

文本分类算法之DPCNN模型
概述
ACL2017年中,腾讯AI-lab提出了Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN),即本文要介绍的主角,我们知道以前的TextCNN的过程类似于提取N-Gram信息,而且只有一层,难以捕捉长距离特征,不能通过卷积获得文本的长距离关系依赖,而论文中提出了一种基于word-level(以单词为语义单位)级别的深层金字塔卷积网(DPCNN),通过不断加深网络,可以抽取长距离的文本依赖关系。其性能如下表所示:
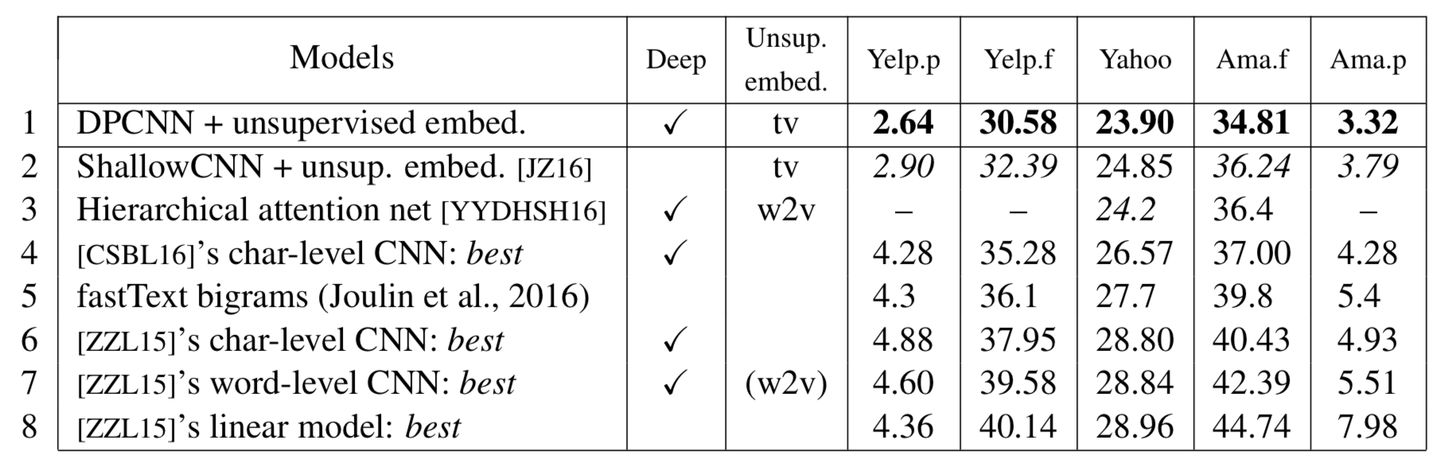
当然,这篇论文里还使用了two-view embedding来进一步提升模型性能,不过从模型性能上纵向比较来看,其也比经典的TextCNN(表格第二行ShallowCNN)有了明显提高,在Yelp五分类情感分类任务中提升了近2个百分点。也是第一次真正意义上证明了在word-level的文本分类问题上,深层CNN依然是有想象空间的。
下面我们会详细的介绍DPCNN模型的网络结构。
DPCNN网络结构
具体的DPCNN网络结构如下图中的(a)所示:
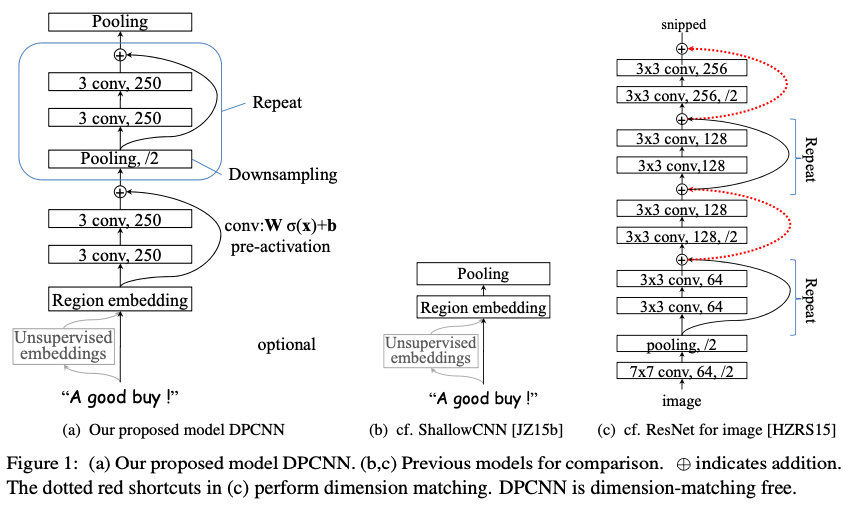
Region embedding
DPCNN的底层貌似保持了跟TextCNN一样的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region(区域) embedding,意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。
对一个3gram进行卷积操作时可以有两种选择:
- 保留词序,也就是设置一组size=3*D的二维卷积核对3gram进行卷积(其中D是word embedding维度);
- 不保留词序(即使用词袋模型),即首先对3gram中的3个词的embedding进行pooling取均值得到一个size=D的向量,然后设置一组size=D的一维卷积核对该3gram进行卷积。
显然TextCNN里使用的是保留词序的做法,而DPCNN使用的是词袋模型的做法,因为实验下来效果差不多,且作者认为前者的表示能力更强,容易过拟合。(前者的卷积核参数更多,表达能力更强,模型更容易过拟合)
在得到Region embedding后,为了避免后续想象太抽象,我们不妨还是把Region embedding看成word embedding,假想为交给网络后面的就是word embedding序列。
等长卷积
首先交代一下卷积的的一个基本概念。
假设输入的序列长度为n,卷积核大小为m,步长(stride)为s,输入序列两端各填补p个零(zero padding),那么该卷积层的输出序列为(n-m+2p)/s+1。
一般常用的卷积有以下三类:
-
窄卷积(narrow convolution): 步长s=1,两端不补零,即p=0,卷积后输出长度为n-m+1。
-
宽卷积(wide onvolution) :步长s=1,两端补零p=m-1,卷积后输出长度 n+m-1。
-
等长卷积(equal-width convolution): 步长s=1,两端补零p=(m-1)/2,卷积后输出长度为n。如下图所示,左右两端同时补零p=1,s=3。
那么对文本,或者说对word embedding序列进行等长卷积的意义是什么呢?既然输入输出序列的位置数一样多,我们将输入输出序列的第n个embedding称为第n个词位,那么这时size为n的卷积核产生的等长卷积的意义就很明显了,那就是将输入序列的每个词位及其左右((n-1)/2)个词的上下文信息压缩为该词位的embedding,也就是说,产生了每个词位的被上下文信息修饰过的更高level、更加准确的语义。
回到DPCNN上来。我们想要克服TextCNN的缺点,捕获长距离模式,显然就要用到深层CNN啦。那么直接等长卷积堆等长卷积可不可以呢?
- 显然这样会让每个词位包含进去越来越多,越来越长的上下文信息,
- 但是这样效率也太低,显然会让网络层数变得非常非常深。
不过,既然等长卷积堆等长卷积,会让每个词位的embedding,描述语义,描述的更加丰富准确,那么当然我们可以适当的堆两层来提高词位embedding的表示的丰富性。
固定feature maps(filters)的数量
许多模型每当执行池化操作时,增加feature maps的数量,导致总计算复杂度是深度的函数。与此相反,作者对feature map的数量进行了修正,他们实验发现增加 feature map 的数量只会大大增加计算时间,而没有提高精度。
在表示好每个词位的语义后,其实很多邻接词或者邻接ngram的词义是可以合并的,例如“小娟 姐姐 人 不要 太好”中的“不要”和“太好”虽然语义本来离得很远,但是作为邻接词“不要太好”出现时其语义基本等价为“很好”,这样完全可以把“不要”和“太好”的语义进行合并哇。同时,合并的过程完全可以在原始的embedding space中进行的,毕竟原文中直接把“不要太好”合并为“很好”是很可以的哇,完全没有必要动整个语义空间。而实际上,相比图像中这种从“点、线、弧”这种low-level特征到“眼睛、鼻子、嘴”这种high-level特征的明显层次性的特征区分,文本中的特征进阶明显要扁平的多,即从单词(1gram)到短语再到3gram、4gram的升级,其实很大程度上均满足“语义取代”的特性。而图像中就很难发生这种”语义取代“现象(例如“鼻子”的语义可以被”弧线“的语义取代嘛?)。因此,DPCNN与ResNet很大一个不同就是,
-
在DPCNN中固定死了feature map的数量,也就是固定住了embedding space的维度(为了方便理解,以下简称语义空间),使得网络有可能让整个邻接词(邻接ngram)的合并操作在原始空间或者与原始空间相似的空间中进行(当然,网络在实际中会不会这样做是不一定的哦,只是提供了这么一种条件)。也就是说,整个网络虽然形状上来看是深层的,但是从语义空间上来看完全可以是扁平的。
-
而ResNet则是不断的改变语义空间,使得图像的语义随着网络层的加深也不断的跳向更高level的语义空间。
1/2池化层
好啦,所以提供了这么好的合并条件后,我们就可以用pooling layer进行合并啦。每经过一个size=3, stride=2(大小为3,步长为2)的池化层(以下简称1/2池化层),序列的长度就被压缩成了原来的一半。这样同样是size=3的卷积核,每经过一个1/2池化层后,其能感知到的文本片段就比之前长了一倍。例如之前是只能感知3个词位长度的信息,经过1/2池化层后就能感知6个词位长度的信息。
好啦,看似问题都解决了,目标成功达成。剩下的我们就只需要重复的进行下图所示的block:
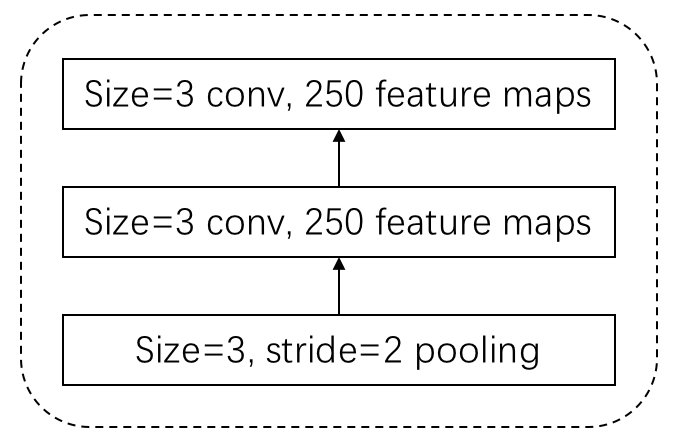
残差连接
但是,如果问题真的这么简单的话,深度学习就一下子少了超级多的难点了。
- 由于我们在初始化深度CNN时,往往各层权重都是初始化为一个很小的值,这就导致最开始的网络中,后续几乎每层的输入都是接近0,这时网络的输出自然是没意义的;
- 而这些小权重同时也阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代好久才能启动。
- 同时,就算网络启动完成,由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题(虽然由于非共享权重,深度CNN网络比RNN网络要好点)。
当然,上述这几点问题本质就是梯度弥散问题。那么如何解决深度CNN网络的梯度弥散问题呢?当然是膜一下何恺明大神,然后把ResNet的精华拿来用啦~ResNet中提出的shortcut-connection/skip-connection/residual-connection(残差连接)就是一种非常简单、合理、有效的解决方案。既然每个block的输入在初始阶段容易是0而无法激活,那么直接用一条线把region embedding层连接到每个block的输入乃至最终的池化层/输出层不就可以啦!
-
想象一下,这时的shortcut connection由于连接到了各个block的输入(当然为了匹配输入维度,要事先经过对应次数的1/2池化操作),这时就相当于一个短路连接,即region embedding直接短路连接到了最终的池化层或输出层。等等,这时的DPCNN不就退化成了TextCNN嘛。深度网络不好训练,就一层的TextCNN可是异常容易训练的。这样模型的起步阶段就是从TextCNN起步了,自然不会遭遇前面说的深度CNN网络的冷启动问题了。
-
同样的道理,有了shortcut后,梯度就可以忽略卷积层权重的削弱,从shortcut一路无损的传递到各个block手里,直至网络前端,从而极大的缓解了梯度消失问题。
所以DPCNN里的Block里加上了shortcut connection后,就完美多啦。即设计出了如下最终版的网络形态:
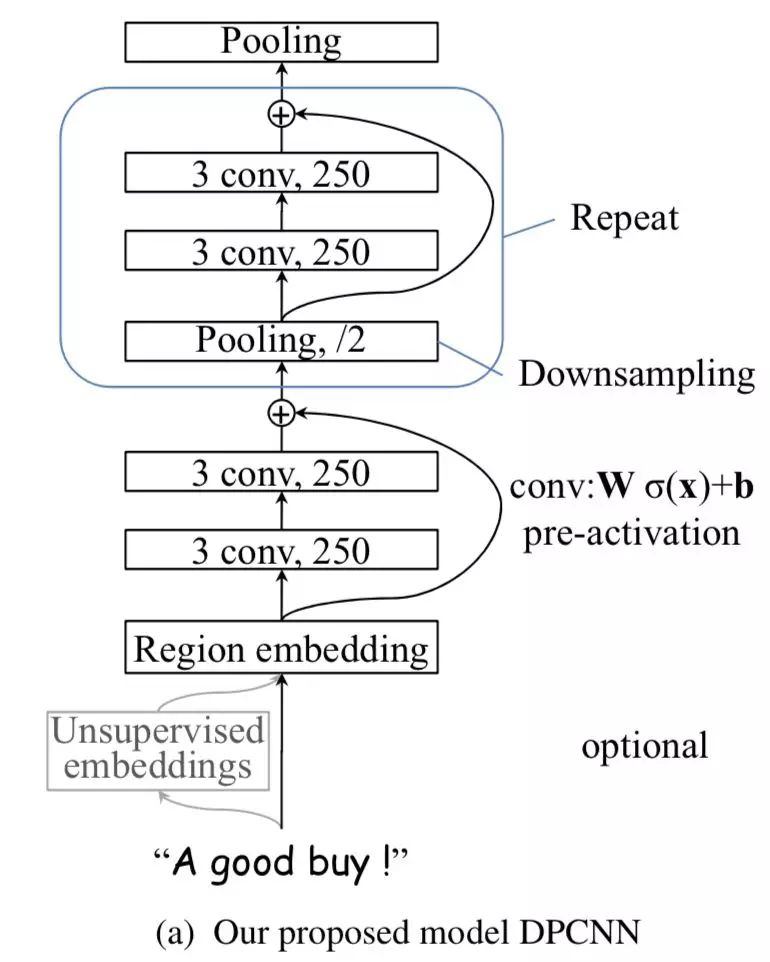
整体来说,巧妙的结构设计,使得这个模型不需要为了维度匹配问题而担忧。
最后点一下题目,由于前面所述的1/2池化层的存在,文本序列的长度会随着block数量的增加呈指数级减少,即
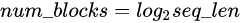
这导致序列长度随着网络加深呈现金字塔(Pyramid)形状:

因此作者将这种深度定制的简化版ResNet称之为Deep “Pyramid” CNN。
pytorch实现中的关键代码部分
这里给出pytorch代码实现中的关键的代码部分,至于整个的代码流程的其它部分,这里不再详述。
class DPCNN(nn.Module):
def __init__(self, config):
super( DPCNN, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embeding_size, padding_idx=config.n_vocab - 1)
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.embeding_size), stride=1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
x = self.embedding(x) # [batch_size,seq_len,embeding_size]
x = x.unsqueeze(1) # [batch_size, 1, seq_len, embeding_size]
x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
while x.size()[2] > 2:
x = self._block(x)
x = x.squeeze() # [batch_size, num_filters(250)]
x = self.fc(x)
return x
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
# Short Cut
x = x + px
return x
参考
从经典文本分类模型TextCNN到深度模型DPCNN
DPCNN 模型详解
知否?知否?一文看懂深度文本分类之DPCNN原理与代码
深度学习文本分类模型综述+代码+技巧

