

文本分类算法之HAN模型
概述
我们前面介绍的文本分类算法,都是句子级别的分类,用到长文本、篇章级,虽然也是可以的,但速度精度都会下降,于是有研究者提出了层次注意力分类框架,即模型Hierarchical Attention,见论文Hierarchical Attention Networks for Document Classification。这篇论文表示,对文档/较长文本进行分类的时候,仅仅对word粒度进行Attention是不够的,还需要对各个句子(短句)进行Attention的学习,不同句子也需要分配不同的权重,每个句子里的词语也分配不同的权重。具体的过程就是先对每个句子用 BiGRU+Att 编码得到句向量,再对句向量用 BiGRU+Att 得到doc级别的表示,然后进行分类。下面我们会详细的介绍HAN模型的架构以及pytorch实现。
模型架构
HAN模型的架构如下所示:
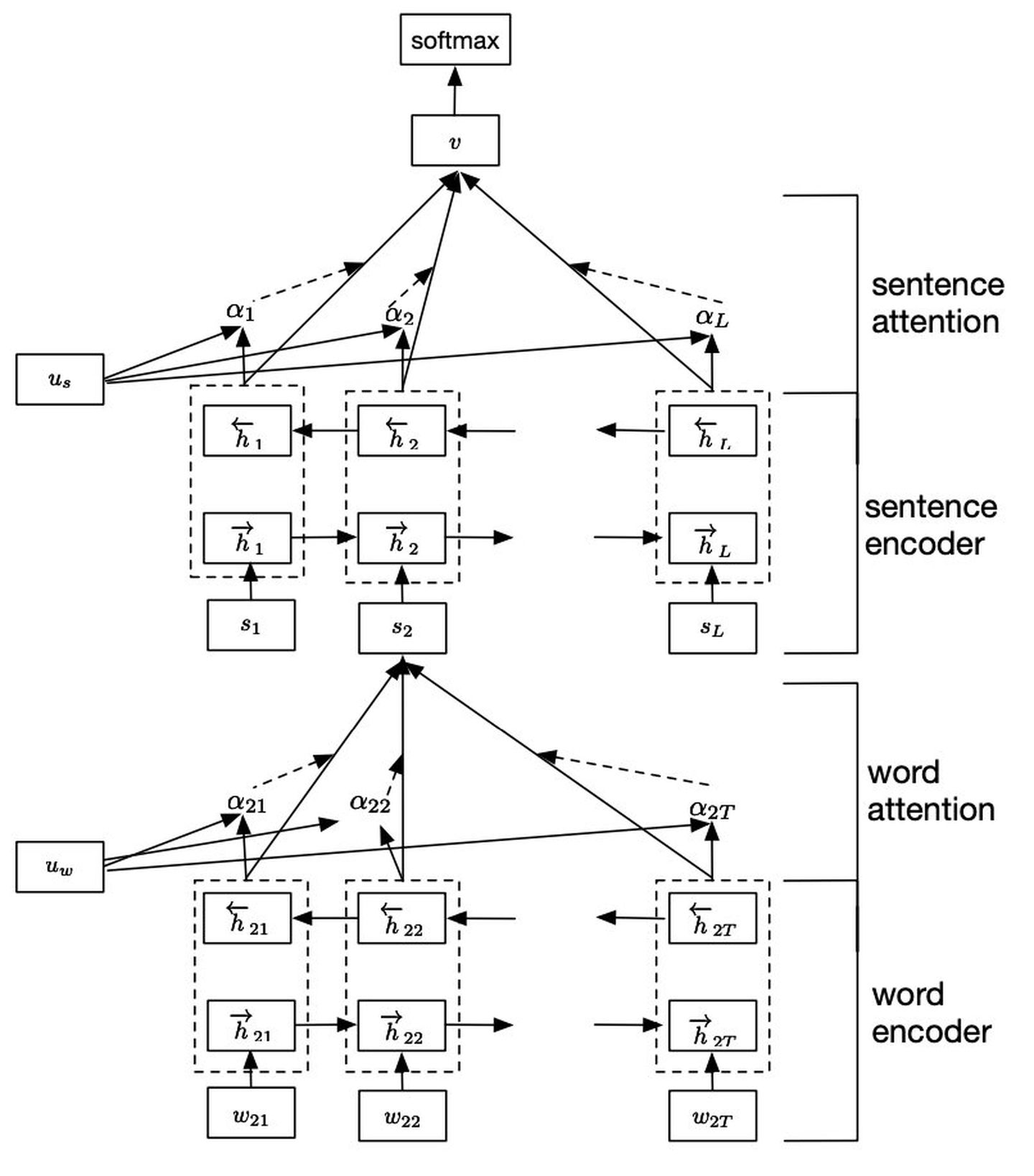
- Word Encoder. 先对词汇进行编码,建立词向量。接着用BiGRU从单词的两个方向汇总信息来获取单词的语义表示,因此将上下文信息合并到句子向量中。
- Word Attention. 对每句话的词语进行Attention操作,最后每句话都有一个特征向量,可以看做句向量
- Sentence Encoder. 与word encoder相似,对句子级别也使用BiGRU获取上下句的信息
- Sentence Attention. 与 word Attention相似,对所有句子进行Attention操作,获得一个每个句子加权平均作为整个输入的特征向量
- Document Classification. 送入全连接softmax层输出分类结果
pytorch实现
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
from torch.nn import functional as F
class HAN_Attention(nn.Module):
'''层次注意力网络文档分类模型实现,词向量,句子向量'''
def __init__(self, vocab_size, embedding_dim, gru_size, class_num, weights=None, is_pretrain=False):
super(HAN_Attention, self).__init__()
if is_pretrain:
self.word_embed = nn.Embedding.from_pretrained(weights, freeze=False)
else:
self.word_embed = nn.Embedding(vocab_size, embedding_dim)
# 词注意力
self.word_gru = nn.GRU(input_size=embedding_dim, hidden_size=gru_size, num_layers=1, bidirectional=True, batch_first=True)
self.word_query = nn.Parameter(torch.Tensor(2*gru_size, 1), requires_grad=True) # 公式中的u(w)
self.word_fc = nn.Linear(2*gru_size, 2*gru_size)
# 句子注意力
self.sentence_gru = nn.GRU(input_size=2*gru_size, hidden_size=gru_size, num_layers=1, bidirectional=True, batch_first=True)
self.sentence_query = nn.Parameter(torch.Tensor(2*gru_size, 1), requires_grad=True) # 公式中的u(s)
self.sentence_fc = nn.Linear(2*gru_size, 2*gru_size)
# 文档分类
self.class_fc = nn.Linear(2*gru_size, class_num)
def forward(self, x, use_gpu=False): # x: b, sentence_num, sentence_len
sentence_num = x.size(1)
sentence_len = x.size(2)
x = x.view(-1, sentence_len) # b*sentence_num, sentence_len
embed_x = self.word_embed(x) # b*sentence_num , sentence_len, embedding_dim
word_output, word_hidden = self.word_gru(embed_x) # word_output: b*sentence_num, sentence_len, 2*gru_size
# 计算u(it)
word_attention = torch.tanh(self.word_fc(word_output)) # b*sentence_num, sentence_len, 2*gru_size
# 计算词注意力向量weights: a(it)
weights = torch.matmul(word_attention, self.word_query) # b*sentence_num, sentence_len, 1
weights = F.softmax(weights, dim=1) # b*sentence_num, sentence_len, 1
x = x.unsqueeze(2) # b*sentence_num, sentence_len, 1
if use_gpu:
# 去掉x中padding为0位置的attention比重
weights = torch.where(x!=0, weights, torch.full_like(x, 0, dtype=torch.float).cuda()) #b*sentence_num, sentence_len, 1
else:
weights = torch.where(x!=0, weights, torch.full_like(x, 0, dtype=torch.float))
# 将x中padding后的结果进行归一化处理,为了避免padding处的weights为0无法训练,加上一个极小值1e-4
weights = weights / (torch.sum(weights, dim=1).unsqueeze(1) + 1e-4) # b*sentence_num, sentence_len, 1
# 计算句子向量si = sum(a(it) * h(it)) : b*sentence_num, 2*gru_size -> b*, sentence_num, 2*gru_size
sentence_vector = torch.sum(weights * word_output, dim=1).view(-1, sentence_num, word_output.size(2))
sentence_output, sentence_hidden = self.sentence_gru(sentence_vector) # sentence_output: b, sentence_num, 2*gru_size
# 计算ui
sentence_attention = torch.tanh(self.sentence_fc(sentence_output)) # sentence_output: b, sentence_num, 2*gru_size
# 计算句子注意力向量sentence_weights: a(i)
sentence_weights = torch.matmul(sentence_attention, self.sentence_query) # sentence_output: b, sentence_num, 1
sentence_weights = F.softmax(sentence_weights, dim=1) # b, sentence_num, 1
x = x.view(-1, sentence_num, x.size(1)) # b, sentence_num, sentence_len
x = torch.sum(x, dim=2).unsqueeze(2) # b, sentence_num, 1
if use_gpu:
sentence_weights = torch.where(x!=0, sentence_weights, torch.full_like(x, 0, dtype=torch.float).cuda())
else:
sentence_weights = torch.where(x!=0, sentence_weights, torch.full_like(x, 0, dtype=torch.float)) # b, sentence_num, 1
sentence_weights = sentence_weights / (torch.sum(sentence_weights, dim=1).unsqueeze(1) + 1e-4) # b, sentence_num, 1
# 计算文档向量v
document_vector = torch.sum(sentence_weights * sentence_output, dim=1) # b, sentence_num, 2*gru_size
document_class = self.class_fc(document_vector) # b, sentence_num, class_num
return document_class
if __name__ == '__main__':
model = HAN_Attention(3000, 200, 50, 4)
x = torch.zeros(64, 50, 100).long() # b, sentence_num, sentence_len
x[0][0][0:10] = 1
document_class = model(x)
print(document_class.shape) # 64, 4
小结
方法很符合直觉,不过实验结果来看比起avg、max池化只高了不到1个点(狗头,真要是很大的doc分类,好好清洗下,fasttext其实也能顶的,捂脸。)
参考
tensorflow文本分类实战(五)——HAN模型
深度学习文本分类模型综述+代码+技巧
【pytorch模型实现9】HAN_Attention
