

LDA主题模型及gensim实战
概述
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。本文中的LDA仅指代Latent Dirichlet Allocation. LDA在主题模型中占有非常重要的地位,常用来文本分类。
LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
先导数学基础
LDA之所以很难懂,是因为其涉及到大量的数学知识。因此,为了更好的理解LDA,还是先铺垫一些数学知识。
多项分布
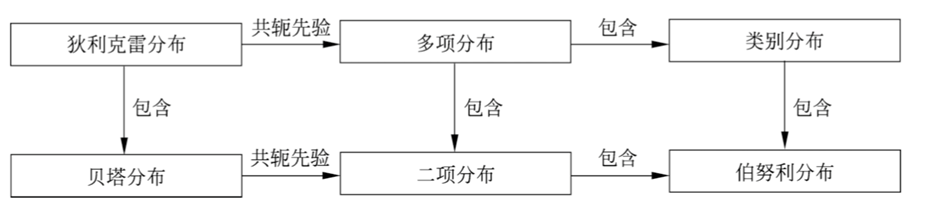
多项分布(multinomial distribution)是一种多元离散随机变量的概率分布,是二项分布(binomial distribution)的扩展。
假设重复进行\(n\)次独立随机试验,每次试验可能出现的结果有\(k\)种,第\(i\)种结果出现的概率为\(p_i\),第\(i\)种结果出现的次数为\(n_i\)。如果用随机变量\(X = (X_1,X_2,...,X_k)\)表示试验所有可能结果的次数,其中\(X_i\)表示第\(i\)种结果出现的次数。那么随机变量\(X\)服从多项分布。

- 当试验的次数\(n\)为\(1\)时,多项分布变成类别分布(categorical distribution)
- 类别分布表示试验可能出现的k种结果的概率
狄利克雷分布
狄利克雷分布(Dirichlet distribution)是一种多元连续随机变量的概率分布,是贝塔分布(beta distribution)的扩展。在贝叶斯学习中,狄利克雷分布常作为多项分布的先验分布使用。

对于狄利克雷分布的期望,有 \(E(Dirichlet(\vec \theta|\vec \alpha)) = (\frac{\alpha_1}{\sum\limits_{k=1}^K\alpha_k}, \frac{\alpha_2}{\sum\limits_{k=1}^K\alpha_k},...,\frac{\alpha_K}{\sum\limits_{k=1}^K\alpha_k})\)
注:
- 式中\(\Gamma(s)\)是伽马(Gamma)函数,定义为:
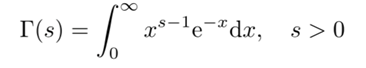
具有性质:\(\Gamma(s+1) = s\Gamma(s)\)。当\(s\)是自然数时,有\(\Gamma(s+1) = s!\) - 令
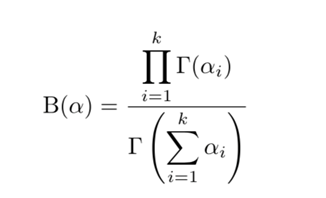
则狄利克雷分布的密度函数可以写成
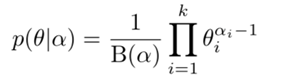
\(B(\alpha)\)是规范化因子,称为多元贝塔函数(或扩展的贝塔函数)。由密度函数的性质
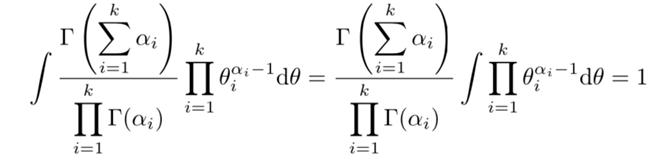
得
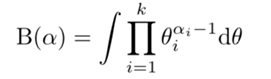
即多元贝塔函数的积分表示。
二项分布和贝塔分布
- 二项分布:
二项分布是多项分布的特殊情况,二项分布是指如下概率分布。\(X\)为离散随机变量,取值为\(m\),其概率质量函数为
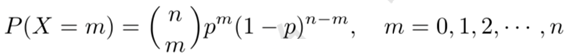
其中\(n\)和\(p(0≤p≤1)\)是参数。
当\(n\)为\(1\)时,二项分布变成伯努利分布(Bernoulli distribution)或\(0-1\)分布,伯努利分布表示试验可能出现的\(2\)种结果的概率。显然,二项分布包含伯努利分布。 - 贝塔(Beta)分布:
贝塔分布是狄利克雷分布的特殊情况,贝塔分布是指如下概率分布,\(X\)为连续随机变量,取值范围为\([0,1]\),其概率密度函数为
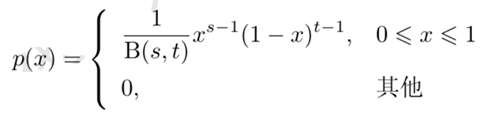
其中\(s>0\)和\(t>0\)是参数,\(B(s,t)=\frac{\Gamma(s)\Gamma(t)}{\Gamma(s+t)}\)是贝塔函数,定义为:
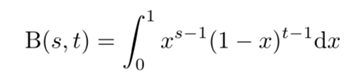
当\(s\),\(t\)是自然数时,\(B(s,t)=\frac{(s-1)!(t-1)!}{(s+t-1)!}\)
下图给出几种概率分布的关系。
LDA贝叶斯模型
LDA是基于贝叶斯模型的,涉及到贝叶斯模型离不开“先验分布”,“数据(似然)”和"后验分布"三块。在贝叶斯学派这里:
先验分布 + 数据(似然)= 后验分布
这点其实很好理解,因为这符合我们人的思维方式,比如你对好人和坏人的认知,先验分布为:100个好人和100个的坏人,即你认为好人坏人各占一半,现在你被2个好人(数据)帮助了和1个坏人骗了,于是你得到了新的后验分布为:102个好人和101个的坏人。现在你的后验分布里面认为好人比坏人多了。这个后验分布接着又变成你的新的先验分布,当你被1个好人(数据)帮助了和3个坏人(数据)骗了后,你又更新了你的后验分布为:103个好人和104个的坏人。依次继续更新下去。
共轭先验
狄利克雷分布有一些重要性质:
- 狄利克雷分布属于指数分布族
- 狄利克雷分布是多项分布的共扼先验(conjugate prior)
贝叶斯学习中常使用共扼分布,如果后验分布与先验分布属于同类,则先验分布与后验分布称为共扼分布(conjugate distributions),先验分布称为共扼先验(conjugate prior)。
如果多项分布的先验分布是狄利克雷分布,则其后验分布也为狄利克雷分布,两者构成共扼分布。作为先验分布的狄利克雷分布的参数又称为超参数。
使用共扼分布的好处是便于从先验分布计算后验分布。
设\(W = \{w_1,w_2,...,w_K \}\)是由\(K\)个元素组成的集合。随机变量\(X\)服从\(W\)上的多项分布,\(X\) ~ \(Mult(n,\theta)\),其中\(n\)和\(\theta = (\theta_1,\theta_2,...\theta_K)\)是参数,参数\(n\)为从\(W\)中重复独立抽取样本的次数,\(\vec n = (n_1,n_2,...,n_K)\),\(n_i,i=1,2,...K\)为样本中\(w_i\)出现的次数,参数\(\theta_i,i=1,2,...K\)为\(w_i\)出现的概率。
将样本数据表示为\(D\),目标是计算在样本数据\(D\)给定条件下参数\(\theta\)的后验概率\(p(\theta|D)\)。
对于给定的样本数据\(D\),似然函数是
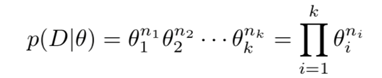
假设随机变量\(\theta\)服从狄利克雷分布\(p(\theta|\alpha)\),其中\(\alpha = (\alpha_1,\alpha_2,...\alpha_K)\)为参数。则\(\theta\)的先验分布为
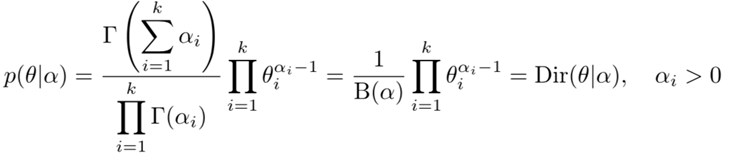
根据贝叶斯规则,在给定样本数据\(D\)和参数\(α\)条件下,\(\theta\)的后验概率分布是
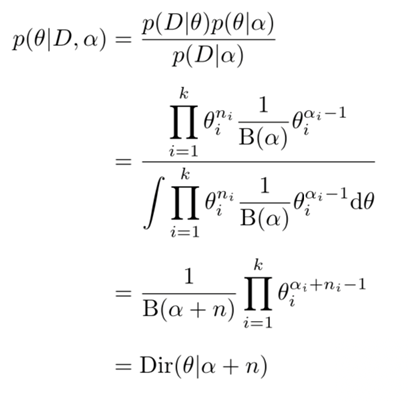
可以看出先验分布和后验分布都是狄利克雷分布,两者有不同的参数,所以狄利克雷分布是多项分布的共扼先验。
狄利克雷后验分布的参数等于狄利克雷先验分布参数\(\alpha = (\alpha_1,\alpha_2,...\alpha_K)\)加上多项分布的观测\(\vec n = (n_1,n_2,...,n_K)\),好像试验之前就已经观察到计数\(\alpha = (\alpha_1,\alpha_2,...\alpha_K)\),因此也把\(α\)叫做先验伪计数(prior pseudo-counts)。
LDA原理
LDA主题模型
前面做了这么多的铺垫,我们终于可以开始LDA主题模型了。
我们的问题是这样的,我们有\(M\)篇文档,对应第\(d\)个文档中有有\(N_d\)个词。即输入为如下图:
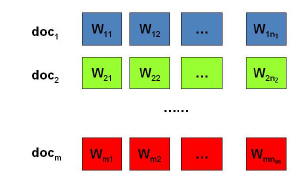
我们的目标是找到每一篇文档的主题分布和每一个主题中词的分布。在LDA模型中,我们需要先假定一个主题数目\(K\),这样所有的分布就都基于\(K\)个主题展开。那么具体LDA模型是怎么样的呢?具体如下图:
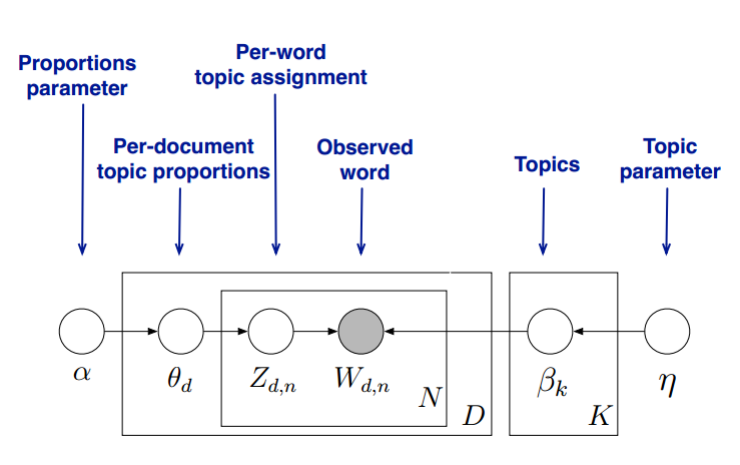
- LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档\(d\), 其主题分布\(θ_d\)为:
\(\theta_d = Dirichlet(\vec \alpha)\)
其中,\(\vec α\)为分布的超参数,是一个\(K\)维向量。 - LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题\(k\), 其词分布\(β_k\)为:
\(\beta_k= Dirichlet(\vec \eta)\)
其中,\(\vec η\)为分布的超参数,是一个\(V\)维向量。\(V\)代表词汇表里所有词的个数。 - 对于数据中任意一篇文档\(d\)中的第\(n\)个词,我们可以从主题分布\(θ_d\)中得到它的主题编号\(z_{d,n}\)的分布为:
\(z_{d,n} = multi(\theta_d)\) - 而对于该主题编号,得到我们看到的词\(w_{d,n}\)的概率分布为:
\(w_{d,n} = multi(\beta_{z_{d,n}})\)
理解LDA主题模型的主要任务就是理解上面的这个模型。
- 这个模型里,我们有\(M\)个文档主题的Dirichlet分布,而对应的数据有\(M\)个主题编号的多项分布,这样\(\alpha \to \theta_d \to \vec z_{d}\)就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。如果在第\(d\)个文档中,第\(k\)个主题的词的个数为:\(n_d^{(k)}\),则对应的多项分布的计数可以表示为\(\vec n_d = (n_d^{(1)}, n_d^{(2)},...n_d^{(K)})\),利用Dirichlet-multi共轭,得到\(\theta_d\)的后验分布为:\(Dirichlet(\theta_d | \vec \alpha + \vec n_d)\)。
- 同样的道理,对于主题与词的分布,我们有\(K\)个主题与词的Dirichlet分布,而对应的数据有K个主题编号的多项分布,这样\(\eta \to \beta_k \to \vec w_{(k)}\)就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。如果在第\(k\)个主题中,第\(v\)个词的个数为:\(n_k^{(v)}\), 则对应的多项分布的计数可以表示为\(\vec n_k = (n_k^{(1)}, n_k^{(2)},...n_k^{(V)})\),利用Dirichlet-multi共轭,得到\(β_k\)的后验分布为:\(Dirichlet(\beta_k | \vec \eta+ \vec n_k)\)。
- 由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。理解了上面这\(M+K\)组Dirichlet-multi共轭,就理解了LDA的基本原理了。
现在的问题是,基于这个LDA模型如何求解我们想要的每一篇文档的主题分布和每一个主题中词的分布呢?
一般有两种方法,
- 第一种是基于Gibbs采样算法求解,
- 第二种是基于变分推断EM算法求解。
在下面的小节里我们会介绍这两种求解方法。
LDA模型的求解
LDA求解之Gibbs采样算法
思路
- 在Gibbs采样算法求解LDA的方法中,我们的\(α\),\(η\)是已知的先验输入,我们的目标是得到各个\(z_{d,n}\),\(w_{k,n}\)对应的整体\(\vec z,\vec w\)的概率分布,即文档主题的分布和主题词的分布。由于我们是采用Gibbs采样法,则对于要求的目标分布,我们需要得到对应分布各个特征维度的条件概率分布。
- 具体到我们的问题,我们的所有文档联合起来形成的词向量\(\vec w\)是已知的数据,不知道的是语料库主题\(\vec z\)的分布。假如我们可以先求出\(w\),\(z\)的联合分布\(p(\vec w,\vec z)\),进而可以求出某一个词\(w_i\)对应主题特征\(z_i\)的条件概率分布\(p(z_i=k|\vec w,\vec z_{\neg i})\)。其中,\(\vec z_{\neg i}\)代表去掉下标为\(i\)的词对应的主题后的主题分布。有了条件概率分布\(p(z_i=k|\vec w,\vec z_{\neg i})\),我们就可以进行Gibbs采样,最终在Gibbs采样收敛后得到第\(i\)个词的主题。
- 如果我们通过采样得到了所有词的主题,那么通过统计所有词的主题计数,就可以得到各个主题的词分布。接着统计各个文档对应词的主题计数,就可以得到各个文档的主题分布。
以上就是Gibbs采样算法求解LDA的思路。
主题和词的联合分布与条件分布的求解
从上一节可以发现,要使用Gibbs采样求解LDA,关键是得到条件概率\(p(z_i=k| \vec w,\vec z_{\neg i})\)的表达式。那么这一节我们的目标就是求出这个表达式供Gibbs采样使用。
首先我们简化下Dirichlet分布的表达式,其中\(\triangle(\alpha)\)是归一化参数:\(Dirichlet(\vec p| \vec \alpha) = \frac{\Gamma(\sum\limits_{k=1}^K\alpha_k)}{\prod_{k=1}^K\Gamma(\alpha_k)}\prod_{k=1}^Kp_k^{\alpha_k-1} = \frac{1}{\triangle( \vec \alpha)}\prod_{k=1}^Kp_k^{\alpha_k-1}\)
现在我们先计算下第d个文档的主题的条件分布\(p(\vec z_d|\alpha)\),在上一篇中我们讲到\(\alpha \to \theta_d \to \vec z_d\)组成了Dirichlet-multi共轭,利用这组分布,计算\(p(\vec z_d|\alpha)\)如下:
\(\begin{align*} p(\vec z_d| \vec \alpha) & = \int p(\vec z_d | \vec \theta_d) p(\theta_d | \vec \alpha) d \vec \theta_d \\ & = \int \prod_{k=1}^Kp_k^{n_d^{(k)}} Dirichlet(\vec p | \vec \alpha) d \vec p \\ & = \int \prod_{k=1}^Kp_k^{n_d^{(k)}} \frac{1}{\triangle( \vec \alpha)}\prod_{k=1}^Kp_k^{\alpha_k-1}d \vec p \\ & = \frac{1}{\triangle( \vec \alpha)} \int \prod_{k=1}^Kp_k^{n_d^{(k)} + \alpha_k-1}d \vec p \\ & = \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)} \end{align*}\)
其中,在第d个文档中,第k个主题的词的个数表示为:\(n_d^{(k)}\),对应的多项分布的计数可以表示为
\(\vec n_d = (n_d^{(1)}, n_d^{(2)},...n_d^{(K)})\)
有了单一一个文档的主题条件分布,则可以得到所有文档的主题条件分布为:
\(p(\vec z|\vec \alpha) = \prod_{d=1}^Mp(\vec z_d|\vec \alpha) = \prod_{d=1}^M \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)}\)
同样的方法,可以得到,所有主题对应的词的条件分布\(p(\vec w|\vec z, \vec \eta)\)为:
\(p(\vec w|\vec z, \vec \eta) =\prod_{k=1}^Kp(\vec w_k|\vec z, \vec \eta) =\prod_{k=1}^K \frac{\triangle(\vec n_k + \vec \eta)}{\triangle( \vec \eta)}\)
其中,第k个主题中,第v个词的个数表示为:\(n_k^{(v)}\), 对应的多项分布的计数可以表示为
\(\vec n_k = (n_k^{(1)}, n_k^{(2)},...n_k^{(V)})\)
最终我们得到主题和词的联合分布\(p(\vec w, \vec z| \vec \alpha, \vec \eta)\)如下:
\(p(\vec w, \vec z) \propto p(\vec w, \vec z| \vec \alpha, \vec \eta) = p(\vec z|\vec \alpha) p(\vec w|\vec z, \vec \eta) = \prod_{d=1}^M \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)}\prod_{k=1}^K \frac{\triangle(\vec n_k + \vec \eta)}{\triangle( \vec \eta)}\)
有了联合分布,现在我们就可以求Gibbs采样需要的条件分布\(p(z_i=k| \vec w,\vec z_{\neg i})\).需要注意的是,这里的i是一个二维下标,对应第d篇文档的第n个词。
对于下标i,由于它对应的词\(w_i\)是可以观察到的,因此我们有:
\(p(z_i=k| \vec w,\vec z_{\neg i}) \propto p(z_i=k, w_i =t| \vec w_{\neg i},\vec z_{\neg i})\)
对于\(z_i=k, w_i =t\),它只涉及到第d篇文档和第k个主题两个Dirichlet-multi共轭,即:
\(\vec \alpha \to \vec \theta_d \to \vec z_d\)
\(\vec \eta \to \vec \beta_k \to \vec w_{(k)}\)
其余的\(M+K-2\)个Dirichlet-multi共轭和它们这两个共轭是独立的。如果我们在语料库中去掉\(z_i,w_i\),并不会改变之前的\(M+K\)个Dirichlet-multi共轭结构,只是向量的某些位置的计数会减少,因此对于\(\vec \theta_d, \vec \beta_k\),对应的后验分布为:
\(p(\vec \theta_d | \vec w_{\neg i},\vec z_{\neg i}) = Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha)\)
\(p(\vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) = Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta)\)
(要对此时,上面式子中的后验分布里的evidence数据做到心中有数)
现在开始计算Gibbs采样需要的条件概率:
\(\begin{align*} p(z_i=k| \vec w,\vec z_{\neg i}) & \propto p(z_i=k, w_i =t| \vec w_{\neg i},\vec z_{\neg i}) \\ & = \int p(z_i=k, w_i =t, \vec \theta_d , \vec \beta_k| \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \\ & = \int p(z_i=k, \vec \theta_d | \vec w_{\neg i},\vec z_{\neg i})p(w_i=t, \vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \\ & = \int p(z_i=k|\vec \theta_d )p( \vec \theta_d | \vec w_{\neg i},\vec z_{\neg i})p(w_i=t|\vec \beta_k)p(\vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \\ & = \int p(z_i=k|\vec \theta_d ) Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) d\vec \theta_d \\ & * \int p(w_i=t|\vec \beta_k) Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) d\vec \beta_k \\ & = \int \theta_{dk} Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) d\vec \theta_d \int \beta_{kt} Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) d\vec \beta_k \\ & = E_{Dirichlet(\theta_d)}(\theta_{dk})E_{Dirichlet(\beta_k)}(\beta_{kt})\end{align*}\)
(上面的第二个等式是因为,\(\vec \theta_d\)只依赖于\(\alpha\),\(z_i\)只依赖于\(\vec \theta_d\)。\(\vec \beta_k\)只依赖于\(\eta\),\(w_i\)只依赖于\(\vec \beta_k\)。故\(z_i,\vec \theta_d\)和\(w_i,\vec \beta_k\)在\(\vec w_{\neg i},\vec z_{\neg i}\)条件下,条件独立)。
在前面的先导数学基础那里,我们讲到了Dirichlet分布的期望公式,因此我们有:
\(E_{Dirichlet(\theta_d)}(\theta_{dk}) = \frac{n_{d, \neg i}^{k} + \alpha_k}{\sum\limits_{s=1}^Kn_{d, \neg i}^{s} + \alpha_s}\)
\(E_{Dirichlet(\beta_k)}(\beta_{kt})= \frac{n_{k, \neg i}^{t} + \eta_t}{\sum\limits_{f=1}^Vn_{k, \neg i}^{f} + \eta_f}\)
最终我们得到每个词对应主题的Gibbs采样的条件概率公式为:
\(p(z_i=k| \vec w,\vec z_{\neg i}) = \frac{n_{d, \neg i}^{k} + \alpha_k}{\sum\limits_{s=1}^Kn_{d, \neg i}^{s} + \alpha_s} \frac{n_{k, \neg i}^{t} + \eta_t}{\sum\limits_{f=1}^Vn_{k, \neg i}^{f} + \eta_f}\)
有了这个公式,我们就可以用Gibbs采样去采样所有词的主题,当Gibbs采样收敛后,即得到所有词的采样主题。
利用所有采样得到的词和主题的对应关系,我们就可以得到每个文档主题的分布\(\theta_d\)和每个主题中所有词的分布\(\beta_k\)。
算法流程
LDA Training:
- 1)选择合适的主题数\(K\), 选择合适的超参数向量\(\vec \alpha,\vec \eta\)
- 2)对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号\(z\)
- 3)重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的topic编号,并更新语料中该词的编号。
- 4)重复第3步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
- 5)统计语料库中的各个文档各个词的主题,得到文档主题分布\(θ_d\),统计语料库中各个主题词的分布,得到LDA的主题的词分布\(β_k\)。
LDA Inference:
下面我们再来看看当新文档出现时,如何统计该文档的主题。此时我们的模型已定,也就是LDA的各个主题的词分布\(β_k\)已经确定,我们需要得到的是该文档的主题分布。因此在Gibbs采样时,我们的\(E_{Dirichlet(\beta_k)}(\beta_{kt})\)已经固定,只需要对前半部分\(E_{Dirichlet(\theta_d)}(\theta_{dk})\)进行采样计算即可。
现在我们总结下LDA Gibbs采样算法的预测流程:
- 1)对应当前文档的每一个词,随机的赋予一个主题编号z
- 2)重新扫描当前文档,对于每一个词,利用Gibbs采样公式更新它的topic编号。
- 3)重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
- 4)统计文档中各个词的主题,得到该文档主题分布。
小结
使用Gibbs采样算法训练LDA模型,我们需要先确定三个超参数\(K, \vec \alpha,\vec \eta\).其中选择一个合适的\(K\)尤其关键,这个值一般和我们解决问题的目的有关。如果只是简单的语义区分,则较小的\(K\)即可,如果是复杂的语义区分,则\(K\)需要较大,而且还需要足够的语料。
由于Gibbs采样可以很容易的并行化,因此也可以很方便的使用大数据平台来分布式的训练海量文档的LDA模型。以上就是LDA Gibbs采样算法。
LDA求解之变分推断EM算法
有空再补充吧
LDA gensim实战
LDA新闻文本主题抽取
上面我们已经把LDA的理论部分讲完了,下面我们使用gensim这个NLP中常用的库来实战一把,用gensim训练LDA模型,进行新闻文本主题抽取。
第一步:对新闻进行分词
这次使用的新闻文档中有5000条新闻,有10类新闻,['体育', '财经', '房产', '家居', '教育', '科技', '时尚', '时政', '游戏', '娱乐'],每类有500条新闻。首先对文本进行清洗,去掉停用词、非汉字的特殊字符等。然后用jieba进行分词,将分词结果保存好。
#!/usr/bin/python
# -*- coding:utf-8 -*-
import jieba,os,re
# corpora:corpus的复数
from gensim import corpora, models, similarities
"""创建停用词列表"""
def stopwordslist():
stopwords = [line.strip() for line in open('./stopwords.txt',encoding='UTF-8').readlines()]
return stopwords
"""对句子进行中文分词"""
def seg_depart(sentence):
sentence_depart = jieba.cut(sentence.strip())
stopwords = stopwordslist()
outstr = ''
for word in sentence_depart:
if word not in stopwords:
outstr += word
outstr += " "
# outstr:'黄蜂 湖人 首发 科比 带伤 战 保罗 加索尔 ...'
return outstr
"""如果文档还没分词,就进行分词"""
if not os.path.exists('./cnews.train_jieba.txt'):
# 给出文档路径
filename = "./cnews.train.txt"
outfilename = "./cnews.train_jieba.txt"
inputs = open(filename, 'r', encoding='UTF-8')
outputs = open(outfilename, 'w', encoding='UTF-8')
# 把非汉字的字符全部去掉
for line in inputs:
line = line.split('\t')[1]
line = re.sub(r'[^\u4e00-\u9fa5]+','',line)
line_seg = seg_depart(line.strip())
outputs.write(line_seg.strip() + '\n')
outputs.close()
inputs.close()
print("删除停用词和分词成功!!!")
第二步:构建词频矩阵,训练LDA模型
gensim所需要的输入格式为:['黄蜂', '湖人', '首发', '科比', '带伤', '战',...],也就是每篇文档是一个列表,元素为词语。
然后构建语料库,再利用语料库把每篇新闻进行数字化,corpus就是数字化后的结果。
第一条新闻ID化后的结果为corpus[0]:[(0, 1), (1, 1), (2, 1), (3, 1), (4, 1),...],每个元素是新闻中的每个词语的ID和频率。
最后训练LDA模型。LDA是一种无监督学习方法,我们可以自由选择主题的个数。这里我们做了弊,事先知道了新闻有10类,就选择10个主题吧。
LDA模型训练好之后,我们可以查看10个主题的单词分布。
第6个主题(从0开始计数)的单词分布如下。还行,从“拍摄、电影、柯达”这些词,可以大致看出是娱乐主题。
(5, '0.007"中" + 0.004"拍摄" + 0.004"说" + 0.003"英语" + 0.002"时间" + 0.002"柯达" + 0.002"中国" + 0.002"国泰" + 0.002"市场" + 0.002"电影"')
从第10个主题的单词分布也大致可以看出是财经主题。
(9, '0.085"基金" + 0.016"市场" + 0.014"公司" + 0.013"投资" + 0.012"股票" + 0.011"分红" + 0.008"中" + 0.007"一季度" + 0.006"经理" + 0.006"收益"')
但效果还是不太令人满意,因为其他的主题不太看得出来是什么。
"""准备好训练语料,整理成gensim需要的输入格式"""
fr = open('./cnews.train_jieba.txt', 'r',encoding='utf-8')
train = []
for line in fr.readlines():
line = [word.strip() for word in line.split(' ')]
train.append(line)
# train: [['黄蜂', '湖人', '首发', '科比', '带伤', '战',...],[...],...]
"""构建词频矩阵,训练LDA模型"""
dictionary = corpora.Dictionary(train)
# corpus[0]: [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1),...]
# corpus是把每条新闻ID化后的结果,每个元素是新闻中的每个词语,在字典中的ID和频率
corpus = [dictionary.doc2bow(text) for text in train]
lda = models.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
topic_list = lda.print_topics(10)
print("10个主题的单词分布为:\n")
for topic in topic_list:
print(topic)
10个主题的单词分布为:
(0, '0.008*"中" + 0.005*"市场" + 0.004*"中国" + 0.004*"货币" + 0.004*"托管" + 0.003*"新" + 0.003*"债券" + 0.003*"说" + 0.003*"公司" + 0.003*"做"')
(1, '0.081*"基金" + 0.013*"公司" + 0.011*"投资" + 0.008*"行业" + 0.007*"中国" + 0.007*"市场" + 0.007*"中" + 0.007*"亿元" + 0.006*"规模" + 0.005*"新"')
(2, '0.013*"功能" + 0.009*"采用" + 0.008*"机身" + 0.007*"设计" + 0.007*"支持" + 0.007*"中" + 0.005*"玩家" + 0.005*"拍摄" + 0.005*"拥有" + 0.005*"倍"')
(3, '0.007*"中" + 0.006*"佣金" + 0.006*"企业" + 0.004*"考" + 0.004*"万家" + 0.003*"市场" + 0.003*"单词" + 0.003*"橱柜" + 0.003*"说" + 0.003*"行业"')
(4, '0.012*"拍摄" + 0.007*"中" + 0.007*"万" + 0.006*"镜头" + 0.005*"搭载" + 0.005*"英寸" + 0.005*"高清" + 0.005*"约" + 0.004*"拥有" + 0.004*"元"')
(5, '0.007*"中" + 0.004*"拍摄" + 0.004*"说" + 0.003*"英语" + 0.002*"时间" + 0.002*"柯达" + 0.002*"中国" + 0.002*"国泰" + 0.002*"市场" + 0.002*"电影"')
(6, '0.024*"考试" + 0.010*"相机" + 0.008*"套装" + 0.007*"拍摄" + 0.005*"万" + 0.005*"玩家" + 0.005*"中" + 0.004*"英寸" + 0.004*"索尼" + 0.004*"四级"')
(7, '0.019*"赎回" + 0.007*"基金" + 0.007*"净" + 0.006*"中" + 0.004*"市场" + 0.004*"资产" + 0.004*"收益" + 0.003*"中国" + 0.003*"债券" + 0.003*"说"')
(8, '0.010*"基金" + 0.010*"中" + 0.006*"公司" + 0.005*"产品" + 0.005*"市场" + 0.004*"元" + 0.004*"中国" + 0.004*"投资" + 0.004*"信息" + 0.004*"考试"')
(9, '0.085*"基金" + 0.016*"市场" + 0.014*"公司" + 0.013*"投资" + 0.012*"股票" + 0.011*"分红" + 0.008*"中" + 0.007*"一季度" + 0.006*"经理" + 0.006*"收益"')
第三步:抽取新闻的主题
我们还可以利用训练好的LDA,得到一条新闻的主题分布,也就是一条新闻属于各主题的可能性的概率分布。
找了三条新闻,分别是体育,娱乐和科技新闻:
体育 马晓旭意外受伤让国奥警惕 无奈大雨格外青睐殷家军记者傅亚雨沈阳报道 来到沈阳,国奥队依然没有摆脱雨水的困扰 ...
娱乐 尚雯婕筹备回沪献演□晨报记者 郭翔鹤 北京摄影报道 3月在北京举行了自己的首唱“尚佳分享·尚雯婕2008北京演唱会”后 ...
科技 摩托罗拉:GPON在FTTH中比EPON更有优势作 者:鲁义轩2009年,在国内光进铜退的火热趋势下,摩托罗拉携其在...
然后同样进行分词、ID化,通过lda.get_document_topics(corpus_test) 这个函数得到每条新闻的主题分布。得到新闻的主题分布之后,通过计算余弦距离,应该也可以进行文本相似度比较。
从结果中可以看到体育新闻的第6个主题的权重最大:(5, 0.60399055),可惜从第6个主题的单词分布来看,貌似这是个娱乐主题。
娱乐新闻的主题分布中,第5个主题的权重最大:(4, 0.46593386),而科技新闻的主题分布中,第3个主题的权重最大:(2, 0.38577113)。
"""抽取新闻的主题"""
# 用来测试的三条新闻,分别为体育、娱乐和科技新闻
file_test = "./cnews.test.txt"
news_test = open(file_test, 'r', encoding='UTF-8')
test = []
# 处理成正确的输入格式
for line in news_test:
line = line.split('\t')[1]
line = re.sub(r'[^\u4e00-\u9fa5]+','',line)
line_seg = seg_depart(line.strip())
line_seg = [word.strip() for word in line_seg.split(' ')]
test.append(line_seg)
# 新闻ID化
corpus_test = [dictionary.doc2bow(text) for text in test]
# 得到每条新闻的主题分布
topics_test = lda.get_document_topics(corpus_test)
labels = ['体育','娱乐','科技']
for i in range(3):
print('这条'+labels[i]+'新闻的主题分布为:\n')
print(topics_test[i],'\n')
fr.close()
news_test.close()
这条体育新闻的主题分布为:
[(2, 0.022305986), (3, 0.20627314), (4, 0.039145608), (5, 0.60399055), (7, 0.1253269)]
这条娱乐新闻的主题分布为:
[(3, 0.06871579), (4, 0.46593386), (7, 0.23081028), (8, 0.23132402)]
这条科技新闻的主题分布为:
[(2, 0.38577113), (5, 0.14801453), (6, 0.09730849), (7, 0.36559567)]
怎么确定LDA的topic个数
LDA中如何确定topic数量一直都没有公认的好方法,原因在于不同业务对于生成topic的要求是存在差异的。
- 如果LDA的结果是用于某个目标明确的学习任务(比如分类),那么就直接采用最终任务的指标来衡量就好了,能够实现分类效果最好的topic个数就是最合适的。
- 如果没有这样的任务怎么办?业界最常用的指标包括Perplexity,MPI-score等。
在LDA中,困惑度计算公式如下:
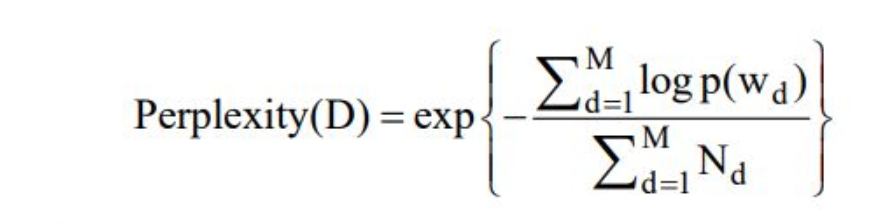
其中\(M\)为文档的总数,\(w_d\)为文档\(d\)中单词所组成的词袋向量,\(p(w_d)\)为模型所预测的文档\(d\)的生成概率,\(N_d\)为文档\(d\)中单词的总数。
以我的经验,通过观察Perplexity/MPI-score这些指标随topic个数的变化,确实能够帮助我们选择合适的个数值,比如可以找出曲线的拐点。但是这些指标只能作为参考,而不能作为标准。
另外,使用gensim包的童鞋注意了,千万不要用log_perplexity()计算的perplexity指标来比较topic数量的好坏!因为这个函数没有对主题数目做归一化,因此不同的topic数目不能直接比较! - 有的业务需要topic之间相互比较独立,那么就可以选择考察topic之间的相关性作为额外的指标。
- 而有的业务可以容忍topic之间存在overlap,但是对topic中词的聚合性要求高,这时候就需要寻找一些聚类的指标做评判标准。topic coherence
- 最后,肉眼看仍然是我目前发现的最简单有效的方法,基于经验 主观判断、不断调试、操作性强、最为常用。
参考资料:
李航:《统计学习方法》(第二版)
文本主题模型之LDA(一) LDA基础
文本主题抽取:用gensim训练LDA模型
怎么确定LDA的topic个数?
