
胡兴龙--第一次个人编程作业
| 博客班级 | <2018级计算机和综合实验班> |
|---|---|
| 作业要求 | <第一次个人编程作业> |
| 作业目标 | <数据采集,jieba 分词,echarts 生出云词图,上传 Github> |
| 作业源代码 | <GitHub 作业地址> |
| 学号 | <211806164> |
1. 记录代码行数,需求分析时间,编码时间
| 步骤 | 完成时间 | 代码量 |
|---|---|---|
| 了解作业需求,整理思路 | 1h | 无 |
| 爬取《在一起》腾讯视频评论 | 1h | 23行 |
| 学习并利用 jieba 进行分词 | 3h | 23行 |
| 学习并使用 echarts 生成词云图 | 4h | 很多很多行(320行) |
| 将作业上传 GitHub | 30min | 无 |
2. 实践开始
-
爬取《在一起》腾讯视频评论
先进入 腾讯视频评论区 按下F12观察,发现评论全部出现在一页,但每次只出现十个评论,需要按下最下方的 查看更多评论 才能查看下十个评论,从而得知,该页面是根据异步刷新方法更新数据,无法直接从网页源代码处爬取数据。但我们可以从 Network 中,以v2开头的标签中的 Preview 中发现评论数据,且每次刷新,都会生出一个新的。
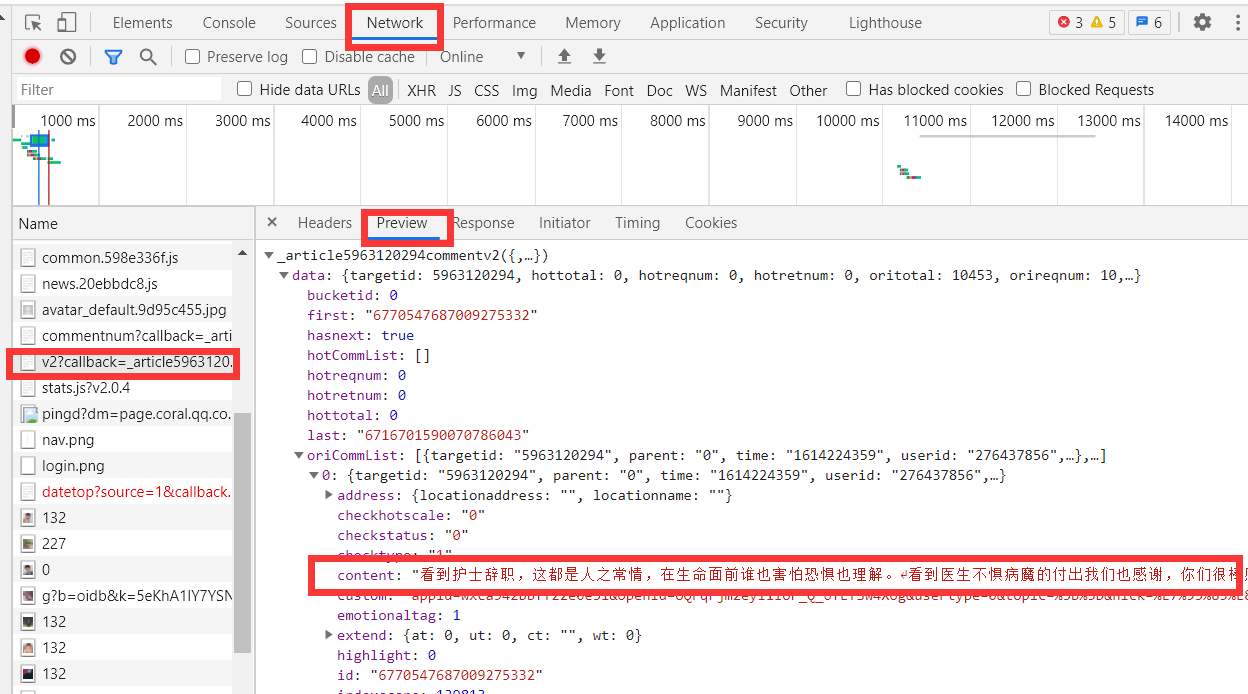
此刻,我便清楚如何爬取数据了,获取每个v2开头的标签的地址,并在其中用正则爬取评论数据(毕竟爬虫也忘得差不多了,也就正则简单还不容易忘)
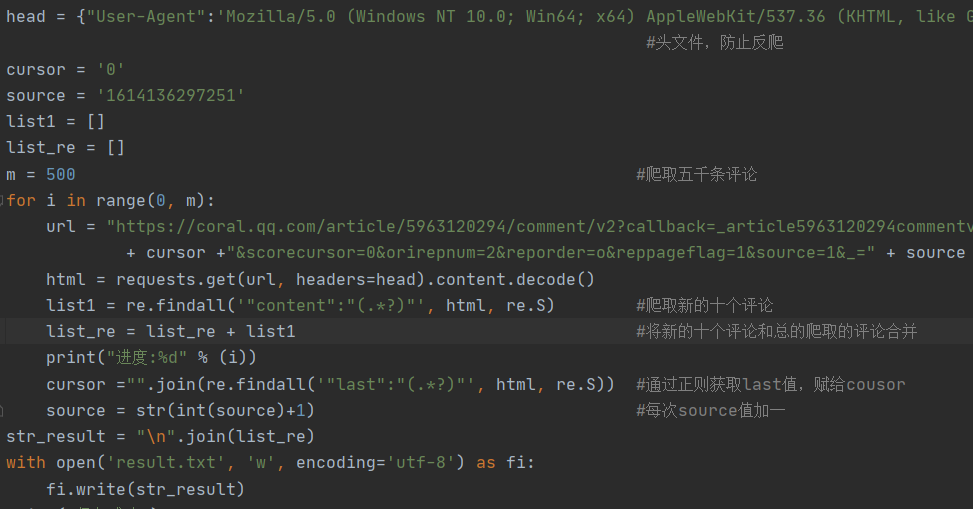
既然要获取地址,但他每次都会有新的v2开头标签的生成。可以发现,每次新生成的地址,只有 cursor 和 source 有区别,再稍加观察,便能发现其中的规律,每更新十个新评论,v2标签地址中的cursor便是上一个标签的last值,而source则直接加一处理便可。

接着便是打开python进行编码爬取评论,将结果保存至 result.txt 文件,提供给 jieba 库使用。
代码如下
- 使用jieba库进行分词
通过网络资料简单了解学习jieba后,发现只要用lcut将数据进行分词即可,但分词后发现会获得大量无用词语,如一直,一个,开始等等,这时我们就需要一个文件来存放无用词,并供得jieba使用,自己写肯定是不现实的其实也不是不行,所以我便从GitHub中找到了一个现成的 无用词库 ,不过添加了之后,还是发现略有不足,还是会出现一些无用的词语,得再自己根据爬取的评论增加一些,才算够用。
代码如下
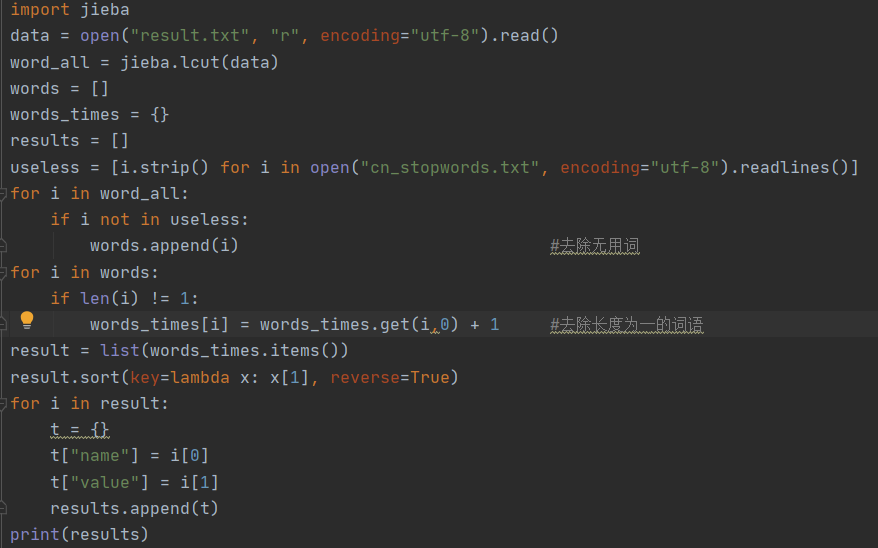
其中在最后一个循环中,不使字典t重新等于空字典,会发生一个非逻辑性的错误,最后结果全部被覆盖为最后一个词语。上网查了资料,发现是字典性质导致,暂时也不深究了。
- 使用echarts生成云词图
这个部分可谓是一片空白,毕竟对这方面的知识可谓是零,查了大量资料,在细节方面疯狂询问同学,才算勉强弄懂。弄懂之后,发现又并不难,选了一个模板之后,发现要将数据弄成列表中套字典才行。
最后自定义形状方面,则需要将图片变成base64码套用进去,好在有 免费的网站 可供转换,方便快捷,需要的自取。
最后产生的词云图如下

3. 上传GitHub
- 克隆远程服务器至本地
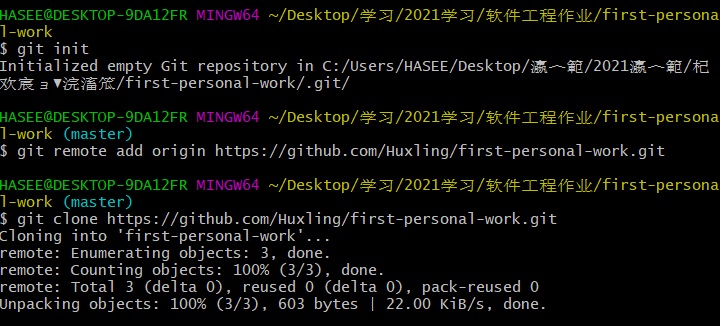
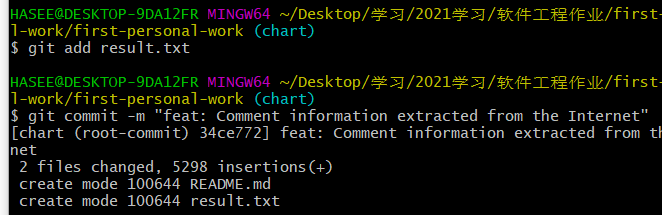
- 创建分支,上传git
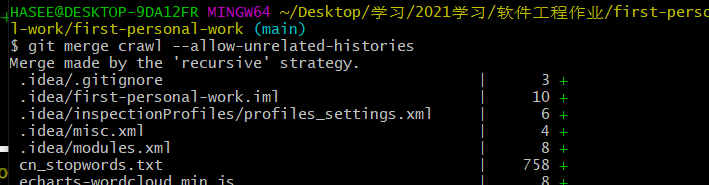
- 合并分支
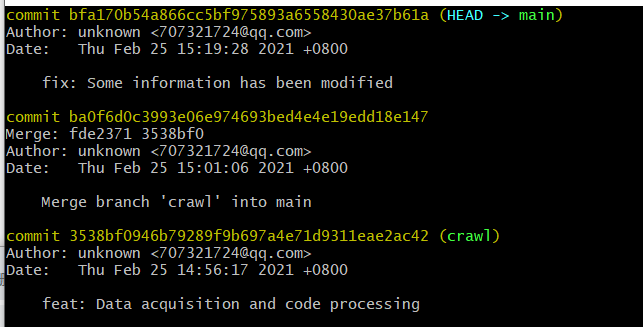
- 五次commit
- 上传至远程库
4. 反思和遇到的难题
- 爬虫知识忘了很多,需要加强编码练习了
- 刚接触 echarts 的时候,甚至不知道该在哪里使用这个东西,最后东查西看才知道是在html中导入使用
- 关于 git 分支朦朦胧胧的,现在知道差不多相当于多条时间线
