

预训练语言模型Bert算法原理
概述
BERT的全称是Bidirectional Encoder Representation from Transformers,是论文BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding中提出的预训练语言模型。这篇论文把预训练语言表示方法分为了以下两种:
- 基于特征的方法(代表ELMo)
- 基于微调的方法(代表OpenAI GPT)

而目前这两种方法在预训练时都是使用单向的语言模型来学习语言表示。这篇论文中,作者们证明了使用双向的预训练效果更好。
其实这篇论文方法的整体框架和GPT类似,是进一步的发展。具体的,他们BERT是使用Transformer的编码器来作为语言模型,在语言模型预训练的时候,提出了两个新的目标任务:
- 遮挡语言模型MLM
- 预测下一个句子的任务Next Sentence Prediction
最后在11个NLP任务上取得了SOTA。

预训练语言模型Bert
BERT模型总体结构
在语言模型上,BERT使用的是多层双向Transformer编码器,并且设计了一个小一点Base结构和一个更大的Large网络结构。

ELMo、GPT、Bert的模型架构的区别
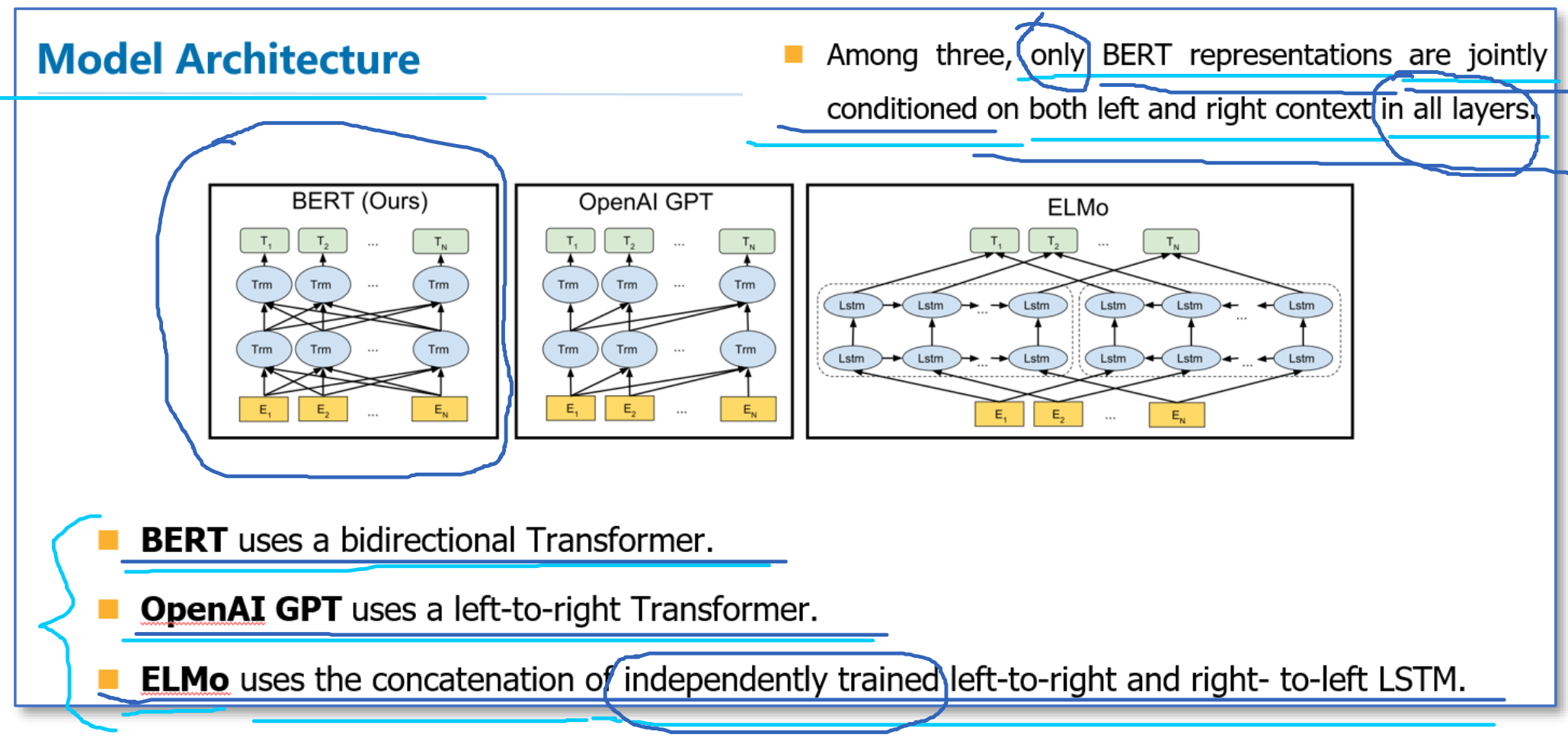
- 对比OpenAI GPT(Generative pre-trained transformer),BERT使用的是Transformer编码器;而OpenAI GPT使用的是Transformer解码器,它是一个需要从左到右的受限制的Transformer。
- 对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以
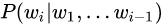 和
和 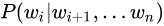 作为目标函数(这两个目标函数训练时都只考虑了单向的上下文),独立训练出两个representation然后拼接,而BERT则是以
作为目标函数(这两个目标函数训练时都只考虑了单向的上下文),独立训练出两个representation然后拼接,而BERT则是以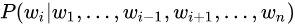 作为目标函数训练LM(假设i为mask位置),Bert训练时的目标函数中已经共同地考虑了左和右的上下文。
作为目标函数训练LM(假设i为mask位置),Bert训练时的目标函数中已经共同地考虑了左和右的上下文。
BERT模型输入
而在模型的输入方面,BERT做了更多的细节,如下图。他们使用了WordPiece embedding作为词向量,并加入了位置向量和句子切分向量。并在每一个文本输入前加入了一个CLS向量,后面会有这个向量作为具体的分类向量。
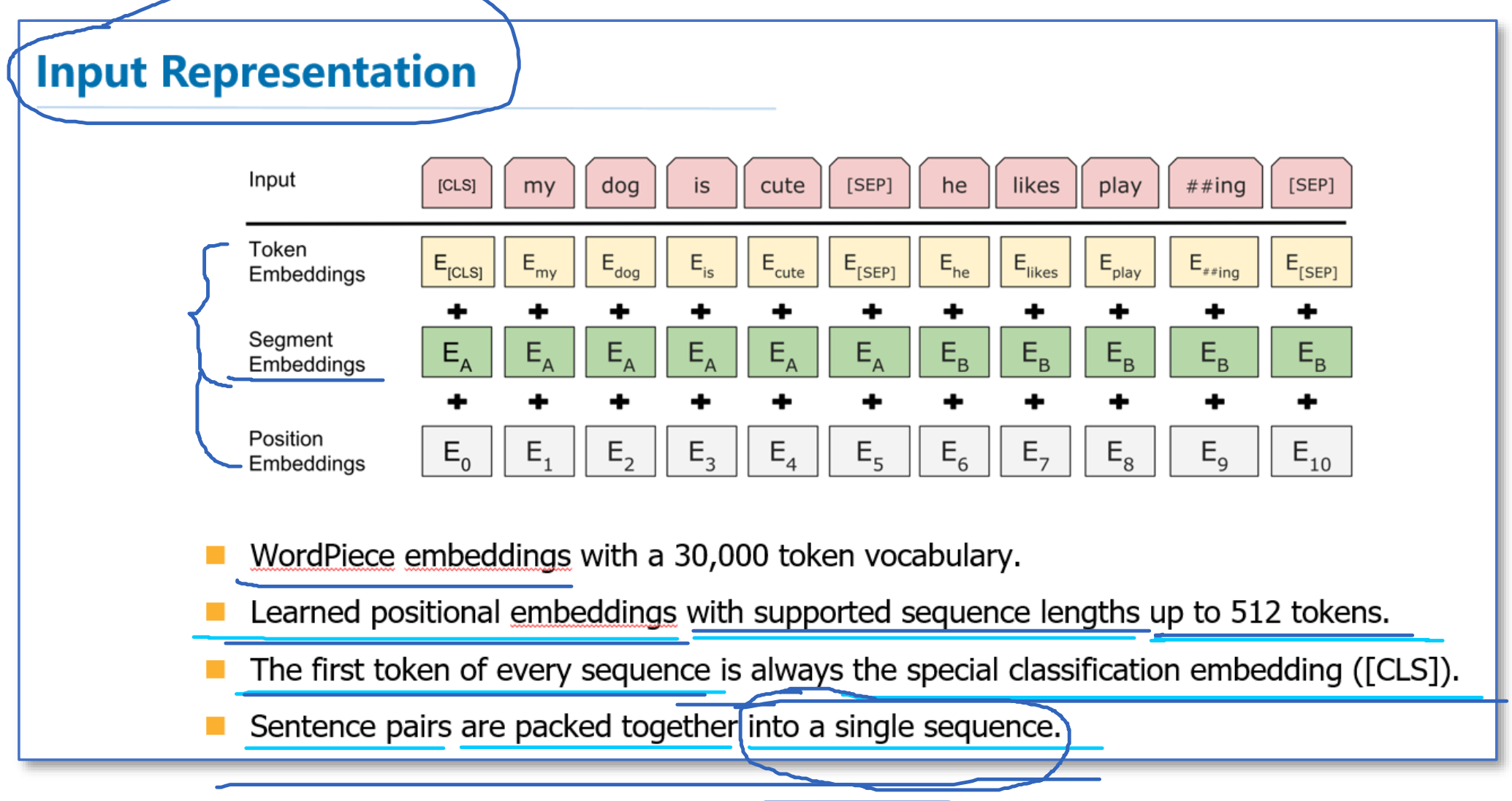
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
BERT模型预训练任务
在语言模型预训练上,Bert不再使用标准的从左到右或者从右到左预测下一个词作为目标任务,而是使用了两个新的无监督预测任务对BERT进行预训练,分别是Masked LM和Next Sentence Prediction。
Masked LM
第一个任务称为MLM,即在输入的词序列中,随机的挡上15%的词,然后任务就是去预测挡上的这些词。可以看到相比传统的语言模型预测目标函数,MLM可以从任何方向去预测这些挡上的词,而不仅仅是单向的。但是这样做会带来两个缺点:
- 预训练用
[MASK]剔除挡住的词后,在微调阶段是没有[MASK]这个词的,所以会出现不匹配; - 预测15%的词而不是预测整个句子,使得预训练的收敛更慢。
但是对于第二点,作者们觉得虽然是慢了,但是效果提升比较明显可以弥补。

对于第一点他们采用了下面的技巧来缓解,即不是总是用[MASK]去替换挡住的词,在10%的时间用一个随机词取替换,10%的时间就用这个词本身。

Next Sentence Prediction
而对于传统语言模型,并没有对句子之间的关系进行考虑。而很多句子级别的任务如自动问答(QA)和自然语言推理(NLI)都需要理解两个句子之间的关系。为了让模型能够学习到句子之间的关系,作者们提出了第二个目标任务就是预测下一个句子。其实就是一个二元分类问题,50%的时间,输入一个句子和下一个句子的拼接,分类标签是正例,而另50%是输入一个句子和非下一个随机句子的拼接,标签为负例(个人猜测应该是为了保持正负样本类别平衡吧)。最后整个预训练的目标函数就是这两个任务的取和求似然。

Fine-tunning
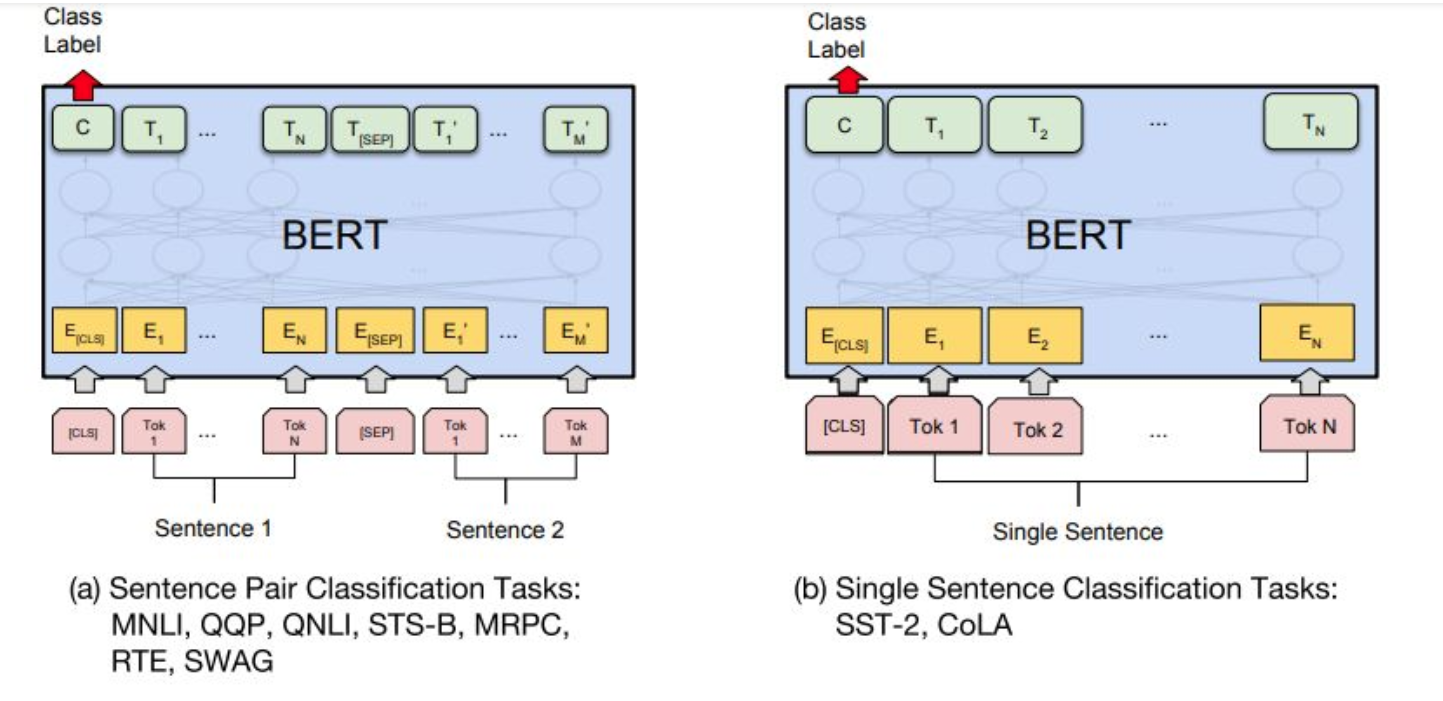
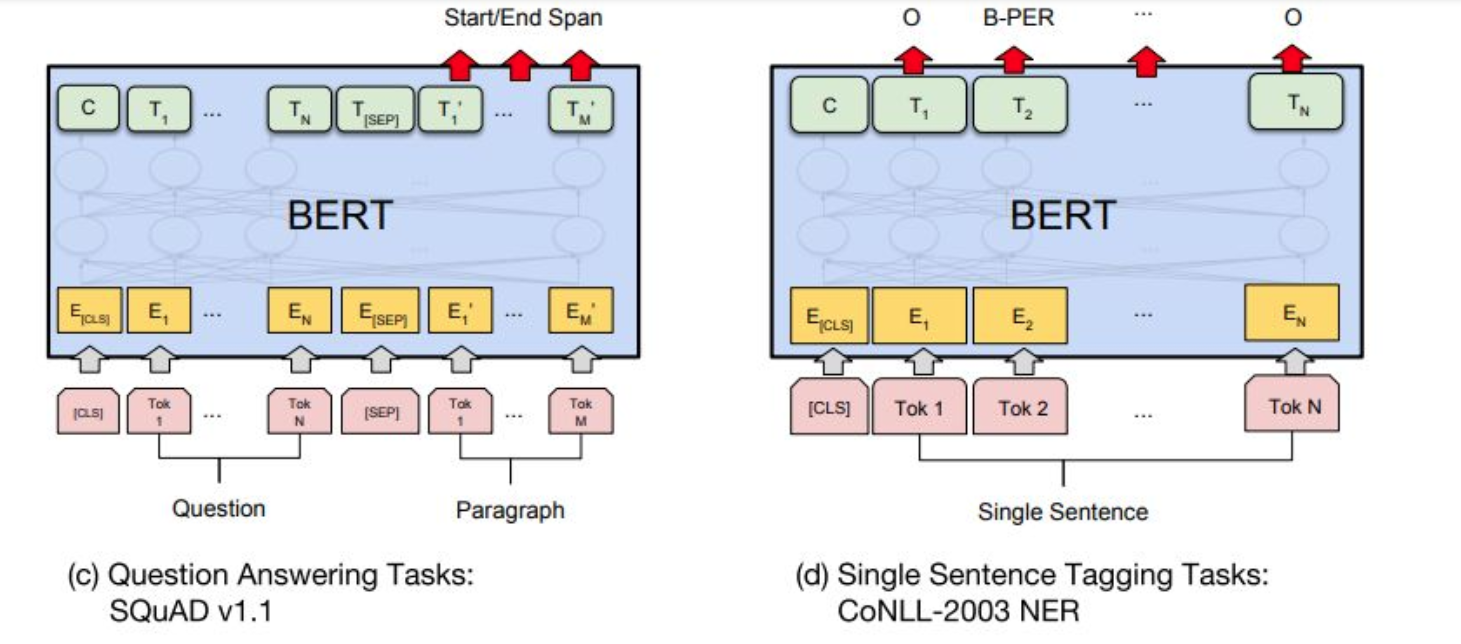
在微调阶段,不同任务的模型如下图,只是在输入层和输出层有所区别,然后整个模型所有参数进行微调。
可以调整的参数和取值范围有:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
因为大部分参数都和预训练时一样,精调会快一些,所以作者推荐多试一些参数。
论文中的实验表明,大规模的模型效果更好,即使在小数据集上。此外,作者也做了像ELMo当成特征加入的实验,从下图可以看到,当成特征加入最好效果能达到96.1%和微调的96.4%差不多,说明BERT对于基于特征和基于微调这两种方法都是有效的。

总结
-
和传统的词向量相比,使用语言模型预训练其实可以看成是一个句子级别的上下文的词表示,它可以充分利用大规模的单语语料,并且可以对一词多义进行建模。而且通过大规模语料预训练后,使用统一的模型或者是当成特征直接加到一些简单模型上,对各种NLP任务都能取得不错的效果,说明很大程度上缓解了具体任务对模型结构的依赖。在目前很多评测上也都取得了SOTA。ELMo也提供了官网供大家使用。
-
但是这些方法在空间和时间复杂度上都比较高,特别是BERT,在论文中他们训练base版本需要在16个TGPU上,large版本需要在64个TPU上训练4天,对于一般条件,一个GPU训练的话,得用上1年。
-
还有就是可以看出这些方法里面都存在很多工程细节,一些细节做得不好的话,效果也会大大折扣。

