
文本分类算法之textCNN模型
概述
textCNN,是Yoon Kim在2014年于论文Convolutional Naural Networks for Sentence Classification中提出的文本分类模型,开创了用CNN编码n-gram特征的先河。我们知道fastText 中的网络结构是完全没有考虑词序信息的,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,CNN原理的核心点在于可以捕捉局部相关性(局部特征),对于文本来说,局部特征就是由若干单词组成的滑动窗口,类似于N-gram。卷积神经网络的优势在于能够自动地对N-gram特征进行组合和筛选,获得不同抽象层次的语义信息。TextCNN的结构如下图所示:
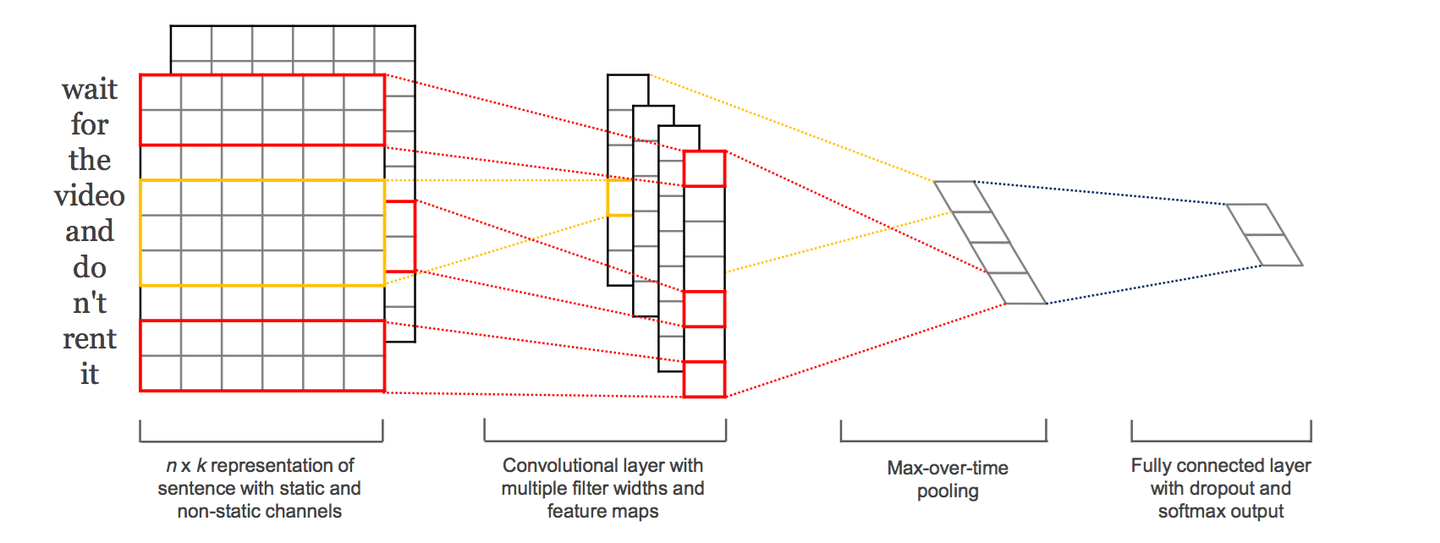
与图像当中CNN的网络相比,textCNN 最大的不同便是在输入数据的不同:
- 图像是二维数据, 图像的卷积核都是二维的,是从左到右, 从上到下进行滑动来进行特征抽取。
- 自然语言是一维数据,textCNN使用一维卷积,即filter_size*embedding_dim,有一个维度和embedding相等。虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义. 比如 "今天" 对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1* 2 从左到右滑动得到[0,0], [0,0], [0,0], [0, 1]这四个向量, 对应的都是"今天"这个词汇, 这种滑动没有帮助.
模型的具体结构
下面我们具体介绍一下TextCNN的详细过程,原理图如下所示:
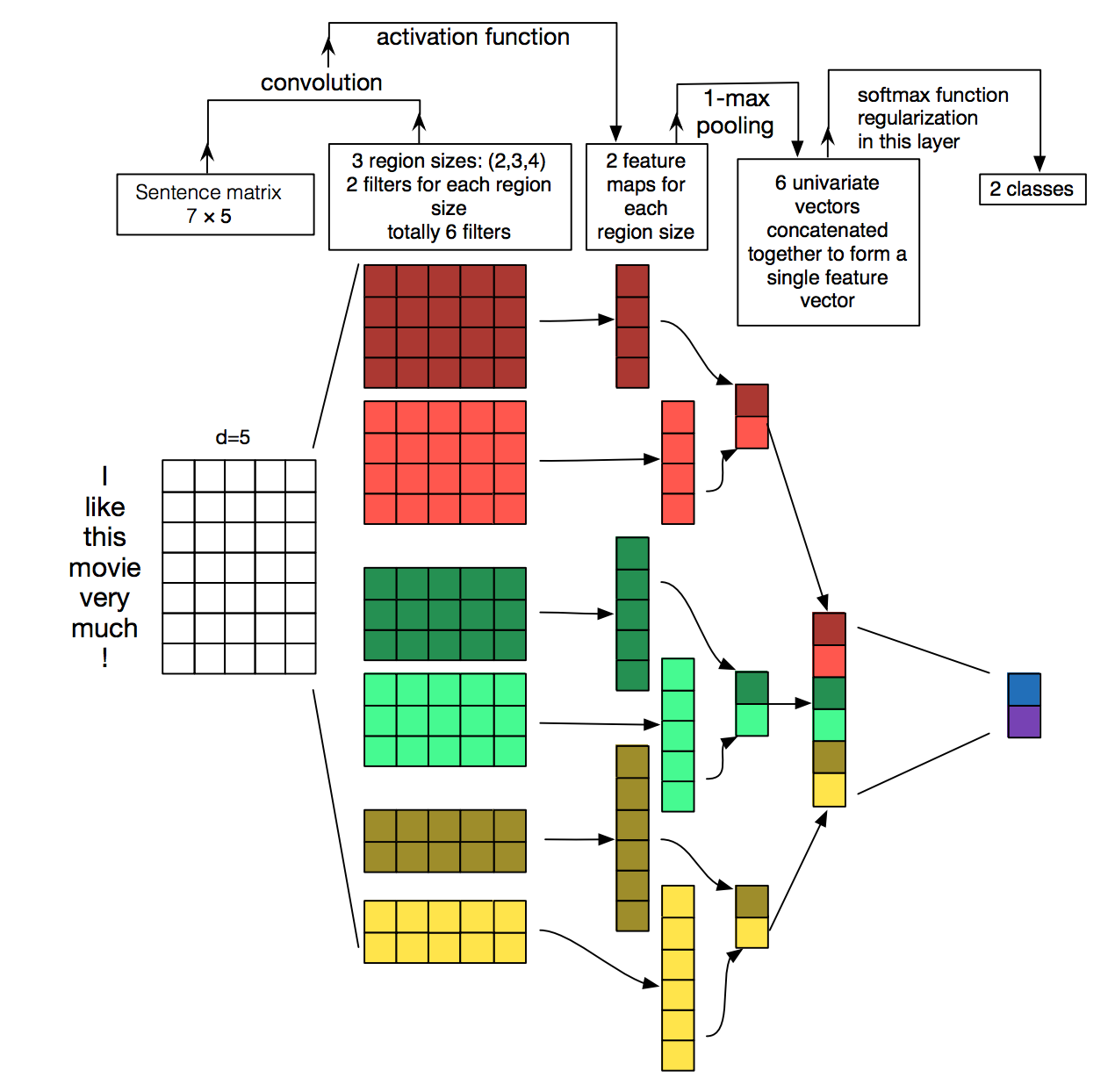
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。以1个样本为例,整体的前向逻辑是:
- 对词进行embedding,得到[seq_length, embedding_dim]
- 用N个卷积核,得到N个seq_length-filter_size+1长度的一维feature map
- 对feature map进行max-pooling(因为是时间维度的,也称max-over-time pooling),得到N个1x1的数值,这样不同长度句子经过pooling层之后都能变成定长的表示了,然后拼接成一个N维向量,作为文本的句子表示。
- 最后接一层全连接的 softmax 层,将N维向量压缩到类目个数的维度,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然,如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。根据原论文作者的描述, 一开始引入channel 是希望防止过拟合(通过保证学习到的vectors 不要偏离输入太多)来在小数据集合获得比单channel更好的表现,后来发现其实直接使用正则化效果更好。对于channel在textCNN 是否有用, 从论文的实验结果来看多channels并没有明显提升模型的分类能力, 七个数据集上的五个数据集 单channel 的textCNN 表现都要优于 多channels的textCNN。

我们在这里也介绍一下论文中四个model 的不同:
CNN-rand (单channel), 设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整.
CNN-static(单channel), 拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量.
CNN-non-static(单channel), pre-trained vectors + fine tuning , 即拿word2vec训练好的词向量初始化, 训练过程中再对它们微调.
CNN-multiple channel(多channels), 类比于图像中的RGB通道, 这里也可以用 static 与 non-static 搭两个通道来做.
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。一般来说在卷积之后会跟一个激活函数,例如ReLU或tanh。
Max-pooling 池化:这里使用的是max-pooling,从feature map中选出最大的一个值。也可以改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
max-pooling 在保持主要特征的情况下, 大大降低了参数的数目,好处有如下几点:
- 这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。
- 降低了过拟合的风险, feature map = [1, 1, 2] 或者[1, 0, 2] 最后的输出都是[2], 表明开始的输入即使有轻微变形, 也不影响最后的识别。
- 参数减少, 进一步加速计算。
pooling 本身无法带来平移不变性(图片有个字母A, 这个字母A 无论出现在图片的哪个位置, 在CNN的网络中都可以识别出来),卷积核的权值共享才能. max-pooling的原理主要是从多个值中取一个最大值,做不到这一点。cnn 能够做到平移不变性,是因为在滑动卷积核的时候,使用的卷积核权值是保持固定的(权值共享), 假设这个卷积核被训练的就能识别字母A, 当这个卷积核在整张图片上滑动的时候,当然可以把整张图片的A都识别出来。
全连接+softmax层 :我们将 max-pooling的结果通过全连接的方式,连接一个softmax层,softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。为了防止过拟合,在倒数第二层的全连接部分上使用dropout技术,dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了,它是防止模型过拟合的一种常用的trick。同时对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
模型的优化和调参
在TextCNN的实践中,有很多地方可以优化(参考这篇论文A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification):
- Filter尺寸:这个参数决定了抽取n-gram特征的长度,这个参数主要跟数据有关,平均长度在50以内的话,用10以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合
- Filter个数:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在100-600之间调参即可
- CNN的激活函数:可以尝试Identity、ReLU、tanh
- 正则化:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
- Pooling方法:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了
- Embedding表:中文可以选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足(10w+),也可以从头训练
- 蒸馏BERT的logits,利用领域内无监督数据
- 加深全连接:原论文只使用了一层全连接,而加到3、4层左右效果会更好
pytorch实现的关键代码片段
这里给出textCNN pytorch代码实现中的关键的代码部分,至于整个的代码流程的其它部分,这里不再详述。
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self, config):
super(TextCNN, self).__init__()
if config.embedding_pretrained is not None:
#模型的嵌入层
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
#模型的卷积层
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)#squeeze挤压
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
#x:[batchsize, max_length]
out = self.embedding(x)# [batchsize, max_length, embedding_size]
#这里相当于增加了一个in_channels维度,TextCNN输入的通道维数为1
out = out.unsqueeze(1)# [batchsize, 1, max_length, embedding_size]
# 这里分别使用不同size的卷积核进行卷积,以(2,, 300)为例
# 输入:[64, 1, 32, 300]
# 进行卷积得到输出:[64, 128, 32-2+1=31, 1]
# 经过卷积之后经过一个relu,然后变形成[64, 128, 31]
# 然后经过1维最大池化得[64, 128, 1],再变形为[64, 128]
# 最终将不同卷积核卷积后的结果拼接为,[64, 128*3]
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return out
数据处理:所有句子padding成一个长度:seq_len
1. 模型输入:
[batch_size, seq_len]
2. 经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size:
[batch_size, seq_len, embed_size]
3. 卷积层:NLP中卷积核宽度与embed-size相同,相当于一维卷积。
3个尺寸的卷积核:(2, 3, 4),每个尺寸的卷积核有128个。卷积后得到三个特征图:[batch_size, 128, seq_len-1]
[batch_size, 128, seq_len-2]
[batch_size, 128, seq_len-3]
4. 池化层:对三个特征图做最大池化
[batch_size, 128]
[batch_size, 128]
[batch_size, 128]
5. 拼接:
[batch_size, 128*3]
6. 全连接:num_class是预测的类别数
[batch_size, num_class]
7. 预测:softmax归一化,将num_class个数中最大的数对应的类作为最终预测
[batch_size, 1]
分析:
卷积操作相当于提取了句中的2-gram,3-gram,4-gram信息,多个卷积是为了提取多种特征,最大池化将提取到最重要的信息保留。
模型的优缺点
- TextCNN模型简单, 训练速度快,效果不错。是很适合中短文本场景的强baseline,
- 但不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。
- 同时max-pooling也存在局限,会丢掉一些有用特征。
- 另外再仔细想的话,TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,解决了词袋模型的稀疏性问题。
参考
文本分类算法TextCNN原理详解(一)
用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
深度学习文本分类模型综述+代码+技巧
