

语言模型的评价指标之困惑度
无论是n-gram语言模型(unigram, bigram, tirgram),还是理论上可以记忆无限个单词的无穷元语法(∞-gram)和递归神经网络语言模型(RNN Language Model),都会涉及到一个最关键的问题:如何来评价这些语言模型的好坏?
语言模型是很多涉及到产生文字或预测文字概率的NLP问题的组成部分,因此最为直观的评价方法是对应用语言模型的NLP任务进行评估。为了评估语言模型的好坏,运行更为复杂且更加耗时的其它NLP任务,显然这种方法比较繁琐。
有没有一种能够直接对语言模型进行评价的方法呢?语言模型简单来说就是计算句子的概率值,通常认定测试集中的句子为模拟真实生产环境中的正常句子,因此,在训练数据集上训练好的语言模型,计算在测试集中的正常句子的概率值越高说明语言模型的越好,而这正是困惑度(perplexity)的基本思想。
困惑度是语言模型效果好坏的常用评价指标,计算困惑度的公式如下:
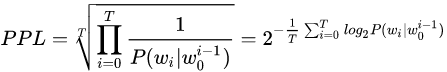
\(\begin{align*} perplexity(S) &= p(w_1,w_2,w_3...,w_n)^{-\frac{1}{n}} \\&= \sqrt[n]{\frac {1} {p(w_1,w_2,w_3...,w_n)}} \\&= \sqrt[n]{\prod_{i=1}^{n}{\frac {1} {p(w_i|w_1, ...,w_{i-1})}}} \end{align*}\)
- 根号内是句子概率的倒数,所以显然句子越好(概率大),困惑度越小,也就是模型对句子越不困惑。 这样我们也就理解了这个指标的名字。
- 开n次根号(n为句子长度),意味着几何平均数(把句子概率拆成词语概率的连乘)
- 需要平均的原因是,因为每个字符的概率必然小于1,所以越长的句子的概率在连乘的情况下必然越小,所以为了对长短句公平,需要平均一下
- 之所以使用几何平均,是因为几何平均数的特点是,如果有其中的一个概率是很小的,那么最终的结果就不可能很大,从而要求好的句子的每个字符都要有基本让人满意的概率
在测试集上得到的困惑度越低,说明语言模型的效果越好。通过上面的公式也可以看出,困惑度实际上是计算每一个单词得到的概率倒数的几何平均,因此困惑度可以理解为平均分支系数(average branching factor),即模型预测下一个单词时的平均可选择的单词数量。别人在作报告时说模型的PPL下降到90,可以直观地理解为,在模型生成一句话时下一个词有90个合理选择,可选词数越少,我们大致认为模型越准确。这样也能解释,为什么PPL越小,模型越好。
上面都是在计算一个句子的困惑度,如果测试集中有n个句子,只需要计算出这n个句子的困惑度,然后将n个困惑度累加取平均,最终的结果作为训练好的语言模型的困惑度。
- 训练数据集越大,PPL会下降得更低,1 billion dataset和10万dataset训练效果是很不一样的。
- 数据中的标点会对模型的PPL产生很大影响,一个句号能让PPL波动几十,标点的预测总是不稳定。
- 预测语句中的“的,了”等词也对PPL有很大影响,可能“我借你的书”比“我借你书”的指标值小几十,但从语义上分析有没有这些停用词并不能完全代表句子生成的好坏。
因此,语言模型评估时,我们可以用perplexity大致估计训练效果,作出判断和分析,但它不是完全意义上的标准,具体问题还是要具体分析。
