
文本分类算法之TextRNN模型
概述
文本分类任务中,CNN可以用来提取句子中类似N-Gram的关键信息,适合短句子文本。尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定filter_size的视野,
- 一方面无法建模更长的序列信息,
- 另一方面
filter_size的超参调节也很繁琐。
CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息,TextRNN擅长捕获更长的序列信息。具体到文本分类任务中,从某种意义上可以理解为可以捕获变长、单向的N-Gram信息(Bi-LSTM可以是双向)。
普通RNN在处理较长文本时会出现梯度消失问题,因此文本中RNN选用LSTM进行实验。
RNN算是在自然语言处理领域非常常见的一个标配网络了,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介绍了RNN用于分类问题的设计,下图是LSTM用于网络结构原理示意图,示例中是利用最后一个词的结果,可以看做是包含了前面所有词语的信息,然后直接接全连接层softmax输出了。
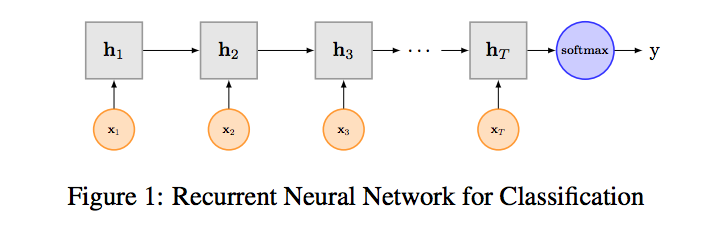
Bi-LSTM
Bi-LSTM是LSTM的改进版本,将单向RNN结构改成了双向RNN,希望不仅能考虑正向编码的信息,也能考虑反向编码的信息,模型结构如下图所示:
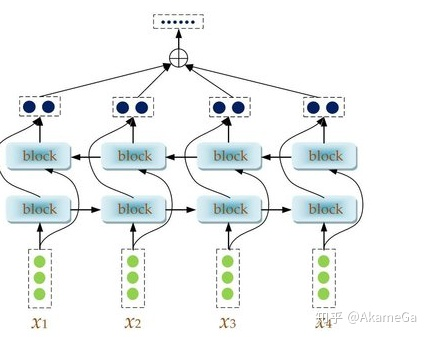
与LSTM不同的是,在rnn部分使用了Bi-LSTM进行信息提取,Bi-LSTM层中,内部有两个LSTM,分别为Forward层和Backward层,表示前向与后向,每个LSTM设定输出的维度为embeding_size维向量,在Forward层从1时刻到t时刻正向计算一遍,得到并保存每个时刻向前隐含层的输出。在Backward层沿着时刻t到时刻1反向计算一遍,得到并保存每个时刻向后隐含层的输出。最后在每个时刻结合Forward层和Backward层的相应时刻输出的结果进行拼接得到最终的输出。因此输出的维度为embeding_size*2维。
pytorch实现中的关键代码部分
这里给出pytorch代码实现中的关键的代码部分,至于整个的代码流程的其它部分,这里不再详述。
对于不同长度的问题文本,padding和truncate成一样长度的。太短的就补空格,太长的就截断。
class TextRNN(nn.Module):
def __init__(self, config):
super(TextRNN, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
#x:[batchsize, max_length]
out = self.embedding(x) # [batch_size, seq_len, embeding]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层和后向隐层拼接)
[batch_size, seq_len, hidden_size * 2]
4.拿出最后时刻的隐层值:
[batch_size, hidden_size * 2]
5.全连接:num_class是预测的类别数
[batch_size, num_class]
总结
- LSTM能更好的捕捉长距离语义关系,
- 但是由于其递归结构,不能并行计算,速度慢。
参考
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
tensorflow文本分类实战(二)——TextRNN
