

pandas rank()函数
api
DataFrame.rank(axis=0,method='average',numeric_only=None,na_option='keep',ascending=True,
pct=False)
Compute numerical data ranks (1 through n) along axis.
By default, equal values are assigned a rank that is the average of the ranks of
those values.
method参数解释
method:{‘average’, ‘min’, ‘max’, ‘first’, ‘dense’}, default ‘average’
How to rank the group of records that have the same value (i.e. ties):
-
average: average rank of the group
-
min: lowest rank in the group
-
max: highest rank in the group
-
first: ranks assigned in order they appear in the array
-
dense: like ‘min’, but rank always increases by 1 between groups.
例子
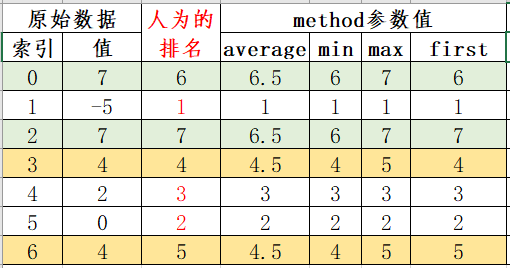
- 若为”average“,不相同的值,排名就取”人为的排名“的排名值,相同值的,排名需要求平均值,例如:索引0和2的值都为7,则平均值为(7+6)/2=6.5;
- 若为”min“,不相同的值,排名就取”人为的排名“的排名值,相同值的,排名取最小值,例如:索引0和2的值都为7,则排名都取6;
- 若为”max“,不相同的值,排名就取”人为的排名“的排名值,相同值的,排名取最大值,例如:索引0和2的值都为7,则排名都取7;
- 若为”first“,则就取”人为的排名“这列的值。
