

预训练语言模型ELMo算法原理
概述
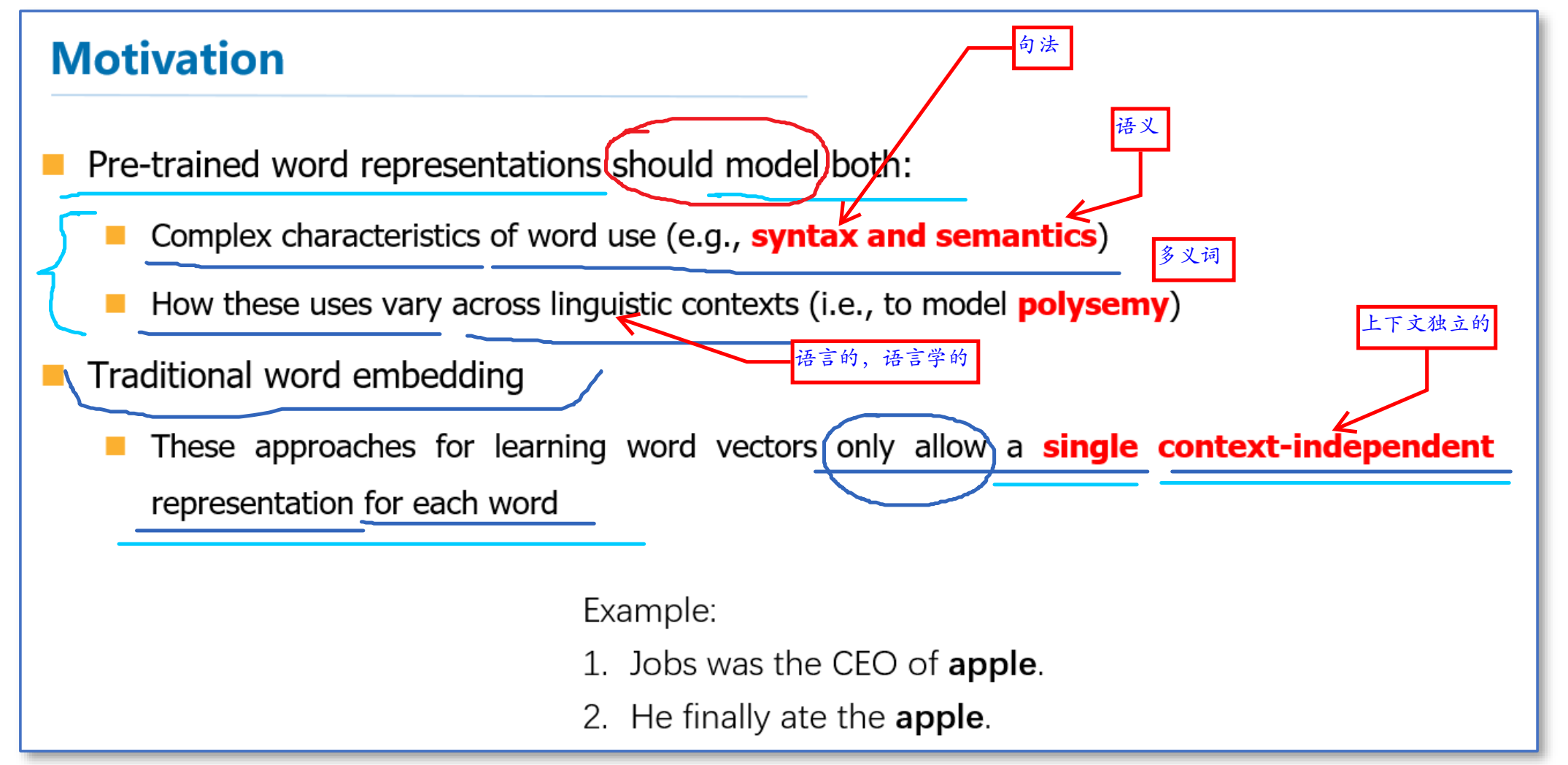
2018年,论文《Deep Contextualized(语境化) Word Representations》中提出了ELMo,即Embeddings from Language Models。作者认为一个预训练的词表示应该具备以下特点:
- 能够包含丰富的句法和语义信息
- 能够对多义词进行建模。
而传统的词向量(例如word2vec)是上下文无关的。例如下面"apple"的例子,这两个"apple"根据上下文意思是不同的,但是在word2vec中,只有apple一个词向量,无法对一词多义进行建模。
所以他们利用语言模型来获得一个上下文相关的预训练表示,称为ELMo,并在6个NLP任务上获得了提升。

在本文下面的部分,我们将会详细的介绍这个预训练语言模型。
ELMo预训练语言模型
原理
在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,经过一层softmax归一,就可以来预测词\(t_k\)。\(\Theta_x\)就是一开始输入的词向量(前后向语言模型共用),\(\Theta_s\)就是softmax层参数(前后向语言模型共用)。目标函数就是取这两个方向语言模型的最大似然。而且作者认为低层的bi-LSTM层能提取语料中的句法信息,高层的bi-LSTM能提取语料中的语义信息。
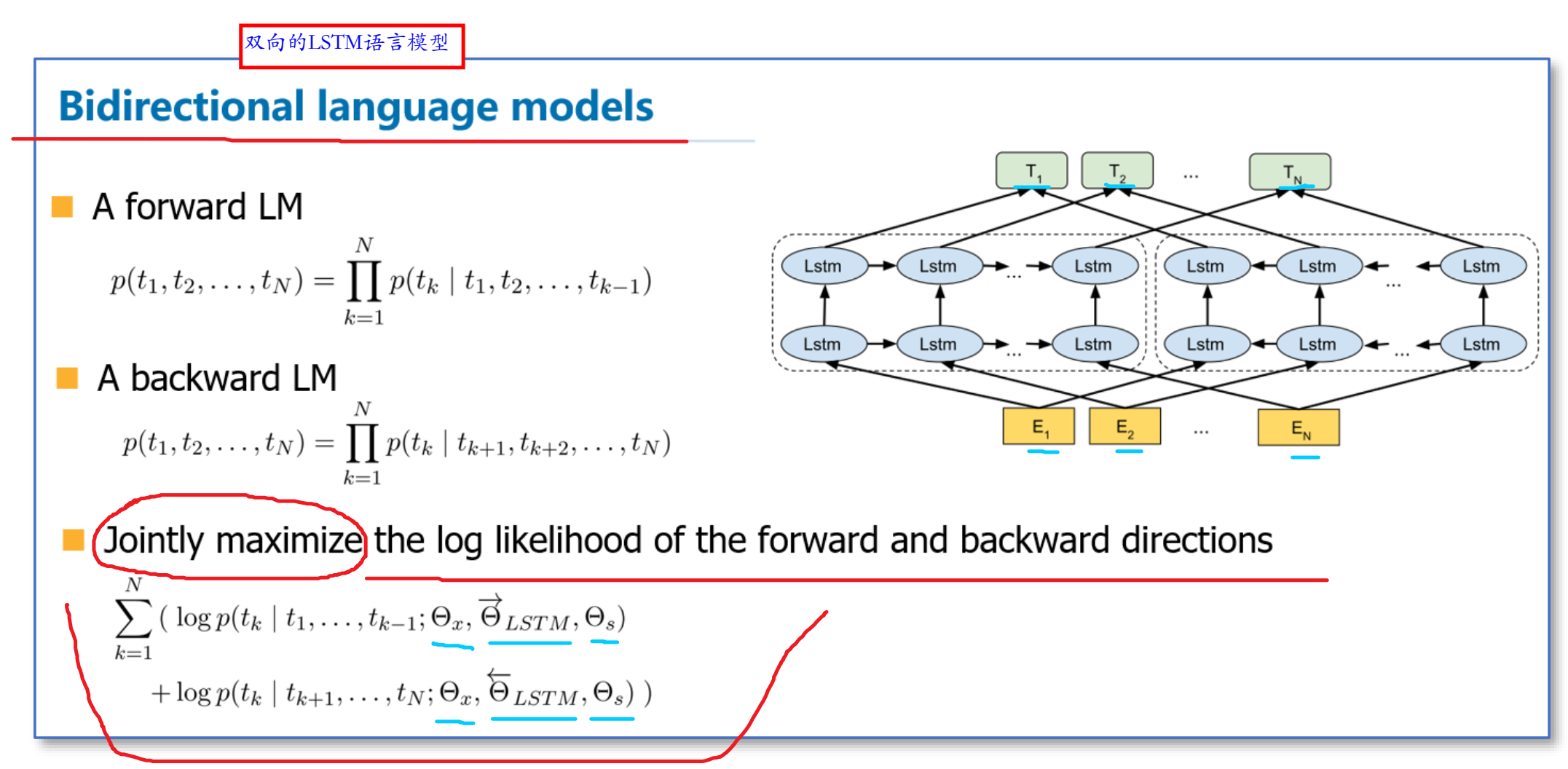
比如,对于前向语言模型\(p(t_1,t_2,...t_N)\),假如我们要计算里面的\(p(t_k|t_1,t_2,...t_{k-1})\),当我们得到\(t-1\)时刻的\(h_{k-1}\)(维数为\(m*1\)),与上下文矩阵\(W\)相乘,即\(Wh_{k-1}\)得到一个列向量,再将该列向量经过softmax归一化。其中,假定数据集有\(V\)个单词,\(W\)是\(|V|*m\)的矩阵,\(h_{k-1}\)是\(m*1\)的列向量,于是最终结果是\(|V|*1\)的归一化后向量,即得到针对下一个词的预测概率。
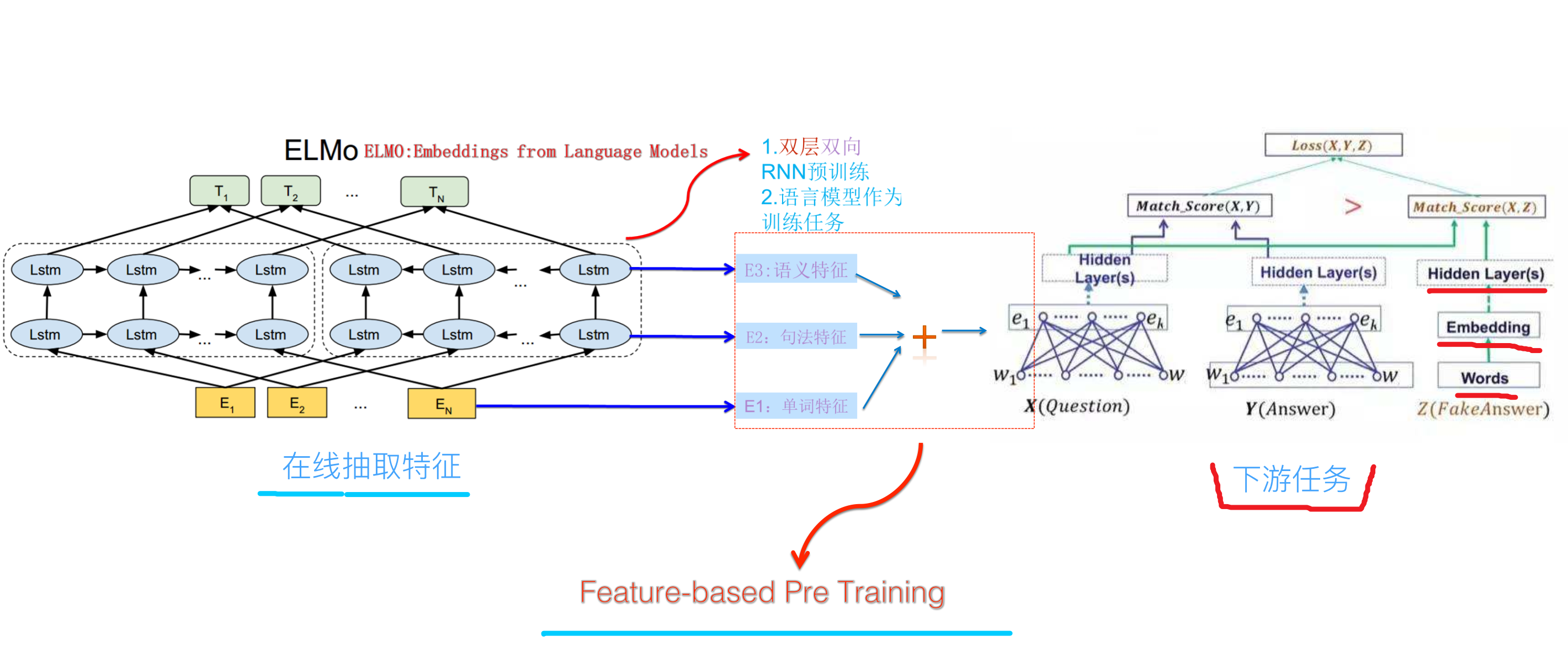
在预训练好这个语言模型之后,ELMo就是根据下面的公式来用作词表示,其实就是把这个双向语言模型的每一中间层进行一个求和。最简单的也可以使用最高层的表示来作为ELMo。

我们对于每层向量,我们加一个权重\(s^{task}_j\)(一个实数),将每层的向量与权重相乘,然后再乘以一个权重\(\gamma^{task}\)。每层LSTM输出,或者每层LSTM学到的东西是不一样的,针对每个任务,每层的向量重要性也不一样,所以有L层LSTM,L+1个权重,加上前面的\(\gamma^{task}\),一共有L+2个权重。注意下此处的权重个数,后面会用到。为何要乘以\(\gamma^{task}\),因为下一节我们会看到,我们会将此向量与另一向量再次拼接,所以此处有一个缩放系数。
笔者思考一个问题,为何不把L+1个向量一起拼接起来?这样子网络可以学的更充分。笔者猜想,可能是考虑维数太高,其实也没那么高了。考虑这些信息有叠加?总之,笔者不确定。
使用
然后在进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。
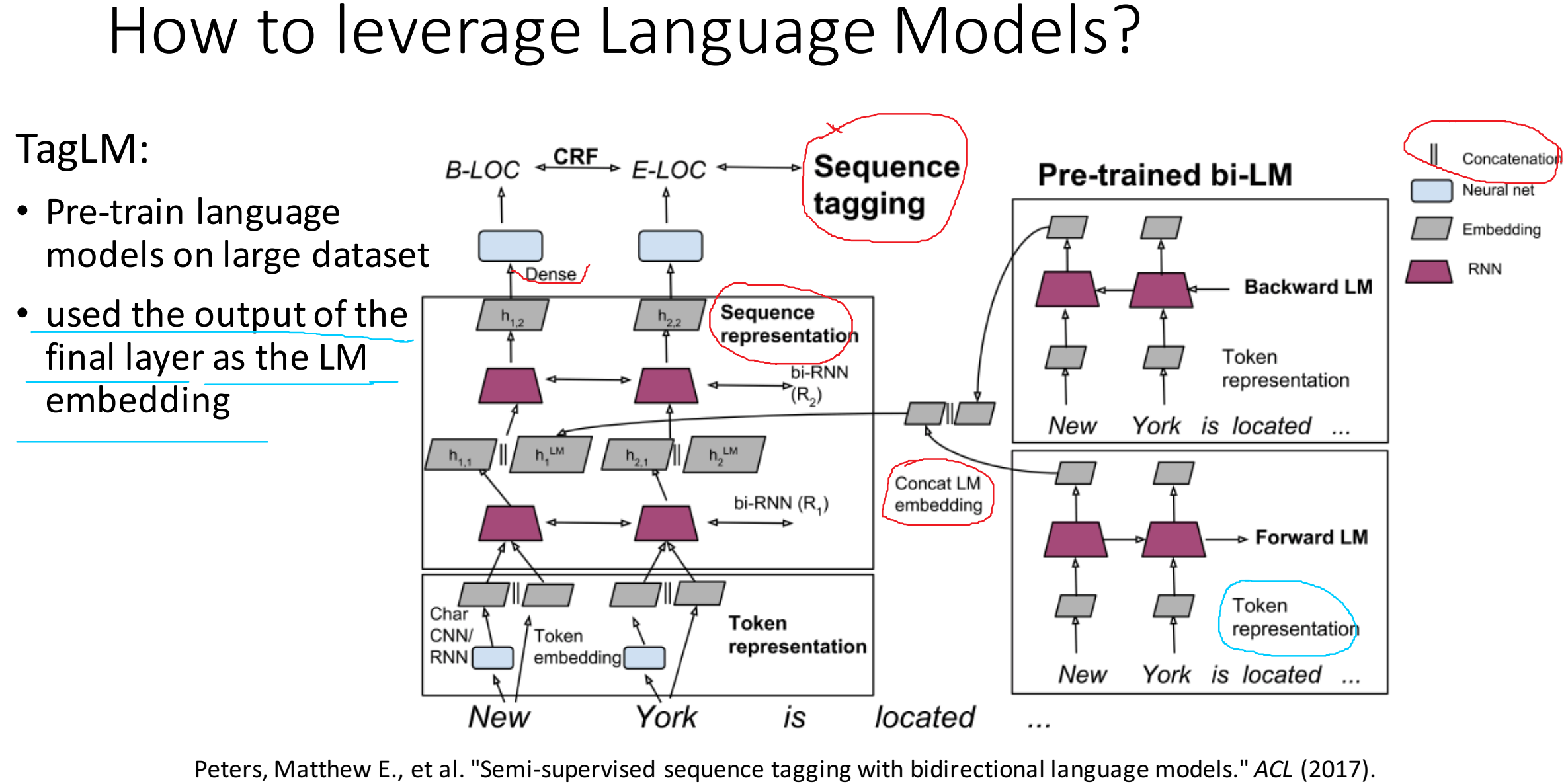
模型结构
作者在实验论证该预训练模型之前,阐述了一下其预训练过程。最终作者用于实验的预训练模型,为了平衡语言模型之间的困惑度以及后期NLP模型的计算复杂度,采用了2层bi-LSTM,共计4096个单元,输入及输出纬度为512,并且在第一层和第二层之间有残差连接,包括最初的那一层文本向量(用了2048个过滤器, 进行基于字符的卷积计算,详细可查看字符卷积的原论文),整个ELMo会为每一个词提供一个3层的输出,而下游模型学习的就是这3层输出的组合。另外,作者强调了一下,对该模型进行FINE-TUNE训练的话,对具体的NLP任务会有提升的作用。
模型效果
这里我们简单看一下主要的实验,具体实验还需阅读论文。首先是整个模型效果的实验。他们在6个NLP任务上进行了实验,首先根据目前每个任务,搭建了不同的模型作为baseline,然后加入ELMo,可以看到加入ELMo后6个任务都有所提升,平均大约能够提升2个多百分点,并且最后的结果都超过了之前的先进结果(SOTA)。
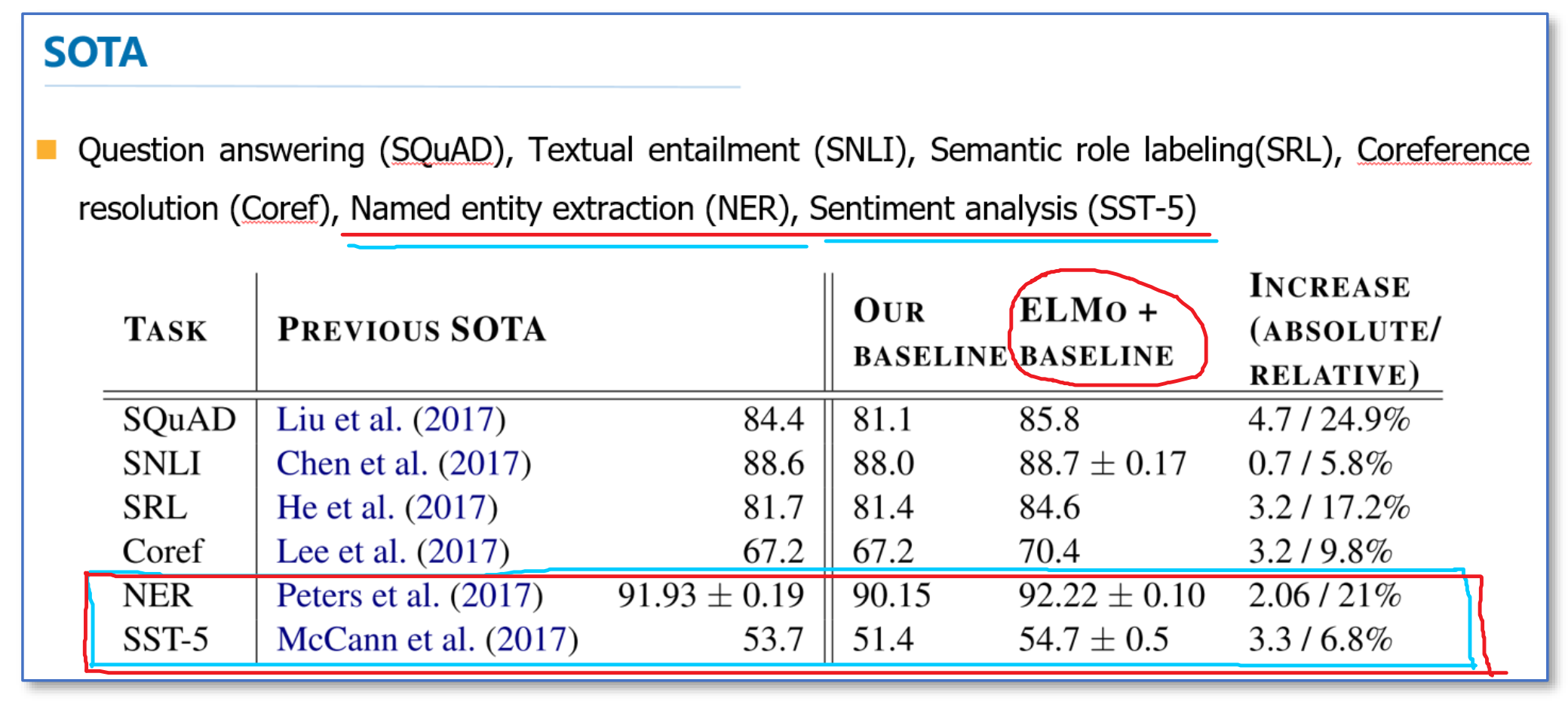
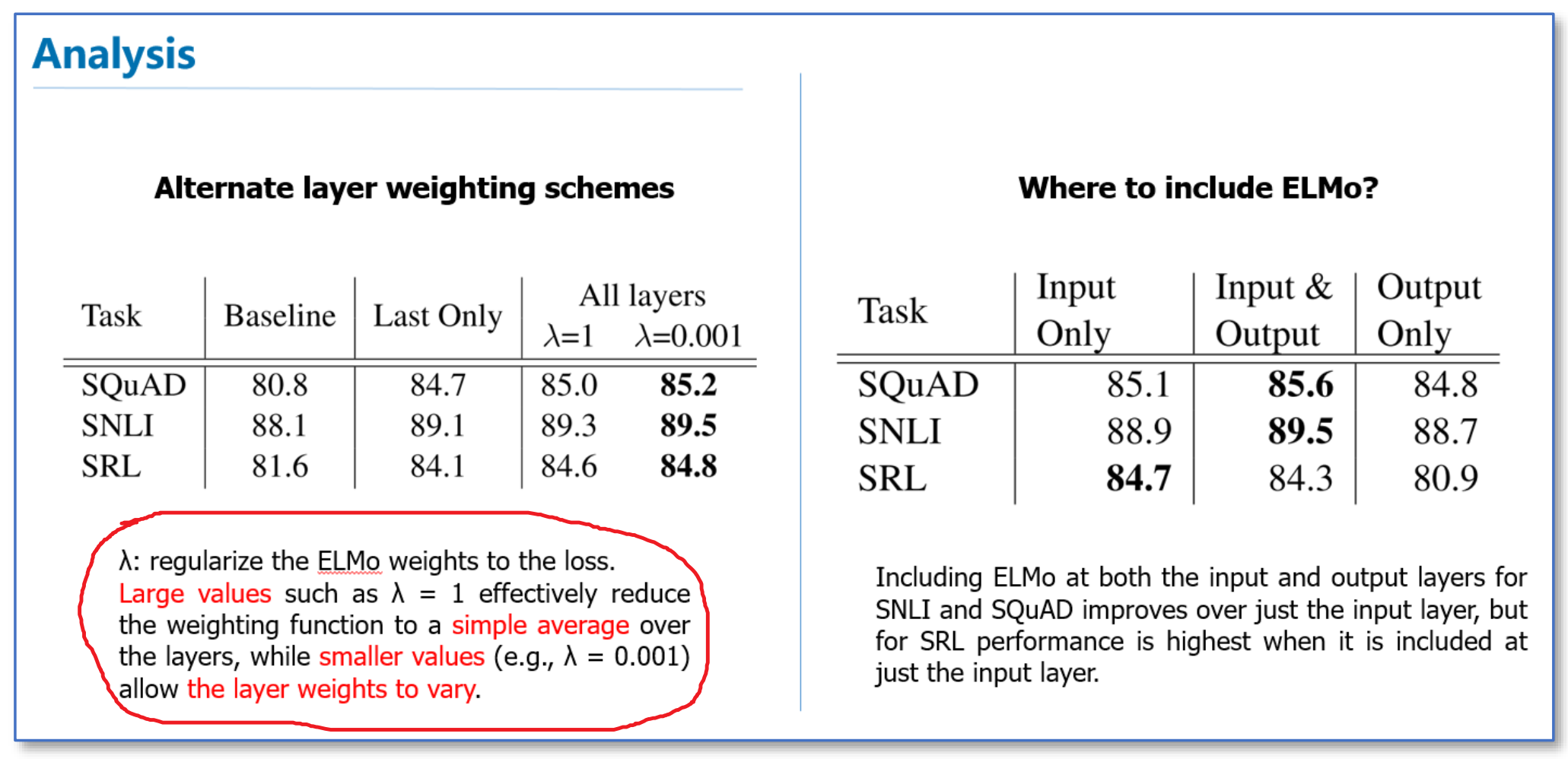
在下面的分析实验中,我们可以看到使用所有层的效果要比只使用最后一层作为ELMo的效果要好。在输入还是输出上面加EMLo效果好的问题上,并没有定论,不同的任务可能效果不一样。
总结
不像传统的词向量,每一个词只对应一个词向量,ELMo利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示(对于不同上下文的同一个词的表示是不一样的),再当成特征加入到具体的NLP有监督模型里。
事后看(GPT和Bert出来之后对比),ELMo的缺点为:
- LSTM抽取特征能力远弱于Transformer
- ELMO采取双向拼接这种融合特征的能力可能比Bert一体化的融合特征方式弱
