

预训练语言模型Open AI GPT算法原理
概述
Open AI GPT是OpenAI 团队在论文Improving Language Understanding by Generative Pre-Training中提出的预训练语言模型,他们的目标是学习一个通用的表示,能够在大量任务上进行应用。核心思想是先通过无标签的文本去训练生成语言模型,再根据具体的NLP任务(如文本蕴涵、QA、文本分类等),来通过有标签的数据对模型进行fine-tuning。具体来说,在这篇论文中提出了半监督的方法,即结合了无监督的预训练和有监督的fine-tuning。论文采用两阶段训练:
- 在未标记数据集上训练语言模型来学习神经网络模型的初始参数。
- 使用相应NLP任务中的有标签的数据将这些参数微调,来适应当前任务。
这篇论文的亮点主要在于,他们利用了多层的单向Transformer结构代替了LSTM作为语言模型来更好的捕获长距离语言结构。然后在进行具体任务有监督微调时,使用了语言模型作为附属任务训练目标。最后再12个NLP任务上进行了实验,9个任务获得了SOTA。

OpenAI GPT模型结构
非监督预训练
首先我们来看一下他们无监督预训练时的语言模型。他们仍然使用的是标准的语言模型目标函数,即通过前k个词预测当前词,但是在语言模型网络上他们使用了google团队在《Attention is all your need》论文中提出的Transformer解码器作为语言模型。
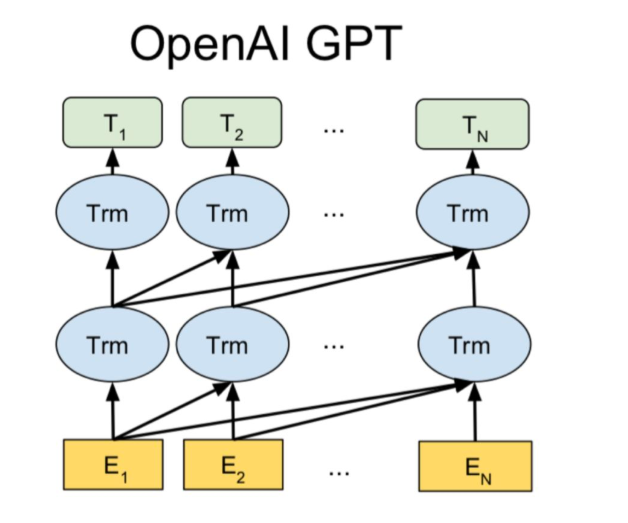


注:\(U\)的维数为\(seq*voc\_size\),每一行为token的one-hot编码,\(W_e\)的维数为\(voc\_size*dim\),每一行为单词的词嵌入,\(W_p\)的维数为\(seq*dim\),每一行为位置embeding
有监督微调
然后在具体NLP任务有监督微调时,与ELMo当成特征的做法不同,OpenAI GPT不需要再重新对任务构建新的模型结构,而是直接在transformer这个语言模型上的最后一层接上softmax作为任务输出层,然后再对这整个模型进行微调。他们额外发现,
- 如果使用语言模型作为辅助任务,能够提升有监督模型的泛化能力,
- 并且能够加速收敛。

特殊任务的输入变换
由于不同NLP任务的输入有所不同,在transformer模型的输入上,针对不同NLP任务,也有所不同。具体如下图所示:
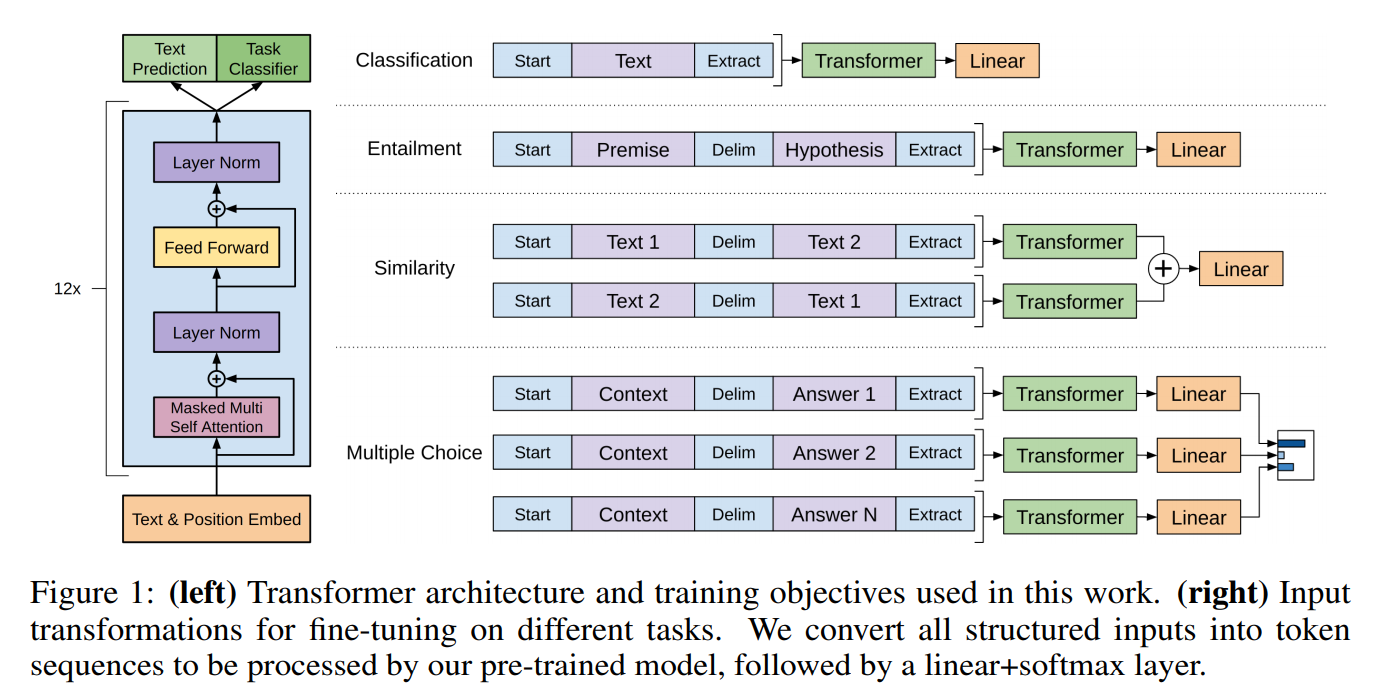
- 分类任务,直接将文本输入即可
- 文本蕴涵任务,需要将前提和假设用一个Delim分割向量拼接后进行输入
- 文本相似度任务,在两个方向上都使用Delim拼接后,进行输入
- 像问答多选择的任务,就是将每个答案和上下文进行拼接进行输入
总结
论文中的实验结果表明:
- 在多项任务上,OpenAI GPT的效果要比ELMo的效果更好
- 在去掉预训练部分后,所有任务都大幅下降,平均下降了14.8%,说明预训练很有效
- 在大数据集上使用语言模型作为附加任务的效果更好,小数据集不然
- 利用LSTM代替Transformer后,结果平均下降了5.6%,也体现了Transformer的性能。
事后看(和Bert出来之后对比),GPT的缺点是:
- 要是把语言模型改造成双向的就好了
- 不太会炒作,GPT也是非常重要的工作
- GPT预训练时利用上文预测下一个单词,BERT是根据上下文预测单词,因此在很多NLU(自然语言理解任务)任务上,GPT的效果都比BERT要差。但是GPT更加适合用于文本生成的任务(NLG,自然语言生成类的任务),因为文本生成通常都是基于当前已有的信息,生成下一个单词
