

语言模型(Language Model)

语言模型简单来说就是一串词序列的概率分布。具体来说,语言模型的作用是为一个长度为m的文本确定一个概率分布P,表示这段文本存在的可能性。在实践中,如果文本的长度较长,\(P(w_i | w_1, w_2, . . . , w_{i−1})\)的估算会非常困难。因此,研究者们提出使用一个简化模型:n元模型(n-gram model)。在 n 元模型中估算条件概率时,只需要对当前词的前n-1个词进行计算。在n元模型中,传统的方法一般采用频率计数的比例来估算n元条件概率。当n较大时,即会存在数据稀疏问题,导致估算结果不准确。因此,一般在百万词级别的语料中,一般也就用到三元模型。
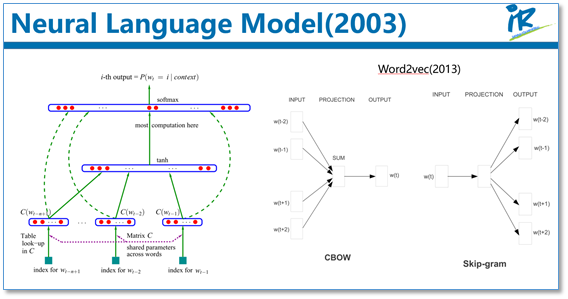
为了缓解n元模型估算概率时遇到的数据稀疏问题,研究者们提出了神经网络语言模型。代表性工作是Bengio等人在2003年提出的神经网络语言模型,该语言模型使用了一个三层前馈神经网络来进行建模。其中有趣的发现了第一层参数,用做词表示不仅低维紧密,而且能够蕴涵语义,也就为现在大家都用的词向量(例如word2vec)打下了基础。其实,语言模型就是根据上下文去预测下一个词是什么,这不需要人工标注语料,所以语言模型能够从无限制的大规模单语语料中,学习到丰富的语义知识。
