

网络正则化
机器学习模型的关键是泛化问题,即在样本真实分布上的期望风险最小化.而训练数据集上的经验风险最小化和期望风险并不一致. 由于神经网络的拟合能力非常强,其在训练数据上的错误率往往都可以降到非常低,甚至可以到0,从而导致过拟合.因此,如何提高神经网络的泛化能力反而成为影响模型能力的最关键因素.
正则化(Regularization)是一类通过限制模型复杂度,从而避免过拟合,提高泛化能力的方法, 比如引入约束、增加先验、提前停止等.
在传统的机器学习中,提高泛化能力的方法主要是限制模型复杂度, 比如采用ℓ1和ℓ2正则化等方式.而在训练深度神经网络时,特别是在过度参数化(Over-Parameterization,过度参数化是指模型参数的数量远远大于训练数据的数量)时,ℓ1和ℓ2正则化的效果往往不如浅层机器学习模型中显著。因此训练深度学习模型时,往往还会使用其他的正则化方法,比如数据增强、提前停止、丢弃法、集成法等.
ℓ1 和ℓ2 正则化
ℓ1和ℓ2正则化是机器学习中最常用的正则化方法, 通过约束参数的ℓ1和ℓ2范数来减小模型在训练数据集上的过拟合现象.
通过加入ℓ1和ℓ2正则化,优化问题可以写为
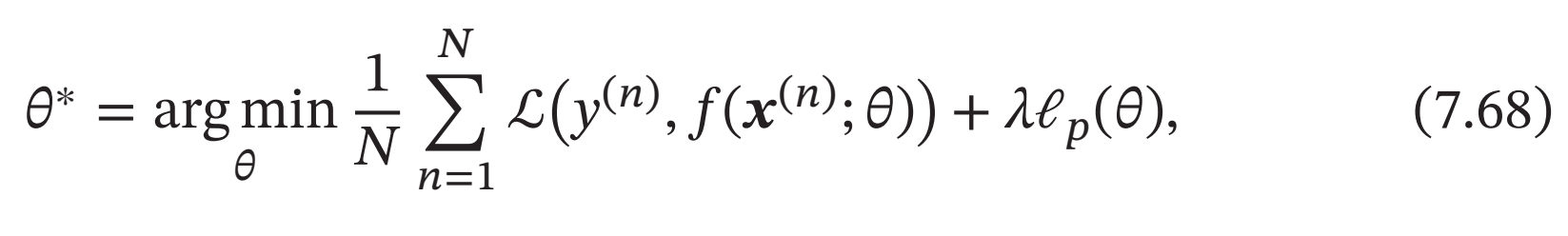
其中ℒ(⋅)为损失函数,𝑁为训练样本数量,𝑓(⋅)为待学习的神经网络,𝜃为其参数,ℓ𝑝为范数函数,𝑝的取值通常为{1, 2}代表ℓ1和ℓ2范数,𝜆为正则化系数.
带正则化的优化问题等价于下面带约束条件的优化问题,
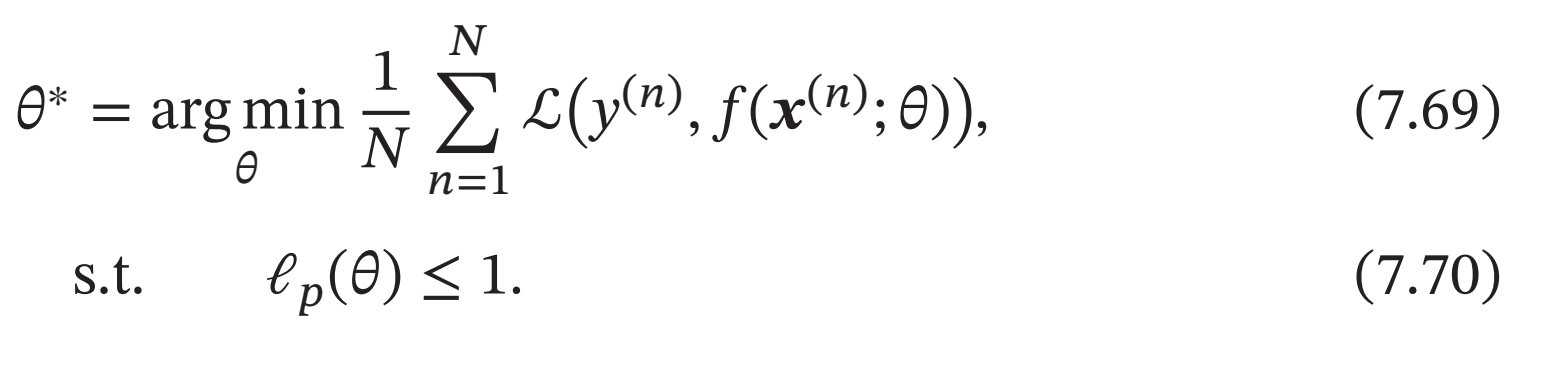
ℓ1范数在零点不可导,因此经常用下式来近似:
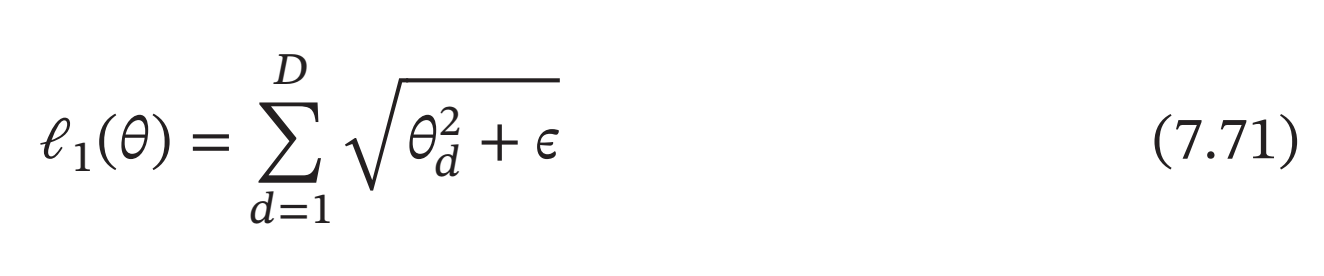
其中𝐷为参数数量,𝜖为一个非常小的常数.
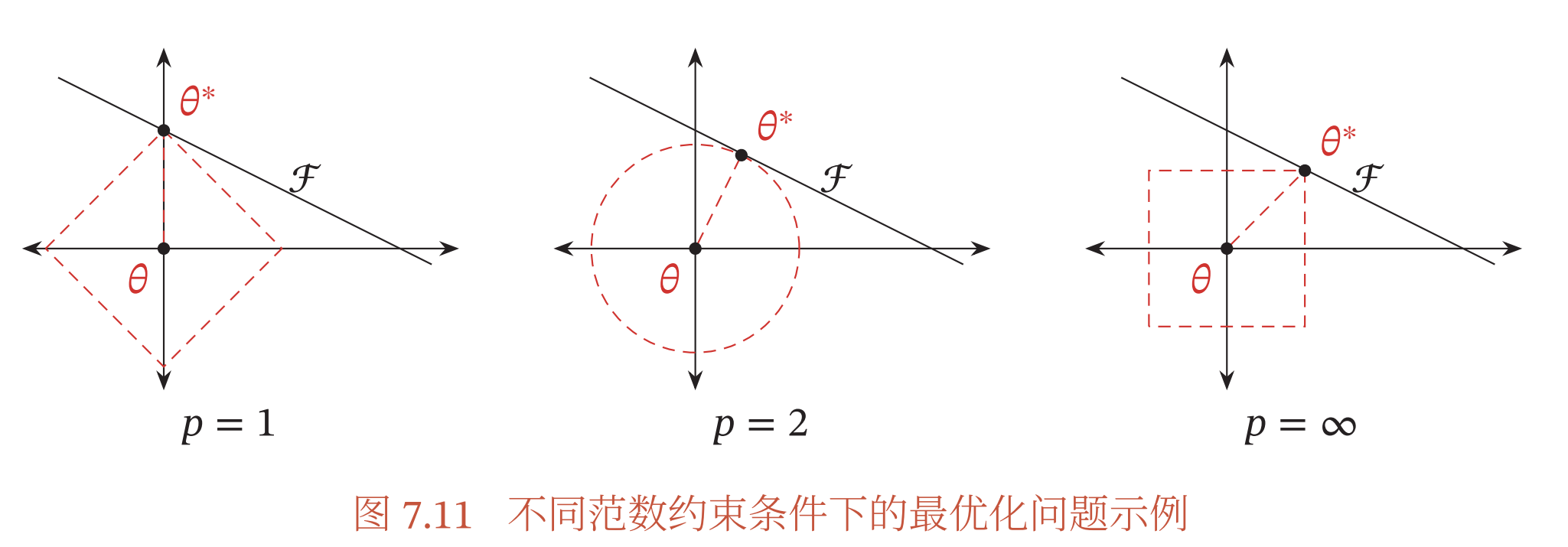
图7.11给出了不同范数约束条件下的最优化问题示例.红线表示函数ℓ𝑝 = 1,ℱ为函数𝑓(𝜃)的等高线(为简单起见,这里用直线表示)
可以看出,ℓ1范数的约束通常会使得最优解位于坐标轴上,从而使得最终的参数为稀疏性向量.
一种折中的正则化方法是同时加入ℓ1和ℓ2正则化,称为弹性网络正则化(Elastic Net Regularization)[Zou et al., 2005],
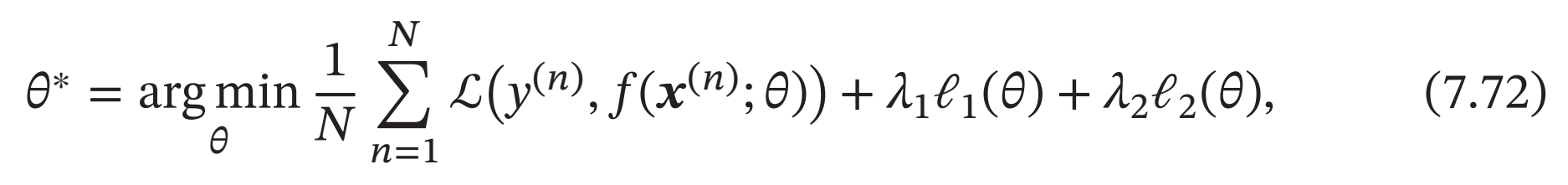
其中𝜆1和𝜆2分别为两个正则化项的系数.
权重衰减
权重衰减(Weight Decay)是一种有效的正则化方法[Hanson et al., 1989],在每次参数更新时, 引入一个衰减系数.
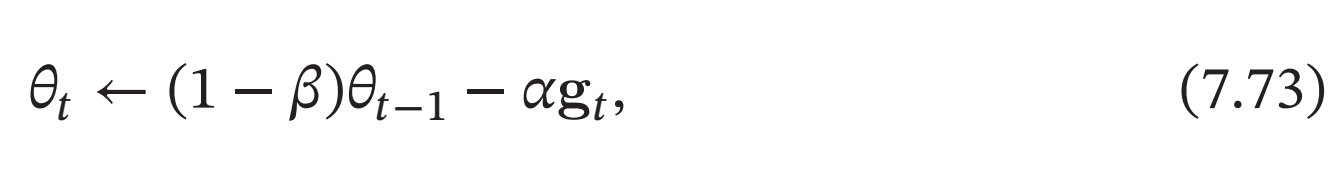
其中\(g_𝑡\)为第\(𝑡\)步更新时的梯度,\(𝛼\)为学习率,\(𝛽\)为权重衰减系数,一般取值比较小,比如\(0.0005\).在标准的随机梯度下降中,权重衰减正则化和\(ℓ2\)正则化的效果相同.因此,权重衰减在一些深度学习框架中通过\(ℓ2\)正则化来实现.但是,在较为复杂的优化方法(比如 Adam)中,权重衰减正则化和\(ℓ2\)正则化并不等价[Loshchilov et al., 2017b].
提前停止
提前停止(Early Stop)对于深度神经网络来说是一种简单有效的正则化方法。由于深度神经网络的拟合能力非常强,因此比较容易在训练集上过拟合.针对梯度下降的优化算法, 除了加正则化项之外,还可以通过提前停止来防止过拟合.
在梯度下降训练的过程中,由于过拟合的原因,在训练样本上收敛的参数,并不一定在测试集上最优.因此,除了训练集和测试集之外, 有时也会使用一个验证集(Validation Set,验证集也叫作开发集Development Set)来进行模型选择,测试模型在验证集上是否最优.在每次迭代时,把新得到的模型𝑓(𝒙; 𝜃)在验证集上进行测试,并计算错误率.如果在验证集上的错误率不再下降,就停止迭代.这种策略叫提前停止(Early
Stop). 如果没有验证集,可以在训练集上划分出一个小比例的子集作为验证集.
图2.4给出了提前停止的示例.
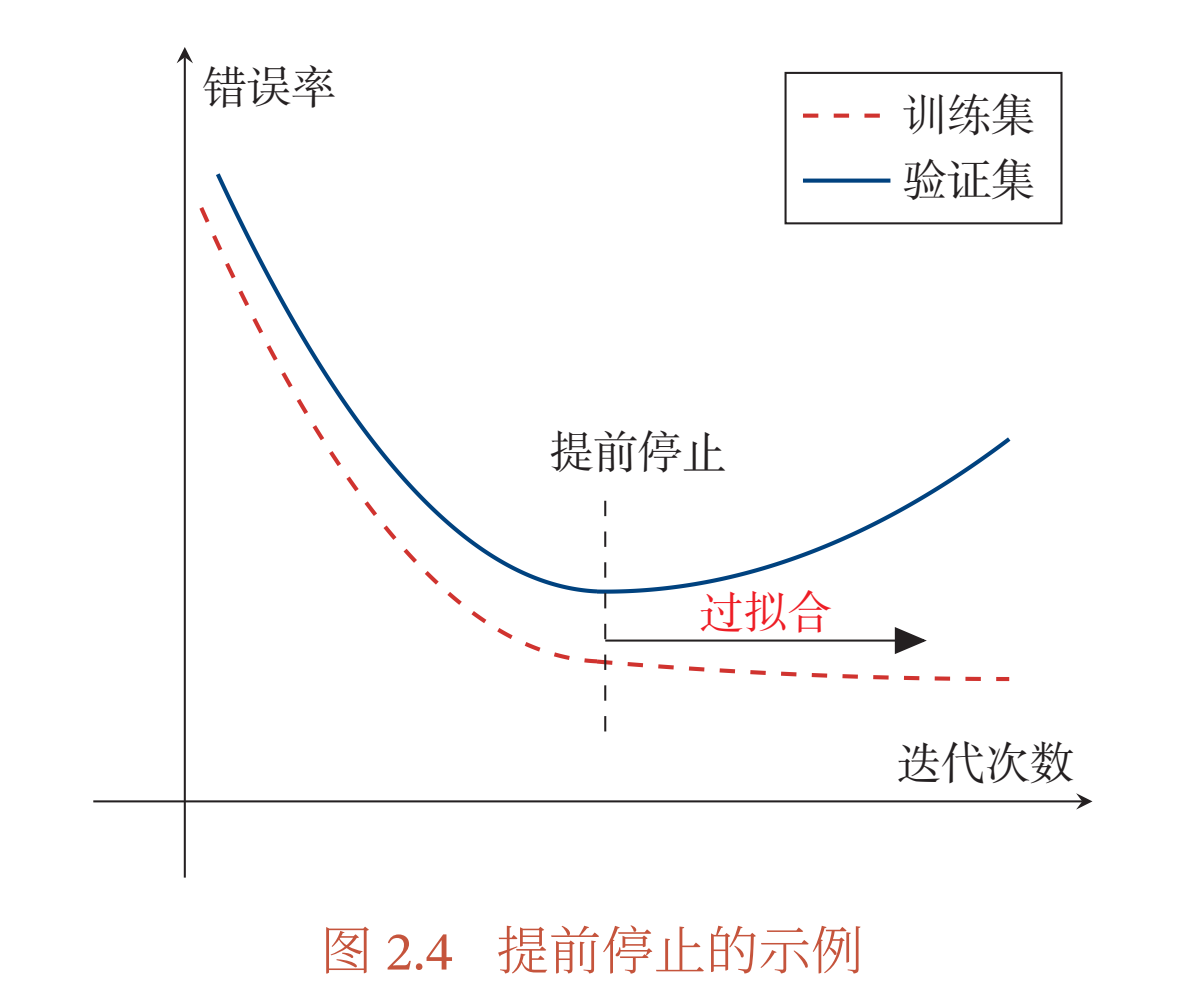
然而在实际操作中,验证集上的错误率变化曲线并不一定是图2.4中所示的平衡曲线, 很可能是先升高再降低.因此,提前停止的具体停止标准需要根据实际任务进行优化[Prechelt, 1998].
丢弃法
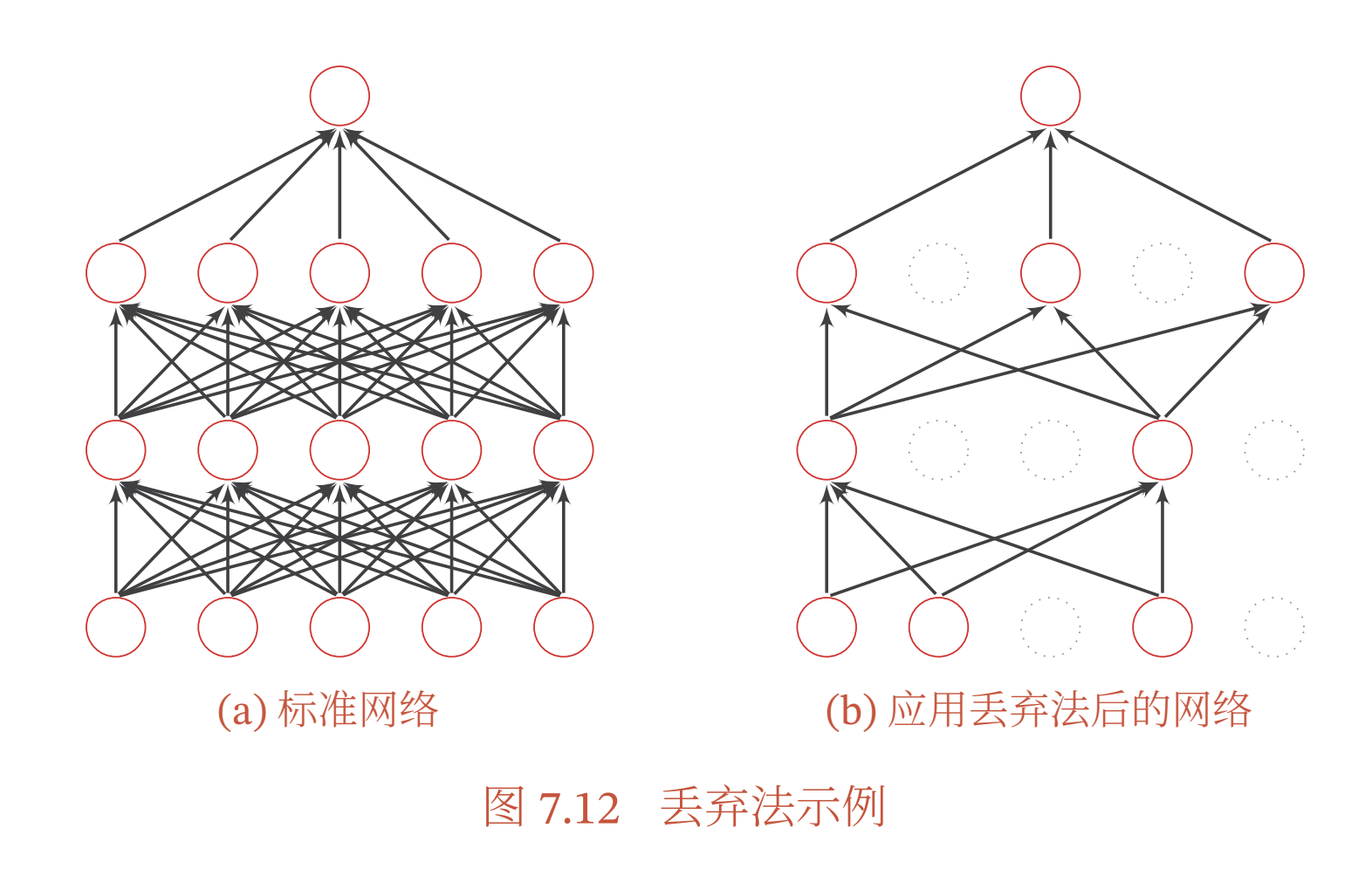
当训练一个深度神经网络时,我们可以随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合,这种方法称为丢弃法(Dropout Method)[Srivastava et al., 2014].每次选择丢弃的神经元是随机的.最简单的方法是设置一个固定的概率𝑝.对每一个神经元都以概率𝑝来判定要不要保留.对于一个神经层\(𝒚 = 𝑓(𝑾𝒙 + 𝒃)\),我们可以引入一个掩蔽函数mask(⋅)使得𝒚 = 𝑓(𝑾mask(𝒙) + 𝒃).掩蔽函数\(mask(⋅)\)的定义为

其中\(𝒎 ∈ \{0, 1\}^𝐷\) 是丢弃掩码(Dropout Mask),通过以概率为𝑝的伯努利分布随机生成,𝐷为输入𝒙的维度(通过在X上进行mask操作,X为上一层神经元的输出,对X进行mask,相当于使得上一层神经元进行随机失活). 在训练时, 激活神经元的平均数量为原来的𝑝倍. 而在测试时, 所有的神经元都是可以激活的, 这会造成训练和测试时网络的输出不一致. 为了缓解这个问题, 在测试时需要将神经层的输入 𝒙 乘以 𝑝, 也相当于把不同的神经网络做了平均.
保留率 𝑝 可以通过验证集来选取一个最优的值. 一般来讲,
- 对于隐藏层的神经元, 其保留率 𝑝 = 0.5 时效果最好, 这对大部分的网络和任务都比较有效. 当𝑝 = 0.5时, 在训练时有一半的神经元被丢弃, 只剩余一半的神经元是可以激活的, 随机生成的网络结构最具多样性.
- 对于输入层的神经元, 其保留率通常设为更接近1的数, 使得输入变化不会太大. 对输入层神经元进行丢弃时, 相当于给数据增加噪声, 以此来提高网络的鲁棒性.
丢弃法一般是针对神经元进行随机丢弃, 但是也可以扩展到对神经元之间的连接进行随机丢弃 [Wan et al., 2013], 或每一层进行随机丢弃. 图7.12给出了一个网络应用丢弃法后的示例.
-
集成学习角度的解释 每做一次丢弃, 相当于从原始的网络中采样得到一个子网络. 如果一个神经网络有 𝑛 个神经元, 那么总共可以采样出 \(2^𝑛\) 个子网络. 每次迭代都相当于训练一个不同的子网络, 这些子网络都共享原始网络的参数. 那么, 最终的网络可以近似看作集成了指数级个不同网络的组合模型.
-
贝叶斯学习角度的解释 丢弃法也可以解释为一种贝叶斯学习的近似[Gal et al.,2016a]. 用\(𝑦 = 𝑓(𝒙; 𝜃)\)来表示要学习的神经网络, 贝叶斯学习是假设参数
𝜃为随机向量, 并且先验分布为\(𝑞(𝜃)\), 贝叶斯方法的预测为
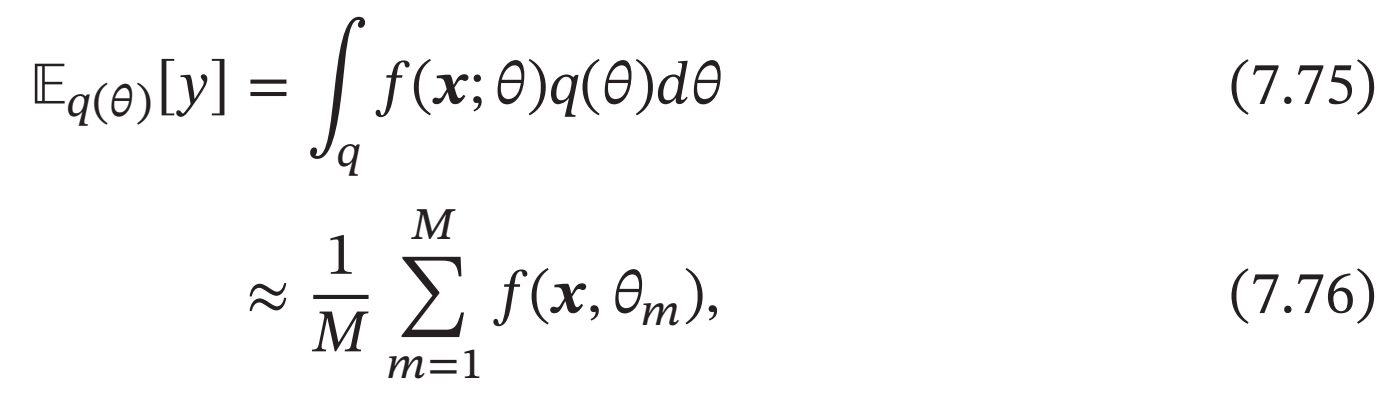
其中\(𝑓(𝒙, 𝜃_𝑚)\)为第𝑚次应用丢弃方法后的网络, 其参数\(𝜃_𝑚\) 为对全部参数𝜃的一次采样(个人:贝叶斯学习是针对参数的,认为参数为随机变量,这里针对全部参数的采样应该是丢弃一些边的连接).
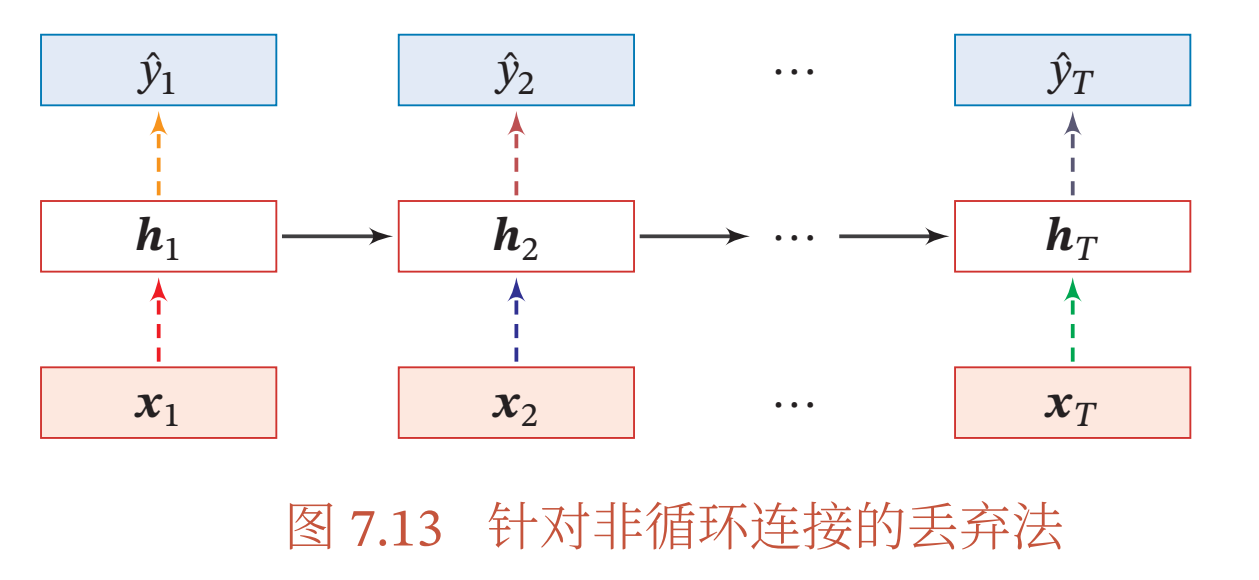
当在循环神经网络上应用丢弃法时, 不能直接对每个时刻的隐状态进行随机丢弃, 这样会损害循环网络在时间维度上的记忆能力. 一种简单的方法是对非时间维度的连接( 即非循环连接) 进行随机丢失[Zaremba et al., 2014]. 如图7.13所示, 虚线边表示进行随机丢弃,不同的颜色表示不同的丢弃掩码.
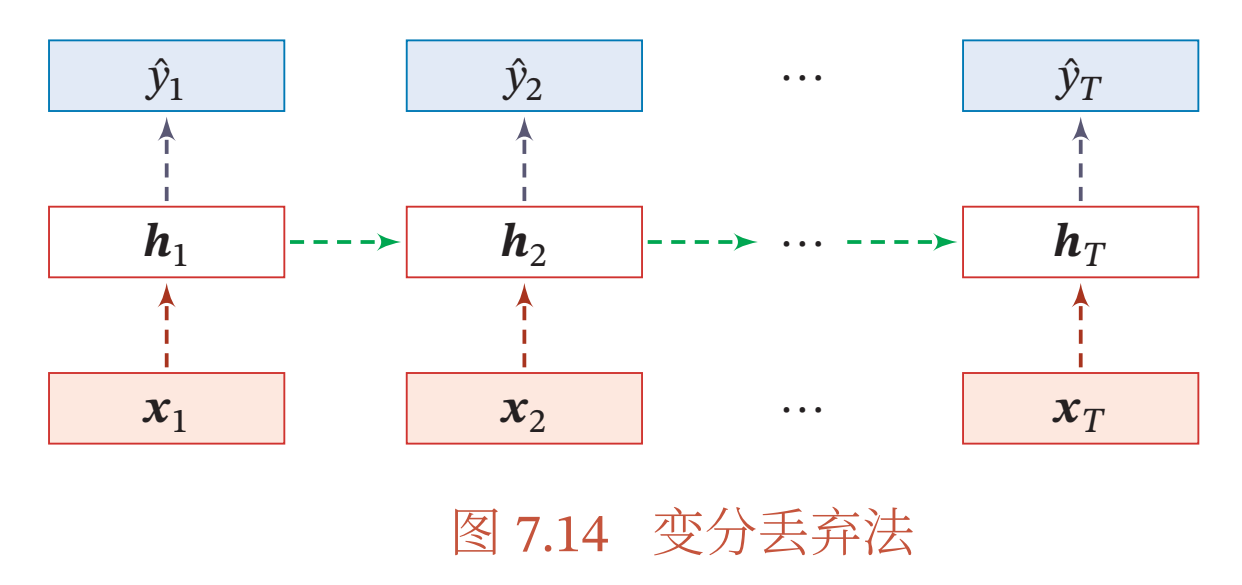
然而根据贝叶斯学习的解释, 丢弃法是一种对参数𝜃 的采样. 每次采样的参数需要在每个时刻保持不变. 因此, 在对循环神经网络上使用丢弃法时, 需要对参数矩阵的每个元素进行随机丢弃, 并在所有时刻都使用相同的丢弃掩码.这种方法称为变分丢弃法( Variational Dropout)[Gal et al., 2016b].图7.14给出了变
分丢弃法的示例,相同颜色表示使用相同的丢弃掩码.
数据增强
深度神经网络一般都需要大量的训练数据才能获得比较理想的效果. 在数据量有限的情况下,可以通过数据增强(Data Augmentation) 来增加数据量,提高模型鲁棒性,避免过拟合。目前,数据增强还主要应用在图像数据上,在文本等其他类型的数据上还没有太好的方法.
图像数据的增强主要是通过算法对图像进行转变,引入噪声等方法来增加数据的多样性. 增强的方法主要有几种:
- 旋转( Rotation): 将图像按顺时针或逆时针方向随机旋转一定角度
- 翻转( Flip): 将图像沿水平或垂直方向随机翻转一定角度
- 缩放( Zoom In/Out): 将图像放大或缩小一定比例
- 平移( Shift): 将图像沿水平或垂直方法平移一定步长
- 加噪声( Noise): 加入随机噪声
标签平滑
在数据增强中,我们可以给样本特征加入随机噪声来避免过拟合。同样,我们也可以给样本的标签引入一定的噪声.假设训练数据集中有一些样本的标签是被错误标注的,那么最小化这些样本上的损失函数会导致过拟合.一种改善的正则化方法是标签平滑(Label Smoothing),即在输出标签中添加噪声来避免模型过拟合[Szegedy et al., 2016].
一个样本𝒙的标签可以用one-hot向量表示, 即
\(𝒚 = [0, ⋯ , 0, 1, 0, ⋯ , 0]^T\).
这种标签可以看作硬目标(Hard Target).如果使用Softmax分类器,并使用交叉熵损失函数,最小化损失函数,会使得正确类和其他类的权重差异变得很大.
- 根据Softmax函数的性质可知, 如果要使得某一类的输出概率接近于1,其未归一化的得分需要远大于其他类的得分,可能会导致其权重越来越大,并导致过拟合(个人:这个权重相对于其他的类很大,会起主导作用,导致分类时倾向于这个类,导致过拟合).
- 此外,如果样本标签是错误的,会导致更严重的过拟合现象.
为了改善这种情况,我们可以引入一个噪声对标签进行平滑,即假设样本以\(𝜖\)的概率为其他类.平滑后的标签为
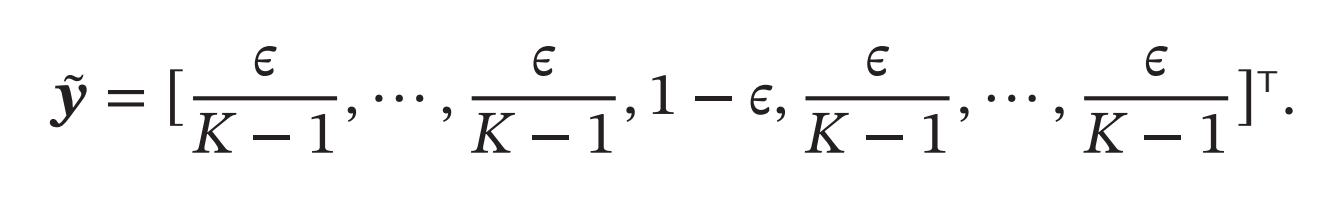
其中𝐾为标签数量,这种标签可以看作软目标(Soft Target)。标签平滑可以避免模型的输出过拟合到硬目标上,并且通常不会损害其分类能力.
上面的标签平滑方法是给其他\(𝐾 − 1\)个标签相同的概率 \(\frac{𝜖 }{𝐾−1}\),没有考虑标签之间的相关性.一种更好的做法是按照类别相关性来赋予其他标签不同的概率.比如先训练另外一个更复杂(一般为多个网络的集成)的教师网络(Teacher Network),并使用大网络的输出作为软目标来训练学生网络(Student Network).这种方法也称为知识蒸馏( Knowledge Distillation) [Hinton et al.,2015].
