

预训练模型之Roberta
概述
Bert出来以后,迅速引爆了NLP领域,出现了很多的针对模型的改进。然而,Roberta用实力表明,只对原来的Bert模型调优就可以有明显的提升。RoBERTa是在论文《RoBERTa: A Robustly Optimized BERT Pretraining Approach》中被提出的。此方法属于BERT的强化版本,也是BERT模型更为精细的调优版本。
先来回顾一下Bert中的一些细节:
- 在输入上,Bert的输入是两个segment,其中每个segment可以包含多个句子,两个segment用
[SEP]拼接起来。 - 模型结构上,使用Transformer,这点跟Roberta是一致的。
- 学习目标上,使用两个目标:
- Masked Language Model(MLM): 其中15%的token要被Mask,在这15%里,有80%被替换成
[Mask]标记,有10%被随机替换成其他token,有10%保持不变。 - Next Sentence Prediction: 判断segment对中第二个是不是第一个的后续。随机采样出50%是和50%不是。
- Masked Language Model(MLM): 其中15%的token要被Mask,在这15%里,有80%被替换成
- Optimizations:
- Adam, beta1=0.9, beta2=0.999, epsilon=1e-6, L2 weight decay=0.01
- learning rate, 前10000步会增长到1e-4, 之后再线性下降。
- dropout=0.1
- GELU激活函数
- 训练步数:1M
- mini-batch: 256
- 输入长度: 512
- Data
- BookCorpus + English Wiki = 16GB
在模型规模、算力和数据上,与BERT相比Roberta主要有以下几点改进:
- 更大的模型参数量(论文提供的训练时间来看,模型使用1024块V100 GPU训练了1天的时间)
- 更大bacth size。RoBERTa 在训练过程中使用了更大的bacth size。尝试过从 256 到 8000 不等的bacth size。
- 更多的训练数据(包括:CC-NEWS 等在内的 160GB 纯文本。而最初的BERT使用16GB BookCorpus数据集和英语维基百科进行训练)
RoBERTa主要在以下几个方面对之前提出的BERT做了该进,
- 改进了优化函数参数;
- 在Masking策略上,改用了动态掩码的方式训练模型;
- 在模型的输入格式上,探讨了NSP(Next Sentence Prediction)训练策略对模型结果的影响,证明了NSP(Next Sentence Prediction)训练策略的不足,去掉下一句预测(NSP)任务;
- 采用了更大的batch size;
- 使用了更大的数据集和更长的训练步数;
- 使用字节级别的BPE来处理文本数据。
RoBERTa的主要改进
改进优化函数参数
原始BERT优化函数采用的是Adam默认的参数,其中\(\beta_1=0.9, \beta_2=0.999, \epsilon=1e^{-6}\),在RoBERTa模型中考虑采用了更大的batches,所以将\(\beta_2\)改为了0.98,在部分训练场景中调节\(\epsilon\),可以得到更稳定更好的效果。
注:Adam更新公式,
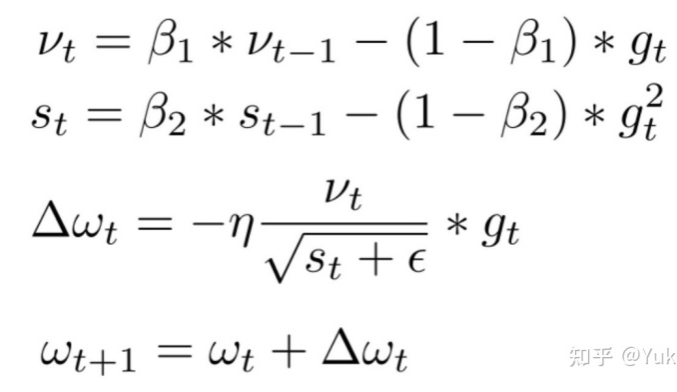
Masking策略
- 原始静态mask:BERT中准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,即单个静态mask,这是原始BERT的做法。
- 修改版静态mask:在预处理的时候将数据集拷贝10次,每次拷贝采用不同的mask(总共40epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态mask来训练40个epoch。
- 动态mask:并没有在预处理的时候执行mask,而是在每次向模型提供输入时动态生成mask,所以是时刻变化的。这样,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征。
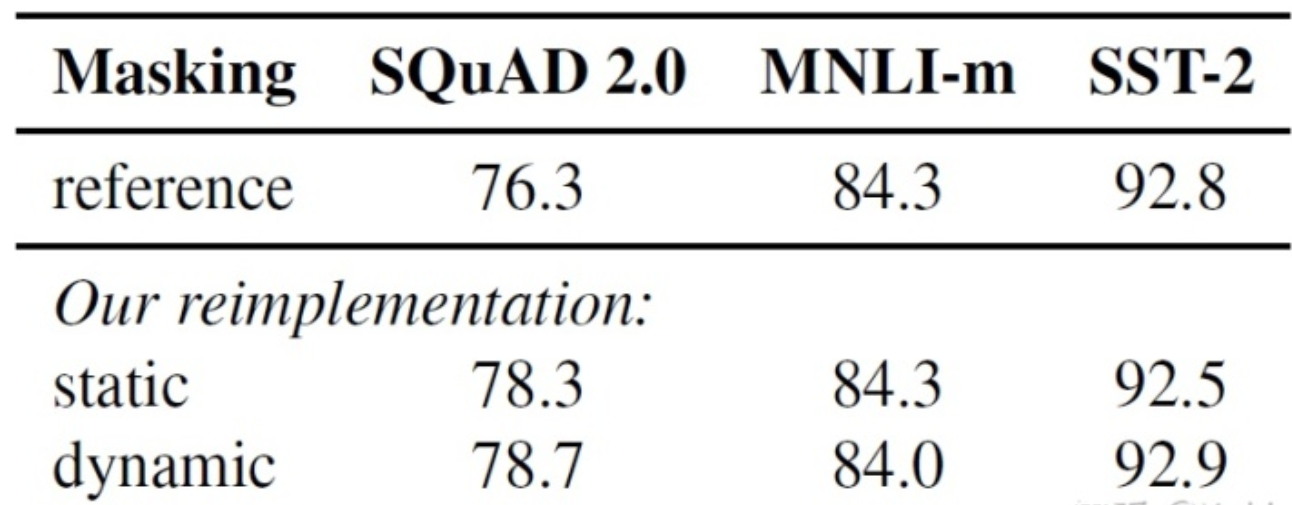
不同模式的实验效果如下表所示。其中reference为BERT用到的原始静态mask,static为修改版的静态mask。
从下图可以看出,采用动态mask,模型的效果稍有提升:
模型输入格式与NSP
Bert的模型输入中是由两个segment组成的,因而就有两个问题:
- 两个segment是不是必要?
- 为什么是segment而不是单个的句子?
为了探索NSP训练策略对模型结果的影响,将以下4种训练方式进行对比:
- Segment-Pair + NSP:这是原始 BERT 的做法。输入包含两部分,每个部分是来自同一文档或者不同文档的 segment(segment是连续的多个句子),这两个segment 的token总数少于 512 。预训练包含 MLM 任务和 NSP 任务。
- Sentence-Pair + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的token总数少于512。由于这些输入明显少于512个tokens,因此增加batch size的大小,以使tokens总数保持与Segment-Pair + NSP相似。预训练包含MLM任务和NSP任务。
- Full-Sentences:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token总数不超过512。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界token
[SEP]。预训练不包含 NSP任务。 - Doc-Sentences:输入只有一部分(而不是两部分),输入的构造类似于FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token总数不超过512。在文档末尾附近采样的输入可以短于512个tokens,因此在这些情况下动态增加batch size大小以达到与FULL-SENTENCES相同的tokens总数。预训练不包含NSP任务。
以下是论文中4种方法的实验结果:
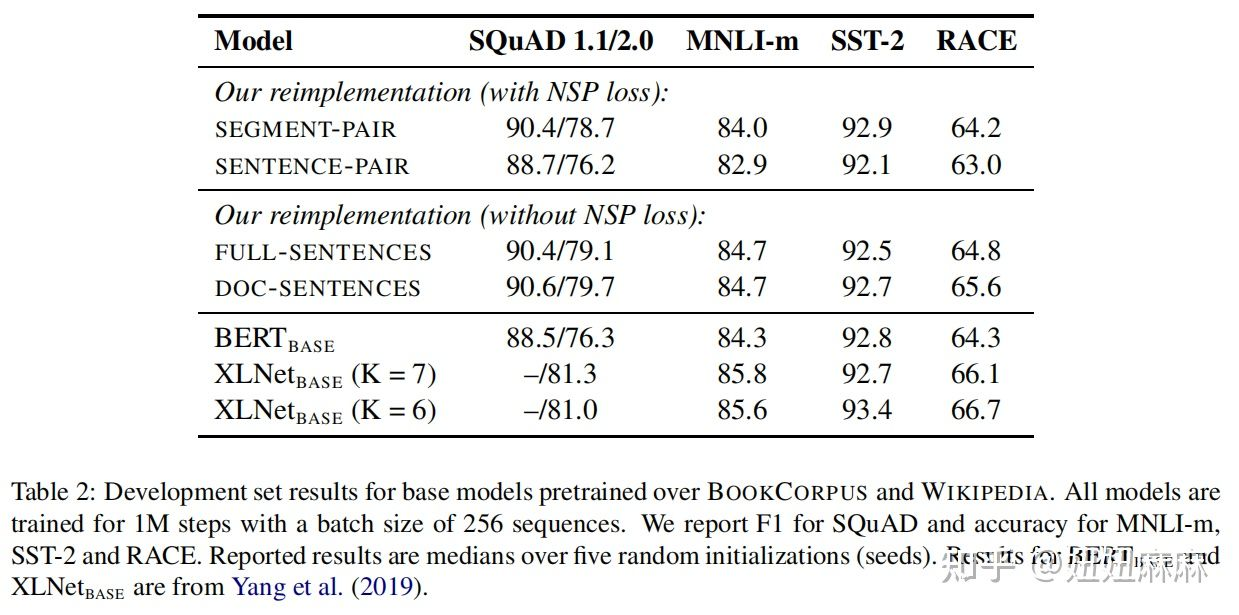
从实验结果来看,
- 如果在采用NSP loss的情况下,将Segment-Pair + NSP与Sentence-Pair + NSP进行对比,结果显示前者优于后者。发现单个句子会损害下游任务的性能,可能是如此模型无法学习远程依赖。
- 接下来把重点放在没有NSP loss的Full-Sentences上,发现相比于采用NSP loss的模式,能够带来微小的提升,说明NSP不是必须的。可能的原因:原始BERT实现采用仅仅是去掉NSP的损失项,但是仍然保持Segment-Pair的输入形式。
- 最后,实验还发现将序列限制为来自单个文档(Doc-Sentences)的性能略好于序列来自多个文档(Full-Sentences)。但是Doc-Sentences策略中,位于文档末尾的样本可能小于512个token。为了保证每个batch的token总数维持在一个较高水平,需要动态调整batch-size。出于处理方便,后面采用Full-Sentences输入格式。
更大的batch size
现在越来越多的实验表明增大batch_size会使得收敛更快,最后的效果更好。原始的Bert中batch_size=256,同时训练1Msteps。
在Roberta中,实验了两个设置:
- batch_size=2k, 训练125k steps。
- batch_size=8k, 训练31k steps。
从结果中看,batch_size=2k时结果最好。
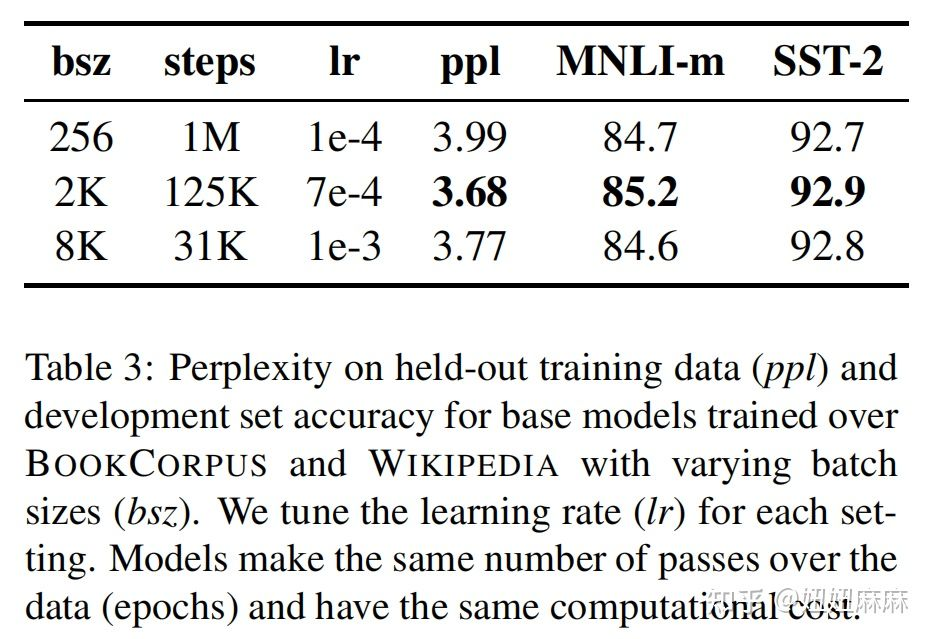
论文考虑了并行计算等因素,在后续的实验中使用batch size=8k进行训练。
更大语料与更长的训练步数
- BETR数据集:BOOKCORPUS + ENGLISG WIKI = 16G
- RoBERTa数据集:BOOKCORPUS + CC-NEWS + OPENWEBTEXT + STORIES = 160GB
将16G的数据集提升到160G数据集,并训练更多的步数,寻找最佳的超参数。在下图可以看出增加数据量和训练步数还是有提升的。
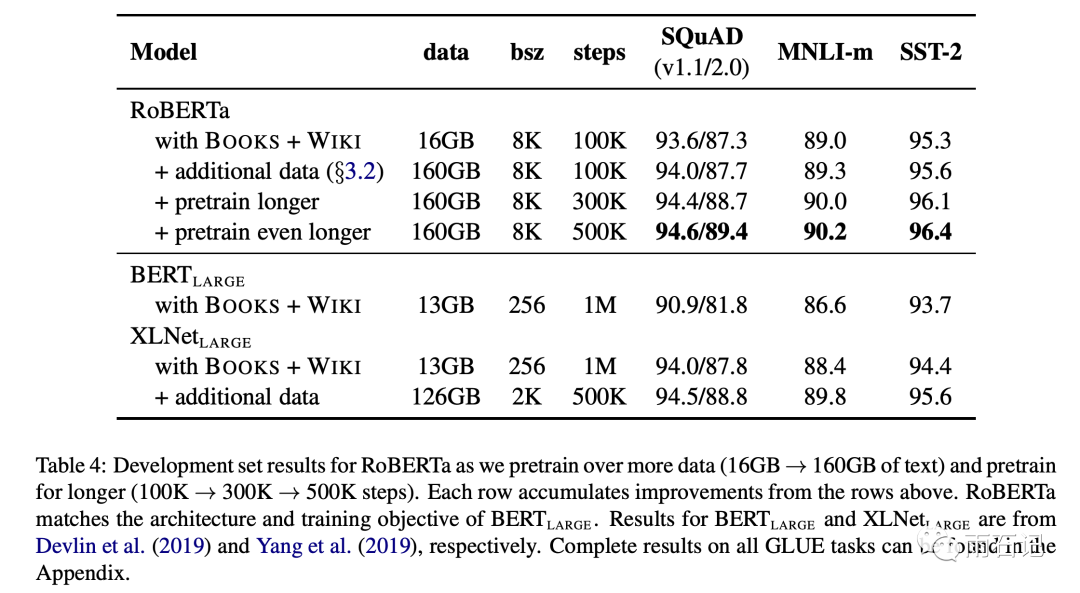
字节级别的BPE文本编码
字节对编码(BPE,Byte-Pair Encoding的简称)(Sennrich et al.,2016),是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在1万到10万之间。当对海量多样语料建模时,unicode characters占据了该词表的大部分。Radford et al.(2019)的工作中介绍了一个简单但高效的BPE, 该BPE使用字节对而非unicode characters作为子词单元。
总结下两种BPE实现方式:
- 基于char-level:原始BERT的方式,它通过对输入文本进行启发式的词干化之后处理得到。
- 基于bytes-level:与char-level的区别在于bytes-level使用bytes而不是unicode字符作为sub-word的基本单位,因此可以编码任何输入文本而不会引入UNKOWN标记。
原版的BERT实现使用字符级别的BPE词汇,大小为30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的byte级别BPE词汇表来训练BERT,这一词汇表包含50K的subword 单元,且没有对输入作任何额外的预处理或分词。
当采用bytes-level的BPE之后,词表大小从3万(原始BERT的char-level)增加到5万。这分别为 BERT-base和 BERT-large增加了1500万和2000万额外的参数。之前有研究表明,这样的做法在有些下游任务上会导致轻微的性能下降。但是本文作者相信:这种统一编码的优势会超过性能的轻微下降。且作者在未来工作中将进一步对比不同的encoding方案。
实验效果
Roberta就是上面所有改进的总和。可以看到,在各项任务中的提升还是很大的。
- GELU数据集效果对比:
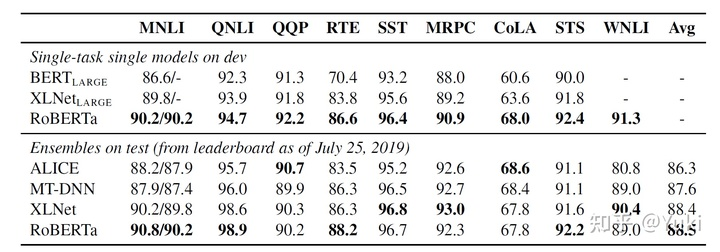
- SQuAD数据集效果对比:
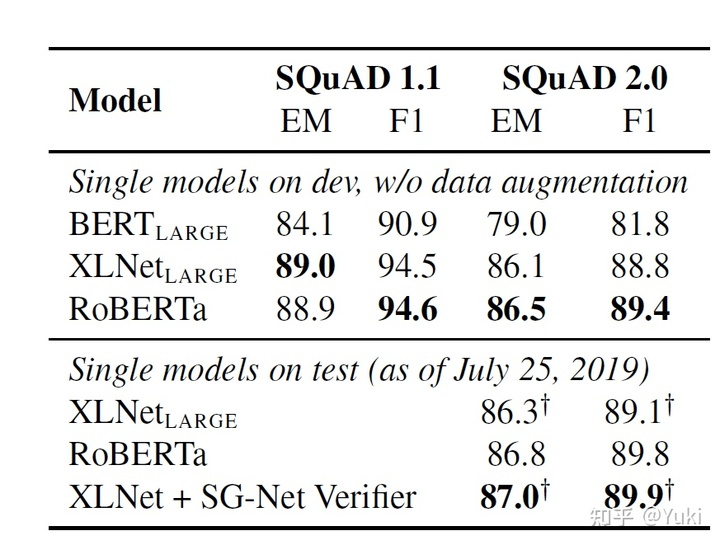
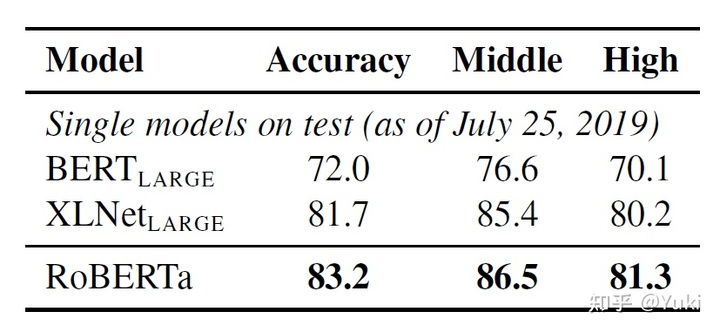
- RACE数据集效果对比:
Middle代表middle-school题库数据,High代表high-school题库数据
总结
- 更多训练数据(16GB->160GB)
- 更大的训练批次(256->8000)
- 训练更多步数(100K->500K)
- 不使用NSP loss
- 更大的序列长度
- 动态mask(掩盖)
- 字节级别的BEP
由于Roberta出色的性能,现在很多应用都是基于Roberta而不是原始的Bert去微调了。
