的。通过这个思想,我们可以想到,既然扰动是加在embedding层的,为什么每次还要计算完整的前后向传播呢?对抗扰动只和神经网络的第一层有关。所以,只对第一层求梯度,并据此来更新扰动。
基于这个想法,作者想复用后几层的梯度,假设$p$(slack variable,松弛变量)为定值:
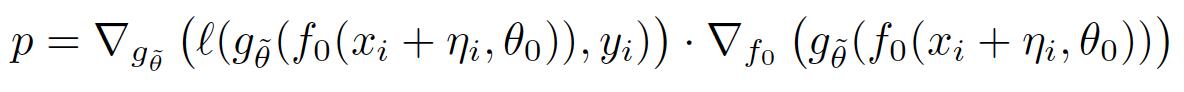
在对$\eta$更新的循环中,我们把p固定,认为它不会随着$\eta$的改变而改变,
这样的话,梯度的计算公式就从
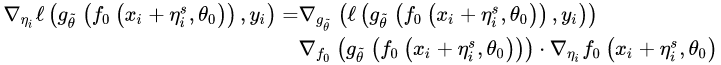
变为:
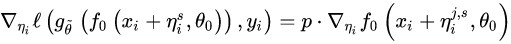
我们只需要计算 $\eta$ 网络第0层$f_0$的梯度,这样就减少了正反向传播的层数,从而加快速度。这里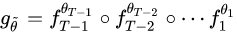
代表网络中除去第0层以外的其它层的共同作用;
详细的算法代码如下:

简单分析一下这个算法,
- 首先给定一个初始的
,计算出对应的p,
- 然后在固定p的情况下做n次梯度上升得到
,
- 接着完成更新:
,并重新计算p,
- 这样进行m步,就得到了 集合
,
- 最后用这m个
完成对于参数
的动量SGD。
作者又提出了PMP版本的YOPO,并证明SGD的YOPO是PMP版的一种特殊形式。这样每次迭代$r$就只用embedding的梯度就可以了。
引用[9]:
虽然YOPO-m-n只完成了m次完整的正反向传播,但是却实现了m*n次扰动的更新。而PGD-r算法完成r次完整的正反向传播却只能实现r次扰动的更新。这样看来,YOPO-m-n算法的效率明显更高,而实验也表明,只要使得m*n略大于r,YOPO-m-n的效果就能够与PGD-r相媲美。
然而故事的反转来的太快,FreeLB指出YOPO使用的假设对于ReLU-based网络不成立:
Interestingly, the analysis backing the extra update steps assumes a twice continuously differentiable loss, which does not hold for ReLU-based neural networks they experimented with, and thus the reasons for the success of such an algorithm remains obscure.
别问了,问就是PMP,来跟我一起进入下一部份的学习。
FreeLB (Free Large-Batch): ICLR2020
FreeLB认为,FreeAT和YOPO对于获得最优$r$(inner max)的计算都存在问题,因此提出了一种类似PGD的方法。只不过PGD只使用了最后一步$x+r$输出的梯度,而FreeLB取了每次迭代$r$输出梯度的平均值,相当于把输入看作一个K倍大的虚拟batch,由$[X+r_1, X+r_2, ..., X+r_k]$拼接而成。具体的公式为:
为了方便对比,再贴下论文中PGD的公式:
FreeLB和PGD主要有两点区别:
1.PGD是迭代K次r后取最后一次扰动的梯度更新参数,FreeLB是取K次迭代中的平均梯度
2.PGD的扰动范围都在epsilon内,因为伪代码第3步将梯度归0了,每次投影都会回到以第1步x为圆心,半径是epsilon的圆内,而FreeLB每次的x都会迭代,所以r的范围更加灵活,更可能接近局部最优:
$r_t\in I_t$在两个balls的交集之内(没看懂)。
FreeLB的伪代码为:

- 和FreeAT一样,FreeLB也想更高效的利用两种梯度。但是和FreeAT不一样的是,FreeLB并不是在每次梯度提升的过程中,都会对参数进行跟新,而是将参数的梯度累积起来,即算法第8行 $g_t$更新的过程。这样走过K步之后,FreeLB利用$K$步之后积累的参数梯度$g_K$,对参数$\theta$进行更新,即算法第13行$\theta$的更新过程。
- FreeLB需要进行$N_{ep}*K$次梯度计算,相比于PGD需要进行 $N_{ep}*(K+1)$次梯度计算,是节省了$N_{ep}$次梯度计算,但是相比于FreeAT只需要$N_{ep}$次梯度计算而言,FreeLB效率的提升并不明显。 所以FreeLB的优势并不在效率,而是在效果。
- 由于FreeLB利用了多步K积累的梯度再做更新,对梯度的估计更加精准,而且不存在FreeAT那样连续利用多个相同的min-batch进行梯度更新的问题。
- 相比于YOPO-m-n,FreeLB也是将K步(这里指m)中的梯度综合后再更新参数,不同的是其没有更进一步的n层,即使有,也是n个完全相同的值。
- 为什么论文成这种算法为Large Batch呢?在梯度下降时,我们使用的梯度是基于$X+\delta_0,...,X+\delta_{K-1}$进行计算的,这可以理解为近似的对K个不同batch的样本进行平均,所以相当于虚拟的增大了样本的数量.
- 论文中还指出了很重要的一点,就是对抗训练和dropout不能同时使用,加上dropout相当于改变了网络结构,会影响r的计算。如果要用的话需要在K步中都使用同一个mask。
SMART (SMoothness-inducing Adversarial Regularization)
SMART论文中提出了两个方法:
1.对抗正则 SMoothness-inducing Adversarial Regularization,提升模型鲁棒性
2.优化算法 Bregman proximal point optimization,避免灾难性遗忘
本文只介绍其中的对抗正则方法。
SMART提出了两种对抗正则损失,加到损失函数中:
- 第一种参考了半监督对抗训练,对抗的目标是最大化扰动前后的输出,在分类任务时loss采用对称的KL散度,回归任务时使用平方损失:
- 第二种方法来自DeepMind的NIPS2019[8],核心思想是让模型学习到的流形更光滑,即让loss在训练数据呈线性变化,增强对扰动的抵抗能力。作者认为,如果loss流形足够平滑,那l(x+r)可以用一阶泰勒展开进行近似,因此用来对抗的扰动需要最大化l(x+r)和一阶泰勒展开的距离:
SMART的算法和PGD相似,也是迭代K步找到最优r,然后更新梯度。
总结
把最近的一些对抗训练方法总结出来,可以看到趋势从“优化PGD的速度”又回到了“找寻最优扰动”,个人也比较认同,训练速度慢一些对于普通模型还是可以接受的,主要还是看最终的效果有没有提升。之前自己试过FGM和PGD,FGM有轻微提升,但PGD没有,应该需要在超参数上进行调整。FreeLB和SMART在GLUE榜单上都有出现过,相信之后对抗训练也是标配了。
