数据预处理之归一化、白化
背景及为什么需要归一化预处理?
- 一般而言,样本特征由于来源以及度量单位不同,它们的尺度(Scale)(即取值范围)往往差异很大.以描述长度的特征为例,当用“米”作单位时令其值为\(𝑥\),那么当用“厘米”作单位时其值为\(100𝑥\).
- 不同机器学习模型对数据特征尺度的敏感程度不一样 .如果一个机器学习算法在缩放全部或部分特征后 不影响它的学习和预测,我们就称该算法具有尺度不变性(Scale Invariance).
- 比如线性分类器是尺度不变的,
- 而最近邻分类器就是尺度敏感的.当我们计算不同样本之间的欧氏距离时,尺度大的特征会起到主导作用.
- 因此,对于尺度敏感的模型,必须先对样本进行预处理,将各个维度的特征转换到相同的取值区间,
- 并且消除不同特征之间的相关性,才能获得比较理想的结果.
从理论上,神经网络应该具有尺度不变性,可以通过参数的调整来适应不同特征的尺度.但尺度不同的输入特征会增加训练难度.
- 参数初始化比较困难
假设一个只有一层的网络\(𝑦 = tanh(𝑤_1𝑥_1 + 𝑤_2𝑥_2 + 𝑏)\),其中\(𝑥_1 ∈ [0, 10], 𝑥_2 ∈ [0, 1]\).之前我们提到\(tanh\)函数的导数在区间\([−2, 2]\)上是敏感的,其余的导数接近于\(0\).因此,如果\(𝑤_1𝑥_1 + 𝑤_2𝑥_2 + 𝑏\)过大或过小,都会导致梯度过小,难以训练.为了提高训练效率,我们需要使\(𝑤_1𝑥_1 + 𝑤_2𝑥_2 + 𝑏\)在\([−2, 2]\)区间, 因此需要将\(𝑤_1\)设得小一点,比如在\([−0.1, 0.1]\)之间.可以想象,如果数据维数很多时,我们很难这样精心去选择每一个参数.因此,如果每一个特征的尺度相似,比如\([0, 1]\)或者\([−1, 1]\), 我们就不太需要区别对待每一个参数,从而减少人工干预. - 影响梯度下降法的效率
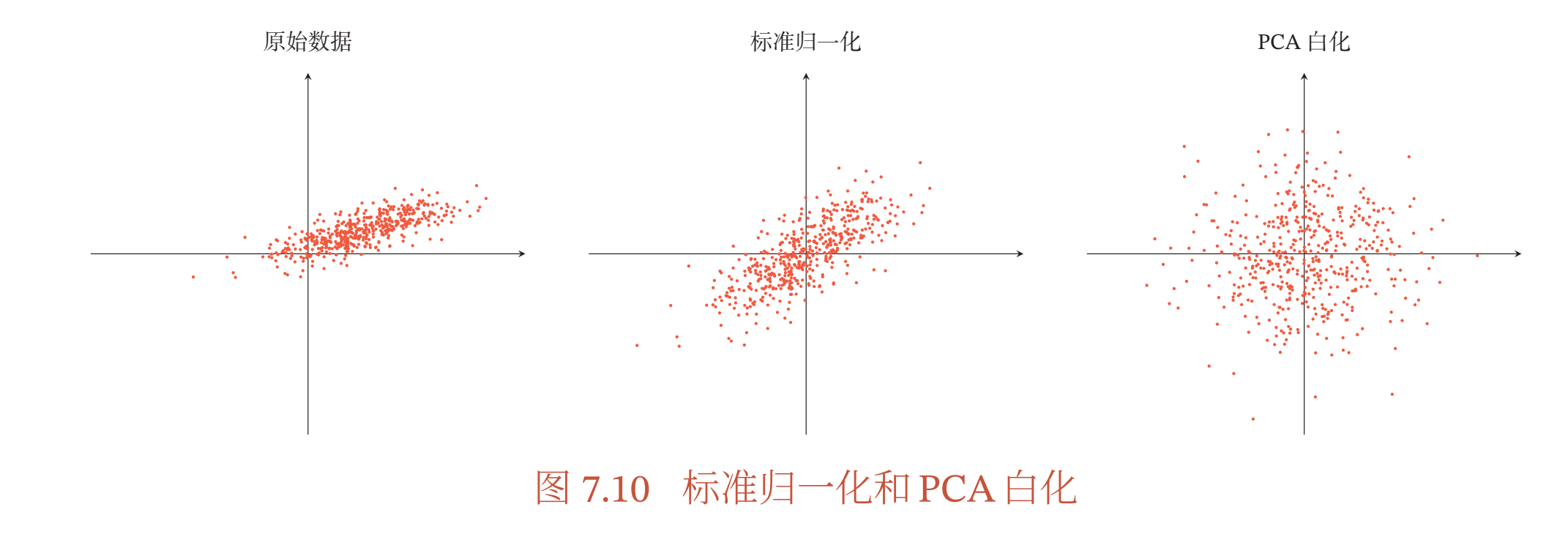
除了参数初始化比较困难之外,不同输入特征的尺度差异比较大时,梯度下降法的效率也会受到影响.图7.9给出了数据归一化对梯度的影响. 其中,图7.9a为未归一化数据的等高线图.尺度不同会造成在大多数位置上的梯度方向并不是最优的搜索方向.当使用梯度下降法寻求最优解时,会导致需要很多次迭代才能收敛.如果我们把数据归一化为相同尺度,如图7.9b所示,大部分位置的梯度方向近似于最优搜索方向.这样,在梯度下降求解时,每一步梯度的方向都基本指向最小值,训练效率会大大提高.
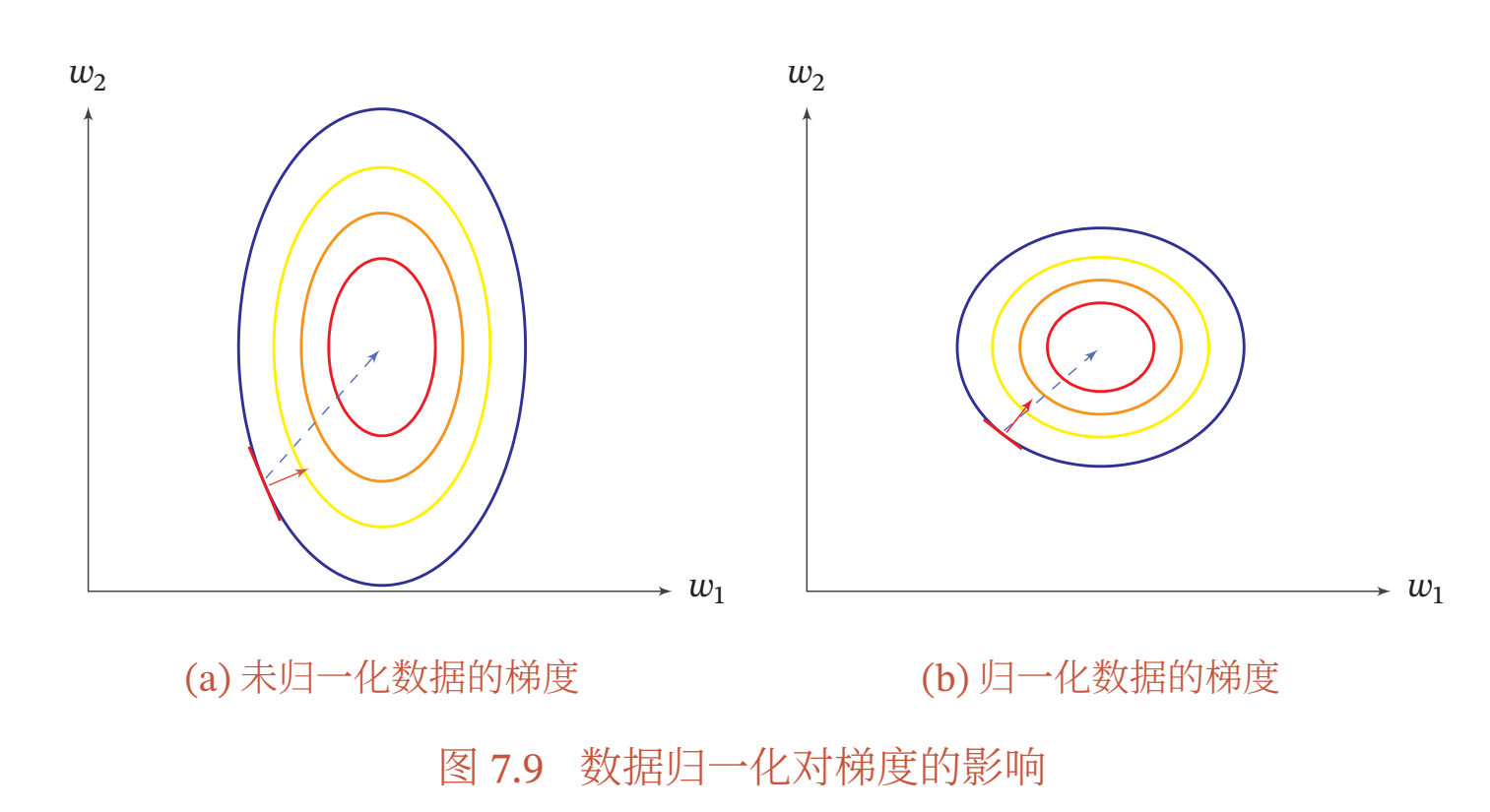
斯坦福机器学习视频做了很好的解释,如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征\(X_1\)和\(X_2\)的区间相差非常大,\(X_1\)区间是[0,2000],\(X_2\)区间是[1,5], 其所形成的等高线非常尖(\(X_1\)所对应的参数\(\theta_1\)的梯度:与\(X_1\)的值有关,\(X_2\)所对应的参数\(\theta_2\)的梯度:与\(X_2\)的值有关,参数\(\theta_1\)的梯度比参数\(\theta_2\)的梯度大,所以参数\(\theta_1\)的很小的变动,引起的\(J\)的变化更大)。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
归一化
归一化(Normalization)方法泛指 把数据特征转换为相同尺度的方法,比如把数据特征映射到\([0, 1]\)或\([−1, 1]\)区间内,或者映射为服从均值为\(0\)、方差为\(1\)的标准正态分布.归一化的方法有很多种,比如之前我们介绍的 Sigmoid型函数等都可以将不同尺度的特征挤压到一个比较受限的区间.这里,我们介绍几种在神经网络中经常使用的归一化方法.
最小最大值归一化
最小最大值归一化(Min-Max Normalization)是一种非常简单的归一化方法,通过缩放将每一个特征的取值范围归一到\([0, 1]\)或\([−1, 1]\)之间. 假设有\(𝑁\)个样本\(\{𝒙^{(𝑛)}\}^𝑁_{𝑛=1}\), 对于每一维特征\(𝑥\), 归一化后的特征为
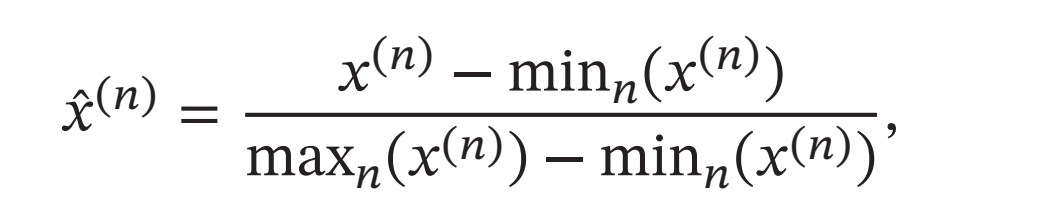
其中\(min(𝑥)\)和\(max(𝑥)\)分别是特征\(𝑥\)在所有样本上的最小值和最大值.
标准化
标准化(Standardization)也叫(Z-Score Normalization)Z值归一化,来源于统计上的标准分数.将每一个维特征都调整为均值为\(0\),方差为\(1\).假设有\(𝑁\)个样本\(\{𝒙^{(𝑛)}\}^𝑁_{𝑛=1}\), 对于每一维特征\(𝑥\),我们先计算它的均值和方差:
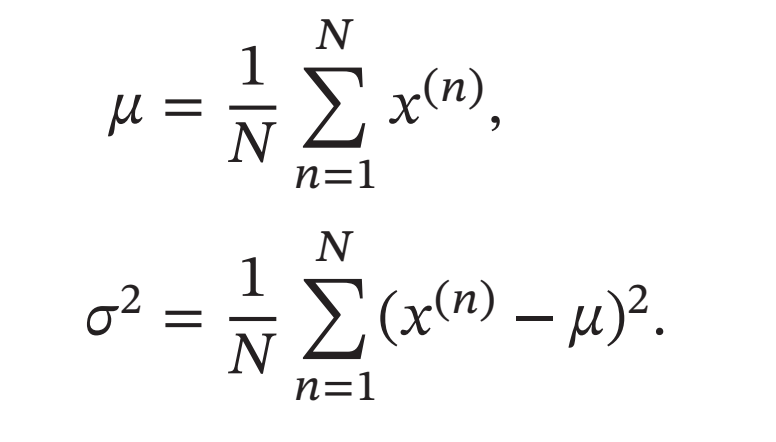
然后,将特征\(𝑥^{(𝑛)}\)减去均值,并除以标准差,得到新的特征值\(\tilde{𝑥}^{(𝑛)}\):
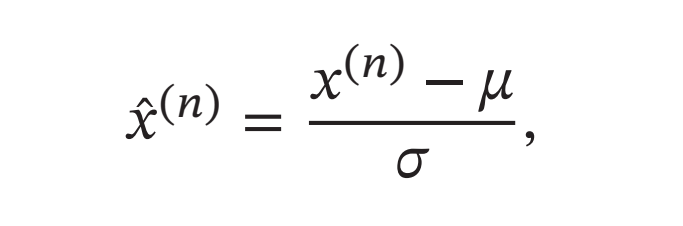
其中标准差\(𝜎\)不能为\(0\).如果标准差为\(0\),说明这一维特征没有任何区分性,可以直接删掉.
白化
白化(Whitening)是一种重要的预处理方法,用来降低输入数据特征之间的冗余性.输入数据经过白化处理后,特征之间相关性较低,并且所有特征具有相同的方差.白化的一个主要实现方式是使用主成分分析(Principal Component Analysis, PCA)方法去除掉各个成分之间的相关性.
图7.10给出了标准归一化和PCA白化的比较.