
文本分类算法之Fasttext 模型
概述
fasttext是facebook开源的一个词向量与文本分类工具,FastText模型 是word2vec 作者 Mikolov转战 Facebook 后于2016年7月发表在论文Bag of Tricks for Efficient Text Classification上,在学术上并没有太大创新,但它的优点也非常明显,它的官网(fasttext.cc)上是这样介绍的:
FastText is an open-source, free, light weight library that allows users to learn text representations and text classifiers.It works on standard, generic hardware. Models can later be reduced in size to even fit on mobile devices.
fastText最惊艳的地方在于,和最前沿深度神经网络模型相比,它在分类精度等指标毫不逊色的情况下,把训练和推断速度降低了几个数量级!按Facebook的报告,在普通多核CPU上,10亿词的文本训练时间小于10分钟,50万句子分到31.2万类别用时小于1分钟。下面这张图可以清楚地看到这一点,

fastText能够做到效果好,速度快,主要依靠两个秘密武器:
- 一是利用了词内的n-gram信息(subword n-gram information),
- 二是用到了层次化Softmax回归(Hierarchical Softmax)的训练trick。
这里有一点需要特别注意,一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。除非你决定使用预训练的embedding来训练fastText分类模型,这另当别论。下面我们会详细的介绍fastText的原理。
FastText原理
模型架构
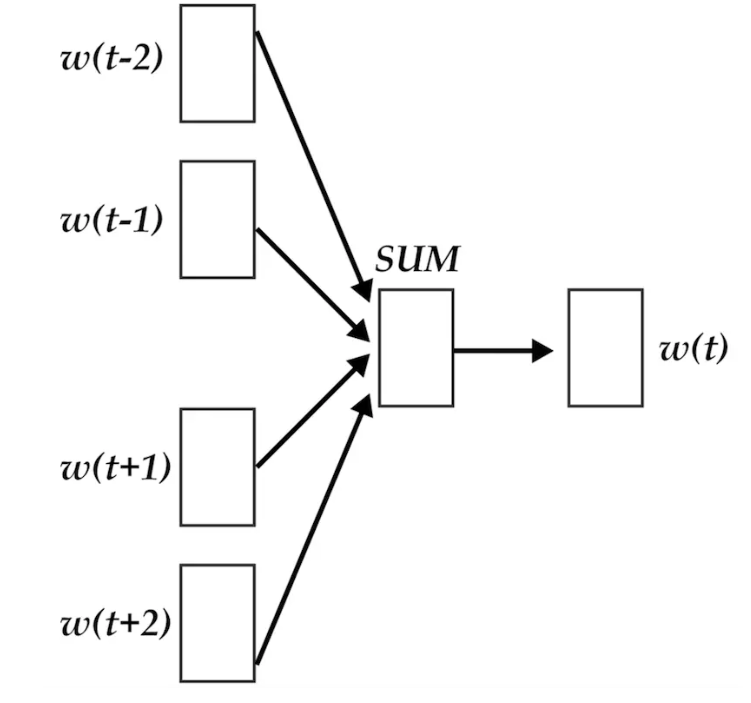
fastText 的架构和 word2vec 中的 CBOW(Continuous Bog-Of-Word) 的架构类似, 不同之处是 fastText 预测标签而 CBOW 预测的是中间词,即模型架构类似但是模型的任务不同。下面我们先看一下 CBOW 的架构:
CBOW架构:
fastText模型架构:
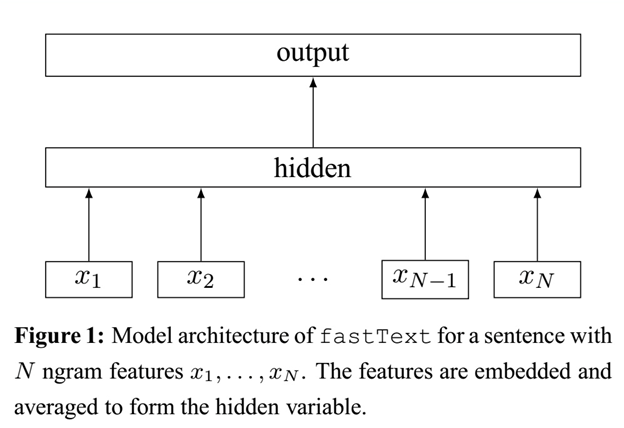
注意:此架构图没有展示词向量的训练过程。
可以看到,和 CBOW 一样,
- fastText 模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),
- 输入都是多个经向量表示的单词,
- 输出都是一个特定的target,
- 隐含层都是对多个词向量的叠加平均。
不同的是,
- CBOW 的输入是目标单词的上下文,fastText 的输入是多个单词及其 n-gram 特征,这些特征用来表示单个文档;
- CBOW 的输入单词被 onehot 编码过,fastText 的输入特征是被 embedding 过;
- CBOW 的输出是目标词汇,fastText 的输出是文档对应的类标。
值得注意的是,fastText 在输入时,将单词的字符级别的 n-gram 向量作为额外的特征;在输出时,fastText 采用了分层 Softmax,大大降低了模型训练时间。
subword n-gram information
在介绍fastText里面引入的subword n-gram information之前,我们先介绍一下什么是n-gram特征。
在文本特征提取中,常常能看到n-gram的身影。它是一种基于语言模型的算法,基本思想是将文本内容,按照字节顺序,进行大小为N的滑动窗口操作,最终形成长度为N的字节片段序列。
看下面的例子:
我来到天安门广场参观
相应的bigram特征为:我来 来到 到天 天安 安门 门广 广场 场参 参观
相应的trigram特征为:我来到 来到天 到天安 天安门 安门广 门广场 广场参 场参观
注意一点:n-gram中的gram根据粒度不同,有不同的含义。它可以是字粒度,也可以是词粒度的。
上面所举的例子属于字粒度的n-gram,词粒度的n-gram看下面例子:
我 来到 天安门广场 参观
相应的bigram特征为:我/来到 来到/天安门广场 天安门广场/参观
相应的trigram特征为:我/来到/天安门广场 来到/天安门广场/参观
n-gram产生的特征只是作为文本特征的候选集,你后面可能会采用信息熵、卡方统计、IDF等文本特征选择方式筛选出比较重要特征。
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:apple 和apples,这两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的 id 丢失了.
为了克服这个问题,fastText引入了subword n-gram的概念(字符级别的n-grams)来解决词形变化(morphology)的问题。举个例子,对于一个单词google,为了表达单词前后边界,我们加入<>两个字符,即变形为<google>。假设我们希望抽取所有的tri-gram信息,可以得到如下集合:G = { <go, goo, oog,ogl, gle, le>}。在实践中,我们往往会同时提取单词的多种n-gram信息,如2/3/4/5-gram。这样,原始的一个单词google,就被一个字符级别的n-gram集合所表达。在训练过程中,每个n-gram都会对应训练一个向量,而原来完整单词的词向量就由它对应的所有 n-gram 的向量求和得到。所有的单词向量以及字符级别的 n-gram 向量会同时相加求平均作为训练模型的输入。
这带来了以下好处:
- 低频词、罕见词,由于在语料中本身出现的次数就少,往往会得不到足够的训练,效果不佳;而
fastText通过引入subword n-gram information的技巧,对于低频词生成的词向量效果会更好。因为它们的 n-gram 可以和其它词共享。 - 未登录词,如果出现了一些在词典中都没有出现过的词,或者带有某些拼写错误的词,传统模型更加无能为力。而
fastText通过引入subword n-gram information的技巧,对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级 n-gram 向量。 - 词袋模型不能考虑词之间的顺序,而 fastText 通过引入 subword n-gram information 的技巧,来捕获一定的局部序列次序信息。例如,“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入字符级别的
2-ngram特征,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。
从实验效果来看,
subword n-gram information的加入,不但解决了低频词、未登录词的表达的问题,而且对于最终任务精度一般会有几个百分点的提升。- 唯一的问题就是由于需要估计的参数多(char n-grams embeding比较多),模型可能会比较膨胀。
不过,Facebook也提供了几点压缩模型的建议:
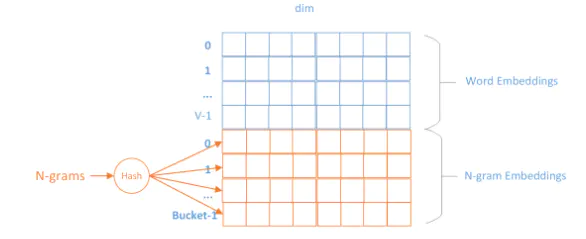
-
采用 hash-trick 。由于
n-gram原始的空间太大,可以用某种hash函数将其映射到固定大小的buckets中去,哈希到同一个桶的所有n-gram共享一个embedding vector,从而实现内存可控.
-
采用
quantize命令,对生成的模型进行参数量化和压缩。 -
减小最终向量的维度。
需要注意的是,以上几种方法都会以一定的精度损失为代价,尤其是维度的压缩,具体可以实践中再权衡。
Hierarchical Softmax
另一个效率优化的点是所谓的层次化 Softmax,对于有大量类别的数据集,fastText 使用了一个分层分类器(而非扁平式架构)。
Softmax 大家都比较熟悉,它是逻辑回归(logistic regression)在多分类任务上的推广,是我们训练的神经网络中的最后一层。一般地,
- Softmax以隐藏层的输出h为输入,
- 经过线性和指数变换后,
- 再进行全局的归一化处理,
- 找到概率最大的输出项。
当词汇数量 V 较大时(一般会到几十万量级),Softmax计算代价很大,是O(V)量级。
层次化的 Softmax 的思想,实质上是将一个全局多分类的问题,转化成为了若干个二元分类问题,从而将计算复杂度从O(V)降到O(logV)。每个二元分类问题,由一个基本的逻辑回归单元来实现。
如下图所示,从根结点开始,每个中间结点(标记成灰色)都是一个逻辑回归单元,根据它的输出来选择下一步是向左走还是向右走。下图示例中实际上走了一条“左-左-右”的路线,从而找到单词w₂。而最终输出单词w₂的概率,等于中间若干逻辑回归单元输出概率的连乘积。
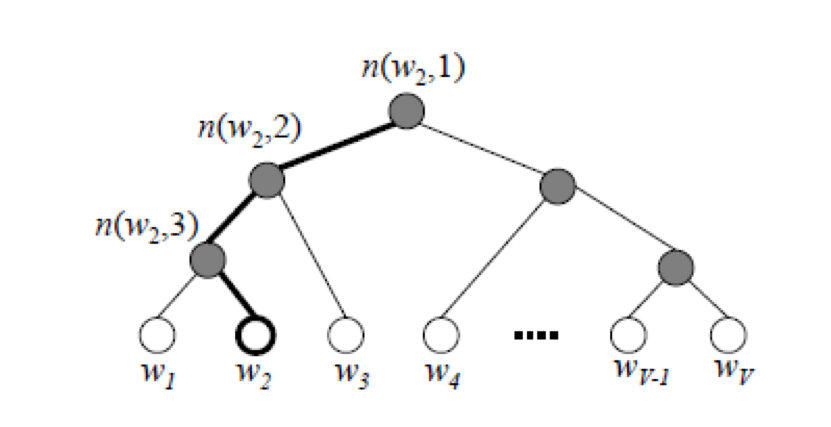
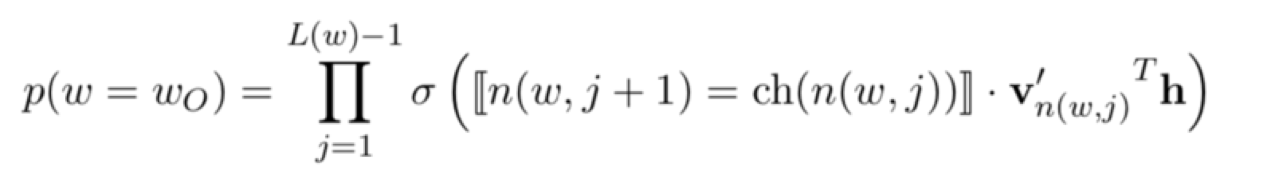
至此,我们还剩下两个问题,
- 一是如何构造每个逻辑回归单元的输入,
- 另一个是如何建立这棵用于判断的树形结构。
逻辑回归单元的参数
每个逻辑回归单元中,sigmoid函数所需的输入实际上由三项构成,如下公式所示:
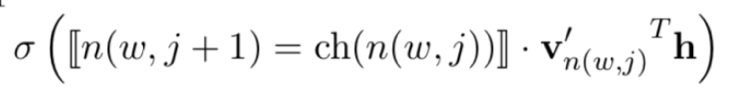
记号说明如下:
-
⟦x⟧是一个特殊的函数,如果下一步需要向左走其函数值定义为1,向右则取-1。在训练时,我们知道,最终输出叶子结点,并且从根结点到叶子结点的每一步的路径也是确定的。 -
v'是每个内部结点(逻辑回归单元)对应的一个向量,这个向量可以在训练过程中学习和更新。 -
h是网络中隐藏层的输出。
因此,我们以隐藏层的输出、中间结点对应向量以及路径取向函数为输入,相乘后再经过sigmoid函数,得到每一步逻辑回归的输出值。
霍夫曼树的构造
Hierarchical Softmax采用的树型结构实际上是一棵二叉霍夫曼树。
霍夫曼树是在解决通信编码过程中引入的。在通信过程中,需要将字符信息编码成为0/1二进制串。显然,给出现频繁的字符较短的编码,出现较少的字符以较长的编码,是最经济的方案。通过一棵霍夫曼树的构造,我们让越频繁的字符离根结点越近,使得最终的通信编码最短。
霍夫曼树的构造步骤如下:

在做Hierarchical Softmax之前,我们需要先利用所有词汇(类别)及其频次构建一棵霍夫曼树。这样,不同词汇(类别)作为输出时,所需要的判断次数实际上是不同的。越频繁出现的词汇,离根结点越近,所需要的判断次数也越少。这样对于类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构,因此,频繁出现类别的树形结构的深度,要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
总结
Fasttext直到现在还被不少人使用,主要有以下优点:
- 模型本身复杂度低,但效果不错,能快速产生任务的baseline
- Facebook使用C++进行实现,进一步提升了计算效率
- 采用了char-level的n-gram作为附加特征,比如paper的trigram是 [pap, ape, per],在将输入paper转为向量的同时也会把trigram转为向量一起参与计算。
- 这样一方面解决了未登录词的OOV (out-of-vocabulary)问题,
- 一方面利用n-gram特征提升了表现
- 当类别过多时,支持采用hierarchical softmax进行分类,提升效率
对于文本长且对速度要求高的场景,Fasttext是baseline首选。同时用它在无监督语料上训练词向量,进行文本表示也不错。不过想继续提升效果还需要更复杂的模型。
