
文本分类算法之BiLSTM+Attention
概述
Attention,注意力机制在提出之时就引起了众多关注,就像我们人类对某些重要信息更加看重一样,Attention可以对信息进行权重的分配,最后进行带权求和,因此Attention方法可解释性强,效果更好。本文主要讲解论文Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification中提出的BiLSTM+Attention模型,下面我们将详细的讲解这个模型。
模型架构
BiLSTM+Attention模型的网络架构如下图所示:
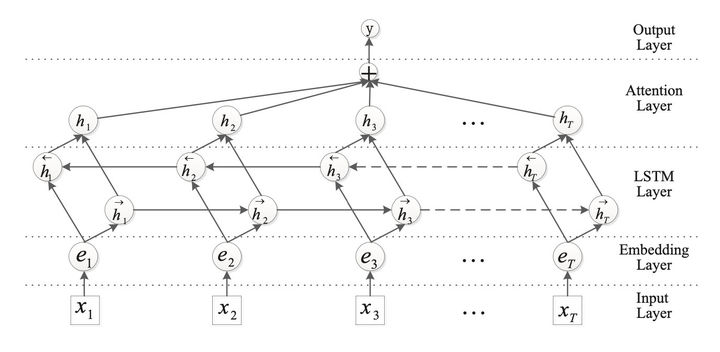
从图中可以看出,相对于以前的文本分类中的BiLSTM模型,BiLSTM+Attention模型的主要区别是在BiLSTM层之后,全连接softmax分类层之前接入了一个叫做Attention Layer的结构,Attention层先计算BiLSTM输出中每个位置词语的权重,然后将所有位置词语的的向量进行加权和作为句子的表示向量,然后进行softmax分类。针对论文Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification,里面的attention计算公式及分类公式为(个人:对于这里的数学公式,这里只要把握住最终得到的attention加权向量\(r\)是一个列向量,而矩阵乘法HAtt,左边的H可以看成\((H_1,H_2,H_3,...,H_n)\),即\(1*n\)的行向量,右边的权重Att可以看成\((att_1;att_2;att_3;...,att_n)\),即\(n*1\)的列向量,最终可以得到经过加权之后的列向量,这一点定下来后,我们可以知道矩阵H的维度,也就是矩阵H里的向量是行排还是列排;这之后,再倒推如何得到权重向量,是左乘还是右乘):
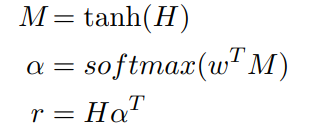
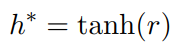
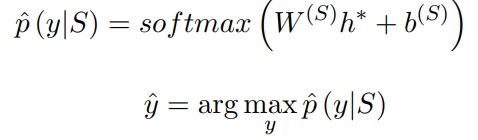
这里H的维数为(hidden_size * 2,seq_len),w的维数为(hidden_size * 2,1),w是需要学习的参数,随机初始化并随着训练更新。
注:这里写的只是数学上的计算公式,具体到我们用pytorch进行实现时,我们会利用到pytorch中张量相乘广播的特性,我会在实现代码中详细的备注好中间过程中变量的维度信息。
pytorch实现中的关键代码部分
这里给出pytorch代码实现中的关键的代码部分,至于整个的代码流程的其它部分,这里不再详述。
class BiLSTMAttention(nn.Module):
def __init__(self, config):
super(BiLSTMAttention, self).__init__()
if config.embedding_pretrained is not None:
#模型的嵌入层
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embedding_size, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embedding_size, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
self.w = nn.Parameter(torch.Tensor(config.hidden_size * 2, 1))
self.tanh2 = nn.Tanh()
self.fc = nn.Linear(config.hidden_size*2, config.num_classes)
nn.init.uniform_(self.w, -0.1, 0.1)
def forward(self, x):
#x:[batch_size,seq_len]
emb = self.embedding(x) # [batch_size, seq_len, embedding_size]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * 2]
M = self.tanh1(H) # [batch_size, seq_len, hidden_size * 2]
#张量广播操作
alpha = F.softmax(torch.matmul(M, self.w), dim=1)# [batch_size, seq_len, 1]
#张量元素相乘,会发生张量广播使得张量的维度满足条件
out = H * alpha # [batch_size, seq_len, hidden_size * 2]
#torch.sum操作默认情况下不保持维度
out = torch.sum(out, 1) # [batch_size,hidden_size * 2]
out = self.tanh2(out)
out = self.fc(out)# [batch_size,num_classes]
return out
参考
tensorflow文本分类实战(四)——Bi-LSTM+Attention
深度学习文本分类模型综述+代码+技巧
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践

