

用图解说Transformer模型
对应的英文地址The Illustrated Transformer
概述
前一段时间谷歌推出的BERT模型在11项NLP任务中夺得SOTA结果,引爆了整个NLP界。而BERT取得成功的一个关键因素是Transformer的强大作用。谷歌的Transformer模型最早是用于机器翻译任务,当时达到了SOTA效果。
- Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行。
- 并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
在本文中,我们将研究Transformer模型,把它掰开揉碎,理解它的工作原理。
Transformer由论文Attention is All You Need提出,现在是谷歌云TPU推荐的参考模型。论文相关的Tensorflow的代码可以从GitHub获取,其作为Tensor2Tensor包的一部分。哈佛的NLP团队也实现了一个基于PyTorch的版本,并注释该论文。在本文中,我们将试图把模型简化一点,并逐一介绍里面的核心概念,希望让普通读者也能轻易理解。
A High-Level Look
我们先将整个模型视为黑盒,比如在机器翻译中,接收一种语言的句子作为输入,然后将其翻译成其他语言输出。

细看下,其中由编码组件、解码组件和它们之间的连接层组成。
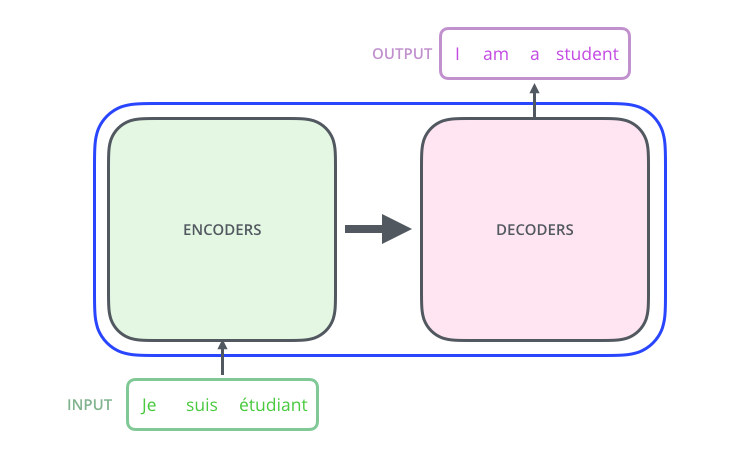
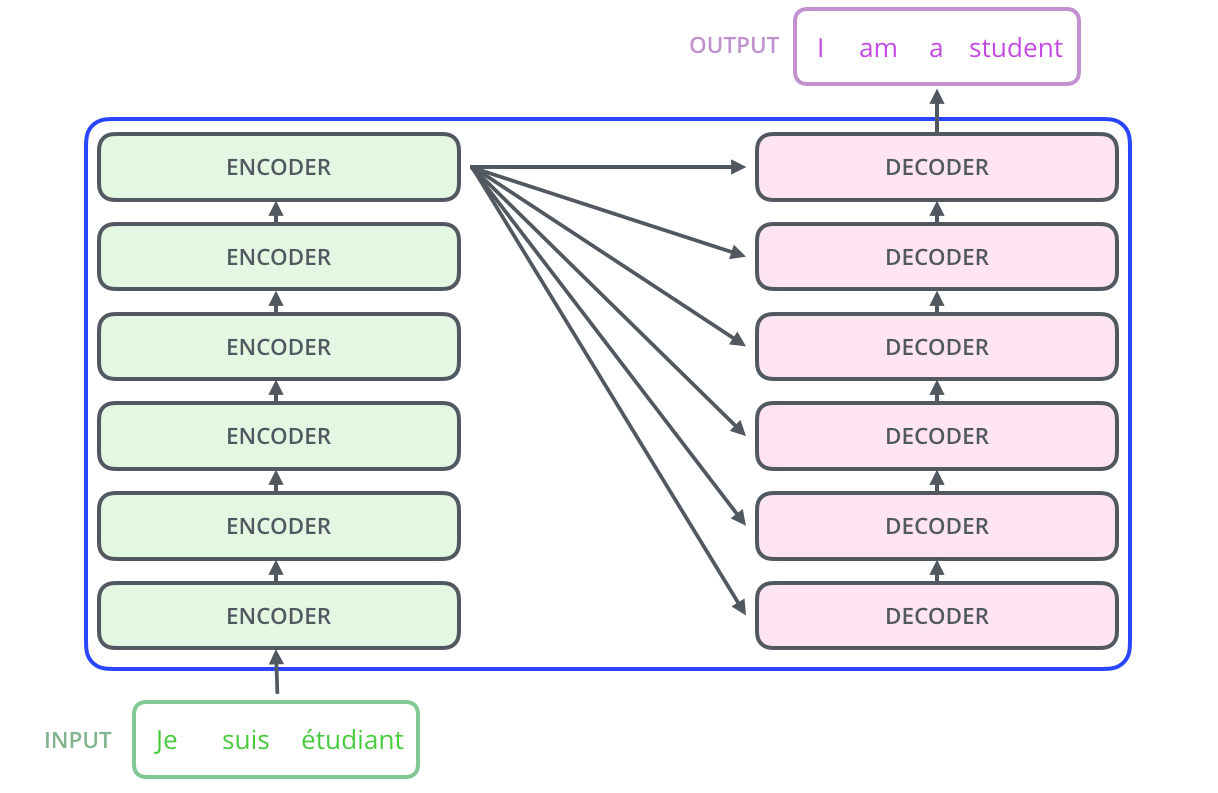
编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起——数字6没有什么神奇之处,你也可以尝试其他数字。解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。
-
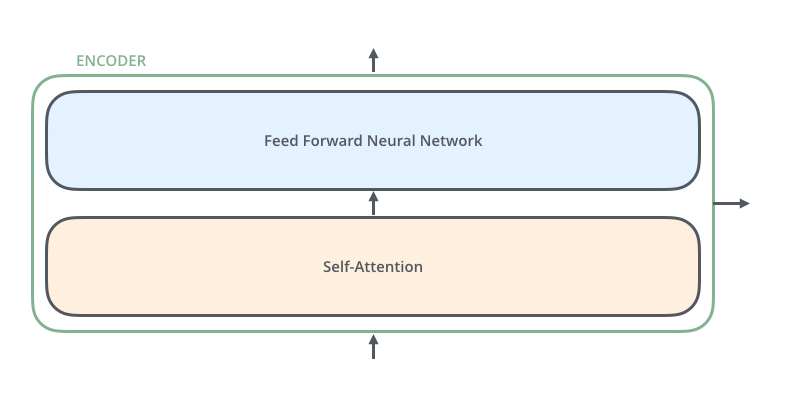
所有的编码器在结构上都是相同的,但它们没有共享参数。每个编码器都可以分解成两个子层。
从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。我们将在稍后的文章中更深入地研究自注意力。自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样(译注:另一种解读就是一层窗口为一个单词的一维卷积神经网络)。
-
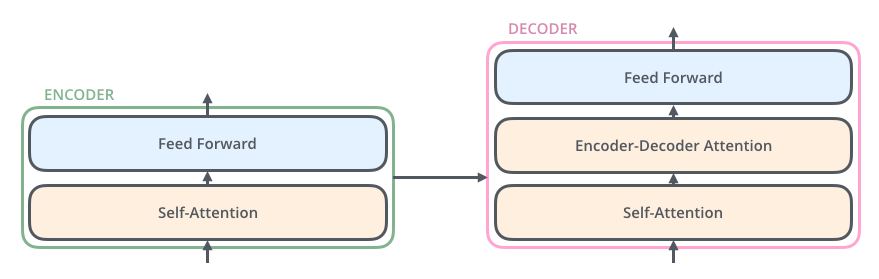
解码器同样也有这些子层,但是在两个子层间增加了attention层(Encoder-Decoder Attention),该层有助于解码器能够关注到输入句子的相关部分,与 seq2seq model 的Attention作用相似。
Bringing The Tensors Into The Picture
我们已经了解了模型的主要部分,接下来我们看一下各种向量或张量(译注:张量概念是矢量概念的推广,可以简单理解矢量是一阶张量、矩阵是二阶张量。)是怎样在模型的不同部分中,将输入转化为输出的。
像大部分NLP应用一样,我们首先将每个输入单词通过词嵌入算法转换为词向量。

Each word is embedded into a vector of size 512. We'll represent those vectors with these simple boxes.
词嵌入过程只发生在最底层的编码器的输入时。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,但是在其他编码器中,它就是前个编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
将输入序列进行词嵌入之后,每个单词都会流经编码器中的两个子层。
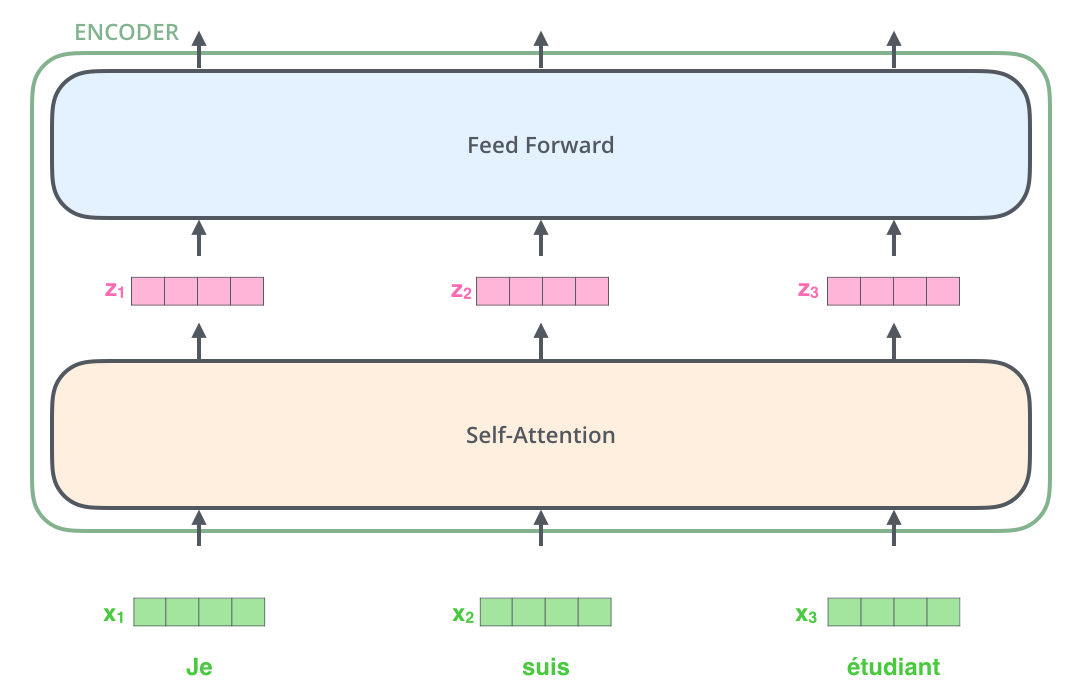
接下来我们看看Transformer的一个核心特性,在这里输入序列中每个位置的单词都有自己独特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
然后我们将以一个更短的句子为例,看看编码器的每个子层中发生了什么。
Now We're Encoding!
如上述已经提到的,一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
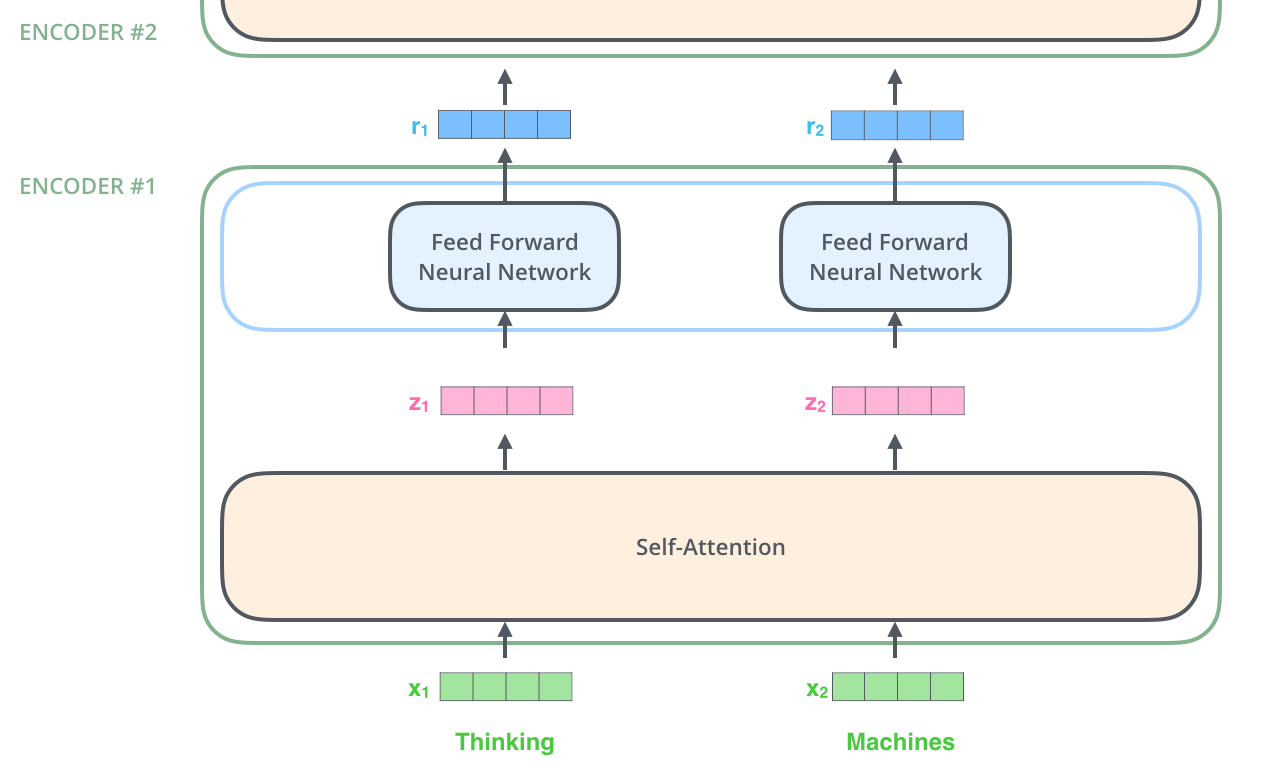
The word at each position passes through a self-attention process. Then, they each pass through a feed-forward neural network -- the exact same network with each vector flowing through it separately.
Self-Attention at a High Level
不要被我用自注意力这个词弄迷糊了,好像每个人都应该熟悉这个概念。其实我之也没有见过这个概念,直到读到Attention is All You Need 这篇论文时才恍然大悟。让我们精炼一下它的工作原理。
例如,下列句子是我们想要翻译的输入句子:
The animal didn't cross the street because it was too tired
这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?这对于人类来说是一个简单的问题,但是对于算法则不是。当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。当模型处理输入序列每个位置的词时,self-attention允许模型看到句子的其他位置信息作辅助线索,来更好地编码当前词。。
如果你熟悉RNN(循环神经网络),就能想到RNN的隐状态是如何允许之前的词向量来解释合成当前词的解释向量。而自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。

As we are encoding the word "it" in encoder #5 (the top encoder in the stack), part of the attention mechanism was focusing on "The Animal", and baked a part of its representation into the encoding of "it".
上图是Tensor2Tensor notebook的可视化例子
Self-Attention in Detail
首先我们了解一下如何使用向量来计算自注意力,然后来看它实怎样用矩阵来实现。
- 第一步,计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的,这些矩阵在训练过程中需要学习。。
可以发现这些新向量在维度上比词嵌入向量更低。他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512. 但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变。
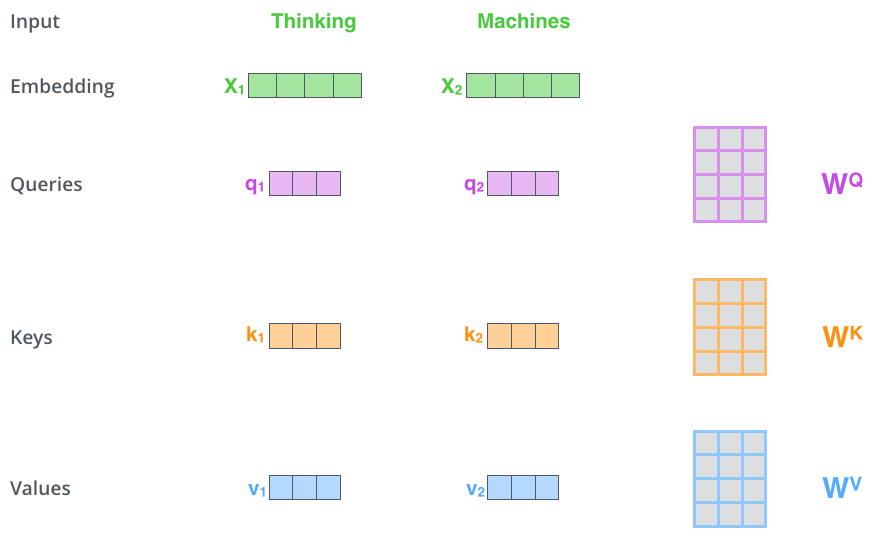
Multiplyingx1by theWQweight matrix producesq1, the "query" vector associated with that word. We end up creating a "query", a "key", and a "value" projection of each word in the input sentence.
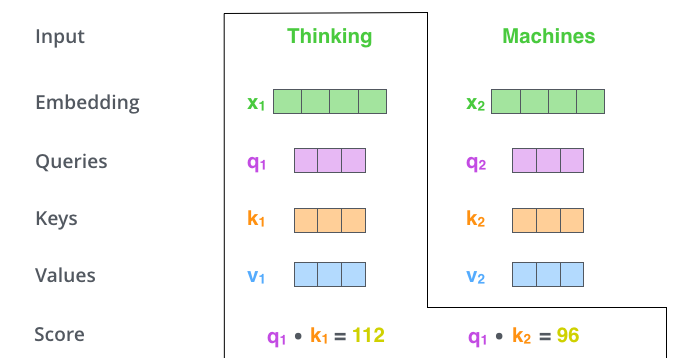
什么是查询向量、键向量和值向量向量?它们都是有助于计算和理解注意力机制的抽象概念。请继续阅读下文的内容,你就会知道每个向量在计算注意力机制中到底扮演什么样的角色。 - 第二步,计算得分。假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。
- 第三步和第四步,将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后加上softmax操作,归一化分值使得全为正数且加和为1。
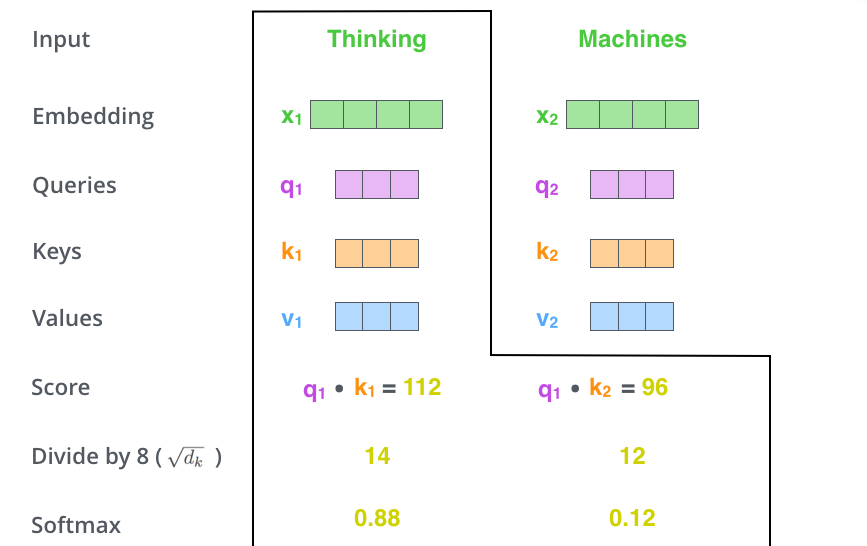
这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。 - 第五步,将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
- 第六步,将所有加权向量加和,产生该位置的self-attention的输出结果。
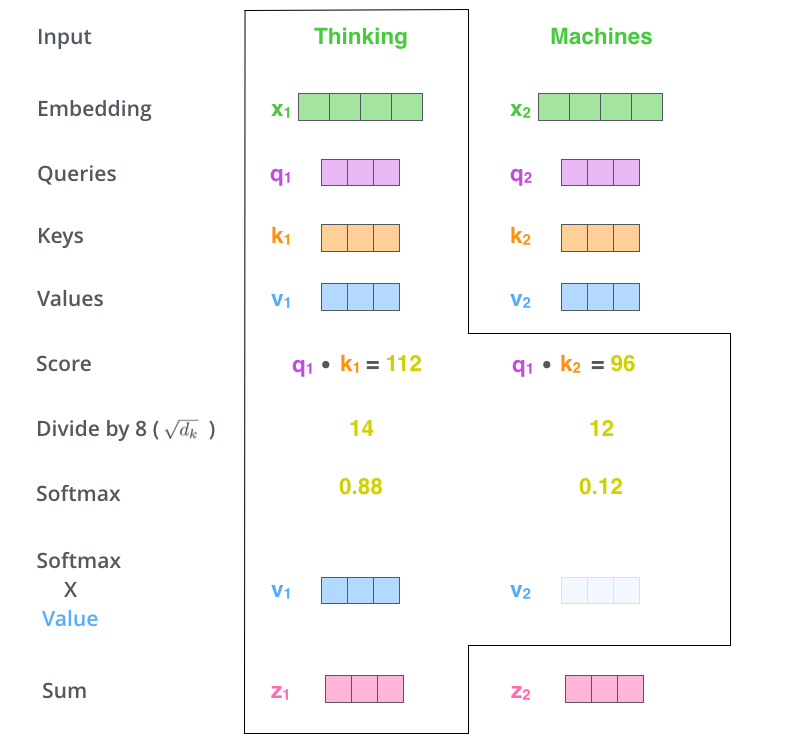
这样自注意力的计算就完成了。得到的向量就可以传给前馈神经网络。然而实际中,这些计算是以矩阵形式完成的,以便算得更快。那我们接下来就看看如何用矩阵实现的。
Matrix Calculation of Self-Attention
- 第一步,计算查询矩阵、键矩阵和值矩阵。为此,我们将所有输入词向量合并成输入矩阵X,将其乘以我们训练的权重矩阵(\(W^Q,W^K,W^V\))。
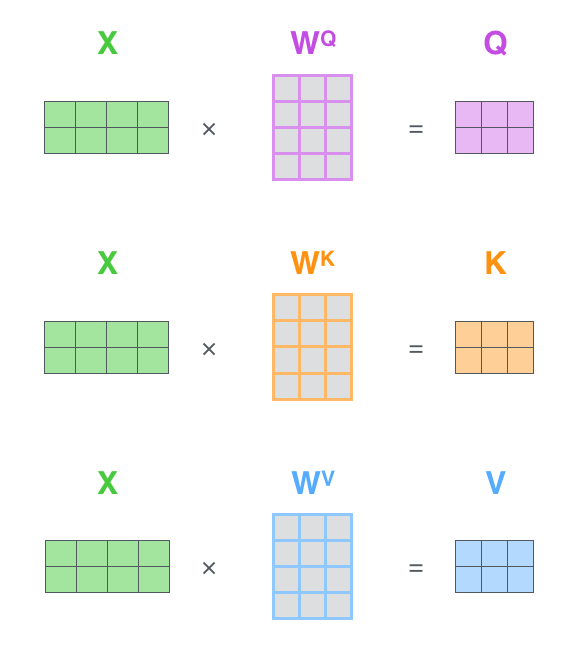
Every row in the X matrix corresponds to a word in the input sentence. We again see the difference in size of the embedding vector (512, or 4 boxes in the figure), and the q/k/v vectors (64, or 3 boxes in the figure) - 最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。
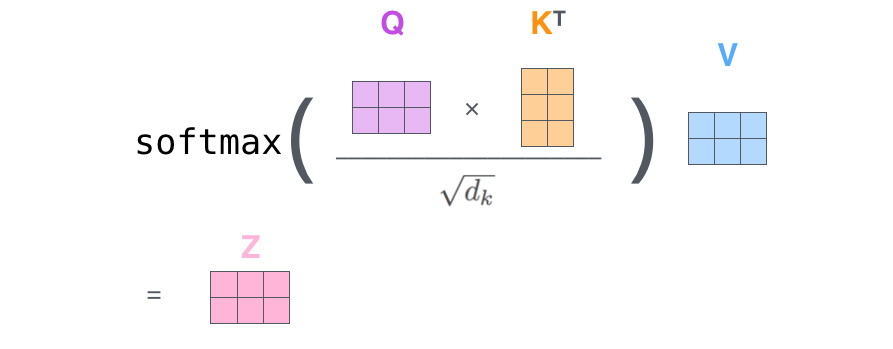
The self-attention calculation in matrix form
The Beast With Many Heads
论文进一步增加了multi-headed的机制到self-attention上,在如下两个方面提高了attention层的效果:
- 它扩展了模型专注于不同位置的能力。在上面的例子中,z1只包含了其他词的很少信息,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
- 它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
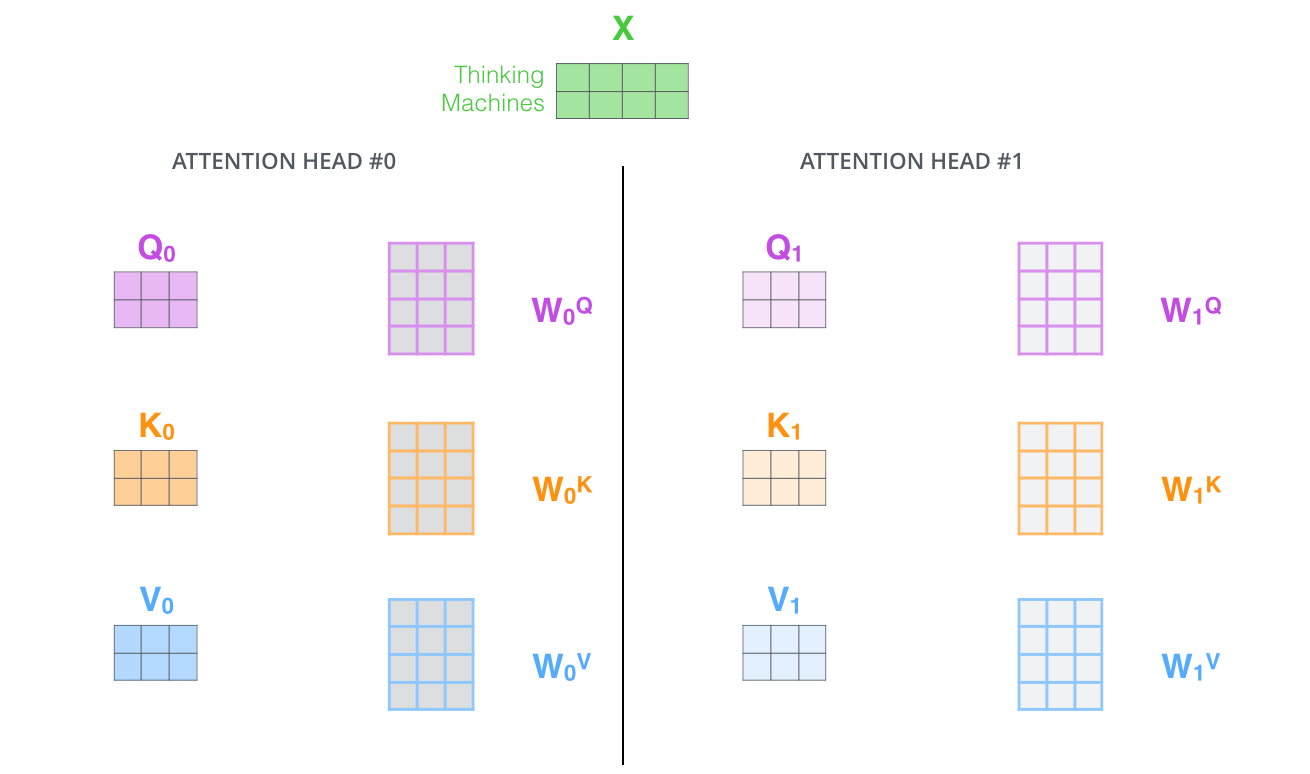
With multi-headed attention, we maintain separate Q/K/V weight matrices for each head resulting in different Q/K/V matrices. As we did before, we multiply X by the WQ/WK/WV matrices to produce Q/K/V matrices.
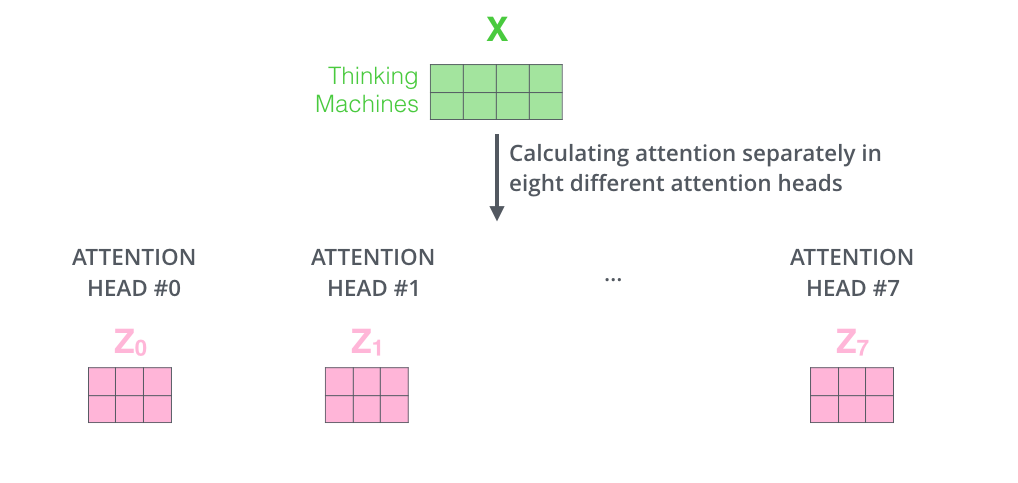
如果我们做与上述相同的自注意力计算,只需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。
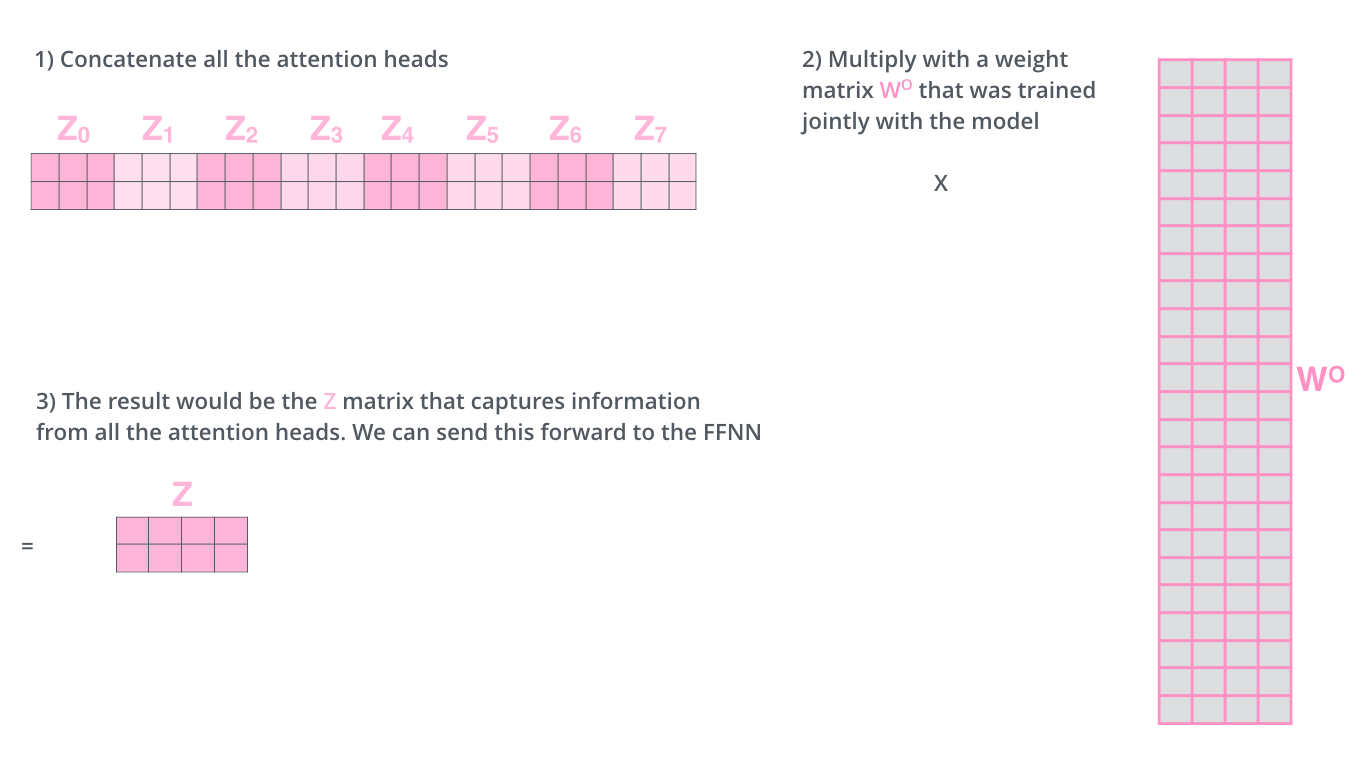
这给我们带来了一点挑战。前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。所以我们需要一种方法把这八个矩阵压缩成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵\(W^O\)与它们相乘。
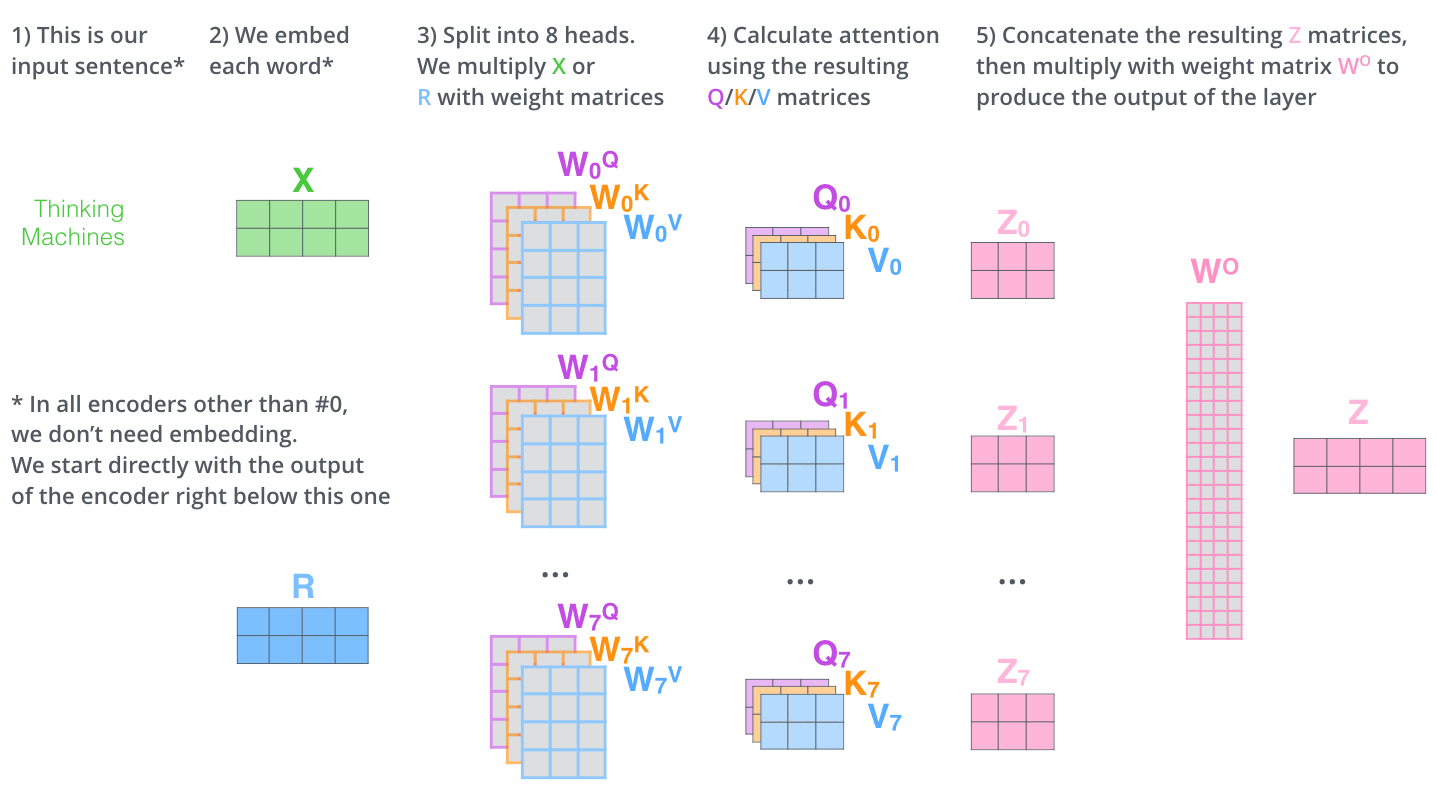
这几乎就是多头自注意力的全部。这确实有好多矩阵,我们试着把它们集中在一个图片中,这样可以一眼看清。
既然我们已经摸到了注意力机制的这么多“头”,那么让我们重温之前的例子,看看我们在例句中编码“it”一词时,不同的注意力“头”集中在哪里:

As we encode the word "it", one attention head is focusing most on "the animal", while another is focusing on "tired" -- in a sense, the model's representation of the word "it" bakes in some of the representation of both "animal" and "tired".
然而,如果我们把所有的attention都加到图示里,事情就更难解释了:
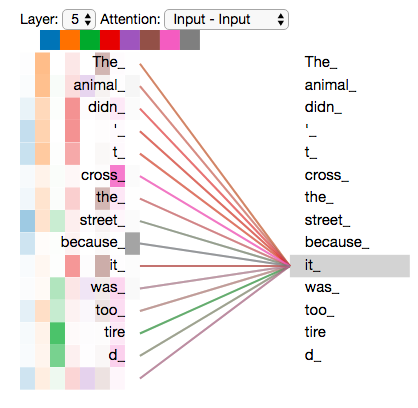
Representing The Order of The Sequence Using Positional Encoding
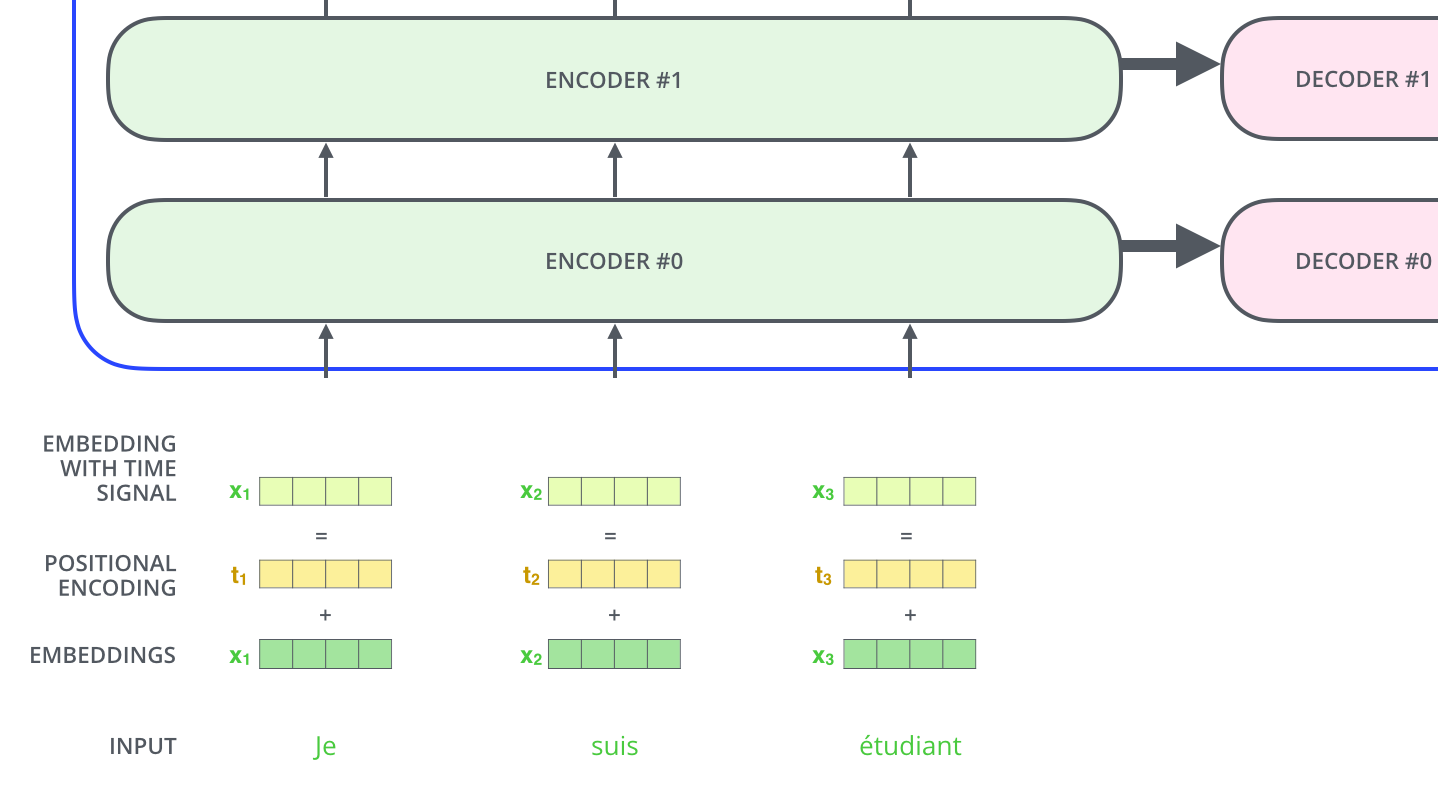
到目前为止,我们对模型的描述缺少了一种理解输入单词顺序的方法。
为了解决这个问题,Transformer为每个输入的词嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将位置向量添加到词嵌入中使得它们在接下来的运算中,能够更好地表达的词与词之间的距离。
To give the model a sense of the order of the words, we add positional encoding vectors -- the values of which follow a specific pattern.
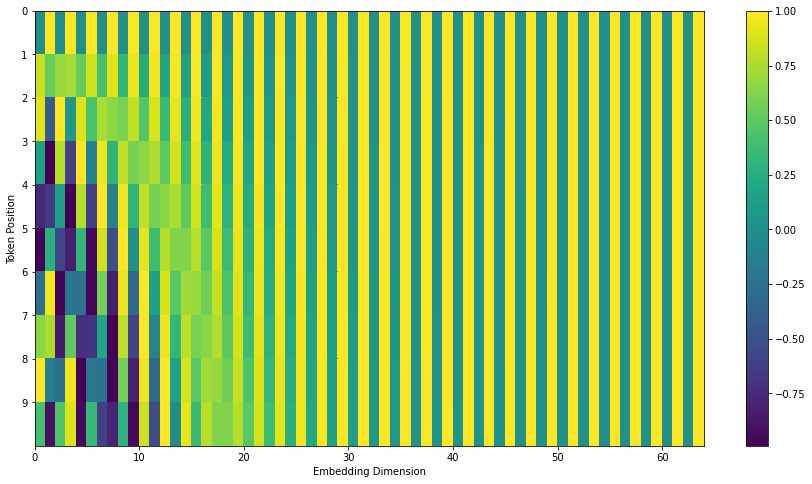
如果我们假设词嵌入的维数为4,则实际的位置编码如下:
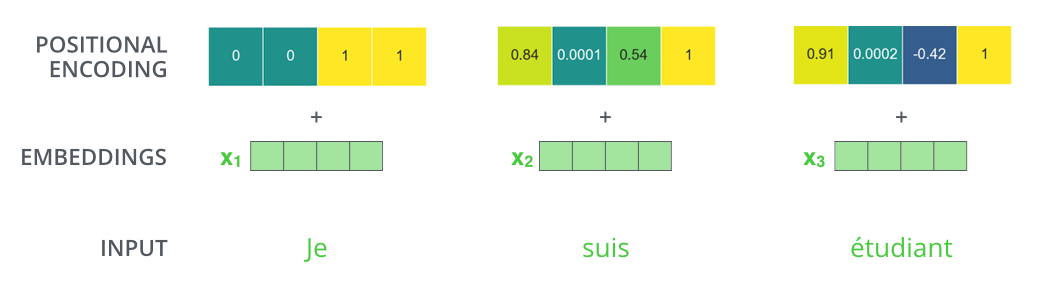
A real example of positional encoding with a toy embedding size of 4
这个模式会是什么样子?
在下图中,每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。我们已经对它们进行了颜色编码,所以图案是可见的。
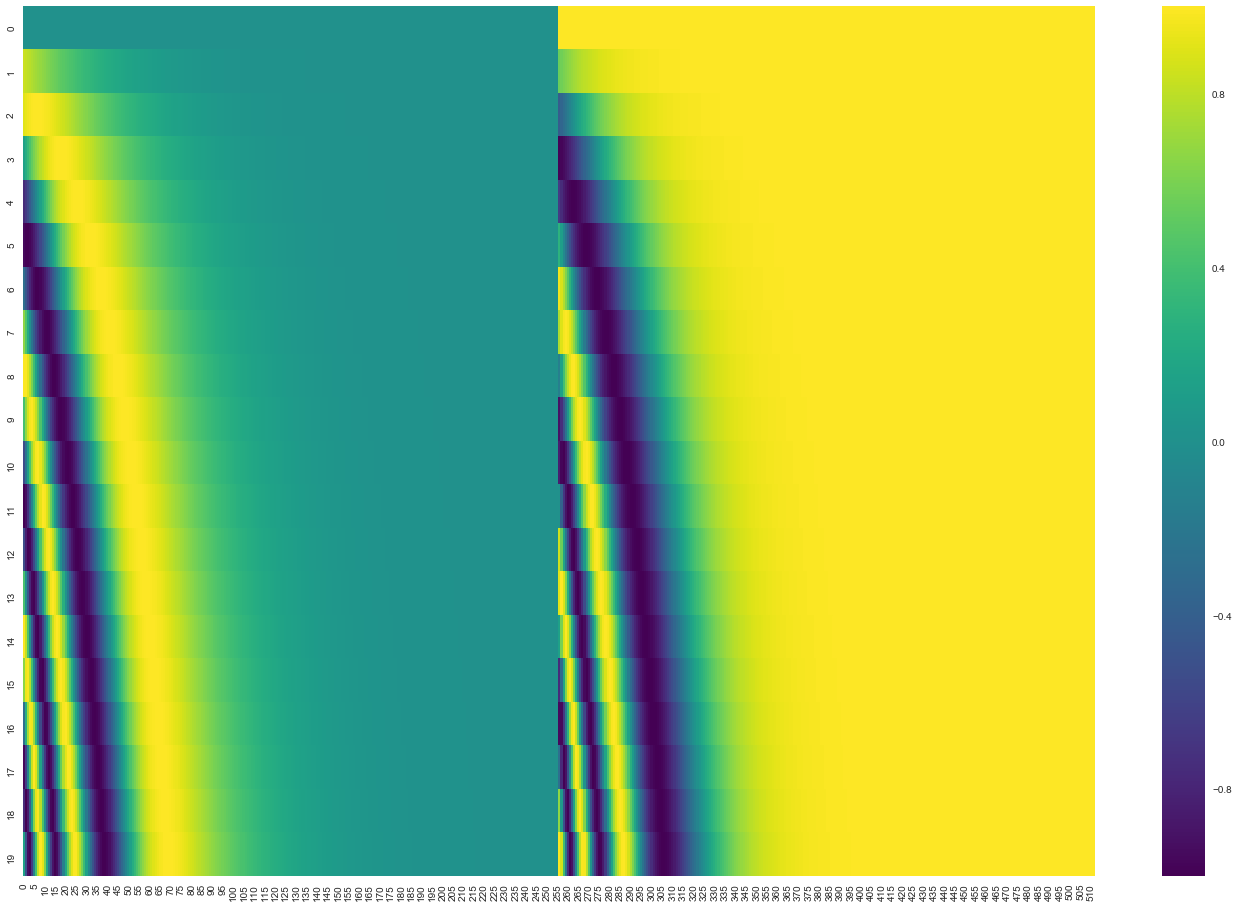
A real example of positional encoding for 20 words (rows) with an embedding size of 512 (columns). You can see that it appears split in half down the center. That's because the values of the left half are generated by one function (which uses sine), and the right half is generated by another function (which uses cosine). They're then concatenated to form each of the positional encoding vectors.
原始论文里描述了位置编码的公式(第3.5节)。你可以在 get_timing_signal_1d()中看到生成位置编码的代码。这不是唯一可能的位置编码方法。然而,它的优点是能够扩展到未知的序列长度(例如,当我们训练出的模型需要翻译远比训练集里的句子更长的句子时)。
July 2020 Update:The positional encoding shown above is from the Tranformer2Transformer implementation of the Transformer. The method shown in the paper is slightly different in that it doesn’t directly concatenate, but interweaves(交错) the two signals. The following figure shows what that looks like. Here’s the code to generate it:
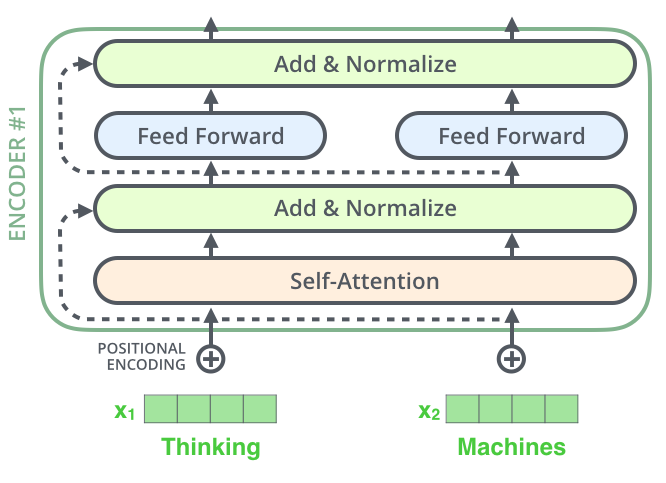
The Residuals
在继续进行下去之前,我们需要提到一个编码器架构中的细节:在每个编码器中的每个子层(自注意力、前馈网络)的周围都有一个残差连接,并且都跟随着一个“层-归一化”步骤。
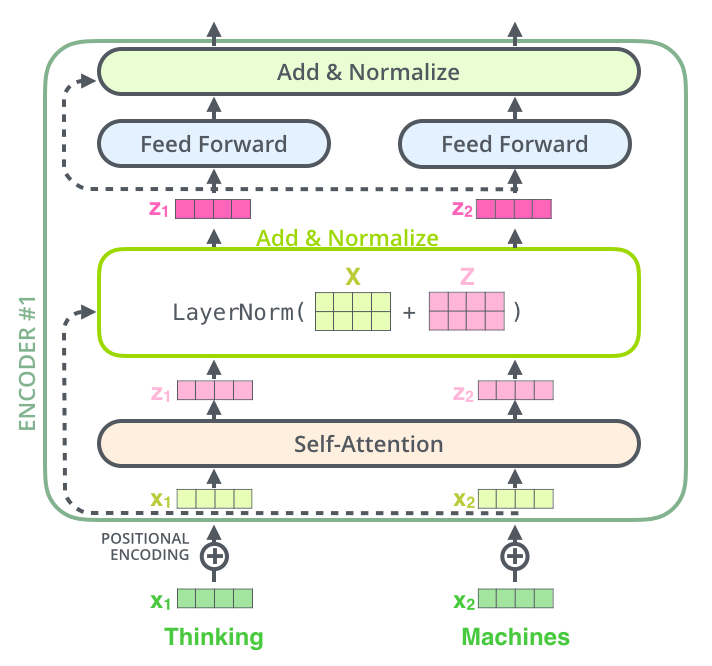
如果我们去可视化这些向量以及这个和自注意力相关联的层-归一化操作,将如下所示:
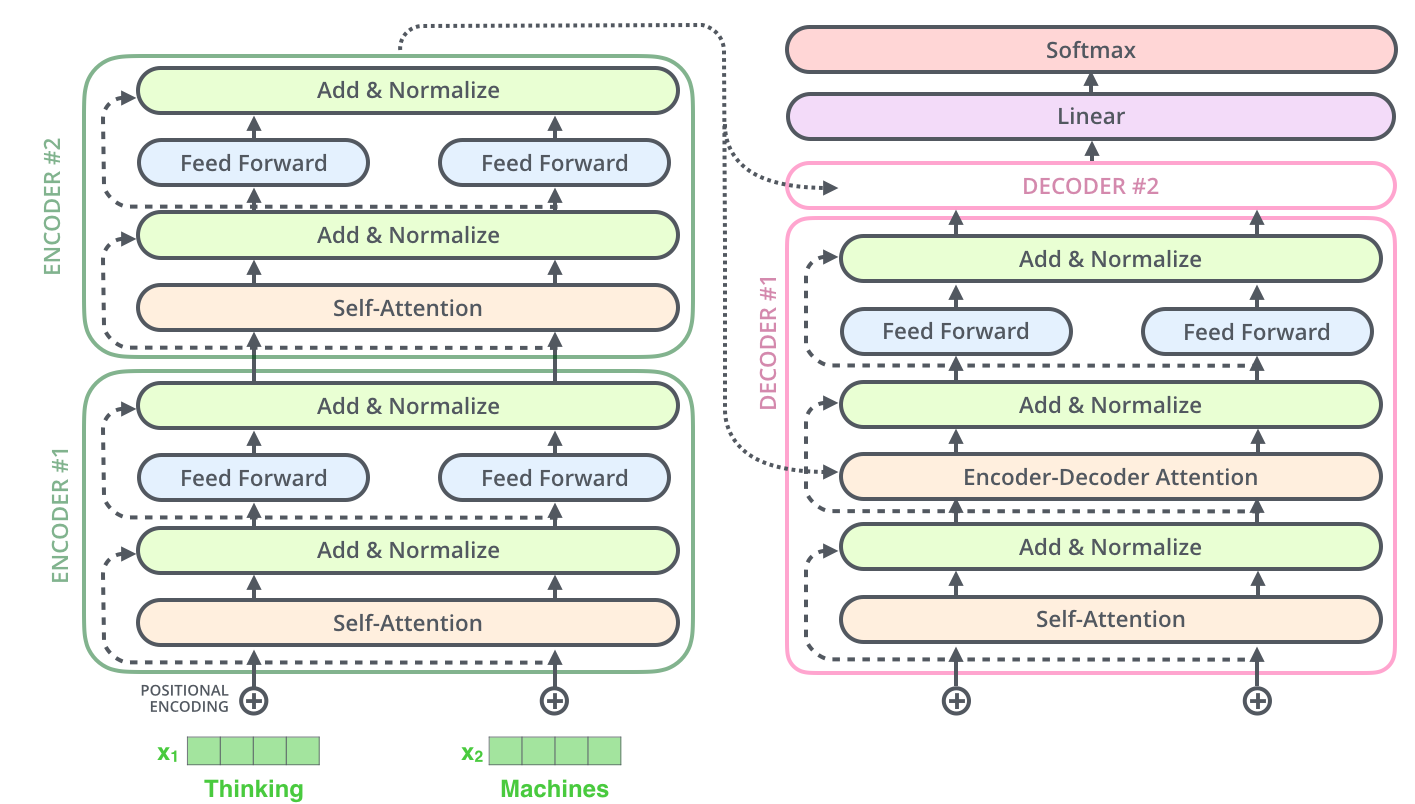
解码器的子层也是这样的。如果我们想象一个2 层编码-解码结构的transformer,它看起来会像下面这张图一样:
The Decoder Side
现在我们已经了解了编码器侧的大部分概念,也基本了解了解码器的工作方式,下面看下他们是如何共同工作的。
编码器从输入序列的处理开始,最后的编码器的输出被转换为一个包含向量K(键向量)和V(值向量)的注意力向量集 ,它俩被每个解码器的"encoder-decoder atttention"层来使用,帮助解码器集中于输入序列的合适位置:
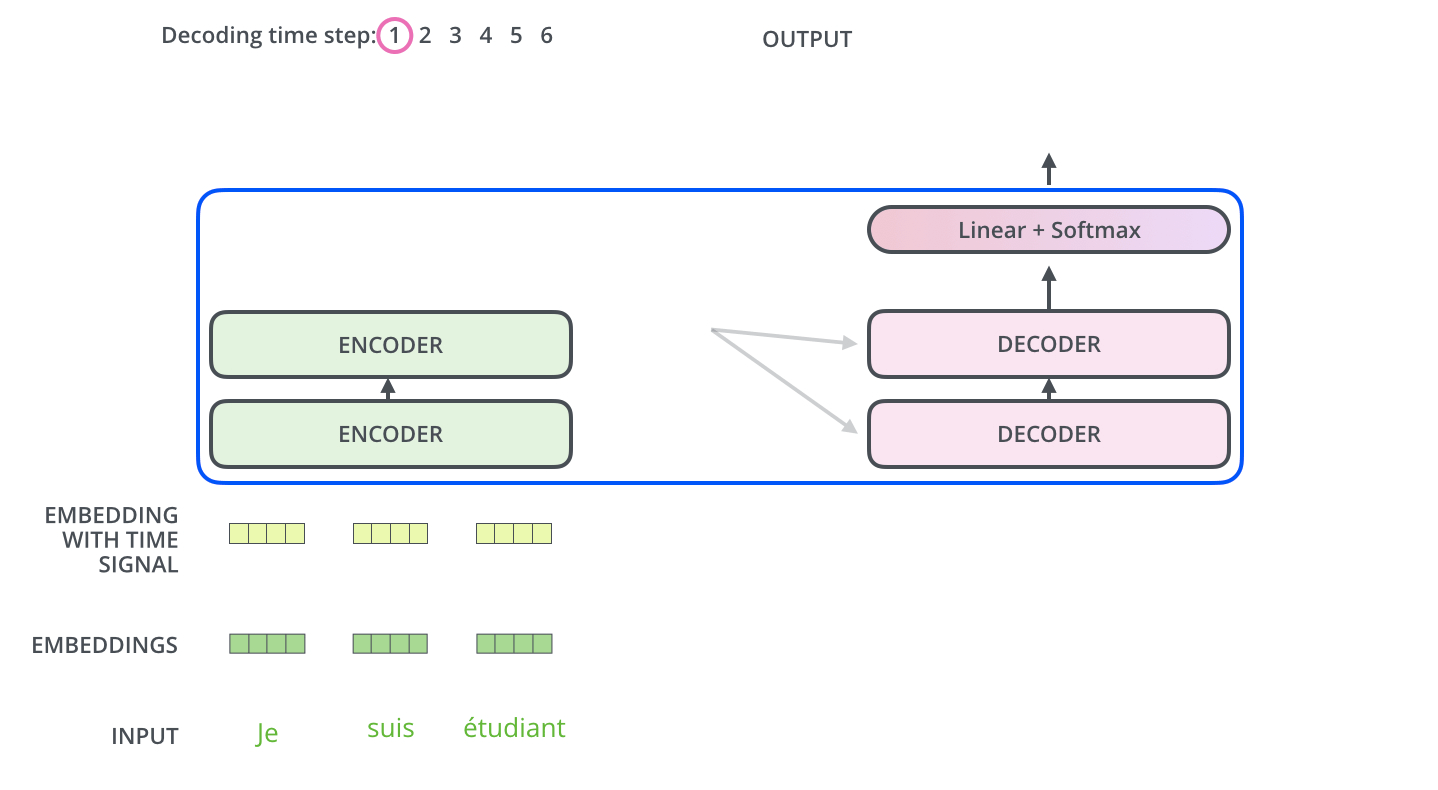
After finishing the encoding phase, we begin the decoding phase. Each step in the decoding phase outputs an element from the output sequence (the English translation sentence in this case).
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
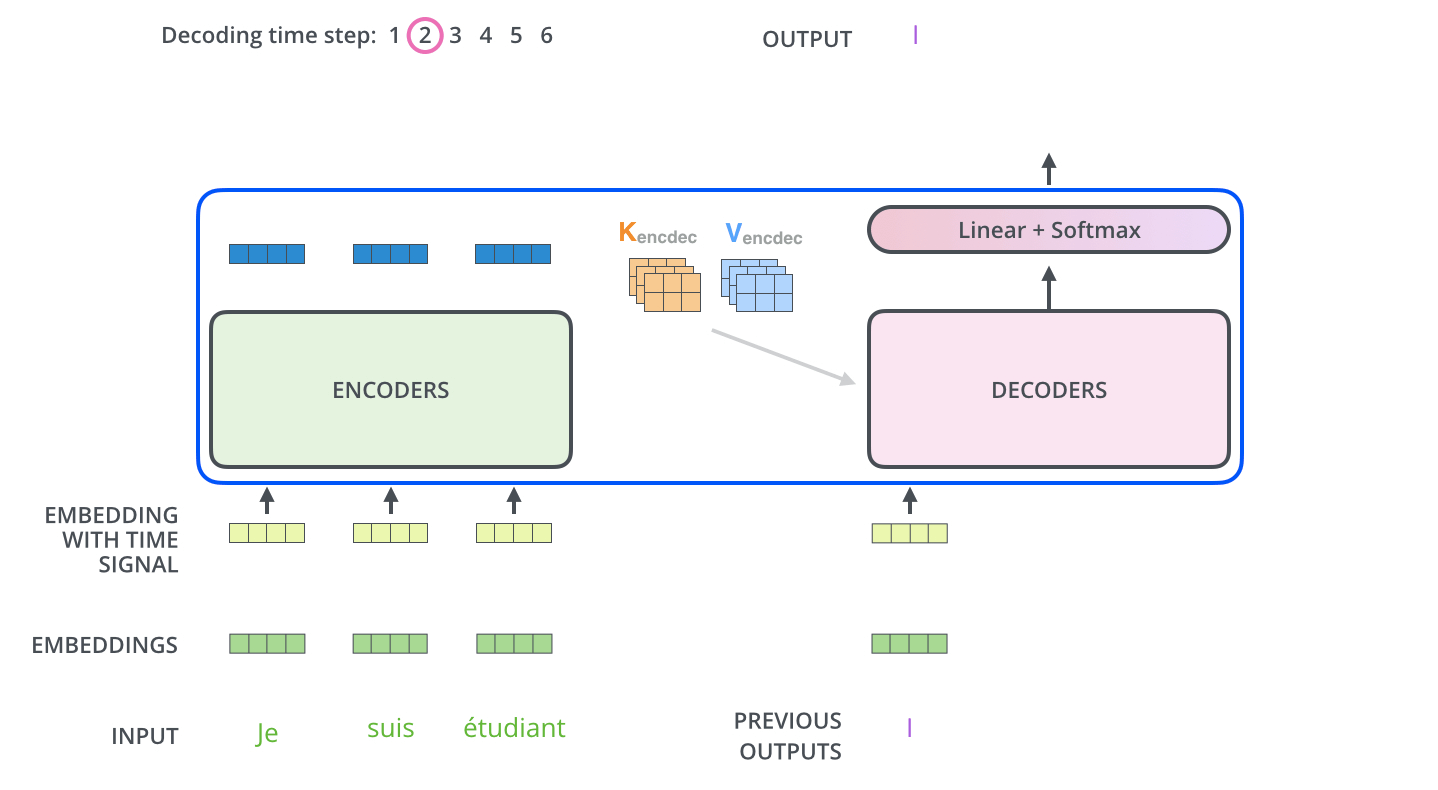
在解码器中的self attention 层与编码器中的稍有不同:在解码器中,self-attention 层仅仅允许关注早于当前输出的位置。在softmax之前,通过遮挡未来位置(将它们设置为-inf)来实现。这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它前层的层来创造query矩阵,并且从最后层编码器中取得key/value矩阵。
The Final Linear and Softmax Layer
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。
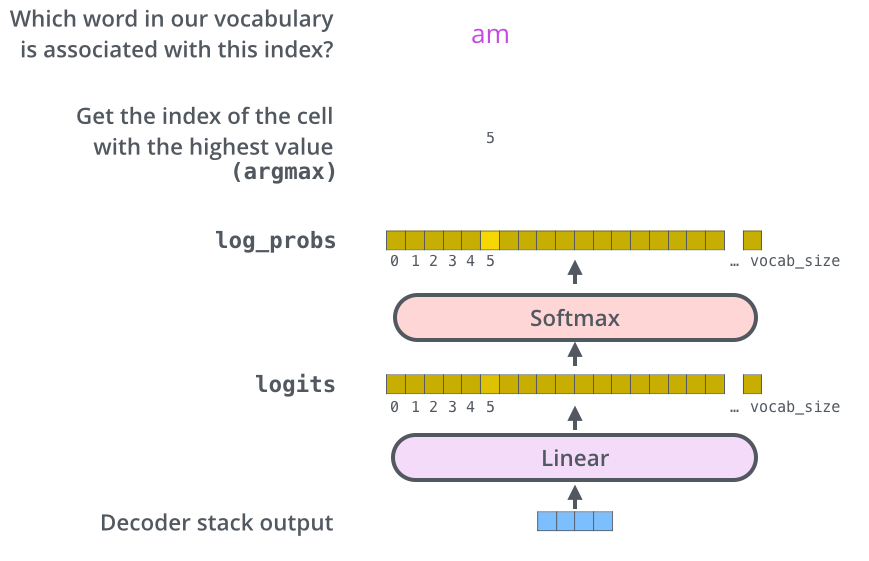
This figure starts from the bottom with the vector produced as the output of the decoder stack. It is then turned into an output word.
Recap Of Training
既然我们已经过了一遍完整的transformer的前向传播过程,顺道看下训练的概念也是非常有用的。在训练时,模型将经历上述的前向过程,当我们在标记训练集上训练时,可以对比预测输出与实际输出。为了可视化,假设输出一共只有6个单词“a”, “am”, “i”, “thanks”, “student”以及 “
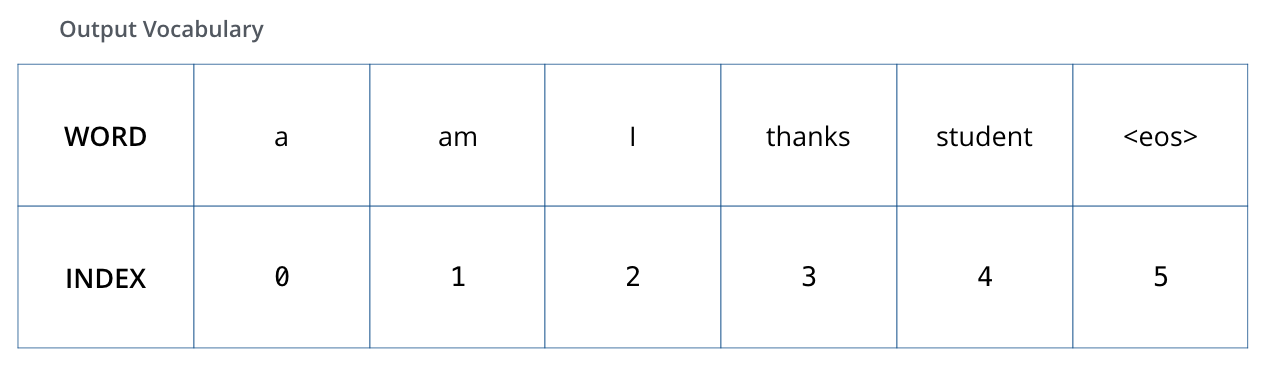
The output vocabulary of our model is created in the preprocessing phase before we even begin training.
一旦我们定义了我们的输出词表,我们可以使用一个相同宽度的向量来表示我们词汇表中的每一个单词。这也被认为是一个one-hot 编码。所以,我们可以用下面这个向量来表示单词“am”:
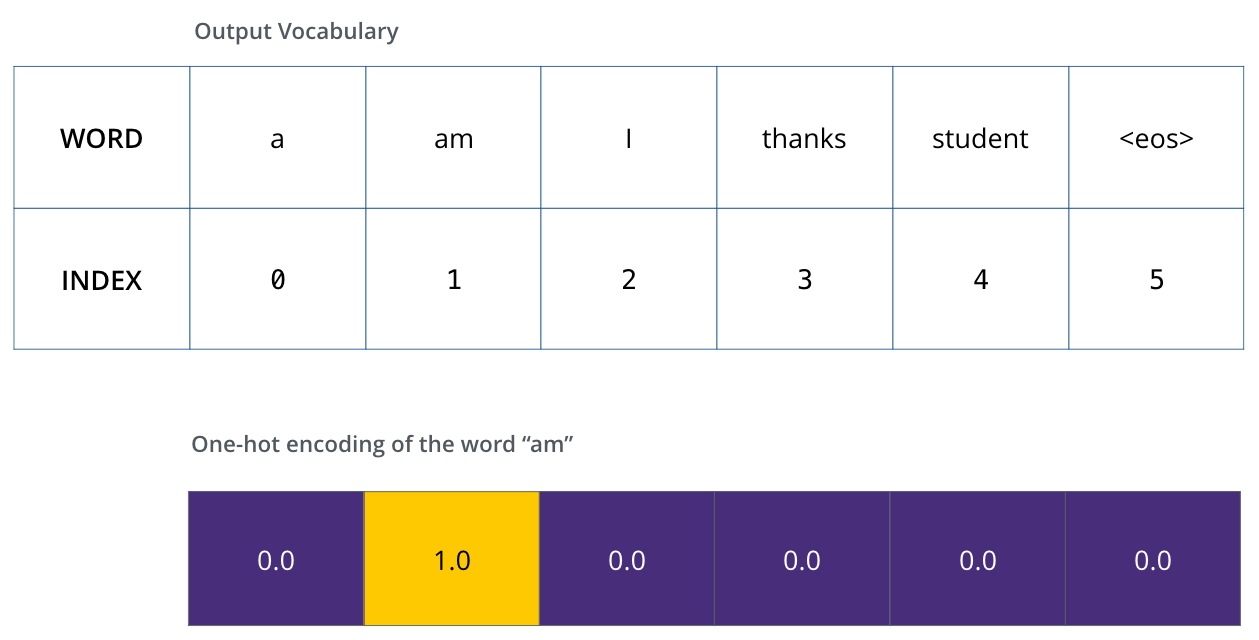
Example: one-hot encoding of our output vocabulary
接下来我们讨论模型的损失函数——这是我们用来在训练过程中优化的标准。通过它可以训练得到一个结果尽量准确的模型。
The Loss Function
比如说我们正在训练模型,现在是第一步,一个简单的例子——把“merci”翻译为“thanks”。这意味着我们想要一个表示单词“thanks”概率分布的输出。但是因为这个模型还没被训练好,所以不太可能现在就出现这个结果。
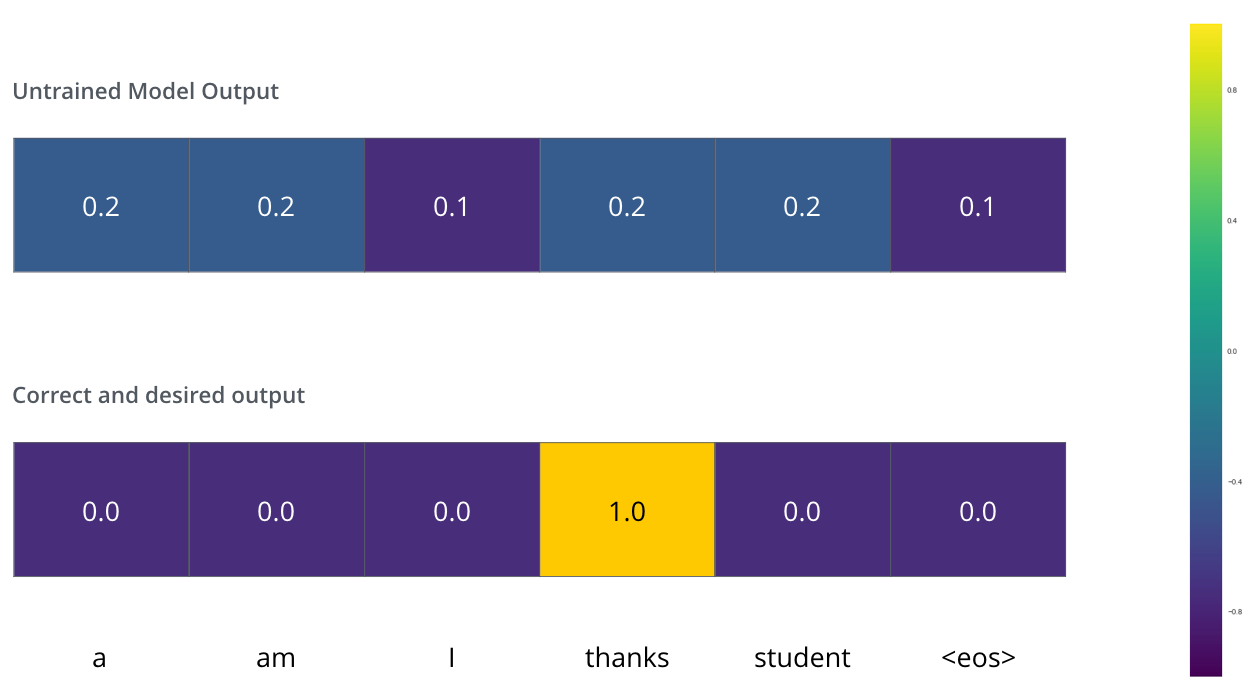
Since the model's parameters (weights) are all initialized randomly, the (untrained) model produces a probability distribution with arbitrary values for each cell/word. We can compare it with the actual output, then tweak all the model's weights using backpropagation to make the output closer to the desired output.
你会如何比较两个概率分布呢?我们可以简单地用其中一个减去另一个。更多细节请参考交叉熵和KL散度。
但注意到这是一个过于简化的例子。更现实的情况是处理一个句子。例如,输入“je suis étudiant”并期望输出是“i am a student”。那我们就希望我们的模型能够成功地在这些情况下输出概率分布:
- 每个概率分布被一个以词表大小(我们的例子里是6,但现实情况通常是3000或10000)为宽度的向量所代表。
- 第一个概率分布在与“i”关联的单元格有最高的概率
- 第二个概率分布在与“am”关联的单元格有最高的概率
- 以此类推,第五个输出的分布表示“
”关联的单元格有最高的概率
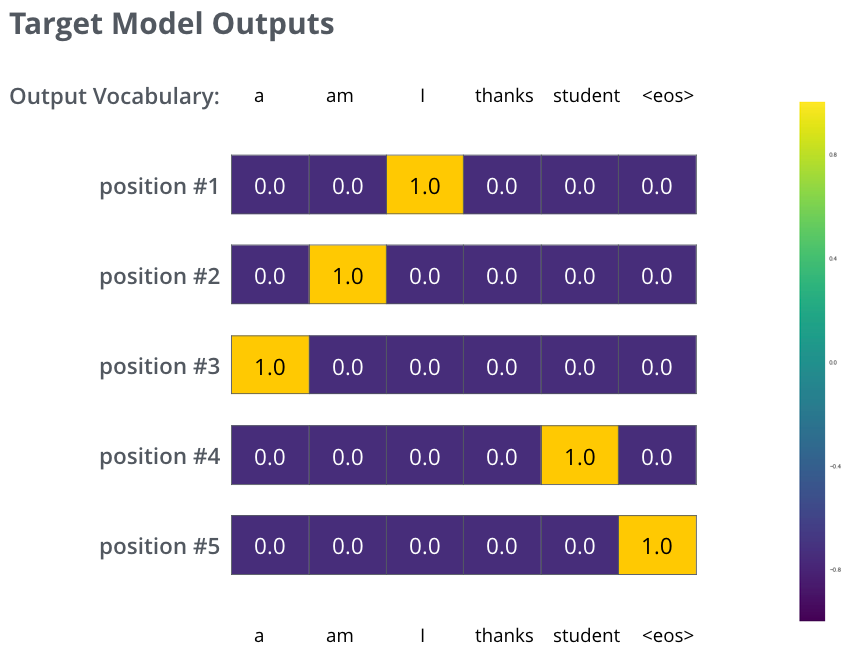
The targeted probability distributions we'll train our model against in the training example for one sample sentence.
在一个足够大的数据集上充分训练后,我们希望模型输出的概率分布看起来像这个样子:
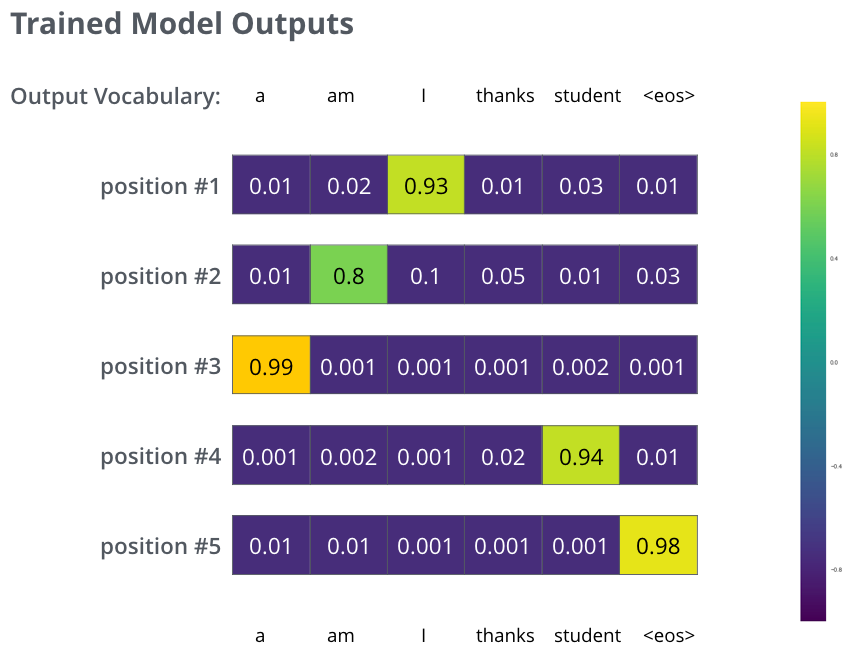
我们期望训练过后,模型会输出正确的翻译。当然如果这段话完全来自训练集,它并不是一个很好的评估指标(参考:交叉验证,链接https://www.youtube.com/watch?v=TIgfjmp-4BA)。注意到每个位置(词)都得到了一点概率,即使它不太可能成为那个时间步的输出——这是softmax的一个很有用的性质,它可以帮助模型训练。
因为这个模型一次只产生一个输出,不妨假设这个模型只选择概率最高的单词,并把剩下的词抛弃。这是其中一种方法(叫贪心解码)。另一个完成这个任务的方法是留住概率最高的两个单词(例如I和a),那么在下一步里,跑模型两次:其中一次假设第一个位置输出是单词“I”,而另一次假设第一个位置输出是单词“me”,并且无论哪个版本产生更少的误差,都保留概率最高的两个翻译结果。然后我们为第二和第三个位置重复这一步骤。这个方法被称作集束搜索(beam search)。在我们的例子中, beam_size was two (meaning that at all times, two partial hypotheses (unfinished translations) are kept in memory), and top_beams is also two (meaning we’ll return two translations). These are both hyperparameters that you can experiment with.
Go Forth And Transform
希望本文能够帮助读者对Transformer的主要概念理解有个破冰效果,如果想更深入了解,建议如下步骤:
- 阅读 Attention Is All You Need paper,Transformer的博客文章Transformer: A Novel Neural Network Architecture for Language Understanding,Tensor2Tensor使用说明。
- 观看"Łukasz Kaiser’s talk",梳理整个模型及其细节。
- 耍一下项目Jupyter Notebook provided as part of the Tensor2Tensor repo
- 尝试下项目Tensor2Tensor
